Prestanda och felsökning för SAP-dataextrahering
Den här artikeln är en del av artikelserien "SAP extend and innovate data: Best practices".
- Identifiera SAP-datakällor
- Välj den bästa SAP-anslutningsappen
- Prestanda och felsökning för SAP-dataextrahering
- Dataintegreringssäkerhet för SAP på Azure
- Allmän arkitektur för SAP-dataintegrering
Det finns många sätt att ansluta till SAP-systemet för dataintegrering. I avsnitten nedan beskrivs allmänna och anslutningsspecifika överväganden och rekommendationer.
Prestanda
Det är viktigt att konfigurera optimala inställningar för källan och målet så att du kan uppnå bästa möjliga prestanda vid extrahering och bearbetning av data.
Generella saker att tänka på
- Kontrollera att rätt SAP-parametrar har angetts för en maximal samtidig anslutning.
- Överväg att använda SAP-gruppens inloggningstyp för bättre prestanda och belastningsfördelning.
- Se till att den virtuella SHIR-datorn (self-hosted Integration Runtime) är tillräckligt stor och har hög tillgänglighet.
- När du arbetar med stora datauppsättningar kontrollerar du om anslutningsappen som du använder har en partitioneringsfunktion. Många av SAP-anslutningsapparna stöder partitionering och parallelliseringsfunktioner för att påskynda datainläsningen. När du använder den här metoden paketeras data i mindre segment som kan läsas in med hjälp av flera parallella processer. Mer information finns i anslutningsspecifik dokumentation.
Allmänna rekommendationer
Använd SAP-transaktionen RZ12 för att ändra värden för maximalt antal samtidiga anslutningar.
SAP-parametrar för RFC – RZ12: Följande parameter kan begränsa antalet RFC-anrop som tillåts för en användare eller ett program, så se till att den här begränsningen inte orsakar en flaskhals.
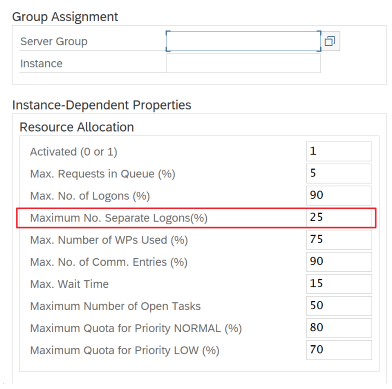
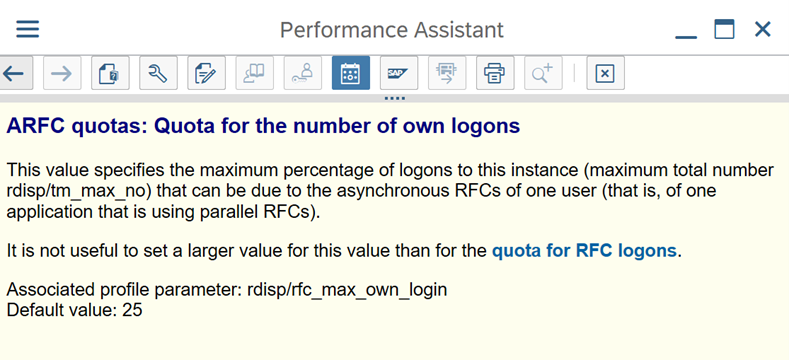
Anslutning till SAP med hjälp av inloggningsgrupp: SHIR (lokalt installerad integrationskörning) bör ansluta till SAP med hjälp av en SAP-inloggningsgrupp (via meddelandeserver) och inte till en specifik programserver för att säkerställa en arbetsbelastningsdistribution över alla tillgängliga programservrar.
Anteckning
Spark-kluster för dataflöde och SHIR är kraftfulla. Många interna SAP-kopieringsaktiviteter, till exempel 16, kan utlösas och köras. Men om SAP-serverns samtidiga anslutningsnummer är litet, till exempel 8, läser perf data från SAP-sidan.
Börja med 4vCPU:er och 16 GB virtuella datorer för SHIR. Följande steg visar anslutningen av dialogprocessen i SAP med SHIR.
- Kontrollera om kunden använder en dålig fysisk dator för att konfigurera och installera SHIR för att köra en intern SAP-kopia.
- Gå till Azure Data Factory-portalen och leta reda på den relaterade länkade SAP CDC-tjänsten som används i dataflödet. Kontrollera det refererade SHIR-namnet.
- Kontrollera cpu-, minnes-, nätverks- och diskinställningarna för den fysiska dator där SHIR är installerat.
- Kontrollera hur många
diawp.exesom körs på SHIR-datorn. Endiawp.exekan köra en kopieringsaktivitet. Antaletdiawp.exebaseras på datorns inställningar för processor, minne, nätverk och disk.
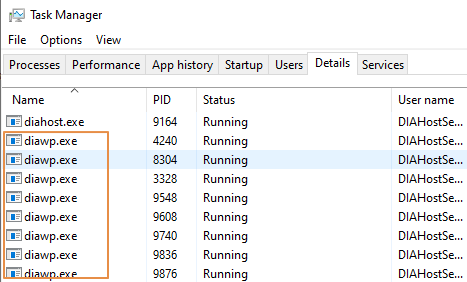
Om du vill köra flera partitioner parallellt på SHIR samtidigt använder du en kraftfull virtuell dator för att konfigurera SHIR. Eller använd skala ut med SHIR-funktioner med hög tillgänglighet och skalbarhet för att ha flera noder. Mer information finns i Hög tillgänglighet och skalbarhet.
Partitioner
I följande avsnitt beskrivs partitioneringsprocessen för en SAP CDC-anslutningsapp. Processen är densamma för en SAP Table- och SAP BW Open Hub-anslutning.

Skalning kan utföras på lokalt installerad IR eller Azure IR beroende på dina prestandakrav. Granska CPU-förbrukningen för SHIR för att visa mått som hjälper dig att bestämma din skalningsmetod. SHIR kan skalas lodrätt eller vågrätt baserat på dina behov. Vi rekommenderar att du distribuerar Azure IR till en lägre SKU. Skala upp för att uppfylla dina prestandakrav som bestäms genom belastningstestning, i stället för att starta i den högre änden i onödan.
Anteckning
Om du når 70 % kapacitet kan du skala upp eller skala ut för SHIR.

Partitionering är användbart för inledande eller stora fullständiga belastningar och krävs vanligtvis inte för deltabelastningar. Om du inte anger partitionen hämtar 1 "producent" i SAP-systemet (vanligtvis en batchprocess) källdata till den operativa datakön (ODQ) och SHIR hämtar data från ODQ. Som standard använder SHIR fyra trådar för att hämta data från ODQ, så potentiellt fyra dialogprocesser används i SAP vid den tidpunkten.
Tanken med partitionering är att dela upp en stor inledande datamängd i flera mindre osammanhängande delmängder som helst är lika stora och som kan bearbetas parallellt. Den här metoden minskar den tid det tar att producera data från källtabellen till ODQ på ett linjärt sätt. Den här metoden förutsätter att det finns tillräckligt med resurser på SAP-sidan för att hantera belastningen.
Anteckning
- Antalet partitioner som körs parallellt begränsas av antalet drivrutinskärnor i Azure IR. En lösning för den här begränsningen pågår för närvarande.
- Varje enhet eller paket i SAP-transaktionen ODQMON är en enda fil i mellanlagringsmappen.
Designöverväganden när du kör pipelines med CDC
Kontrollera varaktigheten för SAP till fas.
Kontrollera körningsprestandan i mottagaren.
Överväg att använda partitioneringsfunktionen för att förbättra prestanda för bättre dataflöde.
Om varaktigheten för SAP till fas är långsam bör du överväga att ändra storlek på SHIR till högre specifikationer.
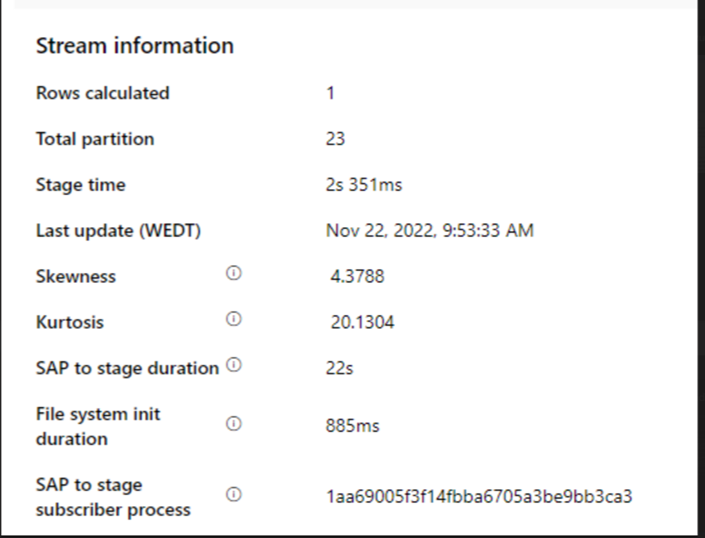
Kontrollera om handfatets bearbetningstid är för långsam.
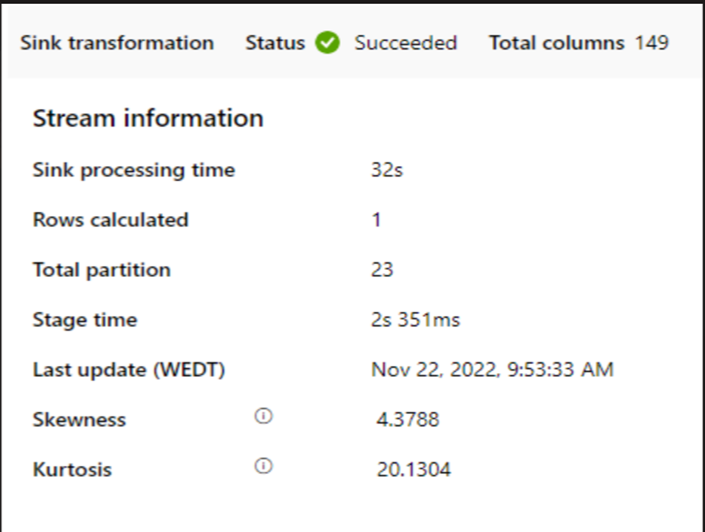
Om ett litet kluster används för att köra dataflödet för mappning kan det påverka prestanda vid mottagaren. Använd ett stort kluster, till exempel 16 + 256 kärnor, så perf läser data från scenen och skriver till mottagaren.
För stora datavolymer rekommenderar vi att du partitionerar belastningen för att köra parallella jobb, men behåller antalet partitioner mindre än eller lika med Azure IR-kärnan, även kallad Spark-klusterkärnan.
Använd fliken Optimera för att definiera partitionerna. Du kan använda källpartitionering i CDC-anslutningsappen.
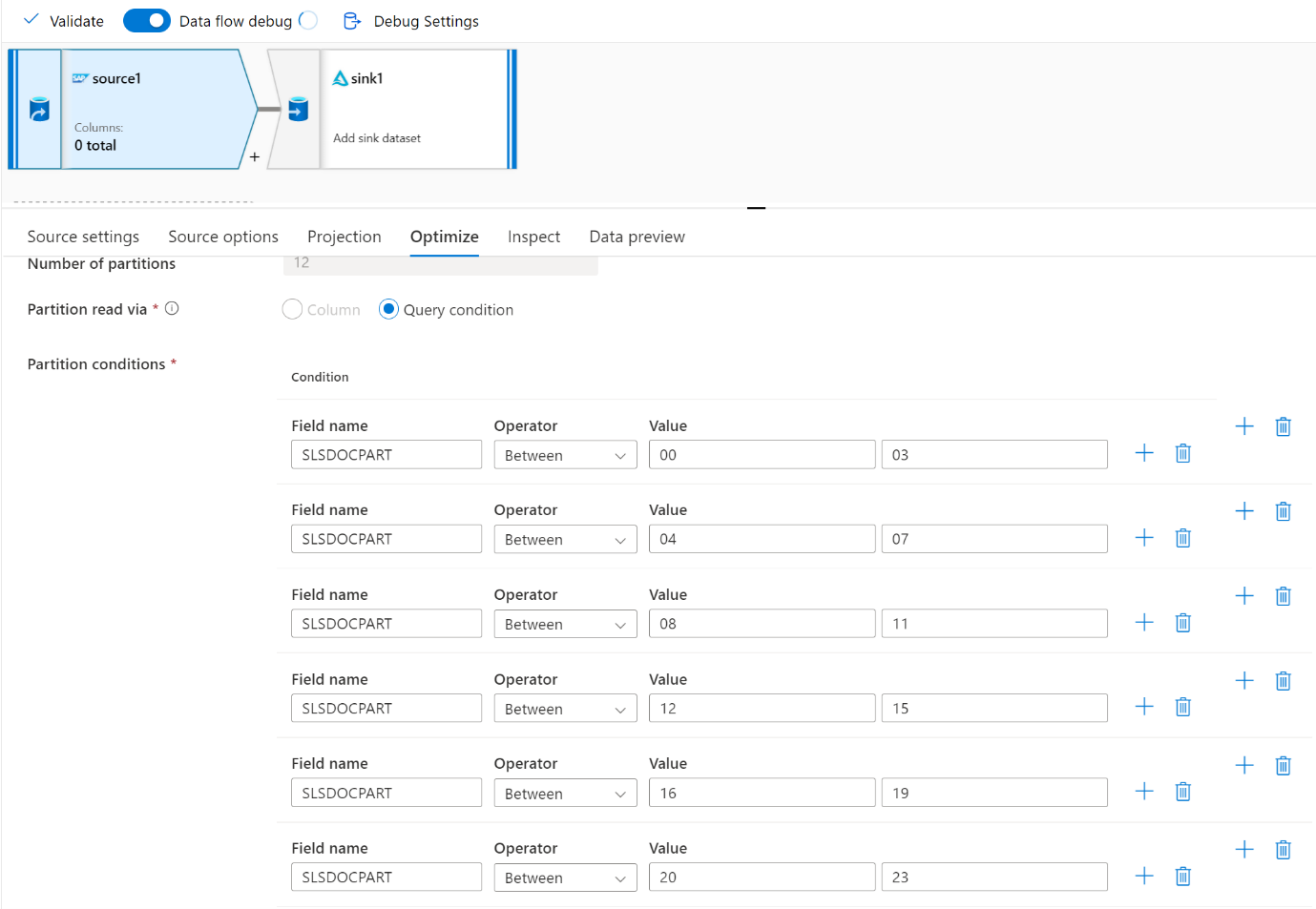
Anteckning
- Det finns en direkt korrelation mellan antalet partitioner med SHIR-kärnor och Azure IR-noder.
- SAP CDC-anslutningsappen visas som Odata-prenumeranttypen "Odata access for Operational Data Provisioning" under ODQMON i SAP-systemet.
Designöverväganden när du använder en tabellanslutning
- Optimera partitioneringen för bättre prestanda.
- Överväg graden av parallellitet från SAP Table.
- Överväg en enskild fildesign för målmottagaren.
- Jämför dataflödet när du använder stora datavolymer.
Utforma rekommendationer när du använder en tabellanslutning
Partition: När du partitioneras i SAP Table Connector delar den upp en underliggande select-instruktion i flera med hjälp av var satser finns i ett lämpligt fält, till exempel ett fält med hög kardinalitet. Om SAP-tabellen har en stor mängd data aktiverar du partitionering för att dela upp data i mindre partitioner. Försök att optimera antalet partitioner (parametern
maxPartitionsNumber) så att partitionerna är tillräckligt små för att undvika minnesdumpar i SAP men tillräckligt stora för att påskynda extraheringen.Parallellitet: Graden av kopieringsparallellitet (parameter
parallelCopies) fungerar tillsammans med partitionering och instruerar SHIR att göra parallella RFC-anrop till SAP-systemet. Om du till exempel anger den här parametern till 4 genererar och kör tjänsten samtidigt fyra frågor baserat på det angivna partitionsalternativet och inställningarna. Varje fråga hämtar en del av data från DIN SAP-tabell.För optimala resultat bör antalet partitioner vara en multipel av antalet kopieringsparallellitet.
När du kopierar data från SAP Table till binära mottagare justeras det faktiska parallella antalet automatiskt baserat på mängden minne som är tillgängligt i SHIR. Registrera storleken på den virtuella SHIR-datorn för varje testcykel, graden av kopieringsparallellitet och antalet partitioner. Observera prestanda för den virtuella SHIR-datorn, prestanda för käll-SAP-systemet och önskad kontra den faktiska graden av parallellitet. Använd en iterativ process för att identifiera optimala inställningar och den perfekta storleken för den virtuella SHIR-datorn. Överväg alla inmatningspipelines som samtidigt läser in data från ett eller flera SAP-system.
Observera det observerade antalet RFC-anrop till SAP mot den konfigurerade graden av parallellitet. Om antalet RFC-anrop till SAP är mindre än graden av parallellitet kontrollerar du att den virtuella SHIR-datorn har tillräckligt med minne och tillgängliga CPU-resurser. Välj en större virtuell dator om det behövs. SAP-källsystemet har konfigurerats för att begränsa antalet parallella anslutningar. Mer information finns i avsnittet Allmänna rekommendationer i den här artikeln.
Antal filer: När du kopierar data till ett filbaserat datalager och målmottagaren är konfigurerad som en mapp genereras flera filer som standard. Om du anger
fileNameegenskapen i mottagaren skrivs data till en enda fil. Vi rekommenderar att du skriver till en mapp som flera filer eftersom det får ett högre skrivgenomflöde jämfört med att skriva till en enda fil.Prestandamått: Vi rekommenderar att du använder prestandamätningsövningen för att mata in stora mängder data. Den här metoden varierar parametrar, till exempel partitionering, grad av parallellitet och antalet filer för att fastställa den optimala inställningen för den angivna arkitekturen, volymen och typen av data. Samla in data från tester i följande format.


Felsökning
För långsam eller misslyckad extrahering från SAP-systemet använder du SAP-loggar från SM37 och matchar dem med avläsningarna i Data Factory.
Om bara ett batchjobb utlöses anger du att SAP-källpartitionerna ska ha bättre prestanda i dataflödet för mappning i Data Factory. Mer information finns i steg 6 i Mappa dataflödesegenskaper.
Om flera batchjobb utlöses i SAP-systemet och det finns en betydande skillnad mellan starttiden för varje batchjobb ändrar du storleken på Azure IR. När du ökar antalet drivrutinsnoder i Azure IR ökar parallelliteten för batchjobb på SAP-sidan.
Anteckning
Det maximala antalet drivrutinsnoder för Azure IR är 16. Varje drivrutinsnod kan bara utlösa en batchprocess.
Kontrollera loggarna i SHIR. Om du vill visa loggar går du till den virtuella SHIR-datorn. Öppna Loggboken > Program och tjänstloggar > Anslutningsappar > Integration Runtime.
Om du vill skicka loggar till support går du till den virtuella SHIR-datorn. Öppna Integration Runtime konfigurationshanteraren > Diagnostik > skicka loggar. Den här åtgärden skickar loggarna från de senaste sju dagarna och ger dig ett rapport-ID. Du behöver det här rapport-ID:t och RunId för din körning. Dokumentera rapport-ID:t för framtida referens.
När du använder SAP CDC-anslutningsappen i ett SLT-scenario:
Se till att kraven uppfylls. Roller krävs för SAP Landscape Transformation-användaren (SLT), till exempel ADFSLTUSER i OLTP-system eller ECC för att SLT-replikering ska fungera. Mer information finns i Vilka auktoriseringar och roller som behövs.
Om fel inträffar i ett SLT-scenario kan du läsa rekommendationerna för analys. Isolera och testa scenariot i SAP-lösningen först. Testa den till exempel utanför Data Factory genom att köra testprogrammet som tillhandahålls av SAP
RODPS_REPL_TESTi SE38. Om problemet finns på SAP-sidan får du samma fel när du använder rapporten. Du kan analysera dataextraheringen i SAP med hjälp av transaktionskodenODQMON.Om replikeringen fungerar när du använder den här testrapporten, men inte med Data Factory, kontaktar du Azure- eller Data Factory-supporten.
I följande exempel visas en rapport för
RODPS_REPL_TESTi SE38: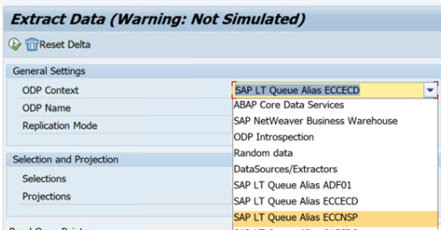
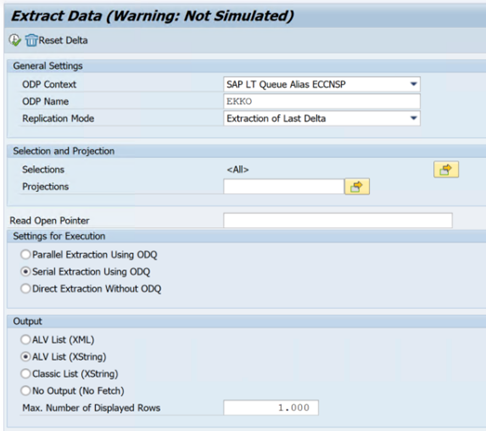

I följande exempel visas transaktionskoden
ODQMON: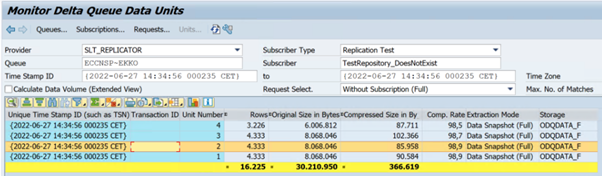
När den länkade Data Factory-tjänsten ansluter till SLT-systemet visas inte SLT-massöverförings-ID:t när du uppdaterar fältet Kontext .
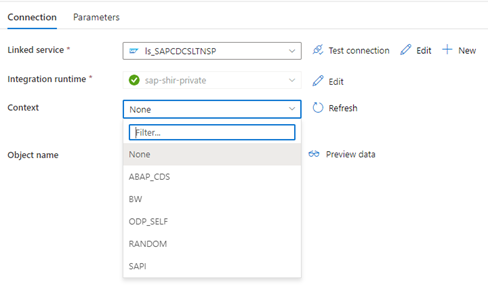
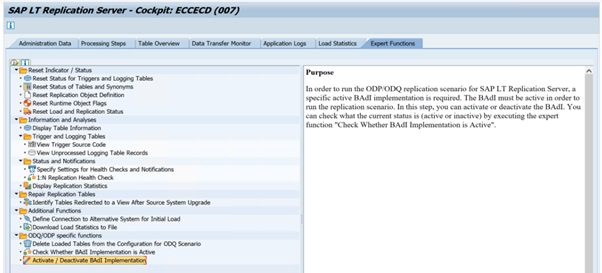
Om du vill köra ODP/ODQ-replikeringsscenariot för SAP LT Replication Server aktiverar du följande BAdI-implementering (business add-in).
Badi:
BADI_ODQ_QUEUE_MODELImplementering av förbättringar:
ODQ_ENH_SLT_REPLICATIONI transaktions-LTRC går du till fliken Expertfunktion och väljer Aktivera/Inaktivera BAdI-implementering för att aktivera implementeringen.
Välj Ja.
I mappen ODQ/ODP-specifika funktioner väljer du Kontrollera om BAdI-implementering är aktiv.

Dialogrutan visar programaktiviteten.
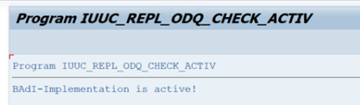
Återställ prenumerationer. Om du vill börja med en ny extrahering eller stoppa replikeringsdata tar du bort prenumerationen i ODQMON. Den här åtgärden tar också bort poster från LTRC. När du har återställt prenumerationen kan det ta några minuter innan du ser effekten i LTRC. Schemalägg odp-hushållningsjobb (Operational Data Provisioning) för att hålla deltaköerna rena, till exempel
ODQ_CLEANUP_CLIENT_004CDS_VIEW (DHCDCMON-transaktion). Från och med S/4HANA 1909 replikerar SAP data från CDS-vyer som använder databaserade utlösare i stället för datumkolumner. Konceptet liknar SLT, men i stället för att använda LTRC-transaktionen för att övervaka den använder du DHCDCMON-transaktionen.
Felsökning av SLT
SLT Replication Server tillhandahåller datareplikering i realtid från SAP-källor och/eller icke-SAP-källor till SAP-mål och/eller icke-SAP-mål. Det finns tre typer av verktygsuppsättningar för att övervaka extrahering från SLT till Azure.
- ODQMON är det övergripande övervakningsverktyget för dataextrahering. Starta analysen med ODQMON för att spåra inkonsekvenser i data, inledande prestandaanalys och öppna prenumerations- och extraheringsbegäranden.
- LTRC är den transaktion som ska användas för att kontrollera prestandaanalys. Det är användbart om du har problem med datareplikering från källsystemet till ODP eftersom du kan övervaka dataflödet och hitta inkonsekvenser.
- SM37 tillhandahåller detaljerad övervakning av varje SLT-extraheringssteg.
Normal hushållning bör göras med ODQMON där du kan hantera prenumerationen direkt och du inte bör använda LTRC för samma sak.
Du kan stöta på problem när du extraherar data från SLT, till exempel:
Extraheringen körs inte. Kontrollera om SAP CDC-anslutningen har skapat en anslutning i ODQMON och kontrollera om prenumerationen finns.
Datainkonsekvenser. Kontrollera ODQMON för att se den enskilda begäran om data och bekräfta att du kan se data där. Om du kan se data i ODQMON men inte i Azure Synapse eller Data Factory bör undersökningen ske på Azure-sidan. Om du inte kan se data i ODQMON utför du en analys av SLT-ramverket med hjälp av LTRC.
Prestandaproblem. Dataextrahering är en metod i två steg. Först läser SLT data från källsystemet och överför dem till ODP. För det andra hämtar SAP CDC-anslutningsappen data från ODP och överför dem till det valda datalagret. Med LTRC-transaktionen kan du analysera den första delen av extraheringsprocessen. Om du vill analysera dataextraheringen från ODP till Azure använder du ÖVERVAKNINGsverktygen ODQMON och Data Factory eller Synapse.
Anteckning
Mer information finns i följande resurser:
SLT-prestanda
I det inledande inläsningsläget (ODPSLT) finns det tre steg för att extrahera data från SLT till ODP:
- Skapa migreringsobjekt. Den här processen tar bara några sekunder.
- Få åtkomst till planberäkningen som delar upp källtabellen i mindre segment. Det här steget beror på det inledande inläsningsläget som du väljer under SLT-konfigurationen och tabellens storlek. Det resursoptimerade alternativet rekommenderas.
- Datainläsningen överför data från källsystemet till ODP.
Varje steg styrs av bakgrundsjobben. Du kan använda transaktionerna SM37 och LTRC för att övervaka varaktigheten. Om systemet är överanvänd kan bakgrundsjobben starta senare eftersom det inte finns tillräckligt med kostnadsfria batcharbetsprocesser. När aktiviteter är inaktiva blir prestandan sämre.
Om beräkningen av åtkomstplanen tar lång tid och det inledande inläsningsläget är inställt på "prestandaoptimerad" ändrar du det till "resursoptimerad" och kör extraheringen igen. Om datainläsningen tar lång tid ökar du antalet parallella trådar i konfigurationen.
Om du använder en fristående arkitektur för SLT-replikering (dedikerad SLT-replikeringsserver) kan nätverkets dataflöde mellan källsystemet och replikeringsservern påverka extraheringsprestandan.
För replikering:
- Se till att du har tillräckligt med dataöverföringsjobb som inte är reserverade för den första inläsningen.
- Kontrollera att du inte har någon obehandlad loggningstabellpost i inläsningsstatistiken.
- Kontrollera att replikeringsalternativet är inställt på realtid.
Avancerade replikeringsinställningar är tillgängliga i LTRS. Mer information finns i felsökningsguiden för SLT.
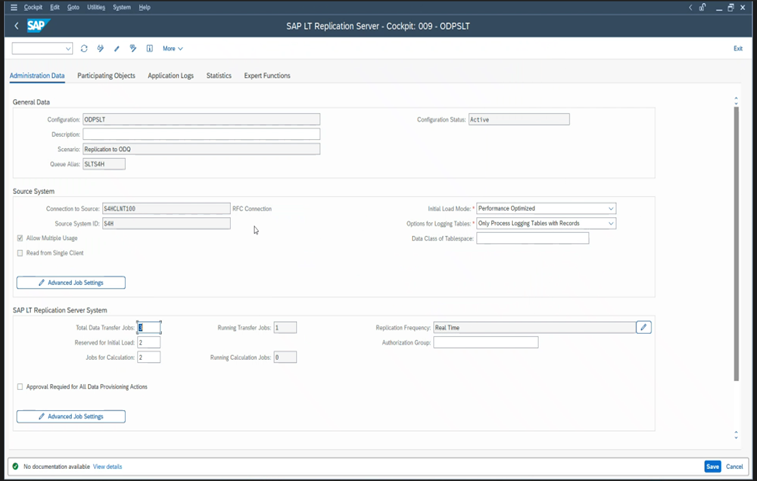
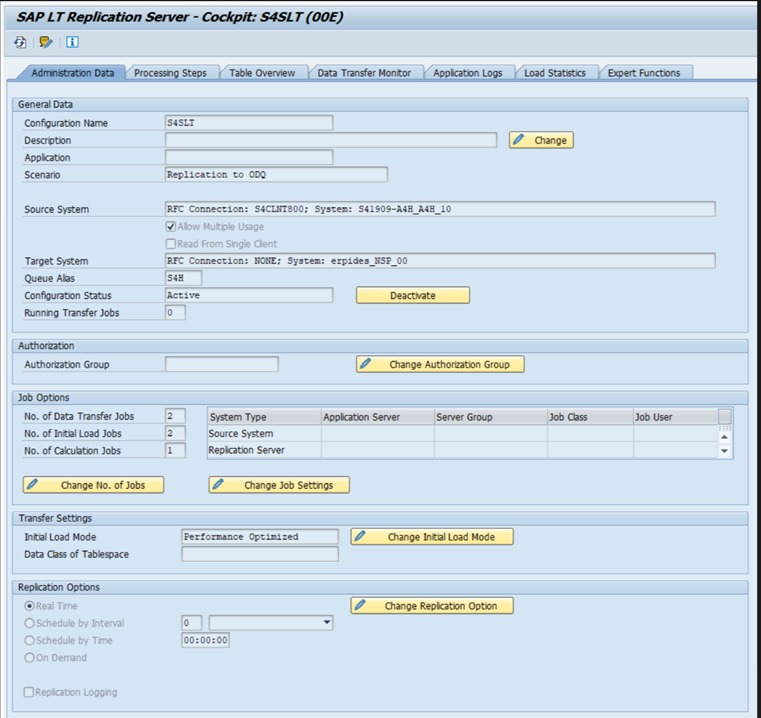
Olika SAP-versioner har olika LTRC-användargränssnitt. Följande skärmbilder visar samma sida för två olika versioner.
SAP S/4HANA:
SAP ECC:


Monitor
Information om hur du övervakar SAP-dataextraheringen finns i följande resurser: