Configurar a preparação de AutoML com Python
APLICA-SE A: Python SDK azureml v1
Python SDK azureml v1
Neste guia, saiba como configurar uma machine learning automatizada, AutoML, execução de preparação com o SDK Python do Azure Machine Learning com o ML automatizado do Azure Machine Learning. O ML automatizado escolhe um algoritmo e hiperparâmetros para si e gera um modelo pronto para implementação. Este guia fornece detalhes das várias opções que pode utilizar para configurar experimentações de ML automatizadas.
Para obter um exemplo ponto a ponto, veja Tutorial: AutoML– modelo de regressão de preparação.
Se preferir uma experiência sem código, também pode Configurar a preparação de AutoML sem código no estúdio do Azure Machine Learning.
Pré-requisitos
Para este artigo de que precisa,
Uma área de trabalho do Azure Machine Learning. Para criar a área de trabalho, veja Criar recursos da área de trabalho.
O SDK Python do Azure Machine Learning instalado. Para instalar o SDK, pode,
Crie uma instância de computação, que instala automaticamente o SDK e é pré-configurada para fluxos de trabalho de ML. Veja Criar e gerir uma instância de computação do Azure Machine Learning para obter mais informações.
Instale o
automlpacote, que inclui a instalação predefinida do SDK.
Importante
Os comandos do Python neste artigo requerem a versão mais recente
azureml-train-automldo pacote.- Instale o pacote mais recente
azureml-train-automlno seu ambiente local. - Para obter detalhes sobre o pacote mais recente
azureml-train-automl, veja as notas de versão.
Aviso
O Python 3.8 não é compatível com
automl.
Selecionar o tipo de experimentação
Antes de começar a sua experimentação, deve determinar o tipo de problema de machine learning que está a resolver. O machine learning automatizado suporta tipos de tarefas de classification, regressione forecasting. Saiba mais sobre os tipos de tarefas.
Nota
Suporte para tarefas de processamento de linguagem natural (NLP): a classificação de imagens (multiclasse e várias etiquetas) e o reconhecimento de entidades com nome estão disponíveis na pré-visualização pública. Saiba mais sobre as tarefas NLP no ML automatizado.
Estas capacidades de pré-visualização são fornecidas sem um contrato de nível de serviço. Determinadas funcionalidades podem não ser suportadas ou podem ter funcionalidades restritas. Para obter mais informações, veja Termos Suplementares de Utilização para Pré-visualizações do Microsoft Azure.
O código seguinte utiliza o task parâmetro no AutoMLConfig construtor para especificar o tipo de experimentação como classification.
from azureml.train.automl import AutoMLConfig
# task can be one of classification, regression, forecasting
automl_config = AutoMLConfig(task = "classification")
Origem de dados e formato
O machine learning automatizado suporta os dados que residem no ambiente de trabalho local ou na cloud, como o Armazenamento de Blobs do Azure. Os dados podem ser lidos num DataFrame do Pandas ou num TabularDataset do Azure Machine Learning. Saiba mais sobre os conjuntos de dados.
Requisitos para a preparação de dados no machine learning:
- Os dados têm de estar em formato tabular.
- O valor a prever, coluna de destino, tem de estar nos dados.
Importante
As experimentações de ML automatizadas não suportam a preparação com conjuntos de dados que utilizam o acesso a dados baseado em identidade.
Para experimentações remotas, os dados de preparação têm de estar acessíveis a partir da computação remota. O ML Automatizado só aceita TabularDatasets do Azure Machine Learning quando trabalha numa computação remota.
Os conjuntos de dados do Azure Machine Learning expõem a funcionalidade para:
- Transfira facilmente dados de ficheiros estáticos ou origens de URL para a área de trabalho.
- Tornar os dados disponíveis para os scripts de preparação ao executar os recursos de computação na cloud. Veja Como preparar com conjuntos de dados para obter um exemplo de utilização da
Datasetclasse para montar dados no destino de computação remota.
O código seguinte cria um TabularDataset a partir de um URL web. Veja Criar um TabularDataset para obter exemplos de código sobre como criar conjuntos de dados a partir de outras origens, como ficheiros locais e arquivos de dados.
from azureml.core.dataset import Dataset
data = "https://automlsamplenotebookdata.blob.core.windows.net/automl-sample-notebook-data/creditcard.csv"
dataset = Dataset.Tabular.from_delimited_files(data)
Para experimentações de computação local, recomendamos dataframes pandas para tempos de processamento mais rápidos.
import pandas as pd
from sklearn.model_selection import train_test_split
df = pd.read_csv("your-local-file.csv")
train_data, test_data = train_test_split(df, test_size=0.1, random_state=42)
label = "label-col-name"
Dados de preparação, validação e teste
Pode especificar dados de preparação separados e conjuntos de dados de validação diretamente no AutoMLConfig construtor. Saiba mais sobre como configurar a preparação, a validação, a validação cruzada e os dados de teste para as suas experimentações de AutoML.
Se não especificar explicitamente um validation_data parâmetro ou n_cross_validation , o ML automatizado aplica técnicas predefinidas para determinar como a validação é executada. Esta determinação depende do número de linhas no conjunto de dados atribuído ao parâmetro training_data .
| Tamanho dos dados de preparação | Técnica de validação |
|---|---|
| Maior que 20 000 linhas | A divisão de dados de preparação/validação é aplicada. A predefinição é assumir 10% do conjunto de dados de preparação inicial como o conjunto de validação. Por sua vez, esse conjunto de validação é utilizado para cálculo de métricas. |
| Menor que 20 000 linhas | É aplicada uma abordagem de validação cruzada. O número predefinido de pastas depende do número de linhas. Se o conjunto de dados for inferior a 1000 linhas, são utilizadas 10 pastas. Se as linhas estiverem entre 1000 e 20 000, são utilizadas três pastas. |
Dica
Pode carregar dados de teste (pré-visualização) para avaliar modelos que o ML automatizado gerou automaticamente. Estas funcionalidades são capacidades de pré-visualização experimentais e podem ser alteradas em qualquer altura. Aprenda a:
- Transmita dados de teste para o objeto AutoMLConfig.
- Teste os modelos de ML automatizado gerados para a sua experimentação.
Se preferir uma experiência sem código, consulte o passo 12 em Configurar o AutoML com a IU do estúdio
Dados grandes
O ML Automatizado suporta um número limitado de algoritmos para preparação em dados grandes que podem criar modelos com êxito para macrodados em pequenas máquinas virtuais. A heurística de ML automatizada depende de propriedades como o tamanho dos dados, o tamanho da memória da máquina virtual, o tempo limite da experimentação e as definições de caracterização para determinar se estes algoritmos de dados grandes devem ser aplicados. Saiba mais sobre que modelos são suportados no ML automatizado.
Para regressão, Gradação De Gradação Online Regressor e Regressor Linear Rápido
Para classificação, Classifier Perceptron Médio e Classificador SVM Linear; em que o classificador SVM Linear tem dados grandes e versões de dados pequenas.
Se quiser substituir estas heurísticas, aplique as seguintes definições:
| Tarefa | Definições | Notas |
|---|---|---|
| Bloquear algoritmos de transmissão em fluxo de dados | blocked_models no objeto AutoMLConfig e liste os modelos que não pretende utilizar. |
Resulta numa falha de execução ou num tempo de execução prolongada |
| Utilizar algoritmos de transmissão em fluxo de dados | allowed_models no objeto e liste AutoMLConfig os modelos que pretende utilizar. |
|
| Utilizar algoritmos de transmissão em fluxo de dados (experimentações de IU do estúdio) |
Bloqueie todos os modelos, exceto os algoritmos de macrodados que pretende utilizar. |
Computação para executar a experimentação
Em seguida, determine onde o modelo será preparado. Uma experimentação de preparação de ML automatizada pode ser executada nas seguintes opções de computação.
Escolha uma computação local: se o seu cenário for sobre explorações ou demonstrações iniciais utilizando pequenos dados e comboios curtos (ou seja, segundos ou alguns minutos por execução subordinada), a preparação no seu computador local poderá ser uma escolha melhor. Não existe tempo de configuração, os recursos de infraestrutura (o SEU PC ou VM) estão diretamente disponíveis. Veja este bloco de notas para obter um exemplo de computação local.
Escolher um cluster de computação ML remoto: se estiver a preparar com conjuntos de dados maiores, como na preparação de produção, a criação de modelos que precisam de comboios mais longos, a computação remota proporcionará um desempenho de tempo ponto a ponto muito melhor, uma vez que
AutoMLirá paralelizar os comboios nos nós do cluster. Numa computação remota, o tempo de arranque da infraestrutura interna irá adicionar cerca de 1,5 minutos por execução subordinada, além de minutos adicionais para a infraestrutura do cluster se as VMs ainda não estiverem a funcionar. A Computação Gerida do Azure Machine Learning é um serviço gerido que permite preparar modelos de machine learning em clusters de máquinas virtuais do Azure. A instância de computação também é suportada como um destino de computação.Um cluster do Azure Databricks na sua subscrição do Azure. Pode encontrar mais detalhes em Configurar um cluster do Azure Databricks para ML automatizado. Veja este site do GitHub para obter exemplos de blocos de notas com o Azure Databricks.
Considere estes fatores ao escolher o destino de computação:
| Profissionais (Vantagens) | Contras (Handicaps) | |
|---|---|---|
| Destino de computação local | ||
| Clusters de computação ML remotos |
Configurar as definições da experimentação
Existem várias opções que pode utilizar para configurar a experimentação de ML automatizado. Estes parâmetros são definidos ao instanciar um AutoMLConfig objeto. Veja a classe AutoMLConfig para obter uma lista completa de parâmetros.
O exemplo seguinte destina-se a uma tarefa de classificação. A experimentação utiliza o AUC ponderado como a métrica primária e tem um tempo limite de experimentação definido para 30 minutos e 2 dobras de validação cruzada.
automl_classifier=AutoMLConfig(task='classification',
primary_metric='AUC_weighted',
experiment_timeout_minutes=30,
blocked_models=['XGBoostClassifier'],
training_data=train_data,
label_column_name=label,
n_cross_validations=2)
Também pode configurar tarefas de previsão, o que requer uma configuração adicional. Veja o artigo Configurar o AutoML para previsão de série temporal para obter mais detalhes.
time_series_settings = {
'time_column_name': time_column_name,
'time_series_id_column_names': time_series_id_column_names,
'forecast_horizon': n_test_periods
}
automl_config = AutoMLConfig(
task = 'forecasting',
debug_log='automl_oj_sales_errors.log',
primary_metric='normalized_root_mean_squared_error',
experiment_timeout_minutes=20,
training_data=train_data,
label_column_name=label,
n_cross_validations=5,
path=project_folder,
verbosity=logging.INFO,
**time_series_settings
)
Modelos suportados
A aprendizagem automática automatizada experimenta diferentes modelos e algoritmos durante o processo de automatização e otimização. Enquanto utilizador, não é necessário especificar o algoritmo.
Os três valores de parâmetros diferentes task determinam a lista de algoritmos ou modelos a aplicar. Utilize os allowed_models parâmetros ou blocked_models para modificar ainda mais as iterações com os modelos disponíveis para incluir ou excluir.
A tabela seguinte resume os modelos suportados por tipo de tarefa.
Nota
Se planear exportar os seus modelos de ML automatizados criados para um modelo ONNX, apenas os algoritmos indicados com um * (asterisco) podem ser convertidos no formato ONNX. Saiba mais sobre como converter modelos em ONNX.
Tenha também em atenção que a ONNX só suporta tarefas de classificação e regressão neste momento.
Métrica primária
O primary_metric parâmetro determina a métrica a ser utilizada durante a preparação de modelos para otimização. As métricas disponíveis que pode selecionar são determinadas pelo tipo de tarefa que escolher.
Escolher uma métrica primária para otimizar o ML automatizado depende de muitos fatores. Recomendamos que a sua principal consideração seja escolher uma métrica que melhor represente as suas necessidades empresariais. Em seguida, considere se a métrica é adequada para o seu perfil de conjunto de dados (tamanho de dados, intervalo, distribuição de classes, etc.). As secções seguintes resumem as métricas primárias recomendadas com base no tipo de tarefa e no cenário empresarial.
Saiba mais sobre as definições específicas destas métricas em Compreender os resultados de machine learning automatizado.
Métricas para cenários de classificação
As métricas dependentes de limiares, como accuracy, recall_score_weighted, norm_macro_recalle precision_score_weighted podem não ser otimizadas também para conjuntos de dados que são pequenos, têm uma distorção de classe muito grande (desequilíbrio de classe) ou quando o valor de métrica esperado está muito próximo de 0,0 ou 1,0. Nesses casos, AUC_weighted pode ser uma escolha melhor para a métrica primária. Após a conclusão do ML automatizado, pode escolher o modelo vencedor com base na métrica mais adequada às suas necessidades empresariais.
| Metric | Casos de utilização de exemplo |
|---|---|
accuracy |
Classificação de imagens, Análise de sentimentos, predição de Churn |
AUC_weighted |
Deteção de fraudes, Classificação de imagens, Deteção de anomalias/deteção de spam |
average_precision_score_weighted |
Análise de sentimentos |
norm_macro_recall |
Predição de alterações |
precision_score_weighted |
Métricas para cenários de regressão
r2_scoree normalized_mean_absolute_errornormalized_root_mean_squared_error estão todos a tentar minimizar os erros de predição. r2_score e normalized_root_mean_squared_error estão a minimizar os erros quadrados médios enquanto normalized_mean_absolute_error está a minimizar o valor absoluto médio dos erros. O valor absoluto trata os erros de todas as magnitudes e os erros quadrados terão uma penalização muito maior por erros com valores absolutos maiores. Dependendo se os erros maiores devem ou não ser punidos, pode optar por otimizar o erro ao quadrado ou o erro absoluto.
A principal diferença entre r2_score e normalized_root_mean_squared_error é a forma como são normalizadas e os seus significados. normalized_root_mean_squared_error é um erro quadrado médio de raiz normalizado por intervalo e pode ser interpretado como a magnitude média do erro para a predição. r2_score é um erro quadrado médio normalizado por uma estimativa da variância dos dados. É a proporção de variação que pode ser capturada pelo modelo.
Nota
r2_score e normalized_root_mean_squared_error também se comportam da mesma forma que as métricas primárias. Se for aplicado um conjunto de validação fixo, estas duas métricas estão a otimizar o mesmo destino, erro quadrado médio e serão otimizadas pelo mesmo modelo. Quando apenas um conjunto de preparação está disponível e a validação cruzada é aplicada, seria ligeiramente diferente, uma vez que o normalizador para normalized_root_mean_squared_error é corrigido como o intervalo de conjunto de preparação, mas o normalizador para r2_score variaria para cada dobra, uma vez que é a variância para cada dobra.
Se a classificação, em vez do valor exato for de interesse, pode ser uma escolha melhor, spearman_correlation uma vez que mede a correlação de classificação entre valores reais e predições.
No entanto, atualmente, nenhuma métrica primária para regressão resolve a diferença relativa. Todos , normalized_mean_absolute_errore normalized_root_mean_squared_error tratem um erro de predição de r2_score20 mil dólares da mesma forma para um trabalhador com um salário de 30 mil dólares como um trabalhador a ganhar 20 milhões de dólares, se estes dois pontos de dados pertencerem ao mesmo conjunto de dados para regressão ou à mesma série temporal especificada pelo identificador da série temporal. Na realidade, prever apenas 20 mil dólares de um salário de 20 milhões de dólares é muito próximo (uma pequena diferença relativa de 0,1%), enquanto 20 mil dólares de 30 mil dólares não estão perto (uma grande diferença relativa de 67%). Para resolver o problema da diferença relativa, pode preparar um modelo com métricas primárias disponíveis e, em seguida, selecionar o modelo com o melhor mean_absolute_percentage_error ou root_mean_squared_log_error.
| Metric | Casos de utilização de exemplo |
|---|---|
spearman_correlation |
|
normalized_root_mean_squared_error |
Predição de preços (casa/produto/sugestão), Previsão de classificação de revisão |
r2_score |
Atraso da companhia aérea, Estimativa salarial, Tempo de resolução de erros |
normalized_mean_absolute_error |
Métricas para cenários de previsão de série temporal
As recomendações são semelhantes às indicadas para cenários de regressão.
| Metric | Casos de utilização de exemplo |
|---|---|
normalized_root_mean_squared_error |
Predição de preços (previsão), Otimização do inventário, Previsão da procura |
r2_score |
Predição de preços (previsão), Otimização do inventário, Previsão da procura |
normalized_mean_absolute_error |
Caracterização de dados
Em todas as experimentações de ML automatizadas, os seus dados são dimensionados e normalizados automaticamente para ajudar determinados algoritmos sensíveis a funcionalidades que estão em escalas diferentes. Este dimensionamento e normalização são referidos como caracterização. Veja Caracterização no AutoML para obter mais detalhes e exemplos de código.
Nota
Os passos de caracterização de machine learning automatizados (normalização de funcionalidades, processamento de dados em falta, conversão de texto em numérico, etc.) tornam-se parte do modelo subjacente. Ao utilizar o modelo para predições, os mesmos passos de caracterização aplicados durante a preparação são aplicados automaticamente aos dados de entrada.
Ao configurar as experimentações no objeto AutoMLConfig , pode ativar/desativar a definição featurization. A tabela seguinte mostra as definições aceites para a caracterização no objeto AutoMLConfig.
| Configuração de Caracterização | Description |
|---|---|
"featurization": 'auto' |
Indica que, como parte do pré-processamento, as proteções de dados e os passos de caracterização são executados automaticamente. Predefinição. |
"featurization": 'off' |
Indica que o passo de caracterização não deve ser feito automaticamente. |
"featurization": 'FeaturizationConfig' |
Indica que deve ser utilizado o passo de caracterização personalizado. Saiba como personalizar a caracterização. |
Configuração do conjunto
Os modelos de conjunto estão ativados por predefinição e aparecem como iterações de execução final numa execução autoML. Atualmente, o VotingEnsemble e o StackEnsemble são suportados.
A votação implementa o voto suave, que utiliza médias ponderadas. A implementação do empilhamento utiliza uma implementação de duas camadas, em que a primeira camada tem os mesmos modelos que o conjunto de votação e o segundo modelo de camada é utilizado para encontrar a combinação ideal dos modelos da primeira camada.
Se estiver a utilizar modelos ONNX ou tiver a explicação do modelo ativada, o empilhamento está desativado e só é utilizada a votação.
A preparação do conjunto pode ser desativada com os enable_voting_ensemble parâmetros booleanos e enable_stack_ensemble .
automl_classifier = AutoMLConfig(
task='classification',
primary_metric='AUC_weighted',
experiment_timeout_minutes=30,
training_data=data_train,
label_column_name=label,
n_cross_validations=5,
enable_voting_ensemble=False,
enable_stack_ensemble=False
)
Para alterar o comportamento predefinido do conjunto, existem vários argumentos predefinidos que podem ser fornecidos como kwargs num AutoMLConfig objeto.
Importante
Os parâmetros seguintes não são parâmetros explícitos da classe AutoMLConfig.
ensemble_download_models_timeout_sec: Durante a geração de modelos VotingEnsemble e StackEnsemble , são transferidos vários modelos ajustados das execuções subordinadas anteriores. Se encontrar este erro:AutoMLEnsembleException: Could not find any models for running ensembling, poderá ter de fornecer mais tempo para que os modelos sejam transferidos. O valor predefinido é de 300 segundos para transferir estes modelos em paralelo e não existe um limite máximo de tempo limite. Configure este parâmetro com um valor superior a 300 segundos, se for necessário mais tempo.Nota
Se o tempo limite for atingido e existirem modelos transferidos, o ensembling continua com o número de modelos que transferiu. Não é necessário que todos os modelos precisem de ser transferidos para serem concluídos dentro desse tempo limite. Os seguintes parâmetros aplicam-se apenas aos modelos StackEnsemble :
stack_meta_learner_type: o meta-aprendiz é um modelo preparado para a saída dos modelos heterogéneos individuais. Os meta-alunos predefinidos destinam-seLogisticRegressiona tarefas de classificação (ouLogisticRegressionCVse a validação cruzada estiver ativada) eElasticNetpara tarefas de regressão/previsão (ouElasticNetCVse a validação cruzada estiver ativada). Este parâmetro pode ser uma das seguintes cadeias:LogisticRegression, ,LogisticRegressionCV,LightGBMClassifier,ElasticNetElasticNetCV, ,LightGBMRegressorouLinearRegression.stack_meta_learner_train_percentage: especifica a proporção do conjunto de preparação (ao escolher o tipo de preparação e de validação) a reservar para a preparação do meta-aluno. O valor predefinido é0.2.stack_meta_learner_kwargs: parâmetros opcionais para passar para o inicializador do meta-learner. Estes parâmetros e tipos de parâmetros espelham os parâmetros e os tipos de parâmetros do construtor de modelos correspondente e são reencaminhados para o construtor de modelos.
O código seguinte mostra um exemplo de especificação do comportamento do conjunto personalizado num AutoMLConfig objeto.
ensemble_settings = {
"ensemble_download_models_timeout_sec": 600
"stack_meta_learner_type": "LogisticRegressionCV",
"stack_meta_learner_train_percentage": 0.3,
"stack_meta_learner_kwargs": {
"refit": True,
"fit_intercept": False,
"class_weight": "balanced",
"multi_class": "auto",
"n_jobs": -1
}
}
automl_classifier = AutoMLConfig(
task='classification',
primary_metric='AUC_weighted',
experiment_timeout_minutes=30,
training_data=train_data,
label_column_name=label,
n_cross_validations=5,
**ensemble_settings
)
Critérios de saída
Existem algumas opções que pode definir na sua AutoMLConfig para terminar a experimentação.
| Critérios | descrição |
|---|---|
| Sem critérios | Se não definir quaisquer parâmetros de saída, a experimentação continuará até que não sejam feitos mais progressos na métrica primária. |
| Após um período de tempo | Utilize experiment_timeout_minutes nas suas definições para definir durante quanto tempo, em minutos, a sua experimentação deve continuar a ser executada. Para ajudar a evitar falhas de tempo limite da experimentação, existe um mínimo de 15 minutos ou 60 minutos se o tamanho da linha por coluna exceder os 10 milhões. |
| Foi alcançada uma classificação | A utilização experiment_exit_score conclui a experimentação depois de ter sido alcançada uma classificação de métrica primária especificada. |
Executar experimentação
Aviso
Se executar uma experimentação com as mesmas definições de configuração e métrica primária várias vezes, provavelmente verá variação em cada classificação de métricas final de experimentações e modelos gerados. Os algoritmos utilizados pelo ML automatizado têm aleatoriedade inerente que pode causar uma ligeira variação na saída dos modelos pela experimentação e a classificação de métricas final do modelo recomendado, como a precisão. Provavelmente também verá resultados com o mesmo nome de modelo, mas diferentes hiperparâmetros utilizados.
Para o ML automatizado, vai criar um Experiment objeto, que é um objeto com nome num Workspace utilizado para executar experimentações.
from azureml.core.experiment import Experiment
ws = Workspace.from_config()
# Choose a name for the experiment and specify the project folder.
experiment_name = 'Tutorial-automl'
project_folder = './sample_projects/automl-classification'
experiment = Experiment(ws, experiment_name)
Submeta a experimentação para executar e gerar um modelo. Transmita o AutoMLConfig para o submit método para gerar o modelo.
run = experiment.submit(automl_config, show_output=True)
Nota
As dependências são instaladas primeiro num novo computador. Pode demorar até 10 minutos até que a saída seja apresentada.
A definição show_output para True resulta na apresentação da saída na consola do .
Várias execuções subordinadas em clusters
As execuções subordinadas de experimentação de ML automatizadas podem ser executadas num cluster que já está a executar outra experimentação. No entanto, a temporização depende do número de nós que o cluster tem e se esses nós estão disponíveis para executar uma experimentação diferente.
Cada nó no cluster atua como uma máquina virtual (VM) individual que pode realizar uma única execução de preparação; para ML automatizado, isto significa uma execução subordinada. Se todos os nós estiverem ocupados, a nova experimentação será colocada em fila. No entanto, se existirem nós gratuitos, a nova experimentação executará execuções subordinadas de ML automatizadas em paralelo nos nós/VMs disponíveis.
Para ajudar a gerir as execuções subordinadas e quando podem ser executadas, recomendamos que crie um cluster dedicado por experimentação e corresponda o número da max_concurrent_iterations experimentação ao número de nós no cluster. Desta forma, utiliza todos os nós do cluster ao mesmo tempo com o número de execuções/iterações subordinadas em simultâneo que pretende.
Configure max_concurrent_iterations no objeto AutoMLConfig . Se não estiver configurado, por predefinição, só é permitida uma execução/iteração subordinada simultânea por experimentação.
Em caso de instância de computação, max_concurrent_iterations pode ser definido como sendo o mesmo que o número de núcleos na VM da instância de computação.
Explorar modelos e métricas
O ML Automatizado oferece opções para monitorizar e avaliar os resultados da preparação.
Pode ver os seus resultados de preparação num widget ou inline se estiver num bloco de notas. Veja Monitorizar as execuções automáticas de machine learning para obter mais detalhes.
Para obter definições e exemplos dos gráficos de desempenho e métricas fornecidos para cada execução, veja Avaliar os resultados da experimentação de machine learning automatizado.
Para obter um resumo de caracterização e compreender que funcionalidades foram adicionadas a um modelo específico, veja Transparência da caracterização.
Pode ver os hiperparâmetros, as técnicas de dimensionamento e normalização e o algoritmo aplicado a uma execução de ML automatizada específica com a solução de código personalizado. print_model()
Dica
O ML Automatizado também lhe permite ver o código de preparação do modelo gerado para modelos preparados para ML Automático. Esta funcionalidade está em pré-visualização pública e pode ser alterada em qualquer altura.
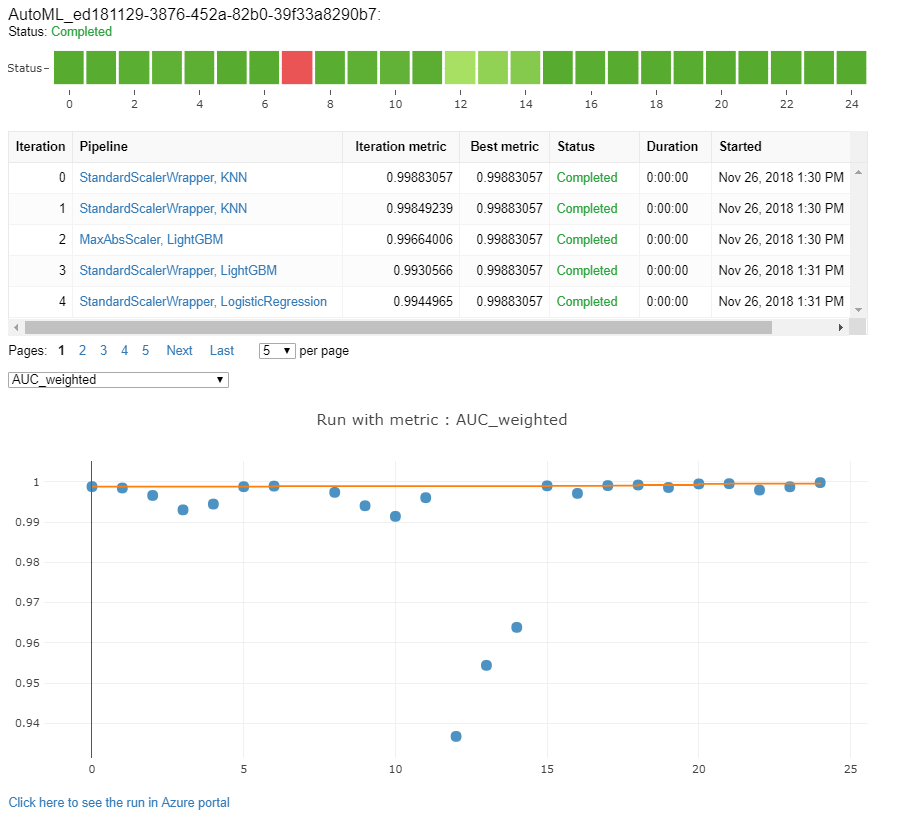
Monitorizar execuções automatizadas de machine learning
Para execuções de ML automatizadas, para aceder aos gráficos de uma execução anterior, substitua <<experiment_name>> pelo nome de experimentação adequado:
from azureml.widgets import RunDetails
from azureml.core.run import Run
experiment = Experiment (workspace, <<experiment_name>>)
run_id = 'autoML_my_runID' #replace with run_ID
run = Run(experiment, run_id)
RunDetails(run).show()
Modelos de teste (pré-visualização)
Importante
Testar os modelos com um conjunto de dados de teste para avaliar modelos automatizados gerados por ML é uma funcionalidade de pré-visualização. Esta capacidade é uma funcionalidade de pré-visualização experimental e pode ser alterada em qualquer altura.
Aviso
Esta funcionalidade não está disponível para os seguintes cenários de ML automatizados
- Tarefas de imagem digitalizada
- Muitos modelos e preparação de previsão de série temporal hiearquista (pré-visualização)
- Tarefas de previsão em que as redes neurais de aprendizagem profunda (DNN) estão ativadas
- O ML automatizado é executado a partir de computação local ou clusters do Azure Databricks
Transmitir os test_data parâmetros ou test_size para o AutoMLConfig, aciona automaticamente uma execução de teste remota que utiliza os dados de teste fornecidos para avaliar o melhor modelo que o ML automatizado recomenda após a conclusão da experimentação. Esta execução de teste remoto é efetuada no final da experimentação, uma vez determinado o melhor modelo. Veja como transmitir dados de teste para o seu AutoMLConfig.
Obter resultados da tarefa de teste
Pode obter as predições e as métricas da tarefa de teste remoto a partir do estúdio do Azure Machine Learning ou com o seguinte código.
best_run, fitted_model = remote_run.get_output()
test_run = next(best_run.get_children(type='automl.model_test'))
test_run.wait_for_completion(show_output=False, wait_post_processing=True)
# Get test metrics
test_run_metrics = test_run.get_metrics()
for name, value in test_run_metrics.items():
print(f"{name}: {value}")
# Get test predictions as a Dataset
test_run_details = test_run.get_details()
dataset_id = test_run_details['outputDatasets'][0]['identifier']['savedId']
test_run_predictions = Dataset.get_by_id(workspace, dataset_id)
predictions_df = test_run_predictions.to_pandas_dataframe()
# Alternatively, the test predictions can be retrieved via the run outputs.
test_run.download_file("predictions/predictions.csv")
predictions_df = pd.read_csv("predictions.csv")
A tarefa de teste de modelo gera o ficheiro predictions.csv armazenado no arquivo de dados predefinido criado com a área de trabalho. Este arquivo de dados é visível para todos os utilizadores com a mesma subscrição. As tarefas de teste não são recomendadas para cenários se alguma das informações utilizadas ou criadas pela tarefa de teste precisar de permanecer privada.
Testar o modelo de ML automatizado existente
Para testar outros modelos de ML automatizados existentes criados, a melhor tarefa ou tarefa subordinada, utilize ModelProxy() para testar um modelo após a conclusão da execução principal do AutoML. ModelProxy() já devolve as predições e as métricas e não requer processamento adicional para obter as saídas.
Nota
O ModelProxy é uma classe de pré-visualização experimental e pode ser alterado em qualquer altura.
O código seguinte demonstra como testar um modelo a partir de qualquer execução com o método ModelProxy.test( ). No método test(), tem a opção de especificar se apenas quer ver as predições da execução do teste com o include_predictions_only parâmetro .
from azureml.train.automl.model_proxy import ModelProxy
model_proxy = ModelProxy(child_run=my_run, compute_target=cpu_cluster)
predictions, metrics = model_proxy.test(test_data, include_predictions_only= True
)
Registar e implementar modelos
Depois de testar um modelo e confirmar que pretende utilizá-lo em produção, pode registá-lo para utilização posterior e
Para registar um modelo a partir de uma execução de ML automatizada, utilize o register_model() método .
best_run = run.get_best_child()
print(fitted_model.steps)
model_name = best_run.properties['model_name']
description = 'AutoML forecast example'
tags = None
model = run.register_model(model_name = model_name,
description = description,
tags = tags)
Para obter detalhes sobre como criar uma configuração de implementação e implementar um modelo registado num serviço Web, veja como e onde implementar um modelo.
Dica
Para modelos registados, a implementação com um clique está disponível através do estúdio do Azure Machine Learning. Veja como implementar modelos registados a partir do estúdio.
Capacidade de interpretação do modelo
A interpretabilidade dos modelos permite-lhe compreender por que motivo os modelos fizeram predições e os valores de importância de funcionalidade subjacentes. O SDK inclui vários pacotes para ativar as funcionalidades de interpretação do modelo, tanto em tempo de preparação como em tempo de inferência, para modelos locais e implementados.
Veja como ativar funcionalidades de interpretação especificamente em experimentações de ML automatizadas.
Para obter informações gerais sobre como as explicações de modelos e a importância das funcionalidades podem ser ativadas noutras áreas do SDK fora do machine learning automatizado, veja o artigo de conceito sobre interpretabilidade .
Nota
O modelo ForecastTCN não é atualmente suportado pelo Cliente de Explicação. Este modelo não devolverá um dashboard de explicação se for devolvido como o melhor modelo e não suportará execuções de explicações a pedido.