Övervakning och diagnostik för Azure Service Fabric
Den här artikeln innehåller en översikt över övervakning och diagnostik för Azure Service Fabric. Övervakning och diagnostik är avgörande för att utveckla, testa och distribuera arbetsbelastningar i alla molnmiljöer. Du kan till exempel spåra hur dina program används, de åtgärder som vidtas av Service Fabric-plattformen, resursanvändningen med prestandaräknare och klustrets övergripande hälsa. Du kan använda den här informationen för att diagnostisera och korrigera problem och förhindra att de inträffar i framtiden. I de kommande avsnitten beskrivs kortfattat varje område i Service Fabric-övervakning som ska beaktas för produktionsarbetsbelastningar.
Kommentar
Den här artikeln uppdaterades nyligen för att använda termen Azure Monitor-loggar i stället för Log Analytics. Loggdata lagras fortfarande på en Log Analytics-arbetsyta och samlas fortfarande in och analyseras av samma Log Analytics-tjänst. Vi uppdaterar terminologin för att bättre återspegla loggarnas roll i Azure Monitor. Mer information finns i Terminologiändringar i Azure Monitor.
Programövervakning
Programövervakning spårar hur funktioner och komponenter i ditt program används. Du vill övervaka dina program för att se till att problem som påverkar användarna fångas. Ansvaret för programövervakning ligger på användarna som utvecklar ett program och dess tjänster eftersom det är unikt för programmets affärslogik. Övervakning av dina program kan vara användbart i följande scenarier:
- Hur mycket trafik upplever mitt program? – Behöver du skala dina tjänster för att uppfylla användarnas krav eller åtgärda en potentiell flaskhals i ditt program?
- Lyckas och spåras mina tjänst-till-tjänst-anrop?
- Vilka åtgärder vidtas av användarna av mitt program? – Insamling av telemetri kan vägleda framtida funktionsutveckling och bättre diagnostik för programfel
- Utlöser mitt program ohanterade undantag?
- Vad händer inom de tjänster som körs i mina containrar?
Det fantastiska med programövervakning är att utvecklare kan använda vilka verktyg och ramverk de vill eftersom det finns inom ramen för ditt program! Du kan lära dig mer om Azure-lösningen för programövervakning med Azure Monitor Application Insights i händelseanalys med Application Insights. Vi har också en självstudiekurs om hur du konfigurerar detta för .NET-program. Den här självstudien beskriver hur du installerar rätt verktyg, ett exempel för att skriva anpassad telemetri i ditt program och visa programdiagnostik och telemetri i Azure-portalen.
Plattformsövervakning (kluster)
En användare har kontroll över vilken telemetri som kommer från deras program eftersom en användare skriver själva koden, men hur är det med diagnostiken från Service Fabric-plattformen? Ett av Service Fabrics mål är att hålla program motståndskraftiga mot maskinvarufel. Det här målet uppnås genom plattformens systemtjänsters förmåga att identifiera infrastrukturproblem och snabbt redundansväxla arbetsbelastningar till andra noder i klustret. Men i det här specifika fallet, vad händer om systemtjänsterna själva har problem? Eller om regler för placering av tjänster överträds vid försök att distribuera eller flytta en arbetsbelastning? Service Fabric tillhandahåller diagnostik för dessa och mer för att se till att du är informerad om aktivitet som äger rum i klustret. Några exempelscenarier för klusterövervakning är:
Service Fabric tillhandahåller en omfattande uppsättning händelser direkt. Dessa Service Fabric-händelser kan nås via EventStore eller den operativa kanalen (händelsekanal som exponeras av plattformen).
Service Fabric-händelsekanaler – I Windows är Service Fabric-händelser tillgängliga från en enda ETW-provider med en uppsättning relevanta
logLevelKeywordFilterssom används för att välja mellan kanaler för drift och data och meddelanden . Det här är det sätt på vilket vi separerar utgående Service Fabric-händelser som ska filtreras efter behov. I Linux kommer Service Fabric-händelser via LTTng och placeras i en Lagringstabell, varifrån de kan filtreras efter behov. Dessa kanaler innehåller utvalda, strukturerade händelser som kan användas för att bättre förstå klustrets tillstånd. Diagnostik aktiveras som standard när klustret skapas, vilket skapar en Azure Storage-tabell där händelserna från dessa kanaler skickas så att du kan fråga i framtiden.EventStore – EventStore är en funktion som erbjuds av plattformen som tillhandahåller Service Fabric-plattformshändelser som är tillgängliga i Service Fabric Explorer och via REST API. Du kan se en ögonblicksbildsvy över vad som händer i klustret för varje entitet, t.ex. nod, tjänst, program och fråga baserat på tidpunkten för händelsen. Du kan också läsa mer om EventStore i Översikt över EventStore.
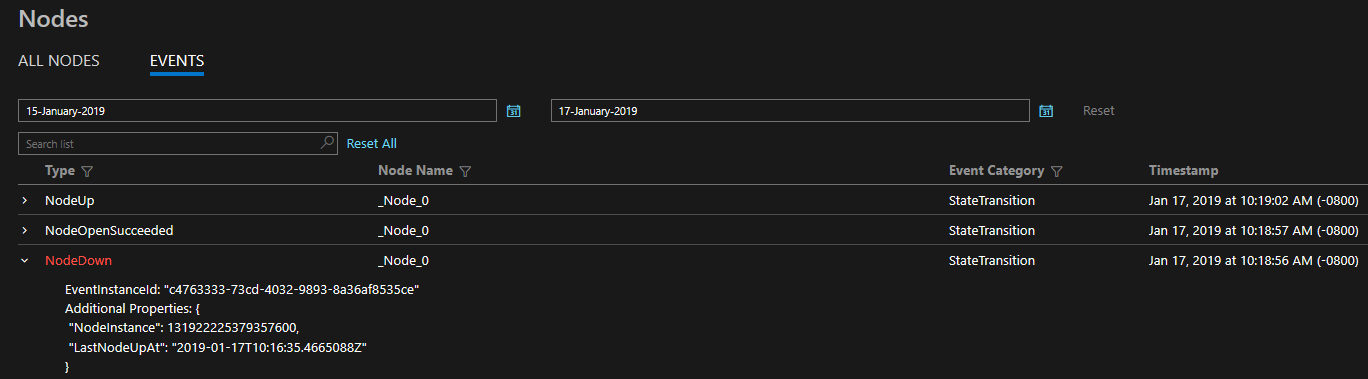
Diagnostiken som tillhandahålls är i form av en omfattande uppsättning händelser direkt. Dessa Service Fabric-händelser illustrerar åtgärder som utförs av plattformen på olika entiteter, till exempel noder, program, tjänster, partitioner osv. I det sista scenariot ovan, om en nod skulle gå ner, skulle plattformen generera en NodeDown händelse och du kan meddelas omedelbart av ditt valfritt övervakningsverktyg. Andra vanliga exempel är ApplicationUpgradeRollbackStarted eller PartitionReconfigured under en redundansväxling. Samma händelser är tillgängliga i både Windows- och Linux-kluster.
Händelserna skickas via standardkanaler i både Windows och Linux och kan läsas av alla övervakningsverktyg som stöder dessa. Azure Monitor-lösningen är Azure Monitor-loggar. Läs gärna mer om vår Integrering av Azure Monitor-loggar som innehåller en anpassad instrumentpanel för ditt kluster och några exempelfrågor som du kan skapa aviseringar från. Fler klusterövervakningskoncept finns tillgängliga på plattformsnivå för händelse- och logggenerering.
Hälsoövervakning
Service Fabric-plattformen innehåller en hälsomodell som tillhandahåller utökningsbar hälsorapportering för status för entiteter i ett kluster. Varje nod, program, tjänst, partition, replik eller instans har en ständigt uppdaterbar hälsostatus. Hälsostatusen kan antingen vara "OK", "Varning" eller "Fel". Tänk på Service Fabric-händelser som verb som görs av klustret till olika entiteter och hälsa som ett adjektiv för varje entitet. Varje gång hälsotillståndet för en viss entitet övergår genereras även en händelse. På så sätt kan du ställa in frågor och aviseringar för hälsohändelser i valfritt övervakningsverktyg, precis som andra händelser.
Dessutom låter vi även användare åsidosätta hälsotillståndet för entiteter. Om ditt program genomgår en uppgradering och verifieringstesten misslyckas kan du skriva till Service Fabric Health med hjälp av hälso-API:et för att indikera att ditt program inte längre är felfritt, och Service Fabric återställer uppgraderingen automatiskt! Mer information om hälsomodellen finns i introduktionen till Service Fabric-hälsoövervakning
Vakthundar
I allmänhet är en vakthund en separat tjänst som bevakar hälsa och belastning för tjänster, pingar slutpunkter och rapporterar oväntade hälsohändelser i klustret. Detta kan hjälpa till att förhindra fel som kanske inte identifieras enbart baserat på prestanda för en enda tjänst. Vakthundar är också en bra plats för att vara värd för kod som utför åtgärdsåtgärder som inte kräver användarinteraktion, till exempel att rensa loggfiler i lagring vid vissa tidsintervall. Om du vill ha en fullständigt implementerad SF-övervakningstjänst med öppen källkod som innehåller en lätthanterad utökningsmodell för vakthundar och som körs i både Windows- och Linux-kluster kan du läsa fabricObserver-projektet . FabricObserver är produktionsklar programvara. Vi rekommenderar att du distribuerar FabricObserver till dina test- och produktionskluster och utökar det för att uppfylla dina behov, antingen via dess plugin-modell eller genom att förgrena den och skriva egna inbyggda observatörer. Den tidigare metoden (plugin-program) är den rekommenderade metoden.
Övervakning av infrastruktur (prestanda)
Nu när vi har gått igenom diagnostiken i ditt program och plattformen, hur vet vi att maskinvaran fungerar som förväntat? Att övervaka din underliggande infrastruktur är en viktig del av att förstå tillståndet för klustret och resursutnyttjandet. Mätning av systemprestanda beror på många faktorer som kan vara subjektiva beroende på dina arbetsbelastningar. Dessa faktorer mäts vanligtvis via prestandaräknare. Dessa prestandaräknare kan komma från en mängd olika källor, inklusive operativsystemet, .NET-ramverket eller själva Service Fabric-plattformen. Vissa scenarier där de skulle vara användbara är
- Använder jag maskinvaran effektivt? Vill du använda maskinvaran med 90 % CPU eller 10 % CPU. Detta är praktiskt när du skalar klustret eller optimerar programmets processer.
- Kan jag förutsäga infrastrukturproblem proaktivt? – Många problem föregås av plötsliga ändringar (sänkningar) av prestanda, så du kan använda prestandaräknare som nätverks-I/O och CPU-användning för att förutsäga och diagnostisera problemen proaktivt.
En lista över prestandaräknare som ska samlas in på infrastrukturnivå finns i Prestandamått.
Service Fabric tillhandahåller också en uppsättning prestandaräknare för programmeringsmodellerna Reliable Services och Actors. Om du använder någon av dessa modeller kan dessa prestandaräknare information för att säkerställa att dina aktörer snurrar upp och ner korrekt, eller att dina tillförlitliga tjänstbegäranden hanteras tillräckligt snabbt. Mer information finns i Övervakning för tillförlitlig tjänstmoting och prestandaövervakning för Reliable Actors.
Azure Monitor-lösningen för att samla in dessa är Azure Monitor-loggar precis som övervakning på plattformsnivå. Du bör använda Log Analytics-agenten för att samla in lämpliga prestandaräknare och visa dem i Azure Monitor-loggar.
Rekommenderad installation
Nu när vi har gått igenom varje område med övervaknings- och exempelscenarier, här är en sammanfattning av Azure-övervakningsverktygen och konfigureras som behövs för att övervaka alla områden ovan.
- Programövervakning med Application Insights
- Klusterövervakning med Diagnostikagent och Azure Monitor-loggar
- Infrastrukturövervakning med Azure Monitor-loggar
Du kan också använda och ändra ARM-exempelmallen som finns här för att automatisera distributionen av alla nödvändiga resurser och agenter.
Andra loggningslösningar
Även om de två lösningar som vi rekommenderade, Azure Monitor-loggar och Application Insights , har byggt in integrering med Service Fabric, skrivs många händelser ut via ETW-leverantörer och är utökningsbara med andra loggningslösningar. Du bör också titta på Elastic Stack (särskilt om du överväger att köra ett kluster i en offlinemiljö), Dynatrace eller någon annan plattform som du föredrar. Vi har en lista över integrerade partner som finns här.
Viktiga punkter för alla plattformar som du väljer bör vara hur bekväm du är med användargränssnittet, frågefunktionerna, de anpassade visualiseringarna och instrumentpanelerna som är tillgängliga och de ytterligare verktyg som de tillhandahåller för att förbättra din övervakningsupplevelse.
Nästa steg
- Information om hur du kommer igång med att instrumentera dina program finns i Händelse och logggenerering på programnivå.
- Gå igenom stegen för att konfigurera Application Insights för ditt program med Övervaka och diagnostisera ett ASP.NET Core-program i Service Fabric.
- Läs mer om övervakning av plattformen och de händelser som Service Fabric tillhandahåller på plattformsnivå för händelse- och logggenerering.
- Konfigurera Integrering av Azure Monitor-loggar med Service Fabric i Konfigurera Azure Monitor-loggar för ett kluster
- Lär dig hur du konfigurerar Azure Monitor-loggar för övervakning av containrar – Övervakning och diagnostik för Windows-containrar i Azure Service Fabric.
- Se exempel på diagnostikproblem och lösningar med Service Fabric när du diagnostiserar vanliga scenarier
- Kolla in andra diagnostikprodukter som integreras med Service Fabric i Service Fabric-diagnostikpartners
- Lär dig mer om allmänna övervakningsrekommendationer för Azure-resurser – Metodtips – Övervakning och diagnostik.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för