你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
本文提供了最佳做法指南,可帮助你优化性能、降低成本并保护启用了 Data Lake Storage 的 Azure 存储帐户。
有关构建数据湖的一般建议,请参阅以下文章:
查找文档
Azure Data Lake Storage 不是专用的服务或帐户类型。 它是一组支持高吞吐量分析工作负载的功能。 Data Lake Storage 文档提供了有关使用这些功能的最佳做法和指导。 有关帐户管理的所有其他方面(例如设置网络安全、设计高可用性和灾难恢复)的信息,请参阅 Blob 存储文档的内容。
评估功能支持和已知问题
将帐户配置为使用 Blob 存储功能时,请使用以下模式。
查看 Azure 存储帐户中的 Blob 存储功能支持一文,以确定帐户是否完全支持某项功能。 在启用了 Data Lake Storage 的帐户中,有些功能还不支持或只部分支持。 功能支持始终在扩展,因此请确保定期查看本文中的更新。
查看《Azure Data Lake Storage 的已知问题》一文,了解你打算使用的功能是否存在任何限制或特殊指导。
扫描功能文章,获取特定于已启用 Data Lake Storage 的帐户的任何指导。
理解文档中使用的术语
在两个内容集之间移动时,你会注意到术语有一些细微的差别。 例如,Blob 存储文档中表述的内容将使用术语 “Blob”而不是“文件”。 从技术上说,你引入到存储帐户的文件将成为帐户中的 Blob。 因此,该术语是正确的。 但是,如果你习惯于使用术语“文件”,则使用术语“blob”可能会导致混淆。 你还将看到文中使用术语“容器”来指代“文件系统”。 请将这些术语视为同义词。
考虑高级版
如果工作负荷需要较低的一致延迟和/或需要大量每秒输入输出操作 (IOP),请考虑使用高级块 blob 存储帐户。 这种类型的帐户可通过高性能硬件获取数据。 数据存储在已针对低延迟进行优化的固态硬盘 (SSD) 上。 与传统的机械硬盘相比,SSD 提供更高的吞吐量。 高级性能的存储成本更高,但事务成本更低。 因此,如果工作负荷执行大量事务,高级性能块 blob 帐户可能更经济实惠。
如果你的存储帐户将用于分析,我们强烈建议你将 Azure Data Lake Storage 与高级块 blob 存储帐户结合使用。 将高级块 blob 存储帐户与已启用 Data Lake Storage 的帐户一起使用的这一组合称为 Azure Data Lake Storage 的高级层。
优化数据引入
从源系统引入数据时,源硬件、源网络硬件或与存储帐户的网络连接可能成为瓶颈。
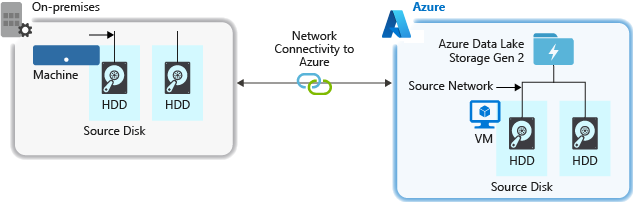
源硬件
无论使用的是本地计算机还是 Azure 中的虚拟机 (VM),都请确保认真选择适当的硬件。 对于磁盘硬件,请考虑使用固态硬盘 (SSD),并选择主轴速度较快的磁盘硬件。 对于网络硬件,请尽可能地使用最快的网络接口控制器 (NIC)。 在 Azure 上,我们建议使用 Azure D14 VM,该系列具有相当强大的磁盘和网络硬件。
与存储帐户的网络连接
源数据和存储帐户之间的网络连接有时可能成为瓶颈。 如果源数据位于本地,请考虑将专用链接和 Azure ExpressRoute 结合使用。 如果源数据位于 Azure 中,则当数据与启用了 Data Lake Storage 的帐户位于同一 Azure 区域时,性能最佳。
配置数据引入工具,实现最大并行化
若要实现最佳性能,请并行执行尽可能多的读取和写入,以使用所有可用吞吐量。

下表汇总了几个热门引入工具的关键设置。
| 工具 | 设置 |
|---|---|
| DistCp | -m (映射器) |
| Azure 数据工厂 | 并行副本 |
| Sqoop | fs.azure.block.size, -m (映射器) |
| AzCopy | AZCOPY_CONCURRENCY_VALUE |
注意
引入操作的总体性能取决于一些其他因素,这些因素与你引入数据时使用的工具相关。 有关最新指导,请参阅相关文档,了解你计划使用的每个工具。
帐户可以缩放,以便为所有分析方案提供所需的吞吐量。 默认情况下,启用了 Data Lake Storage 的帐户在其默认配置中提供足够的吞吐量,以满足各种使用案例的需求。 如果达到了默认限制,可以联系 Azure 支持部门配置帐户,以获得更多吞吐量。
结构数据集
请考虑预先规划数据的结构。 文件格式、文件大小和目录结构都可能影响性能和成本。
文件格式
可以采用各种格式引入数据。 数据可以按照人类可读格式(如 JSON、CSV 或 XML)或压缩的二进制格式(如 .tar.gz)出现。 数据也可以有各种大小。 数据可由数个大型文件(几 TB)组成,例如从本地系统导出的 SQL 表的数据。 数据也可以大量小文件(几 KB)的形式提供,例如来自物联网 (IoT) 解决方案中实时事件的数据。 可以通过选择适当的文件格式和文件大小来优化效率和成本。
Hadoop 支持一组已针对存储和处理结构化数据进行优化的文件格式。 一些常见格式包括 Avro、Parquet 和优化行纵栏 (ORC) 格式。 所有这些格式都是计算机可读的二进制文件格式。 数据经过压缩,有助于你管理文件大小。 这些格式在每个文件中嵌入一个架构,使得它们成为自描述文件。 这些格式的区别在于数据的存储方式。 Avro 以基于行的格式存储数据,Parquet 和 ORC 则以纵栏格式存储数据。
如果 I/O 模式写入操作繁重,或查询模式倾向于检索多个整行记录,请考虑使用 Avro 文件格式。 例如,Avro 格式适用于连续写入多个事件/消息的消息总线,如事件中心或 Kafka。
当 I/O 模式读取操作繁重,或查询模式侧重于记录中的列子集时,请考虑使用 Parquet 和 ORC 文件格式。 读取事务可以优化为检索特定列,而不是读取整个记录。
Apache Parquet 是一种开源文件格式,已针对读取密集型分析管道进行优化。 Parquet 的列式存储结构允许跳过不相关的数据。 查询效率将大幅提高,因为它们可以缩小从存储发送到分析引擎的数据的范围。 此外,由于类似的数据类型(适用于列)将一起存储,Parquet 支持高效的数据压缩和编码方案,这可以降低数据存储成本。 Azure Synapse Analytics、Azure Databricks 和 Azure 数据工厂等服务具有利用 Parquet 文件格式的本机功能。
文件大小
文件越大,性能越好,成本也更低。
通常,HDInsight 等分析引擎在处理每个文件时都会产生开销,这涉及到列出内容、检查访问权限和执行各种元数据操作等任务。 如果将数据存储为多个小文件,这可能会对性能产生负面影响。 通常可将数据组织成较大的文件(大小为 256 MB 到 100 GB),以获得更好的性能。 某些引擎和应用程序可能会在高效处理大于 100 GB 的文件方面遇到问题。
增加文件大小还可以降低事务成本。 读取和写入操作按 4 MB 的增量计费,因此,无论文件包含 4 MB 还是只有几 KB 的数据,都会收取操作费用。 有关定价信息,请参阅 Azure Data Lake Storage 定价。
有时,数据管道对原始数据(含有多个小文件)的控制有限。 通常,建议系统采用某种进程,将小文件聚合为较大的文件,以供下游应用程序使用。 如果你要实时处理数据,可将实时流式处理引擎(例如 Azure 流分析或 Spark 流式处理)与消息代理(例如事件中心或 Apache Kafka)一起使用,以便将数据作为较大的文件进行存储。 将小文件聚合为较大文件时,请考虑以读取优化格式(例如 Apache Parquet)保存这些大文件,供下游处理。
目录结构
每个工作负载对数据使用方式的要求各不相同,以下是在使用物联网 (IoT) 和批处理方案以及在优化时序数据时,需要考虑的一些常见布局。
IoT 结构
在 IoT 工作负载中,可能会引入大量来自多个产品、设备、组织和客户的数据。 必须预先规划目录布局,以便对下游使用者的数据进行组织,确保其安全性并提高处理效率。 考虑使用的常规模板可能是以下布局:
- {Region}/{SubjectMatter(s)}/{yyyy}/{mm}/{dd}/{hh}/
例如,在英国,飞机引擎的着陆遥测数据可能看起来像以下结构:
- UK/Planes/BA1293/Engine1/2017/08/11/12/
在此示例中,通过将日期放在目录结构的末尾,你可以使用 ACL 更轻松地保护区域和主题,使其仅供特定用户和组访问。 如果将数据结构放在开头,则保护这些区域和主题会困难得多。 例如,如果你只想提供对英国数据或特定航班的访问,则需要针对每个小时目录下的大量目录应用单独的权限。 随着时间的推移,此结构还会导致目录数量呈指数级增加。
批处理作业结构
批处理中常用的方法是将数据放入“in”目录。 然后,当数据处理完以后,再将新数据置于“out”目录中,供下游进程使用。 有的作业需要对单个文件进行处理,但可能不需要对大型数据集进行大规模并行处理。对于这种作业,有时会使用此目录结构。 与上面建议的 IoT 结构一样,好的目录结构会设置父级目录,用于存储区域和主题之类的内容(例如,组织、产品或制造者)。 考虑在结构中添加日期和时间,以便更好地在处理过程中进行组织、筛选式搜索,增强安全性并提高自动化程度。 日期结构的粒度级别取决于上传或处理数据的时间间隔,例如每小时、每天甚至每月。
有时候,数据损坏或格式异常会导致文件处理失败。 在这种情况下,可以将这些文件移到 /bad 文件夹中进一步进行检查,这样的目录结构更有效。 还可以通过批处理作业将这些损坏的文件报告或通知给相关人员,要求其进行人工干预。 请考虑以下模板结构:
- {Region}/{SubjectMatter(s)}/In/{yyyy}/{mm}/{dd}/{hh}/
- {Region}/{SubjectMatter(s)}/Out/{yyyy}/{mm}/{dd}/{hh}/
- {Region}/{SubjectMatter(s)}/Bad/{yyyy}/{mm}/{dd}/{hh}/
例如,一家市场营销公司每天从其北美的客户端提取客户更新数据。 该数据在处理前和处理后可能看起来像以下片段:
- NA/Extracts/ACMEPaperCo/in/2017/08/14/updates_08142017.csv
- NA/Extracts/ACMEPaperCo/out/2017/08/14/processed_updates_08142017.csv
在常见情况下,批数据在处理后会直接进入 Hive 之类的数据库或传统的 SQL 数据库,不需要 /in 或 /out 目录,因为输出已经进入一个适用于 Hive 表或外部数据库的单独文件夹中 。 例如,每日从客户提取的数据将会进入其各自对应的目录中。 然后,Azure 数据工厂、Apache Oozie 或 Apache Airflow 等服务将触发每日 Hive 或 Spark 作业来处理数据并将其写入 Hive 表中。
时序数据结构
对于 Hive 工作负载,对时序数据进行分区修剪将有助于某些查询只读取一部分数据,从而提高性能。
那些引入时序数据的管道在放置其文件时通常会以结构化方式命名文件和文件夹。 下面是一个常见示例,其中数据按日期进行了结构化:
/DataSet/YYYY/MM/DD/datafile_YYYY_MM_DD.tsv
请注意,日期/时间信息同时显示为文件夹和文件名。
下方是日期和时间的一种常见模式
/DataSet/YYYY/MM/DD/HH/mm/datafile_YYYY_MM_DD_HH_mm.tsv
同样,选择的文件夹和文件组织方式应针对更大的文件大小和每个文件夹中合理的文件数进行优化。
设置安全性
请首先查看有关 Blob 存储的安全性建议一文中的建议。 你将找到有关如何保护数据免遭意外或恶意删除、保护防火墙后面的数据以及使用 Microsoft Entra ID 作为标识管理基础的最佳做法指导。
然后,查看《Azure Data Lake Storage 中的访问控制模型》一文,了解特定于已启用 Data Lake Storage 的帐户的指导。 本文将帮助你了解如何使用 Azure 基于角色的访问控制 (Azure RBAC) 角色和访问控制列表 (ACL),对分层文件系统中的目录和文件强制执行安全权限。
引入、处理和分析
有许多不同的数据源,并且可以通过不同的方式将数据引入启用了 Data Lake Storage 的帐户。
例如,可以从 HDInsight 和 Hadoop 群集引入大型数据集,也可以引入小型临时数据集以便为应用程序制作原型。 可以引入各种源(例如应用程序、设备和传感器)生成的流数据。 对于这种类型的数据,可以使用相应的工具以逐个事件的方式实时捕获和处理数据,然后将事件分批写入帐户。 还可以引入包含页面请求历史记录等信息的 Web 服务器日志。 对于日志数据,请考虑编写自定义脚本或应用程序来上传这些数据,以便可以灵活地将数据上传组件作为更大的大数据应用程序的一部分包括在内。
数据在帐户中可用后,可以对该数据运行分析,创建可视化效果,甚至将数据下载到本地计算机或其他存储库(例如 Azure SQL 数据库或 SQL Server 实例)。
下表推荐了可用于引入、分析、可视化和下载数据的工具。 使用此表中的链接可以找到有关如何配置和使用每个工具的指导。
| 目的 | 工具和工具指导 |
|---|---|
| 引入临时数据 | Azure 门户、Azure PowerShell、Azure CLI、REST、Azure 存储资源管理器、Apache DistCp、AzCopy |
| 引入关系数据 | Azure 数据工厂 |
| 引入 Web 服务器日志 | Azure PowerShell、Azure CLI、REST、Azure SDK(.NET、Java、Python 和 Node.js)、Azure 数据工厂 |
| 从 HDInsight 群集引入 | Azure 数据工厂、Apache DistCp、AzCopy |
| 从 Hadoop 群集引入 | Azure 数据工厂、Apache DistCp、WANdisco LiveData Migrator for Azure、Azure Data Box |
| 引入大型数据集(若干 TB) | Azure ExpressRoute |
| 处理和分析数据 | Azure Synapse Analytics、Azure HDInsight、Databricks |
| 可视化数据 | Power BI、Azure Data Lake Storage 查询加速 |
| 下载数据 | Azure 门户、PowerShell、Azure CLI、REST、Azure SDK(.NET、Java、Python 和 Node.js)、Azure 存储资源管理器、AzCopy、Azure 数据工厂、Apache DistCp |
注意
此表未反映支持 Data Lake Storage 的 Azure 服务的完整列表。 若要查看支持的 Azure 服务列表及其支持级别,请参阅支持 Azure Data Lake Storage 的 Azure 服务。
监视遥测数据
监视使用情况和性能是实现服务的重要部分。 示例包括频繁的操作、出现高延迟的操作或导致服务端限制的操作。
存储帐户的所有遥测数据都可以通过 Azure Monitor 中的 Azure 存储日志提供。 此功能将存储帐户与 Log Analytics 和事件中心集成,同时允许将日志存档到另一个存储帐户。 要查看指标和资源日志及其关联架构的完整列表,请参阅 Azure 存储监视数据参考。
选择存储日志的位置取决于计划访问日志的方式。 例如,如果要近乎实时地访问日志,并且能够将日志中的事件与 Azure Monitor 的其他指标相关联,可将日志存储在 Log Analytics 工作区中。 然后,使用 KQL 和创建者查询来查询日志,这些查询枚举了工作区中的 StorageBlobLogs 表。
如果要存储的日志用于近乎实时的查询并需要长期保留,可将诊断设置配置为将日志发送到 Log Analytics 工作区和存储帐户。
如果要通过另一个查询引擎(如 Splunk)访问日志,可将诊断设置配置为将日志发送到事件中心,然后将日志从事件中心引入到所选目标。
可以通过 Azure 门户、PowerShell、Azure CLI 和 Azure 资源管理器模板启用 Azure Monitor 中的 Azure 存储日志。 对于大规模部署,Azure Policy 完全支持修正任务。 有关详细信息,请参阅 ciphertxt/AzureStoragePolicy。