Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Note
Kunskapslager är sekundär lagring som finns i Azure Storage och innehåller utdata från Azure AI-sökning-kompetensuppsättningar. De är separata från kunskapskällor och kunskapsbaser som används i arbetsflöden för agentisk hämtning .
Knowledge Store är sekundär lagring för innehåll berikat med AI skapat av en skillset i Azure AI-sökning. I Azure AI-sökning skickar ett indexeringsjobb alltid utdata till ett sökindex, men om du kopplar en kompetensuppsättning till en indexerare kan du även skicka AI-berikade utdata till en container eller tabell i Azure Storage. Ett kunskapslager kan användas för oberoende analys eller nedströmsbearbetning i scenarier som inte är sökscenarier som kunskapsutvinning.
De två resultat från indexeringen, ett sökindex och ett kunskapslager, är produkter av samma bearbetningsflöde. De härleds från samma indata och innehåller samma data, men deras innehåll är strukturerat, lagrat och används i olika program.

Fysiskt är ett kunskapslager Azure Storage, antingen Azure Table Storage, Azure Blob Storage eller båda. Alla verktyg eller processer som kan ansluta till Azure Storage kan använda innehållet i ett kunskapslager. Det finns inget frågestöd i Azure AI-sökning för att hämta innehåll från ett kunskapslager.
När du tittar på Azure Portal ser ett kunskapslager ut som alla andra tabeller, objekt eller filer. Följande skärmbild visar ett kunskapslager som består av tre tabeller. Du kan anta en namngivningskonvention, till exempel ett kstore prefix, för att hålla ihop innehållet.

Fördelar med kunskapslager
De främsta fördelarna med ett kunskapslager är tvådelat: flexibel åtkomst till innehåll och möjligheten att forma data.
Till skillnad från ett sökindex som bara kan nås via frågor i Azure AI-sökning är ett kunskapslager tillgängligt för alla verktyg, appar eller processer som stöder anslutningar till Azure Storage. Denna flexibilitet öppnar nya möjligheter att använda analyserat och berikat innehåll som produceras av en berikningspipeline.
Samma kompetensuppsättning som berikar data kan också användas för att forma data. Vissa verktyg som Power BI fungerar bättre med tabeller, medan en data science-arbetsbelastning kan kräva en komplex datastruktur i blobformat. Genom att lägga till en Shaper-färdighet i en kompetensuppsättning får du kontroll över formen på dina data. Du kan sedan skicka dessa former till projektioner, antingen tabeller eller blobar, för att skapa fysiska datastrukturer som överensstämmer med datans avsedda användning.
I följande video förklaras både dessa fördelar och mer.
Definition av kunskapslager
Ett kunskapslager definieras i en kompetensuppsättningsdefinition och har två komponenter:
En anslutningssträng till Azure Storage
Projektioner som avgör om kunskapsarkivet består av tabeller, objekt eller filer. Projektionselementet är en matris. Du kan skapa flera uppsättningar med olika kombinationer av tabell-, objekt- och filstrukturer i ett kunskapslager.
"knowledgeStore": { "storageConnectionString":"<YOUR-AZURE-STORAGE-ACCOUNT-CONNECTION-STRING>", "projections":[ { "tables":[ ], "objects":[ ], "files":[ ] } ] }
Vilken typ av projektion du anger i den här strukturen avgör vilken typ av lagring som används av kunskapsarkivet, men inte dess struktur. Fält i tabeller, objekt och filer bestäms av Shaper-kunskapsutdata om du skapar kunskapsarkivet programmatiskt, eller av guiden Importera data om du använder Azure-portalen.
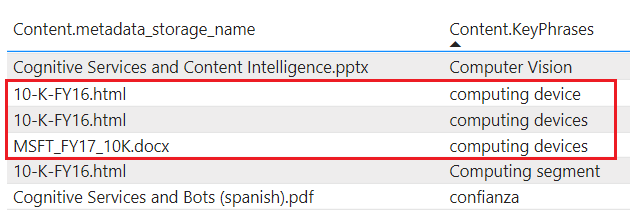
tablesprojekt att berika innehåll till Table Storage. Definiera en tabellprojektion när du behöver tabellrapporteringsstrukturer för indata till analysverktyg eller exportera som dataramar till andra datalager. Du kan ange fleratablesi samma projektionsgrupp för att hämta en delmängd eller ett tvärsnitt av berikade dokument. I samma projektionsgrupp bevaras tabellrelationer så att du kan arbeta med dem alla.Projicerat innehåll är inte aggregerat eller normaliserat. Följande skärmbild visar en tabell, sorterad efter nyckelfras, med det överordnade dokumentet som anges i den intilliggande kolumnen. Till skillnad från datainmatning under indexering finns det ingen språklig analys eller sammansättning av innehåll. Pluralformer och skillnader i hölje betraktas som unika instanser.
objectsprojicera JSON-dokument till Bloblagring. Den fysiska representationen av enobjectär en hierarkisk JSON-struktur som representerar ett berikat dokument.filesöverför bildfiler till Blob Storage. Afileär en bild som extraherats från ett dokument och överförts intakt till Blob Storage. Även om det kallas "files" visas det i Blob-lagring, inte fillagring.
Skapa ett kunskapslager
Använd Azure-portalen, REST-API:er eller ett Azure SDKs-paket för att skapa ett kunskapslager. Alla metoder kräver Azure Storage, en kompetensuppsättning och en indexerare. Eftersom indexerare kräver ett sökindex måste du också ange en indexdefinition.
REST-API:er och SDK:er ger fullständig kontroll över projektioner: tabeller, objekt och filer. Azure-portalen skapar ett kunskapslager automatiskt som en del av det multimodala RAG-arbetsflödet, som är begränsat till filprojektioner för extraherade bilder.
Guiden Importera data skapar endast ett kunskapslager för det multimodala RAG-scenariot. Kom igång genom att läsa Snabbstart: Multimodal sökning i Azure-portalen.
Ansluta med appar
När berikat innehåll finns i lagringen kan alla verktyg eller tekniker som ansluter till Azure Storage användas för att utforska, analysera eller använda innehållet. Följande lista är en början:
Storage Explorer eller Storage-webbläsaren i Azure Portal för att visa utökad dokumentstruktur och innehåll. Tänk på detta som baslinjeverktyg för att visa innehåll i kunskapslager.
Power BI för rapportering och analys.
Azure Data Factory för ytterligare manipulering.
Innehållslivscykel
Varje gång du kör indexeraren och kunskapsuppsättningen uppdateras kunskapsarkivet om kunskapsuppsättningen eller underliggande källdata har ändrats. Alla ändringar som hämtas av indexeraren sprids genom berikningsprocessen till projektionerna i kunskapsarkivet, vilket säkerställer att dina beräknade data är en aktuell representation av innehåll i den ursprungliga datakällan.
Note
Även om du kan redigera data i projektionerna skrivs alla ändringar över vid nästa pipelineanrop, förutsatt att dokumentet i källdata uppdateras.
Ändringar i källdata
För datakällor som stöder ändringsspårning bearbetar en indexerare nya och ändrade dokument och kringgår befintliga dokument som redan har bearbetats. Tidsstämpelinformationen varierar beroende på datakälla, men i en blobcontainer tittar indexeraren på lastmodified datumet för att avgöra vilka blobar som måste matas in.
Ändringar i en kompetensuppsättning
Om du gör ändringar i en kompetensuppsättning bör du aktivera cachelagring av berikade dokument för att återanvända befintliga berikningar där det är möjligt.
Utan inkrementell cachelagring bearbetar indexeraren alltid dokument i ordning efter högvattenmärket, utan att gå bakåt. För blobar kommer indexeraren att bearbeta blobar sorterade efter lastModified, oavsett ändringar i indexerarens inställningar eller färdighetsuppsättningen. Om du ändrar en kompetensuppsättning uppdateras inte tidigare bearbetade dokument för att återspegla den nya kompetensuppsättningen. Dokument som bearbetas efter ändringen av kompetensuppsättningen använder den nya kompetensuppsättningen, vilket resulterar i att indexdokument är en blandning av gamla och nya färdigheter.
Med inkrementell cachelagring och efter en uppdatering av kompetensuppsättningen återanvänder indexeraren alla berikanden som inte påverkas av ändringen av kompetensuppsättningen. Uppströmsberikningar hämtas från cachen, liksom berikningar som är oberoende och isolerade från den funktion som ändrades.
Deletions
Även om en indexerare skapar och uppdaterar strukturer och innehåll i Azure Storage tas de inte bort. Projektioner fortsätter att finnas även när indexeraren eller kompetensuppsättningen tas bort. Som ägare till lagringskontot bör du ta bort en projektion om den inte längre behövs.
Nästa steg
Kunskapsarkivet erbjuder beständighet av berikade dokument, användbart när du utformar en kompetensuppsättning eller skapar nya strukturer och innehåll för förbrukning av alla klientprogram som kan komma åt ett Azure Storage-konto.
Den enklaste metoden för att skapa berikade dokument programmatiskt är via REST-API:er.