Azure Virtual Desktop är en omfattande tjänst för skrivbords- och appvirtualisering som körs på Microsoft Azure. Virtual Desktop hjälper till att möjliggöra en säker fjärrskrivbordsupplevelse som hjälper organisationer att stärka affärsresiliensen. Det ger förenklad hantering, Windows 10 och 11 Enterprise flera sessioner och optimeringar för Microsoft 365-applikationer för företag. Med Virtual Desktop kan du distribuera och skala dina Windows-skrivbord och appar i Azure på några minuter, vilket ger integrerade säkerhets- och efterlevnadsfunktioner som hjälper dig att skydda dina appar och data.
När du fortsätter att aktivera distansarbete för din organisation med Virtual Desktop är det viktigt att förstå dess haveriberedskapsfunktioner och metodtips. Dessa metoder stärker tillförlitligheten i olika regioner för att hålla data säkra och anställda produktiva. Den här artikeln beskriver förutsättningar för affärskontinuitet och haveriberedskap (BCDR), distributionssteg och metodtips. Du lär dig mer om alternativ, strategier och arkitekturvägledning. Innehållet i det här dokumentet gör att du kan förbereda en lyckad BCDR-plan och kan hjälpa dig att öka motståndskraften för ditt företag under planerade och oplanerade stilleståndstider.
Det finns flera typer av katastrofer och avbrott, och var och en kan ha olika effekter. Återhämtning och återställning diskuteras på djupet för både lokala och regionomfattande händelser, inklusive återställning av tjänsten i en annan fjärransluten Azure-region. Den här typen av återställning kallas geo-haveriberedskap. Det är viktigt att skapa din Virtual Desktop-arkitektur för återhämtning och tillgänglighet. Du bör ange maximal lokal återhämtning för att minska effekten av felhändelser. Den här återhämtningsförmågan minskar också kraven för att köra återställningsprocedurer. Den här artikeln innehåller också information om hög tillgänglighet och metodtips.
Mål och omfattning
Målet med den här guiden är att:
- Säkerställ maximal tillgänglighet, återhämtning och geo-haveriberedskap samtidigt som du minimerar dataförlusten för viktiga valda användardata.
- Minimera återställningstiden.
Dessa mål kallas även mål för återställningspunkt (RPO) och mål för återställningstid (RTO).
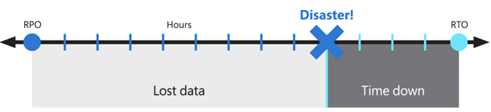
Den föreslagna lösningen ger lokal hög tillgänglighet, skydd mot ett fel i en enda tillgänglighetszon och skydd mot ett helt Azure-regionfel. Den förlitar sig på en redundant distribution i en annan eller sekundär Azure-region för att återställa tjänsten. Det är fortfarande en bra idé, men Virtual Desktop och den teknik som används för att skapa BCDR kräver inte att Azure-regioner paras ihop. Primära och sekundära platser kan vara valfri kombination av Azure-regioner, om nätverksfördröjningen tillåter det. Drift av AVD-värdpooler i flera geografiska regioner kan ge fler fördelar som inte är begränsade till BCDR.
Om du vill minska effekten av ett fel i en enskild tillgänglighetszon använder du återhämtning för att förbättra hög tillgänglighet:
- Sprid virtuella skrivbordssessionsvärdar mellan olika tillgänglighetszoner på beräkningslagret.
- Använd zonåterhämtning när det är möjligt på lagringsskiktet .
- På nätverksskiktet distribuerar du zontåliga Azure ExpressRoute- och VPN-gatewayer (virtual private network).
- För varje beroende granskar du effekten av ett avbrott i en enda zon och planerar åtgärder. Du kan till exempel distribuera Active Directory-domän styrenheter och andra externa resurser som används av Virtual Desktop-användare i flera tillgänglighetszoner.
Beroende på hur många tillgänglighetszoner du använder utvärderar du överetablering av antalet sessionsvärdar för att kompensera för förlusten av en zon. Även med (n-1) zoner tillgängliga kan du till exempel säkerställa användarupplevelse och prestanda.
Kommentar
Azure-tillgänglighetszoner är en funktion med hög tillgänglighet som kan förbättra återhämtning. Men betrakta dem inte som en haveriberedskapslösning som kan skydda mot katastrofer i hela regionen.

På grund av möjliga kombinationer av typer, replikeringsalternativ, tjänstfunktioner och tillgänglighetsbegränsningar i vissa regioner rekommenderas Cloud Cache-komponenten från FSLogix att användas i stället för lagringsspecifika replikeringsmekanismer.
OneDrive beskrivs inte i den här artikeln. Mer information om redundans och hög tillgänglighet finns i SharePoint- och OneDrive-dataåterhämtning i Microsoft 365.
Under resten av den här artikeln får du lära dig mer om lösningar för de två olika typerna av virtuella skrivbordsvärdpooler. Det finns också observationer som tillhandahålls så att du kan jämföra den här arkitekturen med andra lösningar:
- Personligt: I den här typen av värdpool har en användare en permanent tilldelad sessionsvärd som aldrig bör ändras. Eftersom den är personlig kan den här virtuella datorn lagra användardata. Antagandet är att använda replikerings- och säkerhetskopieringstekniker för att bevara och skydda tillståndet.
- Pool: Användare tilldelas tillfälligt en av de tillgängliga virtuella sessionsvärddatorerna från poolen, antingen direkt via en skrivbordsprogramgrupp eller med hjälp av fjärrappar. Virtuella datorer är tillståndslösa och användardata och profiler lagras i extern lagring eller OneDrive.
Kostnadskonsekvenser diskuteras, men det primära målet är att tillhandahålla en effektiv distribution av geo-haveriberedskap med minimal dataförlust. Mer information om BCDR finns i följande resurser:
Förutsättningar
Distribuera kärninfrastrukturen och se till att den är tillgänglig i den primära och sekundära Azure-regionen. Om du vill ha vägledning om nätverkstopologin kan du använda nätverkstopologin och anslutningsmodellerna för Azure Cloud Adoption Framework:
I båda modellerna distribuerar du den primära Virtual Desktop-värdpoolen och den sekundära haveriberedskapsmiljön i olika virtuella ekernätverk och ansluter dem till varje hubb i samma region. Placera en hubb på den primära platsen, en hubb på den sekundära platsen och upprätta sedan anslutningen mellan de två.
Hubben tillhandahåller så småningom hybridanslutning till lokala resurser, brandväggstjänster, identitetsresurser som Active Directory-domän styrenheter och hanteringsresurser som Log Analytics.
Du bör överväga alla verksamhetsspecifika program och beroende resurstillgänglighet när du redväxar till den sekundära platsen.
Kontrollplan affärskontinuitet och haveriberedskap
Virtual Desktop erbjuder affärskontinuitet och haveriberedskap för kontrollplanet för att bevara kundmetadata vid avbrott. Azure-plattformen hanterar dessa data och processer och användarna behöver inte konfigurera eller köra något.

Virtual Desktop är utformat för att vara motståndskraftigt mot fel i enskilda komponenter och för att snabbt kunna återställa från fel. När ett avbrott inträffar i en region redundansväxlar tjänstinfrastrukturkomponenterna till den sekundära platsen och fortsätter att fungera som vanligt. Du kan fortfarande komma åt tjänstrelaterade metadata och användarna kan fortfarande ansluta till tillgängliga värdar. Slutanvändaranslutningar är online om klientmiljön eller värdarna förblir tillgängliga. Dataplatser för Virtual Desktop skiljer sig från platsen för värdpoolsessionens värddistribution av virtuella datorer (VM). Det går att hitta Virtual Desktop-metadata i en av de regioner som stöds och sedan distribuera virtuella datorer på en annan plats. Mer information finns i artikeln om arkitektur och motståndskraft för Virtual Desktop-tjänsten.
Aktiv-aktiv jämfört med aktiv-passiv
Om olika uppsättningar användare har olika BCDR-krav rekommenderar Microsoft att du använder flera värdpooler med olika konfigurationer. Användare med ett verksamhetskritiskt program kan till exempel tilldela en fullständigt redundant värdpool med funktioner för geo-haveriberedskap. Utvecklings- och testanvändare kan dock använda en separat värdpool utan haveriberedskap alls.
För varje virtuell skrivbordsvärdpool kan du basera DIN BCDR-strategi på en aktiv-aktiv eller aktiv-passiv modell. Det här scenariot förutsätter att samma uppsättning användare på en geografisk plats hanteras av en specifik värdpool.
- Aktiv-aktiv
För varje värdpool i den primära regionen distribuerar du en andra värdpool i den sekundära regionen.
Den här konfigurationen ger nästan noll RTO och RPO har en extra kostnad.
Du behöver inte en administratör för att ingripa eller redundansväxla. Under normala åtgärder ger den sekundära värdpoolen användaren virtual desktop-resurser.
Varje värdpool har egna lagringskonton (minst ett) för beständiga användarprofiler.
Du bör utvärdera svarstiden baserat på användarens fysiska plats och tillgängliga anslutningsmöjligheter. För vissa Azure-regioner, till exempel Västeuropa och Norra Europa, kan skillnaden vara försumbar vid åtkomst till antingen de primära eller sekundära regionerna. Du kan verifiera det här scenariot med hjälp av beräkningsverktyget för Azure Virtual Desktop Experience .
Användare tilldelas till olika programgrupper, till exempel DAG (Desktop Application Group) och RemoteApp Application Group (RAG) i både de primära och sekundära värdpoolerna. I det här fallet ser de duplicerade poster i sin Virtual Desktop-klientfeed. Undvik förvirring genom att använda separata Virtual Desktop-arbetsytor med tydliga namn och etiketter som återspeglar syftet med varje resurs. Informera användarna om användningen av dessa resurser.
Om du behöver lagring för att hantera FSLogix-profil- och ODFC-containrar separat använder du Cloud Cache för att säkerställa nästan noll RPO.
- Undvik profilkonflikter genom att inte tillåta användare att komma åt båda värdpoolerna samtidigt.
- På grund av det här scenariots aktiva aktiva karaktär bör du informera användarna om hur de använder dessa resurser på rätt sätt.
Kommentar
Att använda separata ODFC-containrar är ett avancerat scenario med högre komplexitet. Distribution på det här sättet rekommenderas endast i vissa specifika scenarier.
- Aktiv-passiv
- Precis som aktiv-aktiv distribuerar du en andra värdpool i den sekundära regionen för varje värdpool i den primära regionen.
- Mängden beräkningsresurser som är aktiva i den sekundära regionen minskas jämfört med den primära regionen, beroende på vilken budget som är tillgänglig. Du kan använda automatisk skalning för att ge mer beräkningskapacitet, men det kräver mer tid och Azure-kapacitet garanteras inte.
- Den här konfigurationen ger högre RTO jämfört med aktiv-aktiv-metoden, men det är billigare.
- Du behöver administratörsintervention för att köra en redundansprocedur om det uppstår ett Azure-avbrott. Den sekundära värdpoolen ger normalt inte användaren åtkomst till Virtual Desktop-resurser.
- Varje värdpool har egna lagringskonton för beständiga användarprofiler.
- Användare som använder Virtual Desktop-tjänster med optimal svarstid och prestanda påverkas endast om det uppstår ett Azure-avbrott. Du bör verifiera det här scenariot med hjälp av verktyget Azure Virtual Desktop Experience Estimator . Prestanda bör vara godtagbara, även om de försämras, för den sekundära haveriberedskapsmiljön.
- Användare tilldelas endast till en uppsättning programgrupper, till exempel skrivbords- och fjärrappar. Under normala åtgärder finns dessa appar i den primära värdpoolen. Under ett avbrott och efter en redundansväxling tilldelas användare till programgrupper i den sekundära värdpoolen. Inga duplicerade poster visas i användarens Virtual Desktop-klientflöde, de kan använda samma arbetsyta och allt är transparent för dem.
- Om du behöver lagring för att hantera FSLogix-profil och Office-containrar använder du Cloud Cache för att säkerställa nästan noll RPO.
- Undvik profilkonflikter genom att inte tillåta användare att komma åt båda värdpoolerna samtidigt. Eftersom det här scenariot är aktiv-passivt kan administratörer tillämpa det här beteendet på programgruppsnivå. Först efter en redundansprocedur kan användaren komma åt varje programgrupp i den sekundära värdpoolen. Åtkomst återkallas i den primära programgruppen för värdpoolen och omtilldelas till en programgrupp i den sekundära värdpoolen.
- Kör en redundansväxling för alla programgrupper, annars kan användare som använder olika programgrupper i olika värdpooler orsaka profilkonflikter om de inte hanteras effektivt.
- Det är möjligt att tillåta en specifik delmängd av användare att selektivt redundansväxla till den sekundära värdpoolen och tillhandahålla begränsat aktivt-aktivt beteende och testa redundansfunktionen. Det går också att redundansväxla specifika programgrupper, men du bör utbilda användarna om att inte använda resurser från olika värdpooler samtidigt.
För specifika omständigheter kan du skapa en enda värdpool med en blandning av sessionsvärdar i olika regioner. Fördelen med den här lösningen är att om du har en enda värdpool behöver du inte duplicera definitioner och tilldelningar för skrivbords- och fjärrappar. Haveriberedskap för delade värdpooler har tyvärr flera nackdelar:
- För poolade värdpooler går det inte att tvinga en användare till en sessionsvärd i samma region.
- En användare kan få högre svarstid och lägre prestanda vid anslutning till en sessionsvärd i en fjärrregion.
- Om du behöver lagring för användarprofiler behöver du en komplex konfiguration för att hantera tilldelningar för sessionsvärdar i de primära och sekundära regionerna.
- Du kan använda tömningsläge för att tillfälligt inaktivera åtkomst till sessionsvärdar som finns i den sekundära regionen. Men den här metoden introducerar mer komplexitet, hanteringskostnader och ineffektiv användning av resurser.
- Du kan underhålla sessionsvärdar i offlineläge i de sekundära regionerna, men det ger mer komplexitet och hanteringskostnader.
Överväganden och rekommendationer
Allmänt
För att distribuera antingen en aktiv-aktiv eller aktiv-passiv konfiguration med hjälp av flera värdpooler och en FSLogix-molncachemekanism kan du skapa värdpoolen på samma arbetsyta eller en annan, beroende på modellen. Den här metoden kräver att du underhåller justeringen och uppdateringarna, så att båda värdpoolerna är synkroniserade och på samma konfigurationsnivå. Förutom en ny värdpool för den sekundära haveriberedskapsregionen behöver du:
- Skapa nya distinkta programgrupper och relaterade program för den nya värdpoolen.
- Återkalla användartilldelningar till den primära värdpoolen och sedan manuellt omtilldela dem till den nya värdpoolen under redundansväxlingen.
Granska alternativen affärskontinuitet och haveriberedskap för FSLogix.
- Ingen profilåterställning beskrivs inte i det här dokumentet.
- Molncache (aktiv/passiv) ingår i det här dokumentet men implementeras med samma värdpool.
- Molncachen (aktiv/aktiv) beskrivs i den återstående delen av det här dokumentet.
Det finns gränser för Virtual Desktop-resurser som måste beaktas vid utformningen av en Virtual Desktop-arkitektur. Verifiera din design baserat på gränserna för Virtual Desktop-tjänsten.
För diagnostik och övervakning är det bra att använda samma Log Analytics-arbetsyta för både den primära och sekundära värdpoolen. Med den här konfigurationen erbjuder Azure Virtual Desktop Insights en enhetlig vy över distributionen i båda regionerna.
Men om du använder ett enda loggmål kan det orsaka problem om hela den primära regionen inte är tillgänglig. Den sekundära regionen kan inte använda Log Analytics-arbetsytan i den otillgängliga regionen. Om den här situationen är oacceptabel kan följande lösningar antas:
- Använd en separat Log Analytics-arbetsyta för varje region och peka sedan virtual desktop-komponenterna för att logga mot den lokala arbetsytan.
- Testa och granska Logs Analytics-arbetsytereplikering och redundansfunktioner.
Compute
För distributionen av båda värdpoolerna i de primära och sekundära katastrofåterställningsregionerna bör du sprida sessionsvärdens VM-flotta över flera tillgänglighetszoner. Om tillgänglighetszoner inte är tillgängliga i den lokala regionen kan du använda en tillgänglighetsuppsättning för att göra din lösning mer elastisk än med en standarddistribution.
Den gyllene avbildningen som du använder för distribution av värdpooler i den sekundära haveriberedskapsregionen bör vara samma som du använder för den primära. Du bör lagra avbildningar i Azure Compute-galleriet och konfigurera flera avbildningsrepliker på både den primära och den sekundära platsen. Varje avbildningsreplik kan upprätthålla en parallell distribution av ett maximalt antal virtuella datorer och du kan kräva mer än en baserat på önskad distributionsbatchstorlek. Mer information finns i Lagra och dela avbildningar i ett Azure Compute-galleri.
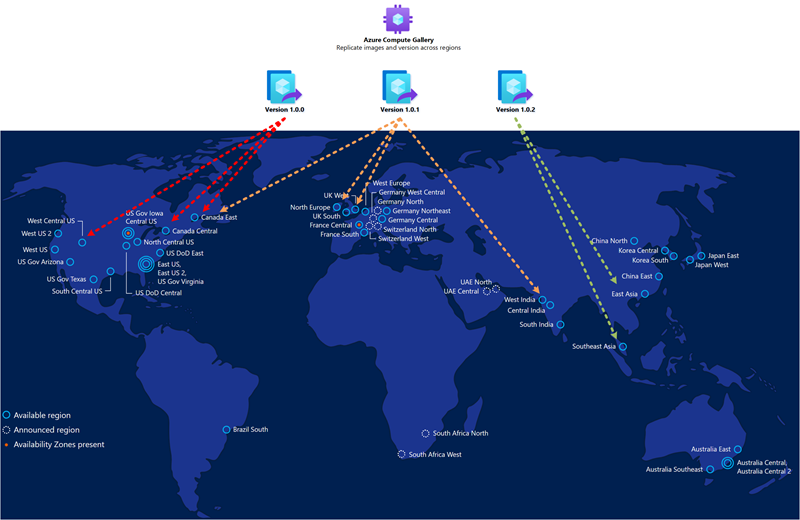
Azure Compute-galleriet är inte en global resurs. Vi rekommenderar att du har minst ett sekundärt galleri i den sekundära regionen. I den primära regionen skapar du ett galleri, en avbildningsdefinition för virtuella datorer och en vm-avbildningsversion. Skapa sedan samma objekt även i den sekundära regionen. När du skapar vm-avbildningsversionen finns det möjlighet att kopiera avbildningsversionen för den virtuella datorn som skapats i den primära regionen genom att ange galleriet, definitionen av VM-avbildningen och vm-avbildningsversionen som används i den primära regionen. Azure kopierar avbildningen och skapar en lokal vm-avbildningsversion. Du kan köra den här åtgärden med hjälp av Azure Portal eller Azure CLI-kommandot enligt beskrivningen nedan:
Alla virtuella sessionsvärddatorer på de sekundära haveriberedskapsplatserna måste inte vara aktiva och köras hela tiden. Du måste först skapa ett tillräckligt antal virtuella datorer och därefter använda en autoskalningsmekanism som skalningsplaner. Med dessa mekanismer är det möjligt att underhålla de flesta beräkningsresurser i ett offline- eller frigjort tillstånd för att minska kostnaderna.
Det går också att använda automatisering för att skapa sessionsvärdar i den sekundära regionen endast när det behövs. Den här metoden optimerar kostnaderna, men beroende på vilken mekanism du använder kan det kräva en längre RTO. Den här metoden tillåter inte redundanstester utan en ny distribution och tillåter inte selektiv redundans för specifika användargrupper.

Kommentar
Du måste aktivera varje virtuell sessionsvärd i några timmar minst en gång var 90:e dag för att uppdatera den autentiseringstoken som behövs för att ansluta till kontrollplanet för virtuellt skrivbord. Du bör också rutinmässigt tillämpa säkerhetskorrigeringar och programuppdateringar.
- Att ha sessionsvärdar offline eller frigjorda, tillstånd i den sekundära regionen garanterar inte att kapaciteten är tillgänglig vid en primär regionomfattande katastrof. Det gäller även om nya sessionsvärdar distribueras på begäran vid behov och med Site Recovery-användning . Beräkningskapacitet kan endast garanteras om de relaterade resurserna redan är allokerade och aktiva.
Viktigt!
Azure-reservationer ger inte garanterad kapacitet i regionen.
För användningsscenarier för Cloud Cache rekommenderar vi att du använder Premium-nivån för hanterade diskar.
Storage
I den här guiden använder du minst två separata lagringskonton för varje Virtual Desktop-värdpool. En är för FSLogix-profilcontainern och en är för Office-containerdata. Du behöver också ytterligare ett lagringskonto för MSIX-paket . Följande gäller:
- Du kan använda Azure Files-resursen och Azure NetApp Files som lagringsalternativ. Information om hur du jämför alternativen finns i lagringsalternativen för FSLogix-container.
- Azure Files-resursen kan ge zonåterhämtning med hjälp av alternativet zonredundant lagringsåterhämtning (ZRS) om den är tillgänglig i regionen.
- Du kan inte använda geo-redundant lagringsfunktion i följande situationer:
- Du behöver en region som inte har ett par. Regionparen för geo-redundant lagring är fasta och kan inte ändras.
- Du använder Premium-nivån.
- RPO och RTO är högre jämfört med FSLogix Cloud Cache-mekanismen.
- Det är inte lätt att testa redundans och återställning efter fel i en produktionsmiljö.
- Azure NetApp Files kräver fler överväganden:
- Zonredundans är ännu inte tillgängligt. Om återhämtningskravet är viktigare än prestanda använder du Azure Files-resursen.
- Azure NetApp Files kan vara zonindelad, dvs. kunder kan bestämma i vilken (enskild) Azure-tillgänglighetszon som ska allokeras.
- Replikering mellan zoner kan upprättas på volymnivå för att ge zonåterhämtning, men replikeringen sker asynkron och kräver manuell redundans. Den här processen kräver ett mål för återställningspunkt (RPO) och mål för återställningstid (RTO) som är större än noll. Innan du använder den här funktionen bör du granska kraven och övervägandena för replikering mellan zoner.
- Du kan använda Azure NetApp Files med zonredundant VPN och ExpressRoute-gatewayer, om standardnätverksfunktionen används, som du kan använda för nätverksåterhämtning. Mer information finns i Nätverkstopologier som stöds.
- Azure Virtual WAN stöds när det används tillsammans med standardnätverk i Azure NetApp Files. Mer information finns i Nätverkstopologier som stöds.
- Azure NetApp Files har en replikeringsmekanism mellan regioner. Följande överväganden gäller:
- Den är inte tillgänglig i alla regioner.
- Replikering mellan regioner för Azure NetApp Files-volymer kan skilja sig från Azure Storage-regionpar.
- Det kan inte användas samtidigt med replikering mellan zoner
- Redundansväxling är inte transparent och återställning efter fel kräver omkonfiguration av lagring.
- Gränser
- Det finns gränser för storlek, indata-/utdataåtgärder per sekund (IOPS), bandbredds-Mbit/s för både Azure Files-resurs och Azure NetApp Files-lagringskonton och volymer. Om det behövs kan du använda mer än en för samma värdpool i Virtual Desktop med hjälp av inställningarna per grupp i FSLogix. Den här konfigurationen kräver dock mer planering och konfiguration.
Lagringskontot som du använder för MSIX-programpaket bör skilja sig från de andra kontona för profil- och Office-containrar. Följande alternativ för geo-haveriberedskap är tillgängliga:
- Ett lagringskonto med geo-redundant lagring aktiverat i den primära regionen
- Den sekundära regionen är fast. Det här alternativet är inte lämpligt för lokal åtkomst om det finns redundans för lagringskontot.
- Två separata lagringskonton, ett i den primära regionen och ett i den sekundära regionen (rekommenderas)
- Använd zonredundant lagring för minst den primära regionen.
- Varje värdpool i varje region har lokal lagringsåtkomst till MSIX-paket med låg svarstid.
- Kopiera MSIX-paket två gånger på båda platserna och registrera paketen två gånger i båda värdpoolerna. Tilldela användare till programgrupperna två gånger.
FSLogix
Microsoft rekommenderar att du använder följande FSLogix-konfiguration och funktioner:
Om innehållet i profilcontainern måste ha separat BCDR-hantering och har olika krav jämfört med Office-containern bör du dela dem.
- Office Container har endast cachelagrat innehåll som kan återskapas eller fyllas i från källan om det uppstår en katastrof. Med Office Container kanske du inte behöver behålla säkerhetskopior, vilket kan minska kostnaderna.
- När du använder olika lagringskonton kan du bara aktivera säkerhetskopior i profilcontainern. Eller så måste du ha olika inställningar som kvarhållningsperiod, lagring som används, frekvens och RTO/RPO.
Cloud Cache är en FSLogix-komponent där du kan ange flera lagringsplatser för profiler och asynkront replikera profildata, allt utan att förlita dig på några underliggande mekanismer för lagringsreplikering. Om den första lagringsplatsen misslyckas eller inte kan nås redundansväxlar Cloud Cache automatiskt för att använda den sekundära och lägger effektivt till ett återhämtningslager. Använd Cloud Cache för att replikera både profil- och Office-containrar mellan olika lagringskonton i de primära och sekundära regionerna.
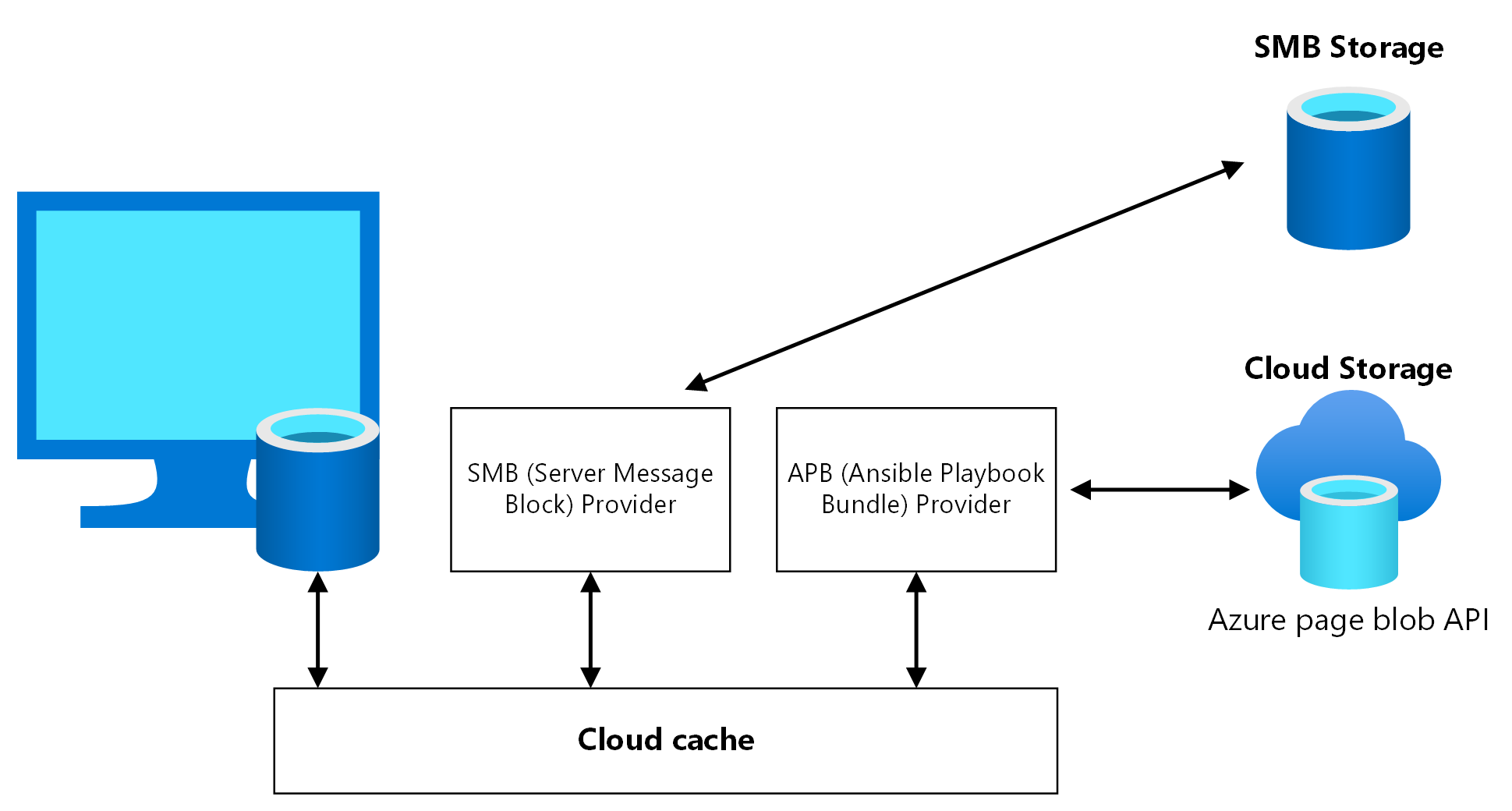
Du måste aktivera Cloud Cache två gånger i sessionsvärdens VM-register, en gång för profilcontainern och en gång för Office Container. Det är möjligt att inte aktivera Cloud Cache for Office Container, men om du inte aktiverar det kan det orsaka en felaktig datajustering mellan den primära och den sekundära haveriberedskapsregionen om det sker redundans och återställning efter fel. Testa det här scenariot noggrant innan du använder det i produktion.
Cloud Cache är kompatibelt med inställningar för både profildelning och per grupp . per grupp kräver noggrann design och planering av active directory-grupper och medlemskap. Du måste se till att varje användare ingår i exakt en grupp och att gruppen används för att ge åtkomst till värdpooler.
Parametern CCDLocations som anges i registret för värdpoolen i den sekundära haveriberedskapsregionen återställs i ordning jämfört med inställningarna i den primära regionen. Mer information finns i Självstudie: Konfigurera Cloud Cache för att omdirigera profilcontainrar eller kontorscontainer till flera leverantörer.
Dricks
Den här artikeln fokuserar på ett specifikt scenario. Ytterligare scenarier beskrivs i alternativ med hög tillgänglighet för alternativ för FSLogix och affärskontinuitet och haveriberedskap för FSLogix.

I följande exempel visas en Cloud Cache-konfiguration och relaterade registernycklar:
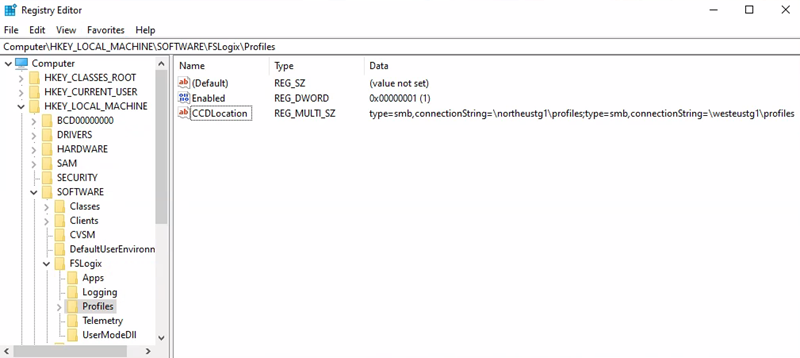
Primär region = Europa, norra
Profilcontainerlagringskonto URI = \northeustg1\profiles
- Registernyckelsökväg = HKEY_LOCAL_MACHINE > SOFTWARE > FSLogix-profiler >
- CCDLocations-värde = type=smb,connectionString=\northeustg1\profiles; type=smb,connectionString=\westeustg1\profiles
Kommentar
Om du tidigare har laddat ned FSLogix-mallarna kan du utföra samma konfigurationer via Active Directory grupprincip-hanteringskonsolen. Mer information om hur du konfigurerar grupprincip-objektet för FSLogix finns i guiden Använd FSLogix grupprincip Template Files.
Office container storage account URI = \northeustg2\odcf
Registernyckelsökväg = HKEY_LOCAL_MACHINE > SOFTWARE >Policy > FSLogix > ODFC
CCDLocations-värde = type=smb,connectionString=\northeustg2\odfc; type=smb,connectionString=\westeustg2\odfc
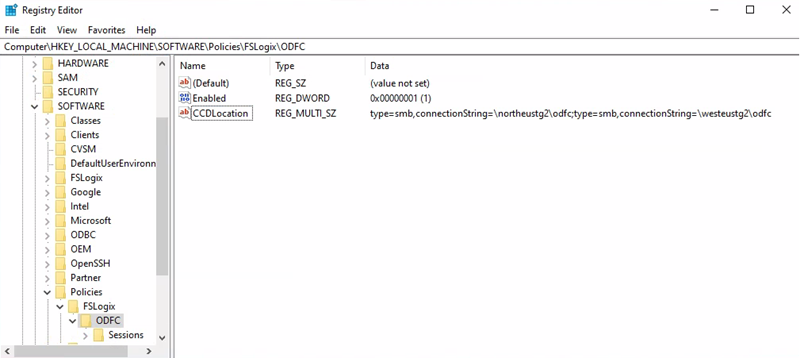


Kommentar
I skärmbilderna ovan rapporteras inte alla rekommenderade registernycklar för FSLogix och Cloud Cache, för korthet och enkelhet. Mer information finns i FSLogix-konfigurationsexempel.
Sekundär region = Europa, västra
- Profilcontainerlagringskonto URI = \westeustg1\profiles
- Registernyckelsökväg = HKEY_LOCAL_MACHINE > SOFTWARE > FSLogix-profiler >
- CCDLocations-värde = type=smb,connectionString=\westeustg1\profiles; type=smb,connectionString=\northeustg1\profiles
- Office container storage account URI = \westeustg2\odcf
- Registernyckelsökväg = HKEY_LOCAL_MACHINE > SOFTWARE >Policy > FSLogix > ODFC
- CCDLocations value = type=smb,connectionString=\westeustg2\odfc; type=smb,connectionString=\northeustg2\odfc
Cloud Cache-replikering
Konfigurations- och replikeringsmekanismerna för Cloud Cache garanterar profildatareplikering mellan olika regioner med minimal dataförlust. Eftersom samma användarprofilfil bara kan öppnas i ReadWrite-läge med en process bör samtidig åtkomst undvikas, vilket innebär att användarna inte bör öppna en anslutning till båda värdpoolerna samtidigt.

Ladda ned en Visio-fil med den här arkitekturen.
Dataflöde
En Virtual Desktop-användare startar Virtual Desktop-klienten och öppnar sedan ett publicerat skrivbords- eller fjärrappprogram som tilldelats till den primära regionvärdpoolen.
FSLogix hämtar användarprofilen och Office-containrarna och monterar sedan den underliggande lagrings-VHD/X från lagringskontot som finns i den primära regionen.
Samtidigt initierar Cloud Cache-komponenten replikering mellan filerna i den primära regionen och filerna i den sekundära regionen. För den här processen hämtar Cloud Cache i den primära regionen ett exklusivt läs-skrivlås på dessa filer.
Samma Virtual Desktop-användare vill nu starta ett annat publicerat program som tilldelats den sekundära regionvärdpoolen.
FSLogix-komponenten som körs på virtual desktop-sessionsvärden i den sekundära regionen försöker montera VHD/X-filer för användarprofilen från det lokala lagringskontot. Men monteringen misslyckas eftersom dessa filer är låsta av Cloud Cache-komponenten som körs på Virtual Desktop-sessionsvärden i den primära regionen.
I standardkonfigurationen för FSLogix och Cloud Cache kan användaren inte logga in och ett fel spåras i FSLogix-diagnostikloggarna ERROR_LOCK_VIOLATION 33 (0x21).


Identitet
Ett av de viktigaste beroendena för Virtual Desktop är tillgängligheten för användaridentitet. För att få åtkomst till fullständiga virtuella fjärrskrivbord och fjärrappar från sessionsvärdarna måste användarna kunna autentisera. Microsoft Entra ID är Microsofts centraliserade molnidentitetstjänst som möjliggör den här funktionen. Microsoft Entra-ID används alltid för att autentisera användare för Virtual Desktop. Sessionsvärdar kan anslutas till samma Microsoft Entra-klientorganisation eller till en Active Directory-domän med hjälp av Active Directory-domän Services (AD DS) eller Microsoft Entra Domain Services, vilket ger dig ett urval av flexibla konfigurationsalternativ.
Microsoft Entra ID
- Det är en global tjänst med flera regioner och elastiska tjänster med hög tillgänglighet. Ingen annan åtgärd krävs i den här kontexten som en del av en BCDR-plan för Virtual Desktop.
Active Directory Domain Services
- För att Active Directory-domän Services ska vara motståndskraftiga och mycket tillgängliga, även om det uppstår en regionomfattande katastrof, bör du distribuera minst två domänkontrollanter (DCs) i den primära Azure-regionen. Dessa domänkontrollanter bör finnas i olika tillgänglighetszoner om möjligt, och du bör säkerställa korrekt replikering med infrastrukturen i den sekundära regionen och så småningom lokalt. Du bör skapa minst en domänkontrollant till i den sekundära regionen med globala katalog- och DNS-roller. Mer information finns i Distribuera Active Directory-domän Services (AD DS) i ett virtuellt Azure-nätverk.
Microsoft Entra Connect
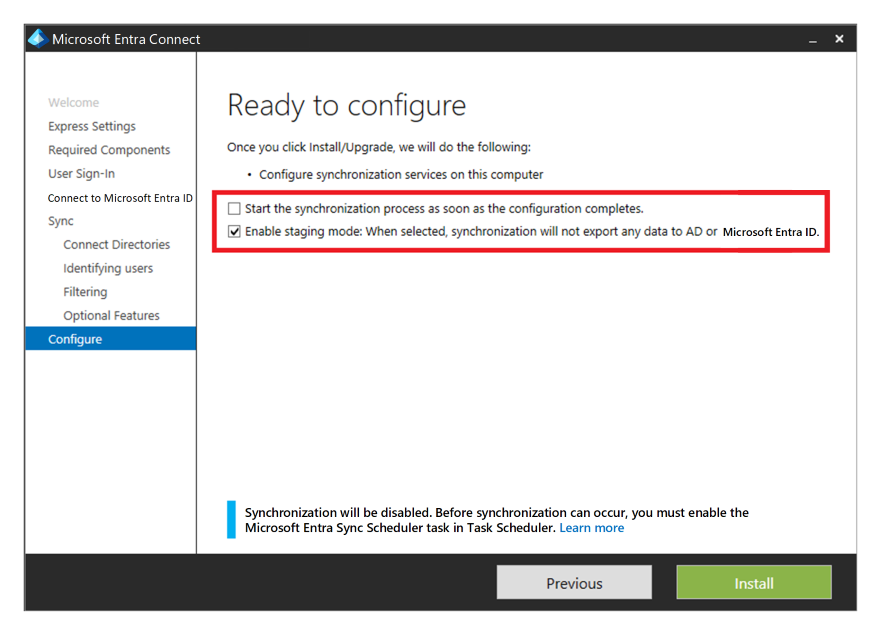
Om du använder Microsoft Entra-ID med Active Directory-domän Services och sedan Microsoft Entra Connect för att synkronisera användaridentitetsdata mellan Active Directory-domän Services och Microsoft Entra-ID bör du överväga återhämtning och återställning av den här tjänsten för skydd mot en permanent katastrof.
Du kan tillhandahålla hög tillgänglighet och haveriberedskap genom att installera en andra instans av tjänsten i den sekundära regionen och aktivera mellanlagringsläge.
Om det finns en återställning måste administratören höja upp den sekundära instansen genom att ta den ur mellanlagringsläget. De måste följa samma procedur som att placera en server i mellanlagringsläge. Microsoft Entra Global Administrator-autentiseringsuppgifter krävs för att utföra den här konfigurationen.
Microsoft Entra Domain Services
- Du kan använda Microsoft Entra Domain Services i vissa scenarier som ett alternativ till Active Directory-domän Services.
- Den erbjuder hög tillgänglighet.
- Om geo-haveriberedskap finns i omfånget för ditt scenario bör du distribuera en annan replik i den sekundära Azure-regionen med hjälp av en replikuppsättning. Du kan också använda den här funktionen för att öka hög tillgänglighet i den primära regionen.
Arkitekturdiagram
Personlig värdpool

Ladda ned en Visio-fil med den här arkitekturen.
Poolad värdpool

Ladda ned en Visio-fil med den här arkitekturen.
Redundans och återställning efter fel
Scenario för personlig värdpool
Kommentar
Endast den aktiva-passiva modellen beskrivs i det här avsnittet– en aktiv-aktiv kräver inte någon redundans eller administratörsintervention.
Redundansväxling och återställning efter fel för en personlig värdpool skiljer sig, eftersom det inte finns någon molncache och extern lagring som används för profil- och Office-containrar. Du kan fortfarande använda FSLogix-teknik för att spara data i en container från sessionsvärden. Det finns ingen sekundär värdpool i haveriberedskapsregionen, så du behöver inte skapa fler arbetsytor och Virtual Desktop-resurser för att replikera och justera. Du kan använda Site Recovery för att replikera virtuella sessionsvärddatorer.
Du kan använda Site Recovery i flera olika scenarier. För Virtual Desktop använder du arkitekturen för haveriberedskap mellan Azure och Azure i Azure Site Recovery.
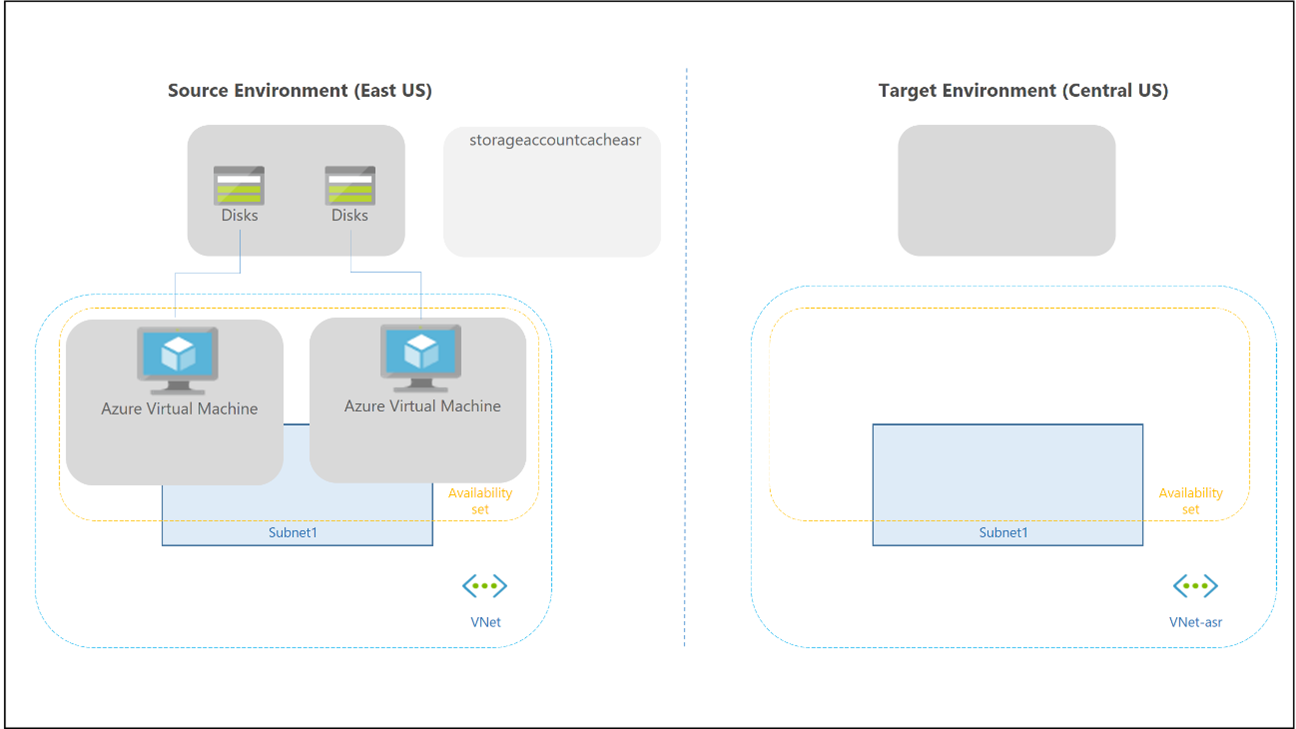
Följande överväganden och rekommendationer gäller:
- Site Recovery-redundansväxlingen är inte automatisk – en administratör måste utlösa den med hjälp av Azure Portal eller Powershell/API.
- Du kan skripta och automatisera hela Site Recovery-konfigurationen och -åtgärderna med hjälp av PowerShell.
- Site Recovery har en deklarerad RTO i sitt serviceavtal (SLA). För det mesta kan Site Recovery redundansväxla virtuella datorer inom några minuter.
- Du kan använda Site Recovery med Azure Backup. Mer information finns i Support för att använda Site Recovery med Azure Backup.
- Du måste aktivera Site Recovery på VM-nivå eftersom det inte finns någon direkt integrering i portalen för Virtuellt skrivbord. Du måste också utlösa redundans och återställning efter fel på den enskilda virtuella datorns nivå.
- Site Recovery tillhandahåller redundanstestfunktion i ett separat undernät för allmänna virtuella Azure-datorer. Använd inte den här funktionen för virtuella Virtual Desktop-datorer eftersom du skulle ha två identiska Virtual Desktop-sessionsvärdar som anropar tjänstkontrollplanet samtidigt.
- Site Recovery underhåller inte tillägg för virtuella datorer under replikeringen. Om du aktiverar några anpassade tillägg för virtuella värddatorer för Virtual Desktop-sessioner måste du återaktivera tilläggen efter redundansväxling eller återställning efter fel. De inbyggda tilläggen för Virtual Desktop joindomain och Microsoft.PowerShell.DSC används endast när en virtuell sessionsvärd skapas. Det är säkert att förlora dem efter en första redundansväxling.
- Se till att granska supportmatrisen för haveriberedskap för virtuella Azure-datorer mellan Azure-regioner och kontrollera krav, begränsningar och kompatibilitetsmatrisen för Haveriberedskapsscenariot för Site Recovery Azure-till-Azure, särskilt operativsystemversionerna som stöds.
- När du redundansväxlar en virtuell dator från en region till en annan startar den virtuella datorn i målregionen för haveriberedskap i ett oskyddat tillstånd. Återställning efter fel är möjlig, men användaren måste återaktivera skyddet av virtuella datorer i den sekundära regionen och sedan aktivera replikering tillbaka till den primära regionen.
- Kör periodisk testning av redundans- och återställningsprocedurer. Dokumentera sedan en exakt lista över steg och återställningsåtgärder baserat på din specifika Virtual Desktop-miljö.
Scenario för poolbaserad värdpool
En av de önskade egenskaperna för en aktiv-aktiv haveriberedskapsmodell är att administratörsintervention inte krävs för att återställa tjänsten om det uppstår ett avbrott. Redundansprocedurer bör endast vara nödvändiga i en aktiv-passiv arkitektur.
I en aktiv-passiv modell bör den sekundära haveriberedskapsregionen vara inaktiv, med minimala resurser konfigurerade och aktiva. Konfigurationen bör hållas i linje med den primära regionen. Om det sker en redundansväxling sker omtilldelningar för alla användare till alla skrivbords- och programgrupper för fjärrappar i den sekundära värdpoolen för haveriberedskap samtidigt.
Det är möjligt att ha en aktiv-aktiv modell och partiell redundans. Om värdpoolen endast används för att tillhandahålla skrivbords- och programgrupper kan du partitionera användarna i flera active directory-grupper som inte överlappar varandra och tilldela om gruppen till skrivbords- och programgrupper i värdpoolerna för primär eller sekundär haveriberedskap. En användare bör inte ha åtkomst till båda värdpoolerna samtidigt. Om det finns flera programgrupper och program kan de användargrupper som du använder för att tilldela användare överlappa varandra. I det här fallet är det svårt att implementera en aktiv-aktiv strategi. När en användare startar en fjärrapp i den primära värdpoolen läses användarprofilen in av FSLogix på en virtuell sessionsvärd. Om du försöker göra samma sak i den sekundära värdpoolen kan det orsaka en konflikt på den underliggande profildisken.
Varning
Som standard förbjuder FSLogix-registerinställningar samtidig åtkomst till samma användarprofil från flera sessioner. I det här BCDR-scenariot bör du inte ändra det här beteendet och lämna värdet 0 för registernyckeln ProfileType.
Här är de inledande situationerna och konfigurationsantagandena:
- Värdpoolerna i den primära regionen och sekundära haveriberedskapsregionerna justeras under konfigurationen, inklusive Cloud Cache.
- I värdpoolerna erbjuds både DAG1 Desktop- och APPG2- och APPG3-fjärrappprogramgrupper till användarna.
- I värdpoolen i den primära regionen används Active Directory-användargrupperna GRP1, GRP2 och GRP3 för att tilldela användare till DAG1, APPG2 och APPG3. Dessa grupper kan ha överlappande användarmedlemskap, men eftersom modellen här använder aktiv-passiv med fullständig redundans är det inget problem.
Följande steg beskriver när en redundansväxling inträffar, antingen efter en planerad eller oplanerad haveriberedskap.
- I den primära värdpoolen tar du bort användartilldelningar av grupperna GRP1, GRP2 och GRP3 för programgrupperna DAG1, APPG2 och APPG3.
- Det finns en tvingad frånkoppling för alla anslutna användare från den primära värdpoolen.
- I den sekundära värdpoolen, där samma programgrupper är konfigurerade, måste du ge användaren åtkomst till DAG1, APPG2 och APPG3 med hjälp av grupperna GRP1, GRP2 och GRP3.
- Granska och justera kapaciteten för värdpoolen i den sekundära regionen. Här kanske du vill förlita dig på en autoskalningsplan för att automatiskt aktivera sessionsvärdar. Du kan också starta nödvändiga resurser manuellt.
Stegen och flödet för återställning efter fel är liknande och du kan köra hela processen flera gånger. Cloud Cache och konfiguration av lagringskonton säkerställer att profil- och Office-containerdata replikeras. Innan återställning efter fel kontrollerar du att konfigurationen av värdpoolen och beräkningsresurserna återställs. För lagringsdelen, om det finns dataförlust i den primära regionen, replikerar Cloud Cache profil- och Office-containerdata från den sekundära regionlagringen.
Det går också att implementera en redundanstestplan med några konfigurationsändringar, utan att påverka produktionsmiljön.
- Skapa några nya användarkonton i Active Directory för produktion.
- Skapa en ny Active Directory-grupp med namnet GRP-TEST och tilldela användare.
- Tilldela åtkomst till DAG1, APPG2 och APPG3 med hjälp av GRUPPEN GRP-TEST.
- Ge instruktioner till användare i GRUPPEN GRP-TEST för att testa program.
- Testa redundansproceduren med hjälp av GRUPPEN GRP-TEST för att ta bort åtkomsten från den primära värdpoolen och bevilja åtkomst till den sekundära haveriberedskapspoolen.
Viktiga rekommendationer:
- Automatisera redundansväxlingen med hjälp av PowerShell, Azure CLI eller något annat tillgängligt API eller verktyg.
- Testa regelbundet hela redundans- och återställningsproceduren.
- Utför en regelbunden konfigurationsjusteringskontroll för att säkerställa att värdpoolerna i den primära och sekundära katastrofregionen är synkroniserade.
Backup
Ett antagande i den här guiden är att det finns profildelning och dataseparation mellan profilcontainrar och Office-containrar. FSLogix tillåter den här konfigurationen och användningen av separata lagringskonton. När du har separata lagringskonton kan du använda olika säkerhetskopieringsprinciper.
För ODFC Container är det inte nödvändigt att säkerhetskopiera data om innehållet endast representerar cachelagrade data som kan återskapas från onlinedatalager som Microsoft 365.
Om det är nödvändigt att säkerhetskopiera Office-containerdata kan du använda ett billigare lagringsutrymme eller en annan säkerhetskopieringsfrekvens och kvarhållningsperiod.
För en personlig värdpoolstyp bör du köra säkerhetskopieringen på sessionsvärdens VM-nivå. Den här metoden gäller endast om data lagras lokalt.
Om du använder OneDrive och känd mappomdirigering kan kravet på att spara data i containern försvinna.
Kommentar
OneDrive-säkerhetskopiering beaktas inte i den här artikeln och scenariot.
Om det inte finns ett annat krav bör säkerhetskopieringen för lagringen i den primära regionen räcka. Säkerhetskopiering av haveriberedskapsmiljön används normalt inte.
För Azure Files-resurs använder du Azure Backup.
Azure NetApp Files tillhandahåller en egen inbyggd säkerhetskopieringslösning.
- Kontrollera tillgängligheten för regionens funktioner tillsammans med krav och begränsningar.
De separata lagringskonton som används för MSIX bör också omfattas av en säkerhetskopia om programpaketens lagringsplatser inte enkelt kan återskapas.
Deltagare
Den här artikeln underhålls av Microsoft. Det har ursprungligen skrivits av följande medarbetare.
Huvudsakliga författare:
- Ben Martin Baur | Molnlösningsarkitekt
- Igor Pagliai | Huvudtekniker för FastTrack för Azure (FTA)
Övriga medarbetare:
- Nelson Del Villar | Molnlösningsarkitekt, Azure Core-infrastruktur
- Jason Martinez | Teknisk författare
Nästa steg
- Haveriberedskapsplan för Virtual Desktop
- BCDR för Virtual Desktop – Cloud Adoption Framework
- Cloud Cache för att skapa återhämtning och tillgänglighet