Samla in data från modeller i produktion
GÄLLER FÖR: Python SDK azureml v1
Python SDK azureml v1
Den här artikeln visar hur du samlar in data från en Azure Machine Learning-modell som distribuerats i ett Azure Kubernetes Service-kluster (AKS). Insamlade data lagras sedan i Azure Blob Storage.
När insamling har aktiverats hjälper de data som du samlar in dig:
Övervaka dataavvikelser på de produktionsdata som du samlar in.
Analysera insamlade data med Power BI eller Azure Databricks
Fatta bättre beslut om när du ska träna om eller optimera din modell.
Träna om din modell med insamlade data.
Begränsningar
- Funktionen för modelldatainsamling kan bara fungera med Ubuntu 18.04-avbildningen.
Viktigt
Från och med 2023-03-10 är Ubuntu 18.04-avbildningen inaktuell. Stöd för Ubuntu 18.04-avbildningar tas bort från och med januari 2023 när den når EOL den 30 april 2023.
MDC-funktionen är inte kompatibel med någon annan avbildning än Ubuntu 18.04, som inte är tillgänglig när Ubuntu 18.04-avbildningen är inaktuell.
mMer information som du kan referera till:
Anteckning
Datainsamlingsfunktionen är för närvarande i förhandsversion. Förhandsgranskningsfunktioner rekommenderas inte för produktionsarbetsbelastningar.
Vad samlas in och vart det går
Följande data kan samlas in:
Modellindata från webbtjänster som distribueras i ett AKS-kluster. Röstljud, bilder och video samlas inte in.
Modellförutsägelser med hjälp av indata för produktion.
Anteckning
Föraggregering och förberäkningar av dessa data ingår för närvarande inte i insamlingstjänsten.
Utdata sparas i Blob Storage. Eftersom data läggs till i Blob Storage kan du välja ditt favoritverktyg för att köra analysen.
Sökvägen till utdata i bloben följer den här syntaxen:
/modeldata/<subscriptionid>/<resourcegroup>/<workspace>/<webservice>/<model>/<version>/<designation>/<year>/<month>/<day>/data.csv
# example: /modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/12/31/data.csv
Anteckning
I versioner av Azure Machine Learning SDK för Python tidigare än version 0.1.0a16 designation heter identifierargumentet . Om du har utvecklat koden med en tidigare version måste du uppdatera den därefter.
Krav
Om du inte har en Azure-prenumeration kan du skapa ett kostnadsfritt konto innan du börjar.
En Azure Machine Learning-arbetsyta, en lokal katalog som innehåller dina skript och Azure Machine Learning SDK för Python måste installeras. Information om hur du installerar dem finns i Så här konfigurerar du en utvecklingsmiljö.
Du behöver en tränad maskininlärningsmodell som ska distribueras till AKS. Om du inte har någon modell kan du läsa självstudien Träna bildklassificeringsmodell .
Du behöver ett AKS-kluster. Information om hur du skapar en och distribuerar till den finns i Distribuera maskininlärningsmodeller till Azure.
Konfigurera din miljö och installera Azure Machine Learning Monitoring SDK.
Använd en docker-avbildning baserad på Ubuntu 18.04, som levereras med
libssl 1.0.0, det väsentliga beroendet av modeldatacollector. Se fördefinierade avbildningar.
Aktivera datainsamling
Du kan aktivera datainsamling oavsett vilken modell du distribuerar via Azure Machine Learning eller andra verktyg.
Om du vill aktivera datainsamling måste du:
Öppna bedömningsfilen.
Lägg till följande kod överst i filen:
from azureml.monitoring import ModelDataCollectorDeklarera dina datainsamlingsvariabler i din
initfunktion:global inputs_dc, prediction_dc inputs_dc = ModelDataCollector("best_model", designation="inputs", feature_names=["feat1", "feat2", "feat3", "feat4", "feat5", "feat6"]) prediction_dc = ModelDataCollector("best_model", designation="predictions", feature_names=["prediction1", "prediction2"])CorrelationId är en valfri parameter. Du behöver inte använda den om din modell inte kräver det. Korrelations-ID hjälper dig att enklare mappa med andra data, till exempel LoanNumber eller CustomerId.
Parametern Identifierare används senare för att skapa mappstrukturen i bloben. Du kan använda den för att skilja rådata från bearbetade data.
Lägg till följande kodrader i
run(input_df)funktionen:data = np.array(data) result = model.predict(data) inputs_dc.collect(data) #this call is saving our input data into Azure Blob prediction_dc.collect(result) #this call is saving our prediction data into Azure BlobDatainsamling anges inte automatiskt till true när du distribuerar en tjänst i AKS. Uppdatera konfigurationsfilen, som i följande exempel:
aks_config = AksWebservice.deploy_configuration(collect_model_data=True)Du kan också aktivera Application Insights för tjänstövervakning genom att ändra den här konfigurationen:
aks_config = AksWebservice.deploy_configuration(collect_model_data=True, enable_app_insights=True)Information om hur du skapar en ny avbildning och distribuerar maskininlärningsmodellen finns i Distribuera maskininlärningsmodeller till Azure.
Lägg till pip-paketet "Azure-Monitoring" i conda-dependencies för webbtjänstmiljön:
env = Environment('webserviceenv')
env.python.conda_dependencies = CondaDependencies.create(conda_packages=['numpy'],pip_packages=['azureml-defaults','azureml-monitoring','inference-schema[numpy-support]'])
Inaktivera datainsamling
Du kan när som helst sluta samla in data. Använd Python-kod för att inaktivera datainsamling.
## replace <service_name> with the name of the web service
<service_name>.update(collect_model_data=False)
Verifiera och analysera dina data
Du kan välja ett verktyg som du föredrar för att analysera de data som samlas in i bloblagringen.
Få snabb åtkomst till dina blobdata
Logga in på Azure-portalen.
Öppna arbetsytan.
Välj Lagring.

Följ sökvägen till blobens utdata med den här syntaxen:
/modeldata/<subscriptionid>/<resourcegroup>/<workspace>/<webservice>/<model>/<version>/<designation>/<year>/<month>/<day>/data.csv # example: /modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/12/31/data.csv

Analysera modelldata med Power BI
Ladda ned och öppna Power BI Desktop.
Välj Hämta data och välj Azure Blob Storage.
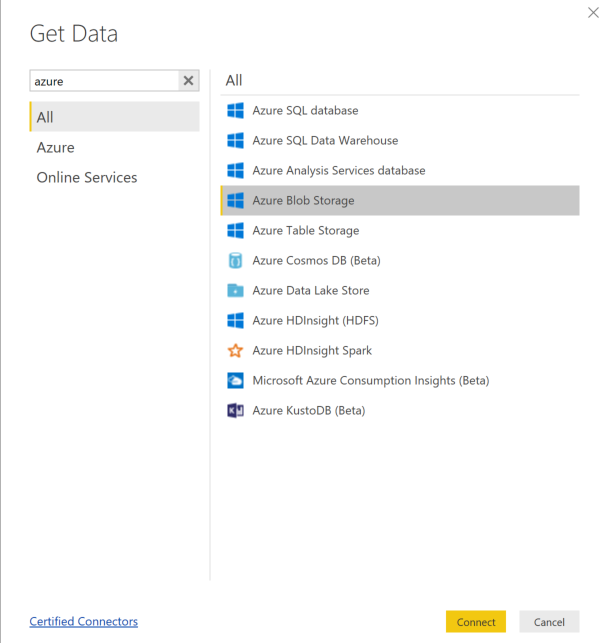
Lägg till lagringskontots namn och ange lagringsnyckeln. Du hittar den här informationen genom att välja Inställningar>Åtkomstnycklar i din blob.
Välj modelldatacontainern och välj Redigera.
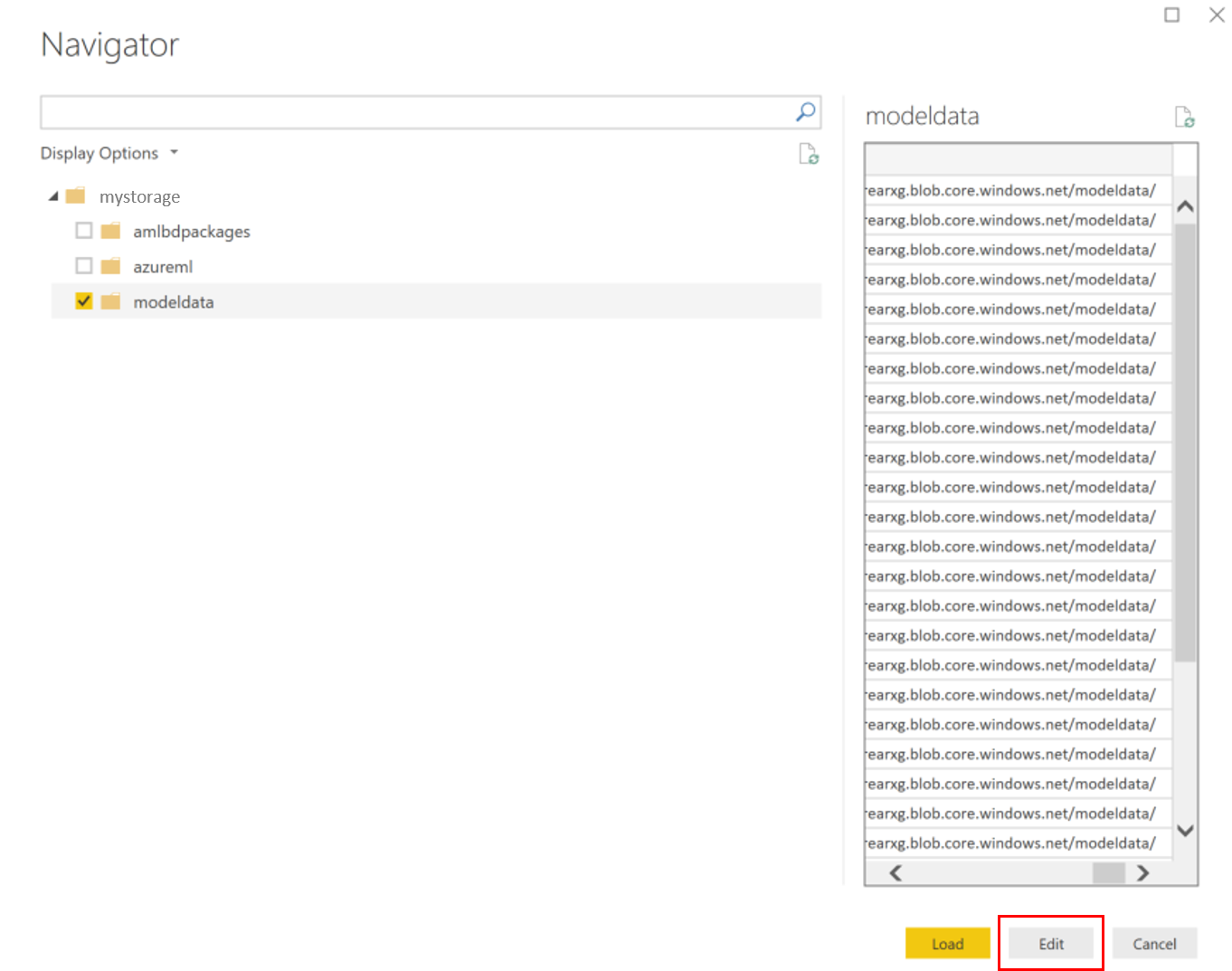
I frågeredigeraren klickar du under kolumnen Namn och lägger till ditt lagringskonto.
Ange din modellsökväg i filtret. Om du bara vill titta på filer från ett visst år eller en viss månad expanderar du bara filtersökvägen. Om du till exempel bara vill titta på marsdata använder du den här filtersökvägen:
/modeldata/<subscriptionid>/<resourcegroupname>/<workspacename>/<webservicename>/<modelname>/<modelversion>/<designation>/<year>/3
Filtrera de data som är relevanta för dig baserat på namnvärden . Om du har lagrat förutsägelser och indata måste du skapa en fråga för var och en.
Välj de nedåtgående dubbelpilarna bredvid kolumnrubriken Innehåll för att kombinera filerna.

Välj OK. Förinläsningar av data.
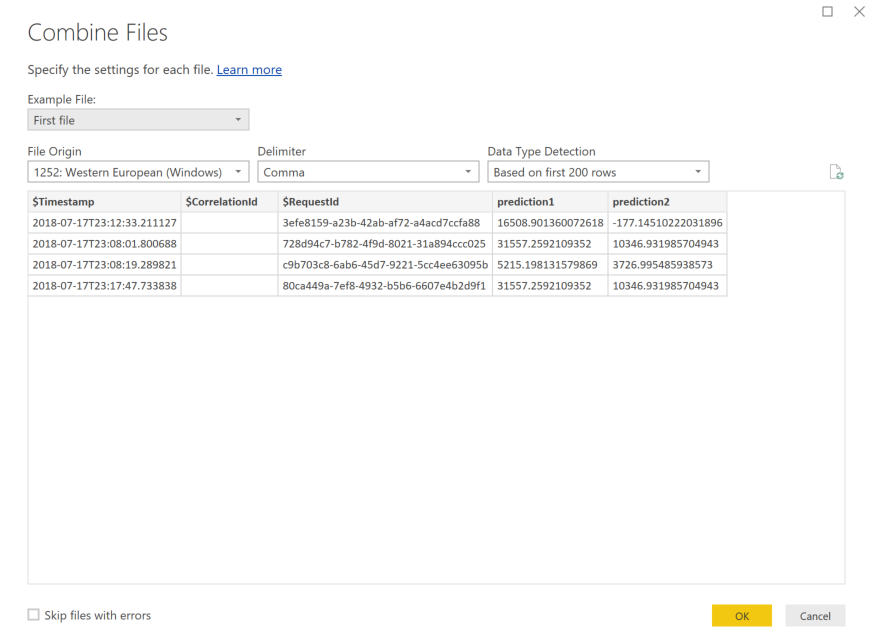
Välj Stäng och tillämpa.
Om du har lagt till indata och förutsägelser sorteras dina tabeller automatiskt efter RequestId-värden .
Börja skapa anpassade rapporter på dina modelldata.




Analysera modelldata med Azure Databricks
Skapa en Azure Databricks-arbetsyta.
Gå till Databricks-arbetsytan.
I Databricks-arbetsytan väljer du Ladda upp data.

Välj Skapa ny tabell och välj Andra datakällor>Azure Blob Storage>Skapa tabell i notebook-fil.
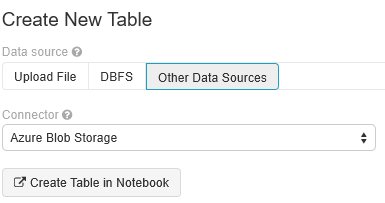
Uppdatera platsen för dina data. Här är ett exempel:
file_location = "wasbs://mycontainer@storageaccountname.blob.core.windows.net/modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/*/*/data.csv" file_type = "csv"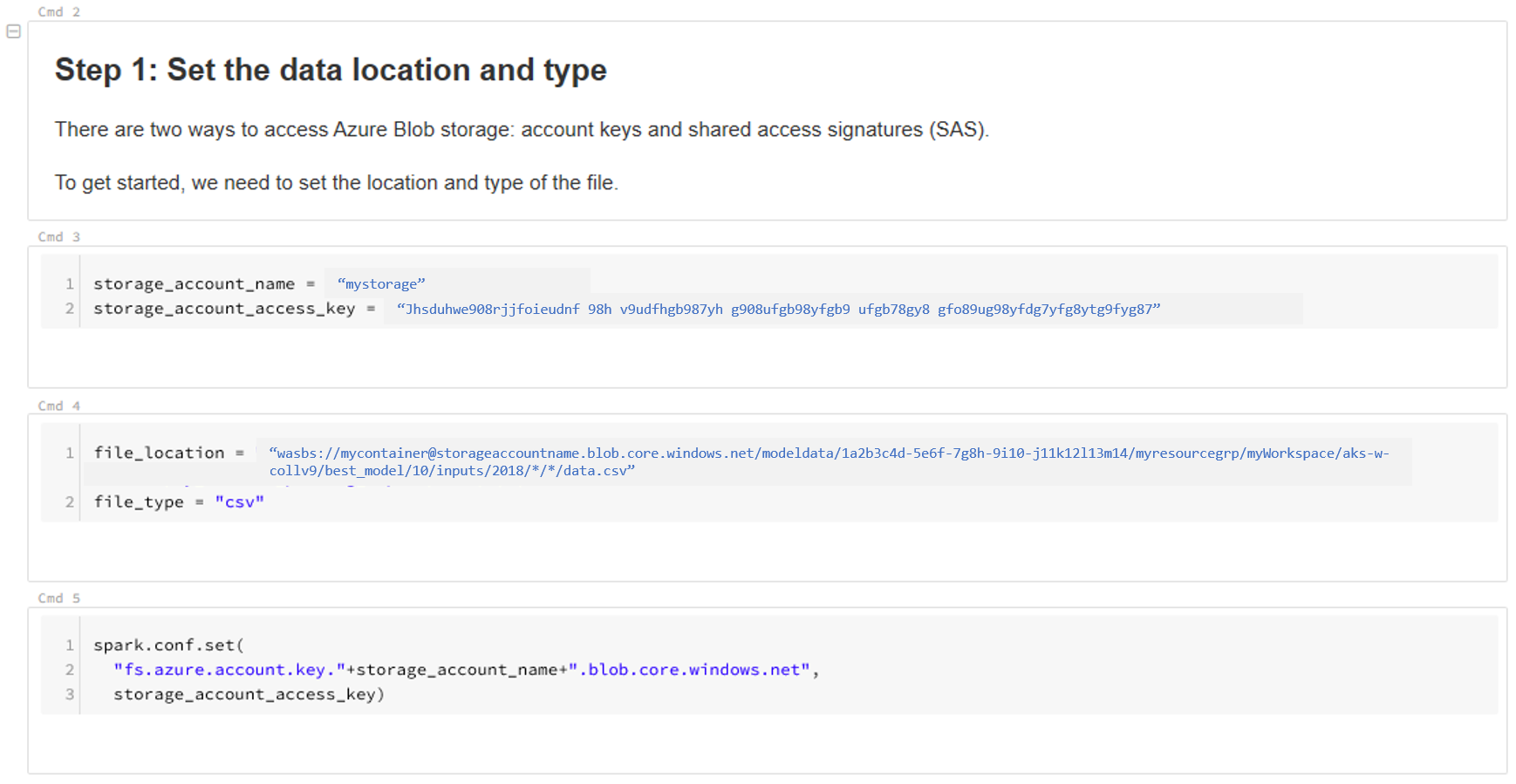
Följ stegen i mallen för att visa och analysera dina data.



Nästa steg
Identifiera dataavvikelser för de data som du har samlat in.