在本教學課程中,您會以儲存為語意模型 (Power BI 資料集) 的 Power BI 分析師所執行的工作為基礎。 藉由在 Microsoft Fabric 的 Synapse 資料科學體驗中使用 SemPy (預覽版),您可以分析 DataFrame 資料行中的功能相依性。 此分析可協助您發現細微的資料品質問題,以獲得更準確的見解。
在本教學課程中,您會了解如何:
- 套用領域知識,在語意模型中提出有關功能相依性的假設。
- 熟悉 Semantic Link 的 Python 程式庫 (SemPy) 元件,這些元件可與 Power BI 整合,並協助自動化資料品質分析。 這些元件包括:
- FabricDataFrame — 類似 pandas 的結構,透過額外的語意資訊增強
- 將語意模型從 Fabric 工作區提取至筆記本的函式
- 評估功能相依性假設並識別語意模型中關係違規的函數
必要條件
取得 Microsoft Fabric 訂用帳戶。 或註冊免費的 Microsoft Fabric 試用版。
登入 Microsoft Fabric。
使用首頁左下方的體驗切換器,切換至 Fabric。
![體驗切換器功能表的螢幕擷取畫面,顯示選取 [資料科學] 的位置。](media/tutorial-data-science-prepare-system/switch-to-data-science.png)
從導覽窗格中選取 [工作區] ,以尋找並選取您的工作區。 此工作區會成為您目前的工作區。
從 fabric-samples GitHub 存放庫下載 Customer Profitability Sample.pbix 檔案。
在工作區中,選取 [從這部計算機匯入>報表或編頁報表>], 將 Customer Profitability Sample.pbix 檔案上傳至工作區。
在筆記本中跟著做
本教學課程隨附 powerbi_dependencies_tutorial.ipynb 筆記本。
若要開啟本教學課程隨附的筆記本,請遵循 準備您的系統以進行資料科學教學課程的指示,將筆記本匯入工作區。
如果您想要複製並貼上此頁面中的程式碼,則可以建立新的筆記本。
開始執行程式碼之前,請務必將 Lakehouse 連結至筆記本。
設定筆記本
使用您需要的模組和資料設定筆記本環境。
用於
%pip在筆記本中安裝 PyPI 中的 SemPy。%pip install semantic-link匯入您需要的模組。
import sempy.fabric as fabric from sempy.dependencies import plot_dependency_metadata
載入及前置處理資料
本教學課程使用標準範例語意模型 Customer Profitability Sample.pbix。 如需語意模型的描述,請參閱 Power BI 的客戶獲利率範例。
使用 函數
fabric.read_table將 Power BI 資料載入 。FabricDataFramedataset = "Customer Profitability Sample" customer = fabric.read_table(dataset, "Customer") customer.head()將表格
FabricDataFrame載入State.state = fabric.read_table(dataset, "State") state.head()雖然輸出看起來像 pandas DataFrame,但這段程式碼會初始化名為 a
FabricDataFrame的資料結構,該結構會在 pandas 之上新增作業。檢查 的資料類型
customer。type(customer)輸出顯示
customersempy.fabric._dataframe._fabric_dataframe.FabricDataFrame是 。聯結 和
customerstateDataFrame物件。customer_state_df = customer.merge(state, left_on="State", right_on="StateCode", how='left') customer_state_df.head()
識別功能相依性
功能相依性是 中兩個或多個資料行 DataFrame中的值之間的一對多關係。 使用這些關係來自動偵測資料品質問題。
在合併
DataFrame上執行 Sempy 的find_dependencies函數,以識別列值之間的功能依賴關係。dependencies = customer_state_df.find_dependencies() dependencies使用 Sempy 的
plot_dependency_metadata函數可視化依賴關係。plot_dependency_metadata(dependencies)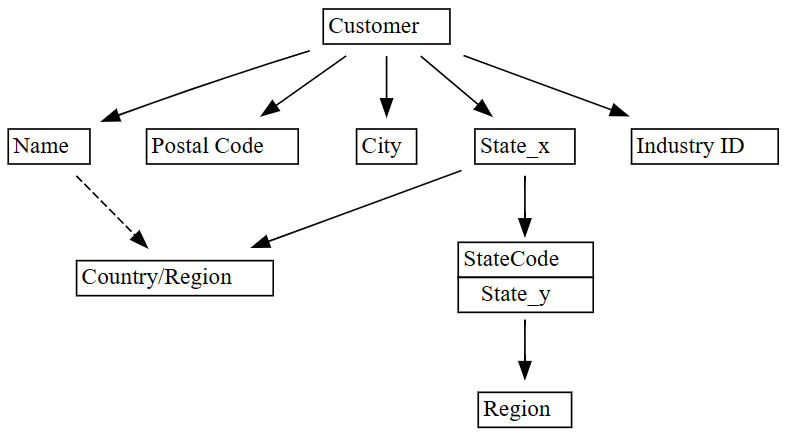
功能相依關係圖表顯示,該
Customer直欄決定了 、Postal Code和Name等City直欄。圖表未顯示 和
Postal Code之間的City功能相依性,可能是因為資料行之間的關係中有許多違規。 使用 SemPy 的功能plot_dependency_violations可視化特定列之間的依賴違規。

探索品質問題的資料
使用 SemPy 的
plot_dependency_violations視覺效果函數繪製關係圖。customer_state_df.plot_dependency_violations('Postal Code', 'City')
相依關係違規的圖形在左側顯示 的值,在右側顯示 的
Postal CodeCity值。 如果有包含這兩個值的資料列,則邊緣會連線左側的Postal Code與右側的City。 邊緣會加上這類資料列計數的標註。 例如,有兩個資料列有郵遞區號 20004,一個是城市 "North Tower",另一個是城市 "Washington"。該圖還顯示了一些違規行為和許多空值。
確認
Postal Code的空白值數目:customer_state_df['Postal Code'].isna().sum()50 行的 NA 表示
Postal Code。卸除具有空白值的資料列。 然後,使用
find_dependencies函數尋找相依性。 請注意額外參數verbose=1,以簡要了解 SemPy 的內部運作:customer_state_df2=customer_state_df.dropna() customer_state_df2.find_dependencies(verbose=1)Postal Code和City的條件熵為 0.049。 此值表示有功能相依性衝突。 修正衝突之前,請將條件熵的閾值從0.01的預設值提高為0.05,以查看相依性。 較低的閾值會產生較少的相依性 (或更高的選取性)。將條件熵的閾值從預設值
0.01提高為0.05:plot_dependency_metadata(customer_state_df2.find_dependencies(threshold=0.05))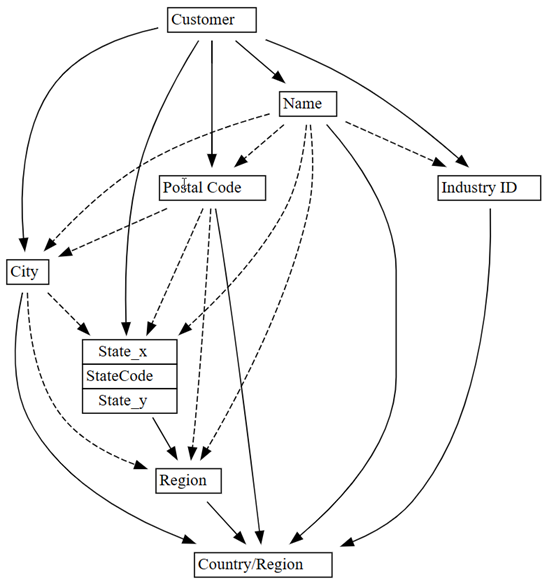
如果您套用網域知識,瞭解哪個實體決定其他實體的值,則此相依性圖表似乎很準確。
探索偵測到的更多資料品質問題。 例如,虛線箭頭聯結
City和Region,表示相依性只是近似值。 此近似關聯性可能表示存在部分功能相依性。customer_state_df.list_dependency_violations('City', 'Region')進一步了解每個非空白
Region值造成衝突的情況:customer_state_df[customer_state_df.City=='Downers Grove']結果顯示了伊利諾伊州和內布拉斯加州的唐納斯格羅夫市。 然而,唐納斯格羅夫是 伊利諾伊州的一座城市,而不是內布拉斯加州。
看看 Fremont 市:
customer_state_df[customer_state_df.City=='Fremont']加州有一個叫 Fremont 的城市。 然而,對於德克薩斯州來說,搜尋引擎會傳回 Premont,而不是 Fremont。
查看
Name和Country/Region之間的相依性衝突也是值得懷疑的,正如原始相依性衝突關係圖中的虛線所表示 (在卸除具有空白值的資料列之前)。customer_state_df.list_dependency_violations('Name', 'Country/Region')SDI Design 的一位客戶出現在兩個區域 — 美國和加拿大。 這種情況可能不是語義違規,只是不常見。 儘管如此,還是值得仔細研究的:
進一步了解客戶 SDI Design:
customer_state_df[customer_state_df.Name=='SDI Design']進一步檢查顯示來自不同行業的兩個不同客戶具有相同的名稱。

探索性資料分析和資料清洗是迭代的。 你發現什麼取決於你的問題和觀點。 語義連結為您提供新工具,讓您從資料中獲得更多資訊。
相關內容
查看語義鏈接和 Sempy 的其他教程: