Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
UYGULANANLAR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
İpucu
Kuruluşlar için hepsi bir arada analiz çözümü olan Microsoft Fabric'te Data Factory'yi deneyin. Microsoft Fabric , veri taşımadan veri bilimine, gerçek zamanlı analize, iş zekasına ve raporlamaya kadar her şeyi kapsar. Yeni bir deneme sürümünü ücretsiz olarak başlatmayı öğrenin!
Bu makalede Azure Data Lake Storage 1. Nesil'a ve Azure'dan veri kopyalama adımları açıklanmaktadır. Daha fazla bilgi edinmek için Azure Data Factory veya Azure Synapse Analytics ile ilgili giriş makalesini okuyun.
Not
Azure Data Lake Storage 1. Nesil 29 Şubat 2024'te kullanımdan kaldırıldı. Lütfen Azure Data Lake Storage 2. Nesil bağlayıcısına geçin. Azure Data Lake Storage 1. Nesil geçiş kılavuzu için bu makaleye bakın.
Desteklenen özellikler
Bu Azure Data Lake Storage 1. Nesil bağlayıcısı aşağıdaki özellikler için desteklenir:
| Desteklenen özellikler | IR |
|---|---|
| Kopyalama etkinliği (kaynak/havuz) | (1) (2) |
| Eşleme veri akışı (kaynak/havuz) | (1) |
| Arama etkinliği | (1) (2) |
| GetMetadata etkinliği | (1) (2) |
| Silme etkinliği | (1) (2) |
(1) Azure tümleştirme çalışma zamanı (2) Şirket içinde barındırılan tümleştirme çalışma zamanı
Özellikle, bu bağlayıcı ile şunları yapabilirsiniz:
- Aşağıdaki kimlik doğrulama yöntemlerinden birini kullanarak dosyaları kopyalayın: Azure kaynakları için hizmet sorumlusu veya yönetilen kimlikler.
- Dosyaları olduğu gibi kopyalayın veya desteklenen dosya biçimleri ve sıkıştırma codec'leriyle dosyaları ayrıştırın veya oluşturun.
- Azure Data Lake Storage 2. Nesil kopyalarken ACL'leri koruyun.
Önemli
Şirket içinde barındırılan tümleştirme çalışma zamanını kullanarak verileri kopyalarsanız, şirket güvenlik duvarını 443 numaralı bağlantı noktasına giden login.microsoftonline.com/<tenant>/oauth2/token trafiğe <ADLS account name>.azuredatalakestore.net izin verecek şekilde yapılandırın. İkincisi, tümleştirme çalışma zamanının erişim belirtecini almak için iletişim kurması gereken Azure Güvenlik Belirteci Hizmeti'dir.
Kullanmaya başlayın
İpucu
Azure Data Lake Store bağlayıcısını kullanma hakkında ayrıntılı bilgi için bkz . Azure Data Lake Store'a veri yükleme.
İşlem hattıyla Kopyalama etkinliği gerçekleştirmek için aşağıdaki araçlardan veya SDK'lardan birini kullanabilirsiniz:
- Veri Kopyalama aracı
- Azure portal
- .NET SDK'sı
- Python SDK'sı
- Azure PowerShell
- The REST API
- Azure Resource Manager şablonu
Kullanıcı arabirimini kullanarak Azure Data Lake Storage 1. Nesil'a bağlı hizmet oluşturma
Azure portalı kullanıcı arabiriminde Azure Data Lake Storage 1. Nesil bağlı hizmet oluşturmak için aşağıdaki adımları kullanın.
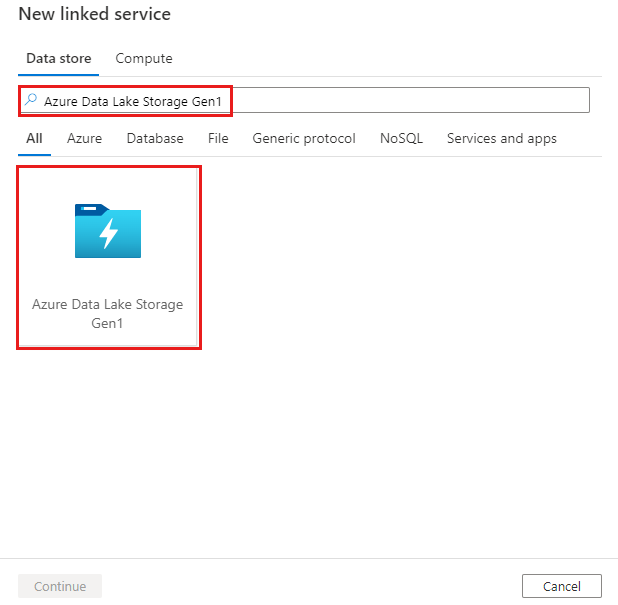
Azure Data Factory veya Synapse çalışma alanınızda Yönet sekmesine gidin ve Bağlı Hizmetler'i ve ardından Yeni'yi seçin:
Azure Data Lake Storage 1. Nesil için arama yapın ve Azure Data Lake Storage 1. Nesil bağlayıcısını seçin.
Hizmet ayrıntılarını yapılandırın, bağlantıyı test edin ve yeni bağlı hizmeti oluşturun.
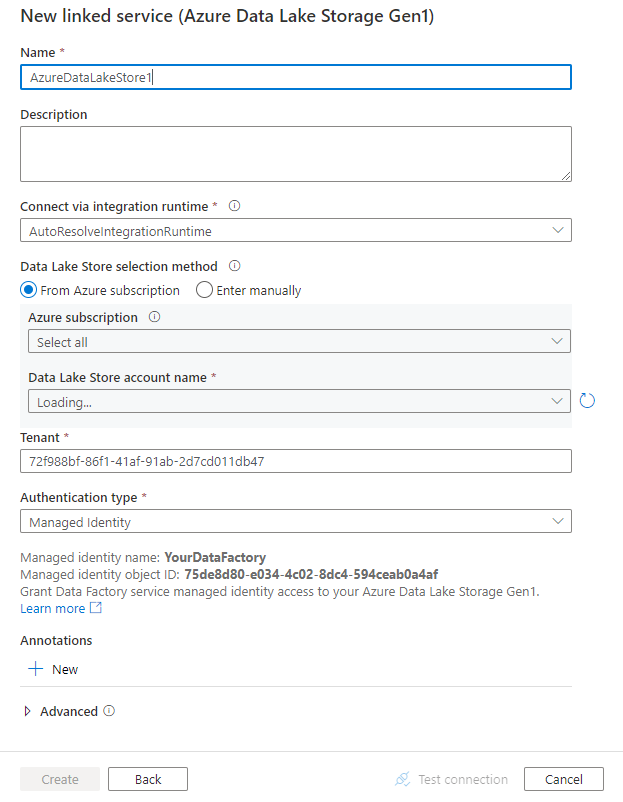
Bağlayıcı yapılandırma ayrıntıları
Aşağıdaki bölümler, Azure Data Lake Store 1. Nesil'e özgü varlıkları tanımlamak için kullanılan özellikler hakkında bilgi sağlar.
Bağlı hizmet özellikleri
Azure Data Lake Store bağlı hizmeti için aşağıdaki özellikler desteklenir:
| Özellik | Açıklama | Gerekli |
|---|---|---|
| Tür | type özelliği AzureDataLakeStore olarak ayarlanmalıdır. |
Yes |
| dataLakeStoreUri | Azure Data Lake Store hesabı hakkında bilgi. Bu bilgiler şu biçimlerden birini alır: https://[accountname].azuredatalakestore.net/webhdfs/v1 veya adl://[accountname].azuredatalakestore.net/. |
Yes |
| subscriptionId | Data Lake Store hesabının ait olduğu Azure abonelik kimliği. | Havuz için gerekli |
| resourceGroupName | Data Lake Store hesabının ait olduğu Azure kaynak grubu adı. | Havuz için gerekli |
| connectVia | Veri deposuna bağlanmak için kullanılacak tümleştirme çalışma zamanı . Veri deponuz özel bir ağda bulunuyorsa Azure tümleştirme çalışma zamanını veya şirket içinde barındırılan tümleştirme çalışma zamanını kullanabilirsiniz. Bu özellik belirtilmezse, varsayılan Azure tümleştirme çalışma zamanı kullanılır. | Hayır |
Hizmet sorumlusu kimlik doğrulamayı kullanma
Hizmet sorumlusu kimlik doğrulamasını kullanmak için aşağıdaki adımları izleyin.
Bir uygulama varlığını Microsoft Entra Id'ye kaydedin ve Data Lake Store'a erişim verin. Ayrıntılı adımlar için bkz . Hizmet-hizmet kimlik doğrulaması. Bağlı hizmeti tanımlamak için kullandığınız aşağıdaki değerleri not edin:
- Uygulama Kimliği
- Uygulama anahtarı
- Kiracı kimliği
Hizmet sorumlusuna uygun izni verin. Azure Data Lake Storage 1. Nesil'daki Erişim denetiminden Data Lake Storage 1. Nesil izinlerin nasıl çalıştığına ilişkin örneklere bakın.
- Kaynak olarak: Veri gezgini>Erişimi'nde, en azından kök de dahil olmak üzere TÜM yukarı akış klasörleri için Yürütme izni ve kopyalanacak dosyalar için Okuma izni verin. Özyinelemeli olması için Bu klasöre ve tüm alt öğelerine ekleyip erişim izni ve varsayılan izin girdisi olarak ekleyebilirsiniz. Hesap düzeyinde erişim denetiminde (IAM) herhangi bir gereksinim yoktur.
- Havuz olarak: Veri gezgini>erişiminde, havuz klasörü için yazma izniyle birlikte kök de dahil olmak üzere EN az TÜM yukarı akış klasörleri için Yürütme izni verin. Özyinelemeli olması için Bu klasöre ve tüm alt öğelerine ekleyip erişim izni ve varsayılan izin girdisi olarak ekleyebilirsiniz.
Aşağıdaki özellikler desteklenir:
| Özellik | Açıklama | Gerekli |
|---|---|---|
| servicePrincipalId | Uygulamanın istemci kimliğini belirtin. | Yes |
| servicePrincipalKey | Uygulamanın anahtarını belirtin. Güvenli bir şekilde depolamak için bu alanı olarak SecureString işaretleyin veya Azure Key Vault'ta depolanan bir gizli diziye başvurun. |
Yes |
| tenant | Uygulamanızın bulunduğu etki alanı adı veya kiracı kimliği gibi kiracı bilgilerini belirtin. Fareyi Azure portalının sağ üst köşesine getirerek alabilirsiniz. | Yes |
| azureCloudType | Hizmet sorumlusu kimlik doğrulaması için Microsoft Entra uygulamanızın kaydedildiği Azure bulut ortamının türünü belirtin. İzin verilen değerler AzurePublic, AzureChina, AzureUsGovernment ve AzureGermany'dir. Varsayılan olarak, hizmetin bulut ortamı kullanılır. |
Hayır |
Örnek:
{
"name": "AzureDataLakeStoreLinkedService",
"properties": {
"type": "AzureDataLakeStore",
"typeProperties": {
"dataLakeStoreUri": "https://<accountname>.azuredatalakestore.net/webhdfs/v1",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"subscriptionId": "<subscription of ADLS>",
"resourceGroupName": "<resource group of ADLS>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Sistem tarafından atanan yönetilen kimlik kimlik doğrulamayı kullanma
Veri fabrikası veya Synapse çalışma alanı, kimlik doğrulaması için hizmeti temsil eden sistem tarafından atanan yönetilen kimlikle ilişkilendirilebilir. Data Lake Store kimlik doğrulaması için sistem tarafından atanan bu yönetilen kimliği, kendi hizmet sorumlunuzu kullanmaya benzer şekilde doğrudan kullanabilirsiniz. Bu belirlenen kaynağın Data Lake Store'a veya Data Lake Store'dan verilere erişmesine ve verileri kopyalamasına izin verir.
Sistem tarafından atanan yönetilen kimlik kimlik doğrulamasını kullanmak için aşağıdaki adımları izleyin.
Sistem tarafından atanan yönetilen kimliğe Data Lake Store erişimi verin. Azure Data Lake Storage 1. Nesil'daki Erişim denetiminden Data Lake Storage 1. Nesil izinlerin nasıl çalıştığına ilişkin örneklere bakın.
- Kaynak olarak: Veri gezgini>Erişimi'nde, en azından kök de dahil olmak üzere TÜM yukarı akış klasörleri için Yürütme izni ve kopyalanacak dosyalar için Okuma izni verin. Özyinelemeli olması için Bu klasöre ve tüm alt öğelerine ekleyip erişim izni ve varsayılan izin girdisi olarak ekleyebilirsiniz. Hesap düzeyinde erişim denetiminde (IAM) herhangi bir gereksinim yoktur.
- Havuz olarak: Veri gezgini>erişiminde, havuz klasörü için yazma izniyle birlikte kök de dahil olmak üzere EN az TÜM yukarı akış klasörleri için Yürütme izni verin. Özyinelemeli olması için Bu klasöre ve tüm alt öğelerine ekleyip erişim izni ve varsayılan izin girdisi olarak ekleyebilirsiniz.
Bağlı hizmetteki genel Data Lake Store bilgileri dışında herhangi bir özellik belirtmeniz gerekmez.
Örnek:
{
"name": "AzureDataLakeStoreLinkedService",
"properties": {
"type": "AzureDataLakeStore",
"typeProperties": {
"dataLakeStoreUri": "https://<accountname>.azuredatalakestore.net/webhdfs/v1",
"subscriptionId": "<subscription of ADLS>",
"resourceGroupName": "<resource group of ADLS>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Kullanıcı tarafından atanan yönetilen kimlik kimlik doğrulamayı kullanma
Veri fabrikası, kullanıcı tarafından atanan bir veya birden çok yönetilen kimlikle atanabilir. Data Lake Store'dan verilere erişmeye ve veri kopyalamaya olanak tanıyan blob depolama kimlik doğrulaması için bu kullanıcı tarafından atanan yönetilen kimliği kullanabilirsiniz. Azure kaynakları için yönetilen kimlikler hakkında daha fazla bilgi edinmek için bkz. Azure kaynakları için yönetilen kimlikler
Kullanıcı tarafından atanan yönetilen kimlik kimlik doğrulamasını kullanmak için şu adımları izleyin:
Kullanıcı tarafından atanan bir veya birden çok yönetilen kimlik oluşturun ve Azure Data Lake'e erişim verin. Azure Data Lake Storage 1. Nesil'daki Erişim denetiminden Data Lake Storage 1. Nesil izinlerin nasıl çalıştığına ilişkin örneklere bakın.
- Kaynak olarak: Veri gezgini>Erişimi'nde, en azından kök de dahil olmak üzere TÜM yukarı akış klasörleri için Yürütme izni ve kopyalanacak dosyalar için Okuma izni verin. Özyinelemeli olması için Bu klasöre ve tüm alt öğelerine ekleyip erişim izni ve varsayılan izin girdisi olarak ekleyebilirsiniz. Hesap düzeyinde erişim denetiminde (IAM) herhangi bir gereksinim yoktur.
- Havuz olarak: Veri gezgini>erişiminde, havuz klasörü için yazma izniyle birlikte kök de dahil olmak üzere EN az TÜM yukarı akış klasörleri için Yürütme izni verin. Özyinelemeli olması için Bu klasöre ve tüm alt öğelerine ekleyip erişim izni ve varsayılan izin girdisi olarak ekleyebilirsiniz.
Veri fabrikanıza kullanıcı tarafından atanan bir veya birden çok yönetilen kimlik atayın ve kullanıcı tarafından atanan her yönetilen kimlik için kimlik bilgileri oluşturun.
Aşağıdaki özellik desteklenir:
| Özellik | Açıklama | Gerekli |
|---|---|---|
| kimlik bilgileri | Kimlik bilgisi nesnesi olarak kullanıcı tarafından atanan yönetilen kimliği belirtin. | Yes |
Örnek:
{
"name": "AzureDataLakeStoreLinkedService",
"properties": {
"type": "AzureDataLakeStore",
"typeProperties": {
"dataLakeStoreUri": "https://<accountname>.azuredatalakestore.net/webhdfs/v1",
"subscriptionId": "<subscription of ADLS>",
"resourceGroupName": "<resource group of ADLS>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Veri kümesi özellikleri
Veri kümelerini tanımlamak için kullanılabilen bölümlerin ve özelliklerin tam listesi için Veri kümeleri makalesine bakın.
Azure Data Factory aşağıdaki dosya biçimlerini destekler. Biçim tabanlı ayarlar için her makaleye bakın.
- Avro biçimi
- İkili biçim
- Sınırlandırılmış metin biçimi
- Excel biçimi
- JSON biçimi
- ORC biçimi
- Parquet biçimi
- XML biçimi
Aşağıdaki özellikler, biçim tabanlı veri kümesindeki ayarlar altında location Azure Data Lake Store 1. Nesil için desteklenir:
| Özellik | Açıklama | Gerekli |
|---|---|---|
| Tür | veri kümesinde altındaki type özelliği location AzureDataLakeStoreLocation olarak ayarlanmalıdır. |
Yes |
| folderPath | Klasörün yolu. Klasörleri filtrelemek için joker karakter kullanmak istiyorsanız, bu ayarı atlayın ve etkinlik kaynağı ayarlarında belirtin. | Hayır |
| fileName | Verilen folderPath altındaki dosya adı. Dosyaları filtrelemek için joker karakter kullanmak istiyorsanız, bu ayarı atlayın ve etkinlik kaynağı ayarlarında belirtin. | Hayır |
Örnek:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<ADLS Gen1 linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "AzureDataLakeStoreLocation",
"folderPath": "root/folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Kopyalama etkinliğinin özellikleri
Etkinlikleri tanımlamak için kullanılabilen bölümlerin ve özelliklerin tam listesi için bkz . İşlem hatları. Bu bölümde, Azure Data Lake Store kaynağı ve havuzu tarafından desteklenen özelliklerin listesi sağlanır.
Kaynak olarak Azure Data Lake Store
Azure Data Factory aşağıdaki dosya biçimlerini destekler. Biçim tabanlı ayarlar için her makaleye bakın.
- Avro biçimi
- İkili biçim
- Sınırlandırılmış metin biçimi
- Excel biçimi
- JSON biçimi
- ORC biçimi
- Parquet biçimi
- XML biçimi
Aşağıdaki özellikler, biçim tabanlı kopyalama kaynağındaki ayarlar altında storeSettings Azure Data Lake Store 1. Nesil için desteklenir:
| Özellik | Açıklama | Gerekli |
|---|---|---|
| Tür | altındaki storeSettings tür özelliği AzureDataLakeStoreReadSettings olarak ayarlanmalıdır. |
Yes |
| Kopyalanacak dosyaları bulun: | ||
| SEÇENEK 1: statik yol |
Veri kümesinde belirtilen belirtilen klasörden/dosya yolundan kopyalayın. Bir klasörden tüm dosyaları kopyalamak istiyorsanız, ek olarak olarak *belirtinwildcardFileName. |
|
| SEÇENEK 2: ad aralığı - listAfter |
Adı bu değerden sonra gelen klasörleri/dosyaları alfabetik olarak (özel olmayan) alın. ADLS 1. Nesil için bir joker karakter filtresine göre daha iyi performans sağlayan hizmet tarafı filtresini kullanır. Hizmet bu filtreyi veri kümesinde tanımlanan yola uygular ve yalnızca bir varlık düzeyi desteklenir. Ad aralığı filtre örnekleri bölümünde daha fazla örnek görebilirsiniz. |
Hayır |
| SEÇENEK 2: ad aralığı - listBefore |
Adı bu değerden önce olan klasörleri/dosyaları alfabetik olarak (dahil) alın. ADLS 1. Nesil için bir joker karakter filtresine göre daha iyi performans sağlayan hizmet tarafı filtresini kullanır. Hizmet bu filtreyi veri kümesinde tanımlanan yola uygular ve yalnızca bir varlık düzeyi desteklenir. Ad aralığı filtre örnekleri bölümünde daha fazla örnek görebilirsiniz. |
Hayır |
| SEÇENEK 3: joker karakter - wildcardFolderPath |
Kaynak klasörleri filtrelemek için joker karakterler içeren klasör yolu. İzin verilen joker karakterler şunlardır: * (sıfır veya daha fazla karakterle eşleşir) ve ? (sıfır veya tek karakterle eşleşir); gerçek klasör adınızın içinde joker karakter veya bu kaçış karakteri varsa kaçış yapmak için kullanın ^ . Klasör ve dosya filtresi örnekleri'ndeki diğer örneklere bakın. |
Hayır |
| SEÇENEK 3: joker karakter - wildcardFileName |
Kaynak dosyaları filtrelemek için verilen folderPath/wildcardFolderPath altında joker karakterler içeren dosya adı. İzin verilen joker karakterler şunlardır: * (sıfır veya daha fazla karakterle eşleşir) ve ? (sıfır veya tek karakterle eşleşir); gerçek dosya adınızın içinde joker karakter veya bu kaçış karakteri varsa kaçış yapmak için kullanın ^ . Klasör ve dosya filtresi örnekleri'ndeki diğer örneklere bakın. |
Yes |
| OPTION 4: dosya listesi - fileListPath |
Belirli bir dosya kümesinin kopyalandığını gösterir. Kopyalamak istediğiniz dosyaların listesini içeren bir metin dosyasının üzerine gelin. Bu, veri kümesinde yapılandırılan yolun göreli yolu olan satır başına bir dosyadır. Bu seçeneği kullanırken veri kümesinde dosya adı belirtmeyin. Dosya listesi örnekleri'ndeki diğer örneklere bakın. |
Hayır |
| Ek ayarlar: | ||
| Özyinelemeli | Verilerin alt klasörlerden veya yalnızca belirtilen klasörden özyinelemeli olarak okunup okunmadığını gösterir. Özyineleme true olarak ayarlandığında ve havuz dosya tabanlı bir depo olduğunda, havuza boş bir klasör veya alt klasör kopyalanır veya oluşturulmaz. İzin verilen değerler true (varsayılan) ve false değerleridir. Yapılandırdığınızda fileListPathbu özellik geçerli değildir. |
Hayır |
| deleteFilesAfterCompletion | hedef depoya başarıyla taşındıktan sonra ikili dosyaların kaynak depodan silinip silinmeyeceğini gösterir. Dosya silme işlemi dosya başınadır, bu nedenle kopyalama etkinliği başarısız olduğunda bazı dosyaların hedefe kopyalandığını ve kaynaktan silindiğini, diğerleri ise kaynak depoda kaldığını görürsünüz. Bu özellik yalnızca ikili dosya kopyalama senaryosunda geçerlidir. Varsayılan değer: false. |
Hayır |
| modifiedDatetimeStart | Dosyalar şu özniteliğe göre filtrelenmiş: Son Değiştirme. Dosyalar, son değiştirme süreleri değerinden büyük veya buna eşit modifiedDatetimeStart ve değerinden modifiedDatetimeEndküçükse seçilir. Saat UTC saat dilimine "2018-12-01T05:00:00Z" biçiminde uygulanır. Özellikler NULL olabilir; başka bir deyişle veri kümesine dosya özniteliği filtresi uygulanmaz. Tarih saat değeri olduğunda modifiedDatetimeStart ancak modifiedDatetimeEnd NULL olduğunda, son değiştirilen özniteliği datetime değerine eşit veya ondan büyük olan dosyaların seçili olduğu anlamına gelir. Tarih saat değeri olduğunda modifiedDatetimeEnd ancak modifiedDatetimeStart NULL olduğunda, son değiştirilen özniteliği datetime değerinden küçük olan dosyaların seçili olduğu anlamına gelir.Yapılandırdığınızda fileListPathbu özellik geçerli değildir. |
Hayır |
| modifiedDatetimeEnd | Yukarıdakiyle aynıdır. | Hayır |
| enablePartitionDiscovery | Bölümlenmiş dosyalar için, bölümlerin dosya yolundan ayrıştırılıp ayrıştırılmayacağını belirtin ve bunları ek kaynak sütunlar olarak ekleyin. İzin verilen değerler false (varsayılan) ve true değerleridir. |
Hayır |
| partitionRootPath | Bölüm bulma etkinleştirildiğinde, bölümlenmiş klasörleri veri sütunları olarak okumak için mutlak kök yolu belirtin. Belirtilmezse, varsayılan olarak - Veri kümesinde dosya yolunu veya kaynaktaki dosyaların listesini kullandığınızda, bölüm kök yolu veri kümesinde yapılandırılan yoldur. - Joker karakter klasör filtresi kullandığınızda, bölüm kök yolu ilk joker karakterden önceki alt yoldur. Örneğin, veri kümesindeki yolu "root/folder/year=2020/month=08/day=27" olarak yapılandırdığınız varsayılır: - Bölüm kök yolunu "root/folder/year=2020" olarak belirtirseniz kopyalama etkinliği, dosyaların içindeki sütunlara ek olarak sırasıyla "08" ve "27" değerine sahip iki sütun month day daha oluşturur.- Bölüm kök yolu belirtilmezse, ek sütun oluşturulmaz. |
Hayır |
| maxConcurrentConnections | Etkinlik çalıştırması sırasında veri deposuna kurulan eş zamanlı bağlantıların üst sınırı. Yalnızca eşzamanlı bağlantıları sınırlamak istediğinizde bir değer belirtin. | Hayır |
Örnek:
"activities":[
{
"name": "CopyFromADLSGen1",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "AzureDataLakeStoreReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Havuz olarak Azure Data Lake Store
Azure Data Factory aşağıdaki dosya biçimlerini destekler. Biçim tabanlı ayarlar için her makaleye bakın.
Aşağıdaki özellikler, biçim tabanlı kopyalama havuzundaki ayarlar altında storeSettings Azure Data Lake Store 1. Nesil için desteklenir:
| Özellik | Açıklama | Gerekli |
|---|---|---|
| Tür | altındaki storeSettings tür özelliği AzureDataLakeStoreWriteSettings olarak ayarlanmalıdır. |
Yes |
| copyBehavior | Kaynak dosya tabanlı bir veri deposundaki dosyalar olduğunda kopyalama davranışını tanımlar. İzin verilen değerler şunlardır: - PreserveHierarchy (varsayılan): Hedef klasördeki dosya hiyerarşisini korur. Kaynak dosyanın kaynak klasöre göreli yolu, hedef dosyanın hedef klasöre göreli yolu ile aynıdır. - FlattenHierarchy: Kaynak klasördeki tüm dosyalar hedef klasörün ilk düzeyindedir. Hedef dosyalar otomatik olarak oluşturulan adlara sahiptir. - MergeFiles: Kaynak klasördeki tüm dosyaları tek bir dosyayla birleştirir. Dosya adı belirtilirse, birleştirilmiş dosya adı belirtilen addır. Aksi takdirde, otomatik olarak oluşturulan bir dosya adıdır. |
Hayır |
| expiryDateTime | Yazılan dosyaların süre sonu süresini belirtir. Saat UTC saatine "2020-03-01T08:00:00Z" biçiminde uygulanır. Varsayılan olarak NULL'tır, yani yazılan dosyaların süresi hiçbir zaman dolmaz. | Hayır |
| maxConcurrentConnections | Etkinlik çalıştırması sırasında veri deposuna kurulan eş zamanlı bağlantıların üst sınırı. Yalnızca eşzamanlı bağlantıları sınırlamak istediğinizde bir değer belirtin. | Hayır |
Örnek:
"activities":[
{
"name": "CopyToADLSGen1",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Parquet output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "ParquetSink",
"storeSettings":{
"type": "AzureDataLakeStoreWriteSettings",
"copyBehavior": "PreserveHierarchy"
}
}
}
}
]
Ad aralığı filtre örnekleri
Bu bölümde ad aralığı filtrelerinin elde edilen davranışı açıklanmaktadır.
| Örnek kaynak yapısı | Yapılandırma | Sonuç |
|---|---|---|
| kök a file.csv balta file2.csv ax.csv b file3.csv bx.csv c file4.csv cx.csv |
Veri kümesinde: - Klasör yolu: rootKopyalama etkinliği kaynağında: - Sonra listele: a- Önce listele: b |
Ardından aşağıdaki dosyalar kopyalanır: kök balta file2.csv ax.csv b file3.csv |
Klasör ve dosya filtresi örnekleri
Bu bölümde, joker karakter filtreleriyle klasör yolunun ve dosya adının elde edilen davranışı açıklanmaktadır.
| folderPath | fileName | Özyinelemeli | Kaynak klasör yapısı ve filtre sonucu (kalın yazılmış dosyalar alınır) |
|---|---|---|---|
Folder* |
(Boş, varsayılanı kullan) | yanlış | KlasörA File1.csv File2.json Alt Klasör1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
(Boş, varsayılanı kullan) | true | KlasörA File1.csv File2.json Alt Klasör1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
yanlış | KlasörA File1.csv File2.json Alt Klasör1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
true | KlasörA File1.csv File2.json Alt Klasör1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Dosya listesi örnekleri
Bu bölümde, kopyalama etkinliği kaynağında dosya listesi yolunu kullanmanın elde edilen davranışı açıklanmaktadır.
Aşağıdaki kaynak klasör yapısına sahip olduğunuzu ve dosyaları kalın yazıyla kopyalamak istediğinizi varsayarsak:
| Örnek kaynak yapısı | FileListToCopy.txt içeriği | Yapılandırma |
|---|---|---|
| kök KlasörA File1.csv File2.json Alt Klasör1 File3.csv File4.json File5.csv Meta veri FileListToCopy.txt |
File1.csv Alt Klasör1/File3.csv Alt Klasör1/File5.csv |
Veri kümesinde: - Klasör yolu: root/FolderAKopyalama etkinliği kaynağında: - Dosya listesi yolu: root/Metadata/FileListToCopy.txt Dosya listesi yolu, veri kümesinde yapılandırılan yolun göreli yolunu içeren, kopyalamak istediğiniz dosyaların listesini içeren aynı veri deposundaki bir metin dosyasını gösterir. |
Kopyalama işleminin davranış örnekleri
Bu bölümde, ve copyBehavior değerlerinin farklı birleşimleri için kopyalama işleminin recursive sonuçta elde edilen davranışı açıklanmaktadır.
| Özyinelemeli | copyBehavior | Kaynak klasör yapısı | Sonuçta elde edilen hedef |
|---|---|---|---|
| true | preserveHierarchy | Klasör1 Dosya1 Dosya2 Alt Klasör1 Dosya3 Dosya4 Dosya5 |
Hedef Klasör1, kaynakla aynı yapıda oluşturulur: Klasör1 Dosya1 Dosya2 Alt Klasör1 Dosya3 Dosya4 Dosya5. |
| true | flattenHierarchy | Klasör1 Dosya1 Dosya2 Alt Klasör1 Dosya3 Dosya4 Dosya5 |
Hedef Klasör1 aşağıdaki yapıyla oluşturulur: Klasör1 Dosya1 için otomatik oluşturulan ad Dosya2 için otomatik oluşturulan ad Dosya3 için otomatik olarak oluşturulan ad Dosya4 için otomatik olarak oluşturulan ad Dosya5 için otomatik oluşturulan ad |
| true | mergeFiles | Klasör1 Dosya1 Dosya2 Alt Klasör1 Dosya3 Dosya4 Dosya5 |
Hedef Klasör1 aşağıdaki yapıyla oluşturulur: Klasör1 Dosya1 + Dosya2 + Dosya3 + Dosya4 + Dosya5 içeriği, otomatik olarak oluşturulan dosya adıyla tek bir dosyada birleştirilir. |
| yanlış | preserveHierarchy | Klasör1 Dosya1 Dosya2 Alt Klasör1 Dosya3 Dosya4 Dosya5 |
Hedef Klasör1 aşağıdaki yapıyla oluşturulur: Klasör1 Dosya1 Dosya2 Dosya3, Dosya4 ve Dosya5 içeren alt klasör1 alınmaz. |
| yanlış | flattenHierarchy | Klasör1 Dosya1 Dosya2 Alt Klasör1 Dosya3 Dosya4 Dosya5 |
Hedef Klasör1 aşağıdaki yapıyla oluşturulur: Klasör1 Dosya1 için otomatik oluşturulan ad Dosya2 için otomatik oluşturulan ad Dosya3, Dosya4 ve Dosya5 içeren alt klasör1 alınmaz. |
| yanlış | mergeFiles | Klasör1 Dosya1 Dosya2 Alt Klasör1 Dosya3 Dosya4 Dosya5 |
Hedef Klasör1 aşağıdaki yapıyla oluşturulur: Klasör1 Dosya1 + Dosya2 içeriği, otomatik olarak oluşturulan dosya adıyla tek bir dosyada birleştirilir. Dosya1 için otomatik oluşturulan ad Dosya3, Dosya4 ve Dosya5 içeren alt klasör1 alınmaz. |
ACL'leri Data Lake Storage 2. Nesil koruma
İpucu
Genel olarak Azure Data Lake Storage 1. Nesil'dan 2. Nesil'e veri kopyalamak için, kılavuz ve en iyi yöntemler için bkz. Azure Data Lake Storage 1. Nesil'dan 2. Nesil'e veri kopyalama.
Data Lake Storage 1. Nesil'den Data Lake Storage 2. Nesil yükseltirken veri dosyalarıyla birlikte erişim denetim listelerini (ACL' ler) çoğaltmak istiyorsanız bkz. Data Lake Storage 1. Nesil ACL'leri koruma.
Eşleme veri akışı özellikleri
Eşleme veri akışlarında verileri dönüştürürken, Azure Data Lake Storage 1. Nesil dosyaları aşağıdaki biçimlerde okuyabilir ve yazabilirsiniz:
Biçime özgü ayarlar, bu biçimin belgelerinde bulunur. Daha fazla bilgi için bkz. Eşleme veri akışında kaynak dönüşümü ve eşleme veri akışında havuz dönüşümü.
Kaynak dönüştürme
Kaynak dönüştürmede, Azure Data Lake Storage 1. Nesil'daki bir kapsayıcıdan, klasörden veya tek tek dosyadan okuyabilirsiniz. Kaynak seçenekleri sekmesi, dosyaların nasıl okunmasını yönetmenizi sağlar.
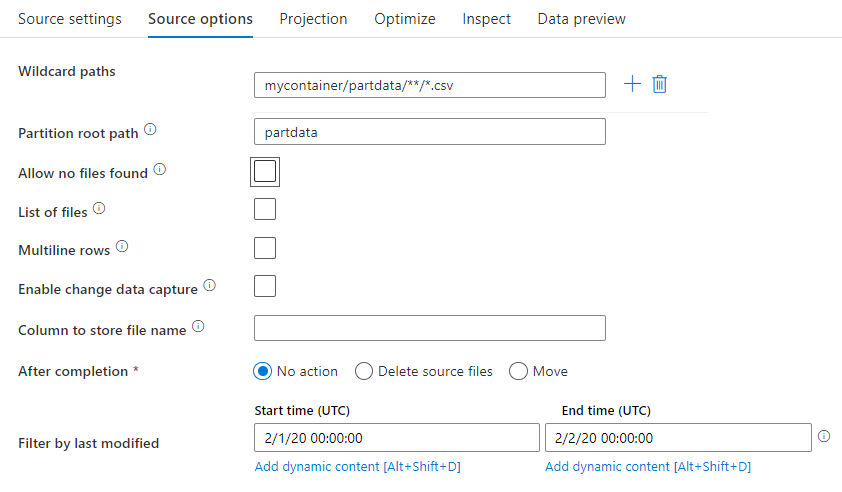
Joker karakter yolu: Joker karakter deseni kullanmak, hizmete eşleşen her klasör ve dosyada tek bir Kaynak dönüşümünde döngü gerçekleştirmesini sağlar. Bu, tek bir akış içinde birden çok dosyayı işlemenin etkili bir yoludur. Var olan joker karakter deseninizin üzerine gelindiğinde görüntülenen + işaretiyle birden çok joker karakter eşleştirme deseni ekleyin.
Kaynak kapsayıcınızdan bir desenle eşleşen bir dizi dosya seçin. Veri kümesinde yalnızca kapsayıcı belirtilebilir. Bu nedenle joker yolunuzun kök klasörden klasör yolunuzu da içermesi gerekir.
Joker karakter örnekleri:
*Herhangi bir karakter kümesini temsil eder**Özyinelemeli dizin iç içe yerleştirmeyi temsil eder?Bir karakteri değiştirir[]Köşeli ayraçtaki daha fazla karakterden biriyle eşleşir/data/sales/**/*.csv/data/sales altındaki tüm csv dosyalarını alır/data/sales/20??/**/Tüm eşleşen 20xx klasörleri içindeki tüm dosyaları özyinelemeli olarak alır/data/sales/*/*/*.csv/data/sales altında csv dosyalarını iki düzey alır/data/sales/2004/12/[XY]1?.csvAralık 2004'ten itibaren X veya Y ile başlayan ve ardından 1 ve tek bir karakter içeren tüm csv dosyalarını alır
Bölüm Kök Yolu: Dosya kaynağınızda key=value bir biçimde bölümlenmiş klasörleriniz varsa (örneğin, year=2019), bu bölüm klasör ağacının en üst düzeyini veri akışı veri akışınızdaki bir sütun adına atayabilirsiniz.
İlk olarak, bölümlenmiş klasörler olan tüm yolları ve okumak istediğiniz yaprak dosyaları içerecek şekilde bir joker karakter ayarlayın.
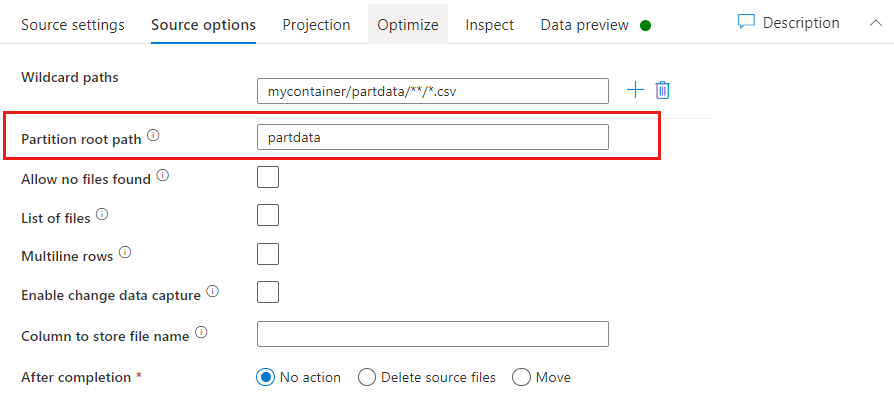
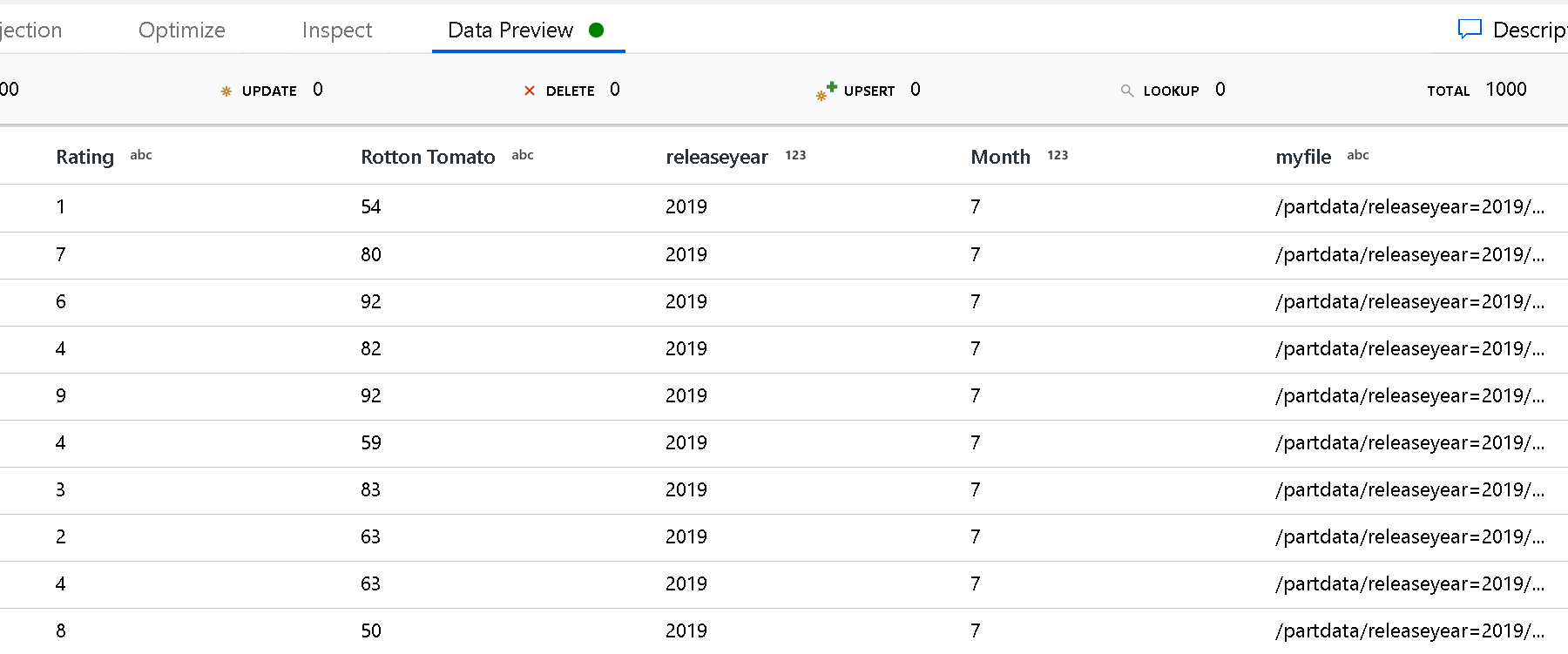
Klasör yapısının en üst düzeyini tanımlamak için Bölüm Kök Yolu ayarını kullanın. Verilerinizin içeriğini bir veri önizlemesi aracılığıyla görüntülediğinizde, hizmetin klasör düzeylerinizin her birinde bulunan çözümlenmiş bölümleri eklediğini görürsünüz.
Dosya listesi: Bu bir dosya kümesidir. İşlenmek üzere göreli yol dosyalarının listesini içeren bir metin dosyası oluşturun. Bu metin dosyasının üzerine gelin.
Dosya adını depolamak için sütun: Kaynak dosyanın adını verilerinizdeki bir sütunda depolayın. Dosya adı dizesini depolamak için buraya yeni bir sütun adı girin.
Tamamlandıktan sonra: Veri akışı çalıştırıldıktan sonra kaynak dosyayla hiçbir şey yapmayı, kaynak dosyayı silmeyi veya kaynak dosyayı taşımayı seçin. Taşımanın yolları görelidir.
Kaynak dosyaları işleme sonrasında başka bir konuma taşımak için önce dosya işlemi için "Taşı"yı seçin. Ardından "kimden" dizinini ayarlayın. Yolunuz için joker karakter kullanmıyorsanız, "kimden" ayarı kaynak klasörünüzle aynı klasördür.
Joker karakter içeren bir kaynak yolunuz varsa söz diziminiz aşağıdaki gibi görünür:
/data/sales/20??/**/*.csv
"kimden" öğesini şu şekilde belirtebilirsiniz:
/data/sales
Ve "to"
/backup/priorSales
Bu durumda, /data/sales altında kaynaklanan tüm dosyalar /backup/priorSales'e taşınır.
Not
Dosya işlemleri yalnızca işlem hattındaki Yürütme Veri Akışı etkinliğini kullanan bir işlem hattı çalıştırmasından (işlem hattı hata ayıklama veya yürütme çalıştırması) veri akışını başlattığınızda çalıştırılır. Dosya işlemleri Veri Akışı hata ayıklama modunda çalışmaz.
Son değiştirilmeye göre filtrele: Son değiştirilme zamanlarının tarih aralığını belirterek hangi dosyaları işlediğinizi filtreleyebilirsiniz. Tüm tarih-saatler UTC olarak belirlenir.
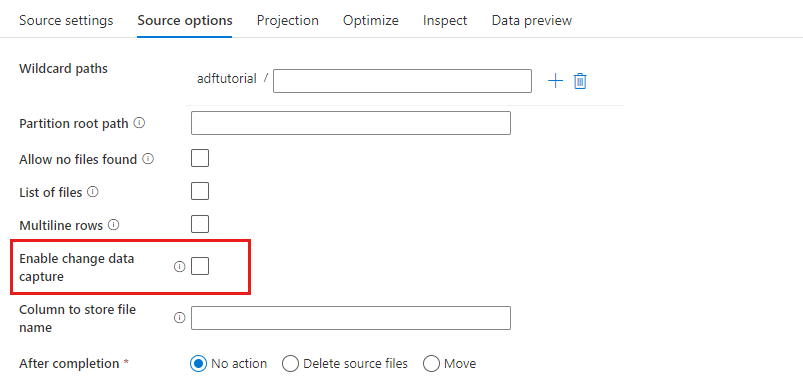
Değişiklik verilerini yakalamayı etkinleştirme: Doğruysa, yalnızca son çalıştırmadan yeni veya değiştirilmiş dosyalar alırsınız. Tam anlık görüntü verilerinin ilk yükü her zaman ilk çalıştırmada alınır ve ardından yalnızca sonraki çalıştırmalarda yeni veya değiştirilmiş dosyalar yakalanacaktır. Diğer ayrıntılar için bkz . Veri yakalamayı değiştirme.
Havuz özellikleri
Havuz dönüşümünde, Azure Data Lake Storage 1. Nesil'da bir kapsayıcıya veya klasöre yazabilirsiniz. Ayarlar sekmesi, dosyaların nasıl yazileceğini yönetmenizi sağlar.
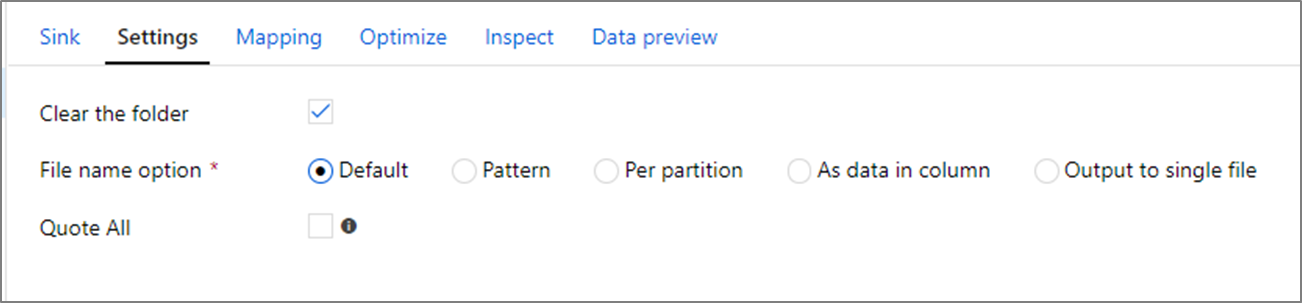
Klasörü temizleme: Veriler yazılmadan önce hedef klasörün temizlenip temizlenmeyeceğini belirler.
Dosya adı seçeneği: Hedef dosyaların hedef klasörde nasıl adlandırileceğini belirler. Dosya adı seçenekleri şunlardır:
- Varsayılan: Spark'ın dosyaları PART varsayılanlarına göre adlandırmasına izin verin.
- Desen: Çıkış dosyalarınızı bölüm başına numaralandıran bir desen girin. Örneğin, loans[n].csv loans1.csv, loans2.csv vb. oluşturur.
- Bölüm başına: Bölüm başına bir dosya adı girin.
- Sütundaki veriler olarak: Çıkış dosyasını bir sütunun değerine ayarlayın. Yol hedef klasöre değil veri kümesi kapsayıcısına göredir. Veri kümenizde bir klasör yolunuz varsa, bu yol geçersiz kılınmış olur.
- Tek bir dosyaya çıkış: Bölümlenmiş çıkış dosyalarını tek bir adlandırılmış dosyada birleştirin. Yol, veri kümesi klasörüne göredir. Birleştirme işleminin düğüm boyutuna göre başarısız olabileceğini unutmayın. Bu seçenek büyük veri kümeleri için önerilmez.
Tümünü tırnak içine alma: Tüm değerlerin tırnak içine alınıp alınmayacağını belirler
Arama etkinliği özellikleri
Özellikler hakkında ayrıntılı bilgi edinmek için Arama etkinliği'ne bakın.
GetMetadata etkinlik özellikleri
Özellikler hakkında ayrıntılı bilgi edinmek için GetMetadata etkinliğini denetleyin
Etkinlik özelliklerini silme
Özellikler hakkında ayrıntılı bilgi edinmek için Silme etkinliği'ne bakın
Eski modeller
Not
Aşağıdaki modeller geriye dönük uyumluluk için olduğu gibi desteklenmektedir. İleride yukarıdaki bölümlerde bahsedilen yeni modeli kullanmanız önerilir ve yazma kullanıcı arabirimi yeni modeli oluşturmaya geçti.
Eski veri kümesi modeli
| Özellik | Açıklama | Gerekli |
|---|---|---|
| Tür | Veri kümesinin tür özelliği AzureDataLakeStoreFile olarak ayarlanmalıdır. | Yes |
| folderPath | Data Lake Store'daki klasörün yolu. Belirtilmezse köke işaret eder. Joker karakter filtresi desteklenir. İzin verilen joker karakterler şunlardır * (sıfır veya daha fazla karakterle eşleşir) ve ? (sıfır veya tek karakterle eşleşir). Gerçek klasör adınızın içinde joker karakter veya kaçış karakteri varsa kaçış yapmak için kullanın ^ . Örneğin: kök klasör/alt klasör/. Klasör ve dosya filtresi örnekleri'ndeki diğer örneklere bakın. |
Hayır |
| fileName | Belirtilen "folderPath" altındaki dosyalar için ad veya joker karakter filtresi. Bu özellik için bir değer belirtmezseniz, veri kümesi klasördeki tüm dosyaları gösterir. Filtre için, izin verilen joker karakterler (sıfır veya daha fazla karakterle eşleşir) ve ? (sıfır veya tek karakterle eşleşir) şeklindedir * .- Örnek 1: "fileName": "*.csv"- Örnek 2: "fileName": "???20180427.txt"Gerçek dosya adınızın içinde joker karakter veya bu kaçış karakteri varsa kaçış yapmak için kullanın ^ .Bir çıkış veri kümesi için fileName belirtilmediğinde ve etkinlik havuzunda preserveHierarchy belirtilmediğinde, kopyalama etkinliği otomatik olarak şu desene sahip dosya adını oluşturur: "Data.[ etkinlik çalıştırma kimliği GUID]. [FlattenHierarchy ise GUID]. [yapılandırıldıysa biçimlendir]. [compression if configured]", örneğin, "Data.0a405f8a-93ff-4c6f-b3be-f69616f1df7a.txt.gz". Tablosal kaynaktan sorgu yerine tablo adı kullanarak kopyalarsanız, ad deseni "[tablo adı].[ biçim]. [compression if configured]", örneğin, "MyTable.csv". |
Hayır |
| modifiedDatetimeStart | Dosyalar, Last Modified özniteliğine göre filtre uygulama. Dosyalar, son değiştirme süreleri değerinden büyük veya buna eşit modifiedDatetimeStart ve değerinden modifiedDatetimeEndküçükse seçilir. Saat UTC saat dilimine "2018-12-01T05:00:00Z" biçiminde uygulanır. Büyük miktarlarda dosya içeren dosya filtresi uygulamak istediğinizde bu ayarın etkinleştirilmesi veri taşımanın genel performansından etkilenir. Özellikler NULL olabilir; başka bir deyişle veri kümesine dosya özniteliği filtresi uygulanmaz. Tarih saat değeri olduğunda modifiedDatetimeStart ancak modifiedDatetimeEnd NULL olduğunda, son değiştirilen özniteliği datetime değerinden büyük veya buna eşit olan dosyaların seçili olduğu anlamına gelir. Tarih saat değeri olduğunda modifiedDatetimeEnd ancak modifiedDatetimeStart NULL olduğunda, son değiştirilen özniteliği datetime değerinden küçük olan dosyaların seçili olduğu anlamına gelir. |
Hayır |
| modifiedDatetimeEnd | Dosyalar, Last Modified özniteliğine göre filtre uygulama. Dosyalar, son değiştirme süreleri değerinden büyük veya buna eşit modifiedDatetimeStart ve değerinden modifiedDatetimeEndküçükse seçilir. Saat UTC saat dilimine "2018-12-01T05:00:00Z" biçiminde uygulanır. Büyük miktarlarda dosya içeren dosya filtresi uygulamak istediğinizde bu ayarın etkinleştirilmesi veri taşımanın genel performansından etkilenir. Özellikler NULL olabilir; başka bir deyişle veri kümesine dosya özniteliği filtresi uygulanmaz. Tarih saat değeri olduğunda modifiedDatetimeStart ancak modifiedDatetimeEnd NULL olduğunda, son değiştirilen özniteliği datetime değerinden büyük veya buna eşit olan dosyaların seçili olduğu anlamına gelir. Tarih saat değeri olduğunda modifiedDatetimeEnd ancak modifiedDatetimeStart NULL olduğunda, son değiştirilen özniteliği datetime değerinden küçük olan dosyaların seçili olduğu anlamına gelir. |
Hayır |
| format | Dosyaları dosya tabanlı depolar (ikili kopya) arasında olduğu gibi kopyalamak istiyorsanız, hem giriş hem de çıkış veri kümesi tanımlarında biçim bölümünü atlayın. Dosyaları belirli bir biçimde ayrıştırmak veya oluşturmak istiyorsanız, şu dosya biçimi türleri desteklenir: TextFormat, JsonFormat, AvroFormat, OrcFormat ve ParquetFormat. biçim altındaki type özelliğini bu değerlerden birine ayarlayın. Daha fazla bilgi için Metin biçimi, JSON biçimi, Avro biçimi, Ork biçimi ve Parquet biçimi bölümlerine bakın. |
Hayır (yalnızca ikili kopyalama senaryosu için) |
| sıkıştırma | Verilerin sıkıştırma türünü ve düzeyini belirtin. Daha fazla bilgi için bkz . Desteklenen dosya biçimleri ve sıkıştırma codec'leri. Desteklenen türler GZip, Deflate, BZip2 ve ZipDeflate'tır. Desteklenen düzeyler En uygun ve en hızlı düzeylerdir. |
Hayır |
İpucu
Bir klasörün altındaki tüm dosyaları kopyalamak için yalnızca folderPath değerini belirtin.
Belirli bir ada sahip tek bir dosyayı kopyalamak için klasör bölümüyle folderPath ve dosya adıyla fileName belirtin.
Klasörün altındaki dosyaların bir alt kümesini kopyalamak için klasör bölümüyle folderPath ve joker karakter filtresiyle fileName belirtin.
Örnek:
{
"name": "ADLSDataset",
"properties": {
"type": "AzureDataLakeStoreFile",
"linkedServiceName":{
"referenceName": "<ADLS linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "datalake/myfolder/",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Eski kopyalama etkinliği kaynak modeli
| Özellik | Açıklama | Gerekli |
|---|---|---|
| Tür | type Kopyalama etkinliği kaynağının özelliği AzureDataLakeStoreSource olarak ayarlanmalıdır. |
Yes |
| Özyinelemeli | Verilerin alt klasörlerden veya yalnızca belirtilen klasörden özyinelemeli olarak okunup okunmadığını gösterir. recursive true olarak ayarlandığında ve havuz dosya tabanlı bir depo olduğunda, havuza boş bir klasör veya alt klasör kopyalanır veya oluşturulmaz. İzin verilen değerler true (varsayılan) ve false değerleridir. |
Hayır |
| maxConcurrentConnections | Etkinlik çalıştırması sırasında veri deposuna kurulan eş zamanlı bağlantıların üst sınırı. Yalnızca eşzamanlı bağlantıları sınırlamak istediğinizde bir değer belirtin. | Hayır |
Örnek:
"activities":[
{
"name": "CopyFromADLSGen1",
"type": "Copy",
"inputs": [
{
"referenceName": "<ADLS Gen1 input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureDataLakeStoreSource",
"recursive": true
},
"sink": {
"type": "<sink type>"
}
}
}
]
Eski kopyalama etkinliği havuz modeli
| Özellik | Açıklama | Gerekli |
|---|---|---|
| Tür | type Kopyalama etkinliği havuzu özelliğinin AzureDataLakeStoreSink olarak ayarlanması gerekir. |
Yes |
| copyBehavior | Kaynak dosya tabanlı bir veri deposundaki dosyalar olduğunda kopyalama davranışını tanımlar. İzin verilen değerler şunlardır: - PreserveHierarchy (varsayılan): Hedef klasördeki dosya hiyerarşisini korur. Kaynak dosyanın kaynak klasöre göreli yolu, hedef dosyanın hedef klasöre göreli yolu ile aynıdır. - FlattenHierarchy: Kaynak klasördeki tüm dosyalar hedef klasörün ilk düzeyindedir. Hedef dosyalar otomatik olarak oluşturulan adlara sahiptir. - MergeFiles: Kaynak klasördeki tüm dosyaları tek bir dosyayla birleştirir. Dosya adı belirtilirse, birleştirilmiş dosya adı belirtilen addır. Aksi takdirde, dosya adı otomatik olarak oluşturulur. |
Hayır |
| maxConcurrentConnections | Etkinlik çalıştırması sırasında veri deposuna kurulan eş zamanlı bağlantıların üst sınırı. Yalnızca eşzamanlı bağlantıları sınırlamak istediğinizde bir değer belirtin. | Hayır |
Örnek:
"activities":[
{
"name": "CopyToADLSGen1",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<ADLS Gen1 output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDataLakeStoreSink",
"copyBehavior": "PreserveHierarchy"
}
}
}
]
Veri yakalamayı değiştirme (önizleme)
Azure Data Factory, eşleme veri akışı kaynağı dönüşümünde Değişiklik veri yakalamayı etkinleştir (Önizleme) özelliğini etkinleştirerek yalnızca Azure Data Lake Storage 1. Nesil'dan yeni veya değiştirilmiş dosyalar alabilir. Bu bağlayıcı seçeneğiyle, dönüştürülmüş verileri seçtiğiniz hedef veri kümelerine yüklemeden önce yalnızca yeni veya güncelleştirilmiş dosyaları okuyabilir ve dönüştürmeleri uygulayabilirsiniz.
İşlem hattı ve etkinlik adını değiştirmediğinizden emin olun; böylece denetim noktası, değişiklikleri oradan almak için her zaman son çalıştırmadan kaydedilebilir. İşlem hattı adınızı veya etkinlik adınızı değiştirirseniz denetim noktası sıfırlanır ve sonraki çalıştırmada baştan başlarsınız.
İşlem hattında hata ayıkladığınızda Değişiklik verilerini yakalamayı etkinleştir (Önizleme) de çalışır. Hata ayıklama çalıştırması sırasında tarayıcınızı yenilediğinizde denetim noktası sıfırlanır. Hata ayıklama çalıştırmasının sonucundan memnun olduktan sonra işlem hattını yayımlayabilir ve tetikleyebilirsiniz. Hata ayıklama çalıştırması tarafından kaydedilen önceki denetim noktasından bağımsız olarak her zaman baştan başlar.
İzleme bölümünde her zaman bir işlem hattını yeniden çalıştırma şansınız olur. Bunu yaparken, değişiklikler her zaman seçili işlem hattı çalıştırmanızdaki denetim noktası kaydından alınmaktadır.
İlgili içerik
Kopyalama etkinliği tarafından kaynak ve havuz olarak desteklenen veri depolarının listesi için bkz . desteklenen veri depoları.