Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Este artigo fornece uma visão geral dos tipos que ajudam a ler dados distribuídos por vários buffers. Eles são usados principalmente para suportar objetos PipeReader.
IBufferWriter<T>
System.Buffers.IBufferWriter<T> é um contrato para escrita em buffer síncrona. No nível mais baixo, a interface:
- É básico e não é difícil de usar.
- Permite o acesso a um Memory<T> ou Span<T>. O
Memory<T>ouSpan<T>pode ser escrito, e você pode determinar quantos itensTforam gravados.
void WriteHello(IBufferWriter<byte> writer)
{
// Request at least 5 bytes.
Span<byte> span = writer.GetSpan(5);
ReadOnlySpan<char> helloSpan = "Hello".AsSpan();
int written = Encoding.ASCII.GetBytes(helloSpan, span);
// Tell the writer how many bytes were written.
writer.Advance(written);
}
O método anterior:
- Solicita um buffer de pelo menos 5 bytes do
IBufferWriter<byte>usandoGetSpan(5). - Grava bytes para a cadeia de caracteres ASCII "Olá" para o retornado
Span<byte>. - Chamadas IBufferWriter<T> para indicar quantos bytes foram gravados no buffer.
Este método de escrita usa o Memory<T>/Span<T> buffer fornecido pelo IBufferWriter<T>. Como alternativa, o Write método de extensão pode ser usado para copiar um buffer existente para o IBufferWriter<T>.
Write faz o trabalho de ligar GetSpan/Advance conforme apropriado, então não há necessidade de ligar Advance depois de escrever:
void WriteHello(IBufferWriter<byte> writer)
{
byte[] helloBytes = Encoding.ASCII.GetBytes("Hello");
// Write helloBytes to the writer. There's no need to call Advance here
// since Write calls Advance.
writer.Write(helloBytes);
}
ArrayBufferWriter<T> é uma implementação de IBufferWriter<T> cujo armazenamento é suportado por uma única matriz contígua.
Problemas comuns do IBufferWriter
-
GetSpaneGetMemoryretornar um buffer com pelo menos a quantidade solicitada de memória. Não assuma tamanhos exatos de buffer. - Não há garantia de que chamadas repetidas retornem o mesmo buffer ou um buffer do mesmo tamanho.
- Um novo buffer deve ser solicitado após a chamada
Advancepara continuar gravando mais dados. Um buffer adquirido anteriormente não pode ser escrito apósAdvanceter sido chamado.
ReadOnlySequence<T>
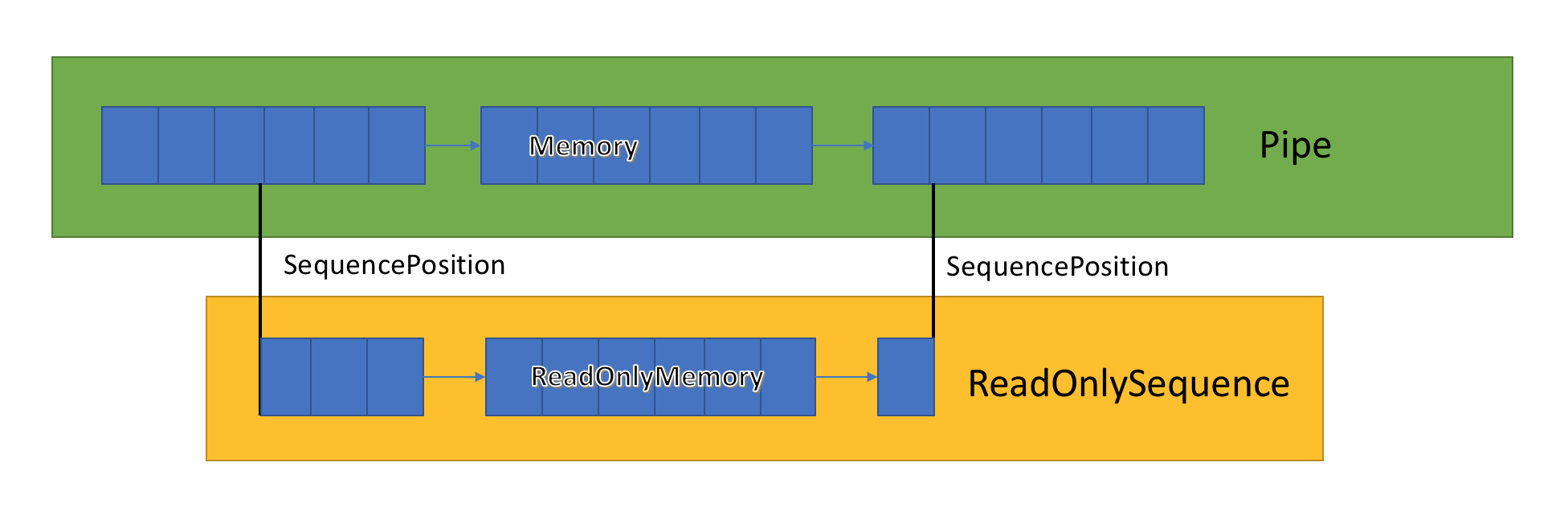
ReadOnlySequence<T> é uma estrutura que pode representar uma sequência contígua ou não contígua de T. Pode ser construído a partir de:
- Uma
T[] - Uma
ReadOnlyMemory<T> - Um par de nós de lista ligada e um índice para representar a posição inicial e final da sequência.
A terceira representação é a mais interessante, pois tem implicações de desempenho em várias operações no ReadOnlySequence<T>:
| Representação | Funcionamento | Complexidade |
|---|---|---|
T[]/ReadOnlyMemory<T> |
Length |
O(1) |
T[]/ReadOnlyMemory<T> |
GetPosition(long) |
O(1) |
T[]/ReadOnlyMemory<T> |
Slice(int, int) |
O(1) |
T[]/ReadOnlyMemory<T> |
Slice(SequencePosition, SequencePosition) |
O(1) |
ReadOnlySequenceSegment<T> |
Length |
O(1) |
ReadOnlySequenceSegment<T> |
GetPosition(long) |
O(number of segments) |
ReadOnlySequenceSegment<T> |
Slice(int, int) |
O(number of segments) |
ReadOnlySequenceSegment<T> |
Slice(SequencePosition, SequencePosition) |
O(1) |
Devido a essa representação mista, o ReadOnlySequence<T> expõe índices como SequencePosition em vez de um inteiro.
SequencePositionR:
- É um valor opaco que representa um índice no
ReadOnlySequence<T>onde se originou. - Consiste em duas partes, um inteiro e um objeto. O que estes dois valores representam está ligado à implementação do
ReadOnlySequence<T>.
Aceder a dados
O ReadOnlySequence<T> expõe dados como um enumerável de ReadOnlyMemory<T>. A enumeração de cada um dos segmentos pode ser feita usando um foreach básico.
long FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
long position = 0;
foreach (ReadOnlyMemory<byte> segment in buffer)
{
ReadOnlySpan<byte> span = segment.Span;
var index = span.IndexOf(data);
if (index != -1)
{
return position + index;
}
position += span.Length;
}
return -1;
}
O método anterior pesquisa cada segmento para um byte específico. Se você precisa acompanhar o de cada segmento, SequencePositionReadOnlySequence<T>.TryGet é mais adequado. O próximo exemplo altera o código anterior para retornar um SequencePosition em vez de um inteiro. Retornar um SequencePosition tem a vantagem de permitir que o chamador evite uma segunda varredura para obter os dados em um índice específico.
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
SequencePosition position = buffer.Start;
SequencePosition result = position;
while (buffer.TryGet(ref position, out ReadOnlyMemory<byte> segment))
{
ReadOnlySpan<byte> span = segment.Span;
var index = span.IndexOf(data);
if (index != -1)
{
return buffer.GetPosition(index, result);
}
result = position;
}
return null;
}
A combinação de SequencePosition e TryGet age como um enumerador. O campo de posição é modificado no início de cada iteração para ser o início de cada segmento dentro do ReadOnlySequence<T>.
O método anterior existe como um método de extensão em ReadOnlySequence<T>.
PositionOf pode ser usado para simplificar o código anterior:
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data) => buffer.PositionOf(data);
Processar um ReadOnlySequence<T>
O processamento de um ReadOnlySequence<T> pode ser um desafio, uma vez que os dados podem ser divididos em vários segmentos dentro da sequência. Para obter o melhor desempenho, divida o código em dois caminhos:
- Um caminho rápido que lida com o caso de segmento único.
- Um caminho lento que lida com os dados divididos entre segmentos.
Existem algumas abordagens que podem ser usadas para processar dados em sequências multissegmentadas:
- Use o
SequenceReader<T>. - Analise os dados segmento por segmento, acompanhando o
SequencePositione o índice dentro do segmento analisado. Isso evita alocações desnecessárias, mas pode ser ineficiente, especialmente para buffers pequenos. - Copie o
ReadOnlySequence<T>para uma matriz contígua e trate-o como um único buffer:- Se o tamanho do
ReadOnlySequence<T>for pequeno, pode ser razoável copiar os dados em um buffer alocado por pilha usando o operador stackalloc . - Copie o
ReadOnlySequence<T>para uma matriz em pool usando ArrayPool<T>.Shared. - Utilize
ReadOnlySequence<T>.ToArray(). Isso não é recomendado em caminhos críticos, pois aloca um novoT[]no heap.
- Se o tamanho do
Os exemplos a seguir demonstram alguns casos comuns de processamento ReadOnlySequence<byte>:
Processar dados binários
O exemplo a seguir analisa a partir do início do ReadOnlySequence<byte> um inteiro de comprimento de 4 bytes no formato big-endian.
bool TryParseHeaderLength(ref ReadOnlySequence<byte> buffer, out int length)
{
// If there's not enough space, the length can't be obtained.
if (buffer.Length < 4)
{
length = 0;
return false;
}
// Grab the first 4 bytes of the buffer.
var lengthSlice = buffer.Slice(buffer.Start, 4);
if (lengthSlice.IsSingleSegment)
{
// Fast path since it's a single segment.
length = BinaryPrimitives.ReadInt32BigEndian(lengthSlice.First.Span);
}
else
{
// There are 4 bytes split across multiple segments. Since it's so small, it
// can be copied to a stack allocated buffer. This avoids a heap allocation.
Span<byte> stackBuffer = stackalloc byte[4];
lengthSlice.CopyTo(stackBuffer);
length = BinaryPrimitives.ReadInt32BigEndian(stackBuffer);
}
// Move the buffer 4 bytes ahead.
buffer = buffer.Slice(lengthSlice.End);
return true;
}
Processar dados de texto
O exemplo a seguir:
- Localiza a primeira nova linha (
\r\n) naReadOnlySequence<byte>e a retorna através do parâmetro 'line' de saída. - Corta essa linha, excluindo o
\r\ndo buffer de entrada.
static bool TryParseLine(ref ReadOnlySequence<byte> buffer, out ReadOnlySequence<byte> line)
{
SequencePosition position = buffer.Start;
SequencePosition previous = position;
var index = -1;
line = default;
while (buffer.TryGet(ref position, out ReadOnlyMemory<byte> segment))
{
ReadOnlySpan<byte> span = segment.Span;
// Look for \r in the current segment.
index = span.IndexOf((byte)'\r');
if (index != -1)
{
// Check next segment for \n.
if (index + 1 >= span.Length)
{
var next = position;
if (!buffer.TryGet(ref next, out ReadOnlyMemory<byte> nextSegment))
{
// You're at the end of the sequence.
return false;
}
else if (nextSegment.Span[0] == (byte)'\n')
{
// A match was found.
break;
}
}
// Check the current segment of \n.
else if (span[index + 1] == (byte)'\n')
{
// It was found.
break;
}
}
previous = position;
}
if (index != -1)
{
// Get the position just before the \r\n.
var delimeter = buffer.GetPosition(index, previous);
// Slice the line (excluding \r\n).
line = buffer.Slice(buffer.Start, delimeter);
// Slice the buffer to get the remaining data after the line.
buffer = buffer.Slice(buffer.GetPosition(2, delimeter));
return true;
}
return false;
}
Segmentos vazios
É válido armazenar segmentos vazios dentro de um ReadOnlySequence<T>arquivo . Segmentos vazios podem ocorrer ao enumerar segmentos explicitamente:
static void EmptySegments()
{
// This logic creates a ReadOnlySequence<byte> with 4 segments,
// two of which are empty.
var first = new BufferSegment(new byte[0]);
var last = first.Append(new byte[] { 97 })
.Append(new byte[0]).Append(new byte[] { 98 });
// Construct the ReadOnlySequence<byte> from the linked list segments.
var data = new ReadOnlySequence<byte>(first, 0, last, 1);
// Slice using numbers.
var sequence1 = data.Slice(0, 2);
// Slice using SequencePosition pointing at the empty segment.
var sequence2 = data.Slice(data.Start, 2);
Console.WriteLine($"sequence1.Length={sequence1.Length}"); // sequence1.Length=2
Console.WriteLine($"sequence2.Length={sequence2.Length}"); // sequence2.Length=2
// sequence1.FirstSpan.Length=1
Console.WriteLine($"sequence1.FirstSpan.Length={sequence1.FirstSpan.Length}");
// Slicing using SequencePosition will Slice the ReadOnlySequence<byte> directly
// on the empty segment!
// sequence2.FirstSpan.Length=0
Console.WriteLine($"sequence2.FirstSpan.Length={sequence2.FirstSpan.Length}");
// The following code prints 0, 1, 0, 1.
SequencePosition position = data.Start;
while (data.TryGet(ref position, out ReadOnlyMemory<byte> memory))
{
Console.WriteLine(memory.Length);
}
}
class BufferSegment : ReadOnlySequenceSegment<byte>
{
public BufferSegment(Memory<byte> memory)
{
Memory = memory;
}
public BufferSegment Append(Memory<byte> memory)
{
var segment = new BufferSegment(memory)
{
RunningIndex = RunningIndex + Memory.Length
};
Next = segment;
return segment;
}
}
O código anterior cria um ReadOnlySequence<byte> com segmentos vazios e mostra como esses segmentos vazios afetam as várias APIs:
-
ReadOnlySequence<T>.Slicecom umSequencePositionapontamento para um segmento vazio preserva esse segmento. -
ReadOnlySequence<T>.Slicecom um int ignora os segmentos vazios. - Enumerar
ReadOnlySequence<T>consiste em listar os segmentos vazios.
Problemas potenciais com ReadOnlySequence<T> e SequencePosition
Existem vários resultados incomuns quando se lida com um ReadOnlySequence<T>/SequencePosition vs. um ReadOnlySpan<T>/ReadOnlyMemory<T>/T[]/int normal:
-
SequencePositioné um marcador de posição para uma posição específicaReadOnlySequence<T>, não absoluta. Por ser relativo a um específicoReadOnlySequence<T>, não tem significado se usado fora doReadOnlySequence<T>local de origem. - Não é possível realizar operações aritméticas em
SequencePositionsem oReadOnlySequence<T>. Isso significa fazer coisas básicas comoposition++está escritoposition = ReadOnlySequence<T>.GetPosition(1, position). -
GetPosition(long)não suporta índices negativos. Isso significa que é impossível obter o penúltimo personagem sem percorrer todos os segmentos. - Dois
SequencePositionnão podem ser comparados, o que dificulta:- Saiba se uma posição é maior ou menor que outra.
- Escreva alguns algoritmos de análise.
-
ReadOnlySequence<T>é maior do que uma referência de objeto e deve ser passada por in ou ref sempre que possível. PassarReadOnlySequence<T>porinou porrefreduz as cópias da estrutura. - Segmentos vazios:
- São válidos dentro de um
ReadOnlySequence<T>arquivo. - Pode aparecer ao iterar usando o método
ReadOnlySequence<T>.TryGet. - Pode aparecer ao fatiar a sequência com o método
ReadOnlySequence<T>.Slice()e os objetosSequencePosition.
- São válidos dentro de um
Leitor de Sequência<T>
- É um novo tipo que foi introduzido no .NET Core 3.0 para simplificar o processamento de um
ReadOnlySequence<T>. - Unifica as diferenças entre um único segmento
ReadOnlySequence<T>e um multisegmentoReadOnlySequence<T>. - Fornece auxiliares para a leitura de dados binários e de texto (
byteechar) que podem ou não ser divididos entre segmentos.
Existem métodos internos para lidar com o processamento de dados binários e delimitados. A seção a seguir demonstra como esses mesmos métodos se parecem com o SequenceReader<T>:
Aceder a dados
SequenceReader<T> tem métodos para enumerar dados dentro do ReadOnlySequence<T> diretamente. O código seguinte é um exemplo de processar um ReadOnlySequence<byte> e um byte de cada vez:
while (reader.TryRead(out byte b))
{
Process(b);
}
O CurrentSpan expõe o segmento atual Span, semelhante ao que foi realizado no método de forma manual.
Posição de utilização
O código a seguir é um exemplo de implementação do FindIndexOf uso do SequenceReader<T>:
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
var reader = new SequenceReader<byte>(buffer);
while (!reader.End)
{
// Search for the byte in the current span.
var index = reader.CurrentSpan.IndexOf(data);
if (index != -1)
{
// It was found, so advance to the position.
reader.Advance(index);
return reader.Position;
}
// Skip the current segment since there's nothing in it.
reader.Advance(reader.CurrentSpan.Length);
}
return null;
}
Processar dados binários
O exemplo a seguir analisa a partir do início do ReadOnlySequence<byte> um inteiro de comprimento de 4 bytes no formato big-endian.
bool TryParseHeaderLength(ref ReadOnlySequence<byte> buffer, out int length)
{
var reader = new SequenceReader<byte>(buffer);
return reader.TryReadBigEndian(out length);
}
Processar dados de texto
static ReadOnlySpan<byte> NewLine => new byte[] { (byte)'\r', (byte)'\n' };
static bool TryParseLine(ref ReadOnlySequence<byte> buffer,
out ReadOnlySequence<byte> line)
{
var reader = new SequenceReader<byte>(buffer);
if (reader.TryReadTo(out line, NewLine))
{
buffer = buffer.Slice(reader.Position);
return true;
}
line = default;
return false;
}
Problemas comuns do SequenceReader<T>
- Por
SequenceReader<T>ser uma estrutura mutável, ela deve sempre ser passada por referência. -
SequenceReader<T>é uma estrutura ref , portanto, só pode ser usada em métodos síncronos e não pode ser armazenada em campos. Para obter mais informações, consulte Evitar alocações. -
SequenceReader<T>é otimizado para uso como um leitor exclusivamente unidirecional.Rewinddestina-se a pequenos backups que não podem ser resolvidos utilizando outrosRead,PeekeIsNextAPIs.
Colabore connosco no GitHub
A origem deste conteúdo pode ser encontrada no GitHub, onde também pode criar e rever problemas e pedidos Pull. Para mais informações, consulte o nosso guia do contribuidor.