Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Saiba como usar o SDK do Azure para .NET para criar um pipeline de enriquecimento de IA para extração de conteúdo e transformações durante a indexação.
Os conjuntos de habilidades adicionam processamento de IA ao conteúdo bruto, tornando-o mais uniforme e pesquisável. Depois de saber como os conjuntos de habilidades funcionam, você pode oferecer suporte a uma ampla gama de transformações, desde a análise de imagens até o processamento de linguagem natural e o processamento personalizado que você fornece externamente.
Neste tutorial, você:
- Defina objetos em um pipeline de enriquecimento.
- Construa um conjunto de habilidades. Invoque OCR, deteção de idioma, reconhecimento de entidade e extração de frases-chave.
- Execute a canalização. Crie e carregue um índice de pesquisa.
- Verifique os resultados usando a pesquisa de texto completo.
Descrição geral
Este tutorial usa C# e a biblioteca de cliente Azure.Search.Documents para criar uma fonte de dados, índice, indexador e conjunto de habilidades.
O indexador conduz cada etapa do pipeline, começando com a extração de conteúdo de dados de exemplo (texto e imagens não estruturados) em um contêiner de blob no Armazenamento do Azure.
Depois que o conteúdo é extraído, o conjunto de habilidades executa habilidades internas da Microsoft para encontrar e extrair informações. Essas habilidades incluem Reconhecimento Ótico de Caracteres (OCR) em imagens, deteção de linguagem em texto, extração de frases-chave e reconhecimento de entidades (organizações). Novas informações criadas pelo conjunto de competências são enviadas para os campos de um índice. Depois que o índice for preenchido, você poderá usar os campos em consultas, facetas e filtros.
Pré-requisitos
Uma conta do Azure com uma assinatura ativa. Crie uma conta gratuitamente.
Nota
Você pode usar um serviço de pesquisa gratuito para este tutorial. O nível Gratuito limita você a três índices, três indexadores e três fontes de dados. Este tutorial cria um exemplar de cada. Antes de começar, certifique-se de que tem espaço no seu serviço para aceitar os novos recursos.
Transferir ficheiros
Faça o download de um arquivo zip do repositório de dados de exemplo e extraia o conteúdo. Saiba como.
Carregar dados de exemplo para o Armazenamento do Azure
No Armazenamento do Azure, crie um novo contêiner e nomeie-o como cog-search-demo.
Carregue os arquivos de dados de exemplo.
Obtenha uma cadeia de conexão de armazenamento para que você possa formular uma conexão no Azure AI Search.
À esquerda, selecione Teclas de acesso.
Copie a cadeia de conexão para a chave um ou a chave dois. A cadeia de conexão é semelhante ao exemplo a seguir:
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
Serviços de IA do Azure
O enriquecimento de IA incorporado é apoiado pelos serviços de IA do Azure, incluindo o serviço de linguagem e o Azure AI Vision para processamento de imagem e linguagem natural. Para pequenas cargas de trabalho como este tutorial, você pode usar a alocação gratuita de 20 transações por indexador. Para cargas de trabalho maiores, anexe um recurso multirregional dos Serviços de IA do Azure a um conjunto de habilidades para preços padrão.
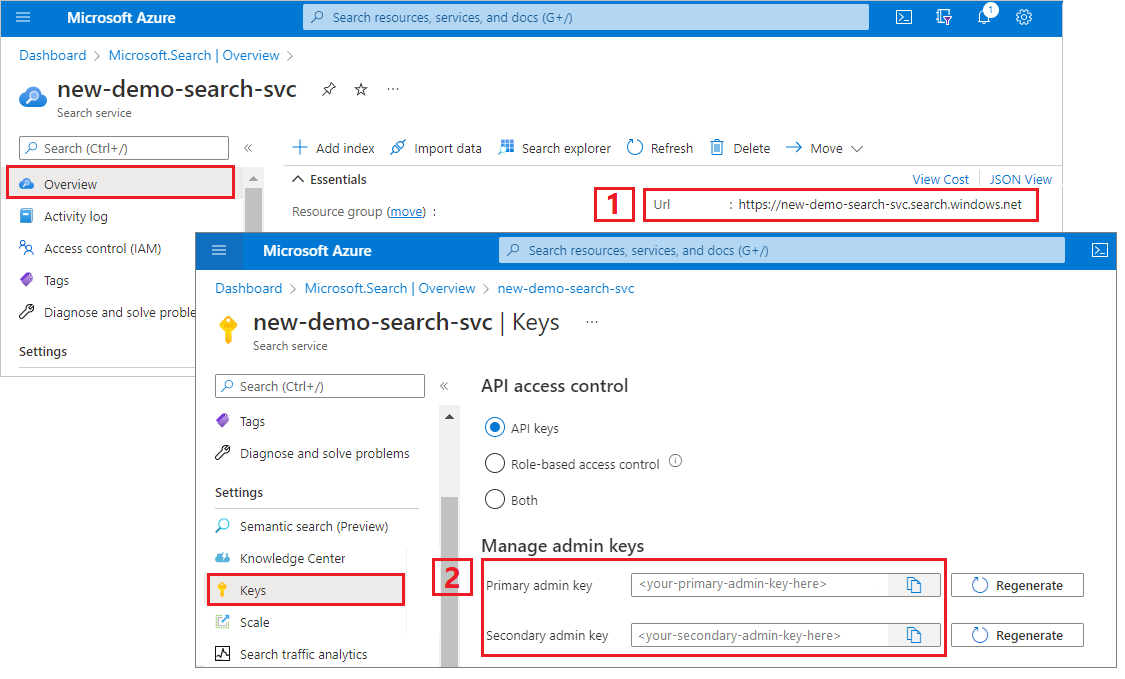
Copiar um URL de serviço de pesquisa e uma chave de API
Para este tutorial, as ligações ao Azure AI Search requerem um ponto de extremidade e uma chave de API. Você pode obter esses valores no portal do Azure.
Entre no portal do Azure, navegue até a página Visão geral do serviço de pesquisa e copie a URL. Um ponto final de exemplo poderá ser parecido com
https://mydemo.search.windows.net.Em Configurações>Teclas, copie uma chave de administrador. As chaves de administrador são usadas para adicionar, modificar e excluir objetos. Existem duas chaves de administração intercambiáveis. Copie qualquer uma delas.
Configurar o ambiente
Comece abrindo o Visual Studio e criando um novo projeto de Aplicativo de Console que pode ser executado no .NET Core.
Instalar Azure.Search.Documents
O SDK .NET do Azure AI Search consiste em uma biblioteca de cliente que permite gerenciar seus índices, fontes de dados, indexadores e conjuntos de habilidades, bem como carregar e gerenciar documentos e executar consultas, tudo sem ter que lidar com os detalhes de HTTP e JSON. Esta biblioteca de cliente é distribuída como um pacote NuGet.
Para este projeto, instale a versão 11 ou posterior do Azure.Search.Documents e a versão mais recente do Microsoft.Extensions.Configuration.
No Visual Studio, selecione Ferramentas>Gestor de Pacotes NuGet>Gerir Pacotes NuGet para a Solução...
Pesquisar por Azure.Search.Document.
Selecione a versão mais recente e, em seguida, selecione Instalar.
Repita as etapas anteriores para instalar Microsoft.Extensions.Configuration e Microsoft.Extensions.Configuration.Json.
Adicionar informações de conexão de serviço
Clique com o botão direito do mouse em seu projeto no Gerenciador de Soluções e selecione Adicionar>Novo Item... .
Nomeie o arquivo
appsettings.jsone selecione Adicionar.Inclua este arquivo no diretório de saída.
- Clique com o botão direito do mouse em
appsettings.jsone selecione Propriedades. - Altere o valor de Copy to Output Directory para Copy if newer.
- Clique com o botão direito do mouse em
Copie o JSON abaixo para seu novo arquivo JSON.
{ "SearchServiceUri": "<YourSearchServiceUri>", "SearchServiceAdminApiKey": "<YourSearchServiceAdminApiKey>", "SearchServiceQueryApiKey": "<YourSearchServiceQueryApiKey>", "AzureAIServicesKey": "<YourMultiRegionAzureAIServicesKey>", "AzureBlobConnectionString": "<YourAzureBlobConnectionString>" }
Adicione o serviço de pesquisa e as informações da conta de armazenamento de blobs. Lembre-se de que você pode obter essas informações das etapas de provisionamento de serviço indicadas na seção anterior.
Para SearchServiceUri, insira o URL completo.
Adicionar namespaces
No Program.cs, adicione os namespaces a seguir.
using Azure;
using Azure.Search.Documents.Indexes;
using Azure.Search.Documents.Indexes.Models;
using Microsoft.Extensions.Configuration;
using System;
using System.Collections.Generic;
using System.Linq;
namespace EnrichwithAI
Criar um cliente
Crie uma instância de a SearchIndexClient e a SearchIndexerClient em Main.
public static void Main(string[] args)
{
// Create service client
IConfigurationBuilder builder = new ConfigurationBuilder().AddJsonFile("appsettings.json");
IConfigurationRoot configuration = builder.Build();
string searchServiceUri = configuration["SearchServiceUri"];
string adminApiKey = configuration["SearchServiceAdminApiKey"];
string azureAiServicesKey = configuration["AzureAIServicesKey"];
SearchIndexClient indexClient = new SearchIndexClient(new Uri(searchServiceUri), new AzureKeyCredential(adminApiKey));
SearchIndexerClient indexerClient = new SearchIndexerClient(new Uri(searchServiceUri), new AzureKeyCredential(adminApiKey));
}
Nota
Os clientes se conectam ao seu serviço de pesquisa. Para evitar abrir muitas conexões, você deve tentar compartilhar uma única instância em seu aplicativo, se possível. Os métodos são thread-safe para permitir esse compartilhamento.
Adicionar função para sair do programa durante a falha
Este tutorial destina-se a ajudá-lo a entender cada etapa do pipeline de indexação. Se houver um problema crítico que impeça o programa de criar a fonte de dados, o conjunto de habilidades, o índice ou o indexador, o programa enviará a mensagem de erro e sairá para que o problema possa ser compreendido e resolvido.
Adicionar ExitProgram a Main para lidar com cenários que exigem a saída do programa.
private static void ExitProgram(string message)
{
Console.WriteLine("{0}", message);
Console.WriteLine("Press any key to exit the program...");
Console.ReadKey();
Environment.Exit(0);
}
Criar a linha de produção
Na Pesquisa de IA do Azure, o processamento de IA ocorre durante a indexação (ou ingestão de dados). Esta parte do passo a passo cria quatro objetos: fonte de dados, definição de índice, conjunto de habilidades, indexador.
Passo 1: criar uma origem de dados
SearchIndexerClient tem uma DataSourceName propriedade que você pode definir como um SearchIndexerDataSourceConnection objeto. Este objeto fornece todos os métodos necessários para criar, listar, atualizar ou excluir fontes de dados do Azure AI Search.
Crie uma nova SearchIndexerDataSourceConnection instância chamando indexerClient.CreateOrUpdateDataSourceConnection(dataSource). O código a seguir cria uma fonte de dados do tipo AzureBlob.
private static SearchIndexerDataSourceConnection CreateOrUpdateDataSource(SearchIndexerClient indexerClient, IConfigurationRoot configuration)
{
SearchIndexerDataSourceConnection dataSource = new SearchIndexerDataSourceConnection(
name: "demodata",
type: SearchIndexerDataSourceType.AzureBlob,
connectionString: configuration["AzureBlobConnectionString"],
container: new SearchIndexerDataContainer("cog-search-demo"))
{
Description = "Demo files to demonstrate Azure AI Search capabilities."
};
// The data source does not need to be deleted if it was already created
// since we are using the CreateOrUpdate method
try
{
indexerClient.CreateOrUpdateDataSourceConnection(dataSource);
}
catch (Exception ex)
{
Console.WriteLine("Failed to create or update the data source\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without a data source");
}
return dataSource;
}
Para uma solicitação bem-sucedida, o método retorna a fonte de dados que foi criada. Se houver um problema com a solicitação, como um parâmetro inválido, o método lançará uma exceção.
Agora, no Main, adiciona uma linha para chamar a função CreateOrUpdateDataSource que acabaste de adicionar.
// Create or Update the data source
Console.WriteLine("Creating or updating the data source...");
SearchIndexerDataSourceConnection dataSource = CreateOrUpdateDataSource(indexerClient, configuration);
Crie e execute a solução. Como essa é sua primeira solicitação, verifique o portal do Azure para confirmar que a fonte de dados foi criada no Azure AI Search. Na página de visão geral do serviço de pesquisa, verifique se a lista Fontes de Dados tem um novo item. Talvez seja necessário aguardar alguns minutos para que a página do portal do Azure seja atualizada.

Etapa 2: Criar um conjunto de habilidades
Nesta seção, você define um conjunto de etapas de enriquecimento que deseja aplicar aos seus dados. Cada etapa de enriquecimento é chamada de habilidade e o conjunto de etapas de enriquecimento, um conjunto de habilidades. Este tutorial usa habilidades internas para o conjunto de habilidades:
Reconhecimento ótico de caracteres para reconhecer texto impresso e manuscrito em arquivos de imagem.
Fusão de texto para consolidar o texto de uma coleção de campos em um único campo de "conteúdo mesclado".
Deteção de Idioma para identificar o idioma do conteúdo.
Reconhecimento de Entidades para extrair os nomes das organizações do conteúdo no contentor de blob.
Divisão de Texto para dividir conteúdo grande em partes menores antes de chamar a técnica de extração de frase-chave e a técnica de reconhecimento de entidade. A extração de frases-chave e o reconhecimento de entidades aceitam entradas de 50.000 caracteres ou menos. Alguns dos ficheiros de exemplo precisam de ser divididos para caberem dentro deste limite.
Extração de Expressões-Chave para extrair as principais expressões-chave.
Durante o processamento inicial, o Azure AI Search quebra cada documento para extrair conteúdo de diferentes formatos de arquivo. O texto originado no arquivo de origem é colocado em um campo gerado content , um para cada documento. Como tal, defina a entrada como "/document/content" para usar este texto. O conteúdo da imagem é colocado num campo gerado normalized_images, especificado num conjunto de competências como /document/normalized_images/*.
As saídas podem ser mapeadas para um índice, utilizadas como entradas para uma tarefa subsequente, ou ambas, como no caso do código de língua. No índice, o código de idioma é útil para a filtragem. Como entrada, o código de idioma é utilizado pelas competências de análise de texto para informar sobre as regras linguísticas em torno da separação de palavras.
Para obter mais informações acerca das noções básicas do conjunto de competências, veja Como definir um conjunto de competências.
Habilidade OCR
O OcrSkill extrai texto de imagens. Esta competência pressupõe a existência de um campo normalized_images. Para gerar este campo, mais adiante no tutorial definimos a "imageAction" configuração na definição do indexador como "generateNormalizedImages".
private static OcrSkill CreateOcrSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("image")
{
Source = "/document/normalized_images/*"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("text")
{
TargetName = "text"
});
OcrSkill ocrSkill = new OcrSkill(inputMappings, outputMappings)
{
Description = "Extract text (plain and structured) from image",
Context = "/document/normalized_images/*",
DefaultLanguageCode = OcrSkillLanguage.En,
ShouldDetectOrientation = true
};
return ocrSkill;
}
Competência de mesclagem
Nesta seção, você cria um MergeSkill que mescla o campo de conteúdo do documento com o texto que foi produzido pela habilidade OCR.
private static MergeSkill CreateMergeSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/content"
});
inputMappings.Add(new InputFieldMappingEntry("itemsToInsert")
{
Source = "/document/normalized_images/*/text"
});
inputMappings.Add(new InputFieldMappingEntry("offsets")
{
Source = "/document/normalized_images/*/contentOffset"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("mergedText")
{
TargetName = "merged_text"
});
MergeSkill mergeSkill = new MergeSkill(inputMappings, outputMappings)
{
Description = "Create merged_text which includes all the textual representation of each image inserted at the right location in the content field.",
Context = "/document",
InsertPreTag = " ",
InsertPostTag = " "
};
return mergeSkill;
}
Habilidade de deteção de idioma
O LanguageDetectionSkill deteta o idioma do texto de entrada e relata um único código de idioma para cada documento enviado na solicitação. Usamos a saída da habilidade de Deteção de Idioma como parte da entrada para a habilidade de Divisão de Texto .
private static LanguageDetectionSkill CreateLanguageDetectionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/merged_text"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("languageCode")
{
TargetName = "languageCode"
});
LanguageDetectionSkill languageDetectionSkill = new LanguageDetectionSkill(inputMappings, outputMappings)
{
Description = "Detect the language used in the document",
Context = "/document"
};
return languageDetectionSkill;
}
Habilidade de divisão de texto
O texto abaixo SplitSkill divide o texto por páginas e limita o comprimento da página a 4.000 caracteres, conforme medido pelo String.Length. O algoritmo tenta dividir o texto em partes que são, no máximo maximumPageLength , em tamanho. Neste caso, o algoritmo faz o seu melhor para quebrar a frase em um limite de frase, então o tamanho do pedaço pode ser um pouco menor do que maximumPageLength.
private static SplitSkill CreateSplitSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/merged_text"
});
inputMappings.Add(new InputFieldMappingEntry("languageCode")
{
Source = "/document/languageCode"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("textItems")
{
TargetName = "pages",
});
SplitSkill splitSkill = new SplitSkill(inputMappings, outputMappings)
{
Description = "Split content into pages",
Context = "/document",
TextSplitMode = TextSplitMode.Pages,
MaximumPageLength = 4000,
DefaultLanguageCode = SplitSkillLanguage.En
};
return splitSkill;
}
Habilidade de reconhecimento de entidades
Esta EntityRecognitionSkill instância é definida para reconhecer o tipo de categoria organization. O EntityRecognitionSkill também pode reconhecer tipos person de categoria e location.
Observe que o campo "contexto" está definido como "/document/pages/*" com um asterisco, o que significa que a etapa de enriquecimento é chamada para cada página em "/document/pages".
private static EntityRecognitionSkill CreateEntityRecognitionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/pages/*"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("organizations")
{
TargetName = "organizations"
});
EntityRecognitionSkill entityRecognitionSkill = new EntityRecognitionSkill(inputMappings, outputMappings)
{
Description = "Recognize organizations",
Context = "/document/pages/*",
DefaultLanguageCode = EntityRecognitionSkillLanguage.En
};
entityRecognitionSkill.Categories.Add(EntityCategory.Organization);
return entityRecognitionSkill;
}
Habilidade de extração de frases-chave
Como a instância EntityRecognitionSkill que acabou de ser criada, a KeyPhraseExtractionSkill é chamada para cada página do documento.
private static KeyPhraseExtractionSkill CreateKeyPhraseExtractionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/pages/*"
});
inputMappings.Add(new InputFieldMappingEntry("languageCode")
{
Source = "/document/languageCode"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("keyPhrases")
{
TargetName = "keyPhrases"
});
KeyPhraseExtractionSkill keyPhraseExtractionSkill = new KeyPhraseExtractionSkill(inputMappings, outputMappings)
{
Description = "Extract the key phrases",
Context = "/document/pages/*",
DefaultLanguageCode = KeyPhraseExtractionSkillLanguage.En
};
return keyPhraseExtractionSkill;
}
Construa e desenvolva competências
Constrói o SearchIndexerSkillset usando as habilidades que criaste.
private static SearchIndexerSkillset CreateOrUpdateDemoSkillSet(SearchIndexerClient indexerClient, IList<SearchIndexerSkill> skills,string azureAiServicesKey)
{
SearchIndexerSkillset skillset = new SearchIndexerSkillset("demoskillset", skills)
{
// Azure AI services was formerly known as Cognitive Services.
// The APIs still use the old name, so we need to create a CognitiveServicesAccountKey object.
Description = "Demo skillset",
CognitiveServicesAccount = new CognitiveServicesAccountKey(azureAiServicesKey)
};
// Create the skillset in your search service.
// The skillset does not need to be deleted if it was already created
// since we are using the CreateOrUpdate method
try
{
indexerClient.CreateOrUpdateSkillset(skillset);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the skillset\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without a skillset");
}
return skillset;
}
Adicione as seguintes linhas a Main.
// Create the skills
Console.WriteLine("Creating the skills...");
OcrSkill ocrSkill = CreateOcrSkill();
MergeSkill mergeSkill = CreateMergeSkill();
EntityRecognitionSkill entityRecognitionSkill = CreateEntityRecognitionSkill();
LanguageDetectionSkill languageDetectionSkill = CreateLanguageDetectionSkill();
SplitSkill splitSkill = CreateSplitSkill();
KeyPhraseExtractionSkill keyPhraseExtractionSkill = CreateKeyPhraseExtractionSkill();
// Create the skillset
Console.WriteLine("Creating or updating the skillset...");
List<SearchIndexerSkill> skills = new List<SearchIndexerSkill>();
skills.Add(ocrSkill);
skills.Add(mergeSkill);
skills.Add(languageDetectionSkill);
skills.Add(splitSkill);
skills.Add(entityRecognitionSkill);
skills.Add(keyPhraseExtractionSkill);
SearchIndexerSkillset skillset = CreateOrUpdateDemoSkillSet(indexerClient, skills, azureAiServicesKey);
Etapa 3: Criar um índice
Nesta secção, pode definir o esquema de índice ao especificar os campos a incluir no índice pesquisável e os atributos de pesquisa para cada campo. Os campos têm um tipo e podem ter atributos que determinam a forma como o campo é utilizado (pesquisável, ordenável e assim por diante). Os nomes de campo em um índice não precisam corresponder de forma idêntica aos nomes de campo na fonte. Num passo posterior, vai adicionar mapeamentos de campos num indexador para ligar campos de origem-destino. Para este passo, defina o índice com convenções de nomenclatura de campo relevantes para a aplicação de pesquisa.
Neste exercício, utiliza os seguintes campos e tipos de campo:
| Nomes de campo | Tipos de campo |
|---|---|
id |
Edm.String |
content |
Edm.String |
languageCode |
Edm.String |
keyPhrases |
Lista<Edm.String> |
organizations |
Lista<Edm.String> |
Criar classe DemoIndex
Os campos para este índice são definidos usando uma classe de modelo. Cada propriedade da classe de modelo tem atributos que determinam os comportamentos relacionados à pesquisa do campo de índice correspondente.
Adicionaremos a classe model a um novo arquivo C#. Selecione com o botão direito do mouse em seu projeto e selecione >, selecione "Classe" e nomeie o arquivo e, em seguida, selecione DemoIndex.cs
Certifique-se de indicar que você deseja usar tipos dos Azure.Search.Documents.Indexes namespaces e System.Text.Json.Serialization .
Adicione a definição DemoIndex.cs de classe de modelo abaixo e inclua-a no mesmo namespace onde você cria o índice.
using Azure.Search.Documents.Indexes;
using System.Text.Json.Serialization;
namespace EnrichwithAI
{
// The SerializePropertyNamesAsCamelCase is currently unsupported as of this writing.
// Replace it with JsonPropertyName
public class DemoIndex
{
[SearchableField(IsSortable = true, IsKey = true)]
[JsonPropertyName("id")]
public string Id { get; set; }
[SearchableField]
[JsonPropertyName("content")]
public string Content { get; set; }
[SearchableField]
[JsonPropertyName("languageCode")]
public string LanguageCode { get; set; }
[SearchableField]
[JsonPropertyName("keyPhrases")]
public string[] KeyPhrases { get; set; }
[SearchableField]
[JsonPropertyName("organizations")]
public string[] Organizations { get; set; }
}
}
Agora que definiu uma classe de modelo, pode regressar a Program.cs para criar uma definição de índice com bastante facilidade. O nome para este índice será demoindex. Se já existir um índice com esse nome, ele será excluído.
private static SearchIndex CreateDemoIndex(SearchIndexClient indexClient)
{
FieldBuilder builder = new FieldBuilder();
var index = new SearchIndex("demoindex")
{
Fields = builder.Build(typeof(DemoIndex))
};
try
{
indexClient.GetIndex(index.Name);
indexClient.DeleteIndex(index.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
//if the specified index not exist, 404 will be thrown.
}
try
{
indexClient.CreateIndex(index);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the index\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without an index");
}
return index;
}
Durante o teste, você pode descobrir que está tentando criar o índice mais de uma vez. Por isso, verifique se o índice que você está prestes a criar já existe antes de tentar criá-lo.
Adicione as seguintes linhas a Main.
// Create the index
Console.WriteLine("Creating the index...");
SearchIndex demoIndex = CreateDemoIndex(indexClient);
Para resolver a referência desambiguada, adicione a seguinte instrução using.
using Index = Azure.Search.Documents.Indexes.Models;
Para saber mais sobre conceitos de índice, consulte Criar índice (API REST).
Etapa 4: Criar e executar um indexador
Até ao momento, criou uma origem de dados, um conjunto de competências e um índice. Estes três componentes tornam-se parte de um indexador que une cada uma das peças numa única operação de várias fases. Para as associar num indexador, tem de definir os mapeamentos de campo.
Os mapeamentos de campo são processados antes do conjunto de competências, mapeando campos de origem da fonte de dados para campos de destino num índice. Se os nomes e tipos de campo forem os mesmos em ambas as extremidades, nenhum mapeamento será necessário.
Os outputFieldMappings são processados após o conjunto de habilidades, fazendo referência a sourceFieldNames que não existem até que a quebra ou o enriquecimento do documento os crie. O targetFieldName é um campo em um índice.
Além de conectar entradas a saídas, você também pode usar mapeamentos de campo para nivelar estruturas de dados. Para obter mais informações, consulte Como mapear campos enriquecidos para um índice pesquisável.
private static SearchIndexer CreateDemoIndexer(SearchIndexerClient indexerClient, SearchIndexerDataSourceConnection dataSource, SearchIndexerSkillset skillSet, SearchIndex index)
{
IndexingParameters indexingParameters = new IndexingParameters()
{
MaxFailedItems = -1,
MaxFailedItemsPerBatch = -1,
};
indexingParameters.Configuration.Add("dataToExtract", "contentAndMetadata");
indexingParameters.Configuration.Add("imageAction", "generateNormalizedImages");
SearchIndexer indexer = new SearchIndexer("demoindexer", dataSource.Name, index.Name)
{
Description = "Demo Indexer",
SkillsetName = skillSet.Name,
Parameters = indexingParameters
};
FieldMappingFunction mappingFunction = new FieldMappingFunction("base64Encode");
mappingFunction.Parameters.Add("useHttpServerUtilityUrlTokenEncode", true);
indexer.FieldMappings.Add(new FieldMapping("metadata_storage_path")
{
TargetFieldName = "id",
MappingFunction = mappingFunction
});
indexer.FieldMappings.Add(new FieldMapping("content")
{
TargetFieldName = "content"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/pages/*/organizations/*")
{
TargetFieldName = "organizations"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/pages/*/keyPhrases/*")
{
TargetFieldName = "keyPhrases"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/languageCode")
{
TargetFieldName = "languageCode"
});
try
{
indexerClient.GetIndexer(indexer.Name);
indexerClient.DeleteIndexer(indexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
//if the specified indexer not exist, 404 will be thrown.
}
try
{
indexerClient.CreateIndexer(indexer);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the indexer\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without creating an indexer");
}
return indexer;
}
Adicione as seguintes linhas a Main.
// Create the indexer, map fields, and execute transformations
Console.WriteLine("Creating the indexer and executing the pipeline...");
SearchIndexer demoIndexer = CreateDemoIndexer(indexerClient, dataSource, skillset, demoIndex);
Espere que o processamento do indexador demore algum tempo para ser concluído. Apesar de o conjunto de dados ser pequeno, as competências analíticas exigem um cálculo intensivo. Algumas competências, como a análise de imagem, são demoradas.
Gorjeta
A criação de um indexador invoca o pipeline. Se houver problemas em atingir os dados, com o mapeamento de entradas e saídas ou com a ordem das operações, estes vão surgir nesta fase.
Explorar a criação do indexador
O código é definido "maxFailedItems" como -1, o que instrui o mecanismo de indexação a ignorar erros durante a importação de dados. Isto é útil porque existem poucos documentos na fonte de dados de demonstração. Para uma origem de dados maior, deve definir o valor para um número maior que 0.
Observe também que o "dataToExtract" está definido como "contentAndMetadata". Esta instrução informa o indexador para extrair automaticamente o conteúdo de diferentes formatos de ficheiro, bem como os metadados relativos a cada ficheiro.
Quando o conteúdo é extraído, pode definir imageAction para extrair texto das imagens existentes na origem de dados. O "imageAction" definido para a configuração "generateNormalizedImages", combinado com a habilidade OCR e a habilidade de Mesclagem de Texto, instrui o indexador a extrair texto das imagens (por exemplo, a palavra "STOP" de um sinal de trânsito de STOP) e incorporá-lo como parte do campo de conteúdo. Este comportamento aplica-se tanto às imagens incorporadas nos documentos (tal como uma imagem num PDF) como às imagens existentes na origem de dados, por exemplo, um ficheiro JPG.
Monitorizar indexação
Assim que o indexador é definido, este é executado automaticamente quando submete o pedido. Dependendo das habilidades definidas, a indexação pode levar mais tempo do que você espera. Para descobrir se o indexador ainda está em execução, use o GetStatus método.
private static void CheckIndexerOverallStatus(SearchIndexerClient indexerClient, SearchIndexer indexer)
{
try
{
var demoIndexerExecutionInfo = indexerClient.GetIndexerStatus(indexer.Name);
switch (demoIndexerExecutionInfo.Value.Status)
{
case IndexerStatus.Error:
ExitProgram("Indexer has error status. Check the Azure Portal to further understand the error.");
break;
case IndexerStatus.Running:
Console.WriteLine("Indexer is running");
break;
case IndexerStatus.Unknown:
Console.WriteLine("Indexer status is unknown");
break;
default:
Console.WriteLine("No indexer information");
break;
}
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to get indexer overall status\n Exception message: {0}\n", ex.Message);
}
}
demoIndexerExecutionInfo representa o status atual e o histórico de execução de um indexador.
Os avisos são comuns com algumas combinações de arquivos de origem e habilidades e nem sempre indicam um problema. Neste tutorial, os avisos são benignos (por exemplo, os ficheiros JPEG não têm entradas de texto).
Adicione as seguintes linhas a Main.
// Check indexer overall status
Console.WriteLine("Check the indexer overall status...");
CheckIndexerOverallStatus(indexerClient, demoIndexer);
Pesquisar
Nos aplicativos de console do tutorial do Azure AI Search, normalmente adicionamos um atraso de 2 segundos antes de executar consultas que retornam resultados, mas como o enriquecimento leva vários minutos para ser concluído, fecharemos o aplicativo de console e usaremos outra abordagem.
A opção mais fácil é o explorador de Pesquisa no portal do Azure. Você pode primeiro executar uma consulta vazia que retorna todos os documentos ou uma pesquisa mais direcionada que retorna o novo conteúdo de campo criado pelo pipeline.
No portal do Azure, na página Visão geral da pesquisa, selecione Índices.
Encontre
demoindexna lista. Deve ter 14 documentos. Se a contagem de documentos for zero, o indexador ainda está em execução ou a página ainda não foi atualizada.Selecione
demoindex. O Explorador de Pesquisa é a primeira aba.O conteúdo pode ser pesquisado assim que o primeiro documento é carregado. Para verificar se o conteúdo existe, execute uma consulta não especificada clicando em Pesquisar. Esta consulta devolve todos os documentos atualmente indexados, dando-lhe uma ideia do que o índice contém.
Em seguida, cole a seguinte cadeia de caracteres para obter resultados mais gerenciáveis:
search=*&$select=id, languageCode, organizations
Repor e executar novamente
Nos estágios experimentais iniciais de desenvolvimento, a abordagem mais prática para iteração de design é excluir os objetos da Pesquisa de IA do Azure e permitir que seu código os reconstrua. Os nomes dos recursos são exclusivos. Quando elimina um objeto, pode recriá-lo com o mesmo nome.
O código de exemplo para este tutorial verifica se há objetos existentes e os exclui para que você possa executar novamente o código. Você também pode usar o portal do Azure para excluir índices, indexadores, fontes de dados e conjuntos de habilidades.
Conclusões
Este tutorial demonstrou as etapas básicas para criar um pipeline de indexação enriquecido por meio da criação de partes de componentes: uma fonte de dados, conjunto de habilidades, índice e indexador.
Habilidades incorporadas foram introduzidas, juntamente com a definição do conjunto de habilidades e a mecânica de encadear habilidades juntas através de entradas e saídas. Você também aprendeu que outputFieldMappings , na definição do indexador, é necessário rotear valores enriquecidos do pipeline para um índice pesquisável em um serviço de Pesquisa do Azure AI.
Por fim, aprendeu como testar os resultados e repor o sistema para iterações futuras. Aprendeu que a emissão de consultas acerca do índice devolve o resultado criado pelo pipeline de indexação melhorado. Também aprendeu como verificar o estado do indexador e quais os objetos a eliminar antes de executar novamente um pipeline.
Limpar recursos
Quando estiver a trabalhar na sua própria subscrição, no final de um projeto, é uma boa ideia remover os recursos que já não são necessários. Os recursos que deixar em execução podem custar-lhe dinheiro. Pode eliminar recursos individualmente ou eliminar o grupo de recursos para eliminar todo o conjunto de recursos.
Você pode localizar e gerenciar recursos no portal do Azure, usando o link Todos os recursos ou Grupos de recursos no painel de navegação esquerdo.
Próximos passos
Agora que você está familiarizado com todos os objetos em um pipeline de enriquecimento de IA, vamos dar uma olhada mais de perto nas definições do conjunto de habilidades e habilidades individuais.