หมายเหตุ
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลอง ลงชื่อเข้าใช้หรือเปลี่ยนไดเรกทอรีได้
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลองเปลี่ยนไดเรกทอรีได้
คุณสามารถสํารวจข้อมูลที่จําลองแบบจากฐานข้อมูลที่มิเรอร์ของคุณด้วยคิวรี Spark ในสมุดบันทึก
สมุดบันทึกเป็นรายการโค้ดที่มีประสิทธิภาพสําหรับคุณในการพัฒนางาน Apache Spark และการทดลองแมชชีนเลิร์นนิงกับข้อมูลของคุณ คุณสามารถใช้สมุดบันทึกใน Fabric Lakehouse เพื่อสํารวจโต๊ะกระจกของคุณ
ข้อกําหนดเบื้องต้น
- ทําบทช่วยสอนให้เสร็จสมบูรณ์เพื่อสร้างฐานข้อมูลมิเรอร์จากฐานข้อมูลต้นทางของคุณ
- บทช่วยสอน: กําหนดค่าฐานข้อมูลมิเรอร์ Microsoft Fabric สําหรับ Azure Cosmos DB
- บทช่วยสอน: กําหนดค่าฐานข้อมูลมิเรอร์ Microsoft Fabric จาก Azure Databricks
- บทช่วยสอน: กําหนดค่าฐานข้อมูลที่มิเรอร์ Microsoft Fabric จากฐานข้อมูล Azure SQL
- บทช่วยสอน: กําหนดค่าฐานข้อมูลที่มิเรอร์ Microsoft Fabric จาก Azure SQL Managed Instance
- บทช่วยสอน: กําหนดค่าฐานข้อมูลมิเรอร์ Microsoft Fabric จาก Snowflake
- บทช่วยสอน: กําหนดค่าฐานข้อมูลที่มิเรอร์ Microsoft Fabric จาก SQL Server
- บทช่วยสอน: สร้างฐานข้อมูลมิเรอร์แบบเปิด
สร้างคําสั่งลัด
ก่อนอื่นคุณต้องสร้างทางลัดจากตารางที่มิเรอร์ไปยัง Lakehouse จากนั้นสร้างสมุดบันทึกด้วยคิวรี Spark ใน Lakehouse ของคุณ
ในพอร์ทัล Fabric ให้เปิด Data Engineering
หากคุณยังไม่ได้สร้าง Lakehouse ให้เลือก Lakehouse และสร้าง Lakehouse ใหม่โดยตั้งชื่อ
เลือก รับข้อมูล ->ทางลัดใหม่
เลือก Microsoft OneLake
คุณสามารถดูฐานข้อมูลที่มิเรอร์ทั้งหมดของคุณในพื้นที่ทํางาน Fabric
เลือกฐานข้อมูลมิเรอร์ที่คุณต้องการเพิ่มลงใน Lakehouse ของคุณเป็นทางลัด
เลือกตารางที่ต้องการจากฐานข้อมูลที่มิเรอร์
เลือก ถัดไป แล้วเลือก สร้าง
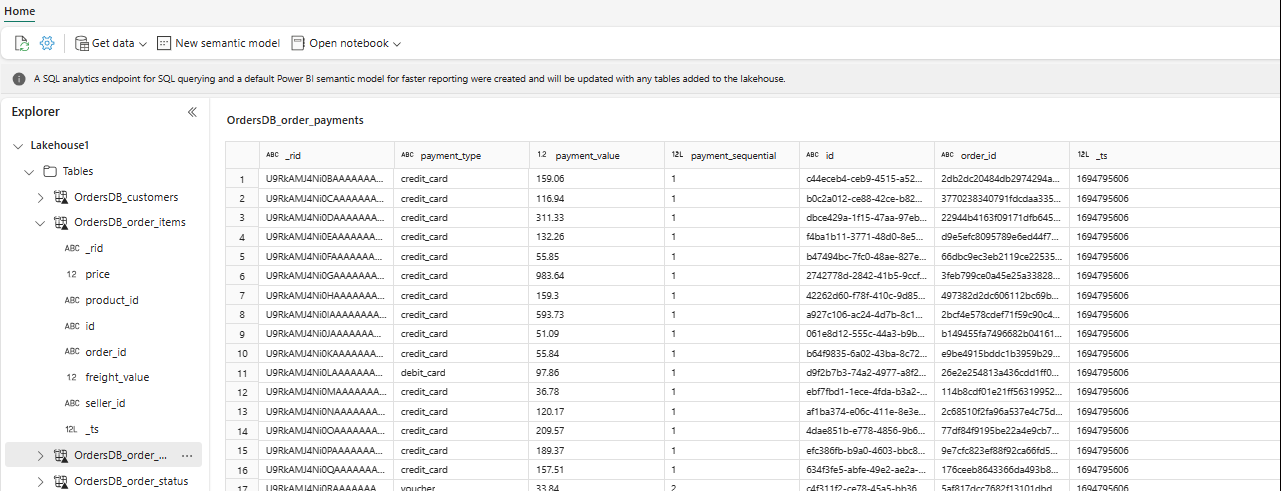
ใน Explorer คุณสามารถดูข้อมูลตารางที่เลือกใน Lakehouse ของคุณได้แล้ว
เคล็ดลับ
คุณสามารถเพิ่มข้อมูลอื่นๆ ใน Lakehouse ได้โดยตรงหรือนําทางลัด เช่น S3, ADLS Gen2 มาใช้ คุณสามารถนําทางไปยัง จุดสิ้นสุดการวิเคราะห์ SQL ของ Lakehouse และรวมข้อมูลในแหล่งข้อมูลเหล่านี้ทั้งหมดด้วยข้อมูลที่มิเรอร์ได้อย่างราบรื่น
เมื่อต้องการสํารวจข้อมูลนี้ใน Spark ให้เลือกจุดถัดจาก
...ตารางใดๆ เลือก สมุดบันทึกใหม่ หรือ สมุดบันทึกที่มีอยู่ เพื่อเริ่มการวิเคราะห์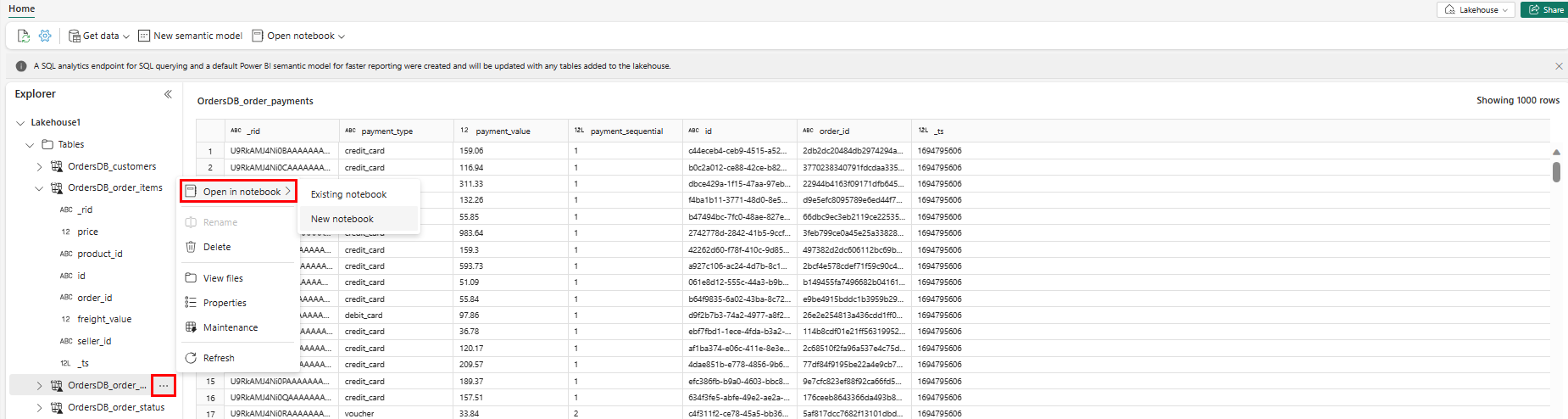
สมุดบันทึกจะเปิดขึ้นโดยอัตโนมัติและโหลดเฟรมข้อมูลด้วย
SELECT ... LIMIT 1000คิวรี Spark SQL- สมุดบันทึกใหม่อาจใช้เวลาถึงสองนาทีในการโหลดจนเสร็จสมบูรณ์ คุณสามารถหลีกเลี่ยงความล่าช้านี้ได้โดยใช้สมุดบันทึกที่มีอยู่กับเซสชันที่ใช้งานอยู่
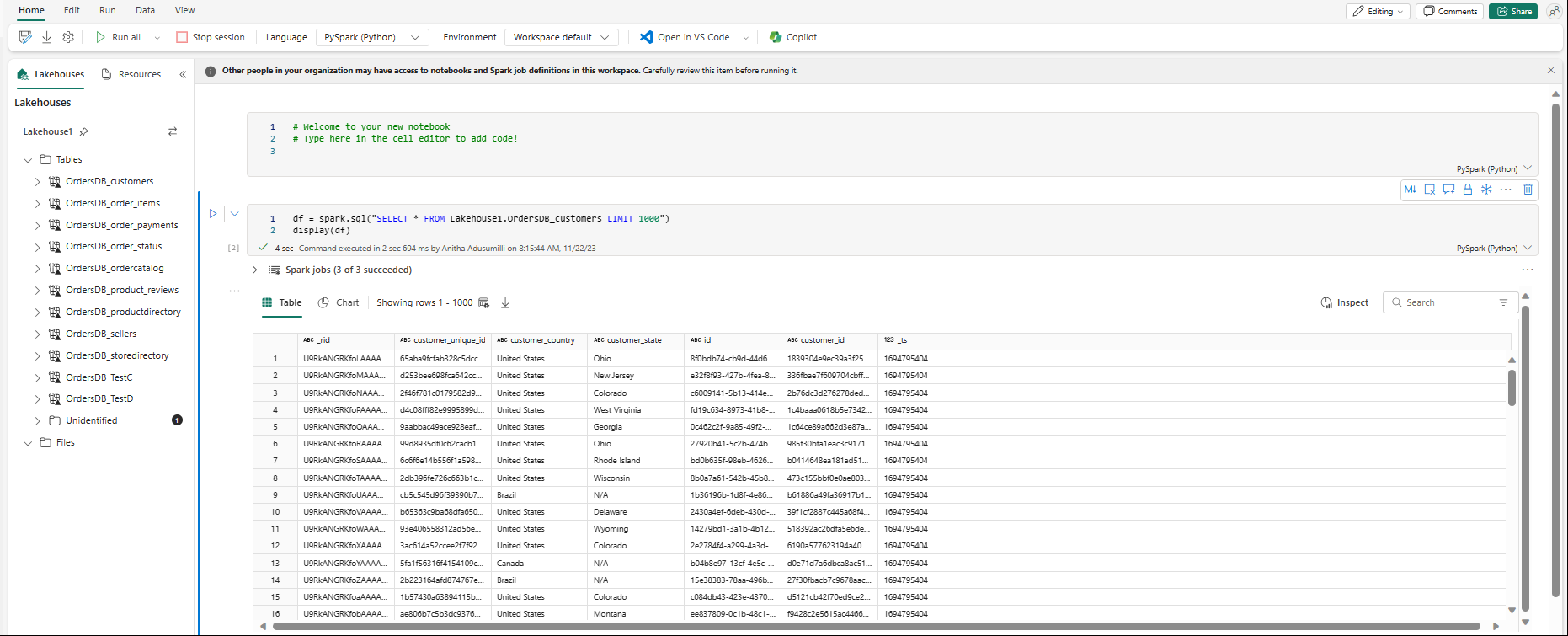
- สมุดบันทึกใหม่อาจใช้เวลาถึงสองนาทีในการโหลดจนเสร็จสมบูรณ์ คุณสามารถหลีกเลี่ยงความล่าช้านี้ได้โดยใช้สมุดบันทึกที่มีอยู่กับเซสชันที่ใช้งานอยู่


