Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Med distributionsprocessen kan du klona innehåll från en fas i distributionspipelinen till en annan, vanligtvis från utveckling till test och från test till produktion.
Under distributionen kopierar Microsoft Fabric innehållet från källfasen till målfasen. Anslutningarna mellan de kopierade objekten behålls under kopieringsprocessen. Fabric tillämpar också de konfigurerade distributionsreglerna på det uppdaterade innehållet i målfasen. Det kan ta en stund att distribuera innehåll, beroende på hur många objekt som distribueras. Under den här tiden kan du navigera till andra sidor i portalen, men du kan inte använda innehållet i målfasen.
Du kan också distribuera innehåll programmatiskt med hjälp av REST API:er för distributionspipelines. Du kan lära dig mer om den här processen i Automatisera din distributionspipeline med hjälp av API:er och DevOps.
Anteckning
Det nya användargränssnittet för distributionspipelinen finns för närvarande i förhandsversion. Om du vill aktivera eller använda det nya användargränssnittet kan du läsa Börja använda det nya användargränssnittet.
Det finns två huvuddelar av distributionspipelinesprocessen:
Definiera distributionspipelinestrukturen
När du skapar en pipeline definierar du hur många steg du vill ha och vad de ska anropas. Du kan också göra en eller flera steg offentliga. Antalet steg och deras namn är permanenta och kan inte ändras när pipelinen har skapats. Du kan dock ändra den offentliga statusen för en fas när som helst.
Om du vill definiera en pipeline följer du anvisningarna i Skapa en distributionspipeline.
Lägga till innehåll i faserna
Du kan lägga till innehåll i en pipelinefas på två sätt:
Tilldela en arbetsyta till en tom scen
När du tilldelar innehåll till en tom scen, skapas en ny arbetsyta på en kapacitet för den scen som du distribuerar till. Alla metadata i rapporter, instrumentpaneler och semantiska modeller för den ursprungliga arbetsytan kopieras till den nya arbetsytan i den fas som du distribuerar till.
När distributionen är klar uppdaterar du de semantiska modellerna så att du kan använda det nyligen kopierade innehållet. Den semantiska modelluppdateringen krävs eftersom data inte kopieras från en fas till en annan. Om du vill veta vilka objektegenskaper som kopieras under distributionsprocessen och vilka objektegenskaper som inte kopieras läser du objektegenskaperna som kopierades under distributionsavsnittet .
Anvisningar om hur du tilldelar och avtilldelar arbetsytor till distributionspipelinesteg finns i Tilldela en arbetsyta till en Distributionspipeline för Microsoft Fabric.
Skapa en arbetsyta
Första gången du distribuerar innehåll kontrollerar distributionspipelines om du har behörighet.
Om du har behörighet kopieras innehållet i arbetsytan till den fas som du distribuerar till, och en ny arbetsyta för den fasen skapas på kapaciteten.
Om du inte har behörighet skapas arbetsytan men innehållet kopieras inte. Du kan be en kapacitetsadministratör att lägga till din arbetsyta i en kapacitet eller be om tilldelningsbehörigheter för kapaciteten. Senare, när arbetsytan har tilldelats till en kapacitet, kan du distribuera innehåll till den här arbetsytan.
Om du använder Premium per användare (PPU) associeras din arbetsyta automatiskt med din PPU. I sådana fall krävs inte behörigheter. Men om du skapar en arbetsyta med en PPU kan endast andra PPU-användare komma åt den. Dessutom kan endast PPU-användare använda innehåll som skapats på sådana arbetsytor.
Ägarskap för arbetsyta och innehåll
Den distribuerande användaren blir automatiskt ägare till de klonade semantiska modellerna och den enda administratören för den nya arbetsytan.
Distribuera innehåll från en fas till en annan
Det finns flera sätt att distribuera innehåll från en fas till en annan. Du kan distribuera allt innehåll eller välja vilka objekt som ska distribueras.
Du kan distribuera innehåll till valfri angränsande fas i båda riktningarna.
Distribution av innehåll från en fungerande produktionspipeline till en fas som har en befintlig arbetsyta innehåller följande steg:
Distribuera nytt innehåll som ett tillägg till innehållet som redan finns där.
Distribuera uppdaterat innehåll för att ersätta en del av innehållet som redan finns där.
Distributionsprocess
När innehåll från källsteget kopieras till målfasen identifierar Fabric befintligt innehåll i målfasen och skriver över det. För att identifiera vilket innehållsobjekt som måste skrivas över använder distributionspipelines anslutningen mellan det överordnade objektet och dess kloner. Den här anslutningen behålls när nytt innehåll skapas. Överskrivningsåtgärden skriver bara över innehållet i objektet. Objektets ID, URL och behörigheter förblir oförändrade.
I målfasen förblir objektegenskaper som inte kopieras som de var före distributionen. Nytt innehåll och nya objekt kopieras från källsteget till målfasen.
Automatisk bindning
När objekten är anslutna i Infrastruktur är ett av objekten beroende av det andra. En rapport beror till exempel alltid på den semantiska modell som är ansluten till den. En semantisk modell kan vara beroende av en annan semantisk modell och kan också anslutas till flera rapporter som är beroende av den. Om det finns en anslutning mellan två objekt försöker distributionspipelines alltid underhålla den här anslutningen.
Automatiskbindning på samma arbetsyta
Under driftsättningen kontrollerar distributionspipeline beroenden. Distributionen lyckas eller misslyckas, beroende på platsen för objektet som tillhandahåller de data som det distribuerade objektet är beroende av.
Det finns ett länkat objekt i målfasen – Distributionspipelines ansluter automatiskt (autobind) det distribuerade objektet till det objekt det är beroende av i det distribuerade stadiet. Om du till exempel distribuerar en sidnumrerad rapport från utveckling till test, och rapporten är ansluten till en semantisk modell som tidigare distribuerades till testfasen, ansluter den automatiskt till den semantiska modellen i testfasen.
Länkat objekt finns inte i målfasen – Distributionspipelines misslyckas med en distribution om ett objekt har ett beroende av ett annat objekt och objektet som tillhandahåller data inte distribueras och inte finns i målfasen. Om du till exempel distribuerar en rapport från utveckling till test och teststeget inte innehåller dess semantiska modell misslyckas distributionen. Om du vill undvika misslyckade distributioner på grund av att beroende objekt inte distribueras använder du knappen Välj relaterad . Välj relaterade väljer automatiskt alla relaterade objekt som ger beroenden till de objekt som du ska distribuera.
Automatisk bindning fungerar endast med objekt som stöds av distributionspipelines och som finns inom Fabric. Om du vill visa beroenden för ett objekt går du till menyn Fler alternativ och väljer Visa ursprung.
Automatisk bindning mellan arbetsytor
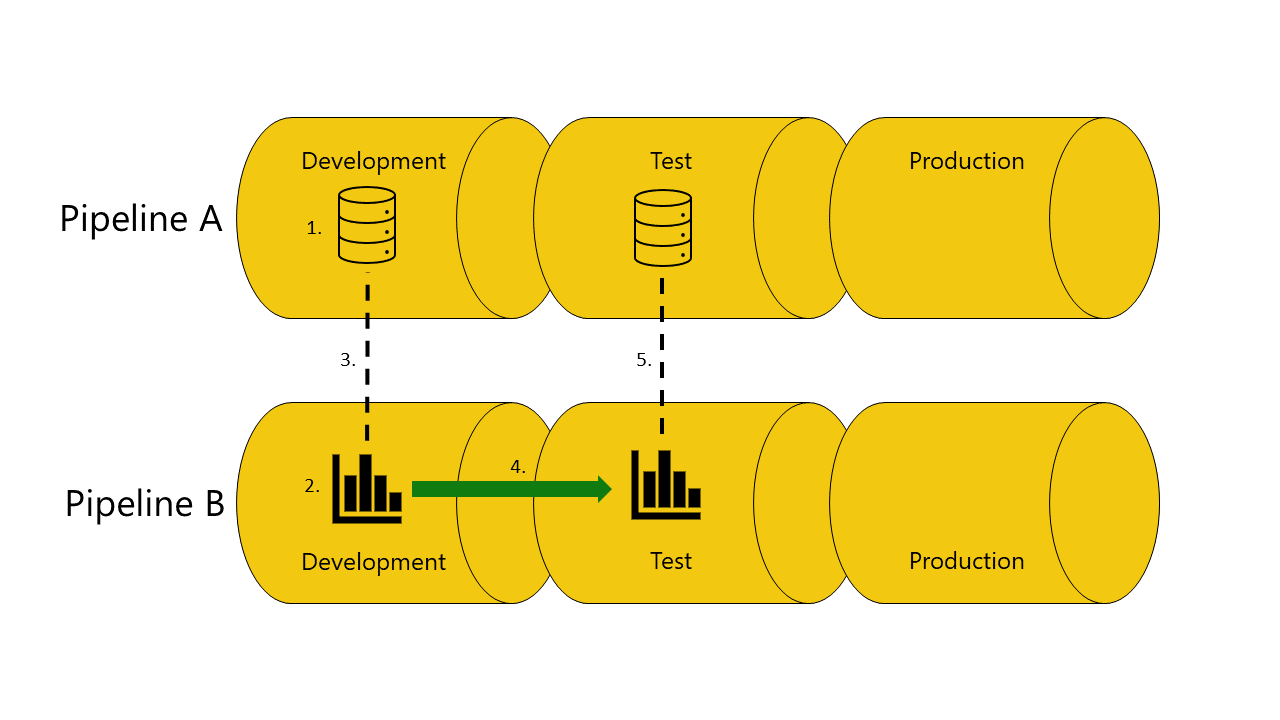
Distributionspipelines binder automatiskt objekt som är anslutna mellan pipelines, om de befinner sig i samma pipelinesteg. När du distribuerar sådana objekt försöker distributionspipelines upprätta en ny anslutning mellan det distribuerade objektet och objektet som är anslutet till det i den andra pipelinen. Om du till exempel har en rapport i testfasen av pipeline A som är ansluten till en semantisk modell i testfasen av pipeline B, identifierar distributionspipelines den här anslutningen.
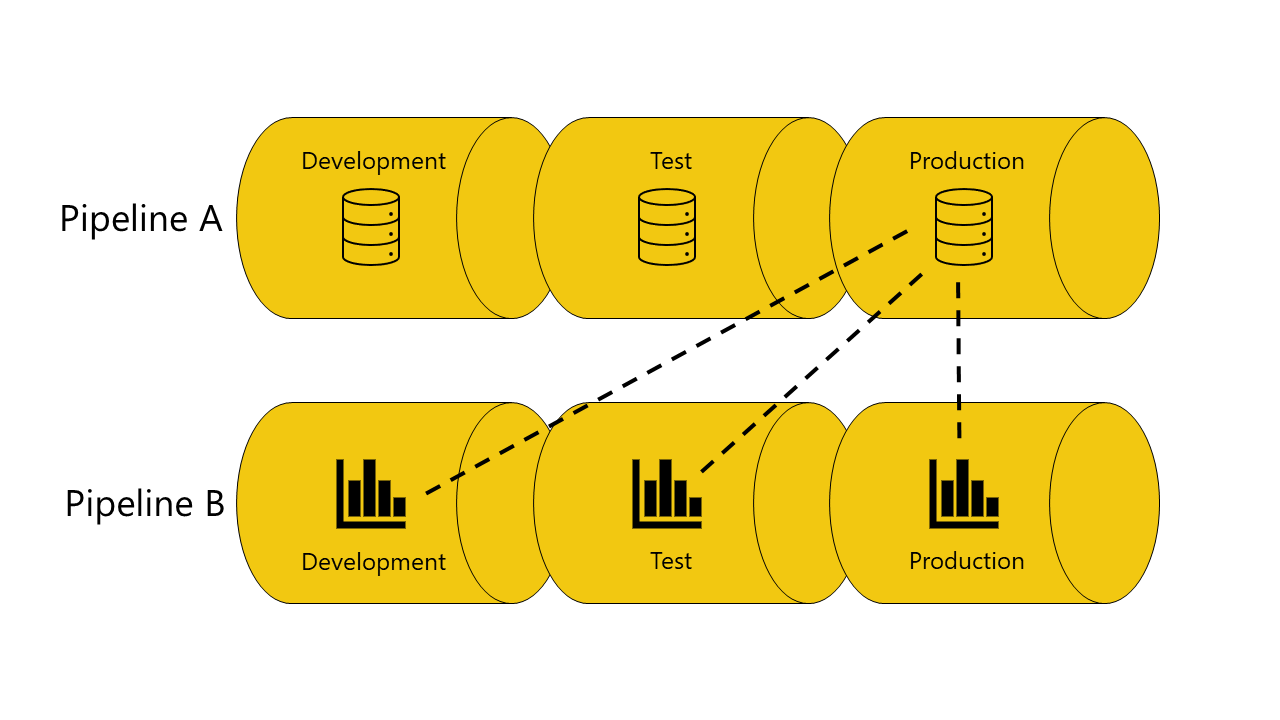
Här är ett exempel med illustrationer som visar hur automatisk bindning mellan pipelines fungerar:
Du har en semantisk modell i utvecklingsfasen av pipeline A.
Du har också en rapport i utvecklingsfasen av pipeline B.
Rapporten i pipeline B är ansluten till din semantiska modell i pipeline A. Rapporten är beroende av den här semantiska modellen.
Du distribuerar rapporten i pipeline B från utvecklingsfasen till testfasen.
Distribueringen lyckas eller misslyckas, beroende på om du har en kopia av den semantiska modellen som den är beroende av i teststadiet av pipeline A.
Om du har en kopia av den semantiska modellen som rapporten är beroende av i testfasen av pipeline A:
Distribueringen lyckas och distributionspipelines ansluter (autobindning) rapporten i testfasen av pipeline B till den semantiska modellen i testfasen av pipeline A.
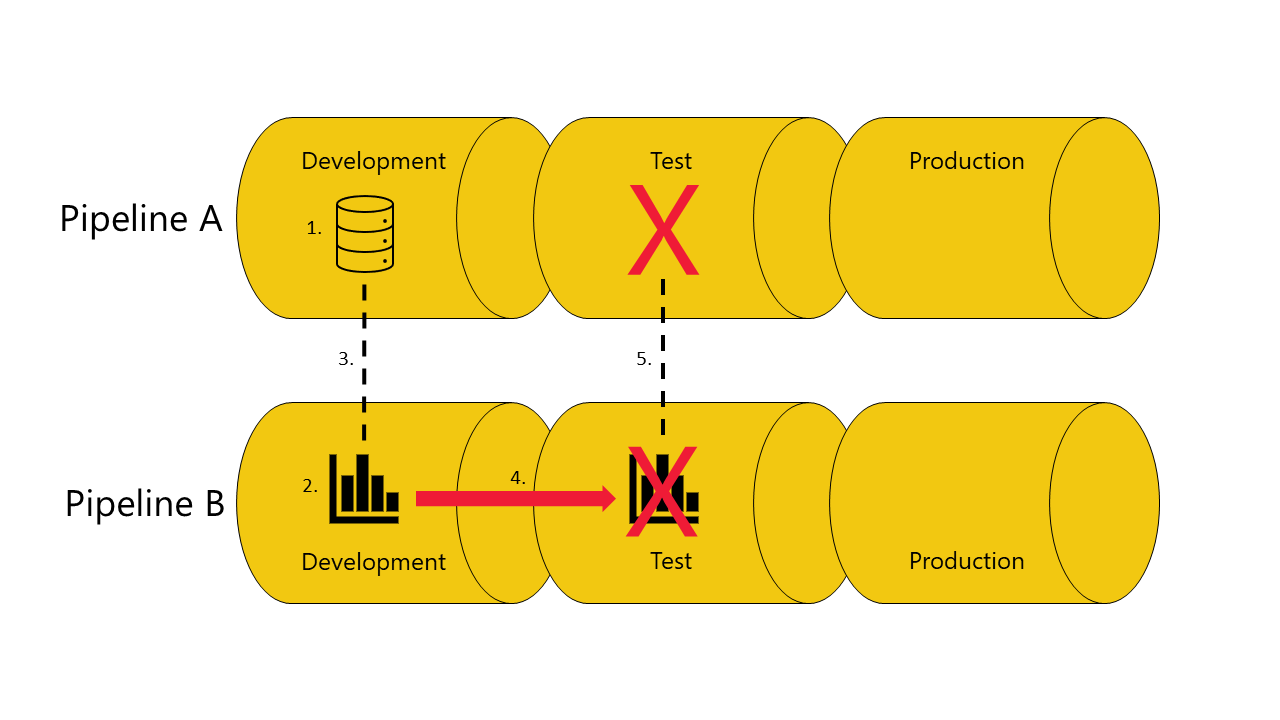
Om du inte har en kopia av den semantiska modellen, som rapporten är beroende av, i testfasen av pipeline A:
Distributionen misslyckas eftersom distributionspipelines inte kan ansluta (automatisktbinda) rapporten i testfasen i pipeline B, till den semantiska modell som den är beroende av i testfasen av pipeline A.
Undvik att använda automatisk bindning
I vissa fall kanske du inte vill använda automatisk bindning. Om du till exempel har en pipeline för att utveckla organisationens semantiska modeller och en annan för att skapa rapporter. I det här fallet kanske du vill att alla rapporter alltid ska vara anslutna till semantiska modeller i produktionsfasen av pipelinen som de tillhör. I det här fallet bör du undvika att använda funktionen för automatisk bindning.
Det finns tre metoder som du kan använda för att undvika automatisk bindning:
Anslut inte objektet till motsvarande faser. När objekten inte är anslutna i samma fas, behåller distributionspipeline den ursprungliga anslutningen. Om du till exempel har en rapport i utvecklingsfasen i pipeline B som är ansluten till en semantisk modell i produktionsfasen av pipeline A. När du distribuerar rapporten till teststeget i pipeline B förblir den ansluten till den semantiska modellen i produktionsfasen av pipeline A.
Definiera en parameterregel. Det här alternativet är inte tillgängligt för rapporter. Du kan bara använda den med semantiska modeller och dataflöden.
Anslut dina rapporter, instrumentpaneler och brickor till en proxysemantisk modell eller ett dataflöde som inte är anslutet till en pipeline.
Automatisk bindning och parametrar
Parametrar kan användas för att styra anslutningarna mellan semantiska modeller eller dataflöden och de objekt som de är beroende av. När en parameter styr anslutningen sker inte automatisk bindning efter distributionen, även om anslutningen innehåller en parameter som gäller för semantikmodellens eller dataflödets ID eller arbetsyte-ID. I dessa fall ombindde du objekten efter distributionen genom att ändra parametervärdet eller med hjälp av parameterregler.
Anteckning
Om du använder parameterregler för att ombinda objekt måste parametrarna vara av typen Text.
Uppdatera data
Data i målobjektet, till exempel en semantisk modell eller dataflöde, sparas när det är möjligt. Om det inte finns några ändringar i ett objekt som innehåller data sparas data som de var före distributionen.
I många fall, när du har en liten ändring som att lägga till eller ta bort en tabell, behåller Fabric de ursprungliga data. För schemaändringar som bryter kompatibiliteten eller ändringar i datakällans koppling krävs en fullständig uppfräschning.
Krav för att distribuera till en fas med en befintlig arbetsyta
Alla licensierade användare som är deltagare i både mål- och källdistributionsarbetsytor kan distribuera innehåll som finns på en kapacitet till en fas med en befintlig arbetsyta. Mer information finns i avsnittet behörigheter .
Mappar i distributionspipelines (förhandsversion)
Med mappar kan användarna effektivt organisera och hantera arbetsyteobjekt på ett välbekant sätt. När du distribuerar innehåll som innehåller mappar till en annan fas tillämpas mapphierarkin för de tillämpade objekten automatiskt.
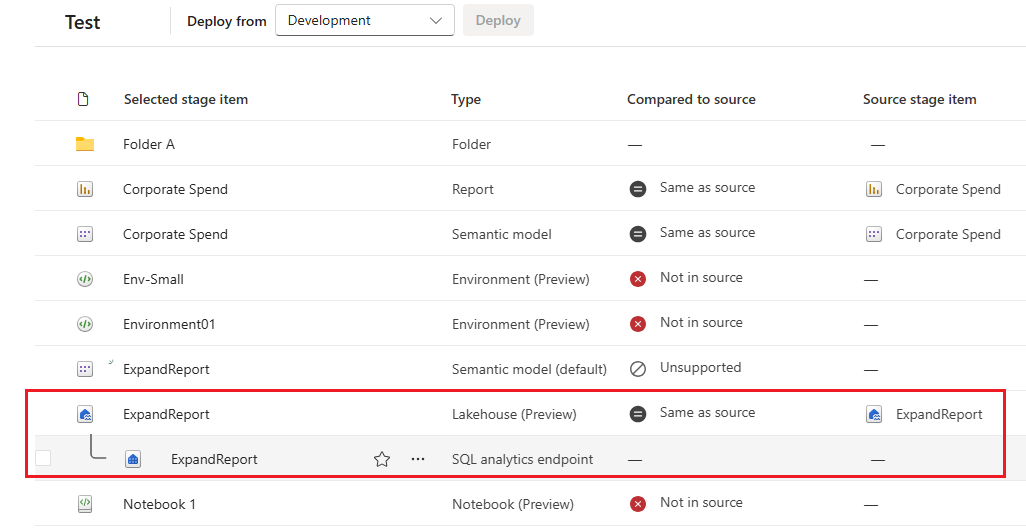
Mapprepresentation
Innehållet i arbetsytan visas enligt dess struktur. Mappar visas och för att kunna se deras objekt måste du välja mappen. Ett objekts fullständiga sökväg visas överst i objektlistan. Eftersom en distribution endast är av objekt kan du bara välja en mapp som innehåller objekt som stöds. Att välja en mapp för distribution innebär att välja alla dess objekt och undermappar med sina objekt för en distribution.
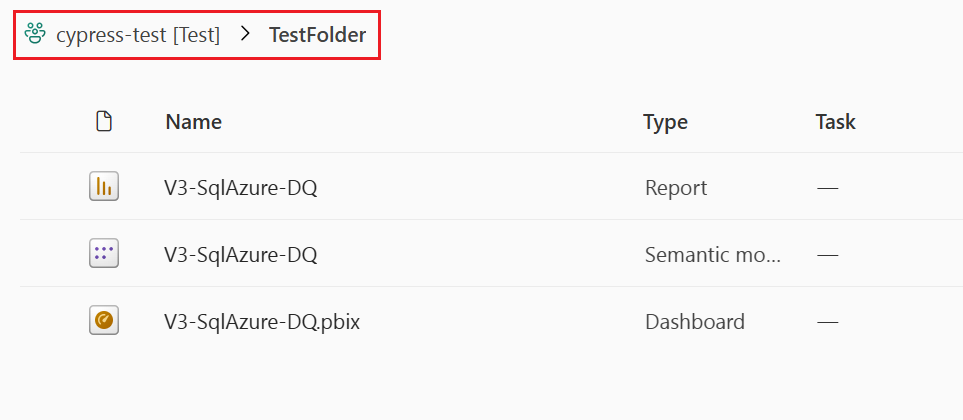
Den här bilden visar innehållet i en mapp i arbetsytan. Mappens fullständiga sökväg visas längst upp i listan.
I Distributionspipelines betraktas mappar som en del av ett objekts namn (ett objektnamn innehåller dess fullständiga sökväg). När ett objekt distribueras, efter att dess sökväg har ändrats (till exempel flyttats från mapp A till mapp B), tillämpar distributionspipelines den här ändringen på dess kopplade objekt under distributionen . Det kopplade objektet flyttas också till mapp B. Om mapp B inte finns i den fas som vi distribuerar till skapas den först i arbetsytan. Mappar kan endast visas och hanteras på arbetsytans sida.
Distribuera objekt i en mapp från den mappen. Du kan inte distribuera objekt från olika hierarkier samtidigt.
Identifiera objekt som har flyttats till olika mappar
Eftersom mappar anses vara en del av objektets namn identifieras objekt som har flyttats till en annan mapp i arbetsytan som Olika när de jämförs på sidan Distributionspipelines. Det här objektet visas inte i jämförelsefönstret eftersom det inte är en schemaändring, men inställningarna ändras.
- Flyttat mappobjekt i nytt användargränssnitt
- Flyttat mappobjekt i det ursprungliga användargränssnittet

Enskilda mappar kan inte distribueras manuellt i distributionspipelines. Deras distribution utlöses automatiskt när minst ett av objekten distribueras.
Mapphierarkin för kopplade objekt uppdateras endast under distributionen. Under tilldelningen, efter parkopplingsprocessen, uppdateras inte hierarkin för kopplade objekt ännu.
Eftersom en mapp endast distribueras om ett av objekten distribueras kan en tom mapp inte distribueras.
När du distribuerar ett objekt av flera i en mapp uppdateras också strukturen för de objekt som inte distribueras i målfasen även om själva objekten inte distribueras.
Representation av förälder-barn-element
Parent Child-relationer visas bara i det nya användargränssnittet. De ser likadana ut som på arbetsytan. Barnet distribueras inte utan återskapas på målscenen.
Objektegenskaper som kopierades under distributionen
En lista över objekt som stöds finns i Distributionspipeline, stödde objekt.
Under distributionen kopieras följande objektegenskaper och skriver över objektegenskaperna i målfasen:
Datakällor (distributionsregler stöds)
Parametrar (distributionsregler stöds)
Rapportvisualiseringar
Rapportsidor
Dashboard-ikoner
Modellmetadata
Objektrelationer
Känslighetsetiketter kopieras endast när något av följande villkor uppfylls. Om dessa villkor inte uppfylls kopieras inte känslighetsetiketter under distributionen.
Ett nytt objekt distribueras eller så distribueras ett befintligt objekt till en tom fas.
Anteckning
Om standardetiketter är aktiverade i klientorganisationen och standardetiketten är giltig, och om det objekt som distribueras är en semantisk modell eller ett dataflöde, kopieras etiketten från källobjektet endast om etiketten har skydd. Om etiketten inte är skyddad tillämpas standardetiketten på den nyligen skapade målsemantikmodellen eller dataflödet.
Källobjektet har en etikett med skydd och målobjektet har inte det. I det här fallet ber ett popup-fönster om medgivande för att åsidosätta målkänslighetsetiketten.
Objektegenskaper som inte kopieras
Följande objektegenskaper kopieras inte under distributionen:
Data – Data kopieras inte. Det är endast metadata som kopieras
webbadress
ID
Behörigheter – för en arbetsyta eller ett specifikt objekt
Inställningar för arbetsyta – Varje fas har en egen arbetsyta
Appinnehåll och inställningar – Information om hur du uppdaterar dina appar finns i Uppdatera innehåll till Power BI-appar
Följande semantiska modellegenskaper kopieras inte heller under distributionen:
Rolltilldelning
Uppdatera schema
Autentiseringsuppgifter för datakälla
Inställningar för cachelagring av frågor (kan ärvas från kapaciteten)
Inställningar för godkännande
Semantiska modellfunktioner som stöds
Distributionspipelines stöder många semantiska modellfunktioner. Det här avsnittet innehåller två semantiska modellfunktioner som kan förbättra upplevelsen med distributionsrörledningarna.
Inkrementell uppdatering
Distributionspipelines stöder inkrementell uppdatering, en funktion som möjliggör stora semantiska modeller snabbare och mer tillförlitliga uppdateringar, med lägre förbrukning.
Med distributionspipelines kan du göra uppdateringar av en semantisk modell med inkrementell uppdatering samtidigt som du behåller både data och partitioner. När du distribuerar den semantiska modellen kopieras policyn.
Om du vill förstå hur inkrementell uppdatering fungerar med dataflöden kan du se varför jag ser två datakällor som är anslutna till mitt dataflöde när jag har använt dataflödesregler?
Anteckning
Inkrementella uppdateringsinställningar kopieras inte i Gen 1.
Aktivera inkrementell uppdatering i en pipeline
Om du vill aktivera inkrementell uppdatering konfigurerar du den i Power BI Desktop och publicerar sedan din semantiska modell. När du har publicerat är principen för inkrementell uppdatering liknande i pipelinen och kan endast redigeras i Power BI Desktop.
När din pipeline har konfigurerats med inkrementell uppdatering rekommenderar vi att du använder följande flöde:
Gör ändringar i .pbix-filen i Power BI Desktop. För att undvika långa väntetider kan du göra ändringar med hjälp av ett exempel på dina data.
Ladda upp .pbix-filen till den första (vanligtvis utvecklingsfasen).
Distribuera ditt innehåll till nästa steg. Efter distributionen gäller de ändringar som du har gjort för hela den semantiska modell som du använder.
Granska de ändringar du gjorde i varje steg och när du har verifierat dem distribuerar du till nästa steg tills du kommer till den sista fasen.
Exempel på användning
Följande är några exempel på hur du kan integrera inkrementell uppdatering med distributionspipelines.
Skapa en ny pipeline och anslut den till en arbetsyta med en semantisk modell som har inkrementell uppdatering aktiverad.
Aktivera inkrementell uppdatering i en semantisk modell som redan finns på en utvecklingsarbetsyta .
Skapa en pipeline från en produktionsarbetsyta som har en semantisk modell som använder inkrementell uppdatering. Du kan till exempel tilldela arbetsytan till en ny pipelines produktionssteg och använda bakåtdistribution för att distribuera till testfasen och sedan till utvecklingssteget.
Publicera en semantisk modell som använder inkrementell uppdatering till en arbetsyta som ingår i en befintlig pipeline.
Begränsningar för inkrementell uppdatering
För inkrementell uppdatering stöder distributionspipelines endast semantiska modeller som använder förbättrade semantiska modellmetadata. Alla semantiska modeller som skapats eller ändrats med Power BI Desktop implementerar automatiskt förbättrade semantiska modellmetadata.
När du publicerar om en semantisk modell till en aktiv pipeline med inkrementell uppdatering aktiverad resulterar följande ändringar i distributionsfel på grund av dataförlustpotential:
Publicera om en semantisk modell som inte använder inkrementell uppdatering för att ersätta en semantisk modell som har inkrementell uppdatering aktiverad.
Byta namn på en tabell som har inkrementell uppdatering aktiverad.
Byta namn på icke-beräknade kolumner i en tabell med inkrementell uppdatering aktiverad.
Andra ändringar som att lägga till en kolumn, ta bort en kolumn och byta namn på en beräknad kolumn tillåts. Men om ändringarna påverkar visningen måste du uppdatera innan ändringen visas.
Sammansatta modeller
Med hjälp av sammansatta modeller kan du konfigurera en rapport med flera dataanslutningar.
Du kan använda funktionen sammansatta modeller för att ansluta en fabric-semantisk modell till en extern semantisk modell, till exempel Azure Analysis Services. Mer information finns i Använda DirectQuery för Fabric-semantiska modeller och Azure Analysis Services.
I en distributionspipeline kan du använda sammansatta modeller för att ansluta en semantisk modell till en annan fabric-semantisk modell utanför pipelinen.
Automatiska aggregeringar
Automatiska aggregeringar bygger på användardefinierade aggregeringar och använder maskininlärning för att kontinuerligt optimera DirectQuery-semantiska modeller för maximal rapportfrågeprestanda.
Varje semantisk modell behåller sina automatiska aggregeringar efter distributionen. Distributionspipelines ändrar inte en semantisk modells automatiska aggregering. Det innebär att om du distribuerar en semantisk modell med en automatisk aggregering förblir den automatiska aggregeringen i målfasen som den är och skrivs inte över av den automatiska aggregering som distribueras från källfasen.
Om du vill aktivera automatiska aggregeringar följer du anvisningarna i konfigurera den automatiska aggregeringen.
Hybridtabeller
Hybridtabeller är tabeller med inkrementell uppdatering som kan ha både import- och direktfrågepartitioner. Vid en ren driftsättning kopieras både uppdateringsprincipen och hybridtabellpartitionerna. När du distribuerar till en etapp i en pipeline som redan har hybridtabellpartitioner kopieras endast uppdateringspolicyn. Uppdatera tabellen om du vill uppdatera partitionerna.
Uppdatera innehåll till Power BI-appar
Power BI-appar är det rekommenderade sättet att distribuera innehåll till kostnadsfria Fabric-konsumenter. Du kan uppdatera innehållet i dina Power BI-appar med hjälp av en distributionspipeline, vilket ger dig mer kontroll och flexibilitet när det gäller appens livscykel.
Skapa en app för varje distributionspipelinesteg så att du kan testa varje uppdatering från slutanvändarens synvinkel. Använd knappen publicera eller visa i kortet i arbetsytan för att publicera eller visa appen i ett specifikt steg i pipeline.
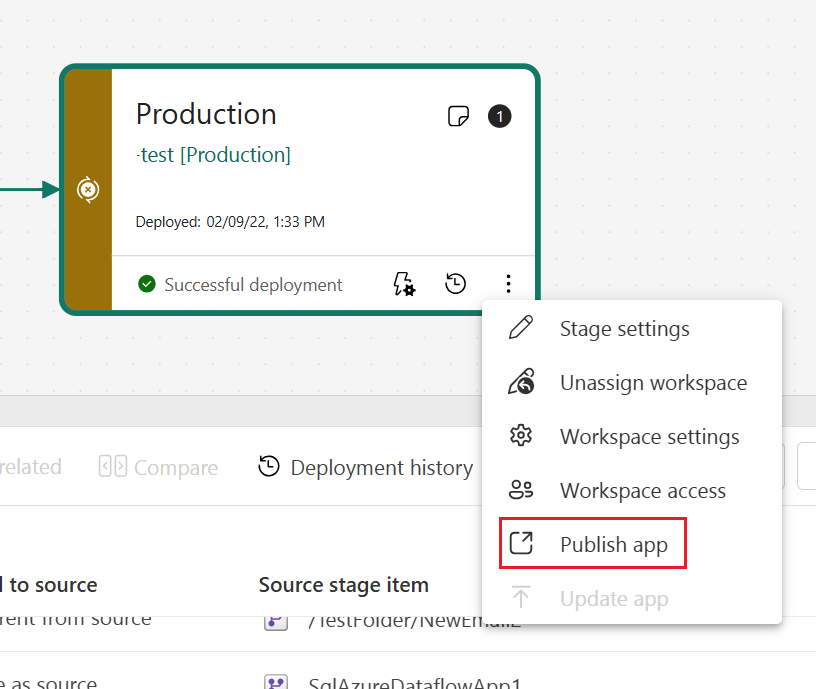

I produktionsfasen kan du även uppdatera appsidan i Infrastrukturresurser så att alla innehållsuppdateringar blir tillgängliga för appanvändare.
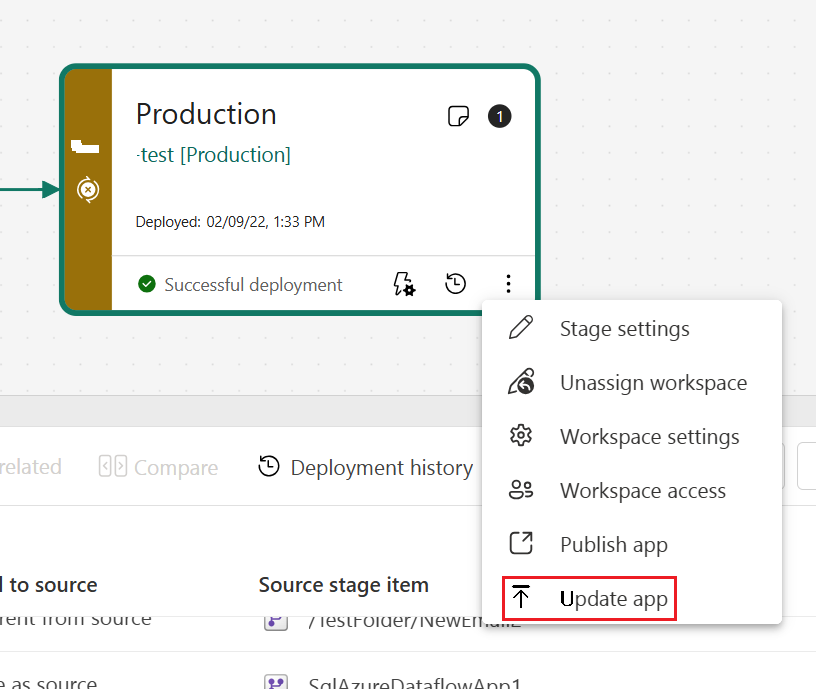

Viktigt!
Distributionsprocessen omfattar inte uppdatering av appens innehåll eller inställningar. Om du vill tillämpa ändringar på innehåll eller inställningar måste du uppdatera appen manuellt i den pipelinefas som krävs.
Behörigheter
Behörigheter krävs för pipelinen och för de arbetsytor som har tilldelats den. Pipelinebehörigheter och arbetsytebehörigheter beviljas och hanteras separat.
Pipelines har bara en behörighet, Administratör, som krävs för delning, redigering och borttagning av en pipeline.
Arbetsytor har olika behörigheter, även kallade roller. Arbetsroller bestämmer åtkomstnivån till en arbetsyta i en pipeline.
Distributionspipelines stöder inte Microsoft 365-grupper som pipelineadministratörer.
För att distribuera från ett steg till ett annat i pipelinen måste du vara pipelineadministratör och dessutom antingen deltagare, medlem eller administratör för de arbetsytor som tilldelats de berörda stegen. Till exempel kan en pipelineadministratör som inte har tilldelats en arbetsyteroll visa pipelinen och dela den med andra. Den här användaren kan dock inte visa innehållet på arbetsytan i pipelinen eller i tjänsten och kan inte utföra distributioner.
Tabell med behörigheter
I det här avsnittet beskrivs behörigheterna för distributionspipelinen. Behörigheterna som anges i det här avsnittet kan ha olika tillämpningar i andra Fabric-funktioner.
Den lägsta behörigheten för distributionspipeline är pipelineadministratör och krävs för alla distributionspipelineåtgärder.
| Användare | Pipelinebehörigheter | Kommentarer |
|---|---|---|
| Pipelineadministratör |
|
Pipelineåtkomst ger inte behörighet att visa eller vidta åtgärder gällande arbetsytans innehåll. |
|
Visningsprogram för arbetsyta (och pipelineadministratör) |
|
Arbetsytemedlemmar som tilldelats rollen Läsare utan byggbehörighet kan inte komma åt den semantiska modellen eller redigera arbetsyteinnehåll. |
|
Arbetsytedeltagare (och pipelineadministratör) |
|
|
|
Medlem i arbetsområde (och pipelineadministratör) |
|
Om inställningen blockera ompublicering och inaktivera paketuppdatering som finns i säkerhetsavsnittet för klientorganisationssemantisk modell är aktiverad kan endast semantiska modellägare uppdatera semantiska modeller. |
|
Arbetsyteadministratör (och pipelineadministratör) |
|
Beviljade behörigheter
När du distribuerar Power BI-objekt kan ägarskapet för det distribuerade objektet ändras. Granska följande tabell för att förstå vem som kan distribuera varje objekt och hur distributionen påverkar objektets ägarskap.
| Tygföremål | Nödvändig behörighet för att distribuera ett befintligt objekt | Objektägarskap efter en första utplacering | Objektägarskap efter distribution till en fas tillsammans med objektet |
|---|---|---|---|
| Semantisk modell | Arbetsytans medlem | Användaren som gjorde distributionen blir ägare | Oförändrad |
| Dataflöde | Dataflödesägare | Användaren som gjorde distributionen blir ägare | Oförändrad |
| Datamart | Datamart-ägare | Användaren som gjorde distributionen blir ägare | Oförändrad |
| Sidnumrerad rapport | Arbetsytans medlem | Användaren som gjorde distributionen blir ägare | Användaren som gjorde distributionen blir ägare |
Nödvändiga behörigheter för populära åtgärder
I följande tabell visas de behörigheter som krävs för populära distributionspipelineåtgärder. Om inget annat anges behöver du alla angivna behörigheter för varje åtgärd.
| Åtgärd | Behörigheter som krävs |
|---|---|
| Visa listan över pipelines i din organisation | Ingen licens krävs (kostnadsfri användare) |
| Skapa en pipeline | En användare med någon av följande licenser:
|
| Ta bort en pipeline | Pipelineansvarig |
| Lägga till eller ta bort en pipelineanvändare | Pipelineansvarig |
| Tilldela en arbetsyta till en fas |
|
| Ta bort tilldelningen av en arbetsyta till en fas | En av följande roller:
|
| Distribuera till en tom scen (se anmärkning) |
|
| Distribuera objekt till nästa steg (se anmärkning) |
|
| Visa eller ange en regel |
|
| Hantera pipelineinställningar | Pipelineansvarig |
| Visa en pipelinefas |
|
| Visa listan över objekt i en fas | Pipelineansvarig |
| Jämför två faser |
|
| Visa utplaceringshistorik | Pipelineansvarig |
Anteckning
Om du vill distribuera innehåll i GCC-miljön måste du vara minst medlem i både käll- och målarbetsytan. Implementering som deltagare stöds inte ännu.
Beaktanden och begränsningar
I det här avsnittet visas de flesta begränsningarna i distributionspipelines.
- Arbetsytan måste vara på en Fabric-kapacitet.
- Det maximala antalet objekt som kan distribueras i en enskild distribution är 300.
- Det går inte att ladda ned en .pbix-fil efter distributionen.
- Microsoft 365-grupper stöds inte som pipelineadministratörer.
- Om ett annat objekt i målfasen har samma namn och typ (till exempel om båda filerna är rapporter) misslyckas distributionen när du distribuerar ett Power BI-objekt för första gången.
- En lista över begränsningar för arbetsytor finns i begränsningarna för tilldelning av arbetsytor.
- En lista över objekt som stöds finns i objekt som stöds. Alla objekt som inte finns i listan stöds inte.
- Distributionen misslyckas om något av objekten har cirkulära eller självberoenden (till exempel objekt A refererar till objekt B och objekt B refererar till objekt A).
- PBIR-rapporter stöds inte.
Begränsningar för semantisk modell
Datauppsättningar som använder dataanslutning i realtid kan inte distribueras.
En semantisk modell med DirectQuery eller sammansatt anslutningsläge som använder variant- eller automatiska datum-/tidstabeller stöds inte. Mer information finns i Vad kan jag göra om jag har en datauppsättning med DirectQuery eller sammansatt anslutningsläge, som använder variant- eller kalendertabeller?.
Om målsemantikmodellen använder en live-anslutning under distributionen måste även källsemantikmodellen använda det här anslutningsläget.
Efter distributionen stöds inte nedladdning av en semantisk modell (från den fas som den distribuerades till).
En lista över begränsningar för distributionsregeln finns i begränsningar för distributionsregler.
Om automatisk bindning är aktiverat:
- Inbyggd fråga och DirectQuery tillsammans stöds inte. Detta omfattar proxydatauppsättningar.
- Datakällans anslutning måste vara det första steget i kombinationsuttrycket.
När en Direct Lake-semantisk modell distribueras binder den inte automatiskt till objekt i målfasen. Om en LakeHouse till exempel är en källa för en DirectLake-semantisk modell och båda distribueras till nästa steg, kommer DirectLake-semantikmodellen i målfasen fortfarande att vara bunden till LakeHouse i källsteget. Använd datakällans regler för att binda den till ett objekt i målfasen. Andra typer av semantiska modeller binds automatiskt till det kopplade objektet i målsteget.
Dataflödesbegränsningar
Inkrementella uppdateringsinställningar kopieras inte i Gen 1.
När du distribuerar ett dataflöde till en tom fas skapar distributionsrörledningar en ny arbetsyta och ställer in dataflödeslagringen till en Fabric lagring. Blob storage används även om källarbetsytan är konfigurerad för att använda Azure Data Lake Storage Gen2 (ADLS Gen2).
Serviceprincipal stöds inte för dataflöden.
Implementering av common data model (CDM) stöds inte.
Information om begränsningar för distributionspipelines som påverkar dataflöden finns i Begränsningar för distributionsregler.
Om ett dataflöde uppdateras under distributionen misslyckas distributionen.
Om du jämför faser under en dataflödesuppdatering är resultatet oförutsägbart.
Automatisk bindning stöds inte för dataflöden Gen2.
Begränsningar för datamart
Du kan inte distribuera ett datamart med känslighetsetiketter.
Du måste vara datamart-ägare för att distribuera en datamart.