Importera guider i Azure AI Search
Azure AI Search har två importguider som automatiserar indexering och objektdefinitioner så att du kan börja fråga direkt. Om du inte har använt Azure AI Search tidigare är de här guiderna en av de mest kraftfulla funktionerna som du har tillgång till. Med minimal ansträngning kan du skapa en indexerings- eller berikningspipeline som använder de flesta funktionerna i Azure AI Search.
Guiden Importera data stöder icke-bevektorarbetsflöden. Du kan extrahera alfanumerisk text från rådatadokument. Du kan också konfigurera tillämpad AI och inbyggda kunskaper som härleder struktur och genererar textsökningsbart innehåll från bildfiler och ostrukturerade data.
Guiden Importera och vektorisera data stöder vektorisering. Du måste ange en befintlig distribution av en inbäddningsmodell, men guiden upprättar anslutningen, formulerar begäran och hanterar svaret. Det genererar vektorinnehåll från text- eller bildinnehåll.
Om du använder guiden för test av konceptbevis förklarar den här artikeln de interna funktionerna i guiderna så att du kan använda dem mer effektivt.
Den här artikeln är inte ett steg för steg. Hjälp med att använda guiden med inbyggda exempeldata finns i:
- Snabbstart: Skapa ett sökindex
- Snabbstart: Skapa en textöversättning och entitetskunskaper
- Snabbstart: Skapa ett vektorindex
- Snabbstart: bildsökning (vektorer)
Starta guiderna
I Azure-portalen öppnar du söktjänstsidan från instrumentpanelen eller hittar din tjänst i tjänstlistan.
På sidan Tjänstöversikt överst väljer du Importera data eller Importera och vektorisera data.

Guiderna öppnas helt expanderade i webbläsarfönstret så att du får mer utrymme att arbeta.
Du kan också starta Importera data från andra Azure-tjänster, inklusive Azure Cosmos DB, Azure SQL Database, SQL Managed Instance och Azure Blob Storage. Leta efter Lägg till Azure AI Search i det vänstra navigeringsfönstret på översiktssidan för tjänsten.
Objekt som skapats av guiden
Guiden matar ut objekten i följande tabell. När objekten har skapats kan du granska deras JSON-definitioner i portalen eller anropa dem från kod.
| Objekt | beskrivning |
|---|---|
| Indexerare | Ett konfigurationsobjekt som anger en datakälla, ett målindex, en valfri kompetensuppsättning, valfritt schema och valfria konfigurationsinställningar för felhantering och base-64-kodning. |
| Datakälla | Bevarar anslutningsinformation till en datakälla som stöds i Azure. Ett datakällans objekt används uteslutande med indexerare. |
| Index | Fysisk datastruktur som används för fulltextsökning och andra frågor. |
| Kompetensuppsättning | Valfritt. En fullständig uppsättning instruktioner för att manipulera, transformera och forma innehåll, inklusive analys och extrahering av information från bildfiler. Kunskapsuppsättningar används också för integrerad vektorisering. Om inte arbetsvolymen ligger under gränsen på 20 transaktioner per indexerare per dag måste kompetensuppsättningen innehålla en referens till en Azure AI-multitjänstresurs som ger berikande. För integrerad vektorisering kan du använda antingen Azure AI Vision eller en inbäddningsmodell i Azure AI Studio-modellkatalogen. |
| Kunskapslager | Valfritt. Lagrar utdata från i tabeller och blobar i Azure Storage för oberoende analys eller nedströmsbearbetning i icke-forskningsscenarier. |
Förmåner
Innan du skriver någon kod kan du använda guiderna för prototyper och test av konceptbevis. Guiderna ansluter till externa datakällor, exempel på data för att skapa ett första index och importerar och kan också vektorisera data som JSON-dokument till ett index i Azure AI Search.
Om du utvärderar kompetensuppsättningar hanterar guiden mappningar för utdatafält och lägger till hjälpfunktioner för att skapa användbara objekt. Textdelning läggs till om du anger ett parsningsläge. Textsammanslagning läggs till om du väljer bildanalys så att guiden kan återförena textbeskrivningar med bildinnehåll. Shaper-kunskaper har lagts till för att stödja giltiga projektioner om du väljer alternativet kunskapslager. Alla ovanstående uppgifter har en inlärningskurva. Om du är nybörjare på berikning kan du mäta värdet för en färdighet utan att behöva investera mycket tid och ansträngning för att kunna hantera de här stegen.
Sampling är den process genom vilken ett indexschema härleds och har vissa begränsningar. När datakällan skapas väljer guiden ett slumpmässigt urval av dokument för att avgöra vilka kolumner som är en del av datakällan. Alla filer läss inte eftersom det kan ta timmar för mycket stora datakällor. Med tanke på ett urval av dokument används källmetadata, till exempel fältnamn eller typ, för att skapa en fältsamling i ett indexschema. Beroende på komplexiteten i källdata kan du behöva redigera det ursprungliga schemat för noggrannhet eller utöka det för fullständighet. Du kan göra dina ändringar infogade på indexdefinitionssidan.
Överlag är fördelarna med att använda guiden tydliga: så länge kraven uppfylls kan du skapa ett frågebart index inom några minuter. Vissa av komplexiteterna i indexering, till exempel serialisering av data som JSON-dokument, hanteras av guiden.
Begränsningar
Guiden är inte utan begränsningar. Begränsningar sammanfattas på följande sätt:
Guiden stöder inte iteration eller återanvändning. Varje pass genom guiden skapar ett nytt index, en ny kompetensuppsättning och en indexerare. Endast datakällor kan sparas och återanvändas i guiden. Om du vill redigera eller förfina andra objekt tar du antingen bort objekten och börjar om eller använder REST-API:erna eller .NET SDK för att ändra strukturerna.
Källinnehållet måste finnas i en datakälla som stöds.
Sampling är över en delmängd av källdata. För stora datakällor är det möjligt att guiden missar fält. Du kan behöva utöka schemat eller korrigera de härledda datatyperna om samplingen är otillräcklig.
AI-berikande, som exponeras i portalen, är begränsat till en delmängd av inbyggda färdigheter.
Ett kunskapslager, som kan skapas av guiden, är begränsat till några standardprojektioner och använder en standardnamngivningskonvention. Om du vill anpassa namn eller projektioner måste du skapa kunskapsarkivet via REST API eller SDK:erna.
Säkra anslutningar
Importguiderna gör utgående anslutningar med hjälp av portalstyrenheten och offentliga slutpunkter. Du kan inte använda guiderna om Azure-resurser nås via en privat anslutning eller via en delad privat länk.
Du kan använda guiderna över begränsade offentliga anslutningar, men alla funktioner är inte tillgängliga.
För att importera inbyggda exempeldata i en söktjänst krävs en offentlig slutpunkt och inga brandväggsregler.
Exempeldata hanteras av Microsoft på specifika Azure-resurser. Portalkontrollanten ansluter till dessa resurser via en offentlig slutpunkt. Om du placerar söktjänsten bakom en brandvägg får du det här felet när du försöker hämta de inbyggda exempeldata:
Import configuration failed, error creating Data Source, följt av"An error has occured.".På Azure-datakällor som stöds som skyddas av brandväggar kan du hämta data om du har rätt brandväggsregler på plats.
Azure-resursen måste ta emot nätverksbegäranden från IP-adressen för den enhet som används i anslutningen. Du bör också lista Azure AI Search som en betrodd tjänst i resursens nätverkskonfiguration. I Azure Storage kan du till exempel lista
Microsoft.Search/searchServicessom en betrodd tjänst.Vid anslutningar till ett Azure AI-multitjänstkonto som du tillhandahåller, eller vid anslutningar till inbäddningsmodeller som distribuerats i Azure AI Studio eller Azure OpenAI, måste offentlig Internetåtkomst vara aktiverad. Dessa Azure-resurser anropas när du använder inbyggda kunskaper i guiden Importera data eller integrerad vektorisering i guiden Importera och vektorisera data .
I guiden Importera och vektorisera data är felet
"Access denied due to Virtual Network/Firewall rules."Det finns inget fel i guiden Importera data, men kunskapsuppsättningen skapas inte.
Om brandväggsinställningarna hindrar dina guidearbetsflöden från att lyckas bör du överväga skriptade eller programmatiska metoder i stället.
Arbetsflöde
Guiden är uppdelad i fyra huvudsteg:
Anslut till en Azure-datakälla som stöds.
Skapa ett indexschema som härleds av sampling av källdata.
Du kan också lägga till tillämpad AI för att extrahera eller generera innehåll och struktur. Indata för att skapa ett kunskapslager samlas in i det här steget.
Kör guiden för att skapa objekt, eventuellt vektorisera data, läsa in data i ett index, ange ett schema och andra konfigurationsalternativ.
Arbetsflödet är en pipeline, så det är ett sätt. Du kan inte använda guiden för att redigera något av de objekt som har skapats, men du kan använda andra portalverktyg, till exempel index- eller indexerarens designer eller JSON-redigerare, för tillåtna uppdateringar.
Konfiguration av datakälla i guiden
Guiderna ansluter till en extern datakälla som stöds med hjälp av den interna logiken som tillhandahålls av Azure AI Search-indexerare, som är utrustade för att sampla källan, läsa metadata, knäcka dokument för att läsa innehåll och struktur och serialisera innehåll som JSON för efterföljande import till Azure AI Search.
Du kan klistra in en anslutning till en datakälla som stöds i en annan prenumeration eller region, men Välj en befintlig anslutningsväljare är begränsad till den aktiva prenumerationen.
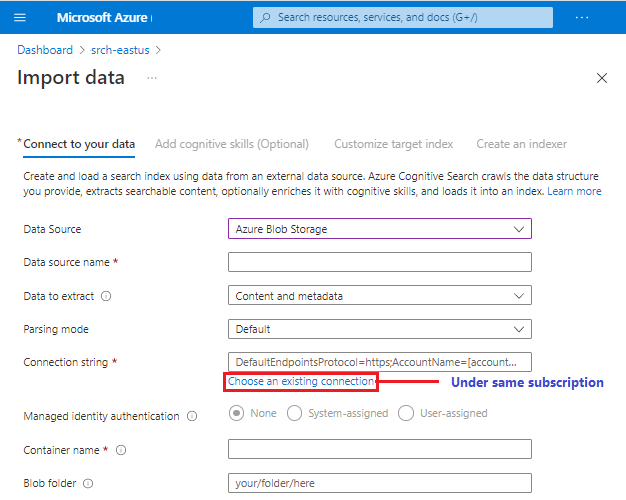
Alla förhandsgranskningsdatakällor är inte garanterade tillgängliga i guiden. Eftersom varje datakälla har potential att införa andra ändringar nedströms läggs en datakälla för förhandsversion bara till i listan över datakällor om den har fullt stöd för alla funktioner i guiden, till exempel definition av kompetensuppsättningar och indexschemainferens.
Du kan bara importera från en enskild tabell, databasvy eller motsvarande datastruktur, men strukturen kan innehålla hierarkiska eller kapslade understrukturer. Mer information finns i Så här modellerar du komplexa typer.
Konfiguration av kompetensuppsättning i guiden
Konfigurationen av kompetensuppsättningen sker efter datakällans definition eftersom typen av datakälla informerar tillgängligheten för vissa inbyggda färdigheter. Om du indexerar filer från Blob Storage avgör ditt val av parsningsläge för dessa filer om attitydanalys är tillgängligt.
Guiden lägger till de kunskaper du väljer. Det lägger också till andra färdigheter som är nödvändiga för att uppnå ett framgångsrikt resultat. Om du till exempel anger ett kunskapslager lägger guiden till en Shaper-färdighet för att stödja projektioner (eller fysiska datastrukturer).
Kompetensuppsättningar är valfria och det finns en knapp längst ned på sidan för att hoppa framåt om du inte vill ha AI-berikning.
Indexschemakonfiguration i guiden
Guiderna exempel på datakällan för att identifiera fält och fälttyp. Beroende på datakällan kan den även erbjuda fält för indexering av metadata.
Eftersom sampling är en oprecis övning bör du granska indexet för följande överväganden:
Stämmer fältlistan? Om datakällan innehåller fält som inte har hämtats i samplingen kan du manuellt lägga till nya fält som samplingen missade och ta bort alla fält som inte lägger till värde i en sökupplevelse eller som inte används i ett filteruttryck eller en bedömningsprofil.
Är datatypen lämplig för inkommande data? Azure AI Search stöder datatyperna entitetsdatamodell (EDM). För Azure SQL-data finns det ett mappningsdiagram som beskriver motsvarande värden. Mer bakgrund finns i Fältmappningar och transformeringar.
Har du ett fält som kan fungera som nyckel? Det här fältet måste vara Edm.string och det måste unikt identifiera ett dokument. För relationsdata kan den mappas till en primärnyckel. För blobar kan det vara
metadata-storage-path. Om fältvärden innehåller blanksteg eller bindestreck måste du ange alternativet Base-64 Encode Key i steget Skapa en indexerare under Avancerade alternativ för att förhindra verifieringskontrollen för dessa tecken.Ange attribut för att avgöra hur fältet används i ett index.
Ta dig tid med det här steget eftersom attribut avgör det fysiska uttrycket för fält i indexet. Om du vill ändra attribut senare, även programmatiskt, behöver du nästan alltid släppa och återskapa indexet. Grundläggande attribut som Sökbar och Hämtningsbar har en försumbar inverkan på lagringen. Genom att aktivera filter och använda förslagsgivare ökar lagringskraven.
Sökbar aktiverar fulltextsökning. Varje fält som används i frågor i fritt format eller i frågeuttryck måste ha det här attributet. Inverterade index skapas för varje fält som du markerar som Sökbara.
Hämtningsbar returnerar fältet i sökresultat. Varje fält som innehåller innehåll för sökresultat måste ha det här attributet. Om du anger det här fältet påverkas inte indexstorleken märkbart.
Filterable gör att fältet kan refereras till i filteruttryck. Varje fält som används i ett $filter uttryck måste ha det här attributet. Filteruttryck är för exakta matchningar. Eftersom textsträngarna förblir intakta krävs mer lagringsutrymme för att hantera det ordagranna innehållet.
Facetable aktiverar fältet för fasetterad navigering. Endast fält som också är markerade som Filterable kan markeras som Facetable.
Sortable tillåter att fältet används i en sortering. Varje fält som används i ett $Orderby uttryck måste ha det här attributet.
Behöver du lexikal analys? För Edm.string-fält som är sökbara kan du ange en Analyzer om du vill ha språkförstärkt indexering och frågor.
Standardvärdet är Standard Lucene , men du kan välja Microsoft English om du vill använda Microsofts analysverktyg för avancerad lexikal bearbetning, till exempel för att lösa oregelbundna substantiv och verbformer. Endast språkanalysverktyg kan anges i portalen. Om du använder en anpassad analysator eller en icke-språkanalysator som Nyckelord, Mönster och så vidare måste du skapa den programmatiskt. Mer information om analysverktyg finns i Lägga till språkanalysverktyg.
Behöver du typeahead-funktioner i form av automatisk komplettering eller föreslagna resultat? Markera kryssrutan Föreslå för att aktivera typeahead-frågeförslag och komplettera automatiskt i markerade fält. Förslagsgivare lägger till antalet tokeniserade termer i ditt index och förbrukar därmed mer lagringsutrymme.
Indexerarens konfiguration i guiden
Den sista sidan i guiden samlar in användarindata för indexerarens konfiguration. Du kan ange ett schema och ange andra alternativ som varierar beroende på datakällans typ.
Internt konfigurerar guiden även följande definitioner, som inte visas i indexeraren förrän den har skapats:
- fältmappningar mellan datakällan och indexet
- mappningar av utdatafält mellan kunskapsutdata och ett index
Nästa steg
Det bästa sättet att förstå fördelarna och begränsningarna i guiden är att gå igenom det. Här är en snabbstart som förklarar varje steg.