Data Factory in Microsoft Fabric 中的分隔文字格式
本文概述如何在 Microsoft Fabric 的 Data Factory 資料管線中設定分隔文字格式。
下列活動和連接器支援分隔文字格式做為來源和目的地。
| 類別 | 連接器/活動 |
|---|---|
| 支援的連接器 | Amazon S3 |
| Amazon S3 相容 | |
| Azure Blob 儲存體 | |
| Azure Data Lake Storage Gen1 | |
| Azure Data Lake Storage Gen2 \(部分機器翻譯\) | |
| Azure 檔案 | |
| 檔案系統 | |
| FTP | |
| Google Cloud Storage | |
| HTTP | |
| Lakehouse 檔案 | |
| Oracle 雲端儲存空間 | |
| SFTP | |
| 支援的活動 | 複製活動(來源/目的地) |
| 查閱活動 | |
| GetMetadata 活動 | |
| 刪除活動 |
若要設定分隔文字格式,請在資料管線複製活動的來源或目的地中選擇您的連線,然後在 [檔案格式] 下拉式清單中選取 [DelimitedText]。 選取 [設定 ] 以進一步設定此格式。
選取 [檔案格式中的設定] 區段之後,快顯 [檔案格式設定] 對話框中會顯示下列屬性。
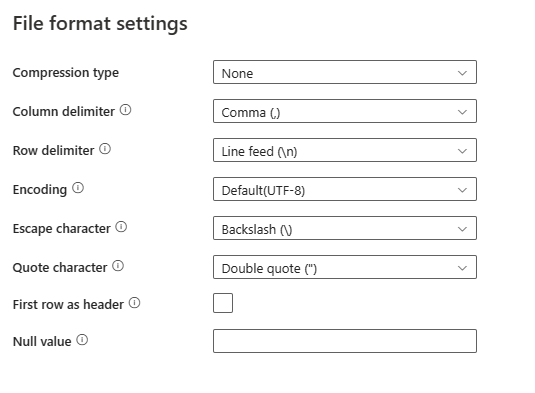
壓縮類型:用來讀取分隔符號文字檔的壓縮編解碼器。 您可以在下拉式清單中選擇 None、bzip2、gzip、deflate、ZipDeflate、TarGzip 或 tar 類型。
如果您選取 ZipDeflate 作為壓縮類型,則系統會在來源索引標籤中的進階設定下顯示保留 zip 檔案名稱作為資料夾。
- 保留 zip 檔案名稱為資料夾:指示是否要在複製期間將來源 zip 檔案名稱保留為資料夾結構。
- 如果核取此方塊(預設值),服務會將解壓縮的檔案寫入至
<specified file path>/<folder named as source zip file>/。 - 如果未核取此方塊,服務會將解壓縮的檔案直接寫入 。
<specified file path>請確定不同的來源 ZIP 檔案中沒有重複的檔案名稱,以避免發生競爭或非預期的行為。
- 如果核取此方塊(預設值),服務會將解壓縮的檔案寫入至
如果您選取 TarGzip/tar 作為壓縮類型,則系統會在來源索引標籤中的進階設定下顯示保留壓縮檔案名稱作為資料夾。
- 保留壓縮檔案名稱為資料夾:指示是否要在複製期間將來源壓縮檔案名稱保留為資料夾結構。
- 如果核取此方塊(預設值),服務會將解壓縮的檔案寫入至
<specified file path>/<folder named as source compressed file>/。 - 如果未核取此方塊,服務會將解壓縮的檔案直接寫入 。
<specified file path>請確定不同的來源 ZIP 檔案中沒有重複的檔案名稱,以避免發生競爭或非預期的行為。
- 如果核取此方塊(預設值),服務會將解壓縮的檔案寫入至
- 保留 zip 檔案名稱為資料夾:指示是否要在複製期間將來源 zip 檔案名稱保留為資料夾結構。
壓縮層級:當您選取壓縮類型時,請指定壓縮比例。 您可以選擇最佳或最快。
- Fastest:即使產生的檔案不以最佳方式壓縮,也應盡快完成壓縮作業。
- Optimal:即使作業需要較長時間完成,壓縮作業也應以最佳方式壓縮。 如需詳細資訊,請參閱 壓縮層級 主題。
資料行分隔符號:用來分隔檔案中的資料行的字元。 預設值為逗號 (
,)。資料列分隔符號:指定用來分隔檔案中資料列的字元。 只允許一個字元。 預設值為換行字元
\n。編碼:用來讀取/寫入測試檔案的編碼類型。 預設值為 UTF-8。
逸出字元:在已加上引號的值內逸出引號的單一字元。 預設值為反斜線
\。 當逸出字元定義為空字串時,必須也將引號字元設為空字串,在此情況下,請確定所有資料行值不包含分隔符號。引號字元:如果包含資料行分隔符號,用於括住資料行值的單一字元。 預設值為雙引號
"。 當引號字元定義為空字串時,表示沒有引號字元,資料行值未加上引號,而且逸出字元會用於逸出資料行分隔符號及其本身。第一個資料列為標題:指定是否要將第一個資料列視為具有資料行名稱的標頭行。 允許的值會選取且未選取 (預設值)。 未選取第一個資料列做為標頭時,請注意,UI 資料預覽和查詢活動輸出會自動產生名稱為 Prop_{n} (從 0 開始) 的資料行,複製活動需要從來源明確對應至目的地,並依序 (從 1 開始) 找出資料行。
Null 值:指定 Null 值的字串表示法。 預設值是空字串。
在 [來源] 索引標籤的 [進階設定] 底下,會公開其他分隔文字格式相關屬性。
選取 [檔案格式中的設定] 區段之後,快顯 [檔案格式設定] 對話框中會顯示下列屬性。
壓縮類型:用來寫入分隔符號文字檔的壓縮編解碼器。 您可以在下拉式清單中選擇 None、bzip2、gzip、deflate、ZipDeflate、TarGzip 或 tar 類型。
壓縮層級:當您選取壓縮類型時,請指定壓縮比例。 您可以選擇最佳或最快。
- Fastest:即使產生的檔案不以最佳方式壓縮,也應盡快完成壓縮作業。
- Optimal:即使作業需要較長時間完成,壓縮作業也應以最佳方式壓縮。 如需詳細資訊,請參閱 壓縮層級 主題。
資料行分隔符號:用來分隔檔案中的資料行的字元。 預設值為逗號 (
,)。ROW 分隔符號:用來分隔檔案中資料列的字元。 只允許一個字元。 預設值為換行字元
\n。編碼:用於寫入測試檔案的編碼類型。 預設值為 UTF-8。
逸出字元:在已加上引號的值內逸出引號的單一字元。 預設值為反斜線
\。 當逸出字元定義為空字串時,必須也將引號字元設為空字串,在此情況下,請確定所有資料行值不包含分隔符號。引號字元:如果包含資料行分隔符號,用於括住資料行值的單一字元。 預設值為雙引號
"。 當引號字元定義為空字串時,表示沒有引號字元,資料行值未加上引號,而且逸出字元會用於逸出資料行分隔符號及其本身。第一個資料列為標題:指定是否要將第一個資料列視為具有資料行名稱的標頭行。 允許的值會選取且未選取 (預設值)。 未選取第一個資料列做為標頭時,請注意,UI 資料預覽和查詢活動輸出會自動產生名稱為 Prop_{n} (從 0 開始) 的資料行,複製活動需要從來源明確對應至目的地,並依序 (從 1 開始) 找出資料行。
Null 值:指定 Null 值的字串表示法。 預設值是空字串。
在 [目的地] 索引標籤的 [進階設定] 底下,會顯示進一步分隔的文字格式相關屬性。
全部加上引號:以引號括住所有值。
副檔名:用來命名輸出檔案的副檔名,例如
.csv、.txt。每個檔案的資料列數上限:當您將資料寫入資料夾時,可以選擇寫入多個檔案,並指定每個檔案的資料列數上限。
檔名前置詞:適用於設定每個檔案的資料列上限時。 當您將資料寫入多個檔案時,請指定檔案名稱前置詞,使系統進行此模式:
<fileNamePrefix>_00000.<fileExtension>。 如果未指定,系統會自動產生檔案名稱前置詞。 當來源是以檔案為基礎的存放區,或啟用資料分割選項的資料存放區時,系統不會套用此屬性。
使用分隔文字格式時,支援複製活動來源區段支援下列屬性。
| 名稱 | 描述 | 值 | 必填 | JSON 腳本屬性 |
|---|---|---|---|---|
| 檔案格式 | 選取要使用的檔案格式。 | DelimitedText | Yes | type (在 datasetSettings 下):DelimitedText |
| 壓縮類型 | 用來讀取分隔符號文字檔的壓縮編解碼器。 | 從下列項目中選擇: None bzip2 gzip deflate ZipDeflate TarGzip tar |
No | type (在 compression 下):bzip2 gzip deflate ZipDeflate TarGzip tar |
| 將 zip 檔名保留為資料夾 | 指出是否要在複製期間保留來源 ZIP 檔案名稱做為資料夾結構。 當您選取 [ZipDeflate 壓縮] 時適用。 | 已選取或取消選取 | 無 | preserveZipFileNameAsFolder ( compressionProperties->type 下為 ZipDeflateReadSettings) |
| 將壓縮檔名保留為資料夾 | 指出是否要在複製期間保留來源壓縮檔案名稱做為資料夾結構。 當您選取 TarGzip/tar 壓縮時適用。 | 已選取或取消選取 | No | preserveCompressionFileNameAsFolder ( compressionProperties->type 下為 TarGZipReadSettings 或 TarReadSettings) |
| 壓縮層級 | 壓縮比。 允許的值為 Optimal 或 Fastest。 | 最佳 或 最快 | 無 | 層級 (下 compression):最快 最佳 |
| 資料行分隔符號 | 用來分隔檔案中的資料行的字元。 | < 選取的資料行分隔符號 > 逗號 , (預設) |
No | columnDelimiter |
| 資料列分隔符號 | 用來分隔檔案中資料列的字元。 | < 選取的資料列分隔符號 > \r、\n (預設為),或 r\n |
無 | rowDelimiter |
| 編碼方式 | 用來讀取/寫入測試檔案的編碼類型。 | "UTF-8" (依預設)、"UTF-8 without BOM"、"UTF-16"、"UTF-16BE"、"UTF-32"、"UTF-32BE"、"US-ASCII"、"UTF-7"、"BIG5"、"EUC-JP"、"EUC-KR"、"GB2312"、"GB18030"、"JOHAB"、"SHIFT-JIS"、"CP875"、"CP866"、"IBM00858"、"IBM037"、"IBM273"、"IBM437"、"IBM500"、"IBM737"、"IBM775"、"IBM850"、"IBM852"、"IBM855"、"IBM857"、"IBM860"、"IBM861"、"IBM863"、"IBM864"、"IBM865"、"IBM869"、"IBM870"、"IBM01140"、"IBM01141"、"IBM01142"、"IBM01143"、"IBM01144"、"IBM01145"、"IBM01146"、"IBM01147"、"IBM01148"、"IBM01149"、"ISO-2022-JP"、"ISO-2022-KR"、"ISO-8859-1"、"ISO-8859-2"、"ISO-8859-3"、"ISO-8859-4"、"ISO-8859-5"、"ISO-8859-6"、"ISO-8859-7"、"ISO-8859-8"、"ISO-8859-9"、"ISO-8859-13"、"ISO-8859-15"、"WINDOWS-874"、"WINDOWS-1250"、"WINDOWS-1251"、"WINDOWS-1252"、"WINDOWS-1253"、"WINDOWS-1254"、"WINDOWS-1255"、"WINDOWS-1256"、"WINDOWS-1257"、"WINDOWS-1258" | 無 | encodingName |
| 逸出字元 | 在已加上引號的值內逸出引號的單一字元。 當逸出字元定義為空字串時,必須也將引號字元設為空字串,在此情況下,請確定所有資料行值不包含分隔符號。 | < 您選取的逸出字元 > 反斜杠 \ (預設) |
No | escapeChar |
| 引號字元 | 如果包含資料行分隔符號,用於括住資料行值的單一字元。 當引號字元定義為空字串時,表示沒有引號字元,資料行值未加上引號,而且逸出字元會用於逸出資料行分隔符號及其本身。 | < 您選取的引號字元 > 雙引號 " (預設) |
No | quoteChar |
| 第一列作為標題 | 指定是否視指定工作表/範圍中的第一個資料列,為包含資料行名稱的標題行。 | 已選取或未選取 | No | firstRowAsHeader: true 或 false (預設值) |
| NULL 值 | 指定 Null 值的字串表示法。 預設值是空字串。 | < Null 值的字串表示法 > 空字串 (預設) |
No | nullValue |
使用分隔文字格式時,複製活動 目的地 區段支援下列屬性。
| 名稱 | 描述 | 值 | 必填 | JSON 腳本屬性 |
|---|---|---|---|---|
| 檔案格式 | 選取要使用的檔案格式。 | DelimitedText | Yes | type (在 datasetSettings 下):DelimitedText |
| 壓縮類型 | 用來寫入分隔符號文字檔的壓縮編解碼器。 | 從下列項目中選擇: None bzip2 gzip deflate ZipDeflate TarGzip tar |
No | type (在 compression 下):bzip2 gzip deflate ZipDeflate TarGzip tar |
| 將 zip 檔名保留為資料夾 | 指出是否要在複製期間保留來源 ZIP 檔案名稱做為資料夾結構。 | 已選取或取消選取 | 無 | preserveZipFileNameAsFolder ( compressionProperties->type 下為 ZipDeflateReadSettings) |
| 將壓縮檔名保留為資料夾 | 指出是否要在複製期間保留來源壓縮檔案名稱做為資料夾結構。 | 已選取或取消選取 | No | preserveCompressionFileNameAsFolder ( compressionProperties->type 下為 TarGZipReadSettings 或 TarReadSettings) |
| 壓縮層級 | 壓縮比。 允許的值為 Optimal 或 Fastest。 | 最佳 或 最快 | 無 | 層級 (下 compression):最快 最佳 |
| 資料行分隔符號 | 用來分隔檔案中的資料行的字元。 | < 選取的資料行分隔符號 > 逗號 , (預設) |
No | columnDelimiter |
| 資料列分隔符號 | 用來分隔檔案中資料列的字元。 | < 選取的資料列分隔符號 > \r、\n (預設為),或 r\n |
無 | rowDelimiter |
| 編碼方式 | 用來讀取/寫入測試檔案的編碼類型。 | "UTF-8" (依預設)、"UTF-8 without BOM"、"UTF-16"、"UTF-16BE"、"UTF-32"、"UTF-32BE"、"US-ASCII"、"UTF-7"、"BIG5"、"EUC-JP"、"EUC-KR"、"GB2312"、"GB18030"、"JOHAB"、"SHIFT-JIS"、"CP875"、"CP866"、"IBM00858"、"IBM037"、"IBM273"、"IBM437"、"IBM500"、"IBM737"、"IBM775"、"IBM850"、"IBM852"、"IBM855"、"IBM857"、"IBM860"、"IBM861"、"IBM863"、"IBM864"、"IBM865"、"IBM869"、"IBM870"、"IBM01140"、"IBM01141"、"IBM01142"、"IBM01143"、"IBM01144"、"IBM01145"、"IBM01146"、"IBM01147"、"IBM01148"、"IBM01149"、"ISO-2022-JP"、"ISO-2022-KR"、"ISO-8859-1"、"ISO-8859-2"、"ISO-8859-3"、"ISO-8859-4"、"ISO-8859-5"、"ISO-8859-6"、"ISO-8859-7"、"ISO-8859-8"、"ISO-8859-9"、"ISO-8859-13"、"ISO-8859-15"、"WINDOWS-874"、"WINDOWS-1250"、"WINDOWS-1251"、"WINDOWS-1252"、"WINDOWS-1253"、"WINDOWS-1254"、"WINDOWS-1255"、"WINDOWS-1256"、"WINDOWS-1257"、"WINDOWS-1258" | 無 | encodingName |
| 逸出字元 | 在已加上引號的值內逸出引號的單一字元。 當逸出字元定義為空字串時,必須也將引號字元設為空字串,在此情況下,請確定所有資料行值不包含分隔符號。 | < 您選取的逸出字元 > 反斜杠 \ (預設) |
No | escapeChar |
| 引號字元 | 如果包含資料行分隔符號,用於括住資料行值的單一字元。 當引號字元定義為空字串時,表示沒有引號字元,資料行值未加上引號,而且逸出字元會用於逸出資料行分隔符號及其本身。 | < 您選取的引號字元 > 雙引號 " (預設) |
No | quoteChar |
| 第一列作為標題 | 指定是否視指定工作表/範圍中的第一個資料列,為包含資料行名稱的標題行。 | 已選取或未選取 | No | firstRowAsHeader: true 或 false (預設值) |
| 將所有文字加上引號 | 以引號括住所有值。 | 已選取 (預設值) 或未選取 | No | quoteAllText: true (預設) 或 false |
| 副檔名 | 用來命名輸出檔案的副檔名。 | < 您的副檔名 > .txt (預設) |
No | fileExtension |
| 每個檔案的最大資料列 | 當您將資料寫入資料夾時,可以選擇寫入多個檔案,並指定每個檔案的資料列數上限。 | < 每個檔案的資料列數上限 > | No | maxRowsPerFile |
| 檔名前置詞 | 適用於設定 每個檔案 的資料列上限時。 當您將資料寫入多個檔案時,請指定檔案名稱前置詞,使系統進行此模式:<fileNamePrefix>_00000.<fileExtension>。 如果未指定,系統會自動產生檔案名稱前置詞。 當來源是以檔案為基礎的存放區,或啟用資料分割選項的資料存放區時,系統不會套用此屬性。 |
< 您的檔名前置詞 > | No | fileNamePrefix |