Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Azure AI Search stöder två grundläggande metoder för att importera data till ett sökindex: skicka data till indexet programmatiskt eller hämta data genom att peka en indexerare mot en datakälla som stöds.
I den här självstudien beskrivs hur du effektivt indexerar data med push-modellen genom att gruppera begäranden och använda en exponentiell backoff-strategi för återförsök. Du kan ladda ned och köra exempelprogrammet. I den här självstudien beskrivs också de viktigaste aspekterna av programmet och vilka faktorer du bör tänka på när du indexerar data.
I den här självstudien använder du C# och Azure.Search.Documents-biblioteket från Azure SDK för .NET för att:
- Skapa ett index
- Testa olika batchstorlekar för att fastställa den mest effektiva storleken
- Indexerar batchar asynkront
- Använd flera trådar för att öka indexeringshastigheten
- Använd en återförsöksstrategi för exponentiell backoff för att försöka igen misslyckade dokument
Förutsättningar
- Ett Azure-konto med en aktiv prenumeration. Skapa ett konto utan kostnad.
- Visual Studio.
Ladda ned filer
Källkoden för denna handledning finns i mappen optimize-data-indexing/v11 i GitHub-förvaret Azure-Samples/azure-search-dotnet-scale.
Viktiga överväganden
Följande faktorer påverkar indexeringshastigheten. Mer information finns i Index stora datamängder.
- Prisnivå och antal partitioner/repliker: Om du lägger till partitioner eller uppgraderar nivån ökar indexeringshastigheten.
- Indexschemakomplexitet: Om du lägger till fält och fältegenskaper sänks indexeringshastigheten. Mindre index är snabbare att indexeras.
- Batchstorlek: Den optimala batchstorleken varierar beroende på indexschemat och datauppsättningen.
- Antal trådar/arbetare: En enda tråd drar inte full nytta av indexeringshastigheter.
- Återförsöksstrategi: En återförsöksstrategi för exponentiell backoff är en metod för optimal indexering.
- Dataöverföringshastigheter i nätverket: Dataöverföringshastigheter kan vara en begränsande faktor. Indexera data inifrån Din Azure-miljö för att öka dataöverföringshastigheten.
Skapa en söktjänst
Denna självstudie kräver en Azure AI Search-tjänst som du kan skapa i Azure-portalen. Du kan också hitta en befintlig tjänst i din aktuella prenumeration. För att testa och optimera indexeringshastigheterna korrekt rekommenderar vi att du använder samma prisnivå som du planerar att använda i produktion.
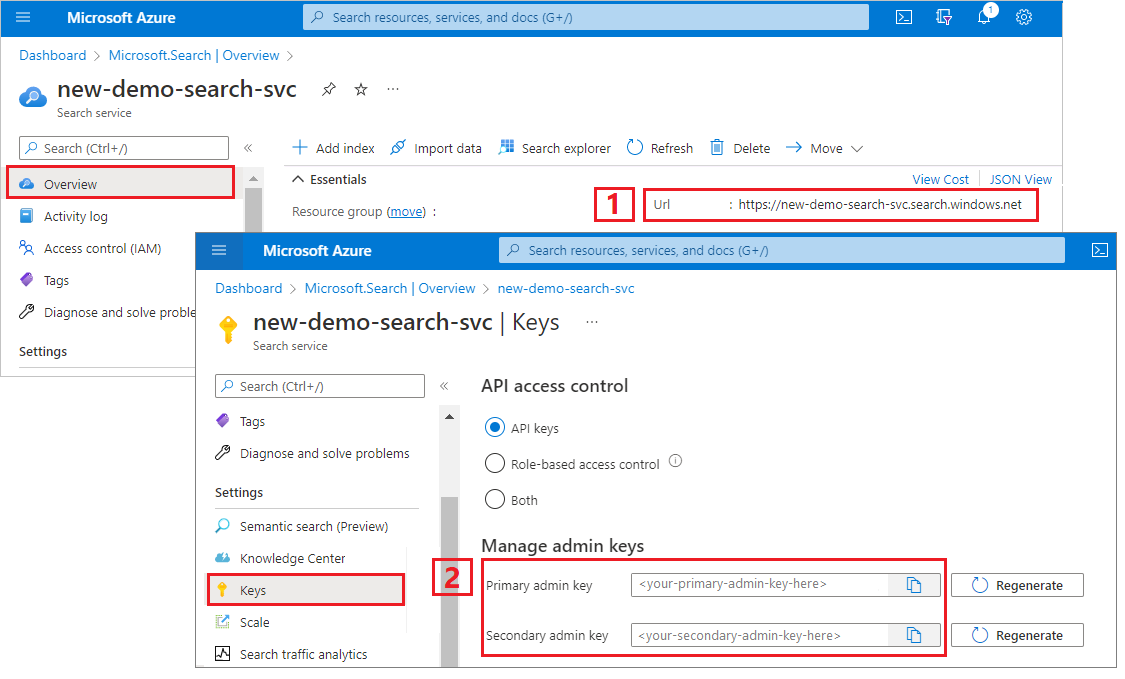
Skaffa en administrativ nyckel och URL för Azure AI Search
I den här guiden används nyckelbaserad autentisering. Kopiera en administratörs-API-nyckel och klistra in den i appsettings.json-filen.
Gå till söktjänsten i Azure-portalen.
I den vänstra rutan väljer du Översikt och kopierar slutpunkten. Det bör vara i det här formatet:
https://my-service.search.windows.netI den vänstra rutan väljer du Inställningar>Nycklar och kopierar en administratörsnyckel för fullständiga rättigheter för tjänsten. Det finns två utbytbara administratörsnycklar som tillhandahålls för affärskontinuitet om du behöver rulla över en. Du kan använda antingen nyckel för begäranden för att lägga till, ändra eller ta bort objekt.
Konfigurera din miljö
Öppna filen
OptimizeDataIndexing.slni Visual Studio.I Solution Explorer redigerar
appsettings.jsondu filen med den anslutningsinformation som du samlade in i föregående steg.{ "SearchServiceUri": "https://{service-name}.search.windows.net", "SearchServiceAdminApiKey": "", "SearchIndexName": "optimize-indexing" }
Utforska koden
När du har uppdaterat appsettings.jsonbör exempelprogrammet i OptimizeDataIndexing.sln vara redo att bygga och köra.
Den här koden härleds från C# -avsnittet i Snabbstart: Fulltextsökning, som innehåller detaljerad information om grunderna i att arbeta med .NET SDK.
Den här enkla C#/.NET-konsolappen utför följande uppgifter:
- Skapar ett nytt index baserat på datastrukturen för C#
Hotel-klassen (som även refererar tillAddressklassen) - Testar olika batchstorlekar för att fastställa den mest effektiva storleken
- Indexerar data asynkront
- Använda flera trådar för att öka indexeringshastigheten
- Använda en återförsöksstrategi för exponentiell backoff för att försöka utföra misslyckade objekt igen
Innan du kör programmet tar det en minut att studera koden och indexdefinitionerna för det här exemplet. Relevant kod finns i flera filer:
-
Hotel.csochAddress.csinnehåller schemat som definierar indexet -
DataGenerator.csinnehåller en enkel klass som gör det enkelt att skapa stora mängder hotelldata -
ExponentialBackoff.csinnehåller kod för att optimera indexeringsprocessen enligt beskrivningen i den här artikeln -
Program.csinnehåller funktioner som skapar och tar bort Azure AI Search-indexet, indexerar batchar med data och testar olika batchstorlekar
Skapa indexet
Det här exempelprogrammet använder Azure SDK för .NET för att definiera och skapa ett Azure AI Search-index. Den använder FieldBuilder klassen för att generera en indexstruktur från en C#-datamodellklass.
Datamodellen definieras av Hotel klassen, som också innehåller referenser till Address klassen.
FieldBuilder ökar detaljnivån genom flera klassdefinitioner för att generera en komplex datastruktur för indexet. Metadatataggar används för att definiera attributen för varje fält, till exempel om det är sökbart eller sorterbart.
Följande kodfragment från Hotel.cs filen anger ett enda fält och en referens till en annan datamodellklass.
. . .
[SearchableField(IsSortable = true)]
public string HotelName { get; set; }
. . .
public Address Address { get; set; }
. . .
Program.cs I filen definieras indexet med ett namn och en fältsamling som genereras av FieldBuilder.Build(typeof(Hotel)) metoden och skapas sedan på följande sätt:
private static async Task CreateIndexAsync(string indexName, SearchIndexClient indexClient)
{
// Create a new search index structure that matches the properties of the Hotel class.
// The Address class is referenced from the Hotel class. The FieldBuilder
// will enumerate these to create a complex data structure for the index.
FieldBuilder builder = new FieldBuilder();
var definition = new SearchIndex(indexName, builder.Build(typeof(Hotel)));
await indexClient.CreateIndexAsync(definition);
}
Generera data
En enkel klass implementeras i DataGenerator.cs filen för att generera data för testning. Syftet med den här klassen är att göra det enkelt att generera ett stort antal dokument med ett unikt ID för indexering.
Kör följande kod för att hämta en lista över 100 000 hotell med unika ID:er:
long numDocuments = 100000;
DataGenerator dg = new DataGenerator();
List<Hotel> hotels = dg.GetHotels(numDocuments, "large");
Det finns två storlekar av hotell som är tillgängliga för testning i det här exemplet: små och stora.
Schemat för ditt index påverkar indexeringshastigheten. När du har slutfört den här självstudien kan du överväga att konvertera den här klassen för att generera data som bäst matchar ditt avsedda indexschema.
Testbatchstorlekar
Azure AI Search stöder följande API:er för att läsa in enskilda eller flera dokument i ett index:
Indexering av dokument i batchar förbättrar indexeringsprestanda avsevärt. Dessa batchar kan vara upp till 1 000 dokument eller upp till cirka 16 MB per batch.
Att fastställa den optimala batchstorleken för dina data är en viktig komponent för att optimera indexeringshastigheter. De två primära faktorerna som påverkar den optimala batchstorleken är:
- Schemat för ditt index
- Storleken på dina data
Eftersom den optimala batchstorleken beror på ditt index och dina data är den bästa metoden att testa olika batchstorlekar för att avgöra vad som resulterar i de snabbaste indexeringshastigheterna för ditt scenario.
Följande funktion visar en enkel metod för att testa batchstorlekar.
public static async Task TestBatchSizesAsync(SearchClient searchClient, int min = 100, int max = 1000, int step = 100, int numTries = 3)
{
DataGenerator dg = new DataGenerator();
Console.WriteLine("Batch Size \t Size in MB \t MB / Doc \t Time (ms) \t MB / Second");
for (int numDocs = min; numDocs <= max; numDocs += step)
{
List<TimeSpan> durations = new List<TimeSpan>();
double sizeInMb = 0.0;
for (int x = 0; x < numTries; x++)
{
List<Hotel> hotels = dg.GetHotels(numDocs, "large");
DateTime startTime = DateTime.Now;
await UploadDocumentsAsync(searchClient, hotels).ConfigureAwait(false);
DateTime endTime = DateTime.Now;
durations.Add(endTime - startTime);
sizeInMb = EstimateObjectSize(hotels);
}
var avgDuration = durations.Average(timeSpan => timeSpan.TotalMilliseconds);
var avgDurationInSeconds = avgDuration / 1000;
var mbPerSecond = sizeInMb / avgDurationInSeconds;
Console.WriteLine("{0} \t\t {1} \t\t {2} \t\t {3} \t {4}", numDocs, Math.Round(sizeInMb, 3), Math.Round(sizeInMb / numDocs, 3), Math.Round(avgDuration, 3), Math.Round(mbPerSecond, 3));
// Pausing 2 seconds to let the search service catch its breath
Thread.Sleep(2000);
}
Console.WriteLine();
}
Eftersom inte alla dokument har samma storlek (även om de finns i det här exemplet) uppskattar vi storleken på de data som vi skickar till söktjänsten. Du kan göra detta med hjälp av följande funktion som först konverterar objektet till JSON och sedan avgör dess storlek i byte. Med den här tekniken kan vi avgöra vilka batchstorlekar som är mest effektiva när det gäller MB/s-indexeringshastigheter.
// Returns size of object in MB
public static double EstimateObjectSize(object data)
{
// converting object to byte[] to determine the size of the data
BinaryFormatter bf = new BinaryFormatter();
MemoryStream ms = new MemoryStream();
byte[] Array;
// converting data to json for more accurate sizing
var json = JsonSerializer.Serialize(data);
bf.Serialize(ms, json);
Array = ms.ToArray();
// converting from bytes to megabytes
double sizeInMb = (double)Array.Length / 1000000;
return sizeInMb;
}
Funktionen kräver ett SearchClient plus antalet försök som du vill testa för varje batchstorlek. Eftersom indexeringstiderna kan variera för varje batch kan du prova varje batch tre gånger som standard för att göra resultaten mer statistiskt signifikanta.
await TestBatchSizesAsync(searchClient, numTries: 3);
När du kör funktionen bör du se utdata i konsolen som liknar följande exempel:

Identifiera vilken batchstorlek som är mest effektiv och använd batchstorleken i nästa steg i den här självstudien. Du kan se en platå i MB/s över olika batchstorlekar.
Indexering av data
Nu när du har identifierat batchstorleken som du tänker använda är nästa steg att börja indexering av data. Det här exemplet visar hur du indexerar data effektivt:
- Använder flera trådar/arbetare
- Implementerar en återförsöksstrategi med exponentiell avståndstagande
Avkommentera raderna 41 genom 49 och kör sedan programmet igen. Vid den här körningen genererar och skickar exemplet batchar med dokument, upp till 100 000 om du kör koden utan att ändra parametrarna.
Använda flera trådar/arbetare
Om du vill dra nytta av Azure AI Searchs indexeringshastigheter använder du flera trådar för att skicka batchindexeringsbegäranden samtidigt till tjänsten.
Flera av de viktigaste övervägandena kan påverka det optimala antalet trådar. Du kan ändra det här exemplet och testa med olika antal trådar för att fastställa det optimala trådantalet för ditt scenario. Men så länge du har flera trådar som körs samtidigt bör du kunna dra nytta av de flesta effektivitetsvinster.
När du ökar antalet begäranden som når söktjänsten kan det uppstå HTTP-statuskoder som anger att begäran inte lyckades helt. Under indexeringen är två vanliga HTTP-statuskoder:
- 503 Tjänsten är inte tillgänglig: Det här felet innebär att systemet är hårt belastat och att din begäran inte kan bearbetas just nu.
- 207 Multi-Status: Det här felet innebär att vissa dokument lyckades, men minst ett misslyckades.
Implementera en metod för återförsök med exponentiell backoff
Om ett fel inträffar bör du upprepa förfrågningarna med hjälp av en exponentiell backoff-återförsöksstrategi.
Azure AI Searchs .NET SDK försöker automatiskt 503:e och andra misslyckade begäranden igen, men du bör implementera din egen logik för att försöka 207:e igen. Verktyg med öppen källkod som Polly kan vara användbara i en återförsöksstrategi.
I det här exemplet implementerar vi vår egen strategi för återförsök av exponentiell backoff. Vi börjar med att definiera vissa variabler, inklusive maxRetryAttempts och den initiala delay för en misslyckad begäran.
// Create batch of documents for indexing
var batch = IndexDocumentsBatch.Upload(hotels);
// Create an object to hold the result
IndexDocumentsResult result = null;
// Define parameters for exponential backoff
int attempts = 0;
TimeSpan delay = delay = TimeSpan.FromSeconds(2);
int maxRetryAttempts = 5;
Resultatet av indexeringsåtgärden lagras i variabeln IndexDocumentResult result. Med den här variabeln kan du kontrollera om dokument i batchen misslyckades, som du ser i följande exempel. Om det uppstår ett partiellt fel skapas en ny batch baserat på de misslyckade dokumentens ID.
RequestFailedException undantag bör också fångas, eftersom de anger att begäran misslyckades helt och bör försöka igen.
// Implement exponential backoff
do
{
try
{
attempts++;
result = await searchClient.IndexDocumentsAsync(batch).ConfigureAwait(false);
var failedDocuments = result.Results.Where(r => r.Succeeded != true).ToList();
// handle partial failure
if (failedDocuments.Count > 0)
{
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
else
{
Console.WriteLine("[Batch starting at doc {0} had partial failure]", id);
Console.WriteLine("[Retrying {0} failed documents] \n", failedDocuments.Count);
// creating a batch of failed documents to retry
var failedDocumentKeys = failedDocuments.Select(doc => doc.Key).ToList();
hotels = hotels.Where(h => failedDocumentKeys.Contains(h.HotelId)).ToList();
batch = IndexDocumentsBatch.Upload(hotels);
Task.Delay(delay).Wait();
delay = delay * 2;
continue;
}
}
return result;
}
catch (RequestFailedException ex)
{
Console.WriteLine("[Batch starting at doc {0} failed]", id);
Console.WriteLine("[Retrying entire batch] \n");
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
Task.Delay(delay).Wait();
delay = delay * 2;
}
} while (true);
Härifrån omsluter du den exponentiella backoff-koden till en funktion så att den enkelt kan anropas.
En annan funktion skapas sedan för att hantera de aktiva trådarna. För enkelhetens skull ingår inte den funktionen här utan finns i ExponentialBackoff.cs. Du kan anropa funktionen med hjälp av följande kommando, där hotels är de data som vi vill ladda upp, 1000 är batchstorleken och 8 är antalet samtidiga trådar.
await ExponentialBackoff.IndexData(indexClient, hotels, 1000, 8);
När du kör funktionen bör du se utdata som liknar följande exempel:

När en batch med dokument misslyckas skrivs ett fel ut som anger felet och att batchen görs om.
[Batch starting at doc 6000 had partial failure]
[Retrying 560 failed documents]
När funktionen har körts kan du kontrollera att alla dokument har lagts till i indexet.
Utforska indexet
När programmet har körts kan du utforska det ifyllda sökindexet antingen programmatiskt eller med hjälp av Sökutforskaren i Azure-portalen.
Programmässigt
Det finns två huvudsakliga alternativ för att kontrollera antalet dokument i ett index: API:et Antal dokument och API:et Hämta indexstatistik. Båda sökvägarna kräver tid att bearbeta, så oroa dig inte om antalet dokument som returneras initialt är lägre än förväntat.
Räkna dokument
Åtgärden Antal dokument hämtar antalet dokument i ett sökindex.
long indexDocCount = await searchClient.GetDocumentCountAsync();
Hämta indexstatistik
Åtgärden Hämta indexstatistik returnerar ett dokumentantal för det aktuella indexet plus lagringsanvändning. Indexstatistiken tar längre tid att uppdatera än antalet dokument.
var indexStats = await indexClient.GetIndexStatisticsAsync(indexName);
Azure portal
I Azure-portalen går du till den vänstra rutan och letar upp indexet för optimeringsindex i listan Index .

Antalet dokument och lagringsstorleken baseras på API:et Hämta indexstatistik och kan ta flera minuter att uppdatera.
Återställa och köra igen
I de tidiga experimentella utvecklingsfaserna är det mest praktiska sättet att utforma iteration att ta bort objekten från Azure AI Search och låta koden återskapa dem. Resursnamn är unika. Om du tar bort ett objekt kan du återskapa det med samma namn.
Exempelkoden för den här handledningen söker efter befintliga index och tar bort dem så att du kan köra koden igen.
Du kan också använda Azure-portalen för att ta bort index.
Rensa resurser
När du arbetar i din egen prenumeration i slutet av ett projekt är det en bra idé att ta bort de resurser som du inte längre behöver. Resurser som körs i onödan kan kosta dig pengar. Du kan ta bort enstaka resurser eller hela resursgruppen om du vill ta bort alla resurser.
Du kan hitta och hantera resurser i Azure Portal med hjälp av länken Alla resurser eller Resursgrupper i det vänstra navigeringsfönstret.
Nästa steg
Om du vill veta mer om att indexera stora mängder data kan du prova följande självstudie: