REST-självstudie: Använda kompetensuppsättningar för att generera sökbart innehåll i Azure AI Search
I den här självstudien lär du dig hur du anropar REST-API:er som skapar en AI-berikningspipeline för extrahering och omvandlingar av innehåll under indexering.
Kunskapsuppsättningar lägger till AI-bearbetning till råinnehåll, vilket gör innehållet mer enhetligt och sökbart. När du vet hur kompetensuppsättningar fungerar kan du stödja en mängd olika omvandlingar: från bildanalys till bearbetning av naturligt språk till anpassad bearbetning som du tillhandahåller externt.
Den här självstudien hjälper dig att lära dig att:
- Definiera objekt i en berikningspipeline.
- Skapa en kompetensuppsättning. Anropa OCR, språkidentifiering, entitetsigenkänning och extrahering av nyckelfraser.
- Kör pipelinen. Skapa och läsa in ett sökindex.
- Kontrollera resultaten med hjälp av fulltextsökning.
Om du inte har en Azure-prenumeration öppnar du ett kostnadsfritt konto innan du börjar.
Översikt
I den här självstudien används en REST-klient och REST API:er för Azure AI Search för att skapa en datakälla, ett index, en indexerare och en kunskapsuppsättning.
Indexeraren kör varje steg i pipelinen och börjar med innehållsextrahering av exempeldata (ostrukturerad text och bilder) i en blobcontainer i Azure Storage.
När innehållet har extraherats kör kompetensuppsättningen inbyggda kunskaper från Microsoft för att hitta och extrahera information. Dessa kunskaper omfattar optisk teckenigenkänning (OCR) på bilder, språkidentifiering på text, extrahering av nyckelfraser och entitetsigenkänning (organisationer). Ny information som skapats av kompetensuppsättningen skickas till fält i ett index. När indexet har fyllts i kan du använda fälten i frågor, fasetter och filter.
Förutsättningar
Kommentar
Du kan använda en kostnadsfri söktjänst för den här självstudien. Den kostnadsfria nivån begränsar dig till tre index, tre indexerare och tre datakällor. I den här kursen skapar du en av varje. Innan du börjar bör du se till att du har plats för din tjänst för att acceptera de nya resurserna.
Ladda ned filer
Ladda ned en zip-fil med exempeldatalagringsplatsen och extrahera innehållet. Lär dig mer.
Ladda upp exempeldata till Azure Storage
I Azure Storage skapar du en ny container och ger den namnet cog-search-demo.
Hämta en lagrings-niska veze så att du kan formulera en anslutning i Azure AI Search.
Välj Åtkomstnycklar till vänster.
Kopiera niska veze för antingen nyckel ett eller nyckel två. Niska veze liknar följande exempel:
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
Azure AI-tjänster
Inbyggd AI-berikning backas upp av Azure AI-tjänster, inklusive Language Service och Azure AI Vision för naturligt språk och bildbearbetning. För små arbetsbelastningar som den här självstudien kan du använda den kostnadsfria allokeringen av tjugo transaktioner per indexerare. För större arbetsbelastningar kan du koppla en Azure AI Services-resurs i flera regioner till en kompetensuppsättning för betala per användning-priser.
Kopiera en url för söktjänsten och API-nyckeln
I den här självstudien kräver anslutningar till Azure AI Search en slutpunkt och en API-nyckel. Du kan hämta dessa värden från Azure-portalen.
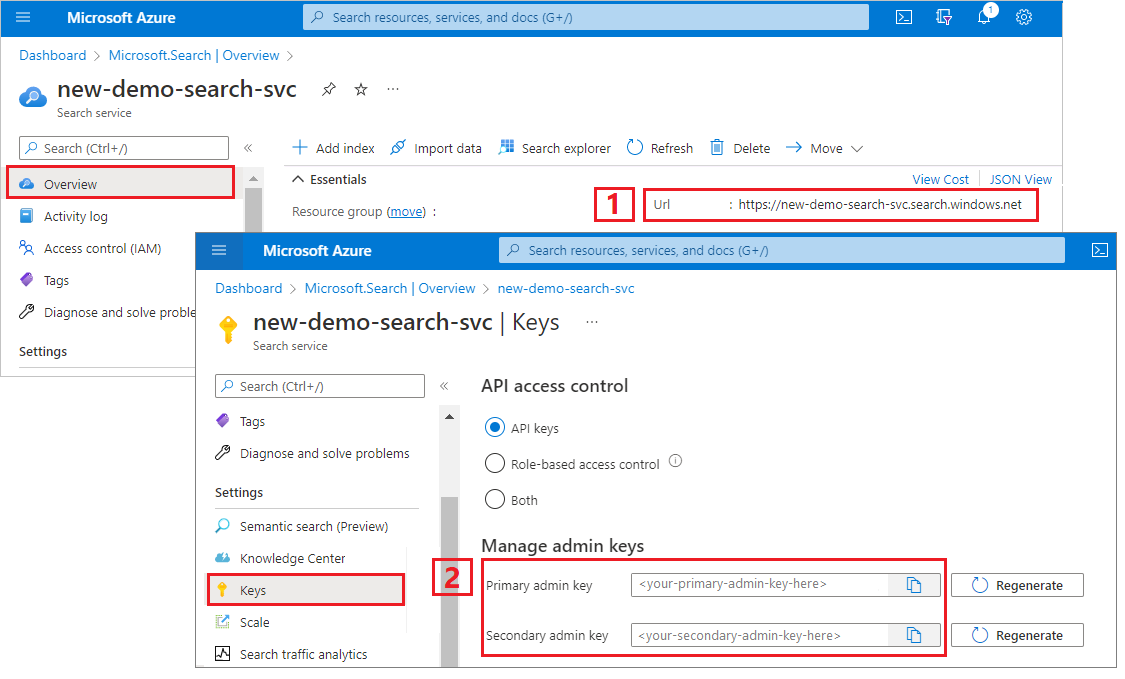
Logga in på Azure-portalen, gå till söktjänstens översiktssida och kopiera URL:en. Här följer ett exempel på hur en slutpunkt kan se ut:
https://mydemo.search.windows.net.Under Inställningar>Nycklar kopierar du en administratörsnyckel. Administratörsnycklar används för att lägga till, ändra och ta bort objekt. Det finns två utbytbara administratörsnycklar. Kopiera någon av dem.
Konfigurera REST-filen
Starta Visual Studio Code och öppna filen skillset-tutorial.rest . Se Snabbstart: Textsökning med REST om du behöver hjälp med REST-klienten.
Ange värden för variablerna: söktjänstens slutpunkt, api-nyckeln för söktjänstens administratör, ett indexnamn, en niska veze till ditt Azure Storage-konto och namnet på blobcontainern.
Skapa pipelinen
AI-berikning är indexerdriven. Den här delen av genomgången skapar fyra objekt: datakälla, indexdefinition, kompetensuppsättning, indexerare.
Steg 1: Skapa en datakälla
Anropa Skapa datakälla för att ange niska veze till blobcontainern som innehåller exempeldatafilerna.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnectionString}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
Steg 2: Skapa en kompetensuppsättning
Anropa Skapa kompetensuppsättning för att ange vilka berikningssteg som ska tillämpas på ditt innehåll. Färdigheter körs parallellt om det inte finns ett beroende.
### Create a skillset
POST {{baseUrl}}/skillsets?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-ss",
"description": "Apply OCR, detect language, extract entities, and extract key-phrases.",
"cognitiveServices": null,
"skills":
[
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"defaultLanguageCode": "en",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.MergeSkill",
"description": "Create merged_text, which includes all the textual representation of each image inserted at the right location in the content field. This is useful for PDF and other file formats that supported embedded images.",
"context": "/document",
"insertPreTag": " ",
"insertPostTag": " ",
"inputs": [
{
"name":"text",
"source": "/document/content"
},
{
"name": "itemsToInsert",
"source": "/document/normalized_images/*/text"
},
{
"name":"offsets",
"source": "/document/normalized_images/*/contentOffset"
}
],
"outputs": [
{
"name": "mergedText",
"targetName" : "merged_text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"textSplitMode": "pages",
"maximumPageLength": 4000,
"defaultLanguageCode": "en",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.LanguageDetectionSkill",
"description": "If you have multilingual content, adding a language code is useful for filtering",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "languageName",
"targetName": "language"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.KeyPhraseExtractionSkill",
"context": "/document/pages/*",
"inputs": [
{
"name": "text",
"source": "/document/pages/*"
}
],
"outputs": [
{
"name": "keyPhrases",
"targetName": "keyPhrases"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Organization"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "organizations",
"targetName": "organizations"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Location"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "locations",
"targetName": "locations"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Person"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "persons",
"targetName": "persons"
}
]
}
]
}
Viktiga punkter:
Brödtexten i begäran anger följande inbyggda kunskaper:
Färdighet beskrivning Optisk teckenigenkänning Identifierar text och siffror i bildfiler. Sammanslagning av text Skapar "sammanfogat innehåll" som kombinerar om tidigare avgränsat innehåll, användbart för dokument med inbäddade bilder (PDF, DOCX och så vidare). Bilder och text separeras under dokumentets sprickfas. Sammanslagningsfärdigheten kombinerar om dem genom att infoga eventuell igenkänd text, bildtexter eller taggar som skapades under berikningen till samma plats där bilden extraherades från i dokumentet. När du arbetar med sammanfogat innehåll i en kompetensuppsättning omfattar den här noden all text i dokumentet, inklusive endast textdokument som aldrig genomgår OCR eller bildanalys. Språkidentifiering Identifierar språket och utdata antingen ett språknamn eller en kod. I flerspråkiga datamängder kan ett språkfält vara användbart för filter. Entitetsigenkänning Extraherar namnen på personer, organisationer och platser från sammanslaget innehåll. Textdelning Delar upp stort sammanfogat innehåll i mindre segment innan du anropar extraheringsfärdigheten för nyckelfraser. Extrahering av nyckelfraser accepterar indata på 50 000 tecken eller mindre. Några av exempelfilerna måste delas upp för att rymmas inom gränsen. Extrahering av diskussionsämne Hämtar de viktigaste nyckelfraserna. Varje kunskap körs på innehållet i dokumentet. Under bearbetningen spricker Azure AI Search varje dokument för att läsa innehåll från olika filformat. Text som hittas från källfilen placeras i ett genererat
content-fält, ett för varje dokument. Därför blir"/document/content"indata .För extrahering av nyckelfraser är
"document/pages/*"kontexten för extraheringsfärdigheten för nyckelfraser (för varje sida i dokumentet) i stället"/document/content"för .
Kommentar
Utdata kan mappas till ett index som används som indata till en underordnad kunskap, eller både, vilket är fallet med språkkod. I indexet kan en språkkod användas för filtrering. Mer information om grunderna i kunskapsuppsättningar finns i Definiera en kunskapsuppsättning.
Steg 3: Skapa ett index
Anropa Skapa index för att ange det schema som används för att skapa inverterade index och andra konstruktioner i Azure AI Search.
Den största komponenten i ett index är fältsamlingen, där datatyp och attribut avgör innehåll och beteende i Azure AI Search. Kontrollera att du har fält för dina nyligen genererade utdata.
### Create an index
POST {{baseUrl}}/indexes?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-idx",
"defaultScoringProfile": "",
"fields": [
{
"name": "content",
"type": "Edm.String",
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
},
{
"name": "text",
"type": "Collection(Edm.String)",
"facetable": false,
"filterable": true,
"searchable": true,
"sortable": false
},
{
"name": "language",
"type": "Edm.String",
"searchable": false,
"sortable": true,
"filterable": true,
"facetable": false
},
{
"name": "keyPhrases",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "organizations",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "persons",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "locations",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "metadata_storage_path",
"type": "Edm.String",
"key": true,
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
},
{
"name": "metadata_storage_name",
"type": "Edm.String",
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
}
]
}
Steg 4: Skapa och köra en indexerare
Anropa Skapa indexerare för att köra pipelinen. De tre komponenter som du har skapat hittills (datakälla, kompetensuppsättning, index) är indata till en indexerare. Att skapa indexeraren i Azure AI Search är den händelse som sätter hela pipelinen i rörelse.
Förvänta dig att steget kan ta flera minuter att slutföra. Trots att datauppsättningen är liten är analytiska kunskaper beräkningsintensiva.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-idxr",
"description": "",
"dataSourceName" : "cog-search-demo-ds",
"targetIndexName" : "cog-search-demo-idx",
"skillsetName" : "cog-search-demo-ss",
"fieldMappings" : [
{
"sourceFieldName" : "metadata_storage_path",
"targetFieldName" : "metadata_storage_path",
"mappingFunction" : { "name" : "base64Encode" }
},
{
"sourceFieldName": "metadata_storage_name",
"targetFieldName": "metadata_storage_name"
}
],
"outputFieldMappings" :
[
{
"sourceFieldName": "/document/merged_text",
"targetFieldName": "content"
},
{
"sourceFieldName" : "/document/normalized_images/*/text",
"targetFieldName" : "text"
},
{
"sourceFieldName" : "/document/organizations",
"targetFieldName" : "organizations"
},
{
"sourceFieldName": "/document/language",
"targetFieldName": "language"
},
{
"sourceFieldName" : "/document/persons",
"targetFieldName" : "persons"
},
{
"sourceFieldName" : "/document/locations",
"targetFieldName" : "locations"
},
{
"sourceFieldName" : "/document/pages/*/keyPhrases/*",
"targetFieldName" : "keyPhrases"
}
],
"parameters":
{
"batchSize": 1,
"maxFailedItems":-1,
"maxFailedItemsPerBatch":-1,
"configuration":
{
"dataToExtract": "contentAndMetadata",
"imageAction": "generateNormalizedImages"
}
}
}
Viktiga punkter:
Brödtexten i begäran innehåller referenser till tidigare objekt, konfigurationsegenskaper som krävs för bildbearbetning och två typer av fältmappningar.
"fieldMappings"bearbetas före kompetensuppsättningen och skickar innehåll från datakällan till målfält i ett index. Du använder fältmappningar för att skicka befintligt, oförändrade innehåll till indexet. Om fältnamn och typer är samma i båda ändar krävs ingen mappning."outputFieldMappings"är för fält som skapats av färdigheter, efter kompetensuppsättningskörning. Referenserna tillsourceFieldNameioutputFieldMappingsfinns inte förrän dokumentsprickor eller berikning skapar dem.targetFieldNameär ett fält i ett index som definieras i indexschemat.Parametern
"maxFailedItems"är inställd på -1, vilket instruerar indexeringsmotorn att ignorera fel under dataimporten. Detta är acceptabelt eftersom det finns så få dokument i demodatakällan. För en större datakälla skulle du ställa in värdet på större än 0.Instruktionen
"dataToExtract":"contentAndMetadata"instruerar indexeraren att automatiskt extrahera värdena från blobens innehållsegenskap och metadata för varje objekt.Parametern
imageActioninstruerar indexeraren att extrahera text från bilder som finns i datakällan. Konfigurationen av"imageAction":"generateNormalizedImages", tillsammans med OCR-färdigheten och färdigheten för textsammanslagning, talar om för indexeraren att den ska extrahera text från bilderna (exempelvis ordet ”stopp” från en trafikstoppskylt) och bädda in den som en del av innehållsfältet. Det här beteendet gäller både inbäddade bilder (tänk på en bild i en PDF) och fristående bildfiler, till exempel en JPG-fil.
Kommentar
När en indexerare skapas anropas pipelinen. Om det uppstår problem med att ansluta till data, mappningsindata eller -utdata eller ordningen på åtgärder visas dem i det här stadiet. Du kan behöva ta bort objekt först om du vill köra pipelinen med kod- eller skriptändringar. Mer information finns i Reset and re-run (Återställa och köra om).
Övervaka indexering
Indexering och berikning påbörjas så snart du skickar begäran om att skapa indexerare. Beroende på kompetensuppsättningens komplexitet och åtgärder kan indexering ta en stund.
Om du vill ta reda på om indexeraren fortfarande körs anropar du Hämta indexerarstatus för att kontrollera indexerarens status.
### Get Indexer Status (wait several minutes for the indexer to complete)
GET {{baseUrl}}/indexers/cog-search-demo-idxr/status?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
Viktiga punkter:
Varningar är vanliga i vissa scenarier och indikerar inte alltid ett problem. Om en blobcontainer till exempel innehåller avbildningsfiler och pipelinen inte hanterar avbildningar får du en varning om att avbildningarna inte bearbetats.
I det här exemplet finns det en PNG-fil som inte innehåller någon text. Alla fem av de textbaserade färdigheterna (språkidentifiering, entitetsigenkänning av platser, organisationer, personer och extrahering av nyckelfraser) kan inte köras på den här filen. Det resulterande meddelandet visas i körningshistoriken.
Kontrollera resultat
Nu när du har skapat ett index som innehåller AI-genererat innehåll anropar du Sökdokument för att köra några frågor för att se resultatet.
### Query the index\
POST {{baseUrl}}/indexes/cog-search-demo-idx/docs/search?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"select": "metadata_storage_name,language,organizations",
"count": true
}
Filter kan hjälpa dig att begränsa resultatet till intressanta objekt:
### Filter by organization
POST {{baseUrl}}/indexes/cog-search-demo-idx/docs/search?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"filter": "organizations/any(organizations: organizations eq 'Microsoft')",
"select": "metadata_storage_name,organizations",
"count": true
}
Dessa frågor illustrerar några av de sätt som du kan arbeta med frågesyntax och filter på nya fält som skapats av Azure AI Search. Fler frågeexempel finns i Exempel i REST API för sökdokument, Enkla syntaxfrågeexempel och Fullständiga Lucene-frågeexempel.
Återställa och köra igen
Under tidiga utvecklingsstadier är iteration över designen vanlig. Återställning och omkörning hjälper till med iteration.
Lärdomar
Den här självstudien visar de grundläggande stegen för att använda REST-API:er för att skapa en PIPELINE för AI-berikande: en datakälla, kompetensuppsättning, index och indexerare.
Inbyggda färdigheter introducerades, tillsammans med kompetensuppsättningsdefinitioner som visar mekaniken för att länka samman färdigheter genom indata och utdata. Du har också lärt dig att outputFieldMappings indexerarens definition krävs för att dirigera berikade värden från pipelinen till ett sökbart index på en Azure AI-usluga pretrage.
Slutligen lärde du dig att testa resultat och återställa systemet för ytterligare iterationer. Du har lärt dig att när du utfärdar frågor mot indexet returneras utdata som skapades av pipelinen för berikande indexering.
Rensa resurser
När du arbetar i din egen prenumeration i slutet av ett projekt är det en bra idé att ta bort de resurser som du inte längre behöver. Resurser som fortsätter att köras kostar pengar. Du kan ta bort enstaka resurser eller hela resursgruppen om du vill ta bort alla resurser.
Du kan hitta och hantera resurser i portalen med hjälp av länken Alla resurser eller Resursgrupper i det vänstra navigeringsfönstret.
Nästa steg
Nu när du är bekant med alla objekt i en AI-berikningspipeline kan du ta en närmare titt på definitioner av kompetensuppsättningar och individuella färdigheter.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för