Events
Mar 31, 11 PM - Apr 2, 11 PM
The biggest Fabric, Power BI, and SQL learning event. March 31 – April 2. Use code FABINSIDER to save $400.
Register todayThis browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
This article outlines how to configure delimited text format in the data pipeline of Data Factory in Microsoft Fabric.
Delimited text format is supported for the following activities and connectors as source and destination.
| Category | Connector/Activity |
|---|---|
| Supported connector | Amazon S3 |
| Amazon S3 Compatible | |
| Azure Blob Storage | |
| Azure Data Lake Storage Gen1 | |
| Azure Data Lake Storage Gen2 | |
| Azure Files | |
| File system | |
| FTP | |
| Google Cloud Storage | |
| HTTP | |
| Lakehouse Files | |
| Oracle Cloud Storage | |
| SFTP | |
| Supported activity | Copy activity (source/destination) |
| Lookup activity | |
| GetMetadata activity | |
| Delete activity |
To configure delimited text format, choose your connection in the source or destination of data pipeline copy activity, and then select DelimitedText in the drop-down list of File format. Select Settings for further configuration of this format.
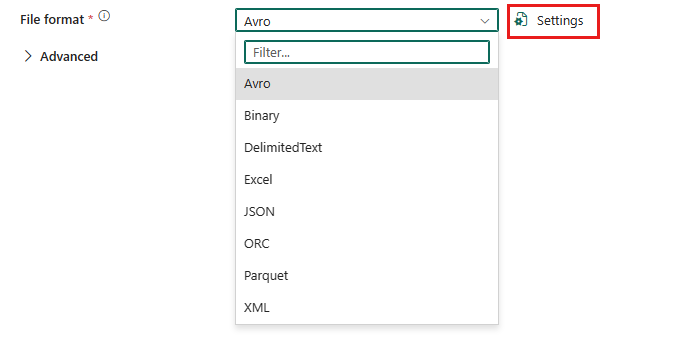
After selecting Settings in File format section, following properties are shown up in the pop-up File format settings dialog box.
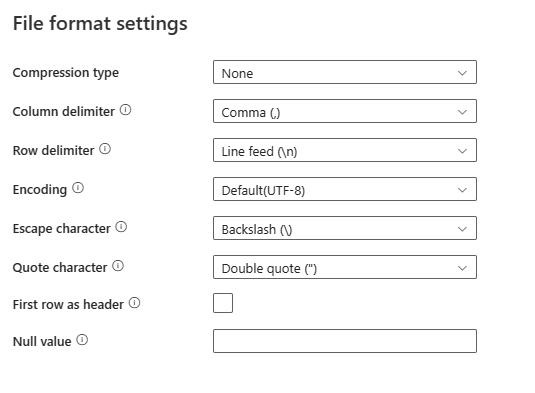
Compression type: The compression codec used to read delimited text files. You can choose from None, bzip2, gzip, deflate, ZipDeflate, TarGzip or tar type in the drop-down list.
If you select ZipDeflate as compression type, Preserve zip file name as folder will show up under Advanced settings in Source tab.
<specified file path>/<folder named as source zip file>/.<specified file path>. Make sure you don't have duplicated file names in different source zip files to avoid racing or unexpected behavior.If you select TarGzip/tar as compression type, Preserve compression file name as folder will show up under Advanced settings in Source tab.
<specified file path>/<folder named as source compressed file>/.<specified file path>. Make sure you don't have duplicated file names in different source zip files to avoid racing or unexpected behavior.Compression level: Specify the compression ratio when you select a compression type. You can choose from Optimal or Fastest.
Column delimiter: The character(s) used to separate columns in a file. The default value is comma (,).
Row delimiter: Specify the character used to separate rows in a file. Only one character is allowed. The default value is line feed \n.
Encoding: The encoding type used to read/write test files. The default value is UTF-8.
Escape character: The single character to escape quotes inside a quoted value. The default value is backslash \. When escape character is defined as empty string, the Quote character must be set as empty string as well, in which case make sure all column values don't contain delimiters.
Quote character: The single character to quote column values if it contains column delimiter. The default value is double quotes ". When Quote character is defined as empty string, it means there is no quote char and column value is not quoted, and escape character is used to escape the column delimiter and itself.
First row as header: Specifies whether to treat/make the first row as a header line with names of columns. Allowed values are selected and unselected (default). When first row as header is unselected, note UI data preview and lookup activity output auto generate column names as Prop_{n} (starting from 0), copy activity requires explicit mapping from source to destination and locates columns by ordinal (starting from 1).
Null value: Specifies the string representation of null value. The default value is empty string.
Under Advanced settings in Source tab, other delimited text format related properties are exposed.
After selecting Settings in File format section, following properties are shown up in the pop-up File format settings dialog box.
Compression type: The compression codec used to write delimited text files. You can choose from None, bzip2, gzip, deflate, ZipDeflate, TarGzip or tar type in the drop-down list.
Compression level: Specify the compression ratio when you select a compression type. You can choose from Optimal or Fastest.
Column delimiter: The character(s) used to separate columns in a file. The default value is comma (,).
Row delimiter: The character used to separate rows in a file. Only one character is allowed. The default value is line feed \n.
Encoding: The encoding type used to write test files. The default value is UTF-8.
Escape character: The single character to escape quotes inside a quoted value. The default value is backslash \. When escape character is defined as empty string, the Quote character must be set as empty string as well, in which case make sure all column values don't contain delimiters.
Quote character: The single character to quote column values if it contains column delimiter. The default value is double quotes ". When Quote character is defined as empty string, it means there is no quote char and column value is not quoted, and escape character is used to escape the column delimiter and itself.
First row as header: Specifies whether to treat/make the first row as a header line with names of columns. Allowed values are selected and unselected (default). When first row as header is unselected, note UI data preview and lookup activity output auto generate column names as Prop_{n} (starting from 0), copy activity requires explicit mapping from source to destination and locates columns by ordinal (starting from 1).
Null value: Specifies the string representation of null value. The default value is empty string.
Under Advanced settings in Destination tab, further delimited text format related property are shown up.
Quote all text: Enclose all values in quotes.
File extension: The file extension used to name the output files, for example, .csv, .txt.
Max rows per file: When writing data into a folder, you can choose to write to multiple files and specify the max rows per file.
File name prefix: Applicable when Max rows per file is configured. Specify the file name prefix when writing data to multiple files, resulted in this pattern: <fileNamePrefix>_00000.<fileExtension>. If not specified, file name prefix will be auto generated. This property does not apply when source is file based store or partition option enabled data store.
The following properties are supported in the copy activity Source section when using delimited text format.
| Name | Description | Value | Required | JSON script property |
|---|---|---|---|---|
| File format | The file format that you want to use. | DelimitedText | Yes | type (under datasetSettings):DelimitedText |
| Compression type | The compression codec used to read delimited text files. | Choose from: None bzip2 gzip deflate ZipDeflate TarGzip tar |
No | type (under compression): bzip2 gzip deflate ZipDeflate TarGzip tar |
| Preserve zip file name as folder | Indicates whether to preserve the source zip file name as folder structure during copy. Applies when you select ZipDeflate compression. | Selected or unselect | No | preserveZipFileNameAsFolder (under compressionProperties->type as ZipDeflateReadSettings) |
| Preserve compression file name as folder | Indicates whether to preserve the source compressed file name as folder structure during copy. Applies when you select TarGzip/tar compression. | Selected or unselect | No | preserveCompressionFileNameAsFolder (under compressionProperties->type as TarGZipReadSettings or TarReadSettings) |
| Compression level | The compression ratio. Allowed values are Optimal or Fastest. | Optimal or Fastest | No | level (under compression): Fastest Optimal |
| Column delimiter | The character(s) used to separate columns in a file. | < the selected column delimiter > comma , (by default) |
No | columnDelimiter |
| Row delimiter | The character used to separate rows in a file. | < the selected row delimiter > \r,\n (by default), or r\n |
No | rowDelimiter |
| Encoding | The encoding type used to read/write test files. | "UTF-8" (by default),"UTF-8 without BOM", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "US-ASCII", "UTF-7", "BIG5", "EUC-JP", "EUC-KR", "GB2312", "GB18030", "JOHAB", "SHIFT-JIS", "CP875", "CP866", "IBM00858", "IBM037", "IBM273", "IBM437", "IBM500", "IBM737", "IBM775", "IBM850", "IBM852", "IBM855", "IBM857", "IBM860", "IBM861", "IBM863", "IBM864", "IBM865", "IBM869", "IBM870", "IBM01140", "IBM01141", "IBM01142", "IBM01143", "IBM01144", "IBM01145", "IBM01146", "IBM01147", "IBM01148", "IBM01149", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-3", "ISO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "ISO-8859-13", "ISO-8859-15", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255", "WINDOWS-1256", "WINDOWS-1257", "WINDOWS-1258" | No | encodingName |
| Escape character | The single character to escape quotes inside a quoted value. When escape character is defined as empty string, the Quote character must be set as empty string as well, in which case make sure all column values don't contain delimiters. | < your selected escape character > backslash \ (by default) |
No | escapeChar |
| Quote character | The single character to quote column values if it contains column delimiter. When Quote character is defined as empty string, it means there is no quote char and column value is not quoted, and escape character is used to escape the column delimiter and itself. | < your selected quote character > double quotes " (by default) |
No | quoteChar |
| First row as header | Specifies whether to treat the first row in the given worksheet/range as a header line with names of columns. | Selected or unselected | No | firstRowAsHeader: true or false (default) |
| Null value | Specifies the string representation of null value. The default value is empty string. | < the string representation of null value > empty string (by default) |
No | nullValue |
The following properties are supported in the copy activity Destination section when using delimited text format.
| Name | Description | Value | Required | JSON script property |
|---|---|---|---|---|
| File format | The file format that you want to use. | DelimitedText | Yes | type (under datasetSettings):DelimitedText |
| Compression type | The compression codec used to write delimited text files. | Choose from: None bzip2 gzip deflate ZipDeflate TarGzip tar |
No | type (under compression): bzip2 gzip deflate ZipDeflate TarGzip tar |
| Preserve zip file name as folder | Indicates whether to preserve the source zip file name as folder structure during copy. | Selected or unselect | No | preserveZipFileNameAsFolder (under compressionProperties->type as ZipDeflateReadSettings) |
| Preserve compression file name as folder | Indicates whether to preserve the source compressed file name as folder structure during copy. | Selected or unselect | No | preserveCompressionFileNameAsFolder (under compressionProperties->type as TarGZipReadSettings or TarReadSettings) |
| Compression level | The compression ratio. Allowed values are Optimal or Fastest. | Optimal or Fastest | No | level (under compression): Fastest Optimal |
| Column delimiter | The character(s) used to separate columns in a file. | < the selected column delimiter > comma , (by default) |
No | columnDelimiter |
| Row delimiter | The character used to separate rows in a file. | < the selected row delimiter > \r,\n (by default), or r\n |
No | rowDelimiter |
| Encoding | The encoding type used to read/write test files. | "UTF-8" (by default),"UTF-8 without BOM", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "US-ASCII", "UTF-7", "BIG5", "EUC-JP", "EUC-KR", "GB2312", "GB18030", "JOHAB", "SHIFT-JIS", "CP875", "CP866", "IBM00858", "IBM037", "IBM273", "IBM437", "IBM500", "IBM737", "IBM775", "IBM850", "IBM852", "IBM855", "IBM857", "IBM860", "IBM861", "IBM863", "IBM864", "IBM865", "IBM869", "IBM870", "IBM01140", "IBM01141", "IBM01142", "IBM01143", "IBM01144", "IBM01145", "IBM01146", "IBM01147", "IBM01148", "IBM01149", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-3", "ISO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "ISO-8859-13", "ISO-8859-15", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255", "WINDOWS-1256", "WINDOWS-1257", "WINDOWS-1258" | No | encodingName |
| Escape character | The single character to escape quotes inside a quoted value. When escape character is defined as empty string, the Quote character must be set as empty string as well, in which case make sure all column values don't contain delimiters. | < your selected escape character > backslash \ (by default) |
No | escapeChar |
| Quote character | The single character to quote column values if it contains column delimiter. When Quote character is defined as empty string, it means there is no quote char and column value is not quoted, and escape character is used to escape the column delimiter and itself. | < your selected quote character > double quotes " (by default) |
No | quoteChar |
| First row as header | Specifies whether to treat the first row in the given worksheet/range as a header line with names of columns. | Selected or unselected | No | firstRowAsHeader: true or false (default) |
| Quote all text | Enclose all values in quotes. | Selected (default) or unselected | No | quoteAllText: true (default) or false |
| File extension | The file extension used to name the output files. | < your file extension > .txt (by default) |
No | fileExtension |
| Max rows per file | When writing data into a folder, you can choose to write to multiple files and specify the max rows per file. | < your max rows per file > | No | maxRowsPerFile |
| File name prefix | Applicable when Max rows per file is configured. Specify the file name prefix when writing data to multiple files, resulted in this pattern: <fileNamePrefix>_00000.<fileExtension>. If not specified, file name prefix will be auto generated. This property does not apply when source is file based store or partition option enabled data store. |
< your file name prefix > | No | fileNamePrefix |
Events
Mar 31, 11 PM - Apr 2, 11 PM
The biggest Fabric, Power BI, and SQL learning event. March 31 – April 2. Use code FABINSIDER to save $400.
Register todayTraining
Module
Orchestrate processes and data movement with Microsoft Fabric - Training
Use Data Factory pipelines in Microsoft Fabric
Certification
Microsoft Certified: Fabric Data Engineer Associate - Certifications
As a Fabric Data Engineer, you should have subject matter expertise with data loading patterns, data architectures, and orchestration processes.