Руководство. Сегментирование данных на рабочих узлах в Azure Cosmos DB для PostgreSQL
Область применения: ![]() Azure Cosmos DB для PostgreSQL (на базе расширения базы данных Citus до PostgreSQL)
Azure Cosmos DB для PostgreSQL (на базе расширения базы данных Citus до PostgreSQL)
В этом руководстве вы узнаете, как использовать Azure Cosmos DB для PostgreSQL:
- создание сегментов с хэш-распределением;
- определение расположения сегментов таблицы;
- определение смещения распределения;
- создание ограничения для распределенных таблиц;
- выполнение запросов к распределенным данным.
В этом руководстве требуется запущенный кластер с двумя рабочими узлами. Если у вас нет работающего кластера, следуйте руководству по созданию кластера и вернитесь к этому.
Распределение строк таблицы между несколькими серверами PostgreSQL — это ключевой способ масштабирования запросов в Azure Cosmos DB для PostgreSQL. Вместе несколько узлов могут содержать больше данных, чем традиционная база данных, а во многих случаях для выполнения запросов могут параллельно использоваться ЦП рабочих узлов. Концепция хэш-распределенных таблиц также называется сегментированием на основе строк.
В разделе предварительных требований мы создали кластер с двумя рабочими узлами.
Таблицы метаданных в узле координатора отслеживают рабочие узлы и распределенные данные. Активные рабочие узлы можно просмотреть в таблице pg_dist_node.
select nodeid, nodename from pg_dist_node where isactive;
nodeid | nodename
--------+-----------
1 | 10.0.0.21
2 | 10.0.0.23
Примечание
Имена узлов в Azure Cosmos DB для PostgreSQL — это внутренние IP-адреса в виртуальной сети, а фактические адреса, которые вы видите, могут отличаться.
Чтобы использовать ресурсы ЦП и хранилища рабочих узлов, необходимо распределить данные таблицы по всему кластеру. С помощью распределения таблицы каждая строка назначается логической группе, которая называется сегментом. Создайте таблицу и распределите ее:
-- create a table on the coordinator
create table users ( email text primary key, bday date not null );
-- distribute it into shards on workers
select create_distributed_table('users', 'email');
Azure Cosmos DB для PostgreSQL назначает каждую строку сегменту в зависимости от значения столбца распространения, который, в нашем случае, мы указали email. Каждая строка будет располагаться точно в одном сегменте, а каждый сегмент может содержать несколько строк.
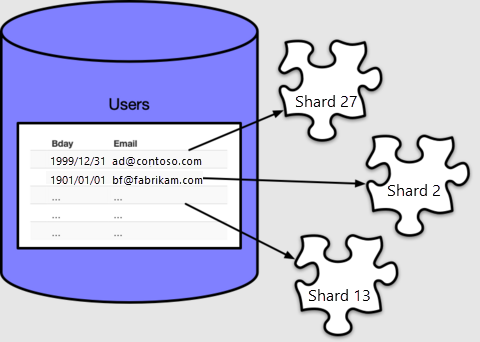
По умолчанию create_distributed_table() включает 32 сегмента, как можно увидеть, выполнив подсчет в таблице метаданных pg_dist_shard:
select logicalrelid, count(shardid)
from pg_dist_shard
group by logicalrelid;
logicalrelid | count
--------------+-------
users | 32
Azure Cosmos DB для PostgreSQL использует pg_dist_shard таблицу для назначения строк сегментам на основе хэша значения в столбце распространения. Для работы с этим руководством не нужно вникать в детали хэширования. Важнее то, что мы можем отправить запрос и увидеть, какие значения сопоставлены с определенными идентификаторами сегментов:
-- Where would a row containing hi@test.com be stored?
-- (The value doesn't have to actually be present in users, the mapping
-- is a mathematical operation consulting pg_dist_shard.)
select get_shard_id_for_distribution_column('users', 'hi@test.com');
get_shard_id_for_distribution_column
--------------------------------------
102008
Сопоставление строк сегментам выполняется абсолютно логично. Сегменты должны быть назначены определенным рабочим узлам для хранения, в том, что Azure Cosmos DB для PostgreSQL вызывает размещение сегментов.
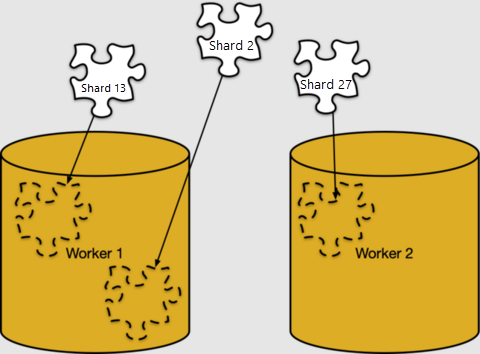
Мы можем рассмотреть размещение сегментов в pg_dist_placement. Если соединить эту таблицу с другими таблицами метаданных, можно понять, где расположен каждый сегмент.
-- limit the output to the first five placements
select
shard.logicalrelid as table,
placement.shardid as shard,
node.nodename as host
from
pg_dist_placement placement,
pg_dist_node node,
pg_dist_shard shard
where placement.groupid = node.groupid
and shard.shardid = placement.shardid
order by shard
limit 5;
table | shard | host
-------+--------+------------
users | 102008 | 10.0.0.21
users | 102009 | 10.0.0.23
users | 102010 | 10.0.0.21
users | 102011 | 10.0.0.23
users | 102012 | 10.0.0.21
Кластер работает наиболее эффективно при равномерном размещении данных на рабочих узлах, а также при совместном размещении связанных данных на одних и том же рабочих узлах. В рамках этого раздела мы уделим внимание первому вопросу — однородности размещения.
Для демонстрации создадим пример данных для таблицы users:
-- load sample data
insert into users
select
md5(random()::text) || '@test.com',
date_trunc('day', now() - random()*'100 years'::interval)
from generate_series(1, 1000);
Чтобы определить размеры сегментов, можно выполнить для сегментов функции для определения размера таблицы.
-- sizes of the first five shards
select *
from
run_command_on_shards('users', $cmd$
select pg_size_pretty(pg_table_size('%1$s'));
$cmd$)
order by shardid
limit 5;
shardid | success | result
---------+---------+--------
102008 | t | 16 kB
102009 | t | 16 kB
102010 | t | 16 kB
102011 | t | 16 kB
102012 | t | 16 kB
Как мы видим, сегменты имеют одинаковый размер. Размещения распределены равномерно между рабочими узлами, поэтому можно сделать вывод, что рабочие узлы содержат приблизительно одинаковое число строк.
Строки в нашем примере users распределены равномерно благодаря свойствам столбца распределения email.
- Число адресов электронной почты было больше числа сегментов или равно ему.
- Число строк на адрес электронной почты было похожим (в нашем случае использовалась точно одна строка на адрес, так как мы объявили его ключом).
Если выбрать таблицу и столбец распределения таким образом, что одно из свойств не будет работать, размещение данных в рабочих узлах будет неравномерным, то есть возникнет неравномерное распределение данных.
Использование Azure Cosmos DB для PostgreSQL позволяет продолжать пользоваться безопасностью реляционной базы данных, включая ограничения базы данных. Но здесь нужно помнить об одном моменте. Из-за характера распределенных систем Azure Cosmos DB для PostgreSQL не будет перекрестно ссылаться на ограничения уникальности или ссылочной целостности между рабочими узлами.
Рассмотрим наш пример таблицы users со связанной таблицей.
-- books that users own
create table books (
owner_email text references users (email),
isbn text not null,
title text not null
);
-- distribute it
select create_distributed_table('books', 'owner_email');
Для повышенной эффективности мы распределим books так же, как users: по адресу электронной почты владельца. Распределение по аналогичным значениям столбцов называется совместным размещением.
У нас не возникло проблем с распределением пользователям таблицы books с внешним ключом, так как ключ был доступен в столбце распределения. Но если мы попытаемся сделать из isbn ключ, возникнут сложности:
-- will not work
alter table books add constraint books_isbn unique (isbn);
ERROR: cannot create constraint on "books"
DETAIL: Distributed relations cannot have UNIQUE, EXCLUDE, or
PRIMARY KEY constraints that do not include the partition column
(with an equality operator if EXCLUDE).
В распределенной таблице оптимальным методом будет сделать столбцы уникальным остатком от деления столбца распределения:
-- a weaker constraint is allowed
alter table books add constraint books_isbn unique (owner_email, isbn);
Приведенное выше ограничение всего лишь делает isbn уникальным для пользователя. Другой вариант — сделать таблицу books ссылочной таблицей (а не распределенной) и создать отдельную распределенную таблицу, связывающую данные о книгах с данными о пользователях.
Из предыдущих разделов мы узнали, как строки распределенной таблицы размещаются в сегментах в рабочих узлах. Большую часть времени вам не нужно знать, как или где хранятся данные в кластере. Azure Cosmos DB для PostgreSQL имеет распределенный исполнитель запросов, который автоматически разбивает регулярные запросы SQL. Он запускает их параллельно в рабочих узлах, расположенных близко к данным.
Например, можно выполнить запрос, чтобы найти средний возраст пользователей, обработав распределенную таблицу users как обычную таблицу в координаторе.
select avg(current_date - bday) as avg_days_old from users;
avg_days_old
--------------------
17926.348000000000
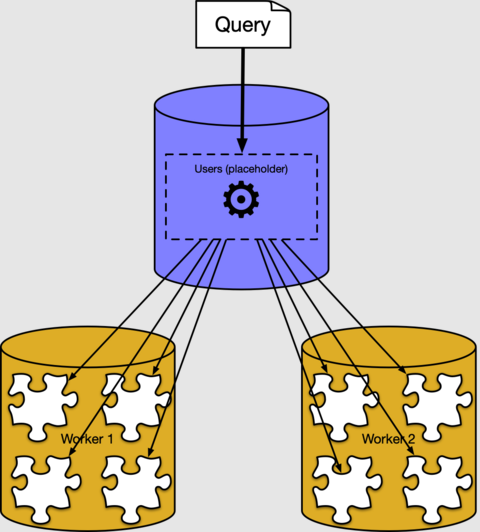
За кулисами исполнитель Azure Cosmos DB для PostgreSQL создает отдельный запрос для каждого сегмента, запускает их на рабочих местах и объединяет результат. Это можно увидеть, если воспользоваться командой EXPLAIN PostgreSQL:
explain select avg(current_date - bday) from users;
QUERY PLAN
----------------------------------------------------------------------------------
Aggregate (cost=500.00..500.02 rows=1 width=32)
-> Custom Scan (Citus Adaptive) (cost=0.00..0.00 rows=100000 width=16)
Task Count: 32
Tasks Shown: One of 32
-> Task
Node: host=10.0.0.21 port=5432 dbname=citus
-> Aggregate (cost=41.75..41.76 rows=1 width=16)
-> Seq Scan on users_102040 users (cost=0.00..22.70 rows=1270 width=4)
В выходных данных приведен пример плана выполнения для фрагмента запроса, выполняющегося в сегменте 102040 (таблица users_102040 в рабочем узле 10.0.0.21). Другие фрагменты не отображаются, так как они похожи. Как мы видим, рабочий узел проверяет таблицы сегмента и выполняет статистические вычисления. Узел координатора объединяет агрегированные данные для получения окончательного результата.
С помощью инструкций из этого руководства мы создали распределенную таблицу. В нем также описаны сегменты и размещения. Мы рассмотрели проблему уникальности и ограничения для внешних ключей, а также то, как распределенные запросы работают на верхнем уровне.
- Дополнительные сведения о типах таблиц PostgreSQL для Azure Cosmos DB
- Изучите советы по выбору столбца распределения.
- Узнайте о преимуществах совместного размещения таблиц.