Vad är en datasjö?
En datasjö är en lagringsplats som innehåller en stor mängd data i sitt ursprungliga rådataformat. Datasjölager är optimerade för att skala deras storlek till terabyte och petabyte med data. Data kommer vanligtvis från flera olika källor och kan innehålla strukturerade, halvstrukturerade eller ostrukturerade data. En datasjö hjälper dig att lagra allt i dess ursprungliga, otransformerade tillstånd. Den här metoden skiljer sig från ett traditionellt informationslager som transformerar och bearbetar data vid tidpunkten för inmatning.
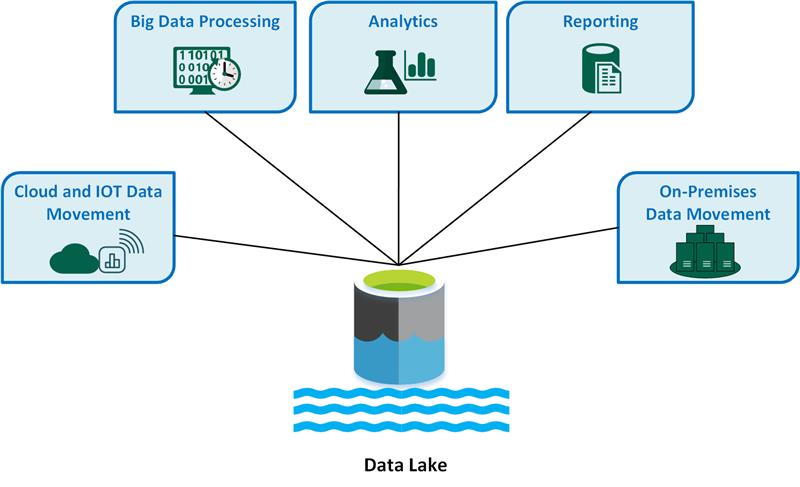
Viktiga användningsfall för datasjöar är:
- Dataförflyttning i molnet och Sakernas Internet (IoT).
- Bearbetning av stordata.
- Analys.
- Rapportering.
- Lokal dataförflyttning.
Överväg följande fördelar med en datasjö:
En datasjö tar aldrig bort data eftersom den lagrar data i sitt rådataformat. Den här funktionen är särskilt användbar i en stordatamiljö eftersom du kanske inte i förväg vet vilka insikter du kan få från data.
Användare kan utforska data och skapa egna frågor.
En datasjö kan vara snabbare än traditionella ETL-verktyg (extract, transform, load).
En datasjö är mer flexibel än ett informationslager eftersom den kan lagra ostrukturerade och halvstrukturerade data.
En komplett datasjölösning består av både lagring och bearbetning. Data lake storage är utformat för feltolerans, oändlig skalbarhet och datainmatning med högt dataflöde av olika former och datastorlekar. Data lake-bearbetning omfattar en eller flera bearbetningsmotorer som kan införliva dessa mål och som kan användas på data som lagras i en datasjö i stor skala.
När du bör använda en datasjö
Vi rekommenderar att du använder en datasjö för datautforskning, dataanalys och maskininlärning.
En datasjö kan fungera som datakälla för ett informationslager. När du använder den här metoden matar datasjön in rådata och omvandlar dem sedan till ett strukturerat frågeformat. Den här omvandlingen använder vanligtvis en ELT-pipeline (extract, load, transform) där data matas in och transformeras på plats. Relations källdata kan gå direkt till informationslagret via en ETL-process och hoppa över datasjön.
Du kan använda datasjölager i händelseströmnings- eller IoT-scenarier eftersom datasjöar kan bevara stora mängder relations- och icke-relationsdata utan transformering eller schemadefinition. Datasjöar kan hantera stora mängder små skrivningar med låg svarstid och är optimerade för massivt dataflöde.
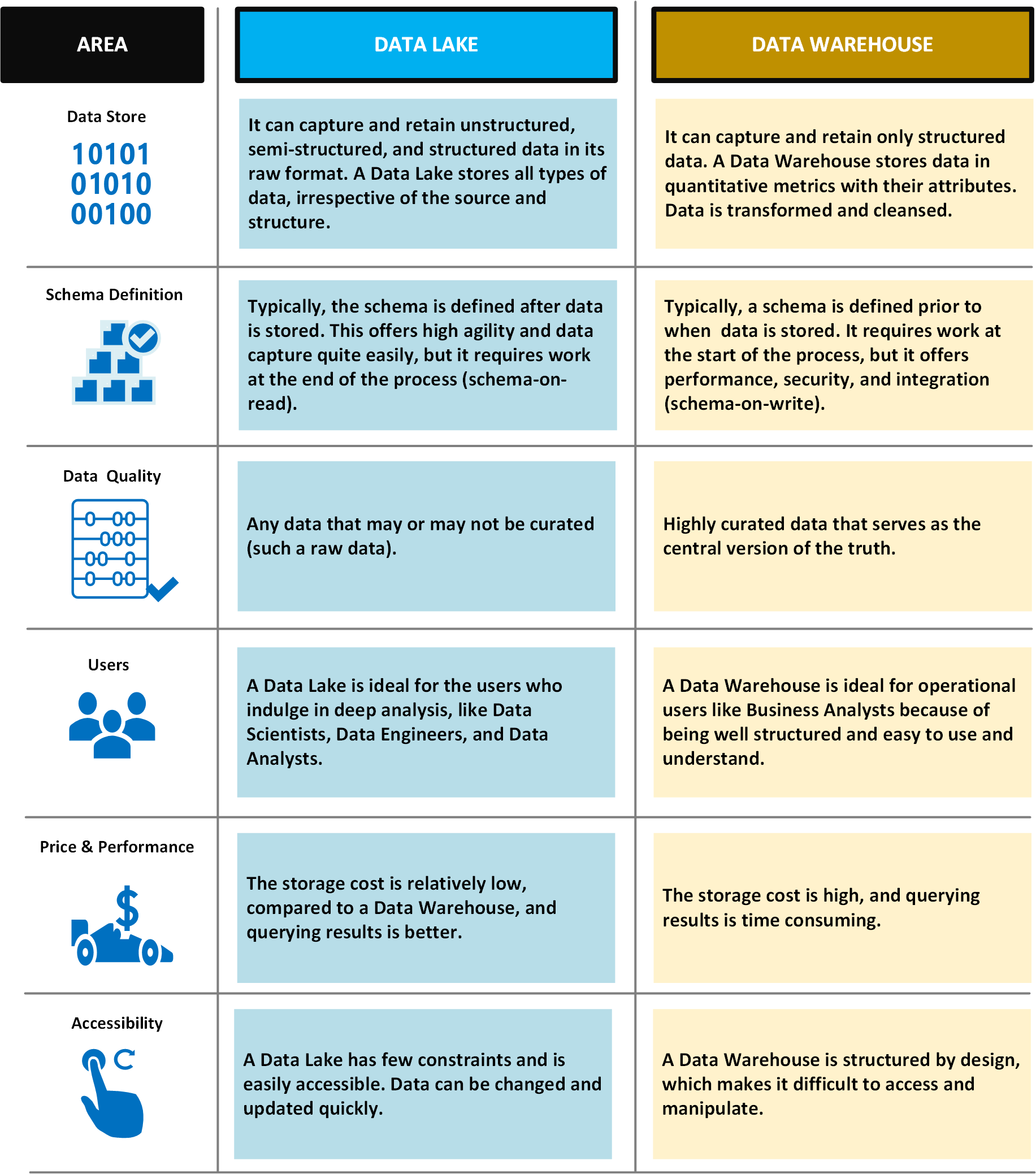
I följande tabell jämförs datasjöar och informationslager.
Utmaningar
Stora mängder data: Hanteringen av stora mängder rådata och ostrukturerade data kan vara komplex och resursintensiv, så du behöver robust infrastruktur och verktyg.
Potentiella flaskhalsar: Databearbetning kan medföra fördröjningar och ineffektivitet, särskilt när du har stora mängder data och olika datatyper.
Risker för datakorruption: Felaktig dataverifiering och övervakning medför en risk för att data skadas, vilket kan äventyra datasjöns integritet.
Problem med kvalitetskontroll: Korrekt datakvalitet är en utmaning på grund av de olika datakällorna och formaten. Du måste implementera strikta metoder för datastyrning.
Prestandaproblem: Frågeprestanda kan försämras när datasjön växer, så du måste optimera strategier för lagring och bearbetning.
Teknikval
När du skapar en omfattande datasjölösning i Azure bör du tänka på följande tekniker:
Azure Data Lake Storage kombinerar Azure Blob Storage med data lake-funktioner, vilket ger Apache Hadoop-kompatibel åtkomst, hierarkiska namnområdesfunktioner och förbättrad säkerhet för effektiv stordataanalys.
Azure Databricks är en enhetlig plattform som du kan använda för att bearbeta, lagra, analysera och tjäna pengar på data. Den stöder ETL-processer, instrumentpaneler, säkerhet, datautforskning, maskininlärning och generativ AI.
Azure Synapse Analytics är en enhetlig tjänst som du kan använda för att mata in, utforska, förbereda, hantera och hantera data för omedelbara behov av business intelligence och maskininlärning. Den integreras djupt med Azure-datasjöar så att du kan köra frågor mot och analysera stora datamängder effektivt.
Azure Data Factory är en molnbaserad dataintegreringstjänst som du kan använda för att skapa datadrivna arbetsflöden för att sedan orkestrera och automatisera dataflytt och transformering.
Microsoft Fabric är en omfattande dataplattform som förenar datateknik, datavetenskap, datalagerhantering, realtidsanalys och business intelligence till en enda lösning.
Deltagare
Den här artikeln underhålls av Microsoft. Det har ursprungligen skrivits av följande medarbetare.
Huvudförfattare:
- Avijit Prasad | Molnkonsult
Om du vill se icke-offentliga LinkedIn-profiler loggar du in på LinkedIn.
Nästa steg
- Vad är OneLake?
- Introduktion till Data Lake Storage
- Dokumentation om Azure Data Lake Analytics
- Utbildning: Introduktion till Data Lake Storage
- Integrering av Hadoop och Azure Data Lake Storage
- Ansluta till Data Lake Storage och Blob Storage
- Läsa in data i Data Lake Storage med Azure Data Factory