Варианты для больших данных на платформе Microsoft SQL Server
Область применения: ![]() SQL Server 2019 (15.x) и более поздних версий
SQL Server 2019 (15.x) и более поздних версий
SQL Server 2019 Big Clusters — это надстройка для платформы SQL Server, которая позволяет развертывать масштабируемые кластеры контейнеров SQL Server, Spark и HDFS, работающих на базе Kubernetes. Эти компоненты работают параллельно, позволяя считывать, записывать и обрабатывать большие данные с помощью библиотек Transact-SQL или Spark, благодаря чему вы можете с легкостью объединять и анализировать важные реляционные данные с нереляционными объемными большими данными. Кластеры больших данных также позволяют виртуализировать данные с помощью PolyBase, чтобы можно было запрашивать данные из внешних систем SQL Server, Oracle, Teradata, MongoDB и других источников данных, использующих внешние таблицы. Надстройка Microsoft SQL Server 2019 Big Clusters обеспечивает высокий уровень доступности для основного экземпляра SQL Server и всех баз данных с помощью технологии групп доступности Always On.
Надстройка Кластеры больших данных SQL Server 2019 запускается локально и в облаке с помощью платформы Kubernetes для любого стандартного развертывания Kubernetes. Кроме того, надстройка Кластеры больших данных SQL Server 2019 интегрируется с Active Directory и обеспечивает управление доступом на основе ролей для обеспечения требований предприятия в области обеспечения безопасности и соблюдения требований.
Прекращение поддержки надстройки Кластеры больших данных SQL Server 2019
28 февраля 2025 г. мы отставим от SQL Server 2019 Кластеры больших данных. Все существующие пользователи SQL Server 2019 с Software Assurance будут полностью поддерживаться на платформе, а программное обеспечение продолжит обслуживаться с помощью накопительных обновлений SQL Server до этого момента. Подробнее см. в записи блога с объявлением.
Изменения в поддержке PolyBase в SQL Server
Прекращение поддержки надстройки Кластеры больших данных SQL Server 2019 затронет ряд функций, связанных с запросами горизонтального масштабирования.
Функция PolyBase "Группа горизонтального увеличения масштаба" в Microsoft SQL Server больше не используется. Функции группы горизонтального масштабирования удаляются из продукта в SQL Server 2022 (16.x). В рыночных версиях SQL Server 2019, SQL Server 2017 и SQL Server 2016 по-прежнему поддерживают функциональность до конца жизни этих продуктов. Виртуализация данных PolyBase будет по-прежнему полностью поддерживаться как функция вертикального увеличения масштаба в SQL Server.
Облачные источники данных (CDP) и Hortonworks (HDP) Hadoop также будут прекращены для всех версий SQL Server на рынке и не включены в SQL Server 2022. Поддержка внешних источников данных ограничена версиями продуктов в основной поддержке соответствующим поставщиком. Рекомендуется использовать новую интеграцию хранилища объектов, доступную в SQL Server 2022 (16.x).
В SQL Server 2022 (16.x) и более поздних версиях пользователи должны настроить внешние источники данных для использования новых соединителей при подключении к служба хранилища Azure. В следующей таблице приводится сводка изменений:
| Внешний источник данных | С дт. | По |
|---|---|---|
| Хранилище BLOB-объектов Azure | wasb[s] |
abs |
| ADLS 2-го поколения | abfs[s] |
adls |
Примечание.
Хранилище BLOB-объектов Azure (abs) потребует использования подписанного URL-адреса (SAS) для секрета в учетных данных базы данных. В SQL Server 2019 и более ранних wasb[s] версиях соединитель использовал ключ учетной записи хранения с учетными данными, указанными в области базы данных при проверке подлинности в служба хранилища Azure учетной записи.
Общие сведения об архитектуре Кластеры больших данных для параметров замены и миграции
Чтобы создать решение на замену для хранилища больших данных и системы обработки, важно понимать, какие возможности предоставляет Кластеры больших данных SQL Server 2019, так как понимание архитектуры может помочь принять продуманное решение. Архитектура кластера больших данных выглядит следующим образом:

Данная архитектура обеспечивает следующее сопоставление функциональных возможностей.
| Компонент | Преимущества |
|---|---|
| Kubernetes | Оркестратор с открытым кодом для развертывания приложений в большом масштабе на основе контейнеров и управления такими приложениями. Предоставляет декларативный метод создания и контроля устойчивости, избыточности и переносимости для всей среды с эластичным масштабированием. |
| Контроллер Кластеры больших данных | Обеспечивает управление кластером и его безопасностью. Он включает службу контроля, хранилище конфигурации, а также другие службы уровня кластера, такие как Kibana, Grafana и Elastic Search. |
| Пул вычислений | Предоставляет кластеру вычислительные ресурсы. Он содержит узлы с pod SQL Server на Linux. Pod в вычислительном пуле подразделяются на вычислительные экземпляры SQL для решения конкретных задач обработки. Этот компонент также обеспечивает виртуализацию данных с помощью PolyBase для запроса внешних источников данных без перемещения или копирования данных. |
| Пул данных | Обеспечивает сохраняемость данных для кластера. Пул данных состоит из одного или нескольких pod с SQL Server на Linux. Он используется для приема данных из SQL-запросов или заданий Spark. |
| Пул носителей | Пул носителей формируется из pod пула носителей, состоящих из SQL Server на Linux, Spark и HDFS. Все узлы хранилища в кластере больших данных входят в кластер HDFS. |
| Пул приложений | Обеспечивает развертывание приложений в кластерах больших данных, предоставляя интерфейсы для создания, администрирования и запуска приложений. |
Дополнительные сведения о б этих функциях см. в разделе Общие сведения о Кластерах больших данных SQL Server 2019.
Варианты замены функциональных возможностей для больших данных и SQL Server
Функция обработки операционных данных, на базе SQL Server в Кластерах больших данных, может быть заменена локальной средой SQL Server в гибридной конфигурации или с помощью платформы Microsoft Azure. Microsoft Azure предоставляет возможность выбора полностью управляемых реляционных баз данных, баз данных NoSQL и выполняющихся в памяти баз данных (как с частными ядрами, так и с ядрами с открытым кодом), что позволяет удовлетворить потребности разработчиков современных приложений. Управление инфраструктурой, включая масштабируемость, доступность и безопасность, осуществляется автоматически, что экономит время и деньги, а также позволяет сосредоточиться на создании приложений. При этом базы данных под управлением Azure упрощают работу, отображая полезные сведения о производительности благодаря внедренной аналитике, масштабированию без ограничений и управлению угрозами безопасности. Дополнительные сведения см. на странице Базы данных Azure.
Следующая точка принятия решений — это расположение вычислительных ресурсов и хранилища данных для аналитики. На выбор предлагается два варианта архитектуры: облачные и гибридные развертывания. Большинство аналитических рабочих нагрузок можно перенести на платформу Microsoft Azure. Порождаемые облаком данные (создаваемые в облачных приложениях) — основной кандидат для таких технологий. При этом службы перемещения данных также могут быстро и безопасно переносить большие объемы локальные данные. Дополнительные сведения о параметрах перемещения данных см. в статье Решения для передачи данных.
В Microsoft Azure есть системы и сертификаты, позволяющие защитить данные и обработку данных в различных средствах. Дополнительные сведения об этих сертификатах см. в центре управления безопасностью.
Примечание.
Платформа Microsoft Azure обеспечивает очень высокий уровень безопасности, несколько сертификатов для различных отраслей и соблюдение независимости данных для государственных учреждений. Microsoft Azure также имеет выделенную облачную платформу для государственных рабочих нагрузок. При принятии решений в отношении локальных систем не следует ориентироваться только на безопасность. Перед принятием решения о локальном хранении решений для работы с большими данными следует тщательно оценить уровень безопасности, предоставляемый Microsoft Azure.
В случае облачной архитектуры все компоненты находятся в Microsoft Azure. Ответственность за данные и код, создаваемый вами для хранения и обработки рабочих нагрузок, лежит на вас. Эти варианты подробно описываются далее в этой статье.
- Этот вариант лучше всего подходит для широкого спектра компонентов для хранения и обработки данных, а также при необходимости сосредоточиться на конструкциях данных и обработке, а не на инфраструктуре.
В случае гибридной архитектуры одни компоненты хранятся локально, а другие — у поставщика облачных служб. Связь между ними разработана из соображений наилучшего размещения для обработки данных.
- Этот вариант лучше всего подходит, если у вас есть значительные инвестиции в локальные технологии и архитектуры, но вы хотите использовать предложения Microsoft Azure или при наличии целевых объектов обработки и приложений, находящихся в локальной среде или для глобальной аудитории.
Дополнительные сведения о создании масштабируемых архитектур см. в статье Создание масштабируемой системы для больших объемов данных.
В облаке
Azure SQL с Synapse
Вы можете заменить функциональные возможности Кластера больших данных SQL Server с помощью одного или нескольких вариантов баз данных SQL Azure для операционных данных, а также Microsoft Azure Synapse для аналитических рабочих нагрузок.
Microsoft Azure Synapse — это корпоративная служба аналитики, которая ускоряет извлечение аналитических сведений в разных хранилищах данных и системах больших данных, используя распределенную обработку конструкций данных. Azure Synapse сочетает в себе технологии SQL, используемые в корпоративных хранилищах данных, технологии Spark, используемые при работе с большими данными, конвейеры для интеграции данных и их извлечения, преобразования и загрузки, а также возможности глубокой интеграции с другими службами Azure, такими как Power BI, Cosmos DB и Машинное обучение Azure.
Используйте Microsoft Azure Synapse в качестве замены Кластеров больших данных SQL Server 2019, если требуется:
- Используйте бессерверные и выделенные модели ресурсов. Для прогнозируемой производительности и затрат можно создавать выделенные пулы SQL, чтобы резервировать вычислительные мощности для данных, хранящихся в таблицах SQL.
- Требуется обработка незапланированных или "пакетных" рабочих нагрузок, постоянный доступ и бессерверная конечная точка SQL.
- Используются встроенные возможности потоковой передачи для передачи данных из облачных источников данных в таблицы SQL.
- Требуется объединить возможности искусственного интеллекта с SQL с помощью моделей машинного обучения для оценки данных с использованием функции T-SQL PREDICT.
- Используйте модели машинного обучения с алгоритмами SparkML и интеграцию Машинное обучение Azure для Apache Spark 2.4, поддерживаемых для Linux Foundation Delta Lake.
- Используется упрощенная модель ресурсов, которая освобождает вас от необходимости заниматься управлением кластерами.
- Выполняется обработка данных, требующая быстрого запуска Spark и агрессивного автоматического масштабирования.
- Обработка данных с помощью .NET для Spark, позволяющая использовать знание языка C# и существующий код .NET в приложении Spark.
- Выполняется работа с таблицами, созданными на основе файлов в озере данных, которые прозрачно потребляются Spark или Hive.
- Используется SQL со Spark для непосредственного изучения и анализа файлов Parquet, CSV, TSV и JSON, хранящихся в озере данных.
- Включена быстрая масштабируемая передача данных между базами данных SQL и Spark.
- Осуществляется прием данных из более чем 90 источников.
- Включено извлечение, преобразование и загрузка без кода с помощью действий потока данных.
- Осуществляется оркестрация записных книжек, заданий Spark, хранимых процедур, скриптов SQL и т. д.
- Осуществляется мониторинг ресурсов, использования и пользователей в SQL и Spark.
- Используется управлением доступом на основе ролей для упрощения доступа к ресурсам аналитики.
- Требуется написать код SQL или Spark и интегрировать его с корпоративными процессами CI/CD.
Архитектура Microsoft Azure Synapse выглядит следующим образом:

Дополнительную информацию о Microsoft Azure Synapse см. в статье Что такое Azure Synapse Analytics?.
Azure SQL и Машинное обучение Azure
Вы можете заменить функциональные возможности Кластера больших данных SQL Server с помощью одного или нескольких вариантов баз данных SQL Azure для операционных данных, а также Машинного обучения Microsoft Azure для прогнозируемых рабочих нагрузок.
Машинное обучение Azure — это облачная служба, которую можно использовать для машинного обучения любого вида: классического и глубокого, а также контролируемого и неконтролируемого. Если вы предпочитаете писать код Python или R, используя пакет SDK, или варианты без кода или с минимальным созданием кода, например в студии, вы можете создавать, изучать и отслеживать модели машинного обучения и глубокого обучения в рабочей области Машинного обучения Azure. Машинное обучение Azure позволяет начать обучение на локальном компьютере, а затем перенести его в облако. Служба также взаимодействует с популярными средствами для глубокого обучения с подкреплением с открытым кодом, такими как PyTorch, TensorFlow, scikit-learn и Ray RLlib.
Используйте Машинное обучение Microsoft Azure в качестве замены Кластеров больших данных SQL Server 2019, если требуется:
- Веб-среда на базе конструктора Машинного обучения: перетащите модули, чтобы создать эксперименты, а затем разверните конвейеры в среде малокодовой разработки.
- Записные книжки Jupyter: используйте наши примеры записных книжек или создайте собственные записные книжки, чтобы использовать наш пакет SDK для примеров Python для машинного обучения.
- Скрипты R или записные книжки, в которых используется пакет SDK для R для написания собственного кода, или модули R в конструкторе.
- Акселератор решений для многих моделей, основанный на службе Машинного обучения Azure, который позволяет обучать, использовать и обслуживать сотни и даже тысячи моделей машинного обучения.
- Расширение Машинного обучения для Visual Studio Code, которое предоставляет полнофункциональную среду разработки для создания проектов машинного обучения и управления ими.
- Интерфейс командной строки (CLI) Машинного обучения. Машинное обучение Azure содержит расширение, которое предоставляет команды для управления ресурсами Машинного обучения Azure из командной строки.
- Интеграция с платформами с открытым кодом (PyTorch, TensorFlow, scikit-learn и многими другими) для обучения, развертывания и управления всеми этапами машинного обучения.
- Обучение с подкреплением с помощью Ray RLlib.
- MLflow для мониторинга метрик и развертывания моделей или Kubeflow для создания конвейеров сквозных рабочих процессов.
Архитектура развертывания Машинного обучения Microsoft Azure выглядит следующим образом:

Дополнительные сведения о Машинном обучении Microsoft Azure см. в статье Машинное обучение Azure.
Azure SQL из Databricks
Вы можете заменить функциональные возможности Кластера больших данных SQL Server с помощью одного или нескольких вариантов баз данных SQL Azure для операционных данных, а также Microsoft Azure Databricks для аналитических рабочих нагрузок.
Azure Databricks — это платформа аналитики данных, оптимизированная для платформы облачных служб Microsoft Azure. Azure Databricks предлагает две среды для разработки приложений с интенсивными данными: Аналитика SQL Azure Databricks и рабочая область Azure Databricks.
Аналитика SQL в Azure Databricks предоставляет простую в использовании платформу для аналитиков, которым нужно выполнять SQL-запросы к озеру данных, создавать разные типы визуализации для просмотра результатов запросов в разных контекстах, а также создавать и совместно использовать панели мониторинга.
Рабочая область Azure Databricks предоставляет интерактивную рабочую область, которая предоставляет возможности совместной работы специалистов по инжинирингу данных, специалистов по обработке и анализу данных и специалистов по машинному обучению. В конвейере больших данных эти данные (необработанные или структурированные) принимаются в Azure через Фабрику данных Azure в виде пакетов или передаются в рамках потоковой передачи практически в реальном времени с помощи Apache Kafka, концентраторов событий или Центра Интернета вещей. Эти данные попадают в озеро данных для долгосрочного хранения в хранилище BLOB-объектов Azure или Azure Data Lake Storage. В рамках рабочего процесса аналитики вы можете использовать Azure Databricks для считывания данных из множества источников данных и получения полезных сведений с помощью Spark.
Используйте Microsoft Azure Databricks в качестве замены Кластеров больших данных SQL Server 2019, если требуется:
- Полностью управляемые кластеры Spark со Spark SQL и элементами DataFrame.
- Потоковая передача для обработки и анализа данных в режиме реального времени для аналитических и интерактивных приложений, интеграции с HDFS, Flume и Kafka.
- Доступ к библиотеке MLlib, состоящей из распространенных алгоритмов обучения и служебных программ, включая классификацию, регрессию, кластеризацию, совместную фильтрацию, уменьшение размерности и примитивы базовой оптимизации.
- Документация хода выполнения в записных книжках в R, Python, Scala или SQL.
- Визуализация данных за несколько шагов с помощью таких привычных средств, как Matplotlib, ggplot или d3.
- Интерактивные панели мониторинга для создания динамических отчетов.
- GraphX для графов и их вычисления для широкой области вариантов использования, начиная с когнитивной аналитики и заканчивая исследованием данных.
- Создание кластера за считанные секунды с помощью динамических кластеров с авто масштабированием и их совместное использование в разных командах.
- Программный доступ к кластеру с помощью интерфейсов REST API.
- Мгновенный доступ к последним функциям Apache Spark с каждым выпуском.
- API ядра Spark, включая поддержку для R, SQL, Python, Scala и Java.
- Интерактивная рабочая область для исследования и визуализации.
- Полностью управляемые конечные точки SQL в облаке.
- Запросы SQL, выполняемые на полностью управляемых конечных точках SQL, размер которых соответствует требованиям к задержке запросов и числу одновременно работающих пользователей.
- Интеграция с идентификатором Microsoft Entra (ранее — Azure Active Directory).
- Доступ на основе ролей для точного определения разрешений пользователя для записных книжек, кластеров, заданий и данных.
- Соглашения об уровне обслуживания корпоративного уровня.
- Панели мониторинга для обмена аналитическими сведениями, объединяющие визуализации и текст для обмена аналитическими сведениями, полученными из запросов.
- Оповещения, которые помогают с отслеживанием и интеграцией, а также уведомления о том, что поле, возвращаемое запросом, соответствует пороговому значению. Используйте оповещения, чтобы отслеживать бизнес-операции, или интегрируйте их с другими инструментами для обслуживания таких процессов, как регистрация пользователей или обработка запросов в службу поддержки.
- Корпоративная безопасность, включая интеграцию идентификатора Microsoft Entra, элементы управления на основе ролей и соглашения об уровне обслуживания, которые защищают данные и бизнес.
- Интеграция с такими службами, базами данных и службами хранения Azure, как Synapse Analytics, Cosmos DB, Data Lake Store и Хранилище BLOB-объектов.
- Интеграция с Power BI и другими средствами бизнес-аналитики, такими как Tableau Software.
Архитектура развертывания Microsoft Azure Databricks выглядит следующим образом:
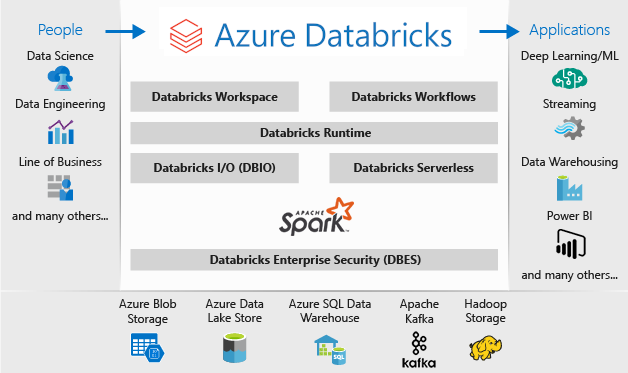
Дополнительные сведения о Microsoft Azure Databricks см. в статье Что такое Databricks для обработки, анализа и инжиниринга данных.
Гибридный трафик
Зеркальная база данных Fabric
Как опыт репликации данных зеркальное отображение базы данных в Fabric — это низкое и низкое время задержки, которое позволяет объединять данные из различных систем в одну платформу аналитики. Вы можете непрерывно реплицировать существующий объект данных непосредственно в OneLake Fabric, включая данные из База данных SQL Azure, Snowflake и Cosmos DB.
Используя самые актуальные данные в запрашиваемом формате в OneLake, теперь можно использовать все различные службы в Fabric, такие как выполнение аналитики с помощью Spark, выполнение записных книжек, проектирование данных, визуализация с помощью отчетов Power BI и многое другое.
Зеркальное отображение в Fabric обеспечивает простой способ ускорения времени на получение аналитических сведений и решений, а также для разбиения силосов данных между технологическими решениями без разработки дорогостоящих процессов извлечения, преобразования и загрузки (ETL) для перемещения данных.
При зеркальном отображении в Fabric вам не нужно объединять разные службы от нескольких поставщиков. Вместо этого вы можете наслаждаться высоко интегрированным, комплексным и простым продуктом, который предназначен для упрощения потребностей аналитики, и построен для открытости и совместной работы между технологическими решениями, которые могут читать формат таблицы Delta Lake с открытым исходным кодом.
Дополнительные сведения см. в разделе:
- Зеркальные базы данных Microsoft Fabric
- Мониторинг зеркальных баз данных Microsoft Fabric
- Изучение данных в зеркальной базе данных с помощью Microsoft Fabric
- Что такое Microsoft Fabric?
- Модели данных в семантической модели Power BI по умолчанию в Microsoft Fabric
- Что такое конечная точка аналитики SQL для Lakehouse?
- Прямое озеро
Использование SQL Server 2022 с Azure Synapse Link для SQL
SQL Server 2022 (16.x) содержит новую функцию, которая позволяет подключаться между таблицами SQL Server и платформой Microsoft Azure Synapse, Azure Synapse Link для SQL. Azure Synapse Link для SQL Server 2022 (16.x) предоставляет автоматические каналы изменений, которые фиксируют изменения в SQL Server и загружают их в Azure Synapse Analytics. Это решение обеспечивает анализ практически в реальном времени и гибридную транзакционную и аналитическую обработку с минимальным влиянием на операционные системы. После того как данные поступают в Synapse, их можно объединить с множеством различных источников данных независимо от их размера, масштаба или формата, а также запустить для них эффективные аналитические средства, используя Машинное обучение Azure, Spark или Power BI. Так как веб-каналы автоматических изменений передают только новые или разные возможности, передача данных выполняется гораздо быстрее, и теперь позволяет практически в реальном времени получать аналитические сведения с минимальным воздействием на производительность исходной базы данных в SQL Server 2022 (16.x).
Для операционных и даже многих аналитических рабочих нагрузок SQL Server может обрабатывать больше объемы баз данных. Дополнительные сведения о требованиях к максимальной емкости для SQL Server см. в статье Ограничения вычислительной емкости для разных выпусков SQL Server Использование нескольких экземпляров SQL Server на отдельных компьютерах с секционированными запросами T-SQL позволяет горизонтально увеличивать масштаб среды для приложений.
Использование PolyBase позволяет вашему экземпляру SQL Server запрашивать данные с помощью T-SQL непосредственно из SQL Server, Oracle, Teradata, MongoDB и Cosmos DB без необходимости устанавливать клиентское программное обеспечение для подключения. Вы также можете использовать универсальный соединитель ODBC в экземпляре на основе Microsoft Windows для подключения к дополнительным поставщикам с помощью сторонних драйверов ODBC. PolyBase позволяет с помощью запросов T-SQL объединить данные из внешних источников с данными из реляционных таблиц в экземпляре SQL Server. Это позволяет сохранить данные в исходном расположении и формате. Вы можете виртуализировать внешние данные в экземпляре и запрашивать их на месте так же, как любую другую таблицу в SQL Server. SQL Server 2022 (16.x) также позволяет выполнять нерегламентированные запросы и резервное копирование и восстановление через Object-Store (с помощью аппаратного или программного хранилища S3-API).
Существует две общие эталонные архитектуры. Одна из них предполагает использование SQL Server на изолированном сервере для структурированных запросов данных и в отдельно установленной нереляционной системе с горизонтальным увеличением масштаба (например, Apache Hadoop или Apache Spark) для локальной связи с Synapse. Другой вариант — использовать набор контейнеров в кластере Kubernetes со всеми компонентами для вашего решения.
Microsoft SQL Server в Windows, Apache Spark и локальном хранилище объектов
Вы можете установить SQL Server в Windows или Linux и увеличить масштаб архитектуры оборудования, используя возможность запроса хранилища объектов SQL Server 2022 (16.x) и функцию PolyBase, чтобы включить запросы ко всем данным в вашей системе.
Установка и настройка платформы с горизонтальным увеличением масштаба, например Apache Hadoop или Apache Spark, позволяет выполнять запросы нереляционных данных в большом масштабе. Использование центрального набора систем Object-Storage, поддерживающих S3-API, позволяет SQL Server 2022 (16.x) и Spark получать доступ к одному набору данных во всех системах.
Соединитель Microsoft Apache Spark для SQL Server и Azure SQL также имеет возможность запрашивать данные непосредственно из SQL Server с помощью заданий Spark. Дополнительные сведения о соединителе Apache Spark для SQL Server и Azure SQL см. в статье Соединитель Apache Spark: SQL Server и Azure SQL.
Для развертывания можно также использовать систему оркестрации контейнеров Kubernetes. Это позволит использовать декларативную архитектуру, которая может работать в локальной среде или в любом облаке, поддерживающем Kubernetes или платформу Red Hat OpenShift. Дополнительные сведения о развертывании SQL Server в среде Kubernetes см. в статье "Развертывание кластера контейнеров SQL Server в Azure " или просмотр развертывания SQL Server 2019 в Kubernetes.
Используйте SQL Server и Hadoop/Spark локально в качестве замены Кластера больших данных SQL Server 2019, если требуется:
- Требуется локальное хранение всего решения.
- Для всех частей решения используется выделенное оборудование.
- Нужен доступ к реляционным и нереляционным данным из одной и той же архитектуры в обоих направлениях.
- Требуется совместное использование одного набора нереляционных данных в SQL Server и нереляционной системе с горизонтальным увеличением масштаба.
Выполнение миграции
После выбора расположения (в облаке или гибридной) для миграции необходимо взвесить векторы простоя и затрат, чтобы определить, выполняете ли вы новую систему и перемещаете данные из предыдущей системы в новую в режиме реального времени (параллельной миграции) или резервное копирование и восстановление или новое начало системы из существующих источников данных (миграция на месте).
Далее необходимо решить, следует ли перезапись текущие функциональные возможности в системе новым вариантом архитектуры, или же переместить максимально возможный объем кода в новую систему. Хотя бывший выбор может занять больше времени, он позволяет использовать новые методы, концепции и преимущества, которые предоставляет новая архитектура. В этом случае при планировании следует в первую очередь сосредоточиться на картах функциональных возможностей и доступа к данным.
Если планируется перенос текущей системы с минимальным изменением кода, при планировании следует уделить основное внимание совместимости языков.
Перенос кода
Следующим шагом является аудит кода, используемого в текущей системе, и изменений, которые необходимо внести в новой среде.
При переносе кода необходимо учитывать два основных вектора:
- Источники и приемники
- Миграция функций
Источники и приемники
Первая задача при переносе кода заключается в определении методов подключения к источникам данных, строк или интерфейсов API, используемых кодом для доступа к импортируемым данным, пути к ним и конечному месту назначения. Задокументируйте эти источники и создайте карту расположений новой архитектуры.
- Если текущее решение использует систему конвейера для перемещения данных через систему, сопоставьте новые источники архитектуры, шаги и приемники с компонентами конвейера.
- Если в новом решении заменяется также архитектура конвейера, при планировании систему следует рассматривать как новую установку, даже если вы повторно используете в качестве замены ту же аппаратную или облачную платформу.
Миграция функций
Наиболее сложная задача, которую необходимо выполнить при миграции, — создание ссылок, обновление или создание документации для функциональных возможностей текущей системы. Если вы планируете обновление на месте и пытаетесь сократить объем перезаписи кода как можно больше времени, этот шаг занимает больше времени.
Тем не менее, миграция с предыдущей технологии зачастую является оптимальным моментом для обновления системы путем внедрения в нее новейших технологических усовершенствований и использования преимуществ предоставляемых ею конструкций. Перезапись текущей системы зачастую позволяет повысить безопасность и производительность, а также улучшить выбор компонентов и даже оптимизировать затраты.
В любом случае у вас есть два основных фактора, связанных с миграцией: код и языки, поддерживаемые новой системой, а также варианты перемещения данных. Как правило, вы сможете изменять строка подключения из текущего кластера больших данных в экземпляр SQL Server и среду Spark. Сведения о подключении к данным и прямая миграция кода должны быть минимальными.
Если вы предполагаете перезапись текущих функциональных возможностей, сопоставите новые библиотеки, пакеты и библиотеки DLL с архитектурой, выбранной для миграции. Список всех библиотек, языков и функций, предлагаемых каждым решением приведен в справочной документации, перечисленной в предыдущих разделах. Сопоставьте все подозрительные или неподдерживаемые языки и запланируйте замену с помощью выбранной архитектуры.
Параметры миграции данных
Для перемещения данных в масштабной аналитической системе можно использовать два распространенных подхода. Первый — создать процесс "прямой миграции", в котором исходная система продолжит обработку данных, а данные сводятся в небольшой набор агрегированных источников данных отчета. В этом случае новая система запускается с новыми данными и используется, начиная с даты переноса.
Иногда из устаревшей системы в новую необходимо перенести все данные. В этом случае можно подключить исходные хранилища файлов из Кластеров больших данных SQL Server, если новая система их поддерживает, а затем скопировать данные по частям в новую систему или обеспечить их физическое перемещение.
Перенос текущих данных из Кластера больших данных SQL Server 2019 в другую систему в значительной степени зависит от двух факторов: расположения текущих данных и их места назначения: локально или в облаке.
Миграция локальных данных
Для миграции между локальными средами можно перенести данные SQL Server с помощью стратегии резервного копирования и восстановления. Кроме того, можно настроить репликацию для перемещения некоторых или всех реляционных данных. Для копирования данных из SQL Server в другое расположение можно также использовать SQL Server Integration Services. Дополнительные сведения о перемещении данных с помощью SQL Server Integration Services см. в статье SQL Server Integration Services.
Для данных HDFS в текущей среде кластера больших данных SQL Server стандартный подход заключается в подключении данных к автономному кластеру Spark, а также использовать процесс хранилища объектов для перемещения данных, чтобы экземпляр SQL Server 2022 (16.x) смог получить доступ к нему или оставить его как есть и продолжать обрабатывать их с помощью заданий Spark.
Миграция данных в облаке
Для данных, расположенных в облачном хранилище или локально, можно использовать Фабрику данных Azure, которая содержит более 90 соединителей для полного конвейера передачи, с возможностями планирования, мониторинга, оповещения и другими службами. Дополнительные сведения о Фабрике данных Azure см. в статье Что такое фабрика данных Azure?.
Чтобы быстро и безопасно переместить большие объемы данных из локальной среды данных в Microsoft Azure, можно воспользоваться службой "Импорт и экспорт Azure". Служба "Импорт и экспорт Azure" используется для безопасного импорта больших объемов данных в Хранилище BLOB-объектов Azure и службу "Файлы Azure" путем отправки дисков в центр обработки данных Azure. Кроме того, эту службу можно использовать, чтобы переносить данные из хранилища BLOB-объектов Azure на диски и передавать на локальные сайты. Данные с одного или нескольких дисков можно импортировать в хранилище BLOB-объектов Azure или службу файлов Azure. Использование этой службы может оказаться самым быстрым путем для очень больших объемов данных.
Если вам нужно передать данные с помощью дисков, предоставленных корпорацией Майкрософт, для импорта данных в Azure можно использовать диск Azure Data Box. Дополнительные сведения см. в статье Что такое служба "Импорт и экспорт Azure"?.
Дополнительные сведения об этих вариантах и связанных с ними решениях см. в разделе Использование Data Lake Storage 1-го поколения для обеспечения соответствия требованиям больших данных.