Vad är Azure Machine Learning?
Azure Machine Learning är en molntjänst för att påskynda och hantera projektets livscykel för maskininlärning (ML). ML-proffs, dataforskare och tekniker kan använda dem i sina dagliga arbetsflöden för att träna och distribuera modeller och hantera maskininlärningsåtgärder (MLOps).
Du kan skapa en modell i Machine Learning eller använda en modell som skapats från en plattform med öppen källkod, till exempel PyTorch, TensorFlow eller scikit-learn. MLOps-verktyg hjälper dig att övervaka, träna om och distribuera om modeller.
Dricks
Kostnadsfri utvärderingsversion! Om du inte har någon Azure-prenumeration skapar du ett kostnadsfritt konto innan du börjar. Prova den kostnadsfria versionen eller betalversionen av Azure Machine Learning-tjänsten. Du får krediter som du kan använda för att köpa Azure-tjänster. När de är slut kan du behålla kontot och använda kostnadsfria Azure-tjänster. Ditt kreditkort debiteras aldrig om du inte specifikt ändrar dina inställningar och ber om debitering.
Vem är Azure Machine Learning för?
Maskininlärning är till för individer och team som implementerar MLOps i organisationen för att föra ML-modeller till produktion i en säker och granskningsbar produktionsmiljö.
Dataforskare och ML-tekniker kan använda verktyg för att påskynda och automatisera sina dagliga arbetsflöden. Programutvecklare kan använda verktyg för att integrera modeller i program eller tjänster. Plattformsutvecklare kan använda en robust uppsättning verktyg som backas upp av hållbara Azure Resource Manager-API:er för att skapa avancerade ML-verktyg.
Företag som arbetar i Microsoft Azure-molnet kan använda välbekant säkerhet och rollbaserad åtkomstkontroll för infrastruktur. Du kan konfigurera ett projekt för att neka åtkomst till skyddade data och välja åtgärder.
Produktivitet för alla i teamet
ML-projekt kräver ofta ett team med en varierad kompetens för att bygga och underhålla. Machine Learning har verktyg som hjälper dig att:
Samarbeta med ditt team via delade notebook-filer, beräkningsresurser, serverlös beräkning, data och miljöer
Utveckla modeller för rättvisa och förklarande, spårning och granskning för att uppfylla kraven på ursprung och granskningsefterlevnad
Distribuera ML-modeller snabbt och enkelt i stor skala och hantera och styra dem effektivt med MLOps
Köra maskininlärningsarbetsbelastningar var som helst med inbyggd styrning, säkerhet och efterlevnad
Plattformsverktyg som uppfyller dina behov
Vem som helst i ett ML-team kan använda sina verktyg för att få jobbet gjort. Oavsett om du kör snabba experiment, hyperparameterjustering, skapar pipelines eller hanterar slutsatsdragningar kan du använda välbekanta gränssnitt, inklusive:
När du förfinar modellen och samarbetar med andra under resten av Machine Learning-utvecklingscykeln kan du dela och hitta tillgångar, resurser och mått för dina projekt i Machine Learning Studio-användargränssnittet.
Studio
Machine Learning Studio erbjuder flera redigeringsupplevelser beroende på typen av projekt och nivån på din tidigare ML-upplevelse, utan att behöva installera något.
Notebook-filer: Skriv och kör din egen kod på hanterade Jupyter Notebook-servrar som är direkt integrerade i studion. Du kan också öppna notebook-filerna i VS Code, på webben eller på skrivbordet.
Visualisera körningsmått: Analysera och optimera dina experiment med visualisering.
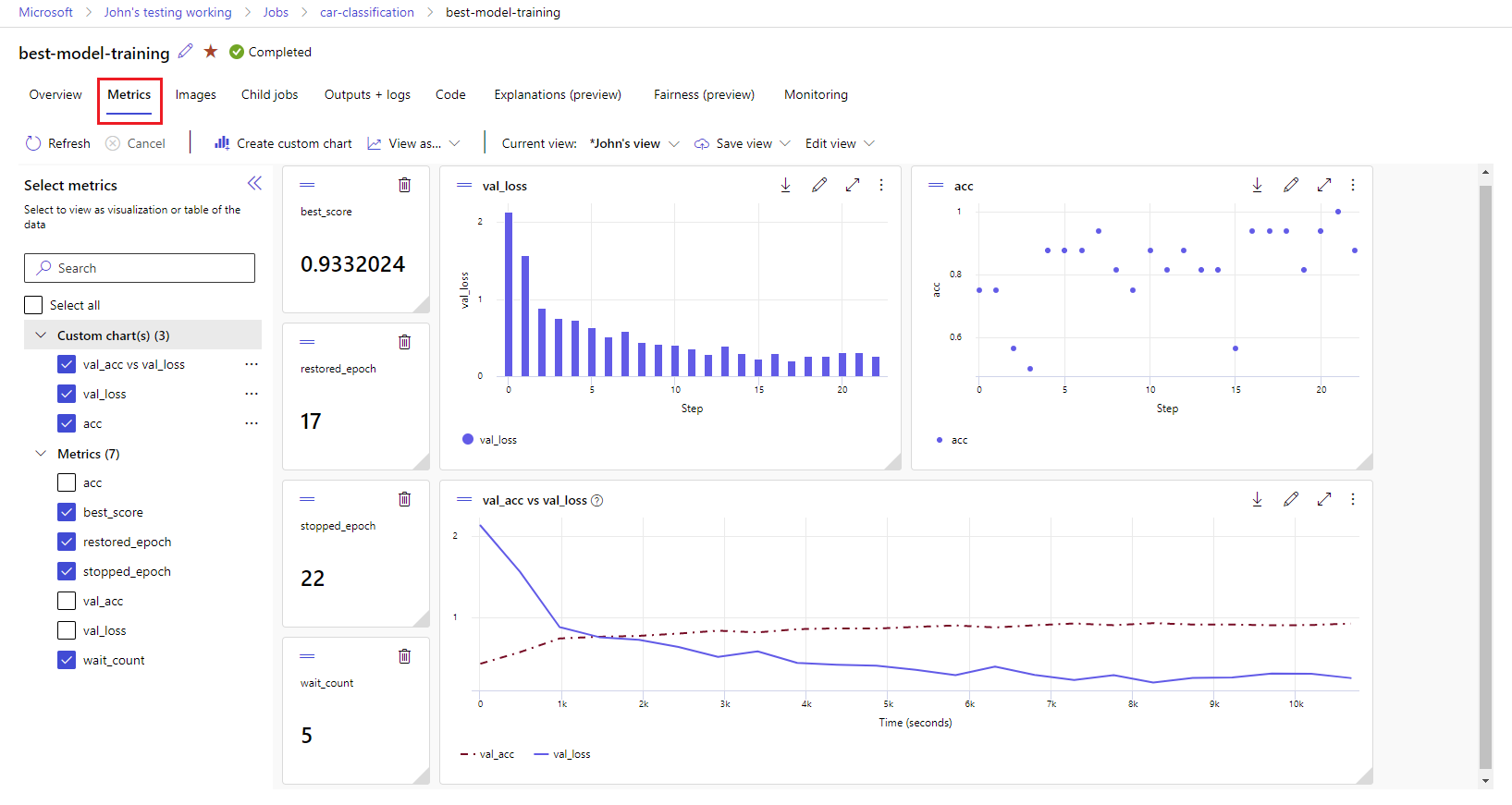
Azure Machine Learning-designer: Använd designern för att träna och distribuera ML-modeller utan att skriva någon kod. Dra och släpp datauppsättningar och komponenter för att skapa ML-pipelines.
Automatiserat användargränssnitt för maskininlärning: Lär dig hur du skapar automatiserade ML-experiment med ett användarvänligt gränssnitt.
Dataetiketter: Använd Machine Learning-dataetiketter för att effektivt samordna bildetiketter eller textetikettprojekt .
Arbeta med LLM:er och generativ AI
Azure Machine Learning innehåller verktyg som hjälper dig att skapa Generativa AI-program som drivs av stora språkmodeller (LLM). Lösningen innehåller en modellkatalog, ett snabbflöde och en uppsättning verktyg för att effektivisera utvecklingscykeln för AI-program.
Med både Azure Machine Learning Studio och Azure AI Studio kan du arbeta med LLM:er. Använd den här guiden för att avgöra vilken studio du ska använda.
Modellkatalog
Modellkatalogen i Azure Machine Learning-studio är navet för att identifiera och använda ett brett utbud av modeller som gör att du kan skapa Generative AI-program. Modellkatalogen innehåller hundratals modeller från modellleverantörer som Azure OpenAI-tjänsten, Mistral, Meta, Cohere, Nvidia, Hugging Face, inklusive modeller som tränats av Microsoft. Modeller från andra leverantörer än Microsoft är icke-Microsoft-produkter, enligt definitionen i Microsofts produktvillkor, och omfattas av villkoren i modellen.
Promptflöde
Azure Machine Learning prompt flow är ett utvecklingsverktyg som utformats för att effektivisera hela utvecklingscykeln för AI-program som drivs av stora språkmodeller (LLM). Promptflöde är en omfattande lösning som förenklar processen med prototyper, experimentering, iterering och distribution av dina AI-program.
Företagsberedskap och säkerhet
Machine Learning integreras med Azure-molnplattformen för att öka säkerheten i ML-projekt.
Säkerhetsintegreringar omfattar:
- Azure Virtual Networks med nätverkssäkerhetsgrupper.
- Azure Key Vault, där du kan spara säkerhetshemligheter, till exempel åtkomstinformation för lagringskonton.
- Azure Container Registry har konfigurerats bakom ett virtuellt nätverk.
Mer information finns i Självstudie: Konfigurera en säker arbetsyta.
Azure-integreringar för kompletta lösningar
Andra integreringar med Azure-tjänster stöder ett ML-projekt från slutpunkt till slutpunkt. De omfattar:
- Azure Synapse Analytics, som används för att bearbeta och strömma data med Spark.
- Azure Arc, där du kan köra Azure-tjänster i en Kubernetes-miljö.
- Lagrings- och databasalternativ, till exempel Azure SQL Database och Azure Blob Storage.
- Azure App Service, som du kan använda för att distribuera och hantera ML-baserade appar.
- Microsoft Purview, som gör att du kan identifiera och katalogisera datatillgångar i hela organisationen.
Viktigt!
Azure Machine Learning lagrar eller bearbetar inte dina data utanför den region där du distribuerar.
Arbetsflöde för maskininlärningsprojekt
Modeller utvecklas vanligtvis som en del av ett projekt med mål och mål. Projekt involverar ofta mer än en person. När du experimenterar med data, algoritmer och modeller är utvecklingen iterativ.
Projektlivscykel
Projektlivscykeln kan variera beroende på projekt, men det ser ofta ut som det här diagrammet.
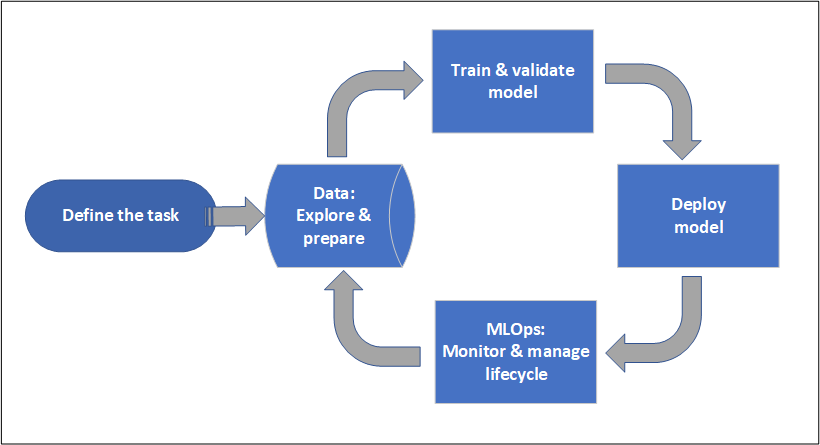
En arbetsyta organiserar ett projekt och möjliggör samarbete för många användare som alla arbetar mot ett gemensamt mål. Användare på en arbetsyta kan enkelt dela resultatet av sina körningar från experimentering i studioanvändargränssnittet. Eller så kan de använda versionshanterade tillgångar för jobb som miljöer och lagringsreferenser.
Mer information finns i Hantera Azure Machine Learning-arbetsytor.
När ett projekt är redo för driftsättning kan användarnas arbete automatiseras i en ML-pipeline och utlösas enligt ett schema eller en HTTPS-begäran.
Du kan distribuera modeller till den hanterade slutsatsdragningslösningen för både realtids- och batchdistributioner, vilket abstraherar bort den infrastrukturhantering som vanligtvis krävs för att distribuera modeller.
Inlärningsmodeller
I Azure Machine Learning kan du köra ditt träningsskript i molnet eller skapa en modell från grunden. Kunder tar ofta med modeller som de har skapat och tränat i ramverk med öppen källkod så att de kan operationalisera dem i molnet.
Öppen och kompatibel
Dataexperter kan använda modeller i Azure Machine Learning som de har skapat i vanliga Python-ramverk, till exempel:
- PyTorch
- TensorFlow
- scikit-learn
- XGBoost
- LightGBM
Andra språk och ramverk stöds också:
- R
- .NET
Mer information finns i Integrering med öppen källkod med Azure Machine Learning.
Automatiserad funktionalisering och algoritmval
I en repetitiv, tidskrävande process i klassisk ML använder dataforskare tidigare erfarenhet och intuition för att välja rätt databedrifter och algoritm för träning. Automatisk ML (AutoML) påskyndar den här processen. Du kan använda det via Machine Learning Studio-användargränssnittet eller Python SDK.
Mer information finns i Vad är automatiserad maskininlärning?.
Optimering av hyperparametrar
Hyperparameteroptimering, eller justering av hyperparametrar, kan vara en omständlig uppgift. Machine Learning kan automatisera den här uppgiften för godtyckliga parametriserade kommandon med liten ändring av jobbdefinitionen. Resultaten visualiseras i studion.
Mer information finns i Justera hyperparametrar.
Distribuerad träning med flera noder
Effektiviteten i träning för djupinlärning och ibland klassiska maskininlärningsträningsjobb kan förbättras drastiskt via distribuerad utbildning med flera noder. Azure Machine Learning-beräkningskluster och serverlös beräkning erbjuder de senaste GPU-alternativen.
Stöds via Azure Machine Learning Kubernetes, Azure Machine Learning-beräkningskluster och serverlös beräkning:
- PyTorch
- TensorFlow
- MPI
Du kan använda MPI-distribution för Horovod eller anpassad multinodlogik. Apache Spark stöds via serverlös Spark-beräkning och ansluten Synapse Spark-pool som använder Azure Synapse Analytics Spark-kluster.
Mer information finns i Distribuerad utbildning med Azure Machine Learning.
Pinsamt parallell träning
Skalning av ett ML-projekt kan kräva en pinsamt parallell modellträning. Det här mönstret är vanligt för scenarier som prognostisering av efterfrågan, där en modell kan tränas för många butiker.
Distribuera modeller
Om du vill föra in en modell i produktion distribuerar du modellen. Azure Machine Learning-hanterade slutpunkter abstraherar den infrastruktur som krävs för både batch- eller realtidsmodellbedömning (inferens).
Realtids- och batchbedömning (slutsatsdragning)
Batchbedömning, eller batch-slutsatsdragning, innebär att anropa en slutpunkt med en referens till data. Batchslutpunkten kör jobb asynkront för att bearbeta data parallellt i beräkningskluster och lagra data för ytterligare analys.
Realtidsbedömning eller onlineinferens innebär att anropa en slutpunkt med en eller flera modelldistributioner och ta emot ett svar nästan i realtid via HTTPS. Trafik kan delas upp i flera distributioner, vilket gör det möjligt att testa nya modellversioner genom att avleda en viss mängd trafik från början och öka när förtroendet för den nya modellen har upprättats.
Mer information finns i:
MLOps: DevOps för maskininlärning
DevOps för ML-modeller, som ofta kallas MLOps, är en process för att utveckla modeller för produktion. En modells livscykel från träning till distribution måste vara granskningsbar om den inte är reproducerbar.
ML-modelllivscykel
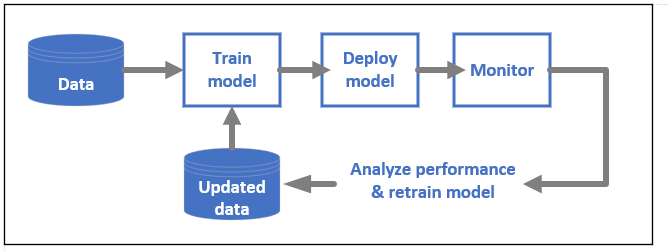
Läs mer om MLOps i Azure Machine Learning.
Integreringar som aktiverar MLOP:er
Maskininlärning skapas med modellens livscykel i åtanke. Du kan granska modellens livscykel ned till en specifik incheckning och miljö.
Några viktiga funktioner som aktiverar MLOps är:
gitintegration.- MLflow-integrering.
- Schemaläggning av maskininlärningspipelines.
- Azure Event Grid-integrering för anpassade utlösare.
- Enkel användning med CI/CD-verktyg som GitHub Actions eller Azure DevOps.
Machine Learning innehåller även funktioner för övervakning och granskning:
- Jobbartefakter, till exempel ögonblicksbilder av kod, loggar och andra utdata.
- Ursprung mellan jobb och tillgångar, till exempel containrar, data och beräkningsresurser.
Om du använder Apache Airflow är paketet airflow-provider-azure-machinelearning en leverantör som gör att du kan skicka arbetsflöden till Azure Machine Learning från Apache AirFlow.
Relaterat innehåll
Börja använda Azure Machine Learning: