Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Azure Data Explorer är en fullständigt hanterad stordataanalysplattform med höga prestanda som gör det enkelt att analysera stora mängder data nästan i realtid. Med verktygslådan Azure Data Explorer får du en lösning från slutpunkt till slutpunkt för datainmatning, frågor, visualisering och hantering.
Genom att analysera strukturerade, halvstrukturerade och ostrukturerade data i tidsserier, och med hjälp av Machine Learning, gör Azure Data Explorer det enkelt att extrahera viktiga insikter, spotmönster och trender och skapa prognosmodeller. Azure Data Explorer använder en traditionell relationsmodell som organiserar data i tabeller med starkt skrivna scheman. Tabeller lagras i databaser och ett kluster kan hantera flera databaser. Azure Data Explorer är skalbart, säkert, robust och företagsklart och är användbart för logganalys, tidsserieanalys, IoT och generella undersökande analyser.
Funktionerna i Azure Data Explorer utökas av andra tjänster som bygger på dess frågespråk: Kusto Query Language (KQL). Dessa tjänster omfattar Azure Monitor-loggar, Application Insights, Time Series Insights och Microsoft Defender för Endpoint.
När ska du använda Azure Data Explorer?
Använd följande frågor för att avgöra om Azure Data Explorer är rätt för ditt användningsfall:
- Interaktiv analys: Är interaktiv analys en del av lösningen? Till exempel aggregering, korrelation eller avvikelseidentifiering.
- Variation, hastighet, volym: Är ditt schema varierande? Behöver du mata in enorma mängder data nästan i realtid?
- Dataorganisation: Vill du analysera rådata? Till exempel inte fullständigt kuraterat stjärnschema.
- Frågekonkurrens: Kommer flera användare eller processer att använda Azure Data Explorer?
- Build vs Buy: Planerar du att anpassa din dataplattform?
Azure Data Explorer är perfekt för att aktivera interaktiva analysfunktioner över hög hastighet, olika rådata. Använd följande beslutsträd för att avgöra om Azure Data Explorer passar dig:
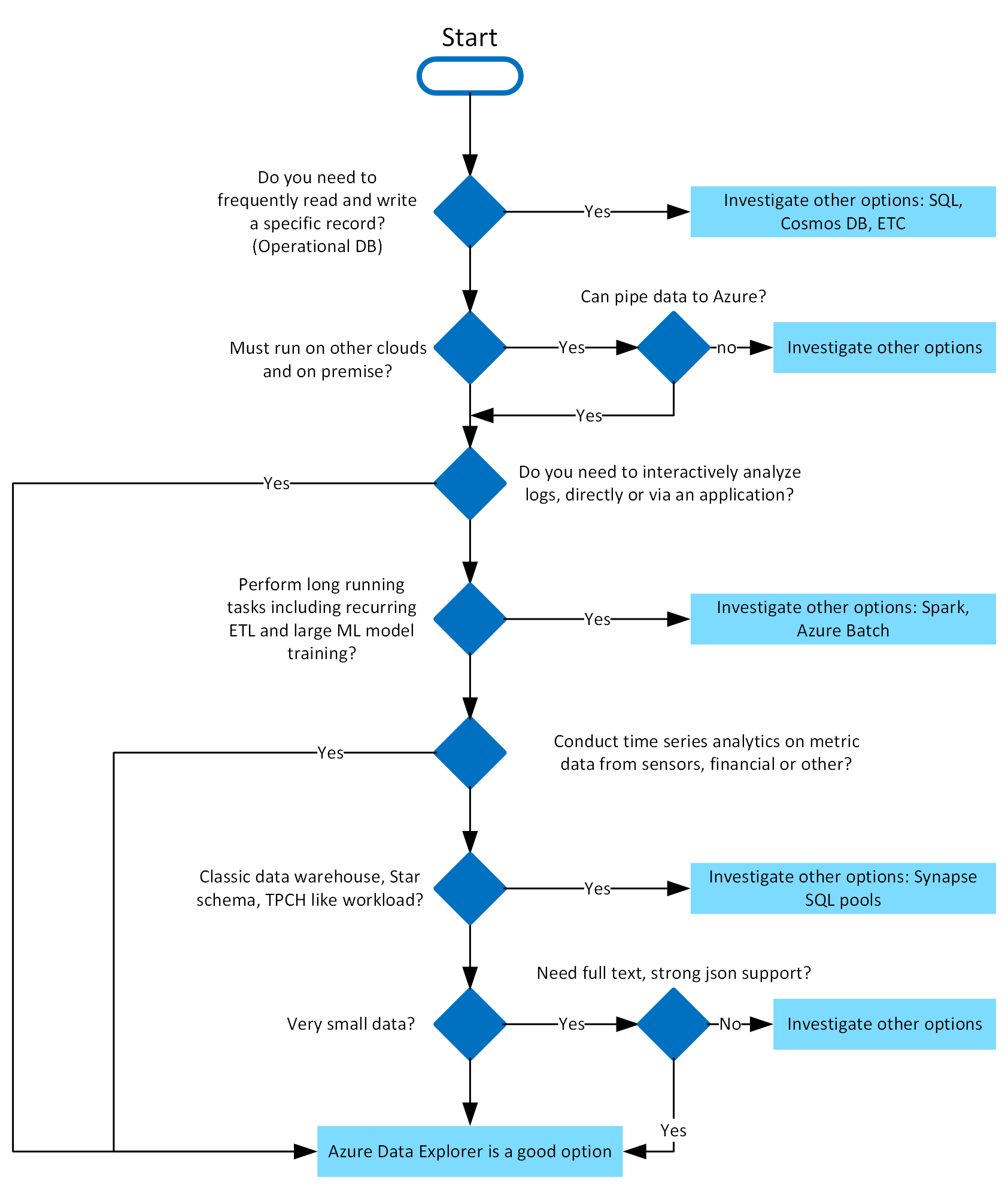
Vad gör Azure Data Explorer unikt?
Datahastighet, variation och volym
Med Azure Data Explorer kan du mata in terabyte data på några minuter via köad inmatning eller strömmande inmatning. Du kan fråga petabyte med data, med resultat som returneras inom millisekunder till sekunder. Azure Data Explorer ger hög hastighet (miljontals händelser per sekund), låg svarstid (sekunder) och linjär skalningsinmatning av rådata. Mata in dina data i olika format och strukturer som flödar från olika pipelines och källor.
Användarvänligt frågespråk
Fråga Azure Data Explorer med KQL (Kusto Query Language), ett språk med öppen källkod som ursprungligen uppfanns av teamet. Språket är enkelt att förstå och lära sig, och mycket produktivt. Du kan använda enkla operatorer och avancerad analys. Azure Data Explorer stöder även T-SQL.
Avancerad analys
Använd Azure Data Explorer för tidsserieanalys med en stor uppsättning funktioner, inklusive: lägga till och subtrahera tidsserier, filtrering, regression, säsongsidentifiering, geospatial analys, avvikelseidentifiering, genomsökning och prognostisering. Tidsseriefunktioner är optimerade för bearbetning av tusentals tidsserier i sekunder. Mönsteridentifiering är enkelt med plugin-program för kluster som kan diagnostisera avvikelser och göra rotorsaksanalyser. Du kan också utöka Funktionerna i Azure Data Explorer genom att bädda in Python-kod i KQL-frågor.
Lätthanterad guide
Datahämtningen gör datainmatningsprocessen enkel, snabb och intuitiv. Webbgränssnittet i Azure Data Explorer ger en intuitiv och guidad upplevelse som hjälper dig att snabbt börja mata in data, skapa databastabeller och mappningsstrukturer. Det möjliggör en gång eller kontinuerlig inmatning från olika källor och i olika dataformat. Tabellmappningar och scheman föreslås automatiskt och är enkla att ändra.
Mångsidig datavisualisering
Datavisualisering hjälper dig att få viktiga insikter. Azure Data Explorer erbjuder inbyggd visualisering och instrumentpaneler direkt, med stöd för olika diagram och visualiseringar. Den har intern integrering med Power BI, interna anslutningsappar för Grafana, Kibana och Databricks, ODBC-stöd för Tableau, Sisense, Qlik med mera.
Automatisk inmatning, process och export
Azure Data Explorer stöder lagrade funktioner på serversidan, kontinuerlig inmatning och kontinuerlig export till Azure Data Lake Store. Det stöder också inmatningstidsmappningstransformeringar på serversidan, uppdateringsprinciper och förberäknade schemalagda aggregeringar med materialiserade vyer.
Azure Data Explorer-flöde
Följande diagram visar de olika aspekterna av att arbeta med Azure Data Explorer.
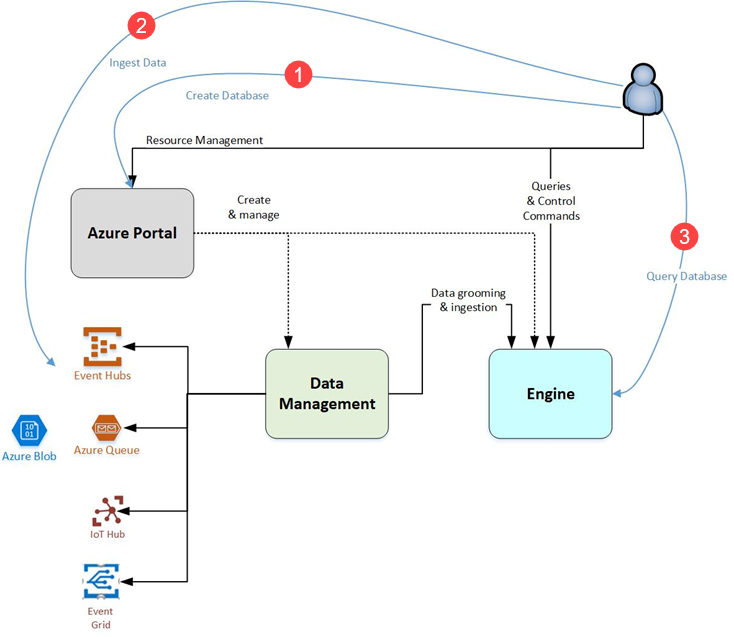
När du interagerar med Azure Data Explorer går du vanligtvis igenom följande arbetsflöde:
Anmärkning
Du kan komma åt dina Azure Data Explorer-resurser antingen i Azure Data Explorer-webbgränssnittet eller med hjälp av SDK:er.
Skapa databas: Skapa ett kluster och skapa sedan en eller flera databaser i klustret. Varje Azure Data Explorer-kluster kan innehålla upp till 10 000 databaser och varje databas upp till 10 000 tabeller. Data i varje tabell lagras i datashards som även kallas "omfattningar". Alla data indexeras och partitioneras automatiskt baserat på inmatningstiden. Det innebär att du kan lagra en stor mängd varierande data, och på grund av hur det lagras får du snabb åtkomst till att söka i det. Snabbstart: Skapa ett Azure Data Explorer-kluster och en databas
Importera data: Läs in data i databastabeller så att du kan utföra frågor på dem. Azure Data Explorer har stöd för flera inmatningsmetoder, var och en med sina egna målscenarier. Dessa metoder omfattar inmatningsverktyg, anslutningsappar och plugin-program till olika tjänster, hanterade pipelines, programmatisk inmatning med SDK:er och direkt åtkomst till inmatning. Kom igång med att hämta data.
Frågedatabas: Azure Data Explorer använder Kusto Query Language, som är ett uttrycksfullt, intuitivt och mycket produktivt frågespråk. Den erbjuder en smidig övergång från enkla one-liners till komplexa databearbetningsskript och stöder frågor mot strukturerade, halvstrukturerade och ostrukturerade data (textsökning). Det finns en mängd olika frågespråksoperatorer och funktioner (sammansättning, filtrering, tidsseriefunktioner, geospatiala funktioner, kopplingar, fackföreningar med mera) på språket. KQL stöder frågor mellan kluster och mellan databaser och är funktionsrika ur ett parsningsperspektiv (json, XML med mera). Språket har också inbyggt stöd för avancerad analys.
Använd webbprogrammet för att köra, granska och dela frågor och resultat. Du kan också skicka frågor programmatiskt (med hjälp av ett SDK) eller till en REST API-slutpunkt. Om du är bekant med SQL kan du komma igång med fuskbladet SQL till Kusto och Snabbstart: Fråga efter data i Azure Data Explorer-webbgränssnittet.
Visualisera resultat: Använd olika visuella visningar av dina data i de interna Instrumentpanelerna i Azure Data Explorer. Du kan också visa dina resultat med hjälp av anslutningsappar till några av de ledande visualiseringstjänsterna, till exempel Power BI och Grafana. Azure Data Explorer har även stöd för ODBC - och JDBC-anslutningsprogram till verktyg som Tableau och Sisense.
Så här ger du feedback
Det vore spännande att höra din feedback om Azure Data Explorer och Kusto Query Language på: