本教學課程會說明如何使用語意連結來偵測公用 Synthea 資料集中的關聯性。
當您使用新資料或在沒有現有資料模型的情況下運作時,自動探索關聯性會很有用。 此關聯性偵測可以協助您:
- 了解高階的模型,
- 在探勘資料分析期間取得更多深入解析,
- 驗證已更新的資料或新的、傳入的資料,以及
- 清除資料。
即使事先知曉關聯性,搜尋關聯性也有助於進一步了解資料模型或識別資料品質問題。
在本教學課程中,您會從簡單的基準範例開始,其中您只使用三個資料表進行實驗,讓兩者之間的連線易於遵循。 然後,您會看到更複雜的範例,其中包括較大的資料表集。
在本教學課程中,您會了解如何:
- 使用語意連結之 Python 庫 (SemPy) 的元件,其可支援與 Power BI 整合,並協助自動化資料分析。 這些元件包括:
- FabricDataFrame - 使用其他語意資訊增強的 Pandas 類似結構。
- 將語意模型從 Fabric 工作區提取至筆記本的函數。
- 自動化語意模型中關聯性探索和視覺效果的函數。
- 針對具有多個資料表和相互相依性的語意模型關聯性探索程序進行疑難排解。
必要條件
取得 Microsoft Fabric 訂用帳戶。 或註冊免費的 Microsoft Fabric 試用版。
登入 Microsoft Fabric。
使用首頁左下方的體驗切換器,切換至 Fabric。
![體驗切換器功能表的螢幕擷取畫面,顯示選取 [資料科學] 的位置。](media/tutorial-data-science-prepare-system/switch-to-data-science.png)
- 從左側瀏覽窗格中選取 [工作區],以尋找並選取您的工作區。 此工作區會成為您目前的工作區。
在筆記本中跟著做
本教學課程隨附 relationships_detection_tutorial.ipynb 筆記本。
若要開啟本教學課程隨附的筆記本,請遵循 準備系統以進行數據科學教學課程中的指示, 將筆記本匯入工作區。
如果您想要複製並貼上此頁面中的程式碼,則可以建立新的筆記本。
開始執行程式碼之前,請務必將 Lakehouse 連結至筆記本。
設定筆記本
在本章節中,您會使用必要的模組和資料來設定筆記本環境。
使用筆記本內的
SemPy內嵌安裝功能從 PyPI 安裝%pip:%pip install semantic-link執行您稍後會需要的必要 SemPy 模組匯入:
import pandas as pd from sempy.samples import download_synthea from sempy.relationships import ( find_relationships, list_relationship_violations, plot_relationship_metadata )匯入 Pandas 以強制執行可協助輸出格式化的組態選項:
import pandas as pd pd.set_option('display.max_colwidth', None)拉取範例資料。 在本教學課程中,您會使用綜合醫療記錄的 Synthea 資料集 (簡單的較小版):
download_synthea(which='small')
偵測 Synthea 資料表較小子集的關聯性
從較大的集合中選取三個資料表:
-
patients會指定病患資訊 -
encounters會指定有醫療看診的病患 (例如醫療預約、程序) -
providers會指定哪些醫療供應商負責照顧病患
encounters資料表會解析patients和providers之間的多對多關聯性,可描述為關聯實體:patients = pd.read_csv('synthea/csv/patients.csv') providers = pd.read_csv('synthea/csv/providers.csv') encounters = pd.read_csv('synthea/csv/encounters.csv')-
使用 SemPy 的
find_relationships函數尋找資料表之間的關聯性:suggested_relationships = find_relationships([patients, providers, encounters]) suggested_relationships使用 SemPy 的
plot_relationship_metadata函數,將 DataFrame 關聯性視覺化為關係圖。plot_relationship_metadata(suggested_relationships)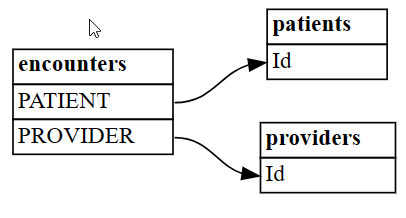
函數會依從左側到右側的順序展示關聯性階層,對應至輸出中的 "from" 和 "to" 資料表。 換句話說,左側的獨立 "from" 資料表會使用其外部索引鍵指向右側的 "to" 相依性資料表。 每個實體方塊都會顯示參與關聯性之 "from" 或 "to" 端的資料行。
根據預設,關聯性會產生為 "m:1" (而不是 "1:m") 或 "1:1"。 可以透過一或兩種方式產生 "1:1" 關聯性,取決於對應值與所有值的比例是否在一或兩個方向中超過
coverage_threshold。 稍後在本教學課程中,會介紹較為不常見的 "m:m" 關聯性情況。

針對關聯性偵測問題進行疑難排解
基準範例會顯示全新 Synthea 資料上成功的關聯性偵測。 在實務上,資料很少是全新的,因此無法成功偵測。 當資料並非全新時,有數種技術很有用。
本教學課程的本章節會討論語意模型包含非全新資料時的關聯性偵測問題。
首先,操作原始 DataFrame 以取得「非全新」資料,並列印非全新資料的大小。
# create a dirty 'patients' dataframe by dropping some rows using head() and duplicating some rows using concat() patients_dirty = pd.concat([patients.head(1000), patients.head(50)], axis=0) # create a dirty 'providers' dataframe by dropping some rows using head() providers_dirty = providers.head(5000) # the dirty dataframes have fewer records than the clean ones print(len(patients_dirty)) print(len(providers_dirty))為了進行比較,列印原始資料表的大小:
print(len(patients)) print(len(providers))使用 SemPy 的
find_relationships函數尋找資料表之間的關聯性:find_relationships([patients_dirty, providers_dirty, encounters])程式碼的輸出顯示,由於您稍早因建立「非全新」語意模型而引入的錯誤,因此沒有偵測到關聯性。
使用驗證
驗證是針對關聯性偵測失敗進行疑難排解的最佳工具,因為:
- 驗證會清楚地報告為什麼特定關聯性未遵循外部索引鍵規則,導致無法偵測到。
- 驗證會使用大型語意模型快速執行,因為它只著重於宣告的關聯性,而且不會執行搜尋。
驗證可以使用任何 DataFrame,其中的資料行與 find_relationships 產生的資料行類似。 在下列程式碼中,suggested_relationships DataFrame 會參考 patients,而不是 patients_dirty,但您可以使用字典為 DataFrame 新增別名:
dirty_tables = {
"patients": patients_dirty,
"providers" : providers_dirty,
"encounters": encounters
}
errors = list_relationship_violations(dirty_tables, suggested_relationships)
errors
放寬搜尋準則
對於更模糊的案例,您可以嘗試放寬搜尋準則。 該方法會增加誤判的可能性。
設定
include_many_to_many=True並評估其是否有用:find_relationships(dirty_tables, include_many_to_many=True, coverage_threshold=1)結果顯示偵測到
encounters到patients的關聯性,但有兩個問題:- 關聯性表示從
patients到encounters的方向,與預期關聯性相反。 這是因為所有patients剛好都由encounters(Coverage From是 1.0) 覆蓋,而encounters只是由patients(Coverage To= 0.85) 部分覆蓋,因為病患資料列遺失。 - 低基數
GENDER資料行發生意外相符,這兩個資料表中的名稱和值都會相符,但這不是相關的 "m:1" 關聯性。 低基數是由Unique Count From和Unique Count To資料行表示。
- 關聯性表示從
請重新執行
find_relationships,以只尋找 "m:1" 關聯性,但具有較低的coverage_threshold=0.5:find_relationships(dirty_tables, include_many_to_many=False, coverage_threshold=0.5)結果會顯示從
encounters到providers的正確關聯性方向。 不過,不會偵測到從encounters到patients的關聯性,因為patients不唯一,所以不能位於 "m:1" 關聯性的 "One" 端。同時放寬
include_many_to_many=True和coverage_threshold=0.5:find_relationships(dirty_tables, include_many_to_many=True, coverage_threshold=0.5)現在兩個相關的關聯性都可見,但有更多的噪音:
- 存在
GENDER上的低基數相符。 - 出現
ORGANIZATION上的較高基數 "m:m" 相符,因此很明顯,ORGANIZATION很可能是兩個資料表的資料行反正規化。
- 存在
比對資料行名稱
根據預設,SemPy 只將顯示名稱相似性的屬性視為相符,這利用了資料庫設計人員通常以相同方式命名相關資料行的事實。 此行為有助於避免虛假關聯性,這種關聯性在低基數整數鍵中最常出現。 例如,如果有 1,2,3,...,10 產品類別和 1,2,3,...,10 訂單狀態代碼,則只查看值對應而不考慮資料行名稱時,就會彼此混淆。 虛假關聯性不應該是類似 GUID 之索引鍵的問題。
SemPy 會查看資料行名稱和資料表名稱之間的相似性。 相符是近似且不區分大小寫。 它會略過最常遇到的 "decorator" 子字串,例如 "id"、"code"、"name"、"key"、"pk"、"fk"。 因此,最常見的相符案例如下:
- 實體 'foo' 中稱為 'column' 的屬性與實體 'bar' 中稱為 'column' 的屬性 (也稱為 'COLUMN' 或 'Column') 相符。
- 實體 'foo' 中稱為 'column' 的屬性與 'bar' 中稱為 'column_id' 的屬性相符。
- 實體 'foo' 中稱為 'bar' 的屬性與 'bar' 中稱為 'code' 的屬性相符。
透過先比對資料行名稱,偵測會更快執行。
比對資料列名稱:
- 若要了解要選取以進一步評估哪些資料行,請使用
verbose=2選項 (verbose=1僅列出正在處理的實體)。 -
name_similarity_threshold參數會決定資料行的比較方式。 閾值 1 表示您只對 100% 相符感興趣。
find_relationships(dirty_tables, verbose=2, name_similarity_threshold=1.0);以 100% 相似性執行無法考慮到名稱之間的微小差異。 在您的範例中,資料表具有帶 "s" 尾碼的複數形式,這不會完全相符。 這是使用預設
name_similarity_threshold=0.8的妥善處理方式。- 若要了解要選取以進一步評估哪些資料行,請使用
使用預設值
name_similarity_threshold=0.8重新執行:find_relationships(dirty_tables, verbose=2, name_similarity_threshold=0.8);請注意,複數形式
patients的 ID 現在會與單數patient比較,而不會將太多其他虛假比較新增至執行時間。使用預設值
name_similarity_threshold=0重新執行:find_relationships(dirty_tables, verbose=2, name_similarity_threshold=0);將
name_similarity_threshold變更為 0 是另一個極端,表示您想要比較所有資料行。 這很少是必要的,而且會導致執行時間增加,以及需要檢閱的虛假相符。 觀察詳細資訊輸出中的比較數目。
疑難排解秘訣摘要
- 從 "m:1" 關聯性完全相符開始 (即預設值
include_many_to_many=False和coverage_threshold=1.0)。 這通常是您想要的。 - 對較小的資料表子集使用窄焦點。
- 使用驗證來偵測資料品質問題。
- 如果您要了解哪些資料列被視爲關聯性,則請使用
verbose=2。 這可能會導致大量的輸出。 - 請注意搜尋引數的取捨。
include_many_to_many=True和coverage_threshold<1.0可能會產生可能更難以分析且需要篩選的虛假關係。
偵測完整 Synthea 資料集上的關聯性
簡單的基準範例是方便的學習和疑難排解工具。 實際上,您可以從語意模型開始,例如完整的 Synthea 資料集,其中包含更多資料表。 探索完整的 Synthea 資料集,如下所示。
從 synthea/csv 目錄讀取所有檔案:
all_tables = { "allergies": pd.read_csv('synthea/csv/allergies.csv'), "careplans": pd.read_csv('synthea/csv/careplans.csv'), "conditions": pd.read_csv('synthea/csv/conditions.csv'), "devices": pd.read_csv('synthea/csv/devices.csv'), "encounters": pd.read_csv('synthea/csv/encounters.csv'), "imaging_studies": pd.read_csv('synthea/csv/imaging_studies.csv'), "immunizations": pd.read_csv('synthea/csv/immunizations.csv'), "medications": pd.read_csv('synthea/csv/medications.csv'), "observations": pd.read_csv('synthea/csv/observations.csv'), "organizations": pd.read_csv('synthea/csv/organizations.csv'), "patients": pd.read_csv('synthea/csv/patients.csv'), "payer_transitions": pd.read_csv('synthea/csv/payer_transitions.csv'), "payers": pd.read_csv('synthea/csv/payers.csv'), "procedures": pd.read_csv('synthea/csv/procedures.csv'), "providers": pd.read_csv('synthea/csv/providers.csv'), "supplies": pd.read_csv('synthea/csv/supplies.csv'), }使用 SemPy 的
find_relationships函數尋找資料表之間的關聯性:suggested_relationships = find_relationships(all_tables) suggested_relationships視覺化關聯性:
plot_relationship_metadata(suggested_relationships)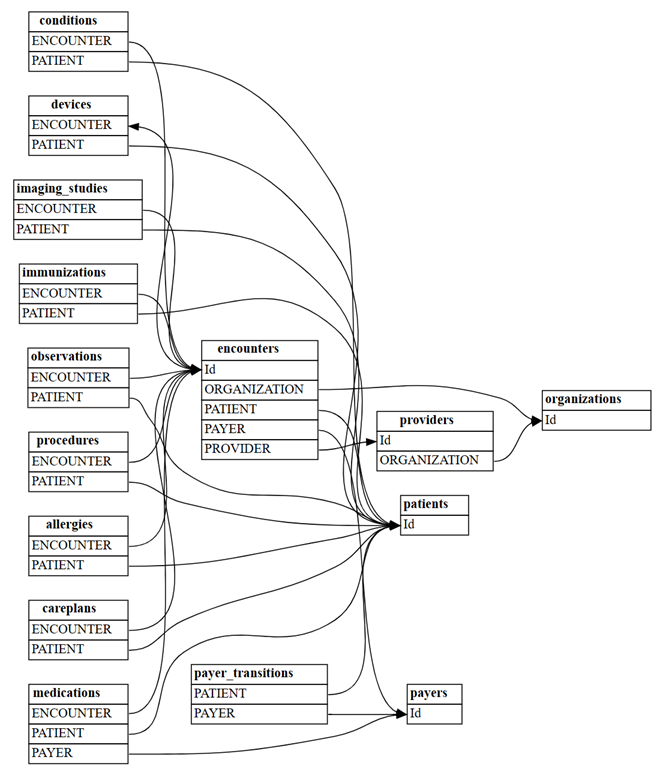
計算使用
include_many_to_many=True將探索到多少新的 "m:m" 關聯性。 這些關聯性是對先前顯示的 "m:1" 關聯性的補充;因此,您必須在multiplicity上進行篩選:suggested_relationships = find_relationships(all_tables, coverage_threshold=1.0, include_many_to_many=True) suggested_relationships[suggested_relationships['Multiplicity']=='m:m']您可以依各種資料行排序關聯性資料,以深入了解其本質。 例如,您可以選擇依
Row Count From和Row Count To排序輸出,以協助識別最大的資料表。suggested_relationships.sort_values(['Row Count From', 'Row Count To'], ascending=False)在不同的語意模型中,也許必須要將焦點放在 Null
Null Count From或Coverage To的數目上。此分析可協助您了解是否有任何關聯性可能無效,以及是否需要從候選清單中將其移除。

相關內容
查看語意連結/SemPy 的其他教學課程: