Nastavenia správy pracovného priestoru Apache Spark v službe Microsoft Fabric
Vzťahuje sa na: ![]() Dátový inžinier ing a dátovú vedu v službe Microsoft Fabric
Dátový inžinier ing a dátovú vedu v službe Microsoft Fabric
Keď vytvoríte pracovný priestor v službe Microsoft Fabric, automaticky sa vytvorí štartovací fond priradený k daného pracovnému priestoru. V prípade zjednodušeného nastavenia v službe Microsoft Fabric nie je potrebné vyberať uzol alebo veľkosť počítača, pretože tieto možnosti sa spracúvajú vedľa vás na pozadí. Táto konfigurácia poskytuje rýchlejšie (5 – 10 sekúnd) spustenie relácie Apache Spark pre používateľov, ktorí môžu začať a spúšťať pracovné miesta v Apache Spark v mnohých bežných scenároch bez toho, aby sa museli starať o nastavenie výpočtu. V prípade pokročilých scenárov so špecifickými požiadavkami na výpočet môžu používatelia vytvoriť vlastný fond Apache Spark a zväčšiť uzly podľa svojich potrieb týkajúcich sa výkonu.
Ak chcete v pracovnom priestore vykonať zmeny v nastaveniach Apache Spark, musíte mať rolu správcu pre tento pracovný priestor. Ďalšie informácie nájdete v téme Roly v pracovných priestoroch.
Ak chcete spravovať nastavenia služby Spark pre fond priradený k vášmu pracovnému priestoru:
Prejdite do nastavení pracovného priestoru vo svojom pracovnom priestore a rozbaľte ponuku výberom možnosti Dátový inžinier ing/Science:
V ponuke na ľavej strane sa zobrazí možnosť Spark Compute :
Poznámka
Ak predvolený fond zmeníte z možnosti Starter Pool na vlastný fond spark, môže sa zobraziť dlhší začiatok relácie (~3 minúty).

Fond
Predvolený fond pre pracovný priestor
Môžete použiť automaticky vytvorený štartovací fond alebo vytvoriť vlastné fondy pre pracovný priestor.
Starter Pool: Vopred zhydrované dynamické bazény automaticky vytvorené pre vaše rýchlejšie používanie. Tieto klastre majú strednú veľkosť. Štartovací fond je nastavený na predvolenú konfiguráciu na základe zakúpenej jednotky SKU kapacity služby Fabric. Správcovia môžu prispôsobiť maximálne uzly a spustiteľných vykonávateľov na základe ich požiadaviek na vyťaženie služby Spark. Ďalšie informácie nájdete v téme Konfigurácia štartovacích bazénov
Vlastný fond spark: Na základe požiadaviek na prácu v službe Spark môžete nastaviť veľkosť uzlov, automatického škálovania a dynamického prideľovania vykonávateľov. Ak chcete vytvoriť vlastný fond spark, správca kapacity by mal povoliť možnosť Prispôsobiť fondy pracovných priestorov v časti Spark Compute v nastaveniach správcu kapacity.
Poznámka
Ovládací prvok úrovne kapacity pre fondy prispôsobených pracovných priestorov je predvolene povolený. Ďalšie informácie nájdete v téme Konfigurácia a spravovanie nastavení dátového inžinierstva a dátovej vedy pre kapacity služby Fabric.
Správcovia môžu vytvoriť vlastné fondy Spark na základe svojich výpočtových požiadaviek výberom možnosti Nový fond .

Apache Spark for Microsoft Fabric podporuje klastre s jedným uzlom, čo umožňuje používateľom vybrať minimálnu konfiguráciu uzla 1, pričom v takom prípade vodič a spustiteľný súbor spustí v jednom uzli. Tieto klastre jedného uzla ponúkajú regenerovateľnú vysokú dostupnosť v prípade zlyhaní uzla a lepšej spoľahlivosti práce pre vyťaženia s menšími výpočtovými požiadavkami. Môžete tiež povoliť alebo zakázať možnosť automatického škálovania pre vlastné fondy Spark. Keď je táto možnosť povolená pomocou automatického škálovania, fond získa nové uzly v rámci maximálneho limitu uzla, ktorý zadal používateľ, a po vykonaní úlohy ho vymaže do dôchodku, aby bol lepší výkon.
Môžete tiež vybrať možnosť dynamického prideľovania vykonávateľov tak, aby automaticky vytvorili optimálny počet vykonávateľov v rámci maximálneho objemu určeného na základe objemu údajov pre lepší výkon.

Ďalšie informácie o výpočte služby Apache Spark pre službu Fabric.
- Prispôsobenie konfigurácie výpočtových položiek: Ako správca pracovného priestoru môžete používateľom povoliť upravovať výpočtové konfigurácie (vlastnosti na úrovni relácie, ktoré zahŕňajú Ovládač/Spustiteľné jadro, pamäť ovládača/vykonávača) pre jednotlivé položky, ako sú poznámkové bloky, definície úloh spark pomocou prostredia.
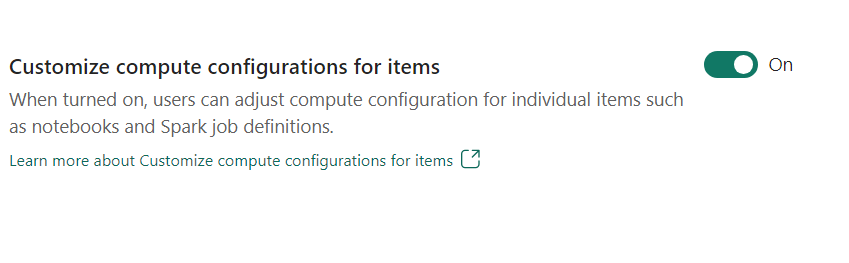
Ak správca pracovného priestoru toto nastavenie vypne, predvolený fond a jeho výpočtové konfigurácie sa použijú pre všetky prostredia v pracovnom priestore.
Environment
Prostredie poskytuje flexibilné konfigurácie na spúšťanie úloh v službe Spark (notebooky, definície úloh Spark). V prostredí môžete nakonfigurovať vlastnosti výpočtu, vybrať rôzne závislosti balíka knižnice runtime a nastaviť knižnicu na základe požiadaviek na vyťaženie.
Na karte prostredia máte možnosť nastaviť predvolené prostredie. Môžete si vybrať, ktorú verziu Služby Spark chcete použiť pre pracovný priestor.
Ako správca pracovného priestoru služby Fabric môžete ako predvolené prostredie vybrať prostredie.
Môžete tiež vytvoriť nový prostredníctvom rozbaľovacieho zoznamu Prostredie .

Ak zakážete možnosť mať predvolené prostredie, máte možnosť vybrať verziu runtime služby Fabric z dostupných verzií modulu runtime uvedených v rozbaľovacom zozname.

Ďalšie informácie o moduloch runtime služby Apache Spark.
Vysoká súbežnosť
Režim vysokej súbežnosti umožňuje používateľom zdieľať rovnaké relácie Spark v dátovom inžinierstve a vyťažení dátovej vedy služby Apache Spark for Fabric. Položka ako poznámkový blok používa na vykonanie reláciu služby Spark a keď je povolená, používatelia môžu zdieľať jednu reláciu služby Spark vo viacerých poznámkových blokoch.

Ďalšie informácie o vysokej súbežnosti v službe Apache Spark for Fabric.
Automatické zapisovanie do denníka pre modely a experimenty strojové učenie
Správcovia teraz môžu povoliť automatické označovanie pre svoje modely strojového učenia a experimenty. Táto možnosť automaticky zaznamenáva hodnoty vstupných parametrov, výstupných metrík a výstupných položiek modelu strojového učenia počas jeho trénovania. Ďalšie informácie o automatickom označovaní.

Súvisiaci obsah
- Prečítajte si o apache Spark Runtimes v službe Fabric – prehľad, tvorba verzií, podpora viacerých modulov runtime a inovácia protokolu Delta Lake.
- Ďalšie informácie nájdete v verejnej dokumentácii k Apache Spark.
- Vyhľadajte odpovede na najčastejšie otázky: Najčastejšie otázky o spravovaní pracovného priestoru Apache Spark.
Pripomienky
Pripravujeme: V priebehu roka 2024 postupne zrušíme službu Problémy v službe GitHub ako mechanizmus pripomienok týkajúcich sa obsahu a nahradíme ju novým systémom pripomienok. Ďalšie informácie nájdete na stránke: https://aka.ms/ContentUserFeedback.
Odoslať a zobraziť pripomienky pre