Migrera HDInsight-kluster till en nyare version
Om du vill dra nytta av de senaste HDInsight-funktionerna rekommenderar vi att HDInsight-kluster regelbundet migreras till den senaste versionen. HDInsight stöder inte uppgraderingar på plats där ett befintligt kluster uppgraderas till en nyare komponentversion. Du måste skapa ett nytt kluster med önskad komponent och plattformsversion och sedan migrera dina program för att använda det nya klustret. Följ riktlinjerna nedan för att migrera dina HDInsight-klusterversioner.
Kommentar
Om du skapar ett Hive-kluster med en primär lagringscontainer kopierar du det från ett befintligt HDInsight-kluster. Kopiera inte det fullständiga innehållet. Kopiera endast de datamappar som är konfigurerade.
Migreringsuppgifter
Arbetsflödet för att uppgradera HDInsight-klustret är följande.
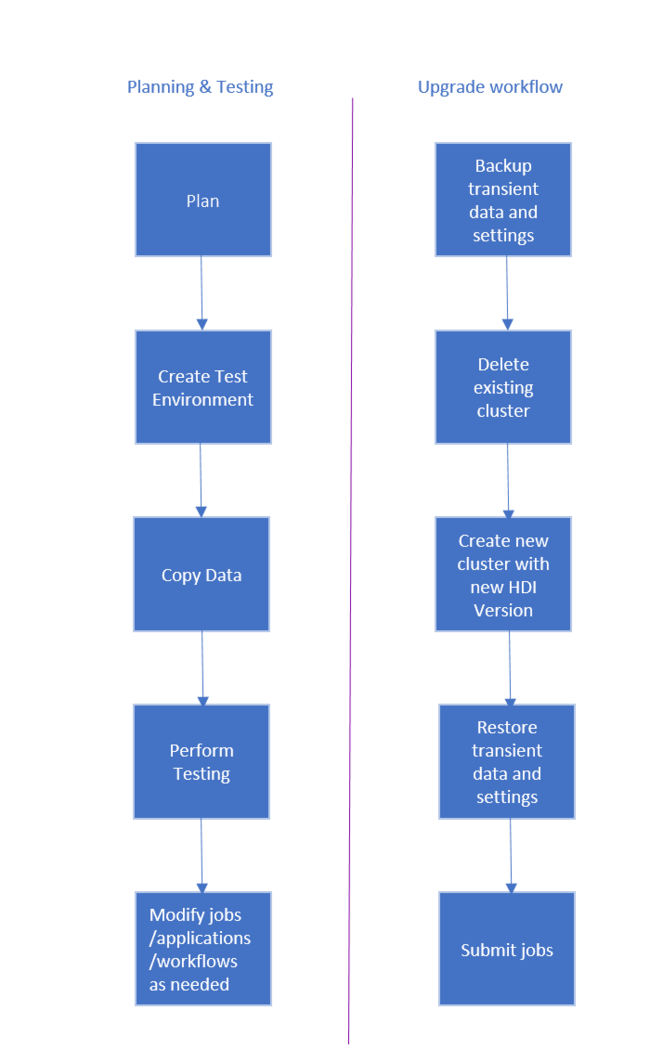
- Läs varje avsnitt i det här dokumentet för att förstå vilka ändringar som kan krävas när du uppgraderar HDInsight-klustret.
- Skapa ett kluster som en test-/kvalitetssäkringsmiljö. Mer information om hur du skapar ett kluster finns i Lär dig hur du skapar Linux-baserade HDInsight-kluster
- Kopiera befintliga jobb, datakällor och mottagare till den nya miljön.
- Utför valideringstestning för att se till att dina jobb fungerar som förväntat i det nya klustret.
När du har kontrollerat att allt fungerar som förväntat schemalägger du stilleståndstid för migreringen. Utför följande åtgärder under den här stilleståndstiden:
- Säkerhetskopiera tillfälliga data som lagras lokalt på klusternoderna. Om du till exempel har data som lagras direkt på en huvudnod.
- Ta bort det befintliga klustret.
- Skapa ett kluster i samma VNET-undernät med den senaste (eller stöds) HDI-versionen med samma standarddatalager som det tidigare klustret använde. Detta gör att det nya klustret kan fortsätta arbeta mot dina befintliga produktionsdata.
- Importera tillfälliga data som du säkerhetskopierade.
- Starta jobb/fortsätt bearbetningen med det nya klustret.
Arbetsbelastningsspecifik vägledning
Följande dokument ger vägledning om hur du migrerar specifika arbetsbelastningar:
Säkerhetskopiera och återställ
Mer information om säkerhetskopiering och återställning av databaser finns i Återställa en databas i Azure SQL Database med hjälp av automatiserade säkerhetskopieringar av databaser.
Uppgraderingsscenarier
Som nämnts ovan rekommenderar Microsoft att HDInsight-kluster regelbundet migreras till den senaste versionen för att dra nytta av nya funktioner och korrigeringar. Se följande lista över orsaker som vi begär att ett kluster ska tas bort och distribueras om:
- Klusterversionen har dragits tillbaka eller om du har ett klusterproblem som skulle lösas med en nyare version.
- Rotorsaken till ett klusterproblem är fast besluten att relatera en undersized VM. Visa Microsofts rekommenderade nodkonfiguration.
- En kund öppnar ett supportärende och Microsofts teknikteam fastställer att problemet redan har åtgärdats i en nyare klusterversion.
- En standarddatabas för metaarkiv (Ambari, Hive, Oozie, Ranger) har nått sin användningsgräns. Microsoft ber dig att återskapa klustret med hjälp av en anpassad metaarkivdatabas .
- Rotorsaken till ett klusterproblem beror på en åtgärd som inte stöds. Här är några av de vanliga åtgärder som inte stöds:
- Flytta eller lägga till en tjänst i Ambari. Se informationen om klustertjänsterna i Ambari. En av de åtgärder som är tillgängliga på menyn Service Actions är Move [Service Name]. En annan åtgärd är Lägg till [Tjänstnamn]. Båda dessa alternativ stöds inte.
- Skadade Python-paket. HDInsight-kluster är beroende av de inbyggda Python-miljöerna Python 2.7 och Python 3.5. Direkt installation av anpassade paket i de inbyggda standardmiljöerna kan orsaka oväntade ändringar i biblioteksversionen och bryta klustret. Lär dig hur du på ett säkert sätt installerar anpassade externa Python-paket för dina Spark-program.
- Programvara från tredje part. Kunder har möjlighet att installera programvara från tredje part i sina HDInsight-kluster. Vi rekommenderar dock att du återskapar klustret om det bryter den befintliga funktionen.
- Flera arbetsbelastningar i samma kluster. I HDInsight 4.0 behöver Hive Warehouse-Anslut eller separata kluster för Spark- och Interaktiv fråga arbetsbelastningar. Följ de här stegen för att konfigurera båda kluster i Azure HDInsight. På samma sätt kräver integrering av Spark med HBASE två olika kluster.
- Anpassat Ambari DB-lösenord har ändrats. Ambari DB-lösenordet anges när klustret skapas och det finns ingen aktuell mekanism för att uppdatera det. Om en kund distribuerar klustret med en anpassad Ambari DB kan de ändra DB-lösenordet i SQL DB. Det finns dock inget sätt att uppdatera lösenordet för ett HDInsight-kluster som körs.
- Ändra HDInsight Load Balancers. HdInsight-lastbalanserare som distribueras automatiskt för Ambari- och SSH-åtkomst bör inte ändras eller tas bort. Om du ändrar HDInsight-lastbalanserarna och den bryter klusterfunktionerna rekommenderar vi att du distribuerar om klustret.
Nästa steg
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för