Träna Keras-modeller i stor skala med Azure Machine Learning
GÄLLER FÖR: Python SDK azure-ai-ml v2 (aktuell)
Python SDK azure-ai-ml v2 (aktuell)
I den här artikeln får du lära dig hur du kör dina Keras-träningsskript med hjälp av Azure Machine Learning Python SDK v2.
Exempelkoden i den här artikeln använder Azure Machine Learning för att träna, registrera och distribuera en Keras-modell som skapats med TensorFlow-serverdelen. Modellen, ett djupt neuralt nätverk (DNN) som skapats med Keras Python-biblioteket som körs ovanpå TensorFlow, klassificerar handskrivna siffror från den populära MNIST-datauppsättningen.
Keras är ett api för neurala nätverk på hög nivå som kan köras ovanpå andra populära DNN-ramverk för att förenkla utvecklingen. Med Azure Machine Learning kan du snabbt skala ut träningsjobb med hjälp av elastiska beräkningsresurser för molnet. Du kan också spåra dina träningskörningar, versionsmodeller, distribuera modeller och mycket mer.
Oavsett om du utvecklar en Keras-modell från grunden eller om du för in en befintlig modell i molnet kan Azure Machine Learning hjälpa dig att skapa produktionsklara modeller.
Kommentar
Om du använder Keras API tf.keras inbyggt i TensorFlow och inte det fristående Keras-paketet läser du i stället Träna TensorFlow-modeller.
Förutsättningar
För att kunna dra nytta av den här artikeln måste du:
- Få åtkomst till en Azure-prenumeration. Om du inte redan har ett skapar du ett kostnadsfritt konto.
- Kör koden i den här artikeln med antingen en Azure Machine Learning-beräkningsinstans eller en egen Jupyter-notebook-fil.
- Azure Machine Learning-beräkningsinstans – inga nedladdningar eller installation krävs
- Slutför Skapa resurser för att komma igång med att skapa en dedikerad notebook-server som är förinstallerad med SDK och exempellagringsplatsen.
- I mappen exempel på djupinlärning på notebook-servern hittar du en slutförd och expanderad notebook-fil genom att navigera till den här katalogen: v2 > sdk > python > jobs > single-step > tensorflow > train-hyperparameter-tune-deploy-with-keras.
- Jupyter Notebook-servern
- Azure Machine Learning-beräkningsinstans – inga nedladdningar eller installation krävs
- Ladda ned träningsskripten keras_mnist.py och utils.py.
Du hittar också en färdig Jupyter Notebook-version av den här guiden på sidan GitHub-exempel.
Innan du kan köra koden i den här artikeln för att skapa ett GPU-kluster måste du begära en kvotökning för din arbetsyta.
Konfigurera jobbet
Det här avsnittet konfigurerar jobbet för träning genom att läsa in nödvändiga Python-paket, ansluta till en arbetsyta, skapa en beräkningsresurs för att köra ett kommandojobb och skapa en miljö för att köra jobbet.
Ansluta till arbetsytan
Först måste du ansluta till din Azure Machine Learning-arbetsyta. Azure Machine Learning-arbetsytan är den översta resursen för tjänsten. Det ger dig en central plats där du kan arbeta med alla artefakter som du skapar när du använder Azure Machine Learning.
Vi använder DefaultAzureCredential för att få åtkomst till arbetsytan. Den här autentiseringsuppgiften bör kunna hantera de flesta Azure SDK-autentiseringsscenarier.
Om DefaultAzureCredential inte fungerar för dig kan du se azure-identity reference documentation eller Set up authentication för mer tillgängliga autentiseringsuppgifter.
# Handle to the workspace
from azure.ai.ml import MLClient
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()Om du föredrar att använda en webbläsare för att logga in och autentisera bör du avkommentera följande kod och använda den i stället.
# Handle to the workspace
# from azure.ai.ml import MLClient
# Authentication package
# from azure.identity import InteractiveBrowserCredential
# credential = InteractiveBrowserCredential()
Hämta sedan en referens till arbetsytan genom att ange ditt prenumerations-ID, resursgruppsnamn och arbetsytenamn. Så här hittar du följande parametrar:
- Leta efter namnet på arbetsytan i det övre högra hörnet i verktygsfältet Azure Machine Learning-studio.
- Välj namnet på arbetsytan för att visa resursgruppen och prenumerations-ID:t.
- Kopiera värdena för Resursgrupp och Prenumerations-ID till koden.
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)Resultatet av att köra det här skriptet är en arbetsytereferens som du ska använda för att hantera andra resurser och jobb.
Kommentar
- När du skapar
MLClientansluts inte klienten till arbetsytan. Klientinitieringen är lat och väntar första gången den behöver göra ett anrop. I den här artikeln sker detta när beräkning skapas.
Skapa en beräkningsresurs för att köra jobbet
Azure Machine Learning behöver en beräkningsresurs för att köra ett jobb. Den här resursen kan vara datorer med en eller flera noder med Linux eller Windows OS, eller en specifik beräkningsinfrastruktur som Spark.
I följande exempelskript etablerar vi en Linux compute cluster. Du kan se sidan Azure Machine Learning pricing för den fullständiga listan över VM-storlekar och priser. Eftersom vi behöver ett GPU-kluster för det här exemplet ska vi välja en STANDARD_NC6 modell och skapa en Azure Machine Learning-beräkning.
from azure.ai.ml.entities import AmlCompute
gpu_compute_target = "gpu-cluster"
try:
# let's see if the compute target already exists
gpu_cluster = ml_client.compute.get(gpu_compute_target)
print(
f"You already have a cluster named {gpu_compute_target}, we'll reuse it as is."
)
except Exception:
print("Creating a new gpu compute target...")
# Let's create the Azure ML compute object with the intended parameters
gpu_cluster = AmlCompute(
# Name assigned to the compute cluster
name="gpu-cluster",
# Azure ML Compute is the on-demand VM service
type="amlcompute",
# VM Family
size="STANDARD_NC6s_v3",
# Minimum running nodes when there is no job running
min_instances=0,
# Nodes in cluster
max_instances=4,
# How many seconds will the node running after the job termination
idle_time_before_scale_down=180,
# Dedicated or LowPriority. The latter is cheaper but there is a chance of job termination
tier="Dedicated",
)
# Now, we pass the object to MLClient's create_or_update method
gpu_cluster = ml_client.begin_create_or_update(gpu_cluster).result()
print(
f"AMLCompute with name {gpu_cluster.name} is created, the compute size is {gpu_cluster.size}"
)Skapa en jobbmiljö
Om du vill köra ett Azure Machine Learning-jobb behöver du en miljö. En Azure Machine Learning-miljö kapslar in de beroenden (till exempel programkörning och bibliotek) som behövs för att köra maskininlärningsträningsskriptet på beräkningsresursen. Den här miljön liknar en Python-miljö på den lokala datorn.
Med Azure Machine Learning kan du antingen använda en kuraterad (eller färdig) miljö eller skapa en anpassad miljö med hjälp av en Docker-avbildning eller en Conda-konfiguration. I den här artikeln skapar du en anpassad Conda-miljö för dina jobb med hjälp av en Conda YAML-fil.
Skapa en anpassad miljö
Om du vill skapa din anpassade miljö definierar du dina Conda-beroenden i en YAML-fil. Skapa först en katalog för lagring av filen. I det här exemplet har vi namngett katalogen dependencies.
import os
dependencies_dir = "./dependencies"
os.makedirs(dependencies_dir, exist_ok=True)Skapa sedan filen i katalogen beroenden. I det här exemplet har vi döpt filen conda.ymltill .
%%writefile {dependencies_dir}/conda.yaml
name: keras-env
channels:
- conda-forge
dependencies:
- python=3.8
- pip=21.2.4
- pip:
- protobuf~=3.20
- numpy==1.22
- tensorflow-gpu==2.2.0
- keras<=2.3.1
- matplotlib
- azureml-mlflow==1.42.0Specifikationen innehåller några vanliga paket (till exempel numpy och pip) som du ska använda i ditt jobb.
Använd sedan YAML-filen för att skapa och registrera den här anpassade miljön på din arbetsyta. Miljön paketeras i en Docker-container vid körning.
from azure.ai.ml.entities import Environment
custom_env_name = "keras-env"
job_env = Environment(
name=custom_env_name,
description="Custom environment for keras image classification",
conda_file=os.path.join(dependencies_dir, "conda.yaml"),
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
)
job_env = ml_client.environments.create_or_update(job_env)
print(
f"Environment with name {job_env.name} is registered to workspace, the environment version is {job_env.version}"
)Mer information om hur du skapar och använder miljöer finns i Skapa och använda programvarumiljöer i Azure Machine Learning.
Konfigurera och skicka ditt träningsjobb
I det här avsnittet börjar vi med att introducera data för träning. Sedan går vi igenom hur du kör ett träningsjobb med hjälp av ett träningsskript som vi har angett. Du lär dig att skapa träningsjobbet genom att konfigurera kommandot för att köra träningsskriptet. Sedan skickar du träningsjobbet som ska köras i Azure Machine Learning.
Hämta träningsdata
Du använder data från MNIST-databasen (Modified National Institute of Standards and Technology) med handskrivna siffror. Dessa data kommer från Yan LeCuns webbplats och lagras på ett Azure-lagringskonto.
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"Mer information om MNIST-datauppsättningen finns på Yan LeCuns webbplats.
Förbereda träningsskriptet
I den här artikeln har vi angett träningsskriptet keras_mnist.py. I praktiken bör du kunna använda ett anpassat träningsskript som det är och köra det med Azure Machine Learning utan att behöva ändra koden.
Det angivna träningsskriptet gör följande:
- hanterar förbearbetningen av data och delar upp data i test- och träningsdata.
- tränar en modell med hjälp av data. och
- returnerar utdatamodellen.
Under pipelinekörningen använder du MLFlow för att logga parametrarna och måtten. Information om hur du aktiverar MLFlow-spårning finns i Spåra ML-experiment och modeller med MLflow.
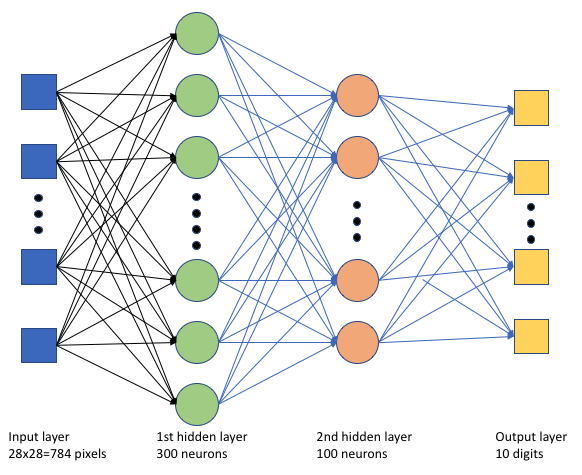
I träningsskriptet keras_mnist.pyskapar vi ett enkelt djupt neuralt nätverk (DNN). Det här DNN:et har:
- Ett indataskikt med 28 * 28 = 784 neuroner. Varje neuron representerar en bildpixel.
- Två dolda lager. Det första dolda lagret har 300 nervceller och det andra dolda lagret har 100 neuroner.
- Ett utdataskikt med 10 neuroner. Varje neuron representerar en riktad etikett från 0 till 9.
Skapa träningsjobbet
Nu när du har alla tillgångar som krävs för att köra jobbet är det dags att skapa det med Hjälp av Azure Machine Learning Python SDK v2. I det här exemplet skapar vi en command.
En Azure Machine Learning command är en resurs som anger all information som behövs för att köra träningskoden i molnet. Den här informationen omfattar indata och utdata, typ av maskinvara som ska användas, programvara som ska installeras och hur du kör koden. Innehåller command information för att köra ett enda kommando.
Konfigurera kommandot
Du använder det allmänna syftet command för att köra träningsskriptet och utföra önskade uppgifter. Skapa ett Command objekt för att ange konfigurationsinformationen för ditt träningsjobb.
from azure.ai.ml import command
from azure.ai.ml import UserIdentityConfiguration
from azure.ai.ml import Input
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"
job = command(
inputs=dict(
data_folder=Input(type="uri_folder", path=web_path),
batch_size=50,
first_layer_neurons=300,
second_layer_neurons=100,
learning_rate=0.001,
),
compute=gpu_compute_target,
environment=f"{job_env.name}:{job_env.version}",
code="./src/",
command="python keras_mnist.py --data-folder ${{inputs.data_folder}} --batch-size ${{inputs.batch_size}} --first-layer-neurons ${{inputs.first_layer_neurons}} --second-layer-neurons ${{inputs.second_layer_neurons}} --learning-rate ${{inputs.learning_rate}}",
experiment_name="keras-dnn-image-classify",
display_name="keras-classify-mnist-digit-images-with-dnn",
)Indata för det här kommandot inkluderar dataplatsen, batchstorleken, antalet neuroner i det första och andra lagret och inlärningshastigheten. Observera att vi har skickat webbsökvägen direkt som indata.
För parametervärdena:
- ange det beräkningskluster
gpu_compute_target = "gpu-cluster"som du skapade för att köra det här kommandot. - ange den anpassade miljö
keras-envsom du skapade för att köra Azure Machine Learning-jobbet. - konfigurera själva kommandoradsåtgärden – i det här fallet är
python keras_mnist.pykommandot . Du kan komma åt indata och utdata i kommandot via notationen${{ ... }}och - konfigurera metadata, till exempel visningsnamn och experimentnamn. där ett experiment är en container för alla iterationer man gör i ett visst projekt. Alla jobb som skickas under samma experimentnamn visas bredvid varandra i Azure Machine Learning-studio.
- ange det beräkningskluster
I det här exemplet använder
UserIdentitydu för att köra kommandot. Att använda en användaridentitet innebär att kommandot använder din identitet för att köra jobbet och komma åt data från bloben.
Skicka jobbet
Nu är det dags att skicka jobbet som ska köras i Azure Machine Learning. Den här gången använder create_or_update du på ml_client.jobs.
ml_client.jobs.create_or_update(job)När jobbet har slutförts registrerar det en modell på din arbetsyta (som ett resultat av träningen) och skickar en länk för att visa jobbet i Azure Machine Learning-studio.
Varning
Azure Machine Learning kör träningsskript genom att kopiera hela källkatalogen. Om du har känsliga data som du inte vill ladda upp använder du en .ignore-fil eller tar inte med den i källkatalogen.
Vad händer under jobbkörningen?
När jobbet körs går det igenom följande steg:
Förbereder: En docker-avbildning skapas enligt den definierade miljön. Avbildningen laddas upp till arbetsytans containerregister och cachelagras för senare körningar. Loggar strömmas också till jobbhistoriken och kan visas för att övervaka förloppet. Om en kuraterad miljö anges används den cachelagrade avbildningsstöd som den kurerade miljön.
Skalning: Klustret försöker skala upp om det krävs fler noder för att köra körningen än vad som för närvarande är tillgängligt.
Körs: Alla skript i skriptmappens src laddas upp till beräkningsmålet, datalager monteras eller kopieras och skriptet körs. Utdata från stdout och mappen ./logs strömmas till jobbhistoriken och kan användas för att övervaka jobbet.
Finjustera modellhyperparametrar
Du har tränat modellen med en uppsättning parametrar. Nu ska vi se om du kan förbättra modellens noggrannhet ytterligare. Du kan finjustera och optimera modellens hyperparametrar med hjälp av Funktionerna i Azure Machine Learning sweep .
Om du vill justera modellens hyperparametrar definierar du det parameterutrymme som du vill söka i under träningen. Du gör detta genom att ersätta några av parametrarna (batch_size, , first_layer_neuronssecond_layer_neuronsoch learning_rate) som skickas till träningsjobbet med särskilda indata från azure.ml.sweep paketet.
from azure.ai.ml.sweep import Choice, LogUniform
# we will reuse the command_job created before. we call it as a function so that we can apply inputs
# we do not apply the 'iris_csv' input again -- we will just use what was already defined earlier
job_for_sweep = job(
batch_size=Choice(values=[25, 50, 100]),
first_layer_neurons=Choice(values=[10, 50, 200, 300, 500]),
second_layer_neurons=Choice(values=[10, 50, 200, 500]),
learning_rate=LogUniform(min_value=-6, max_value=-1),
)Sedan konfigurerar du svepning på kommandojobbet med hjälp av några svepspecifika parametrar, till exempel det primära måttet att titta på och samplingsalgoritmen som ska användas.
I följande kod använder vi slumpmässig sampling för att prova olika konfigurationsuppsättningar med hyperparametrar i ett försök att maximera vårt primära mått, validation_acc.
Vi definierar också en princip för tidig uppsägning – BanditPolicy. Den här principen fungerar genom att kontrollera jobbet varannan iteration. Om det primära måttet ligger validation_accutanför det översta tioprocentsintervallet avslutar Azure Machine Learning jobbet. Detta sparar modellen från att fortsätta utforska hyperparametrar som inte visar något löfte om att hjälpa till att nå målmåttet.
from azure.ai.ml.sweep import BanditPolicy
sweep_job = job_for_sweep.sweep(
compute=gpu_compute_target,
sampling_algorithm="random",
primary_metric="Accuracy",
goal="Maximize",
max_total_trials=20,
max_concurrent_trials=4,
early_termination_policy=BanditPolicy(slack_factor=0.1, evaluation_interval=2),
)Nu kan du skicka det här jobbet som tidigare. Den här gången kör du ett svepjobb som sveper över ditt tågjobb.
returned_sweep_job = ml_client.create_or_update(sweep_job)
# stream the output and wait until the job is finished
ml_client.jobs.stream(returned_sweep_job.name)
# refresh the latest status of the job after streaming
returned_sweep_job = ml_client.jobs.get(name=returned_sweep_job.name)Du kan övervaka jobbet med hjälp av länken för studioanvändargränssnittet som visas under jobbkörningen.
Hitta och registrera den bästa modellen
När alla körningar har slutförts kan du hitta den körning som skapade modellen med högsta noggrannhet.
from azure.ai.ml.entities import Model
if returned_sweep_job.status == "Completed":
# First let us get the run which gave us the best result
best_run = returned_sweep_job.properties["best_child_run_id"]
# lets get the model from this run
model = Model(
# the script stores the model as "keras_dnn_mnist_model"
path="azureml://jobs/{}/outputs/artifacts/paths/keras_dnn_mnist_model/".format(
best_run
),
name="run-model-example",
description="Model created from run.",
type="mlflow_model",
)
else:
print(
"Sweep job status: {}. Please wait until it completes".format(
returned_sweep_job.status
)
)Du kan sedan registrera den här modellen.
registered_model = ml_client.models.create_or_update(model=model)Distribuera modellen som en onlineslutpunkt
När du har registrerat din modell kan du distribuera den som en onlineslutpunkt, dvs. som en webbtjänst i Azure-molnet.
För att distribuera en maskininlärningstjänst behöver du vanligtvis:
- De modelltillgångar som du vill distribuera. Dessa tillgångar omfattar modellens fil och metadata som du redan har registrerat i ditt träningsjobb.
- Viss kod som ska köras som en tjänst. Koden kör modellen på en angiven indatabegäran (ett inmatningsskript). Det här postskriptet tar emot data som skickas till en distribuerad webbtjänst och skickar dem till modellen. När modellen har bearbetat data returnerar skriptet modellens svar till klienten. Skriptet är specifikt för din modell och måste förstå de data som modellen förväntar sig och returnerar. När du använder en MLFlow-modell skapar Azure Machine Learning automatiskt det här skriptet åt dig.
Mer information om distribution finns i Distribuera och poängsätta en maskininlärningsmodell med hanterad onlineslutpunkt med Python SDK v2.
Skapa en ny onlineslutpunkt
Som ett första steg för att distribuera din modell måste du skapa din onlineslutpunkt. Slutpunktsnamnet måste vara unikt i hela Azure-regionen. I den här artikeln skapar du ett unikt namn med hjälp av en universellt unik identifierare (UUID).
import uuid
# Creating a unique name for the endpoint
online_endpoint_name = "keras-dnn-endpoint-" + str(uuid.uuid4())[:8]from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
)
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="Classify handwritten digits using a deep neural network (DNN) using Keras",
auth_mode="key",
)
endpoint = ml_client.begin_create_or_update(endpoint).result()
print(f"Endpint {endpoint.name} provisioning state: {endpoint.provisioning_state}")När du har skapat slutpunkten kan du hämta den på följande sätt:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)Distribuera modellen till slutpunkten
När du har skapat slutpunkten kan du distribuera modellen med inmatningsskriptet. En slutpunkt kan ha flera distributioner. Med hjälp av regler kan slutpunkten sedan dirigera trafik till dessa distributioner.
I följande kod skapar du en enda distribution som hanterar 100 % av den inkommande trafiken. Vi har angett ett godtyckligt färgnamn (tff-blått) för distributionen. Du kan också använda andra namn, till exempel tff-green eller tff-red för distributionen. Koden för att distribuera modellen till slutpunkten gör följande:
- distribuerar den bästa versionen av modellen som du registrerade tidigare.
- poängsätter modellen med hjälp av
score.pyfilen och - använder den anpassade miljön (som du skapade tidigare) för att utföra inferens.
from azure.ai.ml.entities import ManagedOnlineDeployment, CodeConfiguration
model = registered_model
# create an online deployment.
blue_deployment = ManagedOnlineDeployment(
name="keras-blue-deployment",
endpoint_name=online_endpoint_name,
model=model,
# code_configuration=CodeConfiguration(code="./src", scoring_script="score.py"),
instance_type="Standard_DS3_v2",
instance_count=1,
)
blue_deployment = ml_client.begin_create_or_update(blue_deployment).result()Kommentar
Förvänta dig att den här distributionen tar lite tid att slutföra.
Testa den distribuerade modellen
Nu när du har distribuerat modellen till slutpunkten kan du förutsäga utdata från den distribuerade modellen med hjälp invoke av metoden på slutpunkten.
För att testa slutpunkten behöver du några testdata. Låt oss lokalt ladda ned testdata som vi använde i vårt träningsskript.
import urllib.request
data_folder = os.path.join(os.getcwd(), "data")
os.makedirs(data_folder, exist_ok=True)
urllib.request.urlretrieve(
"https://azureopendatastorage.blob.core.windows.net/mnist/t10k-images-idx3-ubyte.gz",
filename=os.path.join(data_folder, "t10k-images-idx3-ubyte.gz"),
)
urllib.request.urlretrieve(
"https://azureopendatastorage.blob.core.windows.net/mnist/t10k-labels-idx1-ubyte.gz",
filename=os.path.join(data_folder, "t10k-labels-idx1-ubyte.gz"),
)Läs in dessa i en testdatauppsättning.
from src.utils import load_data
X_test = load_data(os.path.join(data_folder, "t10k-images-idx3-ubyte.gz"), False)
y_test = load_data(
os.path.join(data_folder, "t10k-labels-idx1-ubyte.gz"), True
).reshape(-1)Välj 30 slumpmässiga exempel från testuppsättningen och skriv dem till en JSON-fil.
import json
import numpy as np
# find 30 random samples from test set
n = 30
sample_indices = np.random.permutation(X_test.shape[0])[0:n]
test_samples = json.dumps({"input_data": X_test[sample_indices].tolist()})
# test_samples = bytes(test_samples, encoding='utf8')
with open("request.json", "w") as outfile:
outfile.write(test_samples)Du kan sedan anropa slutpunkten, skriva ut de returnerade förutsägelserna och rita dem tillsammans med indatabilderna. Använd röd teckenfärg och inverterad bild (vit på svart) för att markera de felklassificerade exemplen.
import matplotlib.pyplot as plt
# predict using the deployed model
result = ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./request.json",
deployment_name="keras-blue-deployment",
)
# compare actual value vs. the predicted values:
i = 0
plt.figure(figsize=(20, 1))
for s in sample_indices:
plt.subplot(1, n, i + 1)
plt.axhline("")
plt.axvline("")
# use different color for misclassified sample
font_color = "red" if y_test[s] != result[i] else "black"
clr_map = plt.cm.gray if y_test[s] != result[i] else plt.cm.Greys
plt.text(x=10, y=-10, s=result[i], fontsize=18, color=font_color)
plt.imshow(X_test[s].reshape(28, 28), cmap=clr_map)
i = i + 1
plt.show()Kommentar
Eftersom modellnoggrannheten är hög kan du behöva köra cellen några gånger innan du ser ett felklassificerat exempel.
Rensa resurser
Om du inte använder slutpunkten tar du bort den för att sluta använda resursen. Kontrollera att inga andra distributioner använder slutpunkten innan du tar bort den.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name)Kommentar
Förvänta dig att den här rensningen tar lite tid att slutföra.
Nästa steg
I den här artikeln har du tränat och registrerat en Keras-modell. Du har också distribuerat modellen till en onlineslutpunkt. Mer information om Azure Machine Learning finns i de här andra artiklarna.