Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
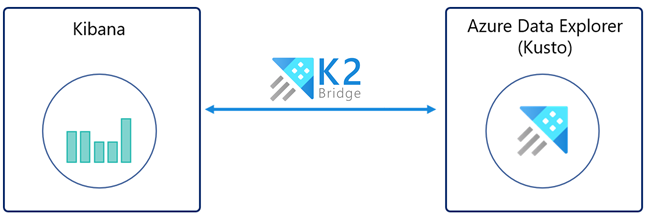
Med K2Bridge (Kibana-Kusto Bridge) kan du använda Azure Data Explorer som datakälla och visualisera dessa data i Kibana. K2Bridge är ett containerbaserat program med öppen källkod. Den fungerar som en proxy mellan en Kibana-instans och ett Azure Data Explorer-kluster. Den här artikeln beskriver hur du använder K2Bridge för att skapa den anslutningen.
K2Bridge översätter Kibana-frågor till Kusto Query Language (KQL) och skickar Azure Data Explorer-resultaten tillbaka till Kibana.
K2Bridge stöder Flikarna Identifiera, Visualisera och Instrumentpanel i Kibana.
Med fliken Identifiera kan du:
- Sök efter och utforska data.
- Filtrera resultat.
- Lägg till eller ta bort fält i resultatrutnätet.
- Visa postinnehåll.
- Spara och dela sökningar.
Med fliken Visualisera kan du:
- Skapa visualiseringar som: stapeldiagram, cirkeldiagram, datatabeller, värmekartor med mera.
- Spara en visualisering
På fliken Instrumentpanel kan du:
- Skapa paneler med hjälp av nya eller sparade visualiseringar.
- Spara en instrumentpanel.
Följande bild visar en Kibana-instans som är bunden till Azure Data Explorer av K2Bridge. Användarupplevelsen i Kibana är oförändrad.

Förutsättningar
Innan du kan visualisera data från Azure Data Explorer i Kibana måste du ha följande redo:
- Ett Azure-abonnemang. Skapa ett kostnadsfritt Azure-konto.
- Ett Azure Data Explorer-kluster och en databas. Du behöver klustrets URL och databasnamnet.
- Helm v3, pakethanterare för Kubernetes.
- Azure Kubernetes Service-kluster (AKS) eller något annat Kubernetes-kluster. Använd version 1.21.2 eller senare, med minst tre Azure Kubernetes Service-noder. Version 1.21.2 har testats och verifierats. Om du behöver ett AKS-kluster kan du se hur du distribuerar ett AKS-kluster med hjälp av Azure CLI eller använder Azure-portalen.
- Ett Microsoft Entra-tjänsthuvudnamn som har behörighet att visa data i Azure Data Explorer, inklusive klient-ID och klienthemlighet. Du kan också använda en systemtilldelad hanterad identitet.
Om du väljer att använda ett tjänsthuvudnamn för Microsoft Entra måste du skapa ett tjänsthuvudnamn för Microsoft Entra. För installationen behöver du ClientID och en hemlighet. Vi rekommenderar ett huvudnamn för tjänsten med visningsbehörighet och avråder dig från att använda behörigheter på högre nivå. Information om hur du tilldelar behörigheter finns i Hantera databasbehörigheter i Azure-portalen eller använd hanteringskommandon för att hantera databassäkerhetsroller.
Om du väljer att använda en systemtilldelad identitet måste du hämta agentpoolens hanterade identitet ClientID (finns i den genererade resursgruppen "[MC_xxxx]"
Kör K2Bridge på Azure Kubernetes Service (AKS)
Som standard refererar Helm-diagrammet i K2Bridge till en offentligt tillgänglig avbildning som finns i Microsoft Container Registry (MCR). MCR kräver inga autentiseringsuppgifter.
Ladda ned nödvändiga Helm-diagram.
Lägg till Elasticsearch-beroendet till Helm. Beroendet krävs eftersom K2Bridge använder en liten intern Elasticsearch-instans. Instanstjänsten hanterar metadatarelaterade begäranden såsom indexmönsterförfrågningar och sparade förfrågningar. Den här interna instansen sparar inga affärsdata. Du kan betrakta instansen som en implementationsdetalj.
Om du vill lägga till Elasticsearch-beroendet i Helm kör du följande kommandon:
helm repo add elastic https://helm.elastic.co helm repo updateSå här hämtar du K2Bridge-diagrammet från diagramkatalogen på GitHub-lagringsplatsen:
Klona lagringsplatsen från GitHub.
Gå till katalogen för K2Bridges-rotlagringsplatsen.
Kör det här kommandot:
helm dependency update charts/k2bridge
Distribuera K2Bridge.
Ange variablerna till rätt värden för din miljö.
ADX_URL=[YOUR_ADX_CLUSTER_URL] #For example, https://mycluster.westeurope.kusto.windows.net ADX_DATABASE=[YOUR_ADX_DATABASE_NAME] ADX_CLIENT_ID=[SERVICE_PRINCIPAL_CLIENT_ID] ADX_CLIENT_SECRET=[SERVICE_PRINCIPAL_CLIENT_SECRET] ADX_TENANT_ID=[SERVICE_PRINCIPAL_TENANT_ID]Anmärkning
När du använder en hanterad identitet är det ADX_CLIENT_ID värdet klient-ID:t för den hanterade identiteten, som finns i den genererade resursgruppen "[MC_xxxx]". Mer information finns i MC_ resursgrupp. ADX_SECRET_ID krävs endast om du använder en tjänsthuvudprincip för Microsoft Entra.
Du kan också aktivera Application Insights-telemetri. Om du använder Application Insights för första gången skapar du en Application Insights-resurs. Kopiera instrumentationsnyckeln till en variabel.
APPLICATION_INSIGHTS_KEY=[INSTRUMENTATION_KEY] COLLECT_TELEMETRY=trueInstallera K2Bridge-diagrammet. Visualiseringar och instrumentpaneler stöds endast med Kibana 7.10-versionen. De senaste bildtaggar är: 6.8_latest och 7.16_latest, som stöder Kibana 6.8 respektive Kibana 7.10. Bilden av "7.16_latest" stöder Kibana OSS 7.10.2 och dess interna Elasticsearch-instans är 7.16.2.
Om ett Huvudnamn för Microsoft Entra-tjänsten användes:
helm install k2bridge charts/k2bridge -n k2bridge --set settings.adxClusterUrl="$ADX_URL" --set settings.adxDefaultDatabaseName="$ADX_DATABASE" --set settings.aadClientId="$ADX_CLIENT_ID" --set settings.aadClientSecret="$ADX_CLIENT_SECRET" --set settings.aadTenantId="$ADX_TENANT_ID" [--set image.tag=6.8_latest/7.16_latest] [--set image.repository=$REPOSITORY_NAME/$CONTAINER_NAME] [--set privateRegistry="$IMAGE_PULL_SECRET_NAME"] [--set settings.collectTelemetry=$COLLECT_TELEMETRY]Eller om hanterad identitet användes:
helm install k2bridge charts/k2bridge -n k2bridge --set settings.adxClusterUrl="$ADX_URL" --set settings.adxDefaultDatabaseName="$ADX_DATABASE" --set settings.aadClientId="$ADX_CLIENT_ID" --set settings.useManagedIdentity=true --set settings.aadTenantId="$ADX_TENANT_ID" [--set image.tag=7.16_latest] [--set settings.collectTelemetry=$COLLECT_TELEMETRY]I Konfiguration hittar du den fullständiga uppsättningen konfigurationsalternativ.
Utdata från det föregående kommandot föreslår nästa Helm-kommando för att distribuera Kibana. Du kan också köra det här kommandot:
helm install kibana elastic/kibana --version 7.17.3 -n k2bridge --set image=docker.elastic.co/kibana/kibana-oss --set imageTag=7.10.2 --set elasticsearchHosts=http://k2bridge:8080Använd portvidarebefordring för att få åtkomst till Kibana på localhost.
kubectl port-forward service/kibana-kibana 5601 --namespace k2bridgeAnslut till Kibana genom att gå till http://127.0.0.1:5601.
Exponera Kibana för användare. Det finns flera metoder för att göra det. Vilken metod du använder beror till stor del på ditt användningsfall.
Du kan till exempel exponera tjänsten som en Load Balancer-tjänst. Det gör du genom att lägga till parametern --set service.type=LoadBalancer i det tidigare Kibana Helm-installationskommandot.
Kör sedan det här kommandot:
kubectl get service -w -n k2bridgeResultatet bör se ut så här:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kibana-kibana LoadBalancer xx.xx.xx.xx <pending> 5601:30128/TCP 4m24sDu kan sedan använda det genererade EXTERNAL-IP-värdet som visas. Använd den för att komma åt Kibana genom att öppna en webbläsare och gå till <EXTERNAL-IP>:5601.
Konfigurera indexmönster för åtkomst till dina data.
I en ny Kibana-instans:
- Öppna Kibana.
- Navigera till Hantering.
- Välj Indexmönster.
- Skapa ett indexmönster. Indexets namn måste exakt matcha tabellnamnet eller funktionsnamnet utan en asterisk (*). Du kan kopiera relevant rad från listan.
Anmärkning
Om du vill köra K2Bridge på andra Kubernetes-leverantörer ändrar du värdet Elasticsearch storageClassName i values.yaml så att det matchar det som föreslås av providern.
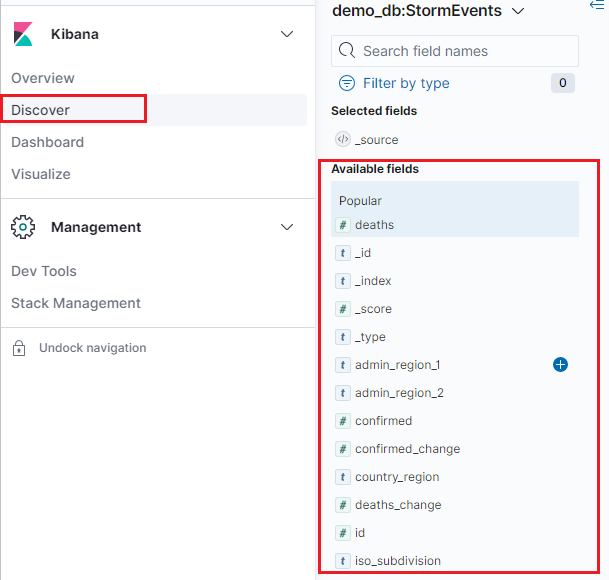
Upptäck data
När Azure Data Explorer har konfigurerats som en datakälla för Kibana kan du använda Kibana för att utforska data.
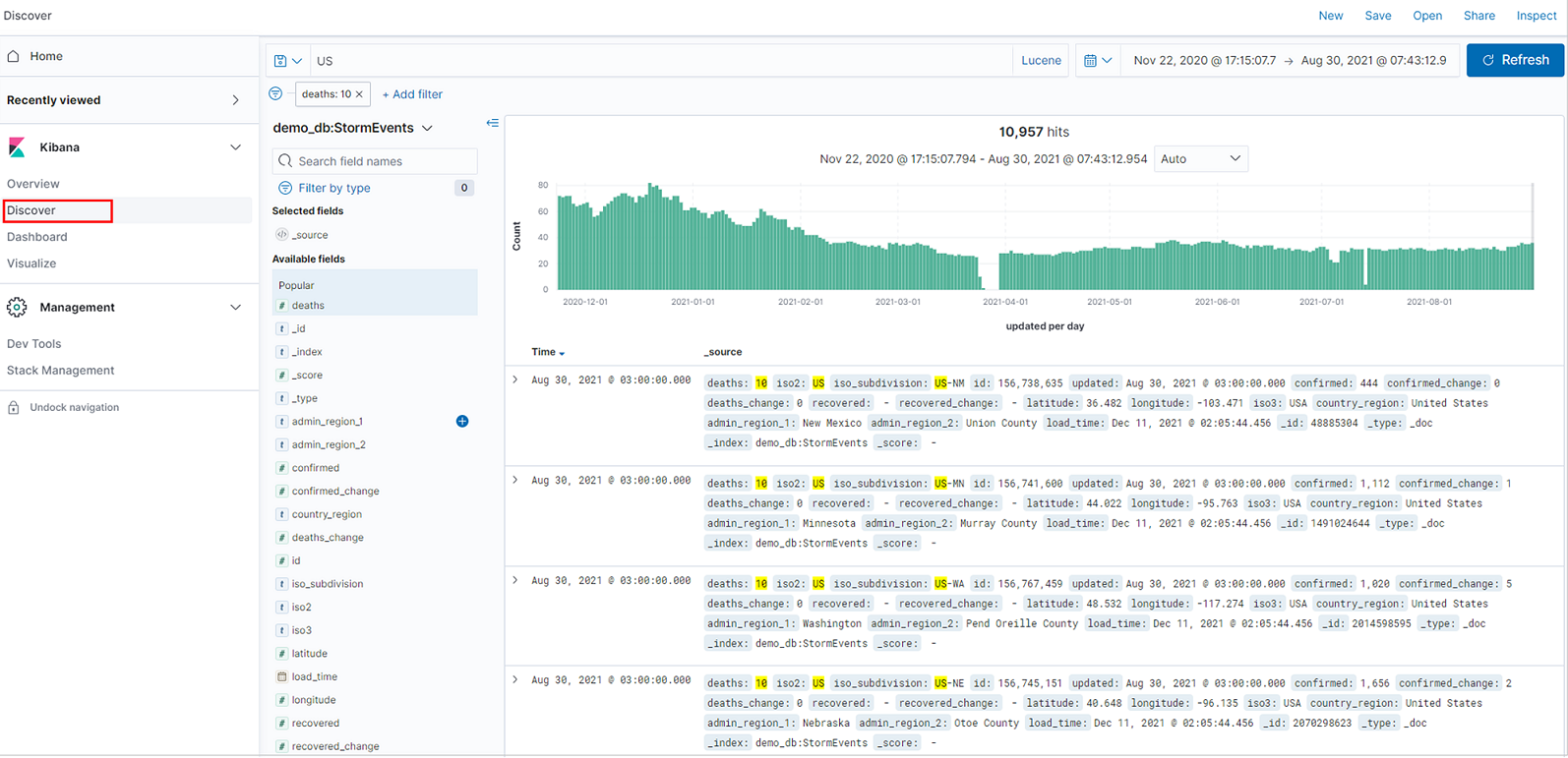
I Kibana väljer du fliken Identifiera .
I listan med indexmönster väljer du ett indexmönster som definierar den datakälla som ska utforskas. Här är indexmönstret en Azure Data Explorer-tabell.
Om dina data har ett tidsfilterfält kan du ange tidsintervallet. Välj ett tidsfilter längst upp till höger på sidan Identifiera . Som standard visar sidan data för de senaste 15 minuterna.

Resultattabellen visar de första 500 posterna. Du kan expandera ett dokument för att undersöka fältdata i antingen JSON- eller tabellformat.
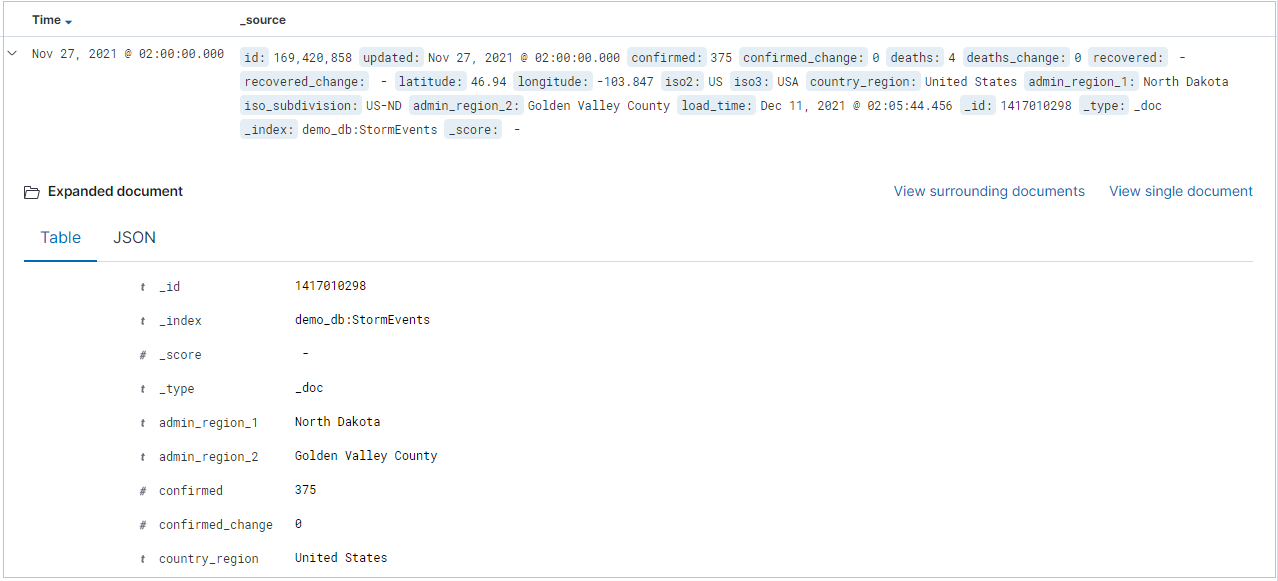
Du kan lägga till specifika kolumner i resultattabellen genom att välja lägg till bredvid fältnamnet. Som standard innehåller resultattabellen kolumnen _source och en tidskolumn om tidsfältet finns.
I frågefältet kan du söka efter data genom att:
- Ange en söktermen.
- Använda Lucene-frågesyntaxen. Till exempel:
- Sök efter "fel" för att hitta alla poster som innehåller det här värdet.
- Sök efter "status: 200" för att hämta alla poster med statusvärdet 200.
- Använda de logiska operatorerna AND, OR och NOT.
- Använd jokertecknet asterisk (*) och frågetecken (?). Frågan "destination_city: L*" matchar till exempel poster där värdet för målort börjar med "L" eller "l". (K2Bridge är inte skiftlägeskänsligt.)

Anmärkning
Endast kibanas Lucene-frågesyntax stöds. Använd inte KQL-alternativet, som står för Kibana Query Language.
Tips/Råd
I Söka kan du hitta fler sökregler och logik.
Om du vill filtrera sökresultaten använder du listan Tillgängliga fält . Fältlistan är den plats där du kan se:
- De fem översta värdena för fältet.
- Antalet poster som innehåller fältet.
- Procentandelen poster som innehåller varje värde.
Tips/Råd
Använd förstoringsglaset för att hitta alla poster som har ett specifikt värde.
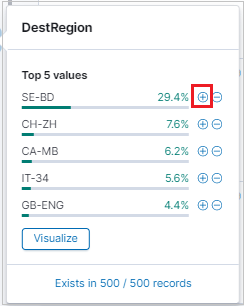
Du kan också använda förstoringsglaset för att filtrera resultat och se tabellvyn för varje post i resultattabellen.

Välj Spara eller Dela för att behålla sökningen.

Visualisera data
Använd Kibana-visualiseringar för att få en snabb överblick över Azure Data Explorer-data.
Skapa en visualisering från fliken Upptäck
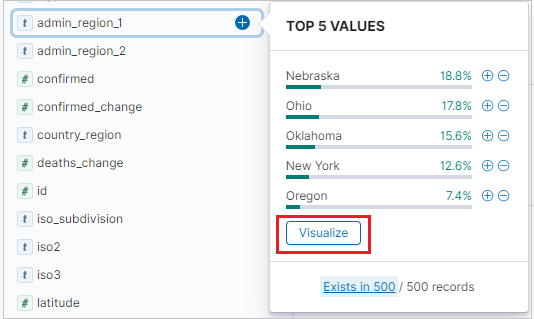
Om du vill skapa en lodrät stapelvisualisering går du till fliken Identifiera och letar upp sidofältet Tillgängliga fält .
Välj ett fältnamn och klicka sedan på Visualisera.
Fliken Visualisera öppnas och visar visualiseringen. Information om hur du redigerar data och mått för visualiseringen finns i Skapa en visualisering från fliken Visualisera.
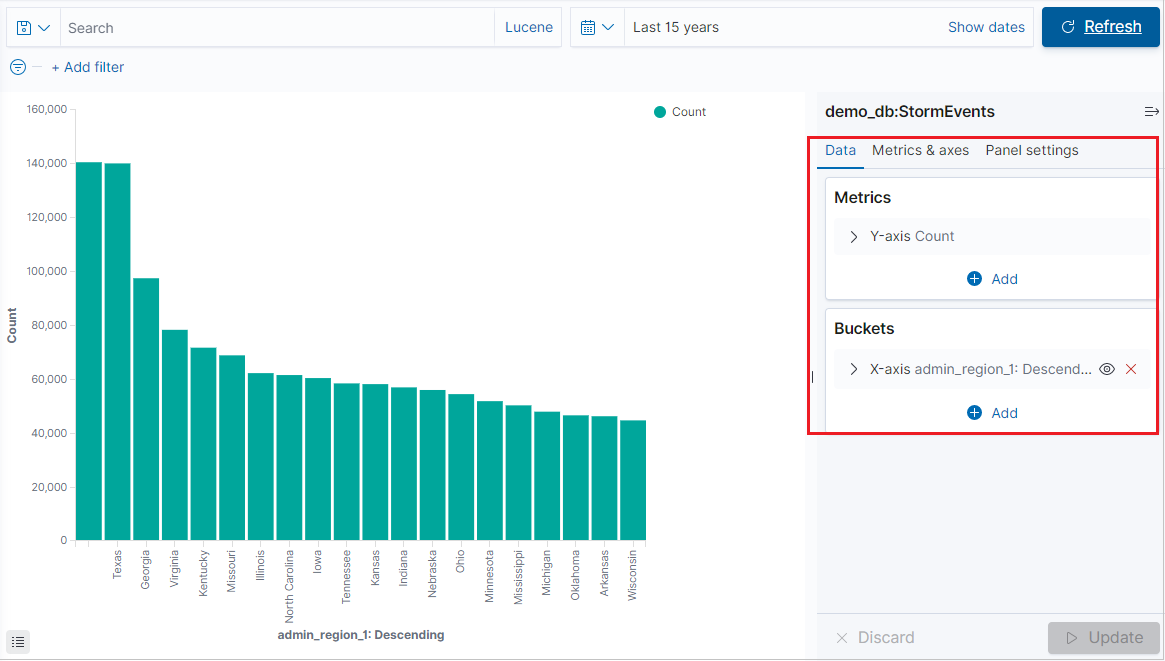
Skapa en visualisering från fliken Visualisera
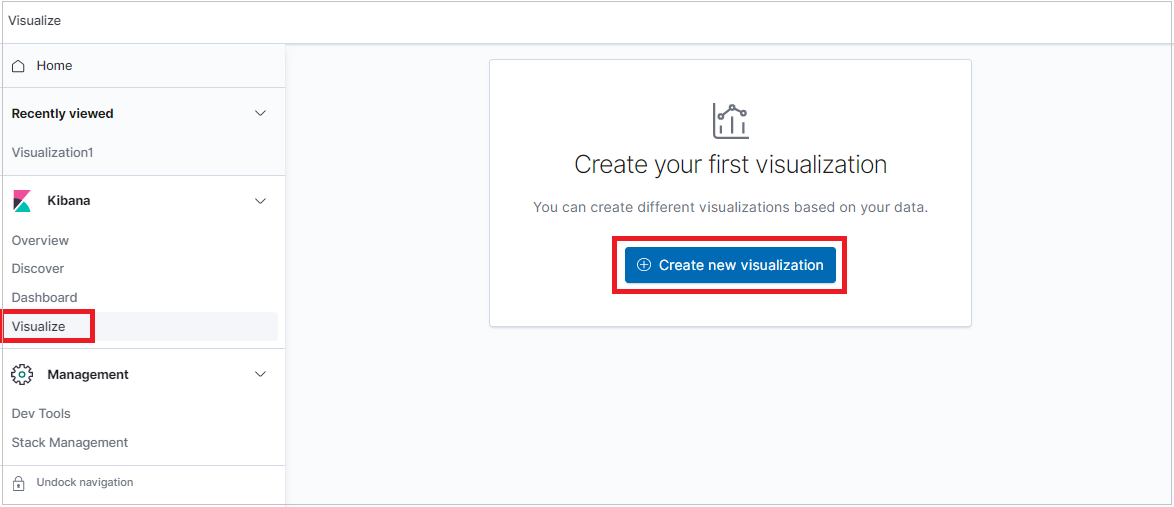
Välj fliken Visualisera och klicka på Skapa visualisering.
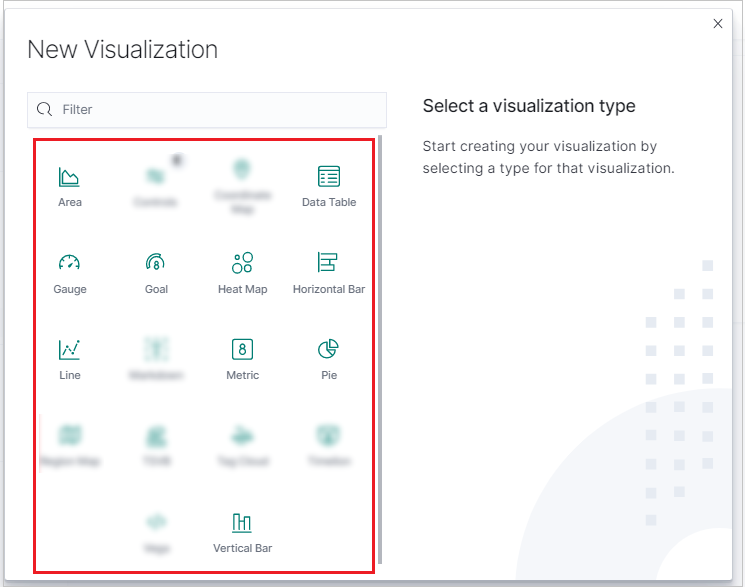
I fönstret Ny visualisering väljer du en visualiseringstyp.
När visualiseringen har genererats kan du redigera måtten och lägga till upp till en bucket.
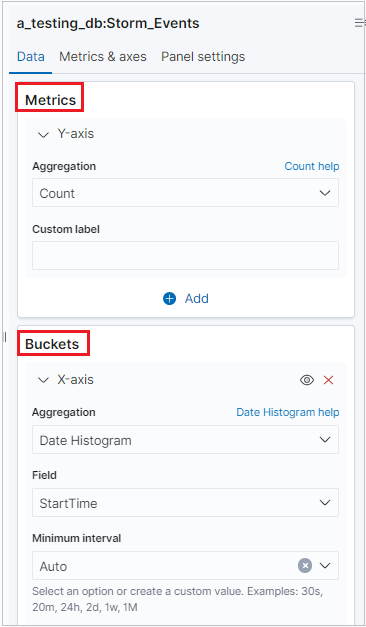
Anmärkning
K2Bridge stöder en bucketaggregering. Vissa sammansättningar stöder sökalternativ. Använd Lucene-syntaxen, inte KQL-alternativet, som står för Kibana Query Language-syntaxen.
Viktigt!
- Följande visualiseringar stöds:
Vertical bar,Area chart,Line chart,Horizontal bar,Pie chart,Gauge,Data table, ,Heat map,Goal chartochMetric chart. - Följande mått stöds:
Average,Count,Max,Median,Min,Percentiles,Standard deviation, ,SumTop hitsochUnique count. - Måttet
Percentiles ranksstöds inte. - Det är valfritt att använda bucketaggregeringar. Du kan visualisera data utan bucketaggregering.
- Följande bucketar stöds:
No bucket aggregation,Date histogram,Filters,Range,Date range, ochHistogramTerms. - Bucketarna
IPv4 rangeochSignificant termsstöds inte.
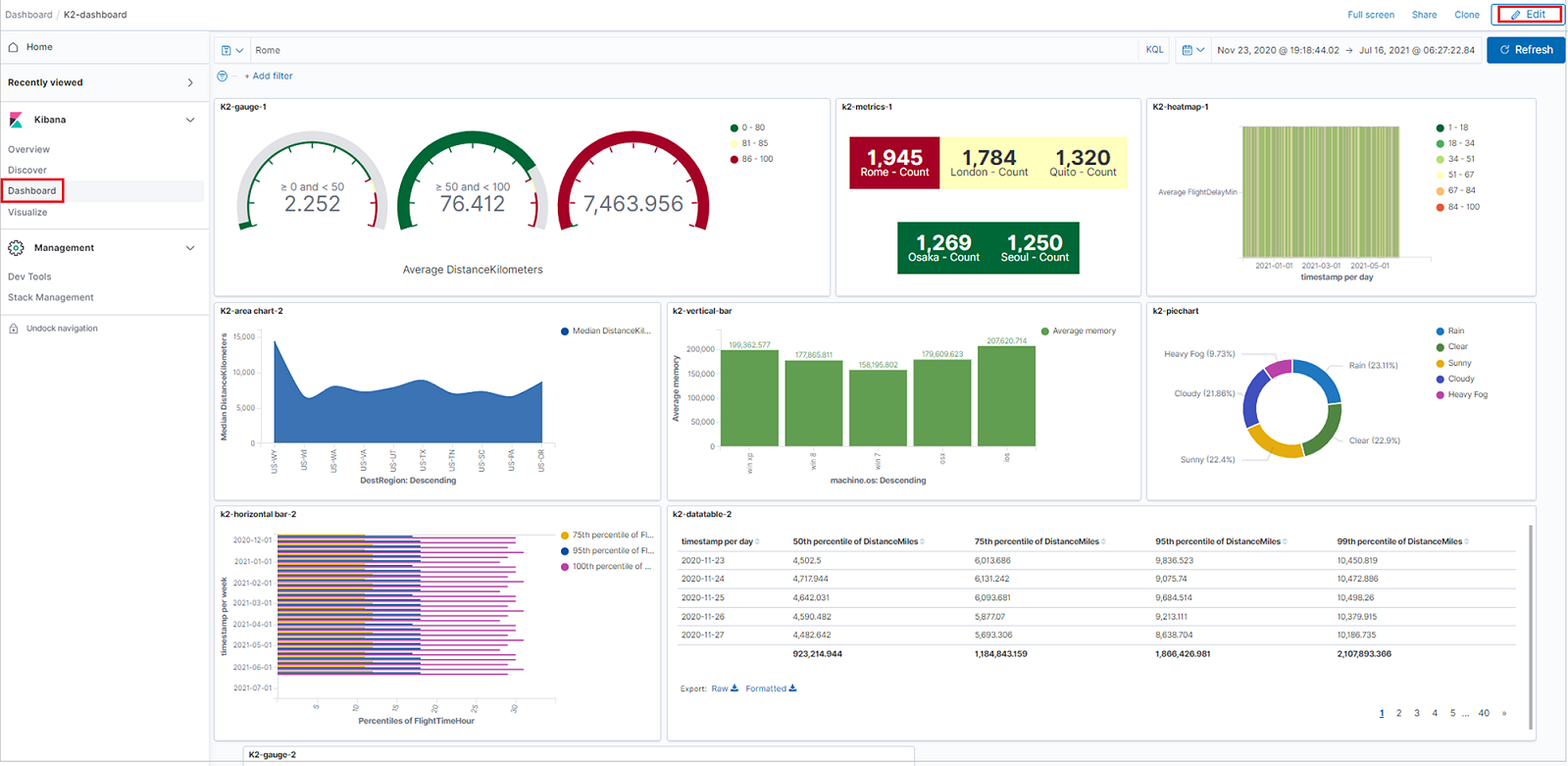
Skapa instrumentpaneler
Du kan skapa instrumentpaneler med Kibana-visualiseringar för att sammanfatta, jämföra och kontrastera vyer med en snabb överblick över Azure Data Explorer-data.
Om du vill skapa en instrumentpanel väljer du fliken Instrumentpanel och klickar sedan på Skapa ny instrumentpanel.
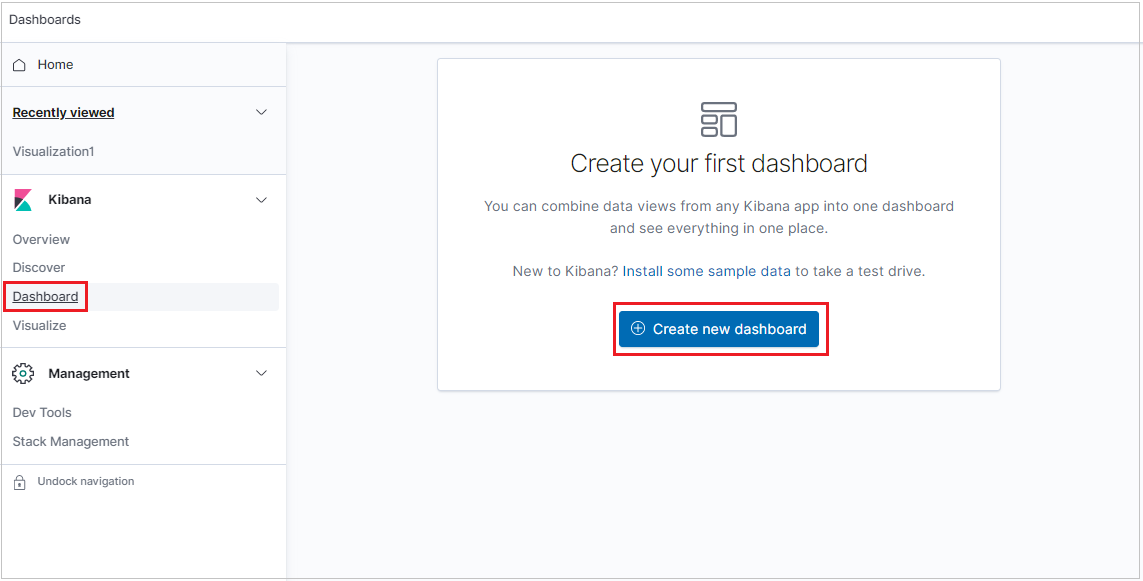
Den nya instrumentpanelen öppnas i redigeringsläge.
Om du vill lägga till en ny visualiseringspanel klickar du på Skapa ny.
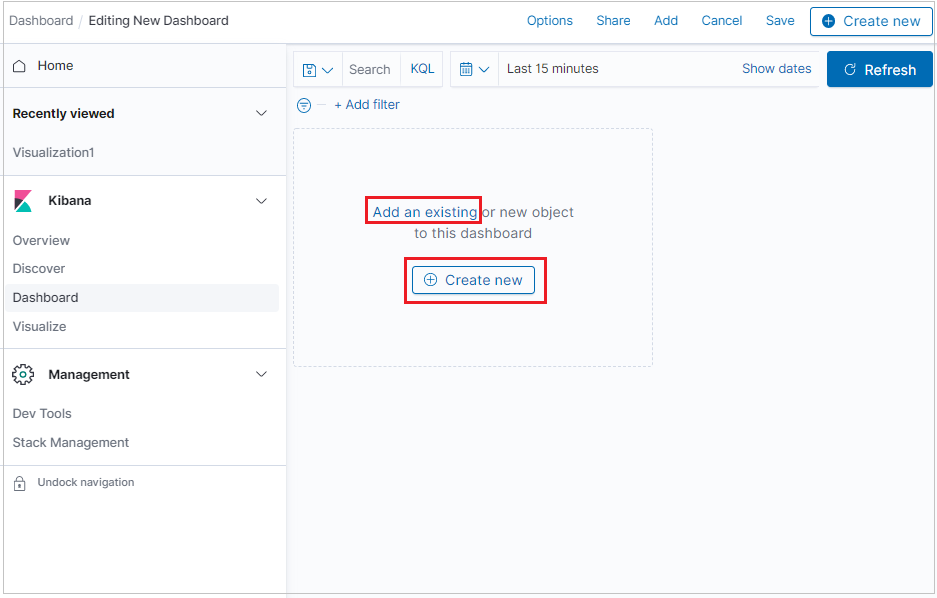
Om du vill lägga till en visualisering som du redan har skapat klickar du på Lägg till en befintlig och väljer en visualisering.
Ordna paneler genom att ordna paneler efter prioritet, ändra storlek på panelerna med mera, klicka på Redigera och sedan använda följande alternativ:
- Om du vill flytta en panel klickar du och håller ned panelrubriken och drar sedan till den nya platsen.
- Om du vill ändra storlek på en panel klickar du på storleksändringskontrollen och drar sedan till de nya dimensionerna.