在大量受众使用报表和仪表板时,数据集横向扩展有助于 Power BI 提供快速的性能。 数据集横向扩展使用 Premium 容量来托管主数据集的一个或多个只读副本。 通过提高吞吐量,只读副本可确保在多个用户同时提交查询时性能不会降低。
当 Power BI 创建只读副本时,它会将它们与主读写数据集分离。 只读副本为 Power BI 报表和仪表板查询提供服务,在执行写入和刷新操作时使用读写数据集。 在写入和刷新操作期间,只读副本将继续为报表和仪表板查询提供服务,而不会中断。 默认情况下,只读和读写数据集会自动同步,以便只读副本保持最新。 但是,可以禁用自动同步,并选择在命令行手动同步或通过脚本同步。
下表显示了在启用了 Power BI 数据集横向扩展并禁用自动同步时,每种刷新方法所需的同步:
| Refresh 方法 | 同步 |
|---|---|
| OnDemand UI | 始终同步 |
| 计划的刷新 | 始终同步 |
| 基本 REST API | 需要手动同步 1 |
| 高级 REST API | 需要手动同步 1 |
| XMLA | 需要手动同步 1 |
1 - queryScaleOutSettings 中的 autoSyncReadOnlyReplicas 设置为 false。
副本管理
横向扩展将创建一个读写语义模型副本,以及所需任意数量的只读副本。 所有写入操作都将定向到读写副本。 这包括针对显式面向读写副本的会话的查询,也就是说请勿在连接字符串中使用 ?readonly。 这些查询可能会导致读写副本上的交互式 CPU 使用率较高。 在这种情况下,不会创建新副本,因为面向读写副本的查询负载不能分发到只读副本。
只读副本数取决于查询使用的 OU 数。 如果需求超过当前在加载模型且保持较高状态的节点上可用的计算资源,则可能会在另一个节点上创建额外的只读副本以分发负载。 但是,所有副本使用的总 OU 数不能超过允许单个模型在给定容量 SKU 上使用的最大 OU 数。
例如,F64 容量上的给定语义模型在单个节点上有足够的资源来使用该 SKU 上所有允许的 OU。 因此,F64 容量通常不会扩展到单个只读副本之外。 另一方面,F256 和 F1024+ 容量更有可能创建第二个只读副本,因为单个节点可能不足以提供允许在 F256/F1024+ 容量上使用的所有 OU。
QSO 旨在利用给定容量 SKU 的可用计算能力,尽可能高效地无缝地使用最少的只读副本,并且没有语义模型所有者的管理开销。
但是,如果添加了更多副本,则容量上的当前负载可能足够高,从而导致 限制 。 限制可防止其他只读副本达到持续较高的 CPU 使用率。 在这种情况下,不会创建新的横向扩展只读副本。
当模型的 CU 使用率足够减少且一致地保持足够低时,将删除副本。
先决条件
默认情况下,会为租户启用横向扩展,但不会为租户中的数据集启用横向扩展。 要启用数据集的横向扩展,必须使用 Power BI REST API。 启用之前,必须满足以下先决条件:
已启用租户的“针对大型数据集的横向扩展查询”设置(默认设置)。
你的工作区驻留在 Power BI Premium 容量上:
- Premium Per User (PPU)
- Power BI Premium P SKU
- 用于 Power BI Embedded 的 Power BI A SKU(也称为为客户嵌入)。
- Fabric F SKU
启用“大型语义模型存储格式”设置。
要使用 REST API 管理数据集,请使用 Power BI 管理 cmdlet。 若要安装,在管理员模式下打开 PowerShell 并运行以下命令:
Install-Module -Name MicrosoftPowerBIMgmt以下(或更高版本)应用、库和服务版本支持连接到只读副本:
应用、库或服务 版本 Microsoft Analysis Services OLE DB Provider for Microsoft SQL Server (MSOLAP) 16.0.20.201(2022 年 3 月) Microsoft.AnalysisServices.AdomdClient (ADOMD.NET) 19.36.0(2022 年 3 月) Power BI Desktop 2022 年 6 月 SQL Server Management Studio (SSMS) 19.0 Tabular Editor 2 2.16.6 Tabular Editor 3 3.2.3 DAX Studio 3.0.0
为语义模型配置横向扩展
要了解如何启用或禁用数据集的横向扩展,或通过使用 PowerShell 和 REST API 获取横向扩展状态,请参阅配置数据集横向扩展。
连接到特定的语义模型类型
启用横向扩展时,将保留以下连接:
默认情况下,Power BI Desktop 会连接到只读副本。
实时连接报告连接到只读副本。
默认情况下,XMLA 客户端应用程序会连接到读写语义模型。
在 Power BI 服务中刷新,并使用增强刷新 REST API 连接到读写数据集进行刷新。
将以下字符串之一追加到语义模型的 URL 可以连接到只读副本或读写语义模型:
- 只读 -
?readonly - 读-写 -
?readwrite
为租户禁用语义模型横向扩展
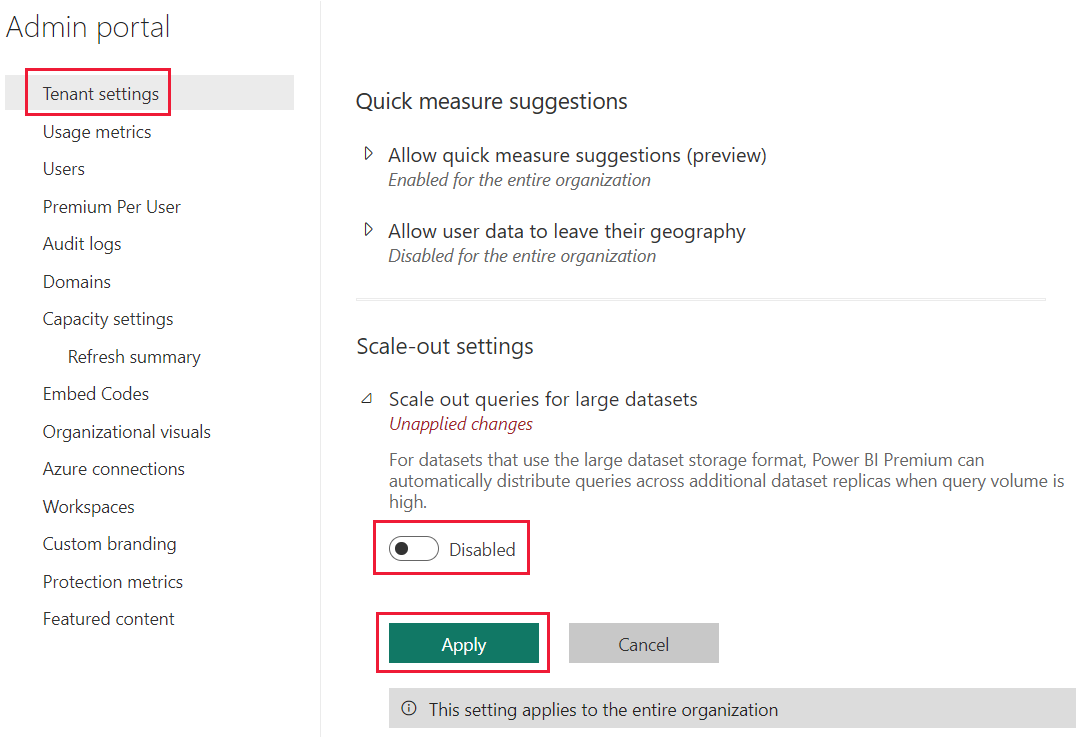
默认情况下,为租户启用了 Power BI 语义模型横向扩展。 Power BI 租户管理员可以禁用此设置。 若要为租户禁用语义模型横向扩展,请执行以下操作:
转到租户设置。
在“横向扩展设置”中,展开“针对大型数据集的横向扩展查询”。
将开关切换为“禁用”。
选择“应用”。
注意事项和限制
客户端应用程序可以通过 XMLA 端点连接到只读副本,前提是它们支持连接字符串中指定的模式。 客户端应用程序还可以使用 XMLA 端点连接到读写实例。
手动和计划的刷新始终自动与最新版本的只读副本同步。 REST API 刷新遵循自动同步配置。 如果禁用自动同步,则必须使用手动同步 REST API 将数据集与只读副本同步。
在禁用自动同步的情况下,必须使用 sync REST API 将 XMLA 更新和刷新与只读数据集副本同步。
删除 Power BI 横向扩展语义模型并创建另一个同名的语义模型时,允许在经过 5 分钟后再创建新的语义模型。 Power BI 可能需要一段时间才能移除主数据集的副本。
当 Power BI 语义模型横向扩展已启用且
autoSyncReadOnlyReplicas=false时,不支持更改以下功能:- 添加或删除角色
- 更新任何角色的角色成员身份集
- 修改数据源
- 删除 DirectQuery 或双表使用的数据源
- 对对象级别安全性 (OLS) 或动态行级别安全性 (RLS) 表达式的更改
要对这些功能进行更改,请禁用横向扩展,并在重新启用之前留出几分钟时间进行更改。
使用动态管理视图(DMV) TMSCHEMA_ROLE_MEMBERSHIPS 行集发现角色成员身份时,如果是针对只读副本运行,则不会返回任何结果。
使用实时连接的报表始终连接到只读副本,即使连接字符串使用
?readwrite也是如此。 但是,在 Power BI Desktop 中,实时连接报表使用?readwrite连接到读写副本。DBSCHEMA_CATALOGS 和 DISCOVER_XML_METADATA 动态管理视图 (DMV) 行集,在连接字符串中使用
?readonly时返回读写副本信息。SQL Server 探查器不适用于
?readonly连接字符串。即使已关闭自动同步 (
AutoSync=Off),这些操作也会触发自动同步。- 将工作区从一个容量迁移到另一个容量。
- 切换(或轮换)用于自带加密密钥 (BYOK) 的密钥版本。
- 将语义模型的工作区从不使用 BYOK 的容量移动到使用 BYOK 的容量。
- 将语义模型的工作区从使用 BYOK 的容量移动到不使用 BYOK 的容量。
- 使用公共 XMLA 终结点还原语义模型。
禁用大型语义模型存储格式时将会禁用横向扩展并丢失所有同步信息。