Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Azure Databricks är en enhetlig, öppen analysplattform för att skapa, distribuera, dela och underhålla data, analyser och AI-lösningar i företagsklass i stor skala. Databricks Data Intelligence Platform integreras med molnlagring och säkerhet i ditt molnkonto och hanterar och distribuerar molninfrastruktur åt dig.
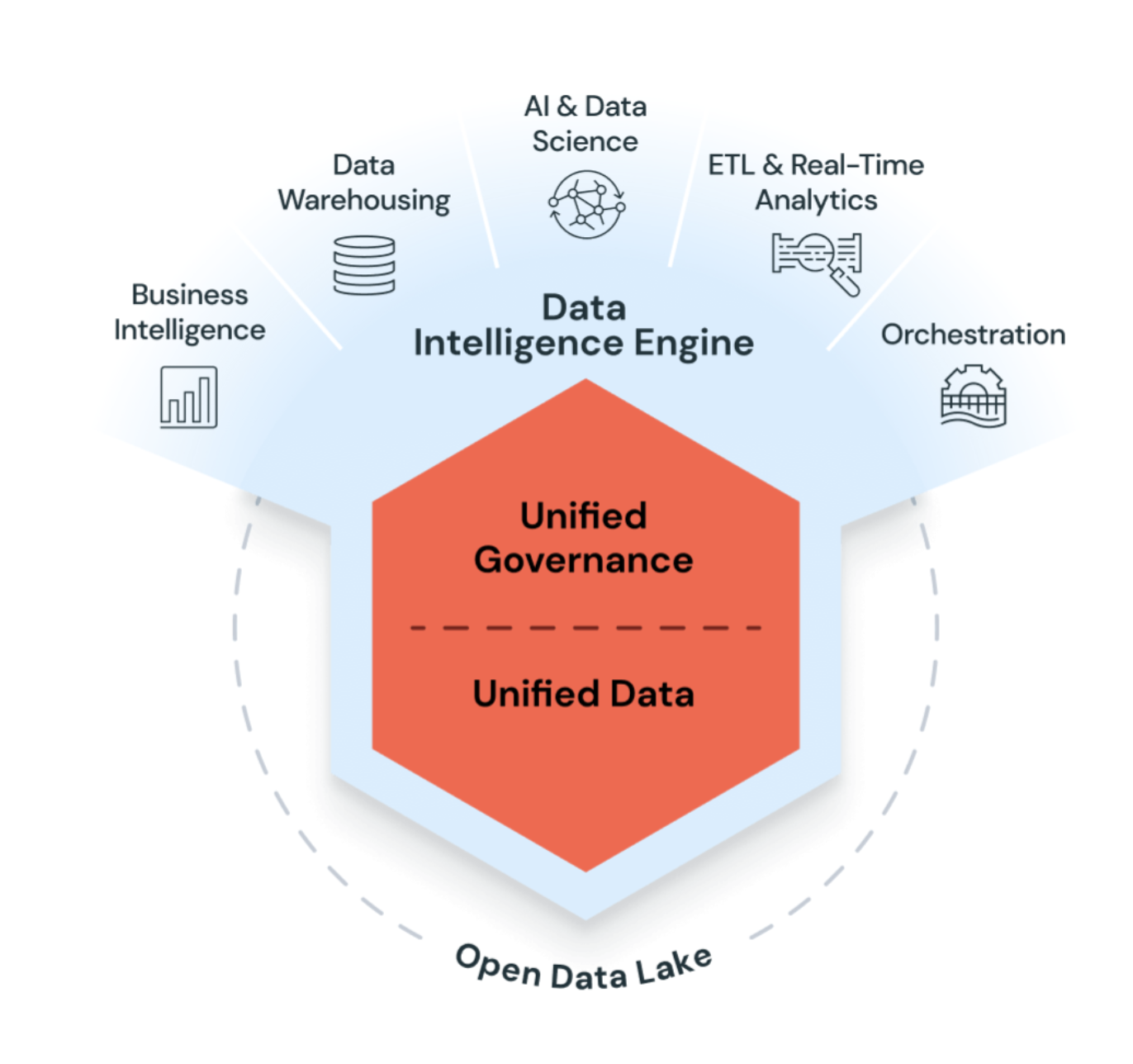
Azure Databricks använder generativ AI med data lakehouse för att förstå de unika semantiken för dina data. Sedan optimerar den automatiskt prestanda och hanterar infrastruktur för att matcha dina affärsbehov.
Bearbetning av naturligt språk lär sig ditt företags språk, så att du kan söka efter och upptäcka data genom att ställa en fråga med egna ord. Hjälp med naturligt språk hjälper dig att skriva kod, felsöka fel och hitta svar i dokumentationen.
Hanterad integrering med öppen källkod
Databricks ingår i communityn med öppen källkod och hanterar uppdateringar av integreringar med öppen källkod med Databricks Runtime-versioner. Följande tekniker är öppen källkod projekt som ursprungligen skapades av Databricks-anställda:
- Delta Lake och Delta Sharing
- MLflow
- Apache Spark och strukturerad direktuppspelning
- Redash
- Unity-katalog
Vanliga användningsfall
Följande användningsfall belyser några av de sätt som kunder använder Azure Databricks på för att utföra uppgifter som är viktiga för bearbetning, lagring och analys av data som driver viktiga affärsfunktioner och beslut.
Skapa ett företagsdatasjöhus
Data lakehouse kombinerar företagsdatalager och datasjöar för att påskynda, förenkla och förena företagsdatalösningar. Datatekniker, dataforskare, analytiker och produktionssystem kan alla använda data lakehouse som sin enda sanningskälla, vilket ger åtkomst till konsekventa data och minskar komplexiteten i att skapa, underhålla och synkronisera många distribuerade datasystem. Läs om Vad är ett data lakehouse?.
ETL och datateknik
Oavsett om du genererar instrumentpaneler eller driver program för artificiell intelligens, ska datateknik utgöra ryggraden för datacentrerade företag genom att säkerställa att data är tillgänglig, ren och lagrad i datamodeller för effektiv upptäckt och användning. Azure Databricks kombinerar kraften i Apache Spark med Delta och anpassade verktyg för att ge en oöverträffad ETL-upplevelse. Använd SQL, Python och Scala för att skapa ETL-logik och orkestrera schemalagd jobbdistribution med några få klick.
Lakeflow Spark Deklarativa Pipelines förenklar ytterligare ETL genom att intelligent hantera beroenden mellan datauppsättningar och automatiskt distribuera och skala produktionsinfrastrukturen för att säkerställa snabb och korrekt informationsleverans enligt dina specifikationer.
Azure Databricks tillhandahåller verktyg för datainmatning, inklusive Auto Loader, ett effektivt och skalbart verktyg för inkrementell och idempotent inläsning av data från molnobjektlagring och datasjöar till data lakehouse.
Maskininlärning, AI och datavetenskap
Azure Databricks-maskininlärning utökar plattformens kärnfunktioner med en uppsättning verktyg som är skräddarsydda för dataforskares och ML-teknikers behov, inklusive MLflow och Databricks Runtime for Machine Learning.
Stora språkmodeller och generativ AI
Databricks Runtime for Machine Learning innehåller bibliotek som Hugging Face Transformers som gör att du kan integrera befintliga förtränade modeller eller andra bibliotek med öppen källkod i arbetsflödet. Databricks MLflow-integreringen gör det enkelt att använda MLflow-spårningstjänsten med transformatorpipelines, modeller och bearbetningskomponenter. Integrera OpenAI-modeller eller lösningar från partner som John Snow Labs i dina Databricks-arbetsflöden.
Med Azure Databricks anpassar du en LLM för dina data för din specifika uppgift. Med stöd för verktyg med öppen källkod, till exempel Hugging Face och DeepSpeed, kan du effektivt ta en grundläggande LLM och börja träna med dina egna data för mer noggrannhet för din domän och arbetsbelastning.
Dessutom tillhandahåller Azure Databricks AI-funktioner som SQL-dataanalytiker kan använda för att komma åt LLM:er, inklusive från OpenAI, direkt i sina datapipelines och arbetsflöden. Se Berika data med AI Functions.
Datalagerhantering, analys och BI
Azure Databricks kombinerar användarvänliga UIs med kostnadseffektiva beräkningsresurser och oändligt skalbar, prisvärd lagring för att ge en kraftfull plattform för att köra analysfrågor. Administratörer konfigurerar skalbara beräkningskluster som SQL-lager, så att slutanvändarna kan köra frågor utan att behöva oroa sig för komplexiteten i arbetet i molnet. SQL-användare kan köra frågor mot data i lakehouse med SQL-frågeredigeraren eller i anteckningsböcker. Notebooks stöder Python, R och Scala utöver SQL och tillåter användare att bädda in samma visualiseringar som är tillgängliga i instrumentpaneler tillsammans med länkar, bilder och kommentarer skrivna i markdown.
Datastyrning och säker datadelning
Unity Catalog tillhandahåller en enhetlig datastyrningsmodell för data lakehouse. Molnadministratörer konfigurerar och integrerar grova åtkomstkontrollbehörigheter för Unity Catalog och sedan kan Azure Databricks-administratörer hantera behörigheter för team och enskilda användare. Behörigheter hanteras med åtkomstkontrollistor (ACL: er) via antingen användarvänliga UIs eller SQL-syntax, vilket gör det enklare för databasadministratörer att skydda åtkomsten till data utan att behöva skala på molnbaserad identitetsåtkomsthantering (IAM) och nätverk.
Unity Catalog gör det enkelt att köra säker analys i molnet och ger en ansvarsfördelning som hjälper till att begränsa den kompetens som krävs för både administratörer och slutanvändare av plattformen. Se även Vad är Unity Catalog?.
Lakehouse gör datadelning i din organisation så enkelt som att ge frågeåtkomst till en tabell eller vy. För delning utanför din säkra miljö har Unity Catalog en hanterad version av Delta Sharing.
DevOps, CI/CD och uppgiftsorkestrering
Utvecklingslivscyklerna för ETL-pipelines, ML-modeller och analysinstrumentpaneler utgör var och en sina egna unika utmaningar. Med Azure Databricks kan alla dina användare utnyttja en enda datakälla, vilket minskar duplicerade insatser och rapportering utan synkronisering. Genom att dessutom tillhandahålla en uppsättning vanliga verktyg för versionshantering, automatisering, schemaläggning, distribution av kod och produktionsresurser kan du förenkla dina kostnader för övervakning, orkestrering och åtgärder.
Jobb schemalägger Azure Databricks-notebook-filer, SQL-frågor och annan godtycklig kod. Med deklarativa Automation-paket kan du definiera, distribuera och köra Databricks-resurser, till exempel jobb och pipelines programmatiskt. Git-mappar kan du synkronisera Azure Databricks-projekt med ett antal populära git-leverantörer.
Metodtips och rekommendationer för CI/CD finns i Metodtips och rekommenderade CI/CD-arbetsflöden på Databricks. En fullständig översikt över verktyg för utvecklare finns i Utveckla på Databricks.
Realtids- och strömningsanalys
Azure Databricks utnyttjar Apache Spark Structured Streaming för att fungera med strömmande data och inkrementella dataändringar. Strukturerad strömning integreras tätt med Delta Lake, och dessa tekniker utgör grunden för både Lakeflow Spark Declarative Pipelines och Auto Loader. Se Begrepp för strukturerad direktuppspelning.
Transaktionsbearbetning online
Lakebase är en OLTP-databas (online transactional processing) som är helt integrerad med Databricks Data Intelligence Platform. Med den här fullständigt hanterade Postgres-databasen kan du skapa och hantera OLTP-databaser som lagras i Azure Databricks-hanterad lagring. Se Vad är Lakebase Provisioned?.