Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этой статье рассматриваются модели данных, разрабатывающие составные модели Power BI. В нем описываются варианты использования составных моделей и приведены рекомендации по проектированию. В частности, рекомендации помогут определить, подходит ли составная модель для решения. Если это так, эта статья также поможет вам разработать оптимальные составные модели и отчеты.
Примечание.
Введение в составные модели не рассматривается в этой статье. Если вы не полностью знакомы с составными моделями, рекомендуется сначала ознакомиться со статьей "Использование составных моделей" в Power BI Desktop .
Так как составные модели состоят по крайней мере из одного источника DirectQuery, важно также иметь полное представление о связях моделей, моделях DirectQuery и руководстве по проектированию моделей DirectQuery.
Варианты использования составной модели
По определению составная модель объединяет несколько исходных групп. Исходная группа может представлять импортированные данные или подключение к источнику DirectQuery. Источник DirectQuery может быть реляционной базой данных или другой табличной моделью, которая может быть семантической моделью Power BI или табличной моделью служб Analysis Services. Когда табличная модель подключается к другой табличной модели, она называется цепочкой. Дополнительные сведения см. в разделе "Использование DirectQuery для семантических моделей Power BI" и служб Analysis Services.
Примечание.
Когда модель подключается к табличной модели, но не расширяет ее с дополнительными данными, это не составная модель. В этом случае это модель DirectQuery, которая подключается к удаленной модели, поэтому она состоит только из одной исходной группы. Этот тип модели можно создать для изменения свойств объекта исходной модели, таких как имя таблицы, порядок сортировки столбцов или строка форматирования.
Подключение к табличным моделям особенно важно при расширении корпоративной семантической модели (если она является семантической моделью Power BI или моделью служб Analysis Services). Семантическая модель предприятия является основой для разработки и эксплуатации хранилища данных. Он предоставляет уровень абстракции по данным в хранилище данных для представления бизнес-определений и терминологии. Обычно он используется в качестве связи между физическими моделями данных и средствами создания отчетов, такими как Power BI. В большинстве организаций она управляется центральной командой, поэтому она описывается как корпоративная. Дополнительные сведения см. в сценарии использования корпоративной бизнес-аналитики .
Вы можете рассмотреть возможность разработки составной модели в следующих ситуациях.
- Модель может быть моделью DirectQuery, и вы хотите повысить производительность. В составной модели можно повысить производительность, настроив соответствующее хранилище для каждой таблицы. Вы также можете добавить определяемые пользователем агрегаты. Оба этих оптимизации описаны далее в этой статье.
- Вы хотите объединить модель DirectQuery с большими данными, которые необходимо импортировать в модель. Вы можете загрузить импортированные данные из другого источника данных или из вычисляемых таблиц.
- Вы хотите объединить два или более источников данных DirectQuery в одну модель. Эти источники могут быть реляционными базами данных или другими табличными моделями.
Примечание.
Составные модели не могут включать подключения к определенным внешним базам данных аналитики. К этим базам данных относятся SAP Business Warehouse и SAP HANA при обработке SAP HANA в качестве многомерного источника.
Оценка других параметров проектирования модели
В то время как составные модели Power BI могут решать определенные задачи проектирования, они могут способствовать замедлению производительности. Кроме того, в некоторых ситуациях могут возникать непредвиденные результаты вычисления (описанные далее в этой статье). По этим причинам оцените другие варианты проектирования модели, когда они существуют.
По возможности рекомендуется разрабатывать модель в режиме импорта. Этот режим обеспечивает максимальную гибкость проектирования и лучшую производительность.
Однако проблемы, связанные с большими объемами данных или отчетами о данных почти в режиме реального времени, не всегда можно решить с помощью моделей импорта. В любом из этих случаев можно рассмотреть модель DirectQuery, обеспечивая хранение данных в одном источнике данных, поддерживаемом режимом DirectQuery. Дополнительные сведения см. в моделях DirectQuery в Power BI Desktop.
Совет
Если цель заключается только в расширении существующей табличной модели с большими данными, когда это возможно, добавьте эти данные в существующий источник данных.
Режим хранения таблиц
В составной модели можно задать режим хранения для каждой таблицы (за исключением вычисляемых таблиц).
- DirectQuery: рекомендуется задать этот режим для таблиц, представляющих большие объемы данных или которые должны обеспечить практически результаты в режиме реального времени. Данные никогда не будут импортированы в эти таблицы. Как правило, эти таблицы будут таблицами типа фактов, которые являются сводными.
- Импорт. Рекомендуется задать этот режим для таблиц, которые не используются для фильтрации и группировки таблиц фактов в режиме DirectQuery или гибридном режиме. Это также единственный вариант для таблиц на основе источников, не поддерживаемых режимом DirectQuery. Вычисляемые таблицы всегда являются таблицами импорта.
- Двойной: рекомендуется задать этот режим для таблиц типов измерений, если они будут запрашиваться вместе с таблицами фактов DirectQuery из одного источника.
- Гибридная среда. Мы рекомендуем задать этот режим, добавив секции импорта и одну секцию DirectQuery в таблицу фактов, если требуется включить последние изменения данных в режиме реального времени или если требуется обеспечить быстрый доступ к наиболее часто используемым данным через секции импорта, оставляя большую часть часто используемых данных в хранилище данных.
Существует несколько возможных сценариев, когда Power BI запрашивает составную модель.
- Запросы импортируют или две таблицы: Power BI извлекает все данные из кэша моделей. Это обеспечит максимально высокую производительность. Этот сценарий распространен для таблиц типов измерений, запрашиваемых фильтрами или визуальными элементами среза.
- Запрашивает две таблицы или таблицы DirectQuery из одного источника: Power BI извлекает все данные, отправляя один или несколько собственных запросов в источник DirectQuery. Он обеспечивает хорошую производительность, особенно если соответствующие индексы существуют в исходных таблицах. Этот сценарий распространен для запросов, связанных с таблицами двойного типа измерения и таблицами типа фактов DirectQuery. Эти запросы являются внутри исходной группы, поэтому все связи "один к одному" или "один ко многим" оцениваются как обычные связи.
- Запросы двух таблиц или гибридных таблиц из одного источника: этот сценарий представляет собой сочетание предыдущих двух сценариев. Power BI извлекает данные из кэша модели, когда он доступен в разделах импорта, в противном случае он отправляет один или несколько собственных запросов в источник DirectQuery. Это обеспечит максимально высокую производительность, так как в исходной таблице запрашивается только срез данных, особенно если соответствующие индексы существуют в исходных таблицах. Что касается таблиц двойного типа измерения и таблиц типа фактов DirectQuery, эти запросы являются внутри исходной группы, поэтому все связи типа "один к одному" или "один ко многим" оцениваются как обычные связи.
- Все остальные запросы: эти запросы включают связи между исходными группами. Это либо потому, что таблица импорта связана с таблицей DirectQuery, либо двойной таблицей относится к таблице DirectQuery из другого источника, в этом случае она ведет себя как таблица импорта. Все связи оцениваются как ограниченные связи. Это также означает, что группировки, применяемые к таблицам, не относящихся к DirectQuery, должны отправляться в источник DirectQuery как материализованные вложенные запросы (виртуальные таблицы). В этом случае собственный запрос может быть неэффективным, особенно для больших наборов группирования.
В сводке рекомендуется:
- Внимательно рассмотрим, что составная модель является правильным решением, хотя она позволяет интегрировать на уровне модели различные источники данных, она также представляет сложности проектирования с возможными последствиями (описанными далее в этой статье).
- Задайте для режима хранения значение DirectQuery , если таблица представляет собой таблицу типа фактов, храняющую большие тома данных, или когда ей необходимо обеспечить практически результаты в режиме реального времени.
- Рекомендуется использовать гибридный режим, определяя политику добавочного обновления и данные в режиме реального времени или секционируя таблицу фактов с помощью TOM, TMSL или стороннего средства. Дополнительные сведения см. в разделе Добавочное обновление и данные в режиме реального времени для семантических моделей и сценария использования расширенной модели данных.
- Задайте для режима хранения двойное значение, если таблица является таблицей типа измерения, и она будет запрашиваться вместе с таблицами DirectQuery или гибридными таблицами типа фактов, которые находятся в той же исходной группе.
- Задайте соответствующие частоты обновления для хранения кэша моделей для двух и гибридных таблиц (и любых зависимых вычисляемых таблиц) в синхронизации с исходными базами данных.
- Старайтесь обеспечить целостность данных между исходными группами (включая кэш модели), так как ограниченные связи будут устранять строки в результатах запроса при несоответствии связанных значений столбцов.
- По возможности оптимизируйте источники данных DirectQuery с соответствующими индексами для эффективных соединений, фильтрации и группировки.
Определяемые пользователем агрегаты
Вы можете добавить определяемые пользователем агрегаты в таблицы DirectQuery. Их цель — повысить производительность для более высоких запросов зерна .
Если агрегаты кэшируются в модели, они ведут себя как таблицы импорта (хотя их нельзя использовать как таблицу моделей). Добавление агрегатов импорта в модель DirectQuery приведет к составной модели.
Примечание.
Гибридные таблицы не поддерживают агрегаты, так как некоторые секции работают в режиме импорта. Невозможно добавить агрегаты на уровне отдельного раздела DirectQuery.
Рекомендуется выполнить агрегирование по базовому правилу: его число строк должно быть не менее 10 меньше, чем базовая таблица. Например, если базовая таблица хранит 1 миллиард строк, то таблица агрегирования не должна превышать 100 миллионов строк. Это правило гарантирует, что существует достаточное повышение производительности относительно затрат на создание и обслуживание агрегирования.
Связи между исходными группами
Когда связь модели охватывает группы источников, она называется связью между исходными группами. Связи между исходными группами также ограничены , так как нет гарантированной "одной" стороны. Дополнительные сведения см. в разделе "Оценка отношений".
Примечание.
В некоторых ситуациях можно избежать создания связи между исходными группами. См. раздел "Использование срезов синхронизации" далее в этой статье.
При определении связей между исходными группами рассмотрите следующие рекомендации.
- Используйте столбцы связи с низким кратностью: для оптимальной производительности рекомендуется, чтобы столбцы связей были низкими кратностью, то есть они должны хранить менее 50 000 уникальных значений. Эта рекомендация особенно относится к сочетанию табличных моделей и для нетекстовых столбцов.
- Избегайте использования столбцов связи большого текста: если необходимо использовать текстовые столбцы в связи, вычислите ожидаемую длину текста для фильтра, умножая кратность на среднюю длину текстового столбца. Возможная длина текста не должна превышать 1 000 000 символов.
- Повышение детализации связи: по возможности создайте связи на более высоком уровне детализации. Например, вместо связи таблицы дат с ключом даты используйте вместо него ключ месяца. Этот подход к проектированию требует, чтобы связанная таблица содержит ключевой столбец месяца, и отчеты не смогут отображать ежедневные факты.
- Старайтесь достичь простой структуры отношений: только создайте связь между исходными группами, если это необходимо, и попытайтесь ограничить количество таблиц в пути связи. Этот подход к проектированию поможет повысить производительность и избежать неоднозначных путей связи.
Предупреждение
Так как Power BI Desktop не тщательно проверяет связи между исходными группами, можно создать неоднозначные связи.
Сценарий связи между исходными группами 1
Рассмотрим сценарий сложной структуры отношений и способ создания различных результатов, но допустимых.
В этом сценарии таблица "Регион" в исходной группе A имеет связь с таблицей Date и Sales в исходной группе B. Связь между таблицей "Регион" и таблицей "Дата" активна, а связь между таблицей "Регион" и таблицей "Продажи" неактивна. Кроме того, существует активная связь между таблицей "Регион " и таблицей Sales , оба из которых находятся в исходной группе B. Таблица Sales включает в себя меру с именем TotalSales, а таблица "Регион " включает в себя две меры с именем RegionalSalesDirect и RegionalSalesDirect.
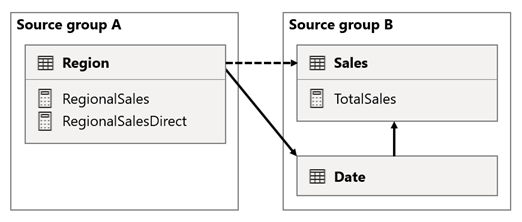
Ниже приведены определения мер.
TotalSales = SUM(Sales[Sales])
RegionalSales = CALCULATE([TotalSales], USERELATIONSHIP(Region[RegionID], Sales[RegionID]))
RegionalSalesDirect = CALCULATE(SUM(Sales[Sales]), USERELATIONSHIP(Region[RegionID], Sales[RegionID]))
Обратите внимание, что мера RegionalSales ссылается на меру TotalSales, а мера RegionalSalesDirect не имеет значения. Вместо этого мера RegionalSalesDirect использует выражение SUM(Sales[Sales]), которое является выражением меры TotalSales .
Разница в результате является тонкой. Когда Power BI оценивает меру RegionalSales, она применяет фильтр из таблицы "Регион" как к таблице Sales, так и к таблице Date. Поэтому фильтр также распространяется из таблицы Date в таблицу Sales . В отличие от этого, когда Power BI оценивает меру RegionalSalesDirect , она распространяет фильтр только из таблицы "Регион " в таблицу Sales . Результаты, возвращаемые мерой RegionalSales, и мера RegionalSalesDirect могут отличаться, несмотря на то, что выражения семантически эквивалентны.
Внимание
Всякий раз, когда вы используете CALCULATE функцию с выражением, которое является мерой в удаленной исходной группе, проверьте результаты вычисления тщательно.
Сценарий связи между исходными группами 2
Рассмотрим сценарий, когда связь между исходными группами имеет столбцы связи с высоким кратностью.
В этом сценарии таблица Date связана с таблицей Sales в столбцах DateKey . Тип данных столбцов DateKey — целое число, в котором хранятся целые числа, использующие формат ггггмдд. Таблицы относятся к разным исходным группам. Кроме того, это связь с высоким кратностью, так как самая ранняя дата в таблице даты — 1 января 1900 года, а последняя дата — 31 декабря 2100 г., поэтому в таблице будет общей сложности 73 414 строк (по одной строке для каждой даты в диапазоне времени 1900-2100).
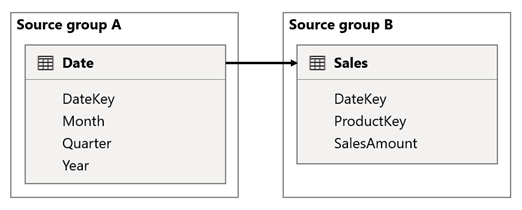
Существует два случая для беспокойства.
Во-первых, при использовании столбцов таблицы Date в качестве фильтров распространение фильтров фильтрует столбец DateKey таблицы Sales для оценки мер. При фильтрации по одному году, например 2022, запрос DAX будет включать выражение фильтра, например Sales[DateKey] IN { 20220101, 20220102, …20221231 }. Размер текста запроса может стать чрезвычайно большим, если количество значений в выражении фильтра большое или если значения фильтра являются длинными строками. Это дорого для Power BI, чтобы создать длинный запрос и источник данных для выполнения запроса.
Во-вторых, при использовании столбцов таблицы "Дата ", таких как "Год", "Квартал" или "Месяц", в качестве столбцов группирования в результате будут использоваться фильтры, включающие все уникальные сочетания годов, квартала или месяца, а также значения столбца DateKey . Размер строки запроса, который содержит фильтры по столбцам группировки и столбцу связи, может стать чрезвычайно большим. Это особенно верно, если количество группирования столбцов и (или) кратность столбца соединения ( столбец DateKey ) имеет большое значение.
Чтобы устранить любые проблемы с производительностью, можно:
- Добавьте таблицу Date в источник данных, в результате чего модель одной исходной группы (то есть она больше не является составной моделью).
- Повышение детализации связи. Например, можно добавить столбец MonthKey в обе таблицы и создать связь с этими столбцами. Однако при повышении детализации связи вы теряете возможность сообщать о ежедневных действиях по продажам (если вы не используете столбец DateKey из таблицы Sales ).
Сценарий связи между исходными группами 3
Рассмотрим сценарий, когда между таблицами не совпадают значения в связи между исходными группами.
В этом сценарии таблица Date в исходной группе B имеет отношение к таблице Sales в этой исходной группе, а также к целевой таблице в исходной группе A. Все связи — это одно ко многим из таблицы даты, относящейся к столбцам Year. Таблица Sales включает столбец SalesAmount, который хранит объемы продаж, а целевая таблица включает столбец TargetAmount, в который хранятся целевые суммы.
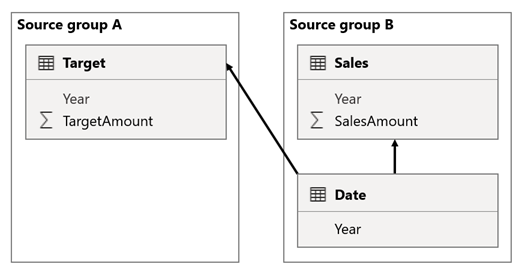
Таблица даты хранит годы 2021 и 2022. Таблица продаж хранит объемы продаж в течение 2021 (100) и 2022 (200), в то время как целевые суммы для целевой таблицы хранятся в 2021 году (100), 2022 (200) и 2023 (300) — в будущем году.
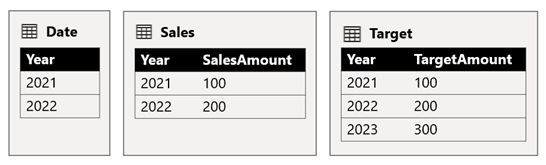
Если визуальный элемент таблицы Power BI запрашивает составную модель, группируя столбец "Год" из таблицы "Дата" и суммируя столбцы SalesAmount и TargetAmount, он не будет отображать целевую сумму для 2023 года. Это связано с тем, что связь между исходными группами является ограниченной связью, поэтому она использует INNER JOIN семантику, которая устраняет строки, в которых нет соответствующего значения на обеих сторонах. Однако он создаст правильный целевой объем (600), так как фильтр таблицы даты не применяется к его оценке.
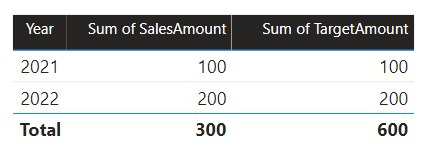
Если связь между таблицей даты и целевой таблицей является связью внутри исходной группы (если целевая таблица принадлежит исходной группе B), визуальный элемент будет включать (пустой) год для отображения целевого значения 2023 (и любых других несовпадаемых лет).
Внимание
Чтобы избежать неправильного просмотра, убедитесь, что в столбцах связей имеются соответствующие значения, когда таблицы измерений и фактов находятся в разных исходных группах.
Дополнительные сведения об ограниченных отношениях см. в разделе "Оценка отношений".
Вычисления
При добавлении вычисляемых столбцов и групп вычислений в составную модель следует учитывать определенные ограничения.
Вычисляемые столбцы
Вычисляемые столбцы, добавленные в таблицу DirectQuery, которая источник своих данных из реляционной базы данных, например Microsoft SQL Server, ограничивается выражениями, которые работают с одной строкой одновременно. Эти выражения не могут использовать функции итератора DAX, например, или функции изменения контекста фильтра, напримерSUMXCALCULATE.
Примечание.
Невозможно добавить вычисляемые столбцы или вычисляемые таблицы, зависящие от цепочки табличных моделей.
Вычисляемое выражение столбца в удаленной таблице DirectQuery ограничено только вычислением внутри строк. Однако вы можете создать такое выражение, но это приведет к ошибке при использовании в визуальном элементе. Например, если вы добавите вычисляемый столбец в удаленную таблицу DirectQuery с именем DimProduct с помощью выражения, вы сможете успешно сохранить выражение [Product Sales] / SUM (DimProduct[ProductSales])в модели. Однако это приведет к ошибке, если она используется в визуальном элементе, так как она нарушает ограничение оценки внутри строк.
В отличие от этого, вычисляемые столбцы, добавленные в удаленную таблицу DirectQuery, которая является табличной моделью, которая является семантической моделью Power BI или моделью служб Analysis Services, являются более гибкими. В этом случае все функции DAX разрешены, так как выражение будет вычисляться в исходной табличной модели.
Многие выражения требуют, чтобы Power BI материализует вычисляемый столбец перед использованием его в качестве группы или фильтра или агрегирования. Если вычисляемый столбец материализуется по большой таблице, он может быть дорогостоящим с точки зрения ЦП и памяти в зависимости от кратности столбцов, от которым зависит вычисляемый столбец. В этом случае рекомендуется добавить эти вычисляемые столбцы в исходную модель.
Примечание.
При добавлении вычисляемых столбцов в составную модель обязательно проверьте все вычисления модели. Вычисления вышестоящего потока могут работать неправильно, так как они не рассмотрели их влияние на контекст фильтра.
Группы расчета
Если группы вычислений существуют в исходной группе, которая подключается к семантической модели Power BI или модели служб Analysis Services, Power BI может возвращать непредвиденные результаты. Дополнительные сведения см. в разделе "Группы вычислений", "Запрос" и "Оценка мер".
Проектирование модели
Вы всегда должны оптимизировать модель Power BI, приняв схему звездочки.
Совет
Дополнительные сведения см. в статье "Общие сведения о схеме звезды" и важности для Power BI.
Не забудьте создать таблицы измерений, которые отделены от таблиц фактов, чтобы Power BI интерпретировать соединения правильно и создавать эффективные планы запросов. Хотя это руководство верно для любой модели Power BI, это особенно верно для моделей, которые вы распознаете, станет исходной группой составной модели. Это позволит упростить и эффективную интеграцию других таблиц в подчиненных моделях.
По возможности избегайте таблиц измерений в одной исходной группе, связанной с таблицей фактов в другой исходной группе. Это связано с тем, что лучше иметь внутри исходных связей групп, чем между отношениями между исходными группами, особенно для столбцов связи с высокой кратностью. Как описано ранее, связи между исходными группами полагаются на наличие совпадающих значений в столбцах связей, в противном случае непредвиденные результаты могут отображаться в визуальных элементах отчета.
Безопасность на уровне строк
Если модель включает определяемые пользователем агрегаты, вычисляемые столбцы в таблицах импорта или вычисляемых таблицах, убедитесь, что все параметры безопасности на уровне строк (RLS) настроены правильно и протестированы.
Если составная модель подключается к другим табличным моделям, правила RLS применяются только к исходной группе (локальной модели), в которой они определены. Они не будут применяться к другим исходным группам (удаленным моделям). Кроме того, нельзя определять правила RLS в таблице из другой исходной группы, а также не определять правила RLS в локальной таблице, которая имеет отношение к другой исходной группе.
Проектирование отчетов
В некоторых ситуациях можно повысить производительность составной модели, создав оптимизированный макет отчета.
Визуальные элементы группы с одним источником
По возможности создайте визуальные элементы, использующие поля из одной исходной группы. Это связано с тем, что запросы, созданные визуальными элементами, будут работать лучше, когда результат извлекается из одной исходной группы. Рассмотрите возможность создания двух визуальных элементов, расположенных параллельно, которые извлекают данные из двух разных исходных групп.
Использование срезов синхронизации
В некоторых ситуациях можно настроить срезы синхронизации, чтобы избежать создания связи между исходными группами в модели. Это позволяет визуально объединять группы источников, которые могут работать лучше.
Рассмотрим сценарий, когда у модели есть две исходные группы. Каждая исходная группа имеет таблицу измерения продукта, используемую для фильтрации торговых посредников и интернет-продаж.
В этом сценарии исходная группа A содержит таблицу Product , связанную с таблицей ResellerSales . Исходная группа B содержит таблицу Product2 , связанную с таблицей InternetSales . Нет связей между исходными группами.
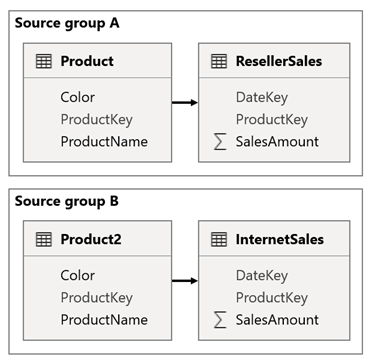
В отчете добавляется срез, который фильтрует страницу с помощью столбца "Цвет" таблицы Product. По умолчанию срез фильтрует таблицу ResellerSales, но не таблицу InternetSales. Затем вы добавите скрытый срез с помощью столбца Color таблицы Product2. Задав идентичное имя группы (найденное в расширенных параметрах срезов синхронизации), фильтры, примененные к видимому срезу, автоматически распространяются на скрытый срез.
Примечание.
При использовании срезов синхронизации может избежать необходимости создания связи между исходными группами, она повышает сложность проектирования модели. Обязательно обучите других пользователей тому, почему вы разработали модель с повторяющимися таблицами измерений. Избегайте путаницы, скрывая таблицы измерений, которые не нужны другим пользователям. Вы также можете добавить текст описания в скрытые таблицы, чтобы задокументировать их назначение.
Дополнительные сведения см. в разделе "Синхронизация отдельных срезов".
Другие рекомендации
Ниже приведены некоторые другие рекомендации по проектированию и обслуживанию составных моделей.
- Производительность и масштабирование. Если ранее отчеты были подключены к семантической модели Power BI или модели Служб Analysis Services, служба Power BI может повторно использовать визуальные кэши в отчетах. После преобразования динамического подключения для создания локальной модели DirectQuery отчеты больше не будут использовать эти кэши. В результате может возникнуть более низкая производительность или даже сбои обновления. Кроме того, рабочая нагрузка для служба Power BI увеличится, что может потребовать увеличения емкости или распределения рабочей нагрузки по другим емкостям. Дополнительные сведения об обновлении и кэшировании данных см. в разделе "Обновление данных" в Power BI.
- Переименование. Не рекомендуется переименовать семантические модели, используемые составными моделями, или переименовать их рабочие области. Это связано с тем, что составные модели подключаются к семантической модели Power BI с помощью имен рабочих областей и семантических моделей (а не их внутренних уникальных идентификаторов). Переименование семантической модели или рабочей области может нарушить подключения, используемые составной моделью.
- Управление. Мы не рекомендуем использовать единую версию модели истины как составную. Это связано с тем, что она будет зависеть от других источников данных или моделей, которые при обновлении могут привести к нарушению составной модели. Вместо этого мы рекомендуем опубликовать корпоративную семантику в качестве единой версии истины. Рассмотрим эту модель как надежную основу. Затем другие модели данных могут создавать составные модели, расширяющие базовую модель для создания специализированных моделей.
- Происхождение данных: используйте функции анализа происхождения данных и семантической модели перед публикацией составных изменений модели. Эти функции доступны в служба Power BI, и они помогают понять, как семантические модели связаны и используются. Важно понимать, что нельзя выполнять анализ влияния на внешние семантические модели, отображаемые в представлении происхождения, но на самом деле находятся в другой рабочей области. Чтобы выполнить анализ влияния на внешнюю семантику, необходимо перейти в исходную рабочую область.
- Обновления схемы. При внесении изменений схемы в вышестоящий источник данных следует обновить составную модель в Power BI Desktop. Затем необходимо повторно опубликовать модель в служба Power BI. Тщательно протестируйте вычисления и зависимые отчеты.
Связанный контент
Дополнительные сведения, связанные с этой статьей, см. в следующих ресурсах.
- Работа с составными моделями в Power BI Desktop
- Связи модели в Power BI Desktop
- Модели DirectQuery в Power BI Desktop
- Использование DirectQuery в Power BI Desktop
- Использование DirectQuery для семантических моделей Power BI и служб Analysis Services
- Режим хранения в Power BI Desktop
- Определяемые пользователем агрегаты
- Вопросы? Задайте их в сообществе Power BI.
- Есть предложения? Участие в разработке идей по улучшению Power BI