Decentralisera arbetsflödeslogik och distribuera ansvaret till andra komponenter i ett system.
Kontext och problem
Ett molnbaserat program är ofta indelat i flera små tjänster som arbetar tillsammans för att bearbeta en affärstransaktion från slutpunkt till slutpunkt. Även en enskild åtgärd (inom en transaktion) kan resultera i flera punkt-till-punkt-anrop mellan alla tjänster. Helst bör dessa tjänster vara löst kopplade. Det är svårt att utforma ett arbetsflöde som är distribuerat, effektivt och skalbart eftersom det ofta omfattar komplex kommunikation mellan tjänster.
Ett vanligt mönster för kommunikation är att använda en centraliserad tjänst eller en orkestrerare. Inkommande begäranden flödar genom orkestratorn när den delegerar åtgärder till respektive tjänster. Varje tjänst slutför bara sitt ansvar och är inte medveten om det övergripande arbetsflödet.
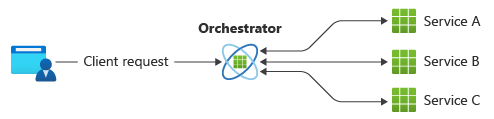
Orchestrator-mönstret implementeras vanligtvis som anpassad programvara och har domänkunskap om ansvarsområden för dessa tjänster. En fördel är att orkestratorn kan konsolidera statusen för en transaktion baserat på resultatet av enskilda åtgärder som utförs av de underordnade tjänsterna.
Det finns dock vissa nackdelar. Att lägga till eller ta bort tjänster kan bryta befintlig logik eftersom du behöver koppla om delar av kommunikationsvägen. Det här beroendet gör orchestrator-implementeringen komplex och svår att underhålla. Orchestrator kan ha en negativ inverkan på arbetsbelastningens tillförlitlighet. Under belastning kan det introducera flaskhalsar för prestanda och vara den enda felpunkten. Det kan också orsaka sammanhängande fel i de underordnade tjänsterna.
Lösning
Delegera transaktionshanteringslogik mellan tjänsterna. Låt varje tjänst bestämma och delta i kommunikationsarbetsflödet för en affärsåtgärd.
Mönstret är ett sätt att minimera beroendet av anpassad programvara som centraliserar kommunikationsarbetsflödet. Komponenterna implementerar gemensam logik när de koreografar arbetsflödet sinsemellan utan att ha direkt kommunikation med varandra.
Ett vanligt sätt att implementera koreografi är att använda en meddelandekö som buffrar begäranden tills underordnade komponenter gör anspråk på och bearbetar dem. Bilden visar hantering av begäranden via en modell för utgivare och prenumerant.
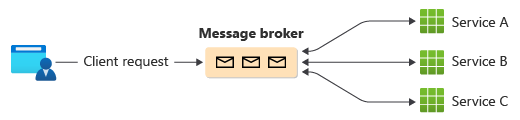
En klientbegäran placeras i kö som meddelanden i en meddelandekö.
Tjänsterna eller prenumeranten avsöker mäklaren för att avgöra om de kan bearbeta meddelandet baserat på deras implementerade affärslogik. Mäklaren kan också skicka meddelanden till prenumeranter som är intresserade av det meddelandet.
Varje prenumerationstjänst utför sin åtgärd enligt meddelandet och svarar asynkron meddelandekö med åtgärdens framgång eller misslyckande.
Om det lyckas kan tjänsten skicka tillbaka ett meddelande till samma kö eller en annan meddelandekö så att en annan tjänst kan fortsätta arbetsflödet om det behövs. Om åtgärden misslyckas fungerar meddelandekoordinatorn med andra tjänster för att kompensera åtgärden eller hela transaktionen.
Problem och överväganden
Att decentralisera orkestreraren kan orsaka problem vid hantering av arbetsflödet.
Det kan vara svårt att lämna in fel. Komponenter i ett program kan utföra atomiska uppgifter, men de kan fortfarande ha en beroendenivå. Fel i en komponent kan påverka andra, vilket kan orsaka fördröjningar i slutförandet av den övergripande begäran.
Om du vill hantera fel på ett korrekt sätt kan implementering av kompenserande transaktioner medföra komplexitet. Felhanteringslogik, till exempel kompenserande transaktioner, är också utsatt för fel.
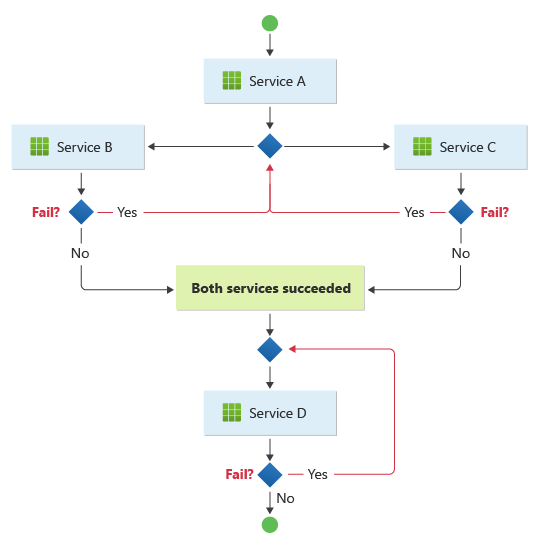
Mönstret är lämpligt för ett arbetsflöde där oberoende affärsåtgärder bearbetas parallellt. Arbetsflödet kan bli komplicerat när koreografin behöver ske i en sekvens. Till exempel kan Service D starta sin åtgärd först när Service B och Service C har slutfört sina åtgärder med framgång.
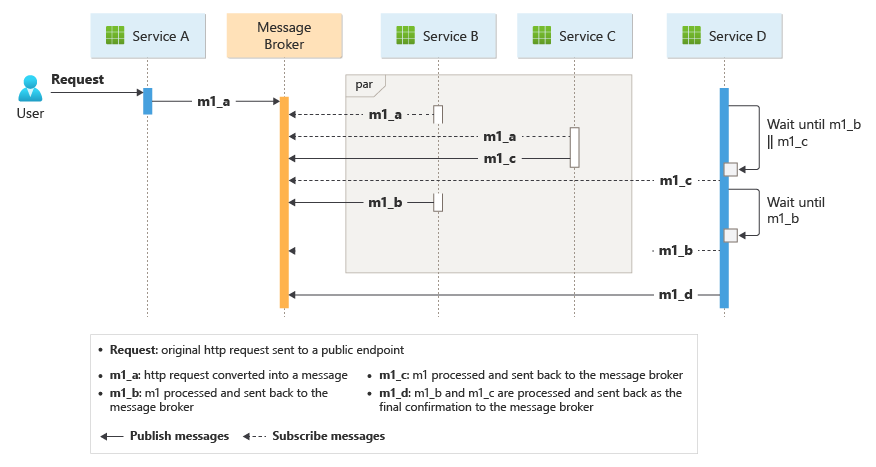
Mönstret blir en utmaning om antalet tjänster växer snabbt. Med tanke på det stora antalet oberoende rörliga delar tenderar arbetsflödet mellan tjänster att bli komplext. Dessutom blir distribuerad spårning svårt.
I en orkestreringsledd design kan den centrala komponenten delvis delta och delegera återhämtningslogik till en annan komponent som försöker utföra tillfälliga, icke-övergående och timeout-fel konsekvent. Med orkestratorns upplösning i koreografimönstret bör de underordnade komponenterna inte plocka upp dessa återhämtningsuppgifter. Dessa måste fortfarande hanteras av återhämtningshanteraren. Men nu måste de underordnade komponenterna kommunicera direkt med återhämtningshanteraren, vilket ökar punkt-till-punkt-kommunikationen.
När du ska använda det här mönstret
Använd det här mönstret i sådana här scenarier:
De underordnade komponenterna hanterar atomiska åtgärder oberoende av varandra. Se det som en "eld och glöm"-mekanism. En komponent ansvarar för en uppgift som inte behöver hanteras aktivt. När uppgiften är klar skickar den ett meddelande till de andra komponenterna.
Komponenterna förväntas uppdateras och ersättas ofta. Mönstret gör att programmet kan ändras med mindre ansträngning och minimala avbrott i befintliga tjänster.
Mönstret passar perfekt för serverlösa arkitekturer som är lämpliga för enkla arbetsflöden. Komponenterna kan vara kortvariga och händelsedrivna. När en händelse inträffar, spunnas komponenter upp, utför sina uppgifter och tas bort när uppgiften har slutförts.
Det här mönstret kan vara ett bra val för kommunikation mellan avgränsade kontexter. För kommunikation inom en enskild begränsad kontext kan ett orchestrator-mönster övervägas.
Det finns en flaskhals i prestandan som introduceras av den centrala orkestratorn.
Det här mönstret är kanske inte användbart om:
Programmet är komplext och kräver en central komponent för att hantera delad logik för att hålla nedströmskomponenterna lätta.
Det finns situationer där punkt-till-punkt-kommunikation mellan komponenterna är oundviklig.
Du måste konsolidera alla åtgärder som hanteras av underordnade komponenter med hjälp av affärslogik.
Design av arbetsbelastning
En arkitekt bör utvärdera hur koreografimönstret kan användas i arbetsbelastningens design för att uppfylla de mål och principer som beskrivs i grundpelarna i Azure Well-Architected Framework. Till exempel:
| Grundpelare | Så här stöder det här mönstret pelarmål |
|---|---|
| Operational Excellence hjälper till att leverera arbetsbelastningskvalitet genom standardiserade processer och teamsammanhållning. | Eftersom de distribuerade komponenterna i det här mönstret är autonoma och utformade för att vara utbytbara kan du ändra arbetsbelastningen med mindre övergripande ändringar i systemet. - OE:04 Verktyg och processer |
| Prestandaeffektivitet hjälper din arbetsbelastning att effektivt uppfylla kraven genom optimeringar inom skalning, data och kod. | Det här mönstret är ett alternativ när prestandaflaskhalsar uppstår i en centraliserad orkestreringstopologi. - PE:02 Kapacitetsplanering - PE:05 Skalning och partitionering |
Som med alla designbeslut bör du överväga eventuella kompromisser mot målen för de andra pelarna som kan införas med det här mönstret.
Exempel
Det här exemplet visar koreografimönstret genom att skapa en händelsedriven, molnbaserad arbetsbelastning som kör funktioner tillsammans med mikrotjänster. När en klient begär att ett paket ska levereras tilldelar arbetsbelastningen en drönare. När paketet är redo att hämtas av den schemalagda drönaren kommer leveransprocessen igång. Under överföring hanterar arbetsbelastningen leveransen tills den får den levererade statusen.
Det här exemplet är en refaktorisering av implementeringen av drönarleveransen som ersätter Orchestrator-mönstret med koreografimönstret.
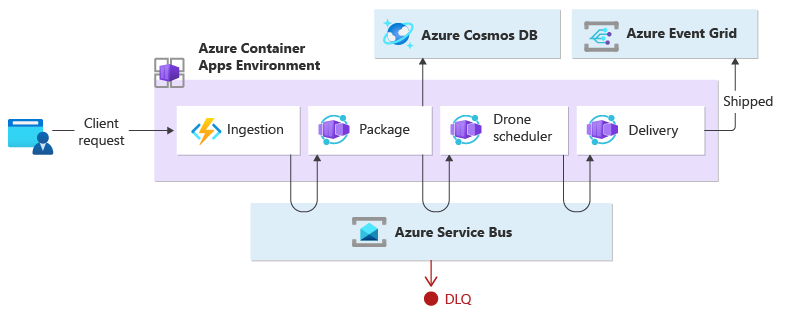
Inmatningstjänsten hanterar klientbegäranden och konverterar dem till meddelanden, inklusive leveransinformation. Affärstransaktioner initieras efter att de nya meddelandena har förbrukats.
En enskild klientaffärstransaktion kräver tre distinkta affärsåtgärder:
- Skapa eller uppdatera ett paket
- Tilldela en drönare för att leverera paketet
- Hantera leveransen som består av att kontrollera och så småningom öka medvetenheten när den levereras.
Tre mikrotjänster utför affärsbearbetningen: Paket-, Drone Scheduler- och Delivery-tjänster. I stället för en central orkestrerare använder tjänsterna meddelanden för att kommunicera sinsemellan. Varje tjänst ansvarar för att implementera ett protokoll i förväg som samordnar på ett decentraliserat sätt affärsarbetsflödet.
Designa
Affärstransaktionen bearbetas i en sekvens genom flera hopp. Varje hopp delar en enda meddelandebuss mellan alla affärstjänster.
När en klient skickar en leveransbegäran via en HTTP-slutpunkt tar inmatningstjänsten emot den, konverterar en sådan begäran till ett meddelande och publicerar sedan meddelandet till den delade meddelandebussen. De prenumerationsbaserade affärstjänsterna kommer att förbruka nya meddelanden som läggs till i bussen. När du tar emot meddelandet kan affärstjänsterna slutföra åtgärden med framgång, fel eller så kan begäran överskrida tidsgränsen. Om det lyckas svarar tjänsterna på bussen med statuskoden Ok, genererar ett nytt åtgärdsmeddelande och skickar det till meddelandebussen. Om det uppstår ett fel eller tidsgräns rapporterar tjänsten fel genom att skicka orsakskoden till meddelandebussen. Dessutom läggs meddelandet till i en kö med obeställbara meddelanden. Meddelanden som inte kunde tas emot eller bearbetas inom en rimlig och lämplig tid flyttas även DLQ.
Designen använder flera meddelandebussar för att bearbeta hela affärstransaktionen. Microsoft Azure Service Bus och Microsoft Azure Event Grid är sammansatta för att tillhandahålla meddelandetjänstplattformen för den här designen. Arbetsbelastningen distribueras på Azure Container Apps som är värd för Azure Functions för inmatning och appar som hanterar händelsedriven bearbetning som kör affärslogik.
Designen säkerställer att koreografin förekommer i en sekvens. Ett enda Azure Service Bus-namnområde innehåller ett ämne med två prenumerationer och en sessionsmedveten kö. Inmatningstjänsten publicerar meddelanden till ämnet. Pakettjänsten och Drone Scheduler-tjänsten prenumererar på ämnet och publicerar meddelanden som kommunicerar lyckade meddelanden till kön. Med en vanlig sessionsidentifierare som ett GUID som är kopplat till leveransidentifieraren möjliggör ordnad hantering av obundna sekvenser av relaterade meddelanden. Leveranstjänsten väntar på två relaterade meddelanden per transaktion. Det första meddelandet anger att paketet är redo att levereras och det andra signalerar att en drönare är schemalagd.
Den här designen använder Azure Service Bus för att hantera värdefulla meddelanden som inte kan gå förlorade eller dupliceras under hela leveransprocessen. När paketet levereras publiceras även en tillståndsändring till Azure Event Grid. I den här designen har händelsesändaren inga förväntningar på hur tillståndsändringen hanteras. Underordnade organisationstjänster som inte ingår som en del av den här designen kan lyssna på den här händelsetypen och reagera på att köra specifik logik för affärsändamål (det vill s.v.s. skicka orderstatusen via e-post till användaren).
Om du planerar att distribuera detta till en annan beräkningstjänst, till exempel AKS pub-sub pattern application boilerplate, kan den implementeras med två containrar i samma podd. En container kör ambassadören som interagerar med meddelandebussen medan den andra kör affärslogik. Metoden med två containrar i samma podd förbättrar prestanda och skalbarhet. Ambassadören och företagstjänsten delar samma nätverk som möjliggör låg svarstid och högt dataflöde.
För att undvika sammanhängande återförsöksåtgärder som kan leda till flera åtgärder bör företagstjänster omedelbart flagga oacceptabla meddelanden. Det är möjligt att utöka sådana meddelanden med hjälp av välkända orsakskoder eller en definierad programkod, så att den kan flyttas till en kö med obeställbara meddelanden (DLQ). Överväg att hantera konsekvensproblem med att implementera Saga från underordnade tjänster. En annan tjänst kan till exempel endast hantera meddelanden med obeställbara meddelanden i reparationssyfte genom att utföra en kompensations-, rety- eller pivottransaktion.
Affärstjänsterna är idempotent för att se till att återförsök inte resulterar i duplicerade resurser. Pakettjänsten använder till exempel upsert-åtgärder för att lägga till data i datalagret.
Relaterade resurser
Tänk på dessa mönster i din design för koreografi.
Modularisera affärstjänsten med hjälp av designmönstret ambassadör.
Implementera köbaserat belastningsutjämningsmönster för att hantera toppar i arbetsbelastningen.
Använd asynkrona distribuerade meddelanden via utgivar-prenumerantmönstret.
Använd kompenserande transaktioner för att ångra en serie lyckade åtgärder om en eller flera relaterade åtgärder misslyckas.
Information om hur du använder en meddelandekö i en meddelandeinfrastruktur finns i Asynkrona meddelandealternativ i Azure.