Gäller för: ✔️ Virtuella Linux-datorer ✔️ med virtuella Windows-datorer ✔️ – flexibla skalningsuppsättningar ✔️ Enhetliga skalningsuppsättningar
Storlekar på virtuella Azure-datorer (VM) är utformade för att tillhandahålla ett brett utbud av alternativ för att vara värd för dina servrar och deras arbetsbelastningar i molnet. Storlekar kategoriseras i olika familjer och typer, var och en optimerad för specifika ändamål. Användare kan välja den lämpligaste VM-storleken baserat på deras krav, till exempel CPU, minne, lagring och nätverksbandbredd.
Den här artikeln beskriver vilka storlekar som är, ger en översikt över tillgängliga storlekar och visar olika alternativ för virtuella Azure-datorinstanser som du kan använda för att köra dina appar och arbetsbelastningar.
Dricks
Prova väljareverktyget För virtuella datorer för att hitta andra storlekar som passar bäst för din arbetsbelastning.
Namn på vm-storlek och serie
Storlekar på virtuella Azure-datorer följer specifika namngivningskonventioner för att ange olika funktioner och specifikationer. Varje tecken i namnet representerar olika aspekter av den virtuella datorn. Dessa omfattar vm-familjen, antalet virtuella processorer och extra funktioner som premiumlagring eller inkluderade acceleratorer.
Namngivning av virtuella datorer är ytterligare uppdelat i serienamnet och namnet "Storlek". Storleksnamn innehåller extra tecken som representerar antalet vCPU:er, typ av lagring osv.
Kategori
beskrivning
Länkar
Typ
Grundläggande kategorisering efter avsedd arbetsbelastning.
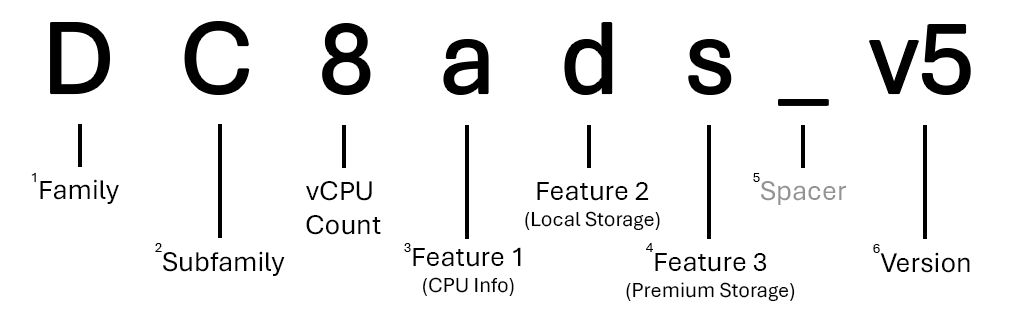
Här är en uppdelning av en storleksserie för generell användning DCads_v5-serien.
1 De flesta familjer representeras med en bokstav, men andra som GPU-storlekar (ND-series, NV-seriesosv.) använder två.
2 De flesta underfamiljer representeras med en enda versal, men andra (till exempel ) betraktas fortfarande som Ebsv5-seriesunderfamiljer till sin överordnade familj på grund av funktionsskillnader.
3 Om ingen funktionsbeteckning för en PROCESSOR visas använder serien Intel x86-64-processorer. Om processorn är AMD visas den som a. Om processorn är ARM-baserad (Microsoft Cobalt eller Ampere Altra) visas den som p.
4 Det kan finnas valfritt antal extra funktioner i ett storleksnamn. Det kan inte finnas någon (Dv5-series) eller så kan det finnas tre (Dplds_v6-series).
5 Versionsnummer visas bara i storleksnamnet om det finns flera versioner av samma serie. Om du använder den första versionen av en serie (HB-series, B-seriesosv.) ingår den ofta inte i storleksnamnet.
Kommentar
Alla storlekar kommer inte att ha underfamiljer, stödacceleratorer eller ange CPU-leverantören. Mer information om namngivningskonventioner för VM-storlek finns i Namngivningskonventioner för virtuella Azure-datorer.
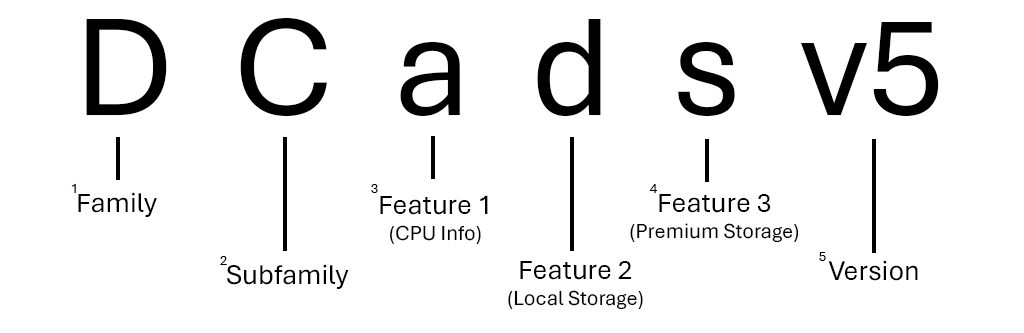
Här är en uppdelning av storleken "Standard_DC8ads_v5" i DCadsv5-serien
1 De flesta familjer representeras med en bokstav, men andra som GPU-storlekar (ND-series, NV-seriesosv.) använder två.
2 De flesta underfamiljer representeras med en enda versal, men andra (till exempel ) betraktas fortfarande som Ebsv5-seriesunderfamiljer till sin överordnade familj på grund av funktionsskillnader.
3 Om ingen funktionsbeteckning för en PROCESSOR visas använder serien Intel x86-64-processorer. Om processorn är AMD visas den som a. Om processorn är ARM-baserad (Microsoft Cobalt eller Ampere Altra) visas den som p.
4 Det kan finnas valfritt antal extra funktioner i ett storleksnamn. Det kan inte finnas någon (Dv5-series) eller så kan det finnas tre (Dplds_v6-series).
5 blanksteg kan visas flera gånger i ett storleksnamn, till exempel i ND_H100_v5-series. I det här fallet separerar de GPU-ID:t från resten av storleksnamnet.
6 Versionsnummer visas bara i storleksnamnet om det finns flera versioner av samma serie. Om du använder den första versionen av en serie (HB-series, B-seriesosv.) ingår den ofta inte i storleksnamnet.
Kommentar
Alla storlekar kommer inte att ha underfamiljer, stödacceleratorer eller ange CPU-leverantören. Mer information om namngivningskonventioner för VM-storlek finns i Namngivningskonventioner för virtuella Azure-datorer.
Lista över vm-storleksfamiljer efter typ
Det här avsnittet innehåller en lista över alla aktuella serier av generationsstorlekar med flikar som är dedikerade till varje storleksfamilj. Varje grupp har kolumnen Serielista med en länkad lista över alla tillgängliga storleksserier. Dessa länkar tar dig till familjesidan för serien, där du hittar detaljerad information om varje storlek i serien eller går till seriens sida för en lista över storlekar i serien.
Om du vill veta mer om en storleksfamilj klickar du på fliken "familj" under varje typavsnitt. Där kan du läsa en sammanfattning om familjen, se de arbetsbelastningar som rekommenderas för och visa hela familjesidan med specifikationer för alla serier i den familjen.
Generell användning
Vm-storlekar för generell användning ger ett balanserat förhållande mellan cpu och minne. Utmärkt för testning och utveckling, små till medelstora databaser och webbservrar med låg till medelhög trafik.
A-serien med VM-storleksserier är en av Azures allmänna VM-instanser. De är utformade för arbetsbelastningar på ingångsnivå, till exempel utvecklings- och testmiljöer, små till medelstora databaser och webbservrar med låg trafik.
Kostnadseffektivitet: Virtuella datorer i A-serien är några av de mest budgetvänliga alternativen i Azure, vilket gör dem till ett bra val för projekt med begränsade ekonomiska resurser eller sådana som inte kräver högpresterande beräkningsfunktioner.
Allmänna arbetsbelastningar: Virtuella datorer i A-serien lämpar sig väl för hantering av grundläggande program, lätta webbservrar och små databaser som inte kräver omfattande processor-, minnes- eller I/O-prestanda.
Program på startnivå: Virtuella datorer i A-serien kan fungera som en bra startpunkt för distribution av program som inte förväntas skalas avsevärt. De tillhandahåller en plattform för program och tjänster som kräver mindre bearbetningskraft.
B-familj
B-serien med VM-storleksserier är en av Azures allmänna VM-instanser. Traditionella virtuella Azure-datorer ger fast CPU-prestanda, men virtuella datorer i B-serien är den enda vm-typ som använder krediter för cpu-prestandaetablering. Virtuella datorer i B-serien använder en CPU-kreditmodell för att spåra hur mycket PROCESSOR som förbrukas – den virtuella datorn ackumulerar CPU-krediter när en arbetsbelastning körs under det grundläggande tröskelvärdet för CPU-prestanda och använder krediter när den körs över det grundläggande cpu-prestandatröskelvärdet tills alla dess krediter förbrukas. När du använder alla CPU-krediter begränsas en virtuell dator i B-serien tillbaka till sin grundläggande CPU-prestanda tills den ackumulerar krediterna till CPU-burst igen.
Flexibilitet för användning: Virtuella datorer i B-serien passar bäst för arbetsbelastningar som inte kräver konstant full CPU-prestanda.
Idealiska program: Virtuella datorer i B-serien är idealiska program som webbservrar, konceptbevis, små databaser och utvecklingsmiljöer.
Prestandabehov: Vissa arbetsbelastningar har ofta höga prestandakrav, vilket innebär att de bara behöver höga prestanda sporadiskt. Virtuella datorer i B-serien är perfekta för det här användningsfallet.
D-familj
D-serien med VM-storlekar är en av Azures vm-storlekar för generell användning. De är utformade för en mängd olika krävande arbetsbelastningar, till exempel företagsprogram, webb- och programservrar, utvecklings- och testmiljöer och batchbearbetningsuppgifter. Utrustade med snabbare processorer och mer minne per kärna än de virtuella datorerna i A-serien erbjuder virtuella datorer i D-serien en stark prestandabalans, vilket gör dem lämpliga för program som kräver både hög beräkningskraft och betydande minnesresurser. De är särskilt gynnade för att köra program i företagsklass, stödja måttliga till högtrafikerade webbservrar och utföra dataintensiv batchbearbetning.
Balanserade prestanda: Virtuella datorer i D-serien ger en solid balans mellan processorfunktioner och minnesstorlek, vilket gör dem lämpliga för de flesta produktionsarbetsbelastningar. De är utrustade med snabbare processorer jämfört med A-serien och ger mer minne per kärna.
Företagsprogram: De passar bra för att köra företagsprogram som SAP, Microsoft Dynamics eller stora relationsdatabaser som kräver både hög beräkningskraft och stort minne.
Utvecklings- och testmiljöer: Med sina balanserade resurser är virtuella datorer i D-serien idealiska för utvecklings- och testmiljöer där utvecklare behöver simulera produktionsförhållanden noga.
Webb- och programservrar: De tillhandahåller de resurser som krävs för att vara värd för webbservrar och programservrar som upplever måttlig till tung trafik, vilket säkerställer smidiga och dynamiska användarupplevelser.
Batchbearbetning: Virtuella datorer i D-serien är effektiva för hantering av batchbearbetningsuppgifter som kräver snabb bearbetning av stora mängder data tack vare snabba processorer och gott om minne.
Spelservrar: De högpresterande funktionerna i virtuella datorer i D-serien gör dem lämpliga för spelservrar där svarstid och hastighet är avgörande för en bra användarupplevelse.
DC-familj
Dc-serien är en av Azures säkerhetsfokuserade vm-instanser för generell användning. De är utformade för konfidentiell databehandling som erbjuder förbättrat dataskydd och integritet med olika maskinvarubaserade TEE(Trusted Execution Environments). Dessa virtuella datorer fungerar bra för många arbetsbelastningar för allmän databehandling, e-handelssystem, webbklientdelar, virtualiseringslösningar för skrivbord, känsliga databaser, andra företagsprogram med mera.
Dataskydd: Virtuella datorer i DC-serien är idealiska för program som hanterar, lagrar och bearbetar känsliga data, till exempel personlig identifierbar information (PII), finansiella data, hälsojournaler och andra typer av konfidentiell information. Den maskinvarubaserade krypteringen säkerställer att data skyddas i vila och under bearbetningen.
Regelefterlevnad: För företag som behöver uppfylla strikta regelkrav för datasekretess och säkerhet (t.ex. GDPR, HIPAA eller finansiella branschbestämmelser) tillhandahåller dc-seriens virtuella datorer en maskinvarusäkrad miljö som kan hjälpa till att uppfylla dessa efterlevnadskrav.
Beräkningsoptimerad
Beräkningsoptimerade VM-storlekar har ett högt cpu-till-minne-förhållande. Dessa storlekar är bra för webbservrar med medelhög trafik, nätverksinstallationer, batchprocesser och programservrar.
Om du vill veta mer om en viss storleksfamilj eller serie klickar du på fliken för den familjen och bläddrar för att hitta önskad storleksserie.
F-familj
Serien "F" för VM-storlek är en av Azures beräkningsoptimerade VM-instanser. De är utformade för arbetsbelastningar som kräver höga CPU-prestanda, till exempel batchbearbetning, webbservrar, analys och spel. Med ett högt förhållande mellan processor och minne är virtuella datorer i F-serien utrustade med kraftfulla processorer för att hantera program som kräver mer CPU-kapacitet i förhållande till minnet. Detta gör dem särskilt effektiva för scenarier där snabb och effektiv bearbetning är avgörande, vilket gör det möjligt för företag att köra sina beräkningsbundna program effektivt och kostnadseffektivt.
Webbservrar: Virtuella datorer i F-serien är utmärkta för att hantera webbservrar och program som kräver betydande beräkningskapacitet för att effektivt hantera webbtrafik utan att nödvändigtvis behöva stora mängder minne.
Batchbearbetning: Virtuella datorer i F-serien är idealiska för batchjobb och andra bearbetningsuppgifter som omfattar hantering av stora mängder data eller uppgifter i en kö men som är mer CPU-intensiva än minnesintensiva.
Programservrar: Program som kräver snabb bearbetning och inte har höga minnesbehov kan dra nytta av virtuella datorer i F-serien. Dessa kan omfatta programservrar med medelhög trafik, serverdelsservrar för företagsprogram och andra liknande uppgifter.
Spelservrar: På grund av deras höga CPU-prestanda är virtuella datorer i F-serien också lämpliga för spelservrar där snabb bearbetning är avgörande för en bra spelupplevelse.
Analys: Virtuella datorer i F-serien kan användas för dataanalysprogram som kräver bearbetningshastighet för att krossa siffror och utföra beräkningar mer än de kräver en stor mängd minne.
FX-familj
Fx-serien av VM-storleksserier är en av Azures specialiserade beräkningsoptimerade VM-instanser, som främst är utformade för arbetsbelastningar som kräver betydande CPU-funktioner. Dessa virtuella datorer använder de senaste Intel Ice Lake-processorerna och är optimerade för beräkningsintensiva uppgifter som finansiell modellering, vetenskapliga simuleringar och tunga beräkningar. Med hög frekvens och en stor cache per kärna ger virtuella datorer i FX-serien exceptionell beräkningskraft, vilket gör dem idealiska för scenarier som kräver omfattande bearbetningsresurser och snabb körning av komplexa åtgärder.
Electronic Design Automation (EDA): Virtuella datorer i FX-serien är väl lämpade för EDA-arbetsbelastningar, vilket kräver höga PROCESSOR-klockhastigheter och höga förhållandet mellan minne och CPU. Dessa arbetsbelastningar drar nytta av höga prestanda med en kärna och stor minneskapacitet för virtuella datorer i FX-serien.
Batchbearbetning: Virtuella datorer i FX-serien är utmärkta för batchbearbetningsjobb med högt dataflöde, till exempel de som omfattar storskalig dataanalys och transformering, där snabb bearbetning är kritisk.
Dataanalys: Virtuella datorer i FX-serien är lämpliga för intensiva dataanalysprogram, särskilt de som kräver snabb iteration och bearbetning av stora datamängder.
Minnesoptimerad
Minnesoptimerade VM-storlekar erbjuder ett högt förhållande mellan minne och CPU som är bra för relationsdatabasservrar, medelstora till stora cacheminnen och minnesintern analys.
Om du vill veta mer om en viss storleksfamilj eller serie klickar du på fliken för den familjen och bläddrar för att hitta önskad storleksserie.
E-familj
E-serien med VM-storlek är en av Azures minnesoptimerade VM-instanser. De är utformade för minnesintensiva arbetsbelastningar, till exempel stora databaser, stordataanalys och företagsprogram som kräver stora mängder RAM-minne för att upprätthålla höga prestanda. Utrustade med höga förhållandet mellan minne och kärna stöder virtuella datorer i E-serien program och tjänster som drar nytta av snabbare dataåtkomst och effektivare databehandlingsfunktioner. Detta gör dem särskilt väl lämpade för scenarier med minnesinterna databaser och omfattande databearbetningsuppgifter där gott om minne är avgörande för optimala prestanda.
Minnesintensiva arbetsbelastningar: Virtuella E-familjedatorer är till för arbetsbelastningar som kräver ett stort minnesfotavtryck för att effektivt hantera uppgifter, till exempel simuleringar, storskaliga beräkningar inom vetenskaplig forskning eller finansiell riskmodellering.
Stora databaser och SQL-servrar: Virtuella datorer i E-serien är idealiska för att hantera stora relationsdatabaser som SQL Server- och NoSQL-databaser som drar nytta av hög minneskapacitet för bättre prestanda vid databearbetning och transaktionshantering.
Företagsprogram: Virtuella datorer i E-serien är lämpliga för resursintensiva företagsprogram, inklusive storskaliga ERP- och CRM-system, där tillgängligheten av gott om minne är avgörande för att hantera komplexa transaktioner och användarbelastningar.
Stordataprogram: Virtuella datorer i E-serien är effektiva för stordataanalysprogram som behöver bearbeta stora mängder data i minnet för att påskynda analys- och insiktsgenereringen.
Minnesintern databehandling: Virtuella E-familjedatorer är bra för minnesinterna databaser (t.ex. SAP HANA) som kräver stora mängder RAM-minne för att hålla hela datamängden i minnet, vilket möjliggör ultrasnabb databearbetning och frågesvar.
Datalagring: Virtuella datorer med e-familj tillhandahåller nödvändiga resurser för datalagerlösningar som hanterar och analyserar stora datamängder, förbättrar frågeprestanda och minskar svarstiderna.
Eb-familj
Eb-serien för VM-storlek är en av Azures minnesoptimerade VM-instanser. De är utformade för minnesintensiva arbetsbelastningar med höga fjärrlagringsprestanda, till exempel stora databaser, stordataanalys och företagsprogram som kräver stora mängder RAM-minne för att upprätthålla höga prestanda. Eb-seriens virtuella datorer har höga minnes-till-kärn-förhållanden och har stöd för program och tjänster som drar nytta av snabbare dataåtkomst och effektivare databehandlingsfunktioner. Detta gör dem särskilt väl lämpade för scenarier med minnesinterna databaser och omfattande databearbetningsuppgifter där gott om minne är avgörande för optimala prestanda.
Minnesintensiva arbetsbelastningar: Virtuella Eb-family-datorer är till för arbetsbelastningar som kräver ett stort minnesavtryck för att effektivt hantera uppgifter, till exempel simuleringar, storskaliga beräkningar inom vetenskaplig forskning eller finansiell riskmodellering.
Stora databaser och SQL-servrar: Virtuella Eb-family-datorer är idealiska för att hantera stora relationsdatabaser som SQL Server- och NoSQL-databaser som drar nytta av höga minneskapaciteter för bättre prestanda vid databearbetning och transaktionshantering.
Företagsprogram: Virtuella Datorer i Eb-familjen är lämpliga för resursintensiva företagsprogram, inklusive storskaliga ERP- och CRM-system, där tillgängligheten av gott om minne är avgörande för att hantera komplexa transaktioner och användarbelastningar.
Stordataprogram: Virtuella Datorer i Eb-familjen är effektiva för stordataanalysprogram som behöver bearbeta stora mängder data i minnet för att påskynda analys- och insiktsgenereringen.
Minnesintern databehandling: Virtuella Eb-family-datorer är bra för minnesinterna databaser (t.ex. SAP HANA) som kräver stora mängder RAM-minne för att hålla hela datamängden i minnet, vilket möjliggör ultrasnabb databearbetning och frågesvar.
Datalagring: Virtuella Datorer i Eb-family tillhandahåller nödvändiga resurser för datalagerlösningar som hanterar och analyserar stora datamängder, förbättrar frågeprestanda och minskar svarstiderna.
EC-familj
Underfamiljen "EC" för VM-storleksserier är en av Azures säkerhetsfokuserade minnesoptimerade VM-instanser. De är utformade för konfidentiell databehandling med förbättrat dataskydd och integritet, med olika maskinvarubaserade betrodda körningsmiljöer (TEE). Dessa instanser är idealiska för minnesintensiva arbetsbelastningar, till exempel stora databaser, stordataanalys och företagsprogram som kräver stora mängder RAM-minne för att upprätthålla höga prestanda.
Minnesintensiva arbetsbelastningar: Alla arbetsbelastningar som kräver ett stort minnesavtryck för att effektivt hantera uppgifter, till exempel simuleringar, storskaliga beräkningar inom vetenskaplig forskning eller modellering av finansiella risker.
Stora databaser och SQL-servrar: De är idealiska för att vara värd för stora relationsdatabaser som SQL Server- och NoSQL-databaser som drar nytta av höga minneskapaciteter för bättre prestanda vid databearbetning och transaktionshantering.
Företagsprogram: Lämpar sig för resursintensiva företagsprogram, inklusive storskaliga ERP- och CRM-system, där tillgängligheten av gott om minne är avgörande för att hantera komplexa transaktioner och användarbelastningar.
Stordataprogram: Effektivt för stordataanalysprogram som behöver bearbeta stora mängder data i minnet för att påskynda analys och insiktsgenerering.
Minnesintern databehandling: Till exempel minnesinterna databaser (t.ex. SAP HANA) som kräver stora mängder RAM-minne för att hålla hela datamängden i minnet, vilket möjliggör ultrasnabb databehandling och frågesvar.
Datalagring: Tillhandahåller nödvändiga resurser för datalagerlösningar som hanterar och analyserar stora datamängder, förbättrar frågeprestanda och minskar svarstiderna.
M-familj
M-serien med VM-storlek är en av Azures ultraminnesoptimerade VM-instanser som är utformade för extremt minnesintensiva arbetsbelastningar, till exempel stora minnesinterna databaser, datalagerhantering och databehandling med höga prestanda (HPC). Utrustade med betydande RAM-kapaciteter och höga vCPU-funktioner stöder de virtuella datorerna i M-familjen program och tjänster som kräver enorma mängder minne och betydande beräkningskraft. Hög resursallokering gör M-familjen särskilt lämplig för hantering av uppgifter som tung SQL Server och andra RDBMS-arbetsbelastningar, komplexa vetenskapliga simuleringar, databearbetning i realtid och storskaliga ERP-system (Enterprise Resource Planning), vilket säkerställer högsta prestanda för de mest krävande datacentrerade programmen.
SQL Server-arbetsbelastningar med höga minnesbehov: M-serien är särskilt effektiv för att köra SQL Server-datorer med höga minnesbehov, till exempel för onlinetransaktionsbearbetning (OLTP) eller dataanalys.
Minnesinterna databaser: M-serien är särskilt effektiv för att köra minnesinterna databaser som kräver stora mängder RAM-minne som SQL Server eller SAP HANA.
Stordataprogram: M-familjen är perfekt för hantering av stordataprogram som behöver bearbeta och analysera enorma datamängder i minnet, förbättra prestanda och minska tiden till insikter.
Datalagerhantering: Virtuella datorer med M-familj ger den prestanda och det minne som behövs för program för datalagerhantering , vilket underlättar snabbare frågor och bättre hantering av stora mängder data.
Företagsprogram: M-familjen stöder storskaliga företagsprogram, inklusive ERP- och CRM-system, som drar nytta av att ha mer minne för att hantera större datamängder och mer komplexa transaktioner effektivt.
Tunga arbetsbelastningar i virtualiserade miljöer: M-familjen är välutrustad för att hantera tunga virtualiserade miljöer, vilket ger betydande minne för att vara värd för flera virtuella datorer och program på en enda fysisk server.
Lagringsoptimerad
Storlekar för lagringsoptimerade virtuella datorer (VM) erbjuder högt diskdataflöde och I/O och är idealiska för stordata, SQL, NoSQL-databaser, datalager och stora transaktionsdatabaser. Exempel är Cassandra, MongoDB, Cloudera och Redis.
Om du vill veta mer om en viss storleksfamilj eller serie klickar du på fliken för den familjen och bläddrar för att hitta önskad storleksserie.
L-familj
L-serien med VM-storleksserier är en av Azures lagringsoptimerade VM-instanser. De är utformade för arbetsbelastningar som kräver högt diskdataflöde och I/O, till exempel databaser, stordataprogram och datalager. Utrustade med högt diskdataflöde och stora lokala disklagringskapaciteter stöder virtuella datorer i L-serien program och tjänster som drar nytta av låg svarstid och höga sekventiella läs- och skrivhastigheter. Detta gör dem särskilt väl lämpade för hantering av uppgifter som storskalig loggbearbetning, stordataanalys i realtid och scenarier med stora databaser som utför frekventa diskåtgärder, vilket säkerställer effektiva prestanda för lagringsintensiva program.
Stordataprogram: Virtuella datorer i L-serien är perfekta för stordataprogram som behöver bearbeta, analysera och manipulera stora datamängder som lagras direkt på lokala diskar, vilket drar nytta av höga I/O-prestanda.
Databasservrar: Virtuella datorer i L-serien ger nödvändiga lokala diskprestanda för SQL Server, MySQL, PostgreSQL och andra databasservrar som drar nytta av snabb åtkomst till disklagring.
Filservrar: Virtuella L-familjedatorer kan användas effektivt som filservrar i ett nätverk, hantera stora filer och hantera dem med högt dataflöde, särskilt användbart i miljöer med stora mediefiler.
Videoredigering och rendering: Det höga diskdataflödet och kapaciteten hos virtuella datorer i L-familjen är bra för videoredigering och renderingsuppgifter, där stora videofiler ofta läses och skrivs till disk.
GPU-accelererad
GPU-optimerade VM-storlekar är specialiserade virtuella datorer som är tillgängliga med enstaka, flera eller bråktals-GPU:er. Dessa storlekar är utformade för beräkningsintensiva, grafikintensiva och visualiseringsarbetsbelastningar.
Om du vill veta mer om en viss storleksfamilj eller serie klickar du på fliken för den familjen och bläddrar för att hitta önskad storleksserie.
NC-familj
Underfamiljen "NC" för VM-storleksserier är en av Azures GPU-optimerade VM-instanser. De är utformade för beräkningsintensiva arbetsbelastningar, till exempel AI- och maskininlärningsmodellträning, högpresterande databehandling (HPC) och grafikintensiva program. Utrustade med kraftfulla NVIDIA GPU:er erbjuder virtuella datorer i NC-serien betydande acceleration för processer som kräver hög beräkningskraft, inklusive djupinlärning, vetenskapliga simuleringar och 3D-rendering. Detta gör dem särskilt väl lämpade för branscher som teknikforskning, underhållning och teknik, där renderings- och bearbetningshastighet är avgörande för produktivitet och innovation.
AI och Maskininlärning: Virtuella datorer i NC-serien är idealiska för att träna komplexa maskininlärningsmodeller och köra AI-program. NVIDIA GPU:er ger betydande acceleration för beräkningar som vanligtvis ingår i djupinlärning och andra intensiva träningsuppgifter.
Databehandling med höga prestanda (HPC): Dessa virtuella datorer är lämpliga för vetenskapliga simuleringar, rendering och andra HPC-arbetsbelastningar som kan påskyndas av GPU:er. Områden som teknik, medicinsk forskning och finansiell modellering använder ofta virtuella datorer i NC-serien för att hantera sina beräkningsbehov effektivt.
Grafikrendering: Virtuella datorer i NC-serien används också för grafikintensiva program, inklusive videoredigering, 3D-rendering och grafikbearbetning i realtid. De är särskilt användbara i branscher som spelutveckling och filmproduktion.
Fjärrvisualisering: För program som kräver avancerade visualiseringsfunktioner, till exempel CAD- och visuella effekter, kan virtuella datorer i NC-serien tillhandahålla den nödvändiga GPU-kraften via fjärranslutning, så att användarna kan arbeta med komplexa grafiska uppgifter utan att behöva kraftfull lokal maskinvara.
Simulering och analys: Dessa virtuella datorer är också lämpliga för detaljerade simuleringar och analyser inom områden som bilkraschtestning, beräkningsströmningsdynamik och vädermodellering, där GPU-funktioner avsevärt kan påskynda bearbetningstiderna.
ND-familj
ND-serien med VM-storleksserier är en av Azures GPU-accelererade VM-instanser. De är utformade för djupinlärning, AI-forskning och högpresterande databehandlingsuppgifter som drar nytta av kraftfull GPU-acceleration. Utrustade med NVIDIA GPU:er erbjuder virtuella datorer i ND-serien särskilda funktioner för träning och slutsatsdragning av komplexa maskininlärningsmodeller, vilket underlättar snabbare beräkningar och effektiv hantering av stora datamängder. Detta gör dem särskilt väl lämpade för akademiska och kommersiella program inom AI-utveckling och simulering, där den senaste GPU-tekniken är avgörande för att uppnå snabba och korrekta resultat vid bearbetning av neurala nätverk och andra beräkningsintensiva uppgifter.
AI och djupinlärning: Virtuella datorer i ND-serien är idealiska för träning och distribution av komplexa djupinlärningsmodeller. Utrustade med kraftfulla NVIDIA GPU:er ger de den beräkningskraft som krävs för att hantera omfattande neural nätverksträning med stora datamängder, vilket avsevärt minskar träningstiderna.
Högpresterande databehandling (HPC): Virtuella datorer i ND-serien är lämpliga för HPC-program som kräver GPU-acceleration. Fält som vetenskaplig forskning, tekniska simuleringar (till exempel beräkningsströmningsdynamik) och genomisk bearbetning kan dra nytta av databehandlingsfunktionerna i ND-seriens virtuella datorer.
NG-familj
NG-serien med VM-storleksserier är en av Azures GPU-optimerade VM-instanser, särskilt utformade för molnspel och fjärrskrivbordsprogram. De utnyttjar kraftfulla AMD Radeon™ PRO GPU:er för att leverera interaktiva spelupplevelser av hög kvalitet i molnet, optimerade för rendering av komplex grafik och strömmande hd-video. Detta säkerställer att spelare får en sömlös, dynamisk spelmiljö som är tillgänglig från alla enheter. Dessutom ger virtuella datorer i NG-serien en högkvalitativ, dynamisk fjärrskrivbordsupplevelse, vilket gör dem idealiska för användare som behöver tillförlitlig och högpresterande åtkomst till skrivbordsprogram var som helst i världen.
Cloud Gaming: Virtuella datorer i NG-serien utnyttjar kraftfulla AMD Radeon™ PRO-GPU:er för att leverera interaktiva spelupplevelser av hög kvalitet i molnet.
Remote Destkop: Virtuella datorer med NG-familj kan användas för fjärrskrivbordsprogram, vilket ger användarna en dynamisk användarupplevelse av hög kvalitet.
NV-familj
NV-serien av VM-storleksserier är en av Azures GPU-accelererade VM-instanser, särskilt utformade för grafikintensiva program som grafikrendering, simulering och virtuella skrivbord. Utrustade med NVIDIA GPU:er ger virtuella datorer i NV-serien en robust plattform för rendering och bearbetning av grafikintensiva uppgifter, vilket gör dem idealiska för organisationer som kräver virtuella arbetsstationer med kraftfulla grafiska funktioner. De här virtuella datorerna stöder scenarier där fjärrvisualisering, realtidssamarbete och 3D-visualisering är nödvändiga, så att användarna effektivt kan köra grafikintensiva program direkt från Azures molnmiljö.
VDI (Virtual Desktop Infrastructure): VIRTUELLA NV-familjedatorer passar bra för virtuella skrivbord som kräver GPU-funktioner för uppgifter som grafisk design, videoredigering och CAD-program. De ger den grafiska prestanda som krävs för smidig drift i scenarier med fjärrskrivbord.
3D-visualisering: Virtuella NV-familjedatorer är idealiska för att köra 3D-program som kräver rendering med höga prestanda, till exempel arkitektoniska visualiseringar, medicinsk bildbehandling och andra grafikuppgifter av professionell kvalitet.
Fjärrgrafikarbete: Virtuella datorer i NV-serien är fördelaktiga för branscher som förlitar sig på grafikintensiv programvara, vilket gör det möjligt för proffs att komma åt och använda program som Adobe Photoshop, Autodesk AutoCAD eller Dassault SOLIDWORKS på distans med nästan intern prestanda.
Högupplöst bildbearbetning: Virtuella datorer i NV-serien är idealiska för hantering av extremt stora vRAM-program, till exempel högupplöst bildbearbetning och analys. Detta omfattar uppgifter inom områden som geospatial analys, bearbetning av satellitbilder och professionell fotoredigering, där hantering av massiva bildfiler och komplexa manipuleringar i realtid är avgörande för produktivitet och prestanda.
Videoströmning: Virtuella NV-familjedatorer är lämpliga för direktuppspelning av videoinnehåll med hög upplösning, inklusive träningsvideor och virtuella händelser, vilket garanterar leverans av hög kvalitet utan lokala maskinvarubegränsningar.
FPGA accelererade
FPGA-optimerade VM-storlekar är specialiserade virtuella datorer som är tillgängliga med en eller flera FPGA:er. Dessa storlekar är utformade för beräkningsintensiva arbetsbelastningar. Den här artikeln innehåller information om antalet och typen av FPGA:er, vCPU:er, datadiskar och nätverkskort. Lagringsdataflöde och nätverksbandbredd ingår också för varje storlek i den här grupperingen.
Om du vill veta mer om en viss storleksfamilj eller serie klickar du på fliken för den familjen och bläddrar för att hitta önskad storleksserie.
NP-familj
Underfamiljen "NP" för VM-storleksserier är en av Azures lagringsoptimerade VM-instanser. De är utformade för arbetsbelastningar som kräver högt diskdataflöde och I/O, till exempel databaser, stordataprogram och datalager. Högt diskdataflöde och stora lokala disklagringskapaciteter på virtuella datorer i L-serien stöder program och tjänster som drar nytta av låg svarstid och höga sekventiella läs- och skrivhastigheter. Detta gör dem väl lämpade för hantering av uppgifter som storskalig loggbearbetning, stordataanalys i realtid och scenarier som involverar stora databaser som utför frekventa diskåtgärder, vilket säkerställer effektiva prestanda för lagringsintensiva program.
Realtidsdatabearbetning: Virtuella NP-familjedatorer är utmärkta i miljöer där data måste bearbetas i realtid med minimal svarstid, till exempel inom finansiell handel, realtidsanalys och bearbetning av nätverksdata.
Anpassad AI och maskininlärning: Virtuella DATORER i NP-serien är lämpliga för att påskynda AI- och maskininlärningsinferensuppgifter, där FPGA kan programmeras att köra specifika algoritmer ibland snabbare än vanliga CPU- eller GPU-baserade lösningar.
Genomics and Life Sciences: Virtuella NP-familjedatorer kan avsevärt påskynda genomisk sekvensering och andra biovetenskapsprogram som drar nytta av anpassad maskinvaruacceleration.
Videotranskodning och strömning: FPGA:er kan användas för att påskynda videobearbetningsuppgifter som transkodning och videoströmning i realtid, optimera prestanda och minska bearbetningstiderna.
Signalbearbetning: Virtuella NP-familjedatorer är idealiska för tillämpningar inom telekommunikation och signalbearbetning där snabb manipulering och analys av signaler är nödvändiga.
Databasacceleration: Virtuella NP-familjedatorer kan förbättra databasåtgärder, särskilt för anpassade sökåtgärder och storskaliga databasfrågor, genom att avlasta dessa uppgifter till FPGA.
Databehandling med höga prestanda
Virtuella Datorer med Azure High Performance Compute är optimerade för olika HPC-arbetsbelastningar, till exempel beräkningsvätskedynamik, finita elementanalyser, klientdels- och serverdels-EDA, rendering, molekylär dynamik, beräkningsgeovetenskap, vädersimulering och analys av finansiella risker.
Om du vill veta mer om en viss storleksfamilj eller serie klickar du på fliken för den familjen och bläddrar för att hitta önskad storleksserie.
Underfamiljen "HB" för VM-storleksserier är en av Azures HPC-optimerade H-familjens VM-instanser. De är utformade för beräkningsintensiva arbetsbelastningar, till exempel beräkningsströmningsdynamik, finita elementanalyser och storskaliga vetenskapliga simuleringar. Högpresterande AMD EPYC-processorer och snabbt minne på virtuella datorer i HB-serien erbjuder exceptionell processor- och minnesbandbredd, vilket gör dem idealiska för program som kräver omfattande beräkningsresurser för att utföra storskaliga beräkningar och databearbetning. Detta gör dem väl lämpade för branscher som teknik, vetenskaplig forskning och dataanalys där bearbetningshastighet och noggrannhet är avgörande för produktivitet och innovation.
Computational Fluid Dynamics (CFD): Virtuella HB-familjedatorer är idealiska för simuleringar inom områden som flyg, fordonsdesign och tillverkning, där beräkningar av vätskedynamik är intensiva.
Finite Element Analysis (FEA): Virtuella HB-familjedatorer är lämpliga för tekniska analyser som simulerar fysiska fenomen, vilket kräver intensiv beräkningskraft för att modellera komplexa system och material.
Väderprognoser: Virtuella HB-familjedatorer kan hantera de massiva datamängder och komplexa simuleringar som krävs för högupplöst vädermodellering och prognostisering.
Seismisk bearbetning: Används i olje- och gasindustrin och virtuella datorer i HB-familjen kan bearbeta seismiska data för att hjälpa till att kartlägga och förstå strukturer under ytan.
Vetenskaplig forskning: Virtuella HB-familjedatorer stöder ett brett spektrum av vetenskaplig forskning som kräver storskalig matematisk modellering, inklusive simuleringar av fysik och beräkningskemi.
Genomik och bioinformatik: Virtuella datorer med HB-familj används också inom biovetenskap för genomisk analys, där stora mängder data måste bearbetas snabbt för att avkoda genetisk information.
HC-serien med VM-storleksserier är en av Azures HPC-optimerade VM-instanser (databehandling med höga prestanda). De är utformade för beräkningsintensiva arbetsbelastningar som kräver betydande processorkraft, till exempel genomisk sekvensering, tekniska simuleringar och finansiell modellering. Intel Xeon-skalbara processorer med höga prestanda och snabbt minne på virtuella datorer i HC-serien erbjuder exceptionella beräkningsfunktioner och minnesbandbredd, vilket gör dem idealiska för program som kräver intensiv bearbetningskraft för att hantera komplexa beräkningar och massiva datamängder effektivt. Dessa virtuella datorer är utformade för sektorer som sjukvård, ekonomi och teknik, där snabb databehandling och simuleringsprecision är avgörande för avancerad forskning och utveckling.
Genomisk sekvensering: Virtuella datorer i HC-serien ger den beräkningskraft som krävs för genomisk sekvensering, vilket gör det möjligt för forskare att bearbeta och analysera stora genetiska datamängder snabbt.
Tekniska simuleringar: Perfekt för att köra komplexa simuleringar inom områden som fordon, flyg och maskinteknik. Dessa simuleringar omfattar ofta finita elementanalyser (FEA) och cfd (computational fluid dynamics).
Finansiell modellering: Dessa virtuella datorer kan hantera de höga kraven från finansiella program, inklusive riskanalys och kvantitativa simuleringar, som kräver enorma beräkningsresurser för att köra många beräkningar snabbt.
Vetenskaplig forskning: Virtuella datorer i HC-serien stöder en mängd olika vetenskapliga databehandlingsbehov, särskilt inom fysik och kemi, där storskaliga beräkningar och dataanalys är avgörande.
Väderprognoser och klimatsimulering: De används i meteorologi för högupplösta vädermodellering och klimatsimuleringar, vilket kräver bearbetning av stora datamängder och komplexa simuleringar.
HX-serien med VM-storlek är en av Azures HPC-optimerade VM-instanser med höga minne och höga prestanda. De är utformade för minnesintensiva arbetsbelastningar som kräver både stora mängder RAM-minne och betydande CPU-prestanda, till exempel minnesinterna databaser, stordataanalys och komplexa vetenskapliga simuleringar. Omfattande minne och kraftfulla processorer på virtuella datorer i HX-serien ger de resurser som krävs för att effektivt hantera stora datamängder och utföra snabb databearbetning. Dessa virtuella datorer är utformade för sektorer som finansiella tjänster, vetenskaplig forskning och resursplanering för företag, där hantering och analys av stora mängder data i realtid är avgörande för driftsframgång och innovation.
Minnesinterna databaser: Virtuella datorer i HX-serien är utmärkta för att hantera minnesinterna databaser, vilket kräver omfattande minne för att underhålla stora datamängder i RAM-minnet för ultrasnabb bearbetning och åtkomst.
Stordataanalys: De kan hantera stordataanalysprogram som behöver bearbeta stora mängder data i minnet för att påskynda analysen, vilket är viktigt för beslutsfattande i realtid.
Genomisk forskning: Genomikforskning omfattar ofta storskalig dataanalys, där hög minneskapacitet avsevärt kan förbättra prestanda genom att tillåta att mer av datamängden lagras i minnet, vilket påskyndar analysen.
Finansiella simuleringar: Finansinstitut använder virtuella datorer i HX-serien för högfrekventa handelsplattformar och riskhanteringssimuleringar som kräver snabb bearbetning av stora datavolymer för att förutsäga aktietrender eller beräkna kreditrisker i realtid.
ERP-system: Erp-system (Large Enterprise Resource Planning) drar nytta av den höga minnes- och bearbetningskraften hos virtuella datorer i HX-serien för att hantera och bearbeta omfattande företagsdata och stödja ett stort antal samtidiga användare effektivt.
Lär dig innehållet i plattformsstorlekar
Information om priser för de olika storlekarna finns på prissidorna för Linux eller Windows.

 1 De flesta familjer representeras med en bokstav, men andra som GPU-storlekar (
1 De flesta familjer representeras med en bokstav, men andra som GPU-storlekar (