Överväganden för programplattform för verksamhetskritiska arbetsbelastningar
Ett viktigt designområde för alla verksamhetskritiska arkitekturer är programplattformen. Plattform refererar till de infrastrukturkomponenter och Azure-tjänster som måste etableras för att stödja programmet. Här följer några övergripande rekommendationer.
Designa i lager. Välj rätt uppsättning tjänster, deras konfiguration och de programspecifika beroendena. Den här skiktade metoden hjälper dig att skapa logisk och fysisk segmentering. Det är användbart när du definierar roller och funktioner och tilldelar lämpliga privilegier och distributionsstrategier. Den här metoden ökar i slutändan systemets tillförlitlighet.
Ett verksamhetskritiskt program måste vara mycket tillförlitligt och motståndskraftigt mot datacenter och regionala fel. Att skapa zonindelad och regional redundans i en aktiv-aktiv konfiguration är huvudstrategin. När du väljer Azure-tjänster för programmets plattform bör du överväga deras Tillgänglighetszoner support- och distributionsmönster och driftsmönster för att använda flera Azure-regioner.
Använd en skalningsenhetsbaserad arkitektur för att hantera ökad belastning. Med skalningsenheter kan du gruppera resurser logiskt och en enhet kan skalas oberoende av andra enheter eller tjänster i arkitekturen. Använd din kapacitetsmodell och förväntade prestanda för att definiera gränserna för, antalet och baslinjeskalan för varje enhet.
I den här arkitekturen består programplattformen av globala resurser, distributionsstämpel och regionala resurser. De regionala resurserna etableras som en del av en distributionsstämpel. Varje stämpel motsvarar en skalningsenhet och kan, om den blir felaktig, ersättas helt.
Resurserna i varje lager har distinkta egenskaper. Mer information finns i Arkitekturmönster för en typisk verksamhetskritisk arbetsbelastning.
| Egenskaper | Överväganden |
|---|---|
| Livstid | Vad är den förväntade livslängden för resursen i förhållande till andra resurser i lösningen? Ska resursen överleva eller dela livslängden med hela systemet eller regionen, eller ska den vara tillfällig? |
| Tillstånd | Vilken inverkan kommer det beständiga tillståndet på det här lagret att ha på tillförlitligheten eller hanterbarheten? |
| Reach | Måste resursen distribueras globalt? Kan resursen kommunicera med andra resurser, globalt eller i regioner? |
| Beroenden | Vad är beroendet av andra resurser, globalt eller i andra regioner? |
| Skalningsgränser | Vilket dataflöde förväntas för resursen på det lagret? Hur stor skala tillhandahålls av resursen för att passa den efterfrågan? |
| Tillgänglighet/haveriberedskap | Vad påverkar tillgängligheten eller katastrofen på det här lagret? Skulle det orsaka ett systemfel eller endast lokaliserad kapacitet eller tillgänglighetsproblem? |
Globala resurser
Vissa resurser i den här arkitekturen delas av resurser som distribueras i regioner. I den här arkitekturen används de för att distribuera trafik mellan flera regioner, lagra permanent tillstånd för hela programmet och cachelagras globala statiska data.
| Egenskaper | Överväganden för lager |
|---|---|
| Livstid | Dessa resurser förväntas leva länge. Deras livslängd sträcker sig över systemets livslängd eller längre. Ofta hanteras resurserna med data på plats och kontrollplansuppdateringar, förutsatt att de stöder uppdateringsåtgärder utan stilleståndstid. |
| Tillstånd | Eftersom dessa resurser finns under systemets livslängd är det ofta det här lagret som ansvarar för att lagra globalt, geo-replikerat tillstånd. |
| Reach | Resurserna ska distribueras globalt. Vi rekommenderar att dessa resurser kommunicerar med regionala eller andra resurser med låg svarstid och önskad konsekvens. |
| Beroenden | Resurserna bör undvika beroenden av regionala resurser eftersom deras otillgänglighet kan vara en orsak till globala fel. Till exempel kan certifikat eller hemligheter som lagras i ett enda valv ha global inverkan om det uppstår ett regionalt fel där valvet finns. |
| Skalningsgränser | Ofta är dessa resurser singleton-instanser i systemet, och därför bör de kunna skala så att de kan hantera dataflödet i systemet som helhet. |
| Tillgänglighet/haveriberedskap | Eftersom regionala resurser och stämpelresurser kan använda globala resurser eller frontas av dem är det viktigt att globala resurser konfigureras med hög tillgänglighet och haveriberedskap för hela systemets hälsotillstånd. |
I den här arkitekturen är globala lagerresurser Azure Front Door, Azure Cosmos DB, Azure Container Registry och Azure Log Analytics för lagring av loggar och mått från andra globala lagerresurser.
Det finns andra grundläggande resurser i den här designen, till exempel Microsoft Entra-ID och Azure DNS. De har utelämnats i den här bilden för korthet.

Global lastbalanserare
Azure Front Door används som den enda startpunkten för användartrafik. Azure garanterar att Azure Front Door levererar det begärda innehållet utan fel 99,99 % av tiden. Mer information finns i Front Door-tjänstbegränsningar. Om Front Door blir otillgängligt ser slutanvändaren systemet som nedständ.
Front Door-instansen skickar trafik till de konfigurerade serverdelstjänsterna, till exempel beräkningsklustret som är värd för API:et och klientdelens SPA. Felkonfigurationer på serverdelen i Front Door kan leda till avbrott. För att undvika avbrott på grund av felkonfigurationer bör du testa Front Door-inställningarna i stor utsträckning.
Ett annat vanligt fel kan komma från felkonfigurerade eller saknade TLS-certifikat, vilket kan hindra användare från att använda klientdelen eller Front Door som kommunicerar med serverdelen. Åtgärder kan kräva manuella åtgärder. Du kan till exempel välja att återställa till den tidigare konfigurationen och utfärda certifikatet igen om det är möjligt. Oavsett, förvänta dig otillgänglighet medan ändringarna träder i kraft. Användning av hanterade certifikat som erbjuds av Front Door rekommenderas för att minska driftkostnaderna, till exempel förfallotid för hantering.
Front Door erbjuder många ytterligare funktioner förutom global trafikroutning. En viktig funktion är brandväggen för webbprogram (WAF), eftersom Front Door kan inspektera trafik som passerar. När det konfigureras i förebyggande läge blockeras misstänkt trafik innan någon av serverdelarna ens når dem.
Information om Front Door-funktioner finns i Vanliga frågor och svar om Azure Front Door.
Andra överväganden om global distribution av trafik finns i Misson-kritisk vägledning i Well-architected Framework: Global routning.
Container Registry
Azure Container Registry används för att lagra OCI-artefakter (Open Container Initiative), särskilt helm-diagram och containeravbildningar. Det deltar inte i begärandeflödet och används endast regelbundet. Containerregistret måste finnas innan stämpelresurser distribueras och bör inte ha beroende av regionala lagerresurser.
Aktivera zonredundans och geo-replikering av register så att körningsåtkomsten till avbildningar är snabb och motståndskraftig mot fel. I händelse av otillgänglighet kan instansen sedan redundansväxla till replikregioner och begäranden dirigeras automatiskt om till en annan region. Förvänta dig tillfälliga fel vid dragning av bilder tills redundansväxlingen är klar.
Fel kan också inträffa om bilder tas bort oavsiktligt, nya beräkningsnoder kan inte hämta bilder, men befintliga noder kan fortfarande använda cachelagrade avbildningar. Den primära strategin för haveriberedskap är omdistribution. Artefakterna i ett containerregister kan återskapas från pipelines. Containerregistret måste kunna hantera många samtidiga anslutningar för att stödja alla dina distributioner.
Vi rekommenderar att du använder Premium SKU för att aktivera geo-replikering. Zonredundansfunktionen säkerställer återhämtning och hög tillgänglighet inom en viss region. Vid ett regionalt avbrott är repliker i andra regioner fortfarande tillgängliga för dataplansåtgärder. Med den här SKU:n kan du begränsa åtkomsten till avbildningar via privata slutpunkter.
Mer information finns i Metodtips för Azure Container Registry.
Databas
Vi rekommenderar att alla tillstånd lagras globalt i en databas som är skild från regionala stämplar. Skapa redundans genom att distribuera databasen mellan regioner. För verksamhetskritiska arbetsbelastningar bör synkronisering av data mellan regioner vara det främsta problemet. I händelse av ett fel bör även skrivbegäranden till databasen fortfarande fungera.
Datareplikering i en aktiv-aktiv konfiguration rekommenderas starkt. Programmet bör kunna ansluta direkt till en annan region. Alla instanser ska kunna hantera läs- och skrivbegäranden.
Mer information finns i Dataplattform för verksamhetskritiska arbetsbelastningar.
Global övervakning
Azure Log Analytics används för att lagra diagnostikloggar från alla globala resurser. Vi rekommenderar att du begränsar den dagliga kvoten för lagring, särskilt i miljöer som används för belastningstestning. Ange också kvarhållningsprincip. Dessa begränsningar förhindrar överförbrukning som uppstår genom att lagra data som inte behövs utöver en gräns.
Överväganden för grundläggande tjänster
Systemet kommer sannolikt att använda andra kritiska plattformstjänster som kan orsaka att hela systemet är i fara, till exempel Azure DNS och Microsoft Entra-ID. Azure DNS garanterar serviceavtal med 100 % tillgänglighet för giltiga DNS-begäranden. Microsoft Entra garanterar minst 99,99 % drifttid. Ändå bör du vara medveten om effekten i händelse av ett fel.
Det är oundvikligt att vara beroende av grundläggande tjänster eftersom många Azure-tjänster är beroende av dem. Förvänta dig avbrott i systemet om de inte är tillgängliga. Till exempel:
- Azure Front Door använder Azure DNS för att nå serverdelen och andra globala tjänster.
- Azure Container Registry använder Azure DNS för att redundansväxla begäranden till en annan region.
I båda fallen påverkas båda Azure-tjänsterna om Azure DNS inte är tillgängligt. Namnmatchningen för användarbegäranden från Front Door misslyckas. Docker-avbildningar hämtas inte från registret. Att använda en extern DNS-tjänst som säkerhetskopiering minskar inte risken eftersom många Azure-tjänster inte tillåter sådan konfiguration och förlitar sig på intern DNS. Förvänta dig fullständigt avbrott.
På samma sätt används Microsoft Entra-ID för kontrollplansåtgärder som att skapa nya AKS-noder, hämta avbildningar från Container Registry eller komma åt Key Vault vid poddstart. Om Microsoft Entra-ID:t inte är tillgängligt bör befintliga komponenter inte påverkas, men övergripande prestanda kan försämras. Nya poddar eller AKS-noder fungerar inte. Om utskalningsåtgärder krävs under den här tiden kan du förvänta dig en minskad användarupplevelse.
Regionala distributionsstämpelresurser
I den här arkitekturen distribuerar distributionsstämpeln arbetsbelastningen och etablerar resurser som deltar i slutförande av affärstransaktioner. En stämpel motsvarar vanligtvis en distribution till en Azure-region. Även om en region kan ha mer än en stämpel.
| Egenskaper | Överväganden |
|---|---|
| Livstid | Resurserna förväntas ha en kort livslängd (tillfällig) med avsikten att de kan läggas till och tas bort dynamiskt medan regionala resurser utanför stämpeln fortsätter att finnas kvar. Den tillfälliga naturen behövs för att ge mer återhämtning, skala och närhet till användare. |
| Tillstånd | Eftersom stämplar är tillfälliga och kan förstöras när som helst, bör en stämpel vara tillståndslös så mycket som möjligt. |
| Reach | Kan kommunicera med regionala och globala resurser. Kommunikation med andra regioner eller andra stämplar bör dock undvikas. I den här arkitekturen finns det inget behov av att dessa resurser distribueras globalt. |
| Beroenden | Stämpelresurserna måste vara oberoende. De bör alltså inte förlita sig på andra stämplar eller komponenter i andra regioner. De förväntas ha regionala och globala beroenden. Den huvudsakliga delade komponenten är databasskiktet och containerregistret. Den här komponenten kräver synkronisering vid körning. |
| Skalningsgränser | Dataflödet upprättas genom testning. Dataflödet för den övergripande stämpeln är begränsat till den resurs som har minst prestanda. Stämpeldataflödet måste ta hänsyn till den uppskattade höga efterfrågan och eventuella redundansväxlingar till följd av att en annan stämpel i regionen blir otillgänglig. |
| Tillgänglighet/haveriberedskap | På grund av stämplarnas tillfälliga karaktär utförs haveriberedskap genom omdistribuering av stämpeln. Om resurserna är i ett feltillstånd kan stämpeln som helhet förstöras och distribueras om. |
I den här arkitekturen är stämpelresurser Azure Kubernetes Service, Azure Event Hubs, Azure Key Vault och Azure Blob Storage.
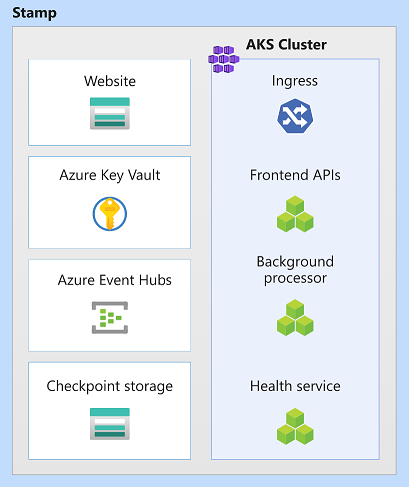
Skalningsenhet
En stämpel kan också betraktas som en skalningsenhet (SU). Alla komponenter och tjänster inom en viss stämpel konfigureras och testas för att hantera begäranden i ett visst intervall. Här är ett exempel på en skalningsenhet som används i implementeringen.
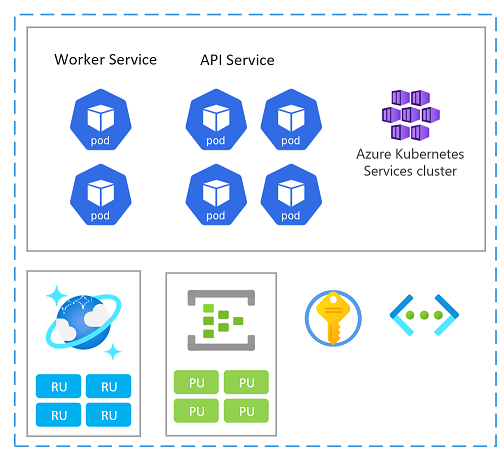
Varje skalningsenhet distribueras till en Azure-region och hanterar därför främst trafik från det angivna området (även om den kan ta över trafik från andra regioner vid behov). Den här geografiska spridningen kommer sannolikt att resultera i belastningsmönster och kontorstid som kan variera från region till region och därför är varje SU utformad för att skala in/ned när den är inaktiv.
Du kan distribuera en ny stämpel för skalning. I en stämpel kan enskilda resurser också vara skalningsenheter.
Här följer några skalnings- och tillgänglighetsöverväganden när du väljer Azure-tjänster i en enhet:
Utvärdera kapacitetsrelationer mellan alla resurser i en skalningsenhet. Om du till exempel vill hantera 100 inkommande begäranden behövs 5 ingresskontrollantpoddar och 3 katalogtjänstpoddar och 1 000 RU:er i Azure Cosmos DB. När du automatiskt skalar ingresspoddarna kan du därför förvänta dig skalning av katalogtjänsten och Azure Cosmos DB RU:er med tanke på dessa intervall.
Belastningstesta tjänsterna för att fastställa ett intervall inom vilket begäranden ska hanteras. Baserat på resultaten konfigurerar du minsta och högsta instanser och målmått. När målet nås kan du välja att automatisera skalningen av hela enheten.
Granska skalningsgränser och kvoter för Azure-prenumerationer för att stödja den kapacitets- och kostnadsmodell som anges av affärskraven. Kontrollera även gränserna för enskilda tjänster. Eftersom enheter vanligtvis distribueras tillsammans tar du hänsyn till de prenumerationsresursgränser som krävs för kanariedistributioner. Mer information finns i Azure-tjänstbegränsningar.
Välj tjänster som stöder tillgänglighetszoner för att skapa redundans. Detta kan begränsa dina teknikval. Mer information finns i Tillgänglighetszoner.
Andra överväganden om storleken på en enhet och en kombination av resurser finns i Misson-critical guidance in Well-architected Framework: Scale-unit architecture (Misson-critical guidance in Well-architected Framework: Scale-unit architecture).
Beräkningskluster
För att containerisera arbetsbelastningen måste varje stämpel köra ett beräkningskluster. I den här arkitekturen väljs Azure Kubernetes Service (AKS) eftersom Kubernetes är den mest populära beräkningsplattformen för moderna, containerbaserade program.
AKS-klustrets livslängd är bunden till stämpelns tillfälliga karaktär. Klustret är tillståndslöst och har inte beständiga volymer. Den använder tillfälliga OS-diskar i stället för hanterade diskar eftersom de inte förväntas ta emot underhåll på program- eller systemnivå.
För att öka tillförlitligheten är klustret konfigurerat att använda alla tre tillgänglighetszonerna i en viss region. Detta gör det möjligt för klustret att använda AKS Uptime SLA som garanterar 99,95 % SLA-tillgänglighet för AKS-kontrollplanet.
Andra faktorer som skalningsgränser, beräkningskapacitet och prenumerationskvot kan också påverka tillförlitligheten. Om det inte finns tillräckligt med kapacitet eller om gränserna nås misslyckas skalnings- och uppskalningsåtgärderna, men den befintliga beräkningen förväntas fungera.
Klustret har automatisk skalning aktiverat så att nodpooler automatiskt kan skalas ut om det behövs, vilket förbättrar tillförlitligheten. När du använder flera nodpooler ska alla nodpooler skalas automatiskt.
På poddnivå skalar HPA (Horizontal Pod Autoscaler) poddar baserat på konfigurerad CPU, minne eller anpassade mått. Belastningstesta komponenterna i arbetsbelastningen för att upprätta en baslinje för autoskalnings- och HPA-värdena.
Klustret är också konfigurerat för automatiska nodavbildningsuppgraderingar och för att skalas korrekt under dessa uppgraderingar. Den här skalningen möjliggör noll stilleståndstid medan uppgraderingar utförs. Om klustret i en stämpel misslyckas under en uppgradering bör andra kluster i andra stämplar inte påverkas, men uppgraderingar mellan stämplar bör ske vid olika tidpunkter för att upprätthålla tillgängligheten. Dessutom distribueras klusteruppgraderingar automatiskt över noderna så att de inte är tillgängliga samtidigt.
Vissa komponenter som cert-manager och ingress-nginx kräver containeravbildningar från externa containerregister. Om dessa lagringsplatser eller bilder inte är tillgängliga kan det hända att nya instanser på nya noder (där avbildningen inte cachelagras) inte kan starta. Den här risken kan minskas genom att dessa avbildningar importeras till miljöns Azure Container Registry.
Observerbarhet är viktigt i den här arkitekturen eftersom stämplar är tillfälliga. Diagnostikinställningar har konfigurerats för att lagra alla logg- och måttdata på en regional Log Analytics-arbetsyta. DESSUTOM aktiveras AKS Container Insights via en OMS-agent i klustret. Med den här agenten kan klustret skicka övervakningsdata till Log Analytics-arbetsytan.
Andra överväganden om beräkningsklustret finns i Misson-kritisk vägledning i Well-architected Framework: Container Orchestration och Kubernetes.
Key Vault
Azure Key Vault används för att lagra globala hemligheter som anslutningssträng till databasen och stämpla hemligheter som Event Hubs-anslutningssträng.
Den här arkitekturen använder en CSI-drivrutin för Secrets Store i beräkningsklustret för att hämta hemligheter från Key Vault. Hemligheter behövs när nya poddar skapas. Om Key Vault inte är tillgängligt kanske nya poddar inte kommer igång. Det kan därför uppstå störningar. utskalningsåtgärder kan påverkas, uppdateringar kan misslyckas, nya distributioner kan inte köras.
Key Vault har en gräns för antalet åtgärder. På grund av den automatiska uppdateringen av hemligheter kan gränsen nås om det finns många poddar. Du kan välja att minska uppdateringsfrekvensen för att undvika den här situationen.
Andra överväganden om hemlig hantering finns i Misson-kritisk vägledning i Well-architected Framework: Dataintegritetsskydd.
Event Hubs
Den enda tillståndskänsliga tjänsten i stämpeln är meddelandekoordinatorn, Azure Event Hubs, som lagrar begäranden under en kort period. Mäklaren tjänar behovet av buffring och tillförlitliga meddelanden. Bearbetade begäranden sparas i den globala databasen.
I den här arkitekturen används Standard SKU och zonredundans aktiveras för hög tillgänglighet.
Event Hubs-hälsotillståndet verifieras av healthservice-komponenten som körs i beräkningsklustret. Den utför regelbundna kontroller mot olika resurser. Detta är användbart för att identifiera feltillstånd. Om meddelanden till exempel inte kan skickas till händelsehubben skulle stämpeln vara oanvändbar för skrivåtgärder. HealthService bör automatiskt identifiera det här villkoret och rapportera feltillstånd till Front Door, vilket tar bort stämpeln från rotationen.
För skalbarhet rekommenderar vi att du aktiverar automatisk blåsning.
Mer information finns i Meddelandetjänster för verksamhetskritiska arbetsbelastningar.
Andra överväganden om meddelanden finns i Misson-critical guidance in Well-architected Framework: Asynchronous messaging (Felon-kritisk vägledning i Välkonstruerat ramverk: Asynkrona meddelanden).
Lagringskonton
I den här arkitekturen etableras två lagringskonton. Båda kontona distribueras i zonredundant läge (ZRS).
Ett konto används för kontrollpunkter för Event Hubs. Om det här kontot inte svarar kan stämpeln inte bearbeta meddelanden från Event Hubs och kan till och med påverka andra tjänster i stämpeln. Det här villkoret kontrolleras regelbundet av HealthService, som är en av de programkomponenter som körs i beräkningsklustret.
Den andra används för att vara värd för UI-enkelsidigt program. Om servering av den statiska webbplatsen har några problem identifierar Front Door problemet och skickar inte trafik till det här lagringskontot. Under den här tiden kan Front Door använda cachelagrat innehåll.
Mer information om återställning finns i Haveriberedskap och redundans för lagringskonto.
Regionala resurser
Ett system kan ha resurser som distribueras i regionen men som inte klarar stämpelresurserna. I den här arkitekturen lagras observerbarhetsdata för stämpelresurser i regionala datalager.
| Egenskaper | Att tänka på |
|---|---|
| Livstid | Resurserna delar regionens livslängd och lever ut stämpelresurserna. |
| Tillstånd | Tillståndet som lagras i en region kan inte leva längre än regionens livslängd. Om tillstånd måste delas mellan regioner bör du överväga att använda ett globalt datalager. |
| Reach | Resurserna behöver inte distribueras globalt. Direkt kommunikation med andra regioner bör undvikas till varje pris. |
| Beroenden | Resurserna kan ha beroenden för globala resurser, men inte på stämpelresurser eftersom stämplar är avsedda att vara kortvariga. |
| Skalningsgränser | Fastställa skalningsgränsen för regionala resurser genom att kombinera alla stämplar i regionen. |
Övervaka data för stämpelresurser
Distribution av övervakningsresurser är ett typiskt exempel för regionala resurser. I den här arkitekturen har varje region en enskild Log Analytics-arbetsyta konfigurerad för att lagra alla logg- och måttdata som genereras från stämpelresurser. Eftersom regionala resurser överlever stämpelresurser är data tillgängliga även när stämpeln tas bort.
Azure Log Analytics och Azure Application Insights används för att lagra loggar och mått från plattformen. Vi rekommenderar att du begränsar den dagliga kvoten för lagring, särskilt i miljöer som används för belastningstestning. Ange också kvarhållningsprincip för att lagra alla data. Dessa begränsningar förhindrar överförbrukning som uppstår genom att lagra data som inte behövs utöver en gräns.
På samma sätt distribueras Application Insights också som en regional resurs för att samla in alla programövervakningsdata.
Designrekommendationer om övervakning finns i Misson-kritisk vägledning i Välkonstruerat ramverk: Hälsomodellering.
Nästa steg
Distribuera referensimplementeringen för att få en fullständig förståelse för de resurser och deras konfiguration som används i den här arkitekturen.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för