從 OneLake 檔案和捷徑來編製資料索引
在本文中,了解如何設定 OneLake 檔案索引子,以從 OneLake 頂端的 Lakehouse 擷取可搜尋的資料和中繼資料。
針對下列工作使用此索引子:
- 資料編製索引和累加編製索引: 索引子可以從 Lakehouse 內的資料路徑為檔案和相關聯的中繼資料編製索引。 它會透過內建變更偵測來偵測新的和更新的檔案與中繼資料。 您可以依排程或視需要設定資料重新整理。
- 刪除偵測: 索引子可透過大部分檔案和捷徑的自訂中繼資料來偵測刪除。 這需要將中繼資料新增至檔案,以表示它們已被「虛刪除」,以便從搜尋索引中將其移除。 目前無法偵測 Google Cloud Storage 或 Amazon S3 捷徑檔案中的刪除,因為這些資料來源不支援自訂中繼資料。
- 透過技能集套用 AI:OneLake 檔案索引子完全支援技能集。 這包括重要功能,例如,可新增資料區塊化和內嵌步驟的整合向量化。
- 剖析模式: 如果您想要將 JSON 陣列或行剖析成個別搜尋文件,索引子支援 JSON 剖析模式。
- 與其他功能的相容性: OneLake 索引子的設計目的為與其他索引子功能順暢地搭配運作,例如偵錯工作階段、累加擴充的索引子快取,以及知識存放區。
使用 2024-05-01-preview REST API、beta Azure SDK 套件,或在 Azure 入口網站中匯入和向量化資料,以從 OneLake 編製索引。
本文使用 REST API 來說明每個步驟。
必要條件
光纖工作區。 遵循本教學課程來建立光纖工作區。
光纖工作區中的 Lakehouse。 遵循本教學課程來建立 Lakehouse。
文字資料。 如果您有二進位資料,您可以使用 AI 擴充 影像分析來擷取文字或產生影像的描述。 檔案內容不能超過搜尋服務層級的索引子限制。
Lakehouse 檔案位置中的內容。 您可以透過下列方式新增資料:
- 直接上傳至 Lakehouse
- 從 Microsoft Fabric 使用資料管線
- 從外部資料來源 (例如 Amazon S3 或 Google Cloud Storage) 新增捷徑。
針對系統受控識別或使用者指派的受控識別所設定的 AI 搜尋服務。 AI 搜尋服務必須位於與 Microsoft Fabric 工作區相同的租用戶內。
Lakehouse 所在的 Microsoft Fabric 工作區中的參與者角色指派。 步驟大綱在本文的授與權限一節中。
用來編寫接近於本文示範之 REST 呼叫的 REST 用戶端。
支援的文件格式
OneLake 檔案索引子可以從下列文件格式擷取文字:
- CSV (請參閱編製 CSV Blob 的索引)
- EML
- EPUB
- GZ
- HTML
- JSON (請參閱編製 JSON Blob 的索引)
- KML (用於地理標記法的 XML)
- Microsoft Office 格式:DOCX/DOC/DOCM、XLSX/XLS/XLSM、PPTX/PPT/PPTM、MSG (Outlook 電子郵件)、XML (2003 和 2006 WORD XML)
- 開放式文件格式:ODT、ODS、ODP
- 純文字檔案 (另請參閱編制純文字的索引)
- RTF
- XML
- ZIP
支援的捷徑
OneLake 檔案索引子支援下列 OneLake 捷徑:
OneLake 捷徑 (另一個 OneLake 執行個體的捷徑)
此預覽版的限制
目前不支援 Parquet (包括 delta parquet) 檔案類型。
Amazon S3 和 Google Cloud Storage 捷徑不支援檔案刪除。
此索引子不支援 OneLake 工作區資料表位置內容。
此索引子不支援 SQL 查詢,但資料來源設定中使用的查詢專門用於新增選擇性的資料夾或存取捷徑。
不支援從 OneLake 中的 My Workspace 工作區內嵌檔案,因為這是每個使用者的個人存放庫。
準備資料以編製索引
設定索引前,請檢閱來源資料並判斷事先是否要進行任何變更。 索引子一次可編製一個容器的內容索引。 依預設。容器中的所有檔案會被處理。 提供您數個更具選擇性的處理選項:
在虛擬資料夾中放置檔案。 索引子資料來源定義包含可以是 Lakehouse 子資料夾或捷徑的「查詢」參數。 如果指定這個值,則只會為 Lakehouse 內的子資料夾或捷徑中的檔案編製索引。
依檔案類型包含或排除檔案。 支援的文件格式清單可協助您判斷要排除的檔案。 例如,您可能要排除不提供可搜尋文字的影像或音訊檔案。 此功能是透過索引子中的設定控制。
包含或排除任意檔案。 如果您基於任何原因要跳過特定檔案,請新增中繼資料屬性和值至 OneLake lakehouse 中的檔案。 遇到此屬性時,索引子會跳過索引執行中的檔案或內容。
索引子設定步驟涵蓋了檔案包含與排除。 如果您未設定準則,索引子會將不符合資格的檔案報告為錯誤並繼續進行。 若發生足夠的錯誤,處理可能停止。 您可在索引子設定中指定錯誤容錯。
索引子通常會為每個檔案建立一個搜尋文件,其中的文字內容和中繼資料會被擷取為索引中的可搜尋欄位。 如果檔案是整個檔案,您可以將其剖析為多個搜尋文件。 例如,您可剖析 CSV 檔案中的資料列,並為每個資料列建立一個搜尋文件。 如果您需要將單一文件區塊化為較小的段落,以向量化資料,請考慮使用整合向量化。
編製檔案中繼資料的索引
檔案中繼資料也可編製索引,如果您認為任何標準或自訂中繼資料屬性有助於篩選或查詢,即適用檔案中繼資料。
使用者指定的中繼資料屬性會逐字擷取。 若要接收值,您必須在類型 Edm.String 的搜尋索引中定義欄位,且名稱與 Blob 中繼資料索引鍵相同。 例如,如果 Blob 有 Priority 的中繼索引鍵且值為 High,請在搜尋索引中定義名為 Priority 的欄位,系統會自動填入值 High。
標準檔案中繼資料屬性可擷取至相似名稱和類型的欄位,如下所示。 OneLake 檔案索引子會自動針對這些中繼資料屬性建立內部欄位對應,並轉換原始連字號名稱 (「metadata-storage-name」) 為底線對等名稱 (「metadata_storage_name」)。
您仍必須新增底線欄位至索引定義,但可省略索引子欄位對應,因為索引子會自動建立關聯。
metadata_storage_name (
Edm.String) - 檔案名稱。 例如,如果您有檔案 /mydatalake/my-folder/subfolder/resume.pdf,則此欄位的值是resume.pdf。metadata_storage_path (
Edm.String) - Blob 的完整 URI,包含儲存體帳戶。 例如,https://myaccount.blob.core.windows.net/my-container/my-folder/subfolder/resume.pdfmetadata_storage_content_type (
Edm.String) - 內容類型,即用來上傳 Blob 的程式碼指定類型。 例如:application/octet-stream。metadata_storage_last_modified (
Edm.DateTimeOffset) - Blob 上次修改的時間戳記。 Azure AI 搜尋服務會使用此時間戳記來識別已變更的 blob,以避免在初始編製索引之後重新對所有項目編制索引。metadata_storage_size (
Edm.Int64) - Blob 大小 (以位元組為單位)。metadata_storage_content_md5 (
Edm.String) - Blob 內容的 MD5 雜湊 (若有)。
最後,特定於您正在編製索引的檔案文件格式之任何中繼資料屬性,也可呈現於索引結構描述中。 如需內容特定中繼資料的詳細資訊,請參閱內容中繼資料屬性。
請務必指出您的搜尋索引不必定義上述所有屬性的欄位,只要擷取應用程式所需的屬性。
授與權限
OneLake 索引子會使用權杖驗證和以角色為基礎的存取來連線到 OneLake。 在 OneLake 中指派權限。 實體資料存放區沒有備份捷徑的權限需求。 例如,如果您要從 AWS 編製索引,不需要在 AWS 中授與搜尋服務權限。
搜尋服務身分識別的最低角色指派為參與者。
為 AI 搜尋服務設定系統或使用者受控識別。
下列螢幕擷取畫面顯示名為 「onelake-demo」 之搜尋服務的系統受控識別。
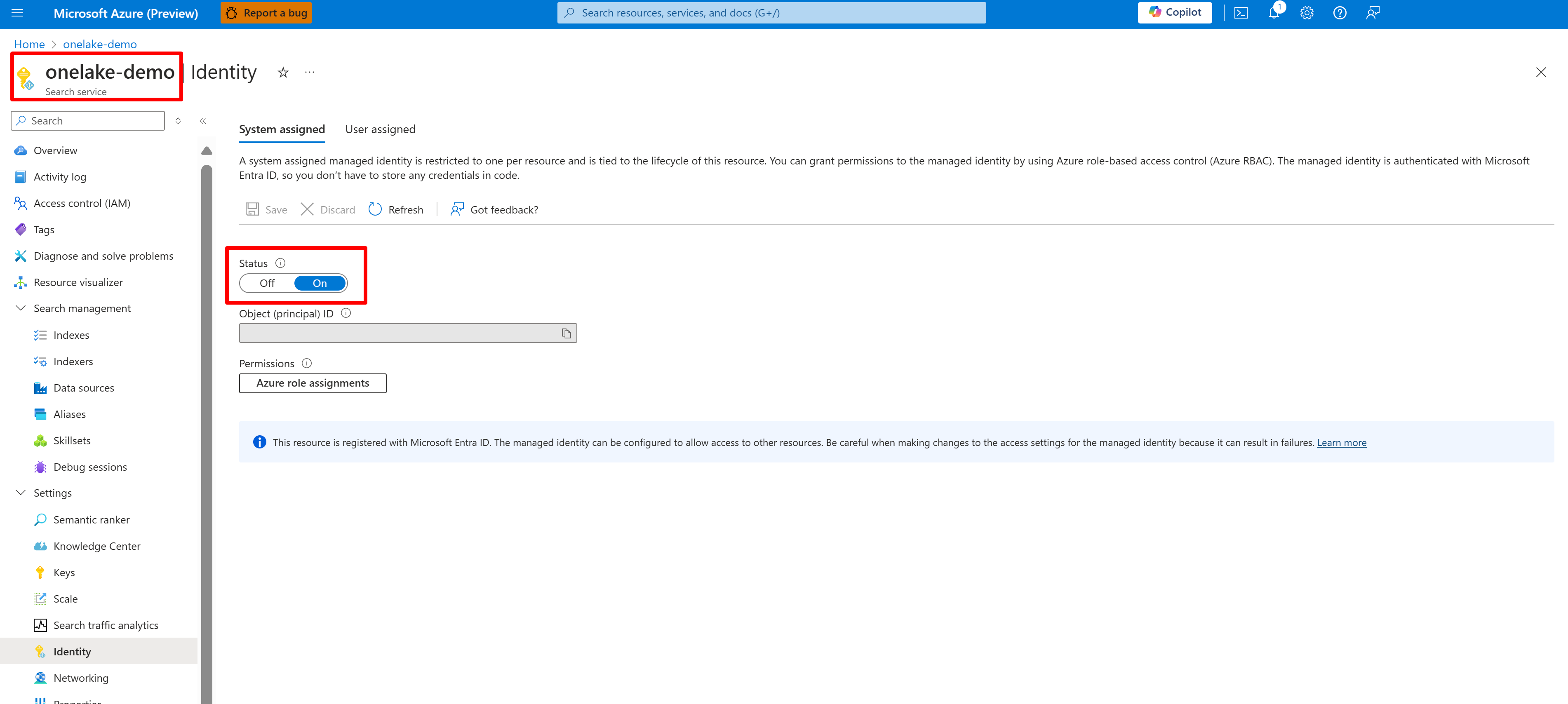
此螢幕擷取畫面顯示相同搜尋服務的使用者受控識別。
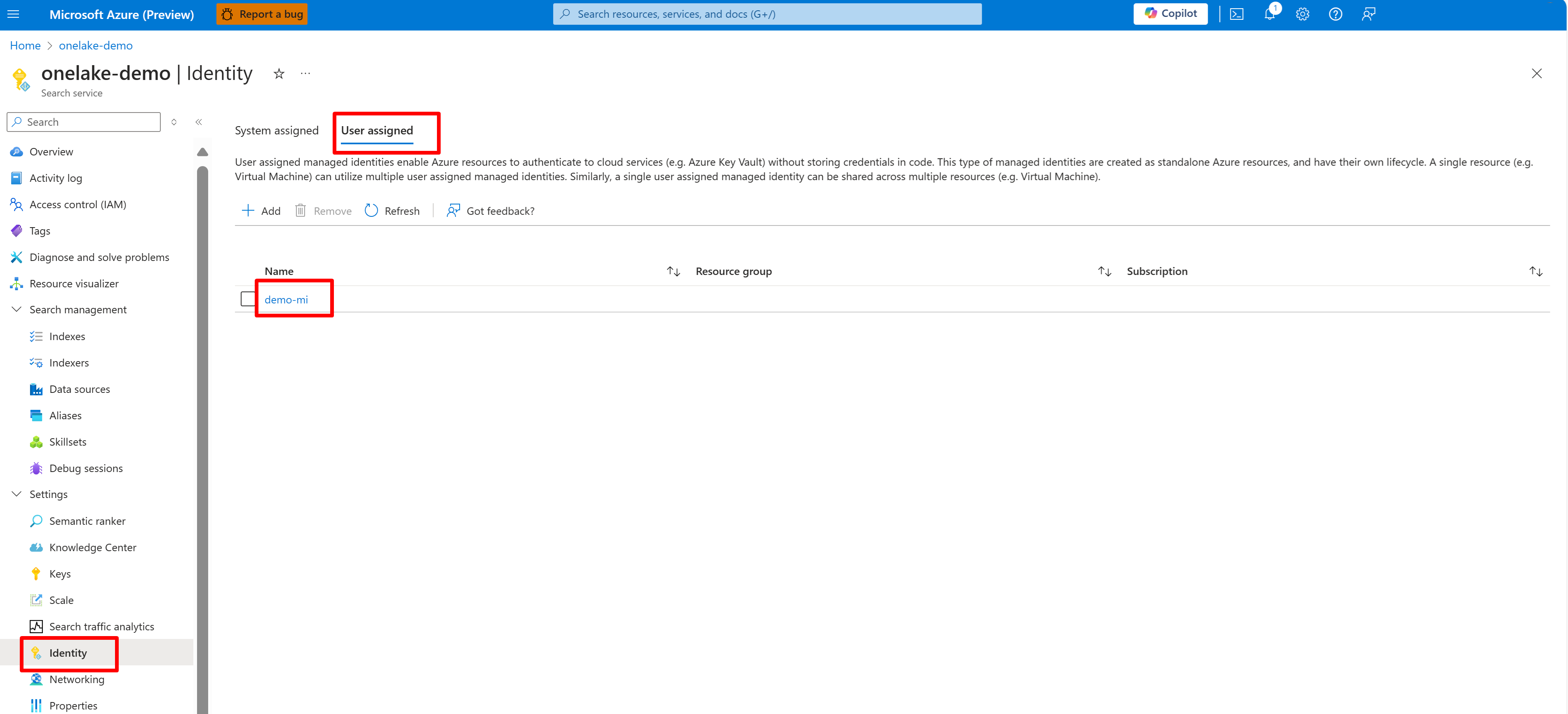
授與搜尋服務存取權限至 Fabric 工作區。 搜尋服務會代表索引子建立連線。
如果您使用系統指派的受控識別,請搜尋 AI 搜尋服務的名稱。 針對使用者指派的受控識別,請搜尋身分識別資源的名稱。
下列螢幕擷取畫面顯示使用系統受控識別的參與者角色指派。
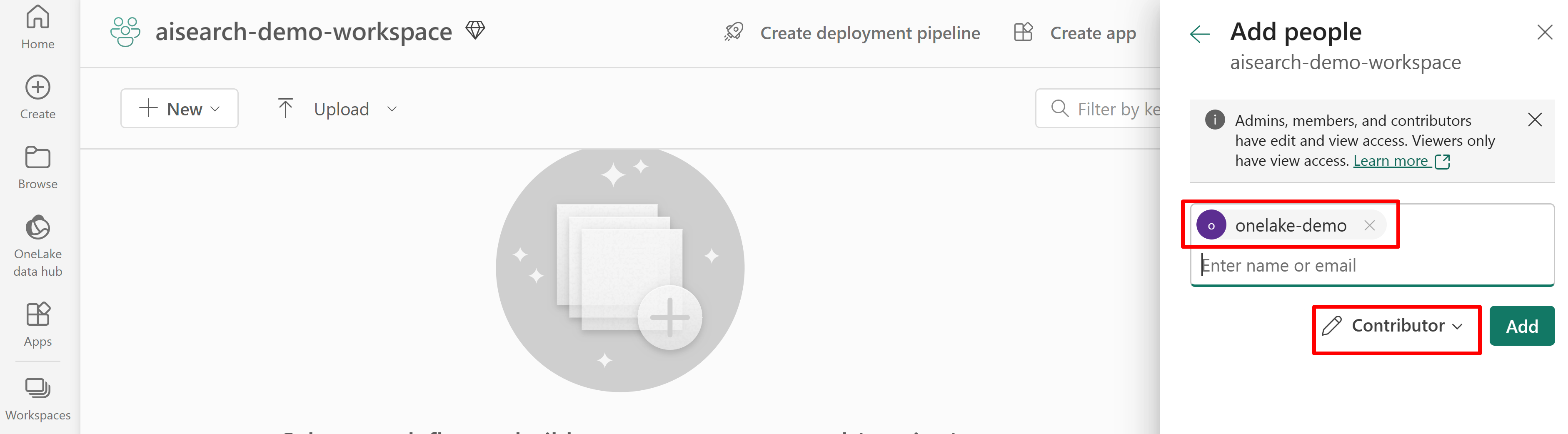
下列螢幕擷取畫面顯示使用系統受控識別的參與者角色指派:
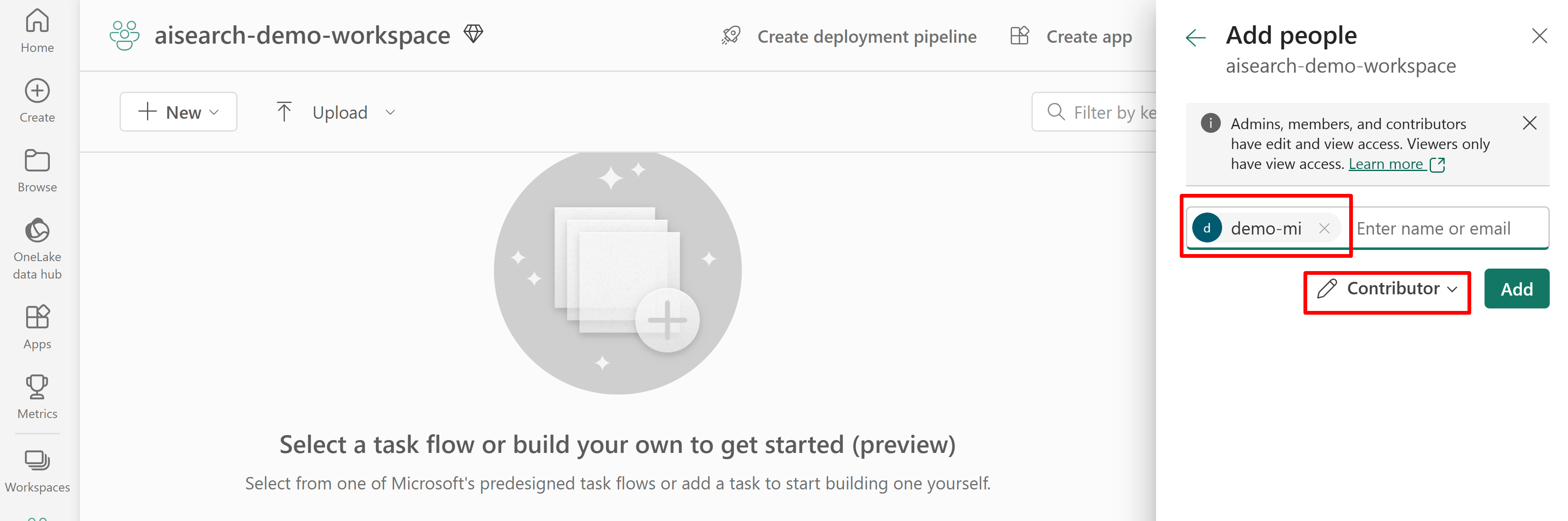




定義資料來源
資料來源定義為獨立的資源,因此可供多個索引子使用。 您必須使用 2024-05-01-preview REST API 來建立資料來源。
使用建立或更新資料來源 REST API 以設定其定義。 這些是定義最重要的步驟。
將
"type"設為"onelake"(必要)。取得 Microsoft Fabric 工作區 GUID 和 Lakehouse GUID:
前往您想要從其 URL 匯入資料的 Lakehouse。 它看起來應該類似此範例: 「https://msit.powerbi.com/groups/00000000-0000-0000-0000-000000000000/lakehouses/11111111-1111-1111-1111-111111111111?experience=power-bi" 複製下列使用於資料來源定義中的值:
複製我們將呼叫
{FabricWorkspaceGuid}的工作區 GUID,其列在 URL 中「群組」之後。 在此範例中,會是 00000000-0000-0000-0000-000000000000。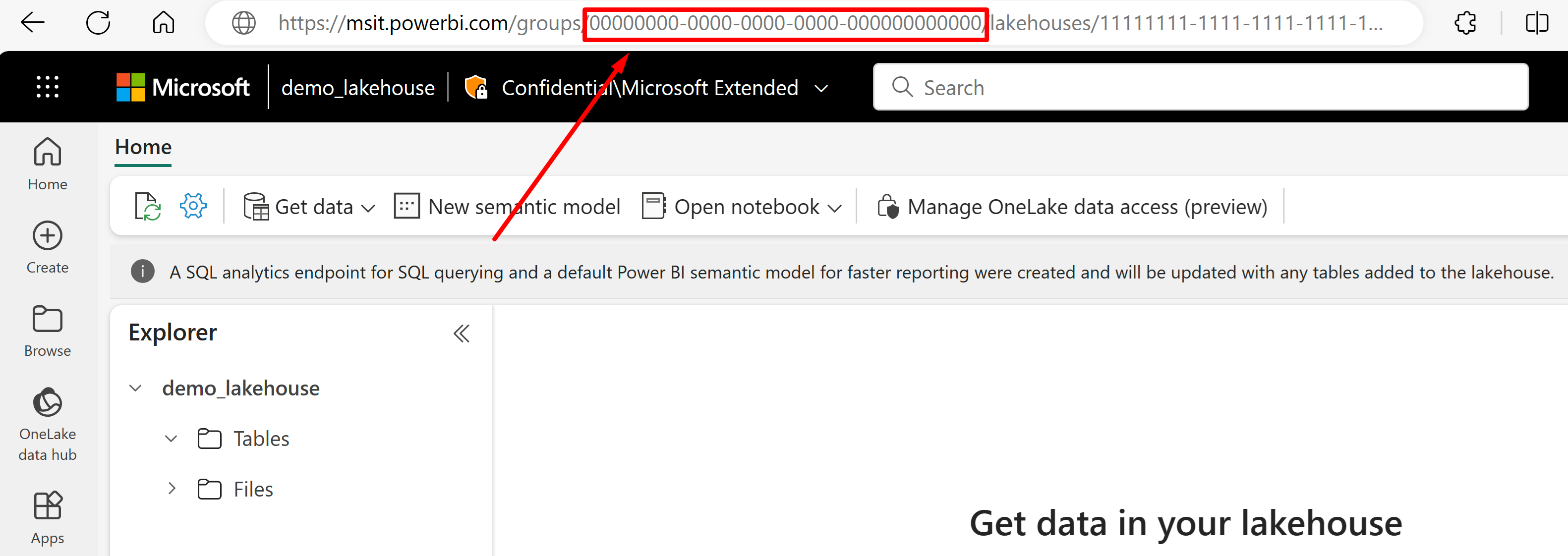
複製 我們將呼叫
{lakehouseGuid}的 lakehouse GUID,其列在 URL 中「lakehouse」之後。 在此範例中,會是 11111111-1111-1111-1111-111111111111。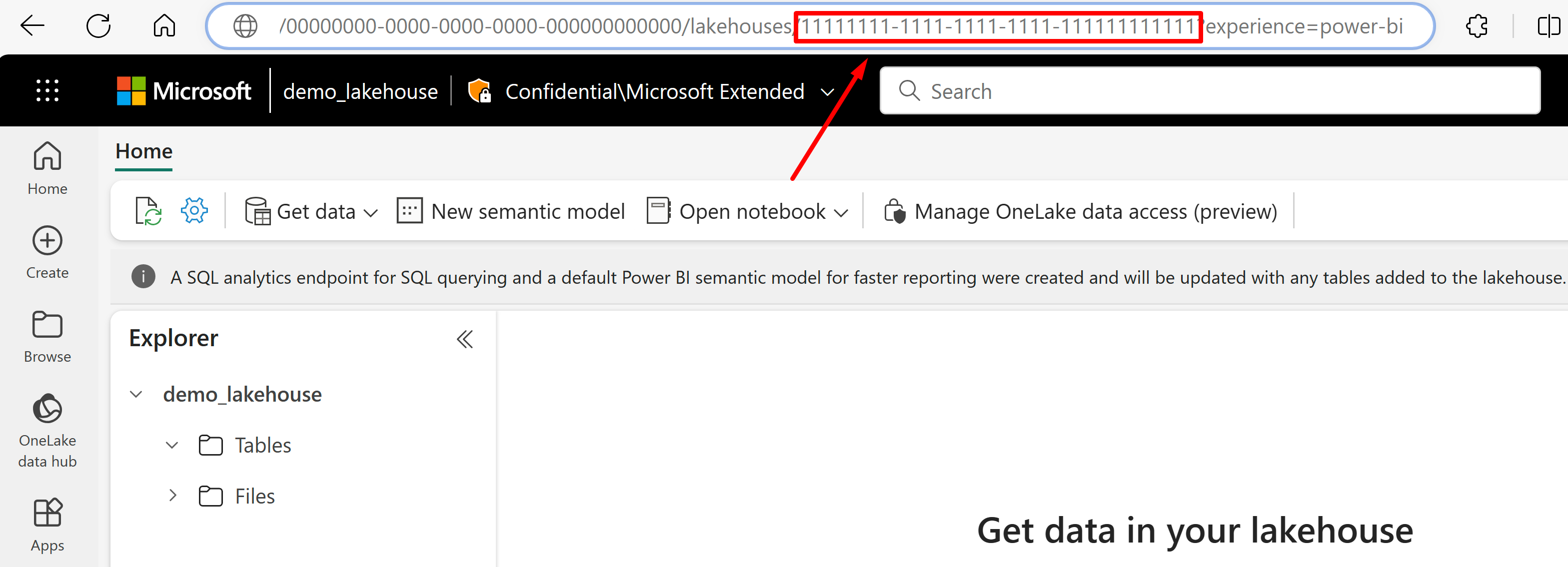
透過將
{FabricWorkspaceGuid}替換為您在上一個步驟中複製的值,將"credentials"設定於 Microsoft Fabric 工作區 GUID。 這是使用您稍後在本指南中會設定之受控識別來存取的 OneLake。"credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }將
"container.name"設定於 lakehouse GUID,使用您在上一個步驟中複製的值來取代{lakehouseGuid}。 使用"query"選擇性地指定 lakehouse 子資料夾或捷徑。"container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }使用使用者指派的受控識別來設定驗證方法,或跳至系統受控識別的下一個步驟。
{ "name": "{dataSourceName}", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }, "identity": { "@odata.type": "Microsoft.Azure.Search.DataUserAssignedIdentity", "userAssignedIdentity": "{userAssignedManagedIdentity}" } }透過存取在 [屬性] 底下的
{userAssignedManagedIdentity}資源,即可找到userAssignedIdentity值,其稱為Id。
範例:
{ "name": "mydatasource", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId=00000000-0000-0000-0000-000000000000" }, "container": { "name": "11111111-1111-1111-1111-111111111111", "query": "folder_name" }, "identity": { "@odata.type": "Microsoft.Azure.Search.DataUserAssignedIdentity", "userAssignedIdentity": "/subscriptions/333333-3333-3333-3333-33333333/resourcegroups/myresourcegroup/providers/Microsoft.ManagedIdentity/userAssignedIdentities/demo-mi" } }您可以選擇性地改用系統指派的受控識別。 如果使用系統指派的受控識別,則會從定義中移除「身分識別」。
{ "name": "{dataSourceName}", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" } }範例:
{ "name": "mydatasource", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId=00000000-0000-0000-0000-000000000000" }, "container": { "name": "11111111-1111-1111-1111-111111111111", "query": "folder_name" } }



透過自訂中繼資料偵測刪除
如果您希望索引子在來源文件標幟為刪除時刪除搜尋文件,則 OneLake 檔案索引子資料來源定義可以包含虛刪除原則。
要啟用自動檔案刪除,請使用自訂中繼資料來指出搜尋文件是否應從索引中移除。
工作流程需要三個不同的動作:
- 「虛刪除」OneLake 中的檔案
- 索引子會刪除索引中的搜尋文件
- 「實刪除」OneLake 中的檔案
「虛刪除」會告訴索引子該怎麼做 (刪除搜尋文件)。 如果您先刪除 OneLake 中的實體檔案,索引子將無法讀取任何內容,而且索引中的對應搜尋文件會被孤立。
OneLake 和 Azure AI 搜尋服務中都有要遵循的步驟,但沒有其他的功能相依性。
在 lakehouse 檔案中,將自訂中繼資料機碼值組新增至檔案,以指出該檔案已標幟為要刪除。 例如,您可以將屬性命名為 "IsDeleted",設為 false。 當您想刪除檔案時,請將其變更為 true。
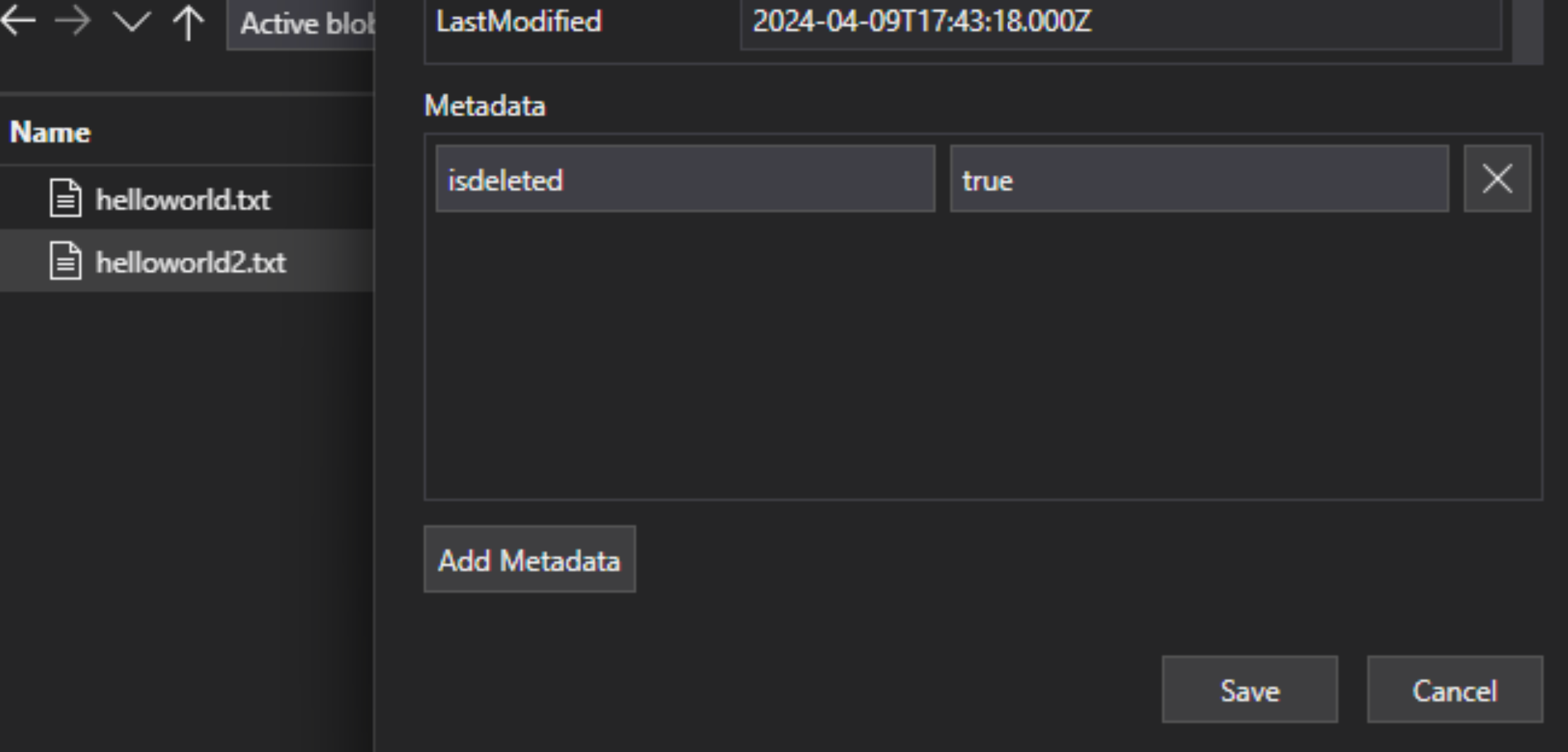
在 Azure AI 搜尋服務中,編輯資料來源定義以包含 "dataDeletionDetectionPolicy" 屬性。 例如,如果檔案有值為 true 的中繼資料屬性「IsDeleted」,則下列原則會認為檔案應被刪除:
PUT https://[service name].search.windows.net/datasources/file-datasource?api-version=2024-05-01-preview { "name" : "onelake-datasource", "type" : "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }, "dataDeletionDetectionPolicy" : { "@odata.type" :"#Microsoft.Azure.Search.SoftDeleteColumnDeletionDetectionPolicy", "softDeleteColumnName" : "IsDeleted", "softDeleteMarkerValue" : "true" } }

在索引子執行並從搜尋索引中刪除文件之後,您即可在資料湖中刪除實體檔案。
一些重點包括:
排程索引子執行有助於將此流程自動化。 我們建議為所有累加編製索引案例進行排程。
如果未在第一次索引子執行時設定刪除偵測原則,您必須重設索引子,以便讀取更新的設定。
請記住,由於自訂中繼資料的相依性,Amazon S3 和 Google Cloud Storage 捷徑不支援刪除偵測。
將搜尋欄位新增至索引
在搜尋索引中,新增欄位以接受 OneLake 資料湖檔案的內容和中繼資料。
建立或更新索引以定義搜尋欄位來儲存檔案內容和中繼資料:
{ "name" : "my-search-index", "fields": [ { "name": "ID", "type": "Edm.String", "key": true, "searchable": false }, { "name": "content", "type": "Edm.String", "searchable": true, "filterable": false }, { "name": "metadata_storage_name", "type": "Edm.String", "searchable": false, "filterable": true, "sortable": true }, { "name": "metadata_storage_size", "type": "Edm.Int64", "searchable": false, "filterable": true, "sortable": true }, { "name": "metadata_storage_content_type", "type": "Edm.String", "searchable": false, "filterable": true, "sortable": true } ] }建立文件索引鍵欄位 ("key": true)。 針對檔案內容,最佳候選項目是中繼資料屬性。
metadata_storage_path(預設) 物件或檔案的完整路徑。 索引鍵欄位 (此範例為「識別碼」) 會填入來自 metadata_storage_path 的值,因為這是預設。metadata_storage_name,只有名稱是唯一名稱時,才能使用。 如果您要此欄位作為索引鍵,請將"key": true移至此欄位的定義。您新增至檔案的自訂中繼資料屬性。 此選項需要檔案上傳流程新增該中繼資料屬性至所有 Blob。 由於索引鍵是必要屬性,遺漏值的任何檔案即無法編製索引。 如果您使用自訂中繼資料屬性作為索引鍵,請避免變更該屬性。 如果索引鍵屬性變更,索引子會針對相同的檔案新增重複文件。
中繼資料屬性通常包含對文件索引鍵無效的字元,例如
/和-。 因為使用「base64EncodeKeys」屬性 (預設為 true),索引子會自動編碼中繼資料屬性,而不需要設定或欄位對應。透過檔案的「內容」屬性,新增「內容」欄位以儲存從每個檔案擷取的文字。 您不必使用此名稱,但這麼做即可利用隱含欄位對應。
設定並執行 OneLake 檔案索引器
建立索引和資料來源之後,您就可以開始建立索引子。 索引子會設定指定輸入、參數和屬性,控制執行階段行為。 您也可指定要編製索引的 Blob 部分。
透過命名索引子並參考資料來源和目標索引,建立或更新索引子:
{ "name" : "my-onelake-indexer", "dataSourceName" : "my-onelake-datasource", "targetIndexName" : "my-search-index", "parameters": { "batchSize": null, "maxFailedItems": null, "maxFailedItemsPerBatch": null, "base64EncodeKeys": null, "configuration": { "indexedFileNameExtensions" : ".pdf,.docx", "excludedFileNameExtensions" : ".png,.jpeg", "dataToExtract": "contentAndMetadata", "parsingMode": "default" } }, "schedule" : { }, "fieldMappings" : [ ] }如果預設值 (10 份文件) 使用量過低或對可用資源負荷過大,請設定 "batchSize"。 預設批次大小是資料來源特定。 基於平均文件大小較大的考量,檔案索引會將批次大小設為 10 個文件。
在「設定」下,根據檔案類型控制要編製索引的檔案,或不指定檔案類型,以擷取所有檔案。
針對
"indexedFileNameExtensions",提供副檔名的逗號分隔清單 (包含前置點)。 針對"excludedFileNameExtensions"執行相同動作,並指出要跳過的副檔名。 若兩份清單中有相同的副檔名,則會排除在索引編製外。在「設定」下,設定「dataToExtract」以控制要編製索引的檔案部位:
“contentAndMetadata” 是預設值。 它指定所有中繼資料和從檔案擷取的文字內容要編製索引。
「storageMetadata」指定只有標準檔案屬性和使用者指定的中繼資料要編製索引。 雖然 Azure Blob 會記錄這些屬性,但 OneLkae 的檔案屬性相同,惟 SAS 相關的中繼資料除外。
「allMetadata」指定從檔案內容擷取標準檔案屬性,和任何找到內容類型的中繼資料,然後編製索引。
如果檔案對應多個搜尋文件,或其包含純文字、JSON 文件或 CSV 檔案,請在「設定」下,設定「parsingMode」。
如果欄位名稱或類型有差異,或如果您在搜尋索引中需要來源欄位的多個版本,請指定欄位對應。
在編製檔案索引時,您通常可以省略欄位對應,因為索引子具備內建支援,可將 "content" 和中繼資料屬性對應至索引中具有類似名稱和類型的欄位。 針對中繼資料屬性,索引子會在搜尋索引中自動以底線取代連字號
-。
如需其他屬性的詳細資訊,請參閱建立索引子。 如需參數描述的完整清單,請參閱 REST API 中的 Blob 設定參數。 OneLake 的參數相同。
根據預設,索引子建立後會自動執行。 您可以將 [已停用] 設定為 true,以變更此行為。 若要控制索引子執行,請視需要執行索引子或排程執行索引子。
檢查索引子狀態
了解多種方式以在這裡監視索引子狀態和執行歷程記錄:
處理錯誤
編製索引期間常發生的錯誤包括內容類型不支援、內容遺漏或檔案過大。 根據預設,一旦遇到不受支援內容類型的檔案時,OneLake 檔案索引子就會停止。 不過,您可能需要繼續編製索引 (即使發生錯誤),並在稍後偵錯個別文件。
暫時性錯誤對於涉及多個平台和產品的解決方案來說很常見。 不過,如果您將索引子保留在排程 (例如每 5 分鐘),索引子應該能夠從接下來執行中的錯誤復原。
發生錯誤時,有五個索引子屬性可控制索引子的回應。
{
"parameters" : {
"maxFailedItems" : 10,
"maxFailedItemsPerBatch" : 10,
"configuration" : {
"failOnUnsupportedContentType" : false,
"failOnUnprocessableDocument" : false,
"indexStorageMetadataOnlyForOversizedDocuments": false
}
}
}
| 參數 | 有效值 | 描述 |
|---|---|---|
| 「maxFailedItems」 | -1、null 或 0、正整數 | 如果處理期間 (剖析 Blob 或新增文件至索引時) 發生任何錯誤,仍要繼續編製索引, 請將這些屬性設為可接受失敗的次數。 無論錯誤發生的次數,-1 的值允許繼續編製索引。 否則,此值為正整數。 |
| 「maxFailedItemsPerBatch」 | -1、null 或 0、正整數 | 同上,但用於批次編製索引。 |
| 「failOnUnsupportedContentType」 | [True] 或 [False] | 如果索引子無法判斷內容類型,請指定是否繼續或放棄作業。 |
| 「failOnUnprocessableDocument」 | [True] 或 [False] | 如果索引子無法處理其他支援內容類型的文件,請指定是否繼續或放棄作業。 |
| 「indexStorageMetadataOnlyForOversizedDocuments」 | [True] 或 [False] | 預設會將過大的 Blob 視為錯誤。 如果您將此參數設定為 true,則即使無法編製內容索引,索引子仍會嘗試編製其中繼資料索引。 有關 Blob 的大小限制,請參閱服務限制。 |
下一步
檢閱匯入和向量化資料精靈的運作方式,並針對此索引子進行嘗試。 您可以使用整合向量化,並使用預設結構描述為向量或混合式搜尋來區塊化和建立內嵌。
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應