I ett typiskt fall av onlinebedrägerier gör tjuven flera transaktioner, vilket leder till en förlust på tusentals dollar. Det är därför bedrägeriidentifiering måste ske nästan i realtid. Mer än 800 miljoner människor använder mobilappar. I takt med att antalet ökar ökar även mobilbanksbedrägerierna. Finansbranschen upplever en 100-procentig ökning av förluster som orsakas av åtkomst från mobila plattformar till 100 procent jämfört med året innan. Men det finns en lindring. Den här artikeln visar en lösning som använder Azure-teknik för att förutsäga en bedräglig mobil banktransaktion inom två sekunder. Arkitekturen som presenteras här baseras på en verklig lösning.
Utmaningar: Sällsynta fall av bedrägeri och strikta regler
De flesta mobilbedrägerier inträffar när en SIM-växlingsattack används för att kompromettera ett mobilnummer. Telefonnumret klonas och brottslingen tar emot SMS-meddelanden och samtal som skickas till offrets mobila enhet. Brottslingen får sedan inloggningsuppgifter med hjälp av social teknik, nätfiske, vishing (med hjälp av en telefon för att nätfiske) eller en infekterad nedladdad app. Med den här informationen kan brottslingen personifiera en bankkund, registrera sig för mobil åtkomst och omedelbart generera fondöverföringar och uttag.
Mobilbedrägerier är svåra att upptäcka och dyra för konsumenter och banker. Den första utmaningen är att det är sällsynt. Färre än 1 procent av alla transaktioner är bedrägliga, så det kan ta tid för en bedrägeri- eller ärendehanteringsgrupp att söka igenom potentiellt bedrägliga transaktioner för att identifiera de bedrägliga. En annan utmaning är att många lösningar för bedrägeriövervakning är beroende av regelbaserade motorer. Traditionellt sett är regelbaserade motorer effektiva för att upptäcka etablerade mönster för bedrägeriliknande transaktioner som genereras från riskfyllda IP-adresser eller flera transaktioner som genereras inom en kort period på ett nytt konto. Men regelbaserade motorer har en betydande begränsning: reglerna anpassar sig inte snabbt till nya eller föränderliga typer av attacker. De är begränsade på följande sätt:
- Identifieringen är inte i realtid, så bedrägerier identifieras efter en ekonomisk förlust.
- Reglerna är binära och begränsade. De rymmer inte komplexiteten och kombinationerna av indatavariabler som kan utvärderas. Den här begränsningen resulterar i ett stort antal falska positiva identifieringar.
- Regler hårdkodas i affärslogik. Att kurera reglerna, införliva nya datakällor eller lägga till nya bedrägerimönster kräver vanligtvis programändringar som påverkar en affärsprocess. Att sprida ändringar i en affärsprocess kan vara besvärligt och dyrt.
AI-modeller kan avsevärt förbättra bedrägeriidentifieringsfrekvensen och identifieringstiderna. Bankerna använder dessa modeller tillsammans med andra metoder för att minska förlusterna. Processen som beskrivs här baseras på tre element:
- En AI-modell som fungerar på en härledd uppsättning beteendeegenskaper
- En metod för maskininlärning
- En modellutvärderingsprocess som liknar den som används av en bedrägerihanterare för att utvärdera en portfölj
Driftkontext
För den bank som den här lösningen bygger på, i takt med att kunderna ökade användningen av digitala tjänster, fanns det en ökning av bedrägerier i hela mobilkanalen. Det var dags för banken att ompröva sin inställning till upptäckt och förebyggande av bedrägerier. Den här lösningen började med frågor som påverkade deras bedrägeriprocess och beslut:
- Vilka aktiviteter eller transaktioner är sannolikt bedrägliga?
- Vilka konton komprometteras?
- Vilka aktiviteter behöver ytterligare utrednings- och ärendehantering?
För att lösningen ska kunna leverera värde måste det finnas en tydlig förståelse för hur mobilbankbedrägerier blir uppenbara i driftsmiljön:
- Vilka typer av bedrägerier förekommer på plattformen?
- Hur checkas det in?
- Vilka är mönstren i bedrägliga aktiviteter och transaktioner?
Svaren på dessa frågor ledde till en förståelse av de typer av beteenden som kan signalera bedrägeri. Dataattribut mappades till meddelandena som samlats in från mobilprogramgatewayerna och som korrelerade med de beteenden som identifierats. Kontobeteendet som är mest relevant för att fastställa bedrägeri profilerades sedan.
I följande tabell identifieras typer av kompromisser, dataattribut som kan signalera bedrägeri och beteenden som var relevanta för banken:
| Komprometterade autentiseringsuppgifter* | Enhetskompromisser | Ekonomiska kompromisser | Icke-transaktionella kompromisser | |
|---|---|---|---|---|
| Metoder som används | Nätfiske, vishing. | SIM-växling, vishing, skadlig kod, jailbreaking, enhetsemulatorer. | Användning av kontoautentiseringsuppgifter och digitala enhets- och användaridentifierare (till exempel e-post och fysiska adresser). | Lägga till nya användare till konto, öka kort- eller kontogränserna, ändra kontoinformation och kundprofilinformation eller lösenord. |
| Data | E-post eller lösenord, kredit- eller debetkortsnummer, kundvalda eller engångs-PIN-koder. | Enhets-ID, SIM-kortnummer, geoplats och IP. | Transaktionsbelopp, överföring, uttag eller betalningsmottagare. | Kontoinformation. |
| Mönster | Ny digital kund (inte tidigare registrerad) med ett befintligt kort och EN PIN-kod. Misslyckade inloggningar för användare som inte finns eller är okända. Inloggningar under tidsramar som är ovanliga för kontot. Flera försök att ändra inloggningslösenord. |
Geografiska oegentligheter (åtkomst från en ovanlig plats). Åtkomst från flera enheter på kort tid. |
Mönster i transaktioner. Till exempel många små transaktioner som loggats för samma konto på kort tid, ibland följt av ett stort uttag. Eller betalningar, uttag eller överföringar som görs för de högsta tillåtna beloppen. Ovanlig transaktionsfrekvens. |
Mönster i inloggningar och sekvenser av aktiviteter. Till exempel flera inloggningar inom en kort tidsperiod, flera försök att ändra kontaktinformation eller lägga till enheter under en ovanlig tidsram. |
* Den vanligaste indikatorn på kompromiss. Den föregår finansiella och icke-finansiella kompromisser.
Beteendedimensionen är viktig för att identifiera mobilbedrägerier. Beteendebaserade profiler kan hjälpa dig att upprätta typiska beteendemönster för ett konto. Analys kan peka på aktivitet som verkar ligga utanför normen. Det här är några exempel på typer av beteenden som kan profileras:
- Hur många konton är associerade med enheten?
- Hur många enheter är associerade med kontot? Hur ofta tas de bort eller läggs till?
- Hur ofta loggar enheten eller kunden in?
- Hur ofta ändrar kunden lösenord?
- Vad är den genomsnittliga penningöverföringen eller uttagsbeloppet från kontot?
- Hur ofta görs uttag från kontot?
Lösningen använder en metod baserad på:
- Funktionstekniker för att skapa beteendeprofiler för kunder och konton.
- Azure Machine Learning för att skapa en modell för bedrägeriklassificering för misstänkt eller inkonsekvent kontobeteende.
- Azure-tjänster för händelsebearbetning i realtid och arbetsflöde från slutpunkt till slutpunkt.
Arkitektur på hög nivå

Ladda ned en Visio-fil med den här arkitekturen.
Dataflöde
Det finns tre arbetsströmmar i den här arkitekturen:
En händelsedriven pipeline matar in och bearbetar loggdata, skapar och underhåller beteendekontoprofiler, införlivar en modell för bedrägeriklassificering och genererar en förutsägelsepoäng. De flesta steg i den här pipelinen börjar med en Azure-funktion. Azure-funktioner används eftersom de är serverlösa, enkelt skalbara och schemalagda. Den här arbetsbelastningen kräver att miljontals inkommande mobiltransaktioner bearbetas och utvärderas för bedrägeri nästan i realtid.
En arbetsström för modellträning kombinerar lokala historiska bedrägeridata och inmatade loggdata. Den här arbetsbelastningen är batchorienterad och används för modellträning och omträning. Azure Data Factory samordnar bearbetningsstegen, inklusive:
- Uppladdning av märkta historiska bedrägeridata från lokala källor.
- Arkiv med datafunktionsuppsättningar och poänghistorik för alla transaktioner.
- Extrahering av händelser och meddelanden i ett strukturerat format för omträning och utvärdering av funktionstekniker och modeller.
- Utbildning och omträning av en bedrägerimodell via Azure Machine Learning.
Den tredje arbetsströmmen integreras med backend-affärsprocesser. Du kan använda Azure Logic Apps för att ansluta och synkronisera till ett lokalt system för att skapa ett bedrägerihanteringsärende, inaktivera kontoåtkomst eller generera en telefonkontakt.
Centralt för den här arkitekturen är datapipelinen och AI-modellen, som beskrivs mer detaljerat senare i den här artikeln.
Lösningen integreras med bankens lokala miljö med hjälp av en företagstjänstbuss (ESB) och en högpresterande nätverksanslutning.
Datapipeline och automatisering
När en brottsling har åtkomst till ett bankkonto via en mobilapp kan ekonomiska förluster inträffa på några minuter. Effektiv identifiering av bedrägeri måste ske medan brottslingen interagerar med mobilapplikationen och innan en monetär transaktion inträffar. Den tid det tar att reagera på en bedräglig transaktion påverkar direkt hur mycket ekonomisk förlust som kan förhindras. Ju tidigare identifieringen sker, desto mindre blir den ekonomiska förlusten.
Mindre än två sekunder, och helst mycket mindre, är den maximala tiden efter att en mobil bankaktivitet vidarebefordras för bearbetning som den behöver bedömas för bedrägeri. Detta är vad som måste hända under dessa två sekunder:
- Samla in en komplex JSON-händelse.
- Verifiera, autentisera, parsa och transformera JSON.
- Skapa kontofunktioner från dataattributen.
- Skicka transaktionen för slutsatsdragning.
- Hämta bedrägeripoängen.
- Synkronisera med ett system för hantering av serverdelsfall.
Svarstider och svarstider är viktiga i en lösning för bedrägeriidentifiering. Infrastrukturen som ska stödja den måste vara snabb och skalbar.
Händelsebearbetning
Telemetrihändelser från bankens mobil- och Internetprogramgatewayer formateras som JSON-filer med ett löst definierat schema. Dessa händelser strömmas som programtelemetri till Azure Event Hubs, där en Azure-funktion i en dedikerad App Service-miljön samordnar bearbetningen.
Följande diagram illustrerar de grundläggande interaktionerna för en Azure-funktion i den här infrastrukturen:
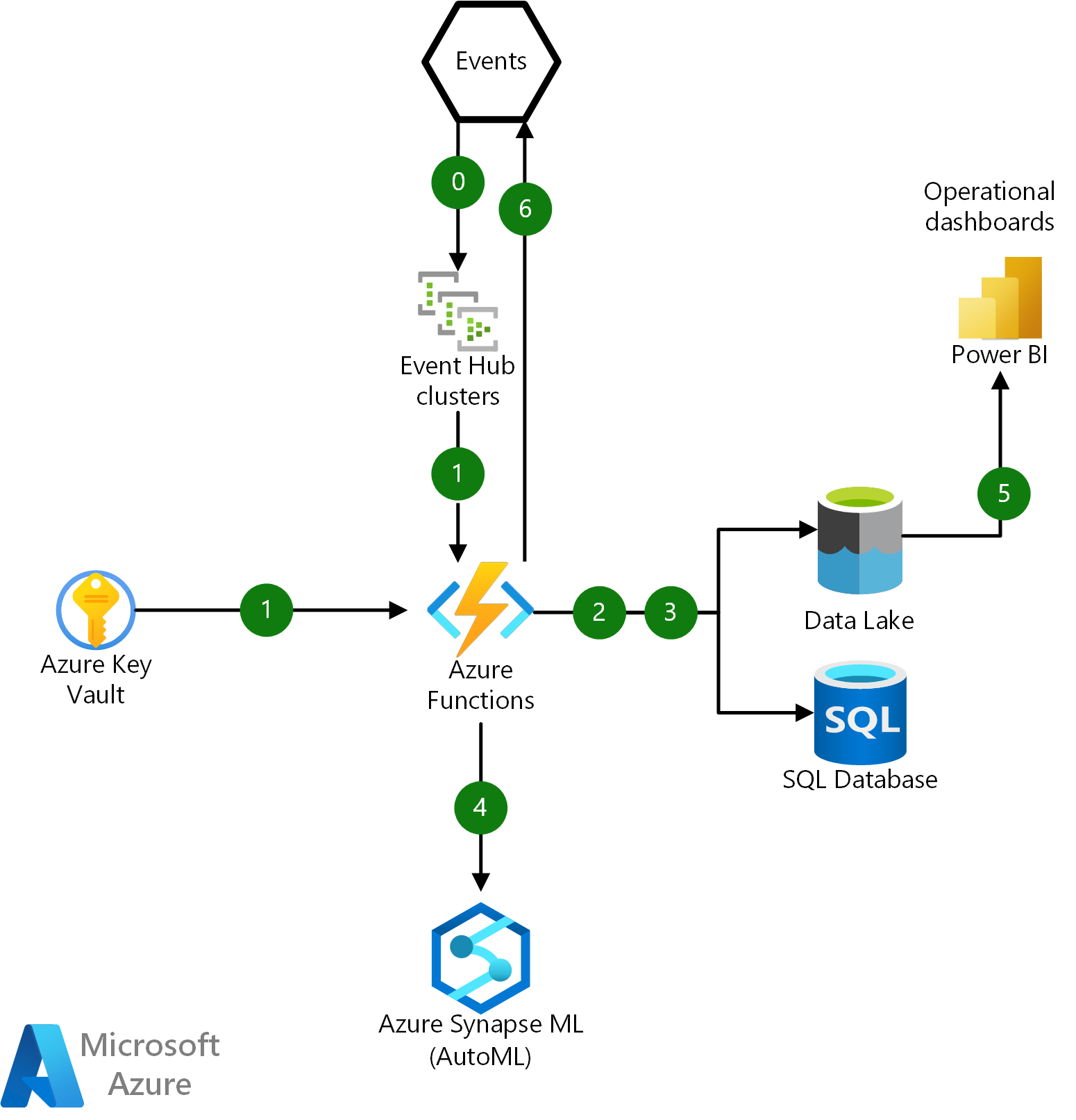
Ladda ned en Visio-fil med den här arkitekturen.
Dataflöde
- Mata in den råa JSON-händelsenyttolasten från Event Hubs och autentisera med hjälp av ett SSL-certifikat som hämtas från Azure Key Vault.
- Samordna deserialisering, parsning, lagring och loggning av råa JSON-meddelanden i Azure Data Lake och användarens ekonomiska transaktionshistorik i Azure SQL Database.
- Uppdatera och hämta användarkonto- och enhetsprofiler från SQL Database och Data Lake.
- Anropa en Azure Machine Learning-slutpunkt för att köra en förutsägelsemodell och få en bedrägeripoäng. Spara inferensresultatet till en datasjö för driftanalys.
- Anslut Power BI till Data Lake via Azure Synapse Analytics för en instrumentpanel för driftanalys i realtid.
- Publicera resultaten som en händelse till ett lokalt system för ytterligare bedrägeriutredning och hanteringsaktivitet.
Förbearbetning av data och JSON-transformering
I det verkliga scenario som den här lösningen baseras på var förbearbetning av data ett viktigt steg i formateringen av data för utveckling och träning av maskininlärningsmodellerna. Det fanns år av historiska mobil- och internetbankhändelser, inklusive transaktionsdata från application gateway-telemetrin i JSON-format. Det fanns hundratusentals filer som innehöll flera händelser som behövde deserialiseras och plattas ut och rensas för att träna maskininlärningsmodellen.
Varje programgateway producerar telemetri från en användares interaktion och samlar in information som operativsystem, metadata för mobila enheter, kontodata och transaktionsbegäranden och svar. Det fanns en variation mellan JSON-filer och attribut, och datatyperna var olika och inkonsekventa. En annan komplikation med JSON-filerna var att attribut och datatyper oväntat kunde ändras när programuppdateringar skickades ut till gatewayerna och funktionerna togs bort, ändrades eller lades till. Datatransformeringsutmaningar med scheman omfattar följande:
- En JSON-fil kan innehålla en eller flera mobiltelefoninteraktioner. Varje interaktion måste extraheras som ett separat meddelande.
- Fält kan namnges eller representeras på olika sätt.
- Tecken som nya rader eller vagnreturer bäddas in inkonsekvent i meddelanden.
- Attribut som e-postadresser kanske saknas eller är delvis formaterade.
- Det kan finnas komplexa, kapslade egenskaper och värden.
En Spark-pool används som en del av den kalla sökvägen för att bearbeta historiska JSON-filer och för att deserialisera, platta ut och extrahera enhets- och transaktionsattribut. Varje JSON-fil verifieras och parsas, och transaktionsattributen extraheras och sparas på en datasjö och partitioneras baserat på transaktionsdatumet.
Dessa attribut används senare för att skapa funktioner för bedrägeriklassificeraren. Kraften i den här lösningen bygger på möjligheten för JSON-data att standardiseras, kopplas och aggregeras med historiska data för att skapa beteendeprofiler.
Databearbetning i nära realtid och funktionalisering med SQL Database
I den här lösningen skapas händelser från flera källor, inklusive autentiseringsposter, kundinformation och demografi, transaktionsposter och logg- och aktivitetsdata från mobila enheter. SQL Database används för att utföra dataparsning i realtid, förbearbetning och funktionalisering eftersom SQL är bekant för många utvecklare.
HTAP-funktioner är nödvändiga för att hämta beteendehistorik för användarkonton för en viss enhet under de senaste sju dagarna för att beräkna funktioner i nära realtid med låg svarstid. I SQL Database används dessa HTAP-funktioner (Hybrid Transaction/Analytical Processing):
- Minnesoptimerade tabeller lagrar kontoprofiler. Minnesoptimerade tabeller har fördelar jämfört med traditionella SQL-tabeller eftersom de skapas och används i huvudminnet. Svarstiden och kostnaderna för diskåtkomst undviks. Kravet för den här lösningen är att bearbeta 300 JSON-meddelanden/sekund. Minnesoptimerade tabeller ger den här dataflödesnivån.
- Minnesoptimerade tabeller används mest effektivt från inbyggda kompilerade lagrade procedurer. Till skillnad från tolkade lagrade procedurer kompileras inbyggda lagrade procedurer när de först skapas.
- En temporal tabell är en tabell som automatiskt upprätthåller ändringshistoriken. När en rad läggs till eller uppdateras, är den versionshanterad och skriven till historiktabellen. I den här lösningen lagras kontoprofilerna i en tidstabell som har en 7-dagars kvarhållningsprincip, så rader tas bort automatiskt efter kvarhållningsperioden.
Den här metoden ger också följande fördelar:
- Åtkomst till arkiverade data för driftanalys, omträning av maskininlärningsmodeller och bedrägerivalidering
- Förenklad dataarkivering till långsiktig lagring
- Skalbarhet via horisontell partitionering av data och användning av en elastisk databas
Hantering av händelsescheman
Automatiseringen av schemahantering är en annan utmaning som måste lösas för den här lösningen. JSON är ett flexibelt och portabelt filformat, delvis på grund av att ett schema inte lagras med data. När JSON-filer måste parsas, deserialiseras och bearbetas måste ett schema som representerar JSON-strukturen kodas någonstans för att verifiera dataegenskaperna och datatyperna. Om schemat inte synkroniseras med det inkommande JSON-meddelandet misslyckas JSON-valideringen och data extraheras inte.
Utmaningen kommer när strukturen för JSON-meddelanden ändras på grund av nya programfunktioner. I den ursprungliga lösningen distribuerade banken för vilken den här lösningen skapades flera programgatewayer, var och en med sitt eget användargränssnitt, funktioner, telemetri och JSON-meddelandestruktur. När schemat var osynkroniserat med inkommande JSON-data skapade inkonsekvenserna dataförlust och bearbetningsfördröjningar för bedrägeriidentifiering.
Banken hade inget formellt schema definierat för dessa händelser, och de ständiga fluktuationerna i strukturen för JSON-filerna skapade teknisk skuld vid varje iteration av lösningen. Den här lösningen löser problemet genom att upprätta ett schema för dessa händelser och använda Azure Schema Registry. Azure Schema Registry tillhandahåller en central lagringsplats med scheman för händelser och flexibilitet för producenter och konsumentprogram att utbyta data utan att behöva hantera och dela schemat. Det enkla styrningsramverk som introduceras för återanvändbara scheman och relationen som definieras mellan scheman via grupperingskonstruktionerna (schemagrupper) kan eliminera betydande tekniska skulder, framtvinga överensstämmelse och ge bakåtkompatibilitet mellan föränderliga scheman.
Funktionsutveckling för maskininlärning
Funktioner ger ett sätt att profilera kontobeteende genom att aggregera aktivitet över olika tidsskalor. De skapas från data i programloggarna som representerar transaktions-, icke-transaktions- och enhetsbeteende. Transaktionsbeteende inkluderar monetära transaktionsaktiviteter som betalningar och uttag. Icke-transaktionellt beteende omfattar användaråtgärder som inloggningsförsök och lösenordsändringar. Enhetsbeteende omfattar aktiviteter som omfattar en mobil enhet, till exempel att lägga till eller ta bort en enhet. Funktioner används för att representera aktuellt och tidigare kontobeteende, inklusive:
- Nya användarregistreringsförsök från en specifik enhet.
- Lyckade och misslyckade inloggningsförsök.
- Begäranden om att lägga till betalare eller mottagare från tredje part.
- Begäranden om att öka konto- eller kreditkortsgränserna.
- Lösenordsändringar.
En kontoprofiltabell innehåller attribut från JSON-transaktionerna, till exempel meddelande-ID, transaktionstyp, betalningsbelopp, veckodag och timme på dagen. Aktiviteter aggregeras över flera tidsramar, till exempel en timme, en dag och sju dagar, och lagras som en beteendehistorik för varje konto. Varje rad i tabellen representerar ett enda konto. Det här är några av funktionerna:
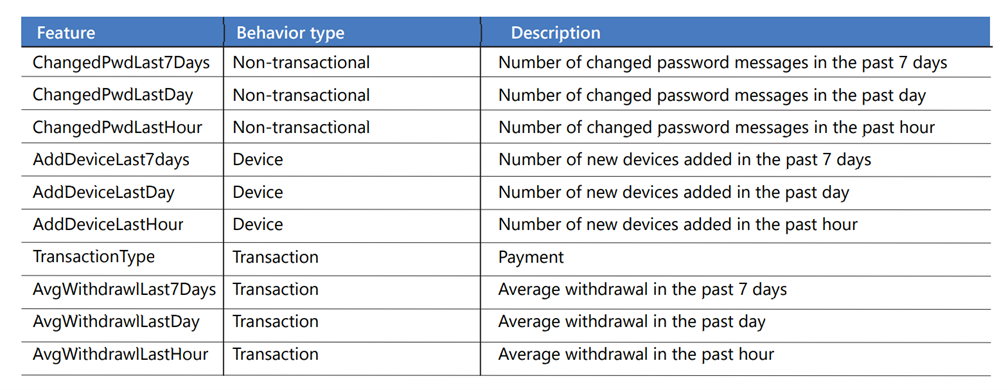
När kontofunktionerna har beräknats och profilen har uppdaterats anropar en Azure-funktion maskininlärningsmodellen för bedömning via ett REST-API för att besvara den här frågan: Vad är sannolikheten för att det här kontot är i ett bedrägeritillstånd baserat på det beteende vi har sett?
AutoML
AutoML används i lösningen eftersom den är snabb och enkel att använda. AutoML kan vara en användbar startpunkt för snabb identifiering och inlärning eftersom det inte kräver särskilda kunskaper eller installationer. Den automatiserar de tidskrävande, iterativa uppgifterna för utveckling av maskininlärningsmodeller. Dataforskare, analytiker och utvecklare kan använda den för att skapa maskininlärningsmodeller med hög skalbarhet, effektivitet och produktivitet samtidigt som modellkvaliteten bibehålls.
AutoML kan utföra följande uppgifter i en maskininlärningsprocess:
- Dela upp data i tränings- och valideringsdatauppsättningar
- Optimera träningen baserat på ett valt mått
- Utföra korsvalidering
- Generera funktioner
- Impute saknade värden
- Utföra kodning med en frekvent kodning och olika skalare
Obalans i data
Det är svårt att klassificera bedrägerier på grund av den allvarliga klassobalansen. I en bedrägeridatauppsättning finns det många fler icke-bedrägliga transaktioner än bedrägliga transaktioner. Vanligtvis innehåller mindre än 1 procent av en datamängd bedrägliga transaktioner. Om den inte åtgärdas kan den här obalansen orsaka ett trovärdighetsproblem i modellen eftersom alla transaktioner kan klassificeras som icke-bedrägliga. Modellen kan helt missa alla bedrägliga transaktioner och ändå uppnå en noggrannhetsgrad på 99 procent.
AutoML kan hjälpa till att omdistribuera data och skapa en bättre balans mellan bedrägliga och icke-bedrägliga transaktioner:
- AutoML har stöd för att lägga till en kolumn med vikter som indata, vilket gör att raderna i data viktas upp eller ned, vilket kan göra en klass mindre viktig. Algoritmerna som används av AutoML identifierar obalans när antalet exempel i minoritetsklassen är lika med eller mindre än 20 procent av antalet exempel i majoritetsklassen. Därefter kör AutoML experimentet med undersamplade data för att kontrollera om användning av klassvikter löser det här problemet och förbättrar prestandan. Om den fastställer att prestandan är bättre på grund av experimentet tillämpas åtgärden.
- Du kan använda ett mått för prestandamätning som hanterar obalanserade data bättre. Om din modell till exempel behöver vara känslig för falska negativa identifieringar använder du
recall. När modellen måste vara känslig för falska positiva identifieringar använder duprecision. Du kan också använda en F1-poäng. Den här poängen är det harmoniska medelvärdet mellanprecisionochrecall, så det påverkas inte av ett stort antal sanna positiva eller sanna negativa resultat. Du kan behöva beräkna vissa mått manuellt under testfasen.
Om du vill öka antalet transaktioner som klassificeras som bedrägliga kan du manuellt använda en teknik som kallas för syntetisk översamplingsteknik (SMOTE). SMOTE är en statistisk teknik som använder bootstrapping och k-nearest neighbor (KNN) för att producera instanser av minoritetsklassen.
Modellträning
För modellträning förväntar sig Python SDK data i ett pandas-dataramformat eller som en Azure Machine Learning-tabelldatauppsättning. Värdet som du vill förutsäga måste finnas i datauppsättningen. Du skickar y-kolumnen som en parameter när du skapar träningsjobbet.
Här är ett kodexempel med kommentarer:
data = https://automlsamplenotebookdata.blob.core.windows.net/automl-sample-notebook-data/creditcard.csv
dataset = Dataset.Tabular.from_delimited_files(data)
training_data, validation_data = dataset.random_split(percentage=0.7)
label_column_name = "Class"
automl_settings = {
"n_cross_validations": 3, # Number of cross validation splits.
"primary_metric": "average_precision_score_weighted", # This is the metric that you want to optimize.
"experiment_timeout_hours": 0.25, # Percentage of an hour you want this to run.
"verbosity": logging.INFO, # Logging info level, debug, info, warning, error, critical.
"enable_stack_ensemble": False, # VotingEnsembled is enabled by default.
}
automl_config = AutoMLConfig(
task="classification",
debug_log="automl_errors.log",
training_data=training_data,
label_column_name=label_column_name,
**automl_settings,
)
local_run = experiment.submit(automl_config, show_output=True)
I koden:
- Läs in datamängden i en Azure Machine Learning-tabelldatauppsättning eller pandas-dataram.
- Dela upp datamängden i 70 procent träning och 30 procent validering.
- Skapa en variabel för den kolumn som du vill förutsäga.
- Börja skapa AutoML-parametrarna.
- Konfigurera
AutoMLConfig.taskär den typ av maskininlärning som du vill göra:classificationellerregression. I det här fallet använder duclassification.debug_logär den plats där felsökningsinformation skrivs.training_dataär dataramen eller tabellobjektet som träningsdata läses in i.label_column_nameär den kolumn som du vill förutsäga.
- Kör maskininlärningsjobbet.
Modellutvärdering
En bra modell ger realistiska och användbara resultat. Det är en av utmaningarna med en modell för bedrägeriidentifiering. De flesta modeller för bedrägeriidentifiering ger upphov till ett binärt beslut för att avgöra om en transaktion är bedräglig. Beslutet baseras på två faktorer:
- En sannolikhetspoäng mellan 0 och 100 som returneras av klassificeringsalgoritmen
- Ett sannolikhetströskelvärde som upprättas av verksamheten. Över tröskelvärdet anses det vara bedrägligt och under tröskelvärdet betraktas det som icke-bedrägligt.
Sannolikhet är ett standardmått för alla klassificeringsmodeller. Men det är vanligtvis inte tillräckligt i ett bedrägeriscenario för beslut om huruvida ett konto ska blockeras för att förhindra ytterligare förluster.
I den här lösningen skapas mått på kontonivå och räknas in i beslutet om företaget ska agera för att blockera ett konto. Måtten på kontonivå definieras baserat på dessa branschstandardmått:
| Problem med bedrägerihanterare | Mätvärde | Beskrivning |
|---|---|---|
| Upptäcker jag bedrägerier? | Identifieringsfrekvens för bedrägerikonto (ADR) | Procentandelen identifierade bedrägerikonton i alla bedrägerikonton. |
| Hur mycket pengar sparar jag (förlustskydd)? Hur mycket kommer en fördröjning att reagera på en aviseringskostnad? | Värdeidentifieringshastighet (VDR) | Procentandelen ekonomiska besparingar, förutsatt att den aktuella bedrägeritransaktionen utlöser en blockerande åtgärd vid efterföljande transaktioner, över alla bedrägeriförluster. |
| Hur många bra kunder är jag inconveniencing? | Konto falskt positivt förhållande (AFPR) | Antalet icke-bedrägliga konton som flaggas för varje verkligt bedrägeri som upptäcks (per dag). Förhållandet mellan identifierade falska positiva konton och identifierade bedrägliga konton. |
Dessa mått är värdefulla datapunkter för en bedrägerihanterare. Chefen använder dem för att få en mer fullständig bild av kontorisken och besluta om reparation.
Modellera operationalisering och omträning
Prediktiva modeller måste uppdateras med jämna mellanrum. Med tiden, och när nya och olika data blir tillgängliga, måste en förutsägelsemodell tränas om. Detta gäller särskilt för modeller för bedrägeriidentifiering där nya mönster för brottslig verksamhet är vanliga. Det blir också nödvändigt när telemetrin från mobilprogramloggarna ändras på grund av ändringar som skickas ut till programgatewayen. För att tillhandahålla omträning i den här lösningen loggas varje transaktion som skickas för analys och motsvarande modellutvärderingsmått. Med tiden övervakas modellprestandan. När det verkar försämras utlöses ett arbetsflöde för omträning. Flera Azure-tjänster används i arbetsflödet för omträning:
Du kan använda Azure Synapse Analytics eller Azure Data Lake för att lagra historiska kunddata. Du kan använda dessa tjänster för att lagra kända bedrägliga transaktioner som laddats upp från lokala källor och data som arkiverats från Azure Machine Learning-webbtjänsten, inklusive transaktioner, förutsägelser och modellutvärderingsmått. De data som behövs för omträning lagras i det här datalagret.
Du kan använda Data Factory - eller Azure Synapse-pipelines för att samordna dataflödet och processen för omträning, inklusive:
- Extrahering av historiska data och loggfiler från lokala system.
- JSON-deserialiseringsprocessen.
- Data förbearbetningslogik.
En detaljerad information finns i Träna om och uppdatera Azure Machine Learning-modeller med Azure Data Factory.
Du kan använda blågröna distributioner i Azure Machine Learning. Information om hur du distribuerar en ny modell med minimal stilleståndstid finns i Valv distribution för onlineslutpunkter.
Komponenter
- Azure Functions tillhandahåller händelsedrivna serverlösa kodfunktioner och en utveckling från slutpunkt till slutpunkt.
- Event Hubs är en fullständigt hanterad datainmatningstjänst i realtid. Du kan använda den för att strömma miljontals händelser per sekund från valfri källa.
- Key Vault krypterar kryptografiska nycklar och andra hemligheter som används av molnappar och -tjänster.
- Azure Machine Learning är en tjänst i företagsklass för maskininlärningslivscykeln från slutpunkt till slutpunkt.
- AutoML är en process för att automatisera de tidskrävande, iterativa uppgifterna för utveckling av maskininlärningsmodeller.
- Azure SQL Database är en alltid uppdaterad, fullständigt hanterad relationsdatabastjänst som har skapats för molnet.
- Azure Synapse Analytics är en obegränsad analystjänst som sammanför dataintegrering, lagring av företagsdata och stordataanalys.
Tekniska överväganden
Om du vill välja rätt teknikkomponenter för en kontinuerligt fungerande molnbaserad infrastruktur för identifiering av bedrägerier måste du förstå aktuella och ibland vaga krav. Teknikvalen för den här lösningen baseras på överväganden som kan hjälpa dig att fatta liknande beslut.
Kunskapsuppsättningar
Överväg de aktuella tekniska kunskapsuppsättningarna för teamen som utformar, implementerar och underhåller lösningen. Moln- och AI-tekniker utökar de tillgängliga alternativen för att implementera en lösning. Om ditt team till exempel har grundläggande datavetenskapskunskaper är Azure Machine Learning ett bra val för att skapa modeller och slutpunkter. Beslutet att använda Event Hubs är ett annat exempel. Event Hubs är en hanterad tjänst som är enkel att konfigurera och underhålla. Det finns tekniska fördelar med att använda ett alternativ som Kafka, men det kan kräva utbildning.
Hybriddriftsmiljö
Distributionen för den här lösningen omfattar en lokal miljö och Azure-miljön. Tjänster, nätverk, program och kommunikation måste fungera effektivt i båda infrastrukturerna för att stödja arbetsbelastningen. Teknikbesluten omfattar:
- Hur är miljöerna integrerade?
- Vilka är kraven på nätverksanslutning mellan Azure-datacentret och den lokala infrastrukturen? Azure ExpressRoute används eftersom det ger dubbla rader, redundans och redundans. Plats-till-plats-VPN tillhandahåller inte den säkerhet eller tjänstkvalitet (QoS) som behövs för arbetsbelastningen.
- Hur integreras poäng för bedrägeriidentifiering med backend-system? Bedömningssvar bör integreras med arbetsflöden för serverdelsbedrägerier för att automatisera verifieringen av transaktioner med kunder eller andra ärendehanteringsaktiviteter. Du kan använda antingen Azure Functions eller Logic Apps för att integrera Azure-tjänster med lokala system.
Säkerhet
Att vara värd för en lösning i molnet skapar nya säkerhetsansvar. I molnet är säkerhet ett delat ansvar mellan en molnleverantör och en kundklientorganisation. Arbetsbelastningsansvaret varierar beroende på om arbetsbelastningen är en SaaS-, PaaS- eller IaaS-tjänst. Mer information finns i Delat ansvar i molnet.
Oavsett om du går mot en Nolltillit metod eller arbetar med att tillämpa regelefterlevnadskrav, måste du noggrant planera och överväga att skydda en lösning från slutpunkt till slutpunkt. För design och distribution rekommenderar vi att du antar säkerhetsprinciper som är konsekventa med en Nolltillit metod. Att anta principer som att verifiera explicit, använda åtkomst med minst behörighet och anta att intrång stärker arbetsbelastningssäkerheten.
Verifiera uttryckligen är processen för att undersöka och utvärdera olika aspekter av en åtkomstbegäran. Här är några av principerna:
- Använd en stark identitetsplattform som Microsoft Entra ID.
- Förstå säkerhetsmodellen för varje molntjänst och hur data och åtkomst skyddas.
- När det är möjligt kan du använda hanterad identitet och tjänstens huvudnamn för att styra åtkomsten till molntjänster.
- Lagra nycklar, hemligheter, certifikat och programartefakter som databassträngar, REST-slutpunkts-URL:er och API-nycklar i Key Vault.
Använd åtkomst med minsta möjliga behörighet hjälper till att säkerställa att behörigheter endast beviljas för att uppfylla specifika affärsbehov från en lämplig miljö till en lämplig klient. Här är några av principerna:
- Dela upp arbetsbelastningar genom att begränsa hur mycket åtkomst en komponent eller resurs har via rolltilldelningar eller nätverksåtkomst.
- Tillåt inte offentlig åtkomst till slutpunkter och tjänster. Använd privata slutpunkter för att skydda dina tjänster, såvida inte tjänsten kräver offentlig åtkomst.
- Använd brandväggsregler för att skydda tjänstslutpunkter eller isolera arbetsbelastningar med hjälp av virtuella nätverk.
Anta att intrång är en strategi för att vägleda design- och distributionsbeslut. Strategin är att anta att en lösning har komprometterats. Det är en metod för att bygga in motståndskraft i en arbetsbelastning genom att planera för identifiering av, svar på och reparation av ett säkerhetshot. För design- och distributionsbeslut innebär det att:
- Arbetsbelastningskomponenter isoleras och segmenteras så att en komprog av en komponent minimerar påverkan på uppströms- eller nedströmskomponenter.
- Telemetri samlas in och analyseras proaktivt för att identifiera avvikelser och potentiella hot.
- Automatisering är på plats för att identifiera, svara på och åtgärda ett hot.
Här följer några riktlinjer att tänka på:
- Kryptera vilande data och under överföring.
- Aktivera granskning för tjänster.
- Samla in och centralisera granskningsloggar och telemetri i en enda loggarbetsyta för att underlätta analys och korrelation.
- Aktivera Microsoft Defender för molnet för att söka efter potentiellt sårbara konfigurationer och ge en tidig varning om potentiella säkerhetsproblem.
Nätverk är en av de viktigaste säkerhetsfaktorerna. Som standard är Slutpunkter för Azure Synapse-arbetsytor offentliga slutpunkter. Det innebär att de kan nås från alla offentliga nätverk, så vi rekommenderar starkt att du inaktiverar offentlig åtkomst till arbetsytan. Överväg att distribuera Azure Synapse med funktionen Hanterat virtuellt nätverk aktiverat för att lägga till ett lager av isolering mellan din arbetsyta och andra Azure-tjänster. Mer information om hanterat virtuellt nätverk och andra säkerhetsfaktorer finns i Säkerhetsdokument för Azure Synapse Analytics: Nätverkssäkerhet.

Ladda ned en Visio-fil med den här arkitekturen.
Säkerhetsvägledning som är specifik för varje lösningskomponent i banklösningen ingår i följande tabell. En bra utgångspunkt finns i Azure Security Benchmark, som innehåller säkerhetsbaslinjer för var och en av de enskilda Azure-tjänsterna. Rekommendationerna för säkerhetsbaslinjen kan hjälpa dig att välja säkerhetskonfigurationsinställningar för varje tjänst.
Mer information finns i Nolltillit Guidance Center.
Skalbarhet
Lösningen måste utföra rusningstid från slutpunkt till slutpunkt. Ett arbetsflöde för direktuppspelning för hantering av miljontals händelser som anländer kontinuerligt kräver högt dataflöde. Planera att skapa ett testsystem som simulerar volymen och samtidigheten för att säkerställa att teknikkomponenterna är konfigurerade och inställda för att uppfylla nödvändiga svarstider. Skalbarhetstestning är särskilt viktigt för dessa komponenter:
- Datainmatning för att hantera samtidiga dataströmmar. I den här arkitekturen används Event Hubs eftersom flera instanser av den kan distribueras och tilldelas till olika konsumentgrupper. En utskalningsmetod är ett bättre alternativ eftersom uppskalning kan orsaka låsning. En utskalningsmetod passar också bättre om du planerar att utöka bedrägeriidentifieringen från mobil bankverksamhet till att omfatta en internetbankkanal.
- Ett ramverk för att hantera och schemalägga processflödet. Azure Functions används för att samordna arbetsflödet. För bättre dataflöde batchas meddelanden i mikrobatch och bearbetas via en enda Azure-funktion i stället för att bearbeta ett meddelande per funktionsanrop.
- En dataprocess med låg latens för att hantera parsning, förbearbetning, aggregeringar och lagring. I den verkliga lösningen som den här artikeln baseras på uppfyller funktionerna i minnesoptimerade SQL-funktioner skalbarhets- och samtidighetskrav.
- Modellbedömning för att hantera samtidiga begäranden. Med Azure Machine Learning-webbtjänster har du två alternativ för skalning:
- Välj en produktionswebbnivå för att stödja API-samtidighetsarbetsbelastningen.
- Lägg till flera slutpunkter i en webbtjänst om du behöver stöd för fler än 200 samtidiga begäranden.
Deltagare
Den här artikeln underhålls av Microsoft. Det har ursprungligen skrivits av följande medarbetare.
Huvudsakliga författare:
- Kate Baroni | Huvudkundtekniker
- Michael Hlobil | Principal Customer Engineering Manager
- Cedric Labuschagne | Teknisk programhanterare
- Frank Garofalo | Huvudkundtekniker
- Shep Sheppard | Senior Service Engineer
Annan deltagare:
- Mick Alberts | Teknisk författare
Nästa steg
- En snabb, serverlös stordatapipeline som drivs av en enda Azure-funktion
- Överväga Azure Functions för ett serverlöst dataströmningsscenario
- Nätverksöverväganden för en App Service-miljö
- Event Hubs
- Key Vault
- Azure Machine Learning