Azure Data Factory veya Synapse Analytics kullanarak Spark'tan veri kopyalama
UYGULANANLAR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
İpucu
Kuruluşlar için hepsi bir arada analiz çözümü olan Microsoft Fabric'te Data Factory'yi deneyin. Microsoft Fabric , veri taşımadan veri bilimine, gerçek zamanlı analize, iş zekasına ve raporlamaya kadar her şeyi kapsar. Yeni bir deneme sürümünü ücretsiz olarak başlatmayı öğrenin!
Bu makalede, Spark'tan veri kopyalamak için Azure Data Factory veya Synapse Analytics işlem hattında Kopyalama Etkinliği'nin nasıl kullanılacağı özetlenmiştir. Kopyalama etkinliğine genel bir genel bakış sunan kopyalama etkinliğine genel bakış makalesini oluşturur.
Desteklenen özellikler
Bu Spark bağlayıcısı aşağıdaki özellikler için desteklenir:
| Desteklenen özellikler | IR |
|---|---|
| Kopyalama etkinliği (kaynak/-) | (1) (2) |
| Arama etkinliği | (1) (2) |
(1) Azure tümleştirme çalışma zamanı (2) Şirket içinde barındırılan tümleştirme çalışma zamanı
Kopyalama etkinliği tarafından kaynak/havuz olarak desteklenen veri depolarının listesi için Desteklenen veri depoları tablosuna bakın.
Hizmet, bağlantıyı etkinleştirmek için yerleşik bir sürücü sağlar, bu nedenle bu bağlayıcıyı kullanarak herhangi bir sürücüyü el ile yüklemeniz gerekmez.
Önkoşullar
Veri deponuz bir şirket içi ağ, Azure sanal ağı veya Amazon Sanal Özel Bulut içinde bulunuyorsa, şirket içinde barındırılan tümleştirme çalışma zamanını buna bağlanmak için yapılandırmanız gerekir.
Veri deponuz yönetilen bir bulut veri hizmetiyse Azure Integration Runtime'ı kullanabilirsiniz. Erişim, güvenlik duvarı kurallarında onaylanan IP'ler ile sınırlıysa Azure Integration Runtime IP'lerini izin verme listesine ekleyebilirsiniz.
Şirket içinde barındırılan tümleştirme çalışma zamanı yüklemeden ve yapılandırmadan şirket içi ağa erişmek için Azure Data Factory'deki yönetilen sanal ağ tümleştirme çalışma zamanı özelliğini de kullanabilirsiniz.
Data Factory tarafından desteklenen ağ güvenlik mekanizmaları ve seçenekleri hakkında daha fazla bilgi için bkz . Veri erişim stratejileri.
Başlarken
İşlem hattıyla Kopyalama etkinliği gerçekleştirmek için aşağıdaki araçlardan veya SDK'lardan birini kullanabilirsiniz:
- Veri Kopyalama aracı
- Azure portal
- .NET SDK'sı
- Python SDK'sı
- Azure PowerShell
- The REST API
- Azure Resource Manager şablonu
Kullanıcı arabirimini kullanarak Spark'a bağlı hizmet oluşturma
Azure portalı kullanıcı arabiriminde Spark'a bağlı hizmet oluşturmak için aşağıdaki adımları kullanın.
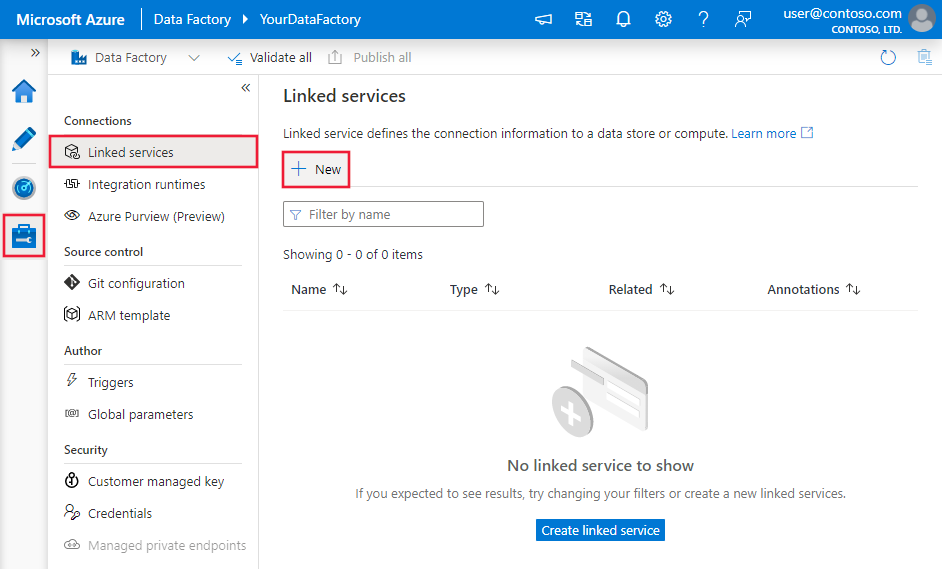
Azure Data Factory veya Synapse çalışma alanınızda Yönet sekmesine göz atın ve Bağlı Hizmetler'i seçin, ardından Yeni'ye tıklayın:
Spark'ı arayın ve Spark bağlayıcısını seçin.

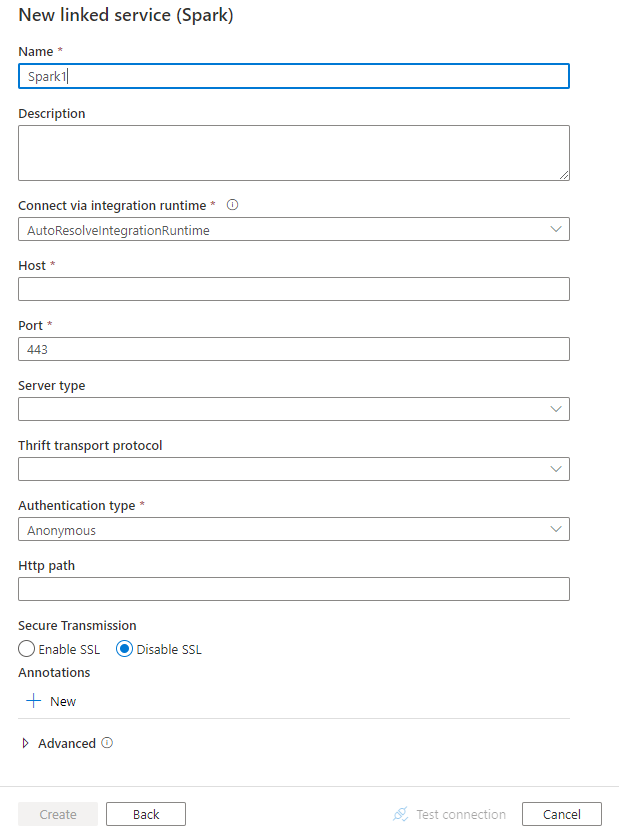
Hizmet ayrıntılarını yapılandırın, bağlantıyı test edin ve yeni bağlı hizmeti oluşturun.
Bağlayıcı yapılandırma ayrıntıları
Aşağıdaki bölümlerde, Spark bağlayıcısına özgü Data Factory varlıklarını tanımlamak için kullanılan özelliklerle ilgili ayrıntılar sağlanır.
Bağlı hizmet özellikleri
Spark bağlı hizmeti için aşağıdaki özellikler desteklenir:
| Özellik | Açıklama | Gerekli |
|---|---|---|
| Tür | Tür özelliği şu şekilde ayarlanmalıdır: Spark | Yes |
| host | Spark sunucusunun IP adresi veya ana bilgisayar adı | Yes |
| port | Spark sunucusunun istemci bağlantılarını dinlemek için kullandığı TCP bağlantı noktası. Azure HDInsights'a bağlanırsanız bağlantı noktasını 443 olarak belirtin. | Yes |
| serverType | Spark sunucusunun türü. İzin verilen değerler şunlardır: SharkServer, SharkServer2, SparkThriftServer |
Hayır |
| thriftTransportProtocol | Thrift katmanında kullanılacak aktarım protokolü. İzin verilen değerler şunlardır: İkili, SASL, HTTP |
Hayır |
| authenticationType | Spark sunucusuna erişmek için kullanılan kimlik doğrulama yöntemi. İzin verilen değerler şunlardır: Anonim, Kullanıcı Adı, KullanıcıAdıAndPassword, WindowsAzureHDInsightService |
Yes |
| username | Spark Server'a erişmek için kullandığınız kullanıcı adı. | Hayır |
| password | Kullanıcıya karşılık gelen parola. Güvenli bir şekilde depolamak için bu alanı SecureString olarak işaretleyin veya Azure Key Vault'ta depolanan bir gizli diziye başvurun. | Hayır |
| httpPath | Spark sunucusuna karşılık gelen kısmi URL. | Hayır |
| enableSsl | Sunucu bağlantılarının TLS kullanılarak şifrelenip şifrelenmediğini belirtir. Varsayılan değer olarak yanlış kullanılır. | Hayır |
| trustedCertPath | TLS üzerinden bağlanırken sunucuyu doğrulamak için güvenilen CA sertifikalarını içeren .pem dosyasının tam yolu. Bu özellik yalnızca şirket içinde barındırılan IR üzerinde TLS kullanılırken ayarlanabilir. Varsayılan değer, IR ile yüklenen cacerts.pem dosyasıdır. | Hayır |
| useSystemTrustStore | Sistem güven deposundan veya belirtilen PEM dosyasından CA sertifikası kullanılıp kullanılmayacağını belirtir. Varsayılan değer olarak yanlış kullanılır. | Hayır |
| allowHostNameCNMismatch | TLS üzerinden bağlanırken sunucunun ana bilgisayar adıyla eşleşmesi için CA tarafından verilen tls/SSL sertifika adının gerekip gerekmediğini belirtir. Varsayılan değer olarak yanlış kullanılır. | Hayır |
| allowSelfSignedServerCert | Sunucudan otomatik olarak imzalanan sertifikalara izin verilip verilmeyeceğini belirtir. Varsayılan değer olarak yanlış kullanılır. | Hayır |
| connectVia | Veri deposuna bağlanmak için kullanılacak Integration Runtime. Önkoşullar bölümünden daha fazla bilgi edinin. Belirtilmezse, varsayılan Azure Integration Runtime'ı kullanır. | Hayır |
Örnek:
{
"name": "SparkLinkedService",
"properties": {
"type": "Spark",
"typeProperties": {
"host" : "<cluster>.azurehdinsight.net",
"port" : "<port>",
"authenticationType" : "WindowsAzureHDInsightService",
"username" : "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
}
}
}
Veri kümesi özellikleri
Veri kümelerini tanımlamak için kullanılabilen bölümlerin ve özelliklerin tam listesi için veri kümeleri makalesine bakın. Bu bölümde Spark veri kümesi tarafından desteklenen özelliklerin listesi sağlanır.
Spark'tan veri kopyalamak için veri kümesinin tür özelliğini SparkObject olarak ayarlayın. Aşağıdaki özellikler desteklenir:
| Özellik | Açıklama | Gerekli |
|---|---|---|
| Tür | Veri kümesinin type özelliği şu şekilde ayarlanmalıdır: SparkObject | Yes |
| schema | Şemanın adı. | Hayır (etkinlik kaynağında "sorgu" belirtilirse) |
| table | Tablonun adı. | Hayır (etkinlik kaynağında "sorgu" belirtilirse) |
| tableName | Şema içeren tablonun adı. Bu özellik geriye dönük uyumluluk için desteklenir. Yeni iş yükü için ve table kullanınschema. |
Hayır (etkinlik kaynağında "sorgu" belirtilirse) |
Örnek
{
"name": "SparkDataset",
"properties": {
"type": "SparkObject",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Spark linked service name>",
"type": "LinkedServiceReference"
}
}
}
Kopyalama etkinliğinin özellikleri
Etkinlikleri tanımlamak için kullanılabilen bölümlerin ve özelliklerin tam listesi için İşlem hatları makalesine bakın. Bu bölümde Spark kaynağı tarafından desteklenen özelliklerin listesi sağlanır.
Kaynak olarak Spark
Spark'tan veri kopyalamak için kopyalama etkinliğindeki kaynak türünü SparkSource olarak ayarlayın. Kopyalama etkinliği kaynağı bölümünde aşağıdaki özellikler desteklenir:
| Özellik | Açıklama | Gerekli |
|---|---|---|
| Tür | Kopyalama etkinliği kaynağının type özelliği şu şekilde ayarlanmalıdır: SparkSource | Yes |
| query | Verileri okumak için özel SQL sorgusunu kullanın. Örneğin: "SELECT * FROM MyTable". |
Hayır (veri kümesinde "tableName" belirtilirse) |
Örnek:
"activities":[
{
"name": "CopyFromSpark",
"type": "Copy",
"inputs": [
{
"referenceName": "<Spark input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SparkSource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Arama etkinliği özellikleri
Özellikler hakkında ayrıntılı bilgi edinmek için Arama etkinliği'ne bakın.
İlgili içerik
Kopyalama etkinliği tarafından kaynak ve havuz olarak desteklenen veri depolarının listesi için bkz . desteklenen veri depoları.