Microsoft Entra ID (eski adıyla Azure Active Directory) kimlik bilgileri geçişini (eski) kullanarak Azure Data Lake Storage'a erişme
Önemli
Bu belge kullanımdan kaldırılmıştır ve güncelleştirilmeyebilir.
Kimlik bilgisi geçişi eski bir veri yönetimi modelidir. Databricks, Unity Kataloğu'na yükseltmenizi önerir. Unity Kataloğu, hesabınızdaki birden çok çalışma alanında veri erişimini yönetmek ve denetlemek için merkezi bir yer sağlayarak verilerinizin güvenliğini ve yönetimini basitleştirir. Unity Kataloğu nedir? bölümüne bakın.
Daha yüksek güvenlik ve idare duruşu için Azure Databricks hesabınızda kimlik bilgisi geçişini devre dışı bırakmak için Azure Databricks hesap ekibinize başvurun.
Not
Bu makale, Azure Databricks'in kullanmadığı beyaz listeye alınmış terimine başvurular içerir. Terim yazılımdan kaldırıldığında bu makaleden de kaldırılacak.
Azure Databricks'de oturum açmak için kullandığınız Microsoft Entra Id (eski adı Azure Active Directory) kimliğini kullanarak Azure Databricks kümelerinden Azure Data Lake Storage 1. Nesil (ADLS 1. Nesil) ve ADLS 2. Nesil'den Erişim için otomatik olarak kimlik doğrulaması yapabilirsiniz. Kümeniz için Azure Data Lake Depolama kimlik bilgisi geçişini etkinleştirdiğinizde, bu kümede çalıştırdığınız komutlar, depolamaya erişim için hizmet sorumlusu kimlik bilgilerini yapılandırmanıza gerek kalmadan Azure Data Lake Depolama'da verileri okuyabilir ve yazabilir.
Azure Data Lake Storage kimlik bilgileri geçişi yalnızca Azure Data Lake Storage 1. Nesil ve 2. Nesil ile desteklenir. Azure Blob depolama kimlik bilgileri geçişini desteklemez.
Bu makalede aşağıdakiler ele alınmaktadır:
- Standart ve yüksek eşzamanlılık kümeleri için kimlik bilgisi geçişlerini etkinleştirme.
- AdLS hesaplarında kimlik bilgisi geçişlerini yapılandırma ve depolama kaynaklarını başlatma.
- Kimlik bilgisi geçişi etkinleştirildiğinde ADLS kaynaklarına doğrudan erişme.
- Kimlik bilgisi geçişi etkinleştirildiğinde bağlama noktası üzerinden ADLS kaynaklarına erişme.
- Kimlik bilgisi geçişi kullanılırken desteklenen özellikler ve sınırlamalar.
Not defterleri, ADLS 1. Nesil ve ADLS 2. Nesil depolama hesaplarıyla kimlik bilgisi geçişini kullanma örnekleri sağlamak için eklenmiştir.
Gereksinim -leri
- Premium plan. Standart planı premium plana yükseltme işleminin ayrıntıları için bkz. Azure Databricks Çalışma Alanını Yükseltme veya Eski Sürüme Düşürme.
- Azure Data Lake Storage 1. Nesil veya 2. Nesil depolama hesabı. Azure Data Lake Storage kimlik bilgileri geçişiyle çalışmak için Azure Data Lake Storage 2. Nesil depolama hesapları hiyerarşik ad alanını kullanmalıdır. Yeni bir ADLS 2. Nesil hesabı oluşturma yönergeleri ve hiyerarşik ad alanını etkinleştirme işlemleri için bkz. Depolama hesabı oluşturma.
- Azure Data Lake Storage için düzgün yapılandırılmış kullanıcı izinleri. Azure Databricks yöneticisinin, Azure Data Lake Depolama'de depolanan verileri okumak ve yazmak için kullanıcıların doğru rollere (örneğin blob veri katkıda bulunanı Depolama) sahip olduğundan emin olması gerekir. Bkz. Azure portalı kullanarak blob ve kuyruk verilerine erişim için Azure rolü atama.
- Geçiş için etkinleştirilmiş çalışma alanlarındaki çalışma alanı yöneticilerinin ayrıcalıklarını anlayın ve mevcut çalışma alanı yönetici atamalarınızı gözden geçirin. Çalışma alanı yöneticileri, çalışma alanları için kullanıcı ve hizmet sorumluları ekleme, küme oluşturma ve diğer kullanıcıları çalışma alanı yöneticisi olarak atama gibi işlemleri yönetebilir. İş sahipliğini yönetme ve not defterlerini görüntüleme gibi çalışma alanı yönetim görevleri, Azure Data Lake Depolama'de kayıtlı verilere dolaylı erişim verebilir. Çalışma alanı yöneticisi, dikkatli bir şekilde dağıtmanız gereken ayrıcalıklı bir roldür.
- ADLS kimlik bilgileriyle yapılandırılmış bir kümeyi (örneğin, hizmet sorumlusu kimlik bilgileri) kimlik bilgisi geçişiyle kullanamazsınız.
Önemli
Microsoft Entra Id'ye giden trafiğe izin verecek şekilde yapılandırılmamış bir güvenlik duvarının arkasındaysanız, Microsoft Entra Id kimlik bilgilerinizle Azure Data Lake Depolama kimlik doğrulaması yapamazsınız. Azure Güvenlik Duvarı Active Directory erişimini varsayılan olarak engeller. Erişime izin vermek için AzureActiveDirectory hizmet etiketini yapılandırın. Azure IP Aralıkları ve Hizmet Etiketleri JSON dosyasındaki AzureActiveDirectory etiketinin altında ağ sanal gereçleri için eşdeğer bilgiler bulabilirsiniz. Daha fazla bilgi için bkz. Azure Güvenlik Duvarı hizmet etiketleri ve Genel Bulut için Azure IP Adresleri.
Günlük önerileri
Azure depolama tanılama günlüklerinde ADLS depolamaya geçirilen kimlikleri günlüğe kaydedebilirsiniz. Kimlikleri günlüğe kaydetme, ADLS isteklerinin Azure Databricks kümelerindeki tek tek kullanıcılara bağlanmasına olanak tanır. Şu günlükleri almaya başlamak için depolama hesabınızda tanılama günlüğünü açın:
- Azure Data Lake Storage 1. Nesil: Data Lake Storage 1. Nesil hesabınız için tanılama günlüğünü etkinleştirme başlığı altındaki yönergeleri izleyin.
- Azure Data Lake Storage 2. Nesil: Komutuyla
Set-AzStorageServiceLoggingPropertyPowerShell kullanarak yapılandırın. Günlük girişi biçimi 2.0 istekte kullanıcı asıl adını içerdiğinden sürüm olarak 2.0 belirtin.
Yüksek Eşzamanlılık kümesi için Azure Data Lake Depolama kimlik bilgisi geçişlerini etkinleştirme
Yüksek eşzamanlılık kümeleri birden çok kullanıcı tarafından paylaşılabilir. Yalnızca Azure Data Lake Depolama kimlik bilgisi geçişi ile Python ve SQL'i destekler.
Önemli
Yüksek Eşzamanlılık kümesi için Azure Data Lake Depolama kimlik bilgisi geçişini etkinleştirmek, 44, 53 ve 80 bağlantı noktaları dışında kümedeki tüm bağlantı noktalarını engeller.
- Küme oluşturduğunuzda Küme Modu'nu Yüksek Eşzamanlılık olarak ayarlayın.
- Gelişmiş Seçenekler'in altında Kullanıcı düzeyinde veri erişimi için kimlik bilgisi geçişini etkinleştir'i seçin ve yalnızca Python ve SQL komutlara izin verin.

Standart küme için Azure Data Lake Depolama kimlik bilgisi geçişlerini etkinleştirme
Kimlik bilgisi geçişi olan standart kümeler tek bir kullanıcıyla sınırlıdır. Standart kümeler Python, SQL, Scala ve R'yi destekler. Databricks Runtime 10.4 LTS ve üzeri sürümlerinde sparklyr desteklenir.
Küme oluşturma sırasında bir kullanıcı atamanız gerekir, ancak küme, özgün kullanıcının yerini almak için istediği zaman YÖNETİLEBİLEBİLECEK izinlere sahip bir kullanıcı tarafından düzenlenebilir.
Önemli
Kümede komut çalıştırmak için kümeye atanan kullanıcının küme için en az CAN ATTACH TO iznine sahip olması gerekir. Çalışma alanı yöneticileri ve küme oluşturucusu CAN MANAGE izinlerine sahiptir, ancak belirlenen küme kullanıcısı olmadığı sürece kümede komut çalıştıramaz.
- Küme oluşturduğunuzda, Küme Modu'nu Standart olarak ayarlayın.
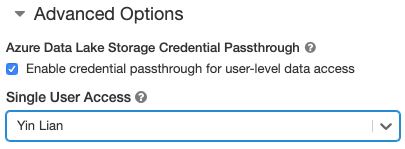
- Gelişmiş Seçenekler'in altında Kullanıcı düzeyinde veri erişimi için kimlik bilgisi geçişini etkinleştir'i seçin ve Tek Kullanıcı Erişimi açılan listesinden kullanıcı adını seçin.
Kapsayıcı oluşturma
Kapsayıcılar , Bir Azure depolama hesabındaki nesneleri düzenlemek için bir yol sağlar.
Kimlik bilgisi geçişini kullanarak Azure Data Lake Depolama doğrudan erişme
Azure Data Lake Depolama kimlik bilgisi geçişini yapılandırdıktan ve depolama kapsayıcıları oluşturduktan sonra, yol kullanarak verilere doğrudan Azure Data Lake Storage 1. Nesil ve yol kullanarak adl://abfss:// Azure Data Lake Storage 2. Nesil erişebilirsiniz.
Azure Data Lake Storage 1. Nesil
Python
spark.read.format("csv").load("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv").collect()
R
# SparkR
library(SparkR)
sparkR.session()
collect(read.df("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv", source = "csv"))
# sparklyr
library(sparklyr)
sc <- spark_connect(method = "databricks")
sc %>% spark_read_csv("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv") %>% sdf_collect()
- değerini ADLS 1. Nesil depolama hesabı adıyla değiştirin
<storage-account-name>.
Azure Data Lake Storage 2. Nesil
Python
spark.read.format("csv").load("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv").collect()
R
# SparkR
library(SparkR)
sparkR.session()
collect(read.df("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv", source = "csv"))
# sparklyr
library(sparklyr)
sc <- spark_connect(method = "databricks")
sc %>% spark_read_csv("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv") %>% sdf_collect()
- değerini ADLS 2. Nesil depolama hesabındaki bir kapsayıcının adıyla değiştirin
<container-name>. - değerini ADLS 2. Nesil depolama hesabı adıyla değiştirin
<storage-account-name>.
Kimlik bilgisi geçişi kullanarak Azure Data Lake Depolama DBFS'ye bağlama
Azure Data Lake Depolama hesabını veya içindeki bir klasörü Databricks Dosya Sistemi (DBFS) nedir? öğesine bağlayabilirsiniz. Bağlama noktasında bir veri gölü deposu işaretçisi oluşturulur ve veriler hiçbir zaman yerel ortama eşitlenmez.
Azure Data Lake Depolama kimlik bilgisi geçişiyle etkinleştirilmiş bir küme kullanarak verileri bağladığınızda, bağlama noktasına yapılan tüm okuma veya yazma işlemleri Microsoft Entra Id kimlik bilgilerinizi kullanır. Bu bağlama noktası diğer kullanıcılar tarafından görülebilir, ancak yalnızca okuma ve yazma erişimine sahip olan kullanıcılar şunlardır:
- Temel alınan Azure Data Lake Depolama depolama hesabına erişme
- Azure Data Lake Depolama kimlik bilgisi geçişi için etkinleştirilen bir küme kullanıyorlar
Azure Data Lake Storage 1. Nesil
Azure Data Lake Storage 1. Nesil kaynağını veya içine klasör bağlamak için aşağıdaki komutları kullanın:
Python
configs = {
"fs.adl.oauth2.access.token.provider.type": "CustomAccessTokenProvider",
"fs.adl.oauth2.access.token.custom.provider": spark.conf.get("spark.databricks.passthrough.adls.tokenProviderClassName")
}
# Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "adl://<storage-account-name>.azuredatalakestore.net/<directory-name>",
mount_point = "/mnt/<mount-name>",
extra_configs = configs)
Scala
val configs = Map(
"fs.adl.oauth2.access.token.provider.type" -> "CustomAccessTokenProvider",
"fs.adl.oauth2.access.token.custom.provider" -> spark.conf.get("spark.databricks.passthrough.adls.tokenProviderClassName")
)
// Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "adl://<storage-account-name>.azuredatalakestore.net/<directory-name>",
mountPoint = "/mnt/<mount-name>",
extraConfigs = configs)
- değerini ADLS 2. Nesil depolama hesabı adıyla değiştirin
<storage-account-name>. - değerini DBFS'de hedeflenen bağlama noktasının adıyla değiştirin
<mount-name>.
Azure Data Lake Storage 2. Nesil
bir Azure Data Lake Storage 2. Nesil dosya sistemini veya içine klasör bağlamak için aşağıdaki komutları kullanın:
Python
configs = {
"fs.azure.account.auth.type": "CustomAccessToken",
"fs.azure.account.custom.token.provider.class": spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName")
}
# Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/",
mount_point = "/mnt/<mount-name>",
extra_configs = configs)
Scala
val configs = Map(
"fs.azure.account.auth.type" -> "CustomAccessToken",
"fs.azure.account.custom.token.provider.class" -> spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName")
)
// Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/",
mountPoint = "/mnt/<mount-name>",
extraConfigs = configs)
- değerini ADLS 2. Nesil depolama hesabındaki bir kapsayıcının adıyla değiştirin
<container-name>. - değerini ADLS 2. Nesil depolama hesabı adıyla değiştirin
<storage-account-name>. - değerini DBFS'de hedeflenen bağlama noktasının adıyla değiştirin
<mount-name>.
Uyarı
Bağlama noktasında kimlik doğrulaması yapmak için depolama hesabı erişim anahtarlarınızı veya hizmet sorumlusu kimlik bilgilerinizi sağlamayın. Bu, diğer kullanıcılara bu kimlik bilgilerini kullanarak dosya sistemine erişim verir. Azure Data Lake Depolama kimlik bilgisi geçişinin amacı, bu kimlik bilgilerini kullanmanıza engel olmak ve dosya sistemine erişimin temel alınan Azure Data Lake Depolama hesabına erişimi olan kullanıcılarla sınırlı olduğundan emin olmaktır.
Güvenlik
Azure Data Lake Depolama kimlik bilgisi geçiş kümelerini diğer kullanıcılarla paylaşmak güvenlidir. Birbirinden yalıtılırsınız ve birbirinizin kimlik bilgilerini okuyamaz veya kullanamazsınız.
Desteklenen özellikler
| Özellik | En Düşük Databricks Runtime Sürümü | Notlar |
|---|---|---|
| Python ve SQL | 5.5 | |
| Azure Data Lake Storage Gen1 | 5.5 | |
%run |
5.5 | |
| DBFS | 5.5 | Kimlik bilgileri yalnızca DBFS yolu Azure Data Lake Storage 1. Nesil veya 2. Nesil'de bir konuma çözümlenirse geçirilir. Diğer depolama sistemlerine çözümleyen DBFS yolları için kimlik bilgilerinizi belirtmek için farklı bir yöntem kullanın. |
| Azure Data Lake Storage 2. Nesil | 5.5 | |
| disk önbelleğe alma | 5.5 | |
| PySpark ML API | 5.5 | Aşağıdaki ML sınıfları desteklenmez: * org/apache/spark/ml/classification/RandomForestClassifier* org/apache/spark/ml/clustering/BisectingKMeans* org/apache/spark/ml/clustering/GaussianMixture* org/spark/ml/clustering/KMeans* org/spark/ml/clustering/LDA* org/spark/ml/evaluation/ClusteringEvaluator* org/spark/ml/feature/HashingTF* org/spark/ml/feature/OneHotEncoder* org/spark/ml/feature/StopWordsRemover* org/spark/ml/feature/VectorIndexer* org/spark/ml/feature/VectorSizeHint* org/spark/ml/regression/IsotonicRegression* org/spark/ml/regression/RandomForestRegressor* org/spark/ml/util/DatasetUtils |
| Yayın değişkenleri | 5.5 | PySpark'ta, büyük UDF'ler yayın değişkenleri olarak gönderildiğinden oluşturabileceğiniz Python UDF'lerinin boyutuna ilişkin bir sınır vardır. |
| Not defteri kapsamlı kitaplıklar | 5.5 | |
| Scala | 5.5 | |
| SparkR | 6,0 | |
| sparklyr | 10.1 | |
| Başka bir not defterinden Databricks not defteri çalıştırma | 6.1 | |
| PySpark ML API | 6.1 | Tüm PySpark ML sınıfları desteklenir. |
| Küme ölçümleri | 6.1 | |
| Databricks Connect | 7.3 | Geçiş, Standart kümelerde desteklenir. |
Sınırlama
Aşağıdaki özellikler Azure Data Lake Depolama kimlik bilgisi geçişiyle desteklenmez:
%fs(bunun yerine eşdeğer dbutils.fs komutunu kullanın).- Databricks İş Akışları.
- Databricks REST API Başvurusu.
- Unity Kataloğu.
- Tablo erişim denetimi. Azure Data Lake Depolama kimlik bilgisi geçişi tarafından verilen izinler tablo ACL'lerinin ayrıntılı izinlerini atlamak için kullanılabilirken, tablo ACL'lerinin ek kısıtlamaları kimlik bilgisi geçişinden elde ettiğiniz avantajlardan bazılarını kısıtlar. Özellikle:
- Belirli bir tablonun altında yatan veri dosyalarına erişmek için Microsoft Entra Id izniniz varsa, tablo ACL'leri aracılığıyla uygulanan kısıtlamalardan bağımsız olarak RDD API'si aracılığıyla bu tablo üzerinde tam izinlere sahip olursunuz.
- Yalnızca DataFrame API'sini kullanırken tablo ACL'leri izinleriyle kısıtlanırsınız. Bu dosyaları doğrudan RDD API'siyle okuyabilseniz bile, dosyaları doğrudan DataFrame API'siyle okumaya çalışırsanız, herhangi bir dosya üzerinde izin
SELECTsahibi olmamayla ilgili uyarılar görürsünüz. - Tabloları okumak için tablo ACL izniniz olsa bile Azure Data Lake Depolama dışındaki dosya sistemleri tarafından desteklenen tablolardan okuyamazsınız.
- SparkContext () ve SparkSession (
scspark) nesneleri için aşağıdaki yöntemler:- Kullanım dışı yöntemler.
- ve
addJar()gibiaddFile()yöntemler, yönetici olmayan kullanıcıların Scala kodunu çağırmasına olanak sağlar. - Azure Data Lake Storage 1. Nesil veya 2. Nesil dışında bir dosya sistemine erişen herhangi bir yöntem (Azure Data Lake Depolama kimlik bilgisi geçişi etkinleştirilmiş bir kümedeki diğer dosya sistemlerine erişmek için, kimlik bilgilerinizi belirtmek için farklı bir yöntem kullanın ve Sorun Giderme altındaki güvenilen dosya sistemleri bölümüne bakın).
- Eski Hadoop API'leri (
hadoopFile()vehadoopRDD()). - Akış hala çalışırken geçirilen kimlik bilgilerinin süresi dolacağı için akış API'leri.
- DBFS bağlamaları (
/dbfs), yalnızca Databricks Runtime 7.3 LTS ve üzerinde kullanılabilir. Kimlik bilgisi geçişi yapılandırılmış bağlama noktaları bu yol üzerinden desteklenmez. - Azure Data Factory.
- Yüksek eşzamanlılık kümelerinde MLflow .
- yüksek eşzamanlılık kümelerinde azureml-sdk Python paketi.
- Microsoft Entra Id belirteci yaşam süresi ilkelerini kullanarak Microsoft Entra Id geçiş belirteçlerinin ömrünü uzatamazsınız. Sonuç olarak, kümeye bir saatten uzun süren bir komut gönderirseniz, 1 saatlik işaretten sonra bir Azure Data Lake Depolama kaynağına erişilirse başarısız olur.
- Hive 2.3 ve üzerini kullanırken, kimlik bilgisi geçişi etkinleştirilmiş bir kümeye bölüm ekleyemezsiniz. Daha fazla bilgi için ilgili sorun giderme bölümüne bakın.
Örnek not defterleri
Aşağıdaki not defterlerinde Azure Data Lake Storage 1. Nesil ve 2. Nesil için Azure Data Lake Depolama kimlik bilgisi geçişi gösterilmektedir.
Azure Data Lake Storage 1. Nesil geçiş not defteri
Azure Data Lake Storage 2. Nesil geçiş not defteri
Sorun giderme
py4j.security.Py4JSecurityException: ... izin verilenler listesine alınmadı
Bu özel durum, Azure Databricks'in Azure Data Lake Storage kimlik bilgisi geçiş kümeleri için açıkça güvenli olarak işaretlemediği bir yönteme eriştiğinizde oluşturulur. Çoğu durumda bunun anlamı, yöntemin bir kullanıcıya Azure Data Lake Storage kimlik bilgisi geçiş kümesinde başka bir kullanıcının kimlik bilgilerine erişim olanağı tanıyabildiğidir.
org.apache.spark.api.python.PythonSecurityException: Yol ... güvenilmeyen bir dosya sistemi kullanır
Azure Data Lake Storage kimlik bilgileri geçiş kümesi tarafından güvenli olduğu bilinmeyen bir dosya sistemine erişmeye çalıştığınızda bu özel durum oluşturulur. Güvenilmeyen bir dosya sistemi kullanmak, Azure Data Lake Depolama kimlik bilgisi geçiş kümesindeki bir kullanıcının başka bir kullanıcının kimlik bilgilerine erişmesine izin verebilir, bu nedenle güvenli bir şekilde kullanıldığından emin olmadığımız tüm dosya sistemlerinin kullanılmasına izin vermiyoruz.
Azure Data Lake Storage kimlik bilgileri geçiş kümesinde bir dizi güvenilen dosya sistemi yapılandırmak için, bu kümedeki Spark spark.databricks.pyspark.trustedFilesystems yapılandırma anahtarını güvenilen org.apache.hadoop.fs.FileSystem uygulamaları olan sınıf adlarının virgülle ayrılmış bir listesi olacak şekilde ayarlayın.
Kimlik bilgisi geçişi etkinleştirildiğinde bölüm ekleme işlemi başarısız AzureCredentialNotFoundException oluyor
Hive 2.3-3.1 kullanırken kimlik bilgileri geçişi etkinleştirilmiş bir kümeye bölüm eklemeyi denerseniz aşağıdaki özel durum oluşur:
org.apache.spark.sql.AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: MetaException(message:com.databricks.backend.daemon.data.client.adl.AzureCredentialNotFoundException: Could not find ADLS Gen2 Token
Bu sorunu geçici olarak çözmek için, kimlik bilgisi geçişi etkinleştirilmeden kümeye bölümler ekleyin.
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin