Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Den här självstudien visar ett enkelt och effektivt sätt att implementera hög tillgänglighet och haveriberedskap (HA/DR) för Java med hjälp av WebSphere Application Server på virtuella Azure-datorer (VM). Lösningen visar hur du uppnår ett rto-mål (Low Recovery Time Objective) och Recovery Point Objective (RPO) med hjälp av ett enkelt databasdrivet Jakarta EE-program som körs på WebSphere Application Server. HA/DR är ett komplext ämne med många möjliga lösningar. Den bästa lösningen beror på dina unika krav. Andra sätt att implementera HA/DR finns i resurserna i slutet av den här artikeln.
I den här självstudien lär du dig att:
- Använd azure-optimerade metodtips för att uppnå hög tillgänglighet och haveriberedskap.
- Konfigurera en Redundansgrupp för Microsoft Azure SQL Database i parkopplade regioner.
- Konfigurera det primära WebSphere-klustret på virtuella Azure-datorer.
- Konfigurera haveriberedskap för klustret med Hjälp av Azure Site Recovery.
- Konfigurera en Azure Traffic Manager.
- Testa redundans från primär till sekundär.
Följande diagram illustrerar arkitekturen som du skapar:

Azure Traffic Manager kontrollerar hälsotillståndet för dina regioner och dirigerar trafiken enligt programnivån. Den primära regionen har en fullständig distribution av WebSphere-klustret. När den primära regionen har skyddats av Azure Site Recovery kan du återställa den sekundära regionen under redundansväxlingen. Därför underhåller den primära regionen aktivt nätverksbegäranden från användarna, medan den sekundära regionen är passiv och aktiverad för att endast ta emot trafik när den primära regionen upplever ett avbrott i tjänsten.
Azure Traffic Manager identifierar hälsotillståndet för appen som distribueras i IBM HTTP-servern för att implementera villkorsstyrd routning. RTO för geo-redundans på programnivån beror på tiden för att stänga av det primära klustret, återställa det sekundära klustret, starta virtuella datorer och köra det sekundära WebSphere-klustret. RPO är beroende av replikeringsprincipen för Azure Site Recovery och Azure SQL Database. Det här beroendet beror på att klusterdata lagras och replikeras i den lokala lagringen av de virtuella datorerna och att programdata sparas och replikeras i Azure SQL Database-redundansgruppen.
Föregående diagram visar primär region och sekundär region som de två regioner som består av HA/DR-arkitekturen. Dessa regioner måste vara Azure-kopplade regioner. Mer information om kopplade regioner finns i Replikering mellan regioner i Azure. Artikeln använder USA, östra och USA, västra som de två regionerna, men de kan vara valfria parkopplade regioner som passar ditt scenario. En lista över regionparningar finns i avsnittet Azure-kopplade regioner i Replikering mellan regioner i Azure.
Databasnivån består av en Azure SQL Database-redundansgrupp med en primär server och en sekundär server. Läs-/skrivlyssningsslutpunkten pekar alltid på den primära servern och är ansluten till WebSphere-klustret i varje region. En geo-redundansväxlar alla sekundära databaser i gruppen till den primära rollen. Geo-redundans-RPO och RTO för Azure SQL Database finns i Översikt över affärskontinuitet med Azure SQL Database.
Den här självstudien skrevs med Azure Site Recovery och Azure SQL Database-tjänsten eftersom självstudien förlitar sig på ha-funktionerna i dessa tjänster. Andra databasval är möjliga, men du måste överväga ha-funktionerna i vilken databas du än väljer.
Förutsättningar
- En Azure-prenumeration. Om du inte har en Azure-prenumeration kan du skapa ettkostnadsfritt konto innan du börjar.
- Kontrollera att du har
Contributorrollen i prenumerationen. Du kan verifiera tilldelningen genom att följa stegen i Lista Azure-rolltilldelningar med hjälp av Azure-portalen. - Förbered en lokal dator med Windows, Linux eller macOS installerat.
- Installera och konfigurera Git.
- Installera en Java SE-implementering, version 17 eller senare, till exempel Microsoft-versionen av OpenJDK.
- Installera Maven, version 3.9.3 eller senare.
Konfigurera en Azure SQL Database-redundansgrupp i parkopplade regioner
I det här avsnittet skapar du en Azure SQL Database-redundansgrupp i parkopplade regioner för användning med dina WebSphere-kluster och din app. I ett senare avsnitt konfigurerar du WebSphere så att dess sessionsdata lagras i den här databasen. Den här metoden refererar till Att skapa en tabell för sessionspersistence.
Skapa först den primära Azure SQL Database genom att följa stegen i Azure-portalen i Snabbstart: Skapa en enkel databas – Azure SQL Database. Följ stegen upp till, men inte inkludera, avsnittet "Rensa resurser". Använd följande anvisningar när du går igenom artikeln och gå sedan tillbaka till den här artikeln när du har skapat och konfigurerat Azure SQL Database:
När du kommer till avsnittet Skapa en enkel databas använder du följande steg:
- I steg 4 för att skapa en ny resursgrupp sparar du värdet Resursgruppnamn , till exempel
myResourceGroup. - Spara värdet Databasnamn åt sidan i steg 5 för databasnamn,
mySampleDatabasetill exempel . - I steg 6 för att skapa servern använder du följande steg:
- Fyll i ett unikt servernamn – till exempel
sqlserverprimary-mjg022624. - För Plats väljer du (USA) USA, östra.
- Som Autentiseringsmetod väljer du Använd SQL-autentisering.
- Spara åt sidan för inloggningsvärdet serveradministratör – till exempel
azureuser. - Spara lösenordet åt sidan.
- Fyll i ett unikt servernamn – till exempel
- I steg 8 väljer du Utveckling för Arbetsbelastningsmiljö. Titta på beskrivningen och överväg andra alternativ för din arbetsbelastning.
- I steg 11 för Redundans för säkerhetskopieringslagring väljer du Lokalt redundant lagring av säkerhetskopiering. Överväg andra alternativ för dina säkerhetskopior. Mer information finns i avsnittet Säkerhetskopieringslagringsredundansi Automatiserade säkerhetskopieringar i Azure SQL Database.
- I steg 14 går du till konfigurationen brandväggsregler och väljer Ja för Tillåt Azure-tjänster och resurser att komma åt den här servern.
- I steg 4 för att skapa en ny resursgrupp sparar du värdet Resursgruppnamn , till exempel
När du kommer till avsnittet Fråga databasen använder du följande steg:
I steg 3 anger du inloggningsinformation för sql-autentiseringsserveradministratören för att logga in.
Kommentar
Om inloggningen misslyckas med ett felmeddelande som liknar Klienten med IP-adressen "xx.xx.xx.xx.xx" inte har behörighet att komma åt servern väljer du Tillåtlista IP xx.xx.xx.xx på servern <your-sqlserver-name> i slutet av felmeddelandet. Vänta tills serverns brandväggsregler har uppdaterats och välj sedan OK igen.
När du har kört exempelfrågan i steg 5 rensar du redigeraren och anger följande fråga och väljer sedan Kör igen:
CREATE TABLE sessions ( ID VARCHAR(128) NOT NULL, PROPID VARCHAR(128) NOT NULL, APPNAME VARCHAR(128) NOT NULL, LISTENERCNT SMALLINT, LASTACCESS BIGINT, CREATIONTIME BIGINT, MAXINACTIVETIME INT, USERNAME VARCHAR(256), SMALL VARBINARY(MAX), MEDIUM VARCHAR(MAX), LARGE VARBINARY(MAX) );Efter en lyckad körning bör du se meddelandet Fråga lyckades: Berörda rader: 0.
Databastabellen
sessionsanvänds för att lagra sessionsdata för din WebSphere-app. WebSphere-klusterdata inklusive transaktionsloggar sparas till lokal lagring av virtuella datorer där klustret distribueras.
Skapa sedan en Azure SQL Database-redundansgrupp genom att följa stegen i Azure-portalen i Konfigurera en redundansgrupp för Azure SQL Database. Du behöver bara följande avsnitt: Skapa redundansgrupp och Testa planerad redundans. Följ stegen nedan när du går igenom artikeln och gå sedan tillbaka till den här artikeln när du har skapat och konfigurerat redundansgruppen för Azure SQL Database:
I avsnittet Skapa redundansgrupp använder du följande steg:
- I steg 5 för att skapa redundansgruppen anger du och sparar det unika redundansgruppens namn , till exempel
failovergroup-mjg022624. - I steg 5 för att konfigurera servern väljer du alternativet för att skapa en ny sekundär server och använder sedan följande steg:
- Ange ett unikt servernamn – till exempel
sqlserversecondary-mjg022624. - Ange samma serveradministratör och lösenord som din primära server.
- För Plats väljer du (USA) USA, västra.
- Kontrollera att Tillåt Azure-tjänster att komma åt servern är valt.
- Ange ett unikt servernamn – till exempel
- I steg 5 för att konfigurera databaserna i gruppen väljer du den databas som du skapade på den primära servern , till exempel
mySampleDatabase.
- I steg 5 för att skapa redundansgruppen anger du och sparar det unika redundansgruppens namn , till exempel
När du har slutfört alla steg i avsnittet Testa planerad redundans håller du sidan för redundansgruppen öppen och använder den för redundanstestet av WebSphere-kluster senare.
Kommentar
Den här artikeln beskriver hur du skapar en enkel Azure SQL Database-databas med SQL-autentisering. En säkrare metod är att använda Microsoft Entra-autentisering för Azure SQL- för att autentisera databasserveranslutningen. SQL-autentisering krävs för att WebSphere-klustret ska kunna ansluta till databasen för sessionspersistens senare. Mer information finns i Konfigurera för databassessionens beständighet.
Konfigurera det primära WebSphere-klustret på virtuella Azure-datorer
I det här avsnittet skapar du de primära WebSphere-klustren på virtuella Azure-datorer med hjälp av IBM WebSphere Application Server-klustret på virtuella Azure-datorer . Det sekundära klustret återställs från det primära klustret under redundansväxlingen med Azure Site Recovery senare.
Distribuera det primära WebSphere-klustret
Öppna först IBM WebSphere Application Server-klustret på virtuella Azure-datorer i webbläsaren och välj Skapa. Du bör se fönstret Grundläggande i erbjudandet.
Använd följande steg för att fylla i fönstret Grundläggande :
- Kontrollera att värdet som visas för Prenumeration är samma som har de roller som anges i avsnittet för förhandskrav.
- I fältet Resursgrupp väljer du Skapa ny och fyller i ett unikt värde för resursgruppen , till exempel
was-cluster-eastus-mjg022624. - Under Instansinformation väljer du USA, östra för Region.
- För Distribuera med befintlig WebSphere-berättigande eller med utvärderingslicens?, väljer du Utvärdering för den här självstudien. Du kan också välja Berättigat och ange dina IBMid-autentiseringsuppgifter.
- Välj Jag har läst och godkänt IBM-licensavtalet..
- Lämna standardvärdena för andra fält.
- Välj Nästa för att gå till fönstret Klusterkonfiguration .

Använd följande steg för att fylla i fönstret Klusterkonfiguration :
- Ange ett lösenord för Lösenord för VM-administratör. För bättre säkerhet bör du överväga att använda offentlig SSH-nyckel som vm-autentiseringstyp.
- Ange ett lösenord för Lösenord för WebSphere-administratör. Spara användarnamnet och lösenordet åt sidan för WebSphere-administratören.
- Lämna standardvärdena för andra fält.
- Välj Nästa för att gå till fönstret Lastbalanserare .

Använd följande steg för att fylla i fönstret Lastbalanserare :
- Ange ett lösenord för Lösenord för VM-administratör. För bättre säkerhet bör du överväga att använda offentlig SSH-nyckel som VM-autentisering.
- Ange ett lösenord för Lösenord för IBM HTTP Server-administratör.
- Lämna standardvärdena för andra fält.
- Välj Nästa för att gå till fönstret Nätverk .

Du bör se alla fält ifyllda med standardvärdena i fönstret Nätverk . Välj Nästa för att gå till fönstret Databas .

Följande steg visar hur du fyller i fönstret Databas :
- Välj Ja för Anslut till databas?.
- För Välj databastyp väljer du Microsoft SQL Server .
- För JNDI-namn anger du jdbc/WebSphereCafeDB.
- För datakällans niska veze (jdbc:sqlserver://<host>:<port>; database=<database>), ersätt platshållarna med de värden som du sparade åt sidan i föregående avsnitt för redundansgruppen för Azure SQL Database , till exempel
jdbc:sqlserver://failovergroup-mjg022624.database.windows.net:1433;database=mySampleDatabase. - För Databasanvändarnamn anger du inloggningsnamnet för serveradministratören och namnet på redundansgruppen som du sparade åt sidan i föregående avsnitt , till exempel
azureuser@failovergroup-mjg022624.Kommentar
Var extra noga med att använda rätt värdnamn för databasservern och databasanvändarnamnet för redundansgruppen i stället för serverns värdnamn och användarnamn från den primära databasen eller säkerhetskopieringsdatabasen. Genom att använda värdena från redundansgruppen uppmanar du i själva verket WebSphere att prata med redundansgruppen. Men när det gäller WebSphere är det bara en vanlig databasanslutning.
- Ange inloggningslösenordet för serveradministratören som du sparade tidigare för Databaslösenord. Ange samma värde för Bekräfta lösenord.
- Lämna standardvärdena för de andra fälten.
- Välj Granska + skapa.
- Vänta tills den slutgiltiga verifieringen har körts... har slutförts och välj sedan Skapa.

Kommentar
Den här artikeln hjälper dig att ansluta till en Azure SQL Database med SQL-autentisering. En säkrare metod är att använda Microsoft Entra-autentisering för Azure SQL- för att autentisera databasserveranslutningen. SQL-autentisering krävs för att WebSphere-klustret ska kunna ansluta till databasen för sessionspersistens senare. Mer information finns i Konfigurera för databassessionens beständighet.
Efter ett tag bör du se sidan Distribution där distribution pågår visas.
Kommentar
Om du ser några problem när du kör den slutliga valideringen... kan du åtgärda dem och försöka igen.
Beroende på nätverksförhållanden och annan aktivitet i den valda regionen kan distributionen ta upp till 25 minuter att slutföra. Därefter bör du se texten Distributionen är klar visas på distributionssidan.
Kontrollera distributionen av klustret
Du har distribuerat en IBM HTTP Server (IHS) och en WebSphere Deployment Manager (Dmgr) i klustret. IHS fungerar som lastbalanserare för alla programservrar i klustret. Dmgr tillhandahåller en webbkonsol för klusterkonfiguration.
Använd följande steg för att kontrollera om IHS- och Dmgr-konsolen fungerar innan du går vidare till nästa steg:
Gå tillbaka till sidan Distribution och välj sedan Utdata.
Kopiera värdet för egenskapen ihsConsole. Öppna webbadressen på en ny webbläsarflik. Observera att vi inte använder
httpsför IHS i det här exemplet. Du bör se en välkomstsida för IHS utan felmeddelande. Om du inte gör det måste du felsöka och lösa problemet innan du fortsätter. Håll konsolen öppen och använd den för att verifiera appdistributionen av klustret senare.
Kopiera och spara värdet för egenskapsadministratörenSecuredConsole. Öppna den på en ny webbläsarflik. Godkänn webbläsarvarningen för det självsignerade TLS-certifikatet. Gå inte till produktion med ett självsignerat TLS-certifikat.
Du bör se inloggningssidan för WebSphere Integrated Solutions Console. Logga in på konsolen med användarnamnet och lösenordet för WebSphere-administratören som du sparade åt sidan tidigare. Om du inte kan logga in måste du felsöka och lösa problemet innan du fortsätter. Håll konsolen öppen och använd den för ytterligare konfiguration av WebSphere-klustret senare.

Använd följande steg för att hämta namnet på den offentliga IP-adressen för IHS. Du använder den när du konfigurerar Azure Traffic Manager senare.
- Öppna resursgruppen där klustret distribueras . Välj till exempel Översikt för att växla tillbaka till fönstret Översikt på distributionssidan och välj sedan Gå till resursgrupp.
- Leta reda på kolumnen Typ i resurstabellen. Välj den för att sortera efter resurstyp.
- Leta reda på den offentliga IP-adressresursen med
ihsprefixet och kopiera och spara dess namn.
Konfigurera klustret
Använd först följande steg för att aktivera alternativet Synkronisera ändringar med noder så att alla konfigurationer kan synkroniseras automatiskt till alla programservrar:
- Växla tillbaka till websfärens integrerade lösningskonsol och logga in igen om du är inloggad.
- I navigeringsfönstret väljer du Konsolinställningar för systemadministration>.
- I fönstret Konsolinställningar väljer du Synkronisera ändringar med noder och sedan Använd. Du bör se meddelandet Dina inställningar har ändrats.
Använd sedan följande steg för att konfigurera databasdistributionssessioner för alla programservrar:
- I navigeringsfönstret väljer du Servrar>Servertyper>WebSphere-programservrar.
- I fönstret Programservrar bör du se tre programservrar i listan. För varje programserver använder du följande instruktioner för att konfigurera de databasdelade sessionerna:
- I tabellen under texten Du kan administrera följande resurser väljer du hyperlänken för programservern, som börjar med
MyCluster. - I avsnittet Containerinställningar väljer du Sessionshantering.
- I avsnittet Ytterligare egenskaper väljer du Inställningar för distribuerad miljö.
- För Distribuerade sessioner väljer du Databas (stöds endast för webbcontainer.).
- Välj Databas och använd följande steg:
- För Datasource JNDI-namn anger du jdbc/WebSphereCafeDB.
- För Användar-ID anger du inloggningsnamnet för serveradministratören och namnet på redundansgruppen som du sparade åt sidan i föregående avsnitt,
azureuser@failovergroup-mjg022624till exempel . - Fyll i inloggningslösenordet för Azure SQL-serveradministratören som du sparade åt sidan tidigare för Lösenord.
- För Namn på tabellutrymme anger du sessioner.
- Välj Använd schema för flera rader.
- Välj OK. Du dirigeras tillbaka till fönstret Inställningar för distribuerad miljö .
- Under avsnittet Ytterligare egenskaper väljer du Anpassade justeringsparametrar.
- För Justeringsnivå väljer du Låg (optimera för redundans).
- Välj OK.
- Under Meddelanden väljer du Spara. Vänta tills processen är klar.
- Välj Programservrar i det övre sökvägsfältet. Du dirigeras tillbaka till fönstret Programservrar .
- I tabellen under texten Du kan administrera följande resurser väljer du hyperlänken för programservern, som börjar med
- I navigeringsfönstret väljer du >>
- I fönstret WebSphere-programserverkluster bör du se klustret
MyClusteri listan. Markera kryssrutan bredvid MyCluster. - Välj Ripplestart.
- Vänta tills klustret har startats om. Du kan välja statusikonen och om det nya fönstret inte visar Startat växlar du tillbaka till konsolen och uppdaterar webbsidan efter ett tag. Upprepa åtgärden tills du ser Startad. Du kan se partiell start innan du når tillståndet Startad
Håll konsolen öppen och använd den för appdistribution senare.
Distribuera en exempelapp
Det här avsnittet visar hur du distribuerar och kör ett CRUD Java/Jakarta EE-exempelprogram på ett WebSphere-kluster för redundanstest för haveriberedskap senare.
Du konfigurerade programservrar för att använda datakällan jdbc/WebSphereCafeDB för att lagra sessionsdata tidigare, vilket möjliggör redundans och belastningsutjämning över ett kluster av WebSphere-programservrar. Exempelappen konfigurerar också ett beständighetsschema för att bevara programdata coffee i samma datakälla jdbc/WebSphereCafeDB.
Använd först följande kommandon för att ladda ned, skapa och paketera exemplet:
git clone https://github.com/Azure-Samples/websphere-cafe
cd websphere-cafe
git checkout 20240326
mvn clean package
Om du ser ett meddelande om att vara i ett Detached HEAD tillstånd är det här meddelandet säkert att ignorera.
Paketet ska genereras och finnas på <.> Om du inte ser paketet måste du felsöka och lösa problemet innan du fortsätter.
Använd sedan följande steg för att distribuera exempelappen till klustret:
- Växla tillbaka till websfärens integrerade lösningskonsol och logga in igen om du är inloggad.
- I navigeringsfönstret väljer du >
- I fönstret Företagsprogram väljer du Installera>Välj fil. Leta sedan reda på paketet som finns på <parent-path-to-your-local-clone>/websphere-café/websphere-café-application/target/websphere-café.ear och välj Öppna. Välj Nästa>nästa>nästa.
- I fönstret Mappa moduler till servrar trycker du på Ctrl och markerar alla objekt som visas under Kluster och servrar. Markera kryssrutan bredvid websphere-café.war. Välj Använd. Välj Nästa tills du ser knappen Slutför .
- Välj Slutför>Spara och vänta sedan tills det är klart. Välj OK.
- Välj det installerade programmet
websphere-cafeoch välj sedan Start. Vänta tills du ser meddelanden som anger att programmet har startats. Om du inte kan se det lyckade meddelandet måste du felsöka och lösa problemet innan du fortsätter.
Använd nu följande steg för att kontrollera att appen körs som förväntat:
Växla tillbaka till IHS-konsolen. Lägg till kontextroten
/websphere-cafe/för den distribuerade appen i adressfältet , till exempelhttp://ihs70685e.eastus.cloudapp.azure.com/websphere-cafe/, och tryck sedan på Retur. Du bör se välkomstsidan för exempelappen.Skapa en ny kaffe med ett namn och pris – till exempel Kaffe 1 med pris 10 USD – som sparas i både tabellen med programdata och sessionstabellen i databasen. Användargränssnittet som du ser bör likna följande skärmbild:
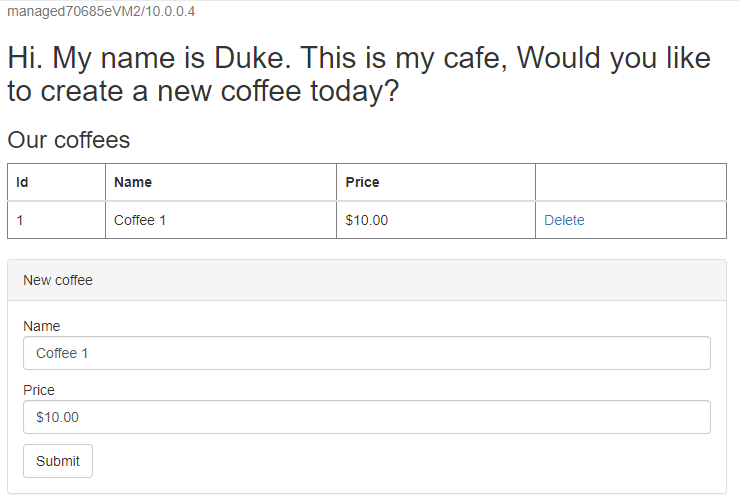

Om användargränssnittet inte ser liknande ut felsöker du och löser problemet du fortsätter.
Konfigurera haveriberedskap för klustret med Azure Site Recovery
I det här avsnittet konfigurerar du haveriberedskap för virtuella Azure-datorer i det primära klustret med hjälp av Azure Site Recovery genom att följa stegen i Självstudie: Konfigurera haveriberedskap för virtuella Azure-datorer. Du behöver bara följande avsnitt: Skapa ett Recovery Services-valv och Aktivera replikering. Var uppmärksam på följande steg när du går igenom artikeln och gå sedan tillbaka till den här artikeln när det primära klustret har skyddats:
I avsnittet Skapa ett Recovery Services-valv använder du följande steg:
I steg 5 för Resursgrupp skapar du en ny resursgrupp med ett unikt namn i din prenumeration , till exempel
was-cluster-westus-mjg022624.I steg 6 för Valvnamn anger du ett valvnamn , till exempel
recovery-service-vault-westus-mjg022624.I steg 7 för Region väljer du USA, västra.
Innan du väljer Granska + skapa i steg 8 väljer du Nästa: Redundans. I fönstret Redundans väljer du Geo-redundant för redundans för lagring av säkerhetskopior och Aktivera för återställning mellan regioner.
Kommentar
Kontrollera att du väljer Geo-redundant för Redundans för lagring av säkerhetskopior och Aktivera för återställning mellan regioner i fönstret Redundans . Annars kan lagringen av det primära klustret inte replikeras till den sekundära regionen.
Aktivera Site Recovery genom att följa stegen i avsnittet Aktivera Site Recovery.
När du når avsnittet Aktivera replikering använder du följande steg:
- I avsnittet Välj källinställningar använder du följande steg:
För Region väljer du USA, östra.
För Resursgrupp väljer du den resurs där det primära klustret distribueras , till exempel
was-cluster-eastus-mjg022624.Kommentar
Om den önskade resursgruppen inte visas kan du först välja USA, västra för regionen och sedan växla tillbaka till USA, östra.
Lämna standardvärdena för andra fält. Välj Nästa.
- I avsnittet Välj de virtuella datorerna för Virtuella datorer väljer du alla fem virtuella datorer som visas och väljer sedan Nästa.
- I avsnittet Granska replikeringsinställningar använder du följande steg:
- För Målplats väljer du USA, västra.
- För Målresursgrupp väljer du den resursgrupp där service recovery-valvet distribueras , till exempel
was-cluster-westus-mjg022624. - Anteckna det nya virtuella redundansnätverket och undernätet för redundans, som mappas från ettor i den primära regionen.
- Lämna standardvärdena för andra fält.
- Välj Nästa.
- I avsnittet Hantera använder du följande steg:
- För Replikeringsprincip använder du standardprincipen 24-timmars kvarhållningsprincip. Du kan också skapa en ny princip för ditt företag.
- Lämna standardvärdena för andra fält.
- Välj Nästa.
- I avsnittet Granska använder du följande steg:
När du har valt Aktivera replikering ser du meddelandet Skapa Azure-resurser. Stäng inte det här bladet. visas längst ned på sidan. Gör ingenting och vänta tills fönstret stängs automatiskt. Du omdirigeras till sidan Site Recovery .
Under Skyddade objekt väljer du Replikerade objekt. Inledningsvis visas inga objekt eftersom replikeringen fortfarande pågår. Replikeringen tar ungefär en timme att slutföra. Uppdatera sidan regelbundet tills du ser att alla virtuella datorer är i skyddat tillstånd, enligt följande skärmbild:
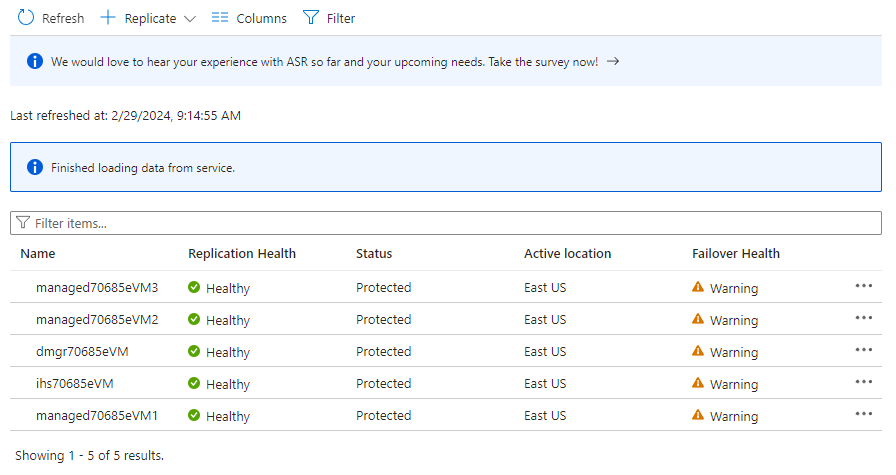
- I avsnittet Välj källinställningar använder du följande steg:

Skapa sedan en återställningsplan för att inkludera alla replikerade objekt så att de kan redundansväxla tillsammans. Använd anvisningarna i Skapa en återställningsplan med följande anpassningar:
- I steg 2 anger du ett namn för planen , till exempel
recovery-plan-mjg022624. - I steg 3 för Källa väljer du USA , östra och för Mål väljer du USA, västra.
- I steg 4 för Välj objekt väljer du alla fem skyddade virtuella datorer för den här självstudien.
Sedan skapar du en återställningsplan. Håll sidan öppen så att du kan använda den för redundanstestning senare.
Ytterligare nätverkskonfiguration för den sekundära regionen
Du behöver också ytterligare nätverkskonfiguration för att aktivera och skydda extern åtkomst till den sekundära regionen i en redundanshändelse. Använd följande steg för den här konfigurationen:
Skapa en offentlig IP-adress för Dmgr i den sekundära regionen genom att följa anvisningarna i Snabbstart: Skapa en offentlig IP-adress med hjälp av Azure-portalen med följande anpassningar:
- För Resursgrupp väljer du den resursgrupp där service recovery-valvet distribueras , till exempel
was-cluster-westus-mjg022624. - För Region väljer du (USA) USA, västra.
- Som Namn anger du ett värde , till exempel
dmgr-public-ip-westus-mjg022624. - För DNS-namnetikett anger du ett unikt värde , till exempel
dmgrmjg022624.
- För Resursgrupp väljer du den resursgrupp där service recovery-valvet distribueras , till exempel
Skapa en annan offentlig IP-adress för IHS i den sekundära regionen genom att följa samma guide med följande anpassningar:
- För Resursgrupp väljer du den resursgrupp där service recovery-valvet distribueras , till exempel
was-cluster-westus-mjg022624. - För Region väljer du (USA) USA, västra.
- Som Namn anger du ett värde , till exempel
ihs-public-ip-westus-mjg022624. Skriv ned det. - För DNS-namnetikett anger du ett unikt värde , till exempel
ihsmjg022624.
- För Resursgrupp väljer du den resursgrupp där service recovery-valvet distribueras , till exempel
Skapa en nätverkssäkerhetsgrupp i den sekundära regionen genom att följa anvisningarna i avsnittet Skapa en nätverkssäkerhetsgrupp i Skapa, ändra eller ta bort en nätverkssäkerhetsgrupp med följande anpassningar:
- För Resursgrupp väljer du den resursgrupp där service recovery-valvet distribueras , till exempel
was-cluster-westus-mjg022624. - Som Namn anger du ett värde , till exempel
nsg-westus-mjg022624. - För Region väljer du USA, västra.
- För Resursgrupp väljer du den resursgrupp där service recovery-valvet distribueras , till exempel
Skapa en regel för inkommande säkerhet för nätverkssäkerhetsgruppen genom att följa anvisningarna i avsnittet Skapa en säkerhetsregel i samma artikel med följande anpassningar:
- I steg 2 väljer du den nätverkssäkerhetsgrupp som du skapade , till exempel
nsg-westus-mjg022624. - I steg 3 väljer du Inkommande säkerhetsregler.
- I steg 4 anpassar du följande inställningar:
- För Målportintervall anger du 9060 9080 9043 9443 80.
- I fältet Protokoll väljer du TCP.
- Som Namn anger du ALLOW_HTTP_ACCESS.
- I steg 2 väljer du den nätverkssäkerhetsgrupp som du skapade , till exempel
Associera nätverkssäkerhetsgruppen med ett undernät genom att följa anvisningarna i avsnittet Associera eller koppla bort en nätverkssäkerhetsgrupp till eller från ett undernät i samma artikel, med följande anpassningar:
- I steg 2 väljer du den nätverkssäkerhetsgrupp som du skapade , till exempel
nsg-westus-mjg022624. - Välj Associera för att associera nätverkssäkerhetsgruppen med det redundansundernät som du antecknade tidigare.
- I steg 2 väljer du den nätverkssäkerhetsgrupp som du skapade , till exempel
Konfigurera en Azure Traffic Manager
I det här avsnittet skapar du en Azure Traffic Manager för att distribuera trafik till dina offentliga program i de globala Azure-regionerna. Den primära slutpunkten pekar på den offentliga IP-adressen för IHS i den primära regionen. Den sekundära slutpunkten pekar på den offentliga IP-adressen för IHS i den sekundära regionen.
Skapa en Azure Traffic Manager-profil genom att följa anvisningarna i Snabbstart: Skapa en Traffic Manager-profil med hjälp av Azure-portalen. Du behöver bara följande avsnitt: Skapa en Traffic Manager-profil och Lägg till Traffic Manager-slutpunkter. Du måste hoppa över de avsnitt där du dirigeras för att skapa App Service-resurser. Använd följande steg när du går igenom de här avsnitten och gå sedan tillbaka till den här artikeln när du har skapat och konfigurerat Azure Traffic Manager.
I avsnittet Skapa en Traffic Manager-profil i steg 2 för Skapa Traffic Manager-profil använder du följande steg:
- Spara åt sidan det unika Traffic Manager-profilnamnet för Namn , till exempel
tmprofile-mjg022624. - Spara åt sidan det nya resursgruppsnamnet för Resursgrupp , till exempel
myResourceGroupTM1.
- Spara åt sidan det unika Traffic Manager-profilnamnet för Namn , till exempel
När du kommer till avsnittet Lägg till Traffic Manager-slutpunkter använder du följande steg:
- När du har öppnat Traffic Manager-profilen i steg 2 går du till sidan Konfiguration och använder följande steg:
- Ange 10 för TTL (DNS time to live).
- Under Inställningar för slutpunktsövervakare för Sökväg anger du /websphere-café/, som är kontextroten för den distribuerade exempelappen.
- Under Inställningar för snabb slutpunktsredundans använder du följande värden:
- För Avsökning internt väljer du 10.
- För Tolererat antal fel anger du 3.
- Använd 5 för timeout för avsökning.
- Välj Spara. Vänta tills den är klar.
- I steg 4 för att lägga till den primära slutpunkten
myPrimaryEndpointanvänder du följande steg:- Som Målresurstyp väljer du Offentlig IP-adress.
- Välj listrutan Välj offentlig IP-adress och ange namnet på den offentliga IP-adressen för IHS i regionen USA, östra som du sparade åt sidan tidigare. Du bör se en post matchad. Välj den för offentlig IP-adress.
- I steg 6 för att lägga till en redundans/sekundär slutpunkt
myFailoverEndpointanvänder du följande steg:- Som Målresurstyp väljer du Offentlig IP-adress.
- Välj listrutan Välj offentlig IP-adress och ange namnet på den offentliga IP-adressen för IHS i regionen USA, västra som du sparade åt sidan tidigare. Du bör se en post matchad. Välj den för offentlig IP-adress.
- Vänta ett tag. Välj Uppdatera tills övervakningsstatusenför slutpunkten
myPrimaryEndpointär Online och Övervakningsstatus för slutpunktenmyFailoverEndpointhar degraderats.
- När du har öppnat Traffic Manager-profilen i steg 2 går du till sidan Konfiguration och använder följande steg:
Använd sedan följande steg för att kontrollera att exempelappen som distribueras till det primära WebSphere-klustret är tillgänglig från Traffic Manager-profilen:
Välj Översikt för Traffic Manager-profilen som du skapade.
Välj och kopiera DNS-namnet (Domain Name System) för Traffic Manager-profilen och lägg sedan till det med
/websphere-cafe/, till exempelhttp://tmprofile-mjg022624.trafficmanager.net/websphere-cafe/.Öppna URL:en på en ny flik i webbläsaren. Du bör se kaffet som du skapade tidigare på sidan.
Skapa ytterligare en kaffe med ett annat namn och pris – till exempel Kaffe 2 med pris 20 – som sparas i både programdatatabellen och sessionstabellen i databasen. Användargränssnittet som du ser bör likna följande skärmbild:
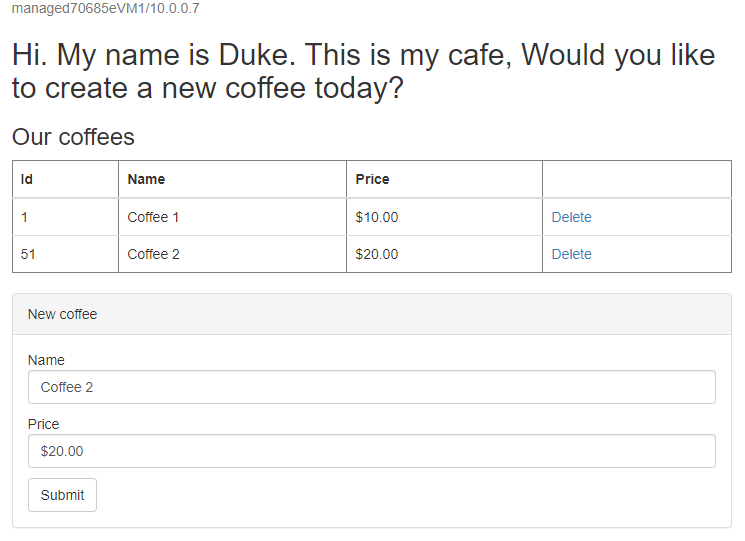

Om användargränssnittet inte ser liknande ut kan du felsöka och lösa problemet innan du fortsätter. Håll konsolen öppen och använd den för redundanstest senare.
Nu konfigurerar du Traffic Manager-profilen. Håll sidan öppen och du använder den för att övervaka ändringen av slutpunktens status i en redundanshändelse senare.
Testa redundans från primär till sekundär
Om du vill testa redundansväxlingen redundansväxlar du azure SQL Database-servern och klustret manuellt och redundansväxlar sedan tillbaka med hjälp av Azure-portalen.
Redundansväxling till den sekundära platsen
Använd först följande steg för att redundansväxlar Azure SQL Database från den primära servern till den sekundära servern:
- Växla till webbläsarfliken i din Azure SQL Database-redundansgrupp – till exempel
failovergroup-mjg022624. - Välj Redundans>Ja.
- Vänta tills den är klar.
Använd sedan följande steg för att redundansväxlar WebSphere-klustret med återställningsplanen:
I sökrutan överst i Azure-portalen anger du Recovery Services-valv och väljer sedan Recovery Services-valv i sökresultaten.
Välj namnet på ditt Recovery Services-valv – till exempel
recovery-service-vault-westus-mjg022624.Under Hantera väljer du Återställningsplaner (Site Recovery). Välj den återställningsplan som du skapade , till exempel
recovery-plan-mjg022624.Välj Redundans. Välj Jag förstår risken. Hoppa över redundanstest.. Lämna standardvärdena för andra fält och välj OK.
Kommentar
Du kan också köra redundanstestet Test och Cleanup för att se till att allt fungerar som förväntat innan du testar redundans. Mer information finns i Självstudie: Kör ett haveriberedskapstest för virtuella Azure-datorer. I den här självstudien testas redundans direkt för att förenkla övningen.
Övervaka redundansväxlingen i meddelanden tills den har slutförts. Det tar ungefär 10 minuter för övningen i den här självstudien.
Du kan också visa information om redundansjobb genom att välja redundanshändelsen, till exempel redundansväxling av "recovery-plan-mjg022624" pågår... – från meddelanden.
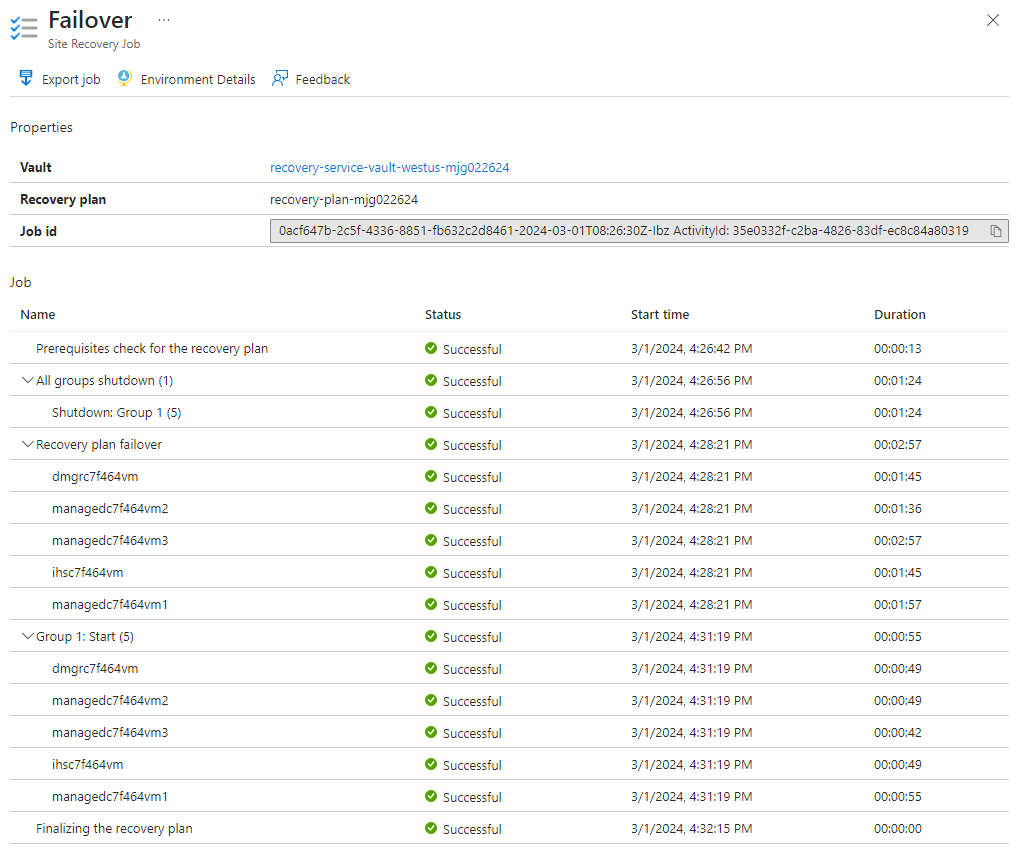




Använd sedan följande steg för att aktivera den externa åtkomsten till WebSphere Integrated Solutions Console och exempelappen i den sekundära regionen:
- I sökrutan överst i Azure-portalen anger du Resursgrupper och väljer sedan Resursgrupper i sökresultaten.
- Välj namnet på resursgruppen för den sekundära regionen , till exempel
was-cluster-westus-mjg022624. Sortera objekt efter typ på sidan Resursgrupp . - Välj Nätverksgränssnittet prefixet med
dmgr. Välj IP-konfigurationer>ipconfig1. Välj Associera offentlig IP-adress. För Offentlig IP-adress väljer du den offentliga IP-adress som är prefixet meddmgr. Den här adressen är den du skapade tidigare. I den här artikeln heterdmgr-public-ip-westus-mjg022624adressen . Välj Spara och vänta sedan tills det har slutförts. - Växla tillbaka till resursgruppen och välj det nätverksgränssnitt som är prefixet med
ihs. Välj IP-konfigurationer>ipconfig1. Välj Associera offentlig IP-adress. För Offentlig IP-adress väljer du den offentliga IP-adress som är prefixet medihs. Den här adressen är den du skapade tidigare. I den här artikeln heterihs-public-ip-westus-mjg022624adressen . Välj Spara och vänta sedan tills det har slutförts.
Använd nu följande steg för att kontrollera att redundansväxlingen fungerar som förväntat:
Leta reda på DNS-namnetiketten för den offentliga IP-adressen för den Dmgr som du skapade tidigare. Öppna URL:en för Dmgr WebSphere Integrated Solutions Console på en ny webbläsarflik. Glöm inte att använda
https. Exempel:https://dmgrmjg022624.westus.cloudapp.azure.com:9043/ibm/consoleUppdatera sidan tills du ser välkomstsidan för inloggning.Logga in på konsolen med användarnamnet och lösenordet för WebSphere-administratören som du sparade åt sidan tidigare och använd sedan följande steg:
I navigeringsfönstret väljer du Servrar>Alla servrar. I fönstret Mellanprogramsservrar bör du se 4 servrar i listan, inklusive 3 WebSphere-programservrar som består av WebSphere-kluster
MyClusteroch en webbserver som är en IHS. Uppdatera sidan tills du ser att alla servrar har startats.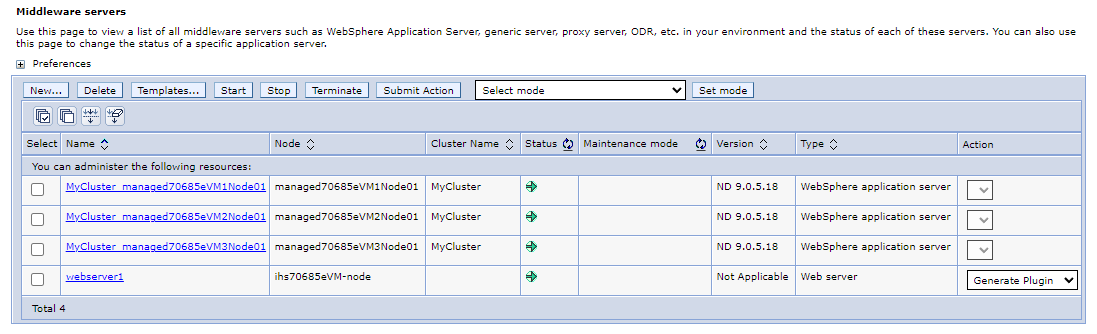
I navigeringsfönstret väljer du > I fönstret Företagsprogram bör du se ett program –
websphere-cafe– som visas och startas.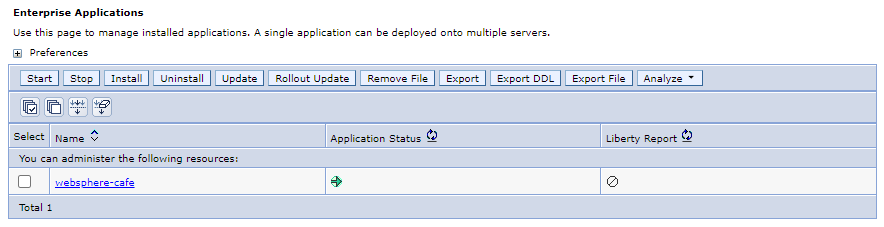
Om du vill verifiera klusterkonfigurationen i den sekundära regionen följer du stegen i avsnittet Konfigurera klustret . Du bör se att inställningarna för Synkronisera ändringar med noder och distribuerade sessioner replikeras till redundansklustret, enligt följande skärmbilder:
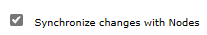
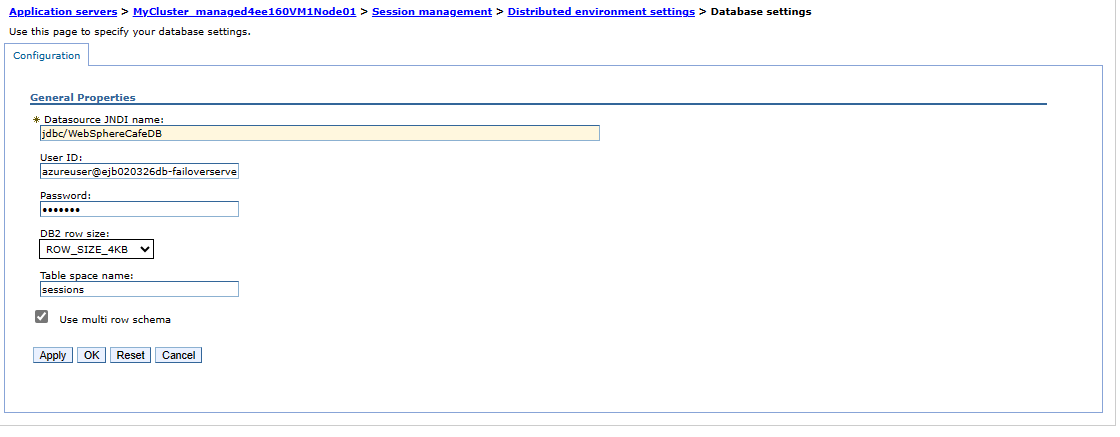
Leta upp DNS-namnetiketten för den offentliga IP-adressen för den IHS som du skapade tidigare. Öppna URL:en för IHS-konsolen som läggs till med rotkontexten
/websphere-cafe/. Observera att du inte får användahttps. Det här exemplet användshttpsinte för IHS – till exempelhttp://ihsmjg022624.westus.cloudapp.azure.com/websphere-cafe/. Du bör se två kaffe som du skapade tidigare på sidan.Växla till webbläsarfliken i Traffic Manager-profilen och uppdatera sedan sidan tills du ser att värdet Övervaka status för slutpunkten
myFailoverEndpointblir Online och värdet För övervakningsstatus för slutpunktenmyPrimaryEndpointdegraderas.Växla till webbläsarfliken med DNS-namnet på Traffic Manager-profilen , till exempel
http://tmprofile-mjg022624.trafficmanager.net/websphere-cafe/. Uppdatera sidan så bör du se samma data som sparas i programdatatabellen och sessionstabellen som visas. Användargränssnittet som du ser bör likna följande skärmbild: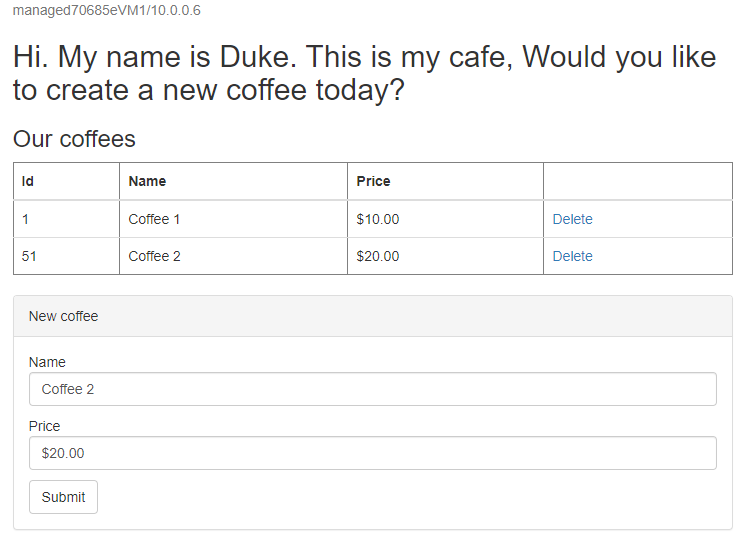
Om du inte ser det här beteendet kan det bero på att Traffic Manager tar tid att uppdatera DNS för att peka på redundansplatsen. Problemet kan också vara att webbläsaren cachelagrade dns-namnmatchningsresultatet som pekar på den misslyckade webbplatsen. Vänta ett tag och uppdatera sidan igen.





Checka in redundansväxlingen
Använd följande steg för att genomföra redundansväxlingen när du har uppfyllt redundansresultatet:
I sökrutan överst i Azure-portalen anger du Recovery Services-valv och väljer sedan Recovery Services-valv i sökresultaten.
Välj namnet på ditt Recovery Services-valv – till exempel
recovery-service-vault-westus-mjg022624.Under Hantera väljer du Återställningsplaner (Site Recovery). Välj den återställningsplan som du skapade , till exempel
recovery-plan-mjg022624.Välj Checka in>OK.
Övervaka incheckningen i meddelanden tills den har slutförts.
Välj Objekt i återställningsplanen. Du bör se 5 objekt som anges som redundans har checkats in.
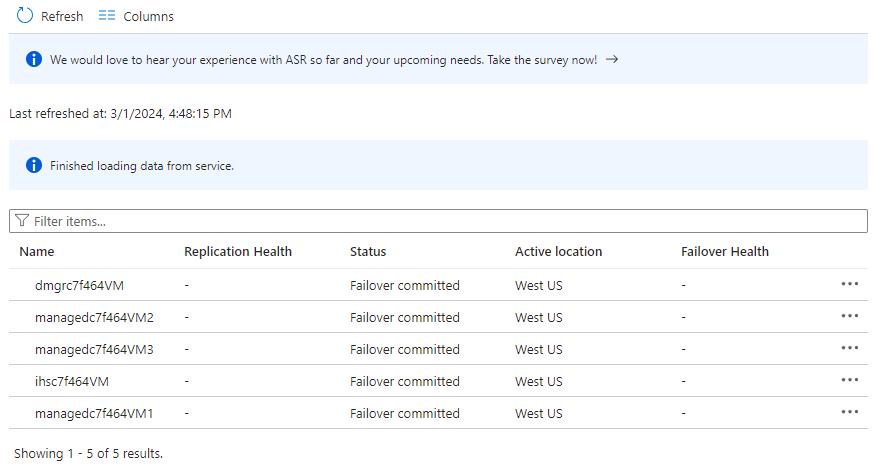



Inaktivera replikeringen
Använd följande steg för att inaktivera replikeringen för objekt i återställningsplanen och ta sedan bort återställningsplanen:
För varje objekt i Objekt i återställningsplanen väljer du ellipsknappen (...) och väljer sedan Inaktivera replikering.
Om du uppmanas att ange en orsak till att inaktivera skyddet för den här virtuella datorn väljer du en du föredrar – till exempel har jag slutfört migreringen av mitt program. Välj OK.
Upprepa steg 1 tills du inaktiverar replikering för alla objekt.
Övervaka processen i meddelanden tills den är klar.
Välj Översikt>Ta bort. Välj Ja för att bekräfta borttagningen.

Förbered för återställning efter fel: Återaktivera skyddet av redundansplatsen
Den sekundära regionen är nu redundansplatsen och aktiv. Du bör återaktivera skyddet i din primära region.
Använd först följande steg för att rensa resurser som inte används och som Azure Site Recovery-tjänsten ska replikera i din primära region senare. Du kan inte bara ta bort resursgruppen eftersom platsåterställningen återställer resurser till den befintliga resursgruppen.
- I sökrutan överst i Azure-portalen anger du Resursgrupper och väljer sedan Resursgrupper i sökresultaten.
- Välj namnet på resursgruppen för den primära regionen , till exempel
was-cluster-eastus-mjg022624. Sortera objekt efter typ på sidan Resursgrupp . - Använd följande steg för att ta bort de virtuella datorerna:
- Välj filtret Typ och välj sedan Virtuell dator i listrutan Värde.
- Välj Använd.
- Markera alla virtuella datorer, välj Ta bort och ange sedan ta bort för att bekräfta borttagningen.
- Välj Ta bort.
- Övervaka processen i meddelanden tills den är klar.
- Använd följande steg för att ta bort diskarna:
- Välj filtret Typ och välj sedan Diskar i listrutan Värde.
- Välj Använd.
- Markera alla diskar, välj Ta bort och ange sedan ta bort för att bekräfta borttagningen.
- Välj Ta bort.
- Övervaka processen i meddelanden och vänta tills den är klar.
- Använd följande steg för att ta bort slutpunkterna:
- Välj filtret Typ och välj Privat slutpunkt i listrutan Värde.
- Välj Använd.
- Markera alla privata slutpunkter, välj Ta bort och ange sedan ta bort för att bekräfta borttagningen.
- Välj Ta bort.
- Övervaka processen i meddelanden tills den är klar. Ignorera det här steget om typen Privat slutpunkt inte visas.
- Använd följande steg för att ta bort nätverksgränssnitten:
- Välj typfiltret> och välj Nätverksgränssnitt i listrutan Värde.
- Välj Använd.
- Markera alla nätverksgränssnitt, välj Ta bort och ange sedan ta bort för att bekräfta borttagningen.
- Välj Ta bort. Övervaka processen i meddelanden tills den är klar.
- Använd följande steg för att ta bort lagringskonton:
- Välj typfiltret> och välj Lagringskonto i listrutan Värde.
- Välj Använd.
- Markera alla lagringskonton, välj Ta bort och ange sedan ta bort för att bekräfta borttagningen.
- Välj Ta bort. Övervaka processen i meddelanden tills den är klar.
Använd sedan samma steg i avsnittet Konfigurera haveriberedskap för klustret med hjälp av Azure Site Recovery för den primära regionen, förutom följande skillnader:
- I avsnittet Skapa ett Recovery Services-valv använder du följande steg:
- Välj den resursgrupp som distribuerats i den primära regionen , till exempel
was-cluster-eastus-mjg022624. - Ange ett annat namn för servicevalvet , till exempel
recovery-service-vault-eastus-mjg022624. - För Region väljer du USA, östra.
- Välj den resursgrupp som distribuerats i den primära regionen , till exempel
- Använd följande steg för Aktivera replikering:
- För Region i Källa väljer du USA, västra.
- Använd följande steg för replikeringsinställningar:
- För Målresursgrupp väljer du den befintliga resursgruppen som distribuerats i den primära regionen , till exempel
was-cluster-eastus-mjg022624. - Som virtuellt redundansnätverk väljer du det befintliga virtuella nätverket i den primära regionen.
- För Målresursgrupp väljer du den befintliga resursgruppen som distribuerats i den primära regionen , till exempel
- För Skapa en återställningsplan för Källa väljer du USA, västra och för Mål väljer du USA, östra.
- Hoppa över stegen i avsnittet Ytterligare nätverkskonfiguration för den sekundära regionen eftersom du skapade och konfigurerade dessa resurser tidigare.
Kommentar
Du kanske märker att Azure Site Recovery stöder återaktivering av skydd av virtuella datorer när den virtuella måldatorn finns. Mer information finns i avsnittet Skydda den virtuella datorn igen i Självstudie: Redundansväxla virtuella Azure-datorer till en sekundär region. På grund av den metod vi använder för WebSphere fungerar inte den här funktionen. Anledningen är att de enda ändringarna mellan källdisken och måldisken synkroniseras för WebSphere-klustret baserat på verifieringsresultatet. I den här självstudien etableras en ny replikering från den sekundära platsen till den primära platsen efter redundansväxlingen för att ersätta funktionen för återaktivering av den virtuella datorn. Hela diskarna kopieras från rederieringsregionen till den primära regionen. Mer information finns i avsnittet Vad händer under återaktivering av skyddet? i Återaktivera skydd över virtuella Azure-datorer till den primära regionen.
Växla tillbaka till den primära platsen
Använd samma steg i avsnittet Redundans till den sekundära platsen för att återställa till den primära platsen, inklusive databasservern och klustret, förutom följande skillnader:
- Välj det Recovery Service-valv som distribuerats i den primära regionen , till exempel
recovery-service-vault-eastus-mjg022624. - Välj den resursgrupp som distribuerats i den primära regionen , till exempel
was-cluster-eastus-mjg022624. - När du har aktiverat den externa åtkomsten till WebSphere Integrated Solutions Console och exempelappen i den primära regionen går du tillbaka till webbläsarflikarna för konsolen WebSphere Integrated Solutions och exempelappen för det primära kluster som du öppnade tidigare. Kontrollera att de fungerar som förväntat. Beroende på hur lång tid det tog att växla tillbaka kanske du inte ser sessionsdata som visas i avsnittet Nytt kaffe i exempelappens användargränssnitt om det upphörde att gälla mer än en timme tidigare.
- I avsnittet Checka in redundans väljer du ditt Recovery Services-valv som distribuerats i det primära – till exempel
recovery-service-vault-eastus-mjg022624. - I Traffic Manager-profilen bör du se att slutpunkten
myPrimaryEndpointblir Online och slutpunktenmyFailoverEndpointdegraderas. - I avsnittet Förbered för återställning efter fel: Återaktivera skyddet av redundanswebbplatsen använder du följande steg:
- Den primära regionen är din redundansplats och är aktiv, så du bör återaktivera skyddet i den sekundära regionen.
- Rensa resursen som distribuerats i den sekundära regionen , till exempel resurser som distribuerats i
was-cluster-westus-mjg022624. - Använd samma steg i avsnittet Konfigurera haveriberedskap för klustret med hjälp av Azure Site Recovery för att skydda den primära regionen i den sekundära regionen, förutom följande ändringar:
- Hoppa över stegen i avsnittet Skapa ett Recovery Services-valv eftersom du skapade ett tidigare , till exempel
recovery-service-vault-westus-mjg022624. - För > väljer du det befintliga virtuella nätverket i den sekundära regionen.
- Hoppa över stegen i avsnittet Ytterligare nätverkskonfiguration för den sekundära regionen eftersom du skapade och konfigurerade dessa resurser tidigare.
- Hoppa över stegen i avsnittet Skapa ett Recovery Services-valv eftersom du skapade ett tidigare , till exempel
Rensa resurser
Om du inte fortsätter att använda WebSphere-kluster och andra komponenter använder du följande steg för att ta bort resursgrupperna för att rensa de resurser som används i den här självstudien:
- Ange resursgruppens namn på Azure SQL Database-servrar – till exempel
myResourceGroup– i sökrutan överst i Azure-portalen och välj den matchade resursgruppen i sökresultaten. - Välj Ta bort resursgrupp.
- I Ange resursgruppens namn för att bekräfta borttagningen anger du resursgruppens namn.
- Välj Ta bort.
- Upprepa steg 1–4 för resursgruppen i Traffic Manager – till exempel
myResourceGroupTM1. - I sökrutan överst i Azure-portalen anger du Recovery Services-valv och väljer sedan Recovery Services-valv i sökresultaten.
- Välj namnet på ditt Recovery Services-valv – till exempel
recovery-service-vault-westus-mjg022624. - Under Hantera väljer du Återställningsplaner (Site Recovery). Välj den återställningsplan som du skapade , till exempel
recovery-plan-mjg022624. - Använd samma steg i avsnittet Inaktivera replikering för att ta bort lås på replikerade objekt.
- Upprepa steg 1–4 för resursgruppen för det primära WebSphere-klustret , till exempel
was-cluster-westus-mjg022624. - Upprepa steg 1–4 för resursgruppen för det sekundära WebSphere-klustret , till exempel
was-cluster-eastus-mjg022624.
Nästa steg
I den här självstudien konfigurerar du en HA/DR-lösning som består av en aktiv-passiv programinfrastrukturnivå med en aktiv-passiv databasnivå och där båda nivåerna sträcker sig över två geografiskt olika platser. På den första platsen är både programinfrastrukturnivån och databasnivån aktiva. På den andra platsen återställs den sekundära domänen med Azure Site Recovery-tjänsten och den sekundära databasen är i vänteläge.
Fortsätt att utforska följande referenser för fler alternativ för att skapa HA/DR-lösningar och köra WebSphere på Azure: