ملاحظة
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
ينطبق على: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
تلميح
جرب Data Factory في Microsoft Fabric، وهو حل تحليلي متكامل للمؤسسات. يغطي Microsoft Fabric كل شيء بدءا من حركة البيانات إلى علم البيانات والتحليلات في الوقت الحقيقي والمعلومات المهنية وإعداد التقارير. تعرف على كيفية بدء إصدار تجريبي جديد مجانا!
توضح هذه المقالة كيفية استخدام نشاط النسخ في البنية الأساسية لبرنامج ربط العمليات التجارية Azure Data Factory وSynapse Analytics لنسخ البيانات من وإلى قاعدة بيانات Azure ل PostgreSQL. وكيفية استخدام تدفق البيانات لتحويل البيانات في قاعدة بيانات Azure ل PostgreSQL. للتعرف على المزيد، اقرأ المقالات التمهيدية حول Azure Data Factory وSynapse Analytics.
هام
توفر Azure Database for PostgreSQL الإصدار 2.0 قاعدة بيانات Azure الأصلية المحسنة لدعم PostgreSQL. إذا كنت تستخدم Azure Database for PostgreSQL الإصدار 1.0 في الحل الخاص بك، فمن المستحسن ترقية قاعدة بيانات Azure لموصل PostgreSQL في أقرب وقت ممكن.
هذا الموصل مخصص لـ قاعدة بيانات Azure لخدمة PostgreSQL . لنسخ البيانات من قاعدة بيانات PostgreSQL العامة الموجودة في أماكن العمل أو في السحابة، استخدم موصل PostgreSQL .
القدرات المدعومة
قاعدة بيانات Azure للموصل PostgreSQL مدعومة للإمكانيات التالية:
| القدرات المدعومة | الاشعه تحت الحمراء | نقطة النهاية الخاصة المُدارة |
|---|---|---|
| Copy activity (المصدر/المتلق) | (1) (2) | ✓ |
| تعيين تدفق البيانات (المصدر/ المتلقي) | (1) | ✓ |
| نشاط البحث | (1) (2) | ✓ |
① وقت تشغيل تكامل Azure ② وقت تشغيل التكامل المستضاف ذاتيًا
تعمل الأنشطة الثلاثة على قاعدة بيانات Azure لخادم PostgreSQL الفردي والخادم المرنوAzure Cosmos DB ل PostgreSQL.
هام
سيتم إيقاف Azure Database for PostgreSQL Single Server في 28 مارس 2025. الترحيل إلى Flexible Server بحلول ذلك التاريخ. يمكنك الرجوع إلى هذه المقالةوالأسئلة المتداولة للحصول على إرشادات الترحيل.
الشروع في العمل
لتنفيذ نشاط النسخ باستخدام أحد المسارات، يمكنك استخدام إحدى الأدوات أو عدد تطوير البرامج التالية:
- أداة نسخ البيانات
- مدخل Azure
- The .NET SDK
- عدة تطوير برامج Python
- Azure PowerShell
- واجهة برمجة تطبيقات REST
- قالب Azure Resource Manager
إنشاء خدمة مرتبطة بقاعدة بيانات Azure ل PostgreSQL باستخدام واجهة المستخدم
استخدم الخطوات التالية لإنشاء خدمة مرتبطة بقاعدة بيانات Azure لـ PostgreSQL في واجهة مستخدم مدخل Microsoft Azure.
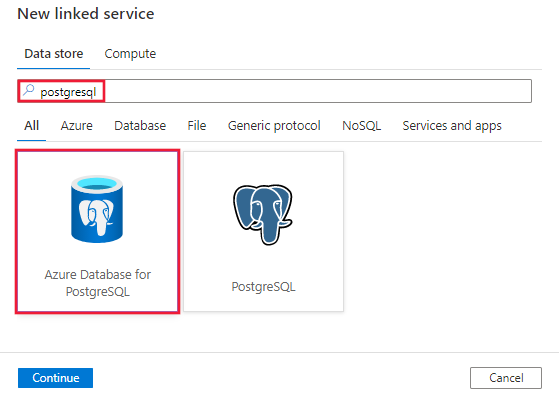
استعرض للوصول إلى علامة تبويب "Manage" في Azure Data Factory أو مساحة عمل Synapse وحدد "Linked Services"، ثم حدد "New":
ابحث عن PostgreSQL وحدد قاعدة بيانات Azure لموصل PostgreSQL.
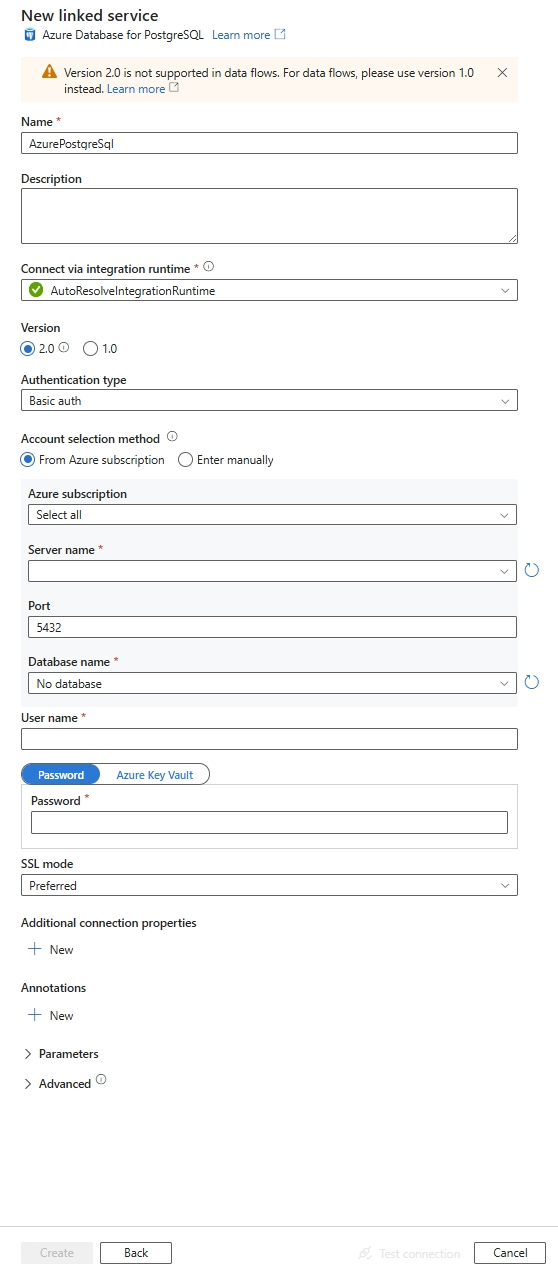
قم بتكوين تفاصيل الخدمة، واختبر الاتصال، وأنشئ الخدمة المرتبطة الجديدة.
تفاصيل تكوين الموصل
تقدم الأقسام التالية تفاصيل حول الخصائص المستخدمة لتحديد كيانات Data Factory الخاصة بقاعدة بيانات Azure لموصل PostgreSQL.
خصائص الخدمة المرتبطة
يدعم Azure Database for PostgreSQL connector الإصدار 2.0 أمان طبقة النقل (TLS) 1.3 وأوضاع طبقة مأخذ التوصيل الآمنة (SSL) المتعددة. راجع هذا القسم لترقية إصدار موصل قاعدة بيانات Azure SQL من الإصدار 1.0. للحصول على تفاصيل الخاصية، راجع الأقسام المقابلة.
الإصدار 2.0
يتم دعم الخصائص التالية لخدمة Azure Database for PostgreSQL المرتبطة عند تطبيق الإصدار 2.0:
| الخاصية | الوصف | مطلوب |
|---|---|---|
| النوع | يجب تعيين خاصية النوع على: AzurePostgreSql . | نعم |
| إصدار | الإصدار الذي تحدده. القيمة هي 2.0. |
نعم |
| نوع المصادقة | حدد من بين أنواع مصادقة الهوية المدارة الأساسية أو كيان الخدمة أو الهوية المدارة المعينة من قبل النظام أو أنواع مصادقة الهوية المدارة المعينة من قبل المستخدم | نعم |
| ملقم | يحدد اسم المضيف والمنفذ الاختياري الذي يتم تشغيل Azure Database for PostgreSQL عليه. | نعم |
| المنفذ | منفذ TCP لقاعدة بيانات Azure لخادم PostgreSQL. القيمة الافتراضية هي 5432. |
لا |
| قاعدة بيانات | اسم قاعدة بيانات Azure لقاعدة بيانات PostgreSQL للاتصال بها. | نعم |
| وضع ssl | يتحكم في ما إذا كان يتم استخدام SSL، اعتمادا على دعم الخادم. - تعطيل: تم تعطيل SSL. إذا كان الخادم يتطلب SSL، يفشل الاتصال. - السماح: يفضل الاتصالات غير SSL إذا كان الخادم يسمح بها، ولكن يسمح باتصالات SSL. - الأفضل: يفضل اتصالات SSL إذا كان الخادم يسمح بها، ولكن يسمح بالاتصالات بدون SSL. - مطلوب: يفشل الاتصال إذا كان الخادم لا يدعم SSL. - Verify-ca: يفشل الاتصال إذا كان الخادم لا يدعم SSL. يتحقق أيضا من شهادة الخادم. - التحقق الكامل: يفشل الاتصال إذا كان الخادم لا يدعم SSL. يتحقق أيضا من شهادة الخادم باسم المضيف. الخيارات: تعطيل (0) / السماح (1) / تفضيل (2) (افتراضي) / طلب (3) / تحقق من ca (4) / التحقق الكامل (5) |
لا |
| connectVia | تمثل هذه الخاصية وقت تشغيل التكامل للاتصال بمخزن البيانات. يمكنك استخدام Azure Integration Runtime أو وقت تشغيل التكامل المستضاف ذاتياً (إذا كان مخزن البيانات موجوداً في شبكة خاصة). إذا لم يتم تحديده، فإنه يستخدم Azure Integration Runtime الافتراضي. | لا |
| خصائص الاتصال الإضافية: | ||
| Schema | تعيين مسار البحث في المخطط. | لا |
| تجميع | ما إذا كان يجب استخدام تجمع الاتصال أم لا. | لا |
| مهلة الاتصال | وقت الانتظار (بالثوان) أثناء محاولة إنشاء اتصال قبل إنهاء المحاولة وإنشاء خطأ. | لا |
| commandمهلة | وقت الانتظار (بالثوان) أثناء محاولة تنفيذ أمر قبل إنهاء المحاولة وإنشاء خطأ. تعيين إلى صفر للنهاية. | لا |
| trustServerCertificate | ما إذا كنت تريد الوثوق بشهادة الخادم دون التحقق من صحتها. | لا |
| readBufferSize | تحديد حجم المخزن المؤقت الداخلي الذي يستخدمه Npgsql عند القراءة. قد تؤدي الزيادة إلى تحسين الأداء إذا تم نقل قيم كبيرة من قاعدة البيانات. | لا |
| المنطقة الزمنية | الحصول على المنطقة الزمنية للجلسة أو تعيينها. | لا |
| ترميز | يحصل على ترميز .NET أو يعينه لترميز/فك ترميز بيانات سلسلة PostgreSQL. | لا |
المصادقة الأساسية
| الخاصية | الوصف | مطلوب |
|---|---|---|
| اسم المستخدم | اسم المستخدم للاتصال به. غير مطلوب إذا كنت تستخدم IntegratedSecurity. | نعم |
| كلمة المرور | كلمة المرور للاتصال بها. غير مطلوب إذا كنت تستخدم IntegratedSecurity. وضع علامة على هذا الحقل باعتباره SecureString لتخزينه بشكل آمن. أو يمكنك أيضًا الإشارة إلى سر مخزن في Azure Key Vault. | نعم |
مثال:
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": "5432",
"database": "<database name>",
"sslMode": 2,
"username": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
}
}
}
مثال:
تخزين كلمة المرور في Azure Key Vault
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": "5432",
"database": "<database name>",
"sslMode": 2,
"username": "<user name>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
}
}
}
مصادقة الهوية المدارة المعينة من قبل النظام
يمكن إقران مصنع البيانات أو مساحة عمل Synapse بهوية مدارة يعينها النظام تمثل الخدمة عند المصادقة على موارد أخرى في Azure. يمكنك استخدام هذه الهوية المدارة لقاعدة بيانات Azure لمصادقة PostgreSQL. يمكن للمصنع المعين أو مساحة العمل Synapse الوصول إلى البيانات ونسخها من قاعدة البيانات الخاصة بك أو إليها باستخدام هذه الهوية.
لاستخدام الهوية المدارة المعينة من قبل النظام، اتبع الخطوات التالية:
يمكن إقران مصنع البيانات أو مساحة عمل Synapse بهوية مدارة يعينها النظام. تعرف على المزيد، إنشاء هوية مدارة يعينها النظام
بيانات Azure ل PostgreSQL مع تشغيل الهوية المدارة المعينة من قبل النظام.
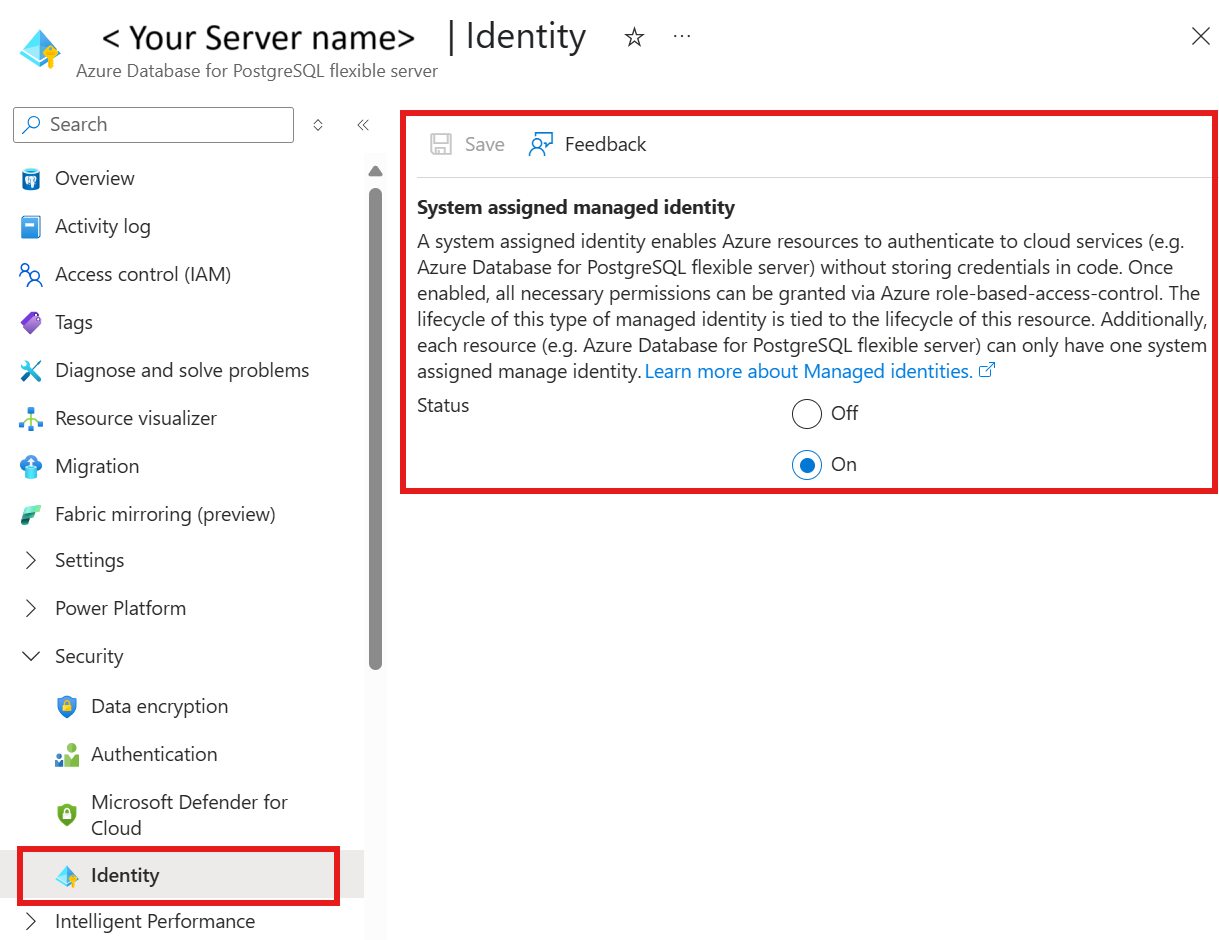
في قاعدة بيانات Azure لمورد PostgreSQL ضمن الأمان
حدد المصادقة
حدد إما مصادقة Microsoft Entra فقط أو PostgreSQL وطريقة مصادقة مصادقة Microsoft Entra .
حدد + إضافة مسؤولي Microsoft Entra
إضافة الهوية المدارة المعينة من قبل النظام لمورد Azure Data Factory كأحد مسؤولي Microsoft Entra
تكوين قاعدة بيانات Azure لخدمة PostgreSQL المرتبطة.


على سبيل المثال:
{
"name": "AzurePostgreSqlLinkedService",
"type": "Microsoft.DataFactory/factories/linkedservices",
"properties": {
"annotations": [],
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": 5432,
"database": "<database name>",
"sslMode": 2,
"authenticationType": "SystemAssignedManagedIdentity"
}
}
}
ملاحظة
نوع المصادقة هذا غير معتمد في وقت تشغيل التكامل المستضاف ذاتيا.
مصادقة الهوية المدارة المعينة من قبل المستخدم
يمكن إقران مصنع البيانات أو مساحة عمل Synapse بهوية مدارة يعينها المستخدم تمثل الخدمة عند المصادقة على موارد أخرى في Azure. يمكنك استخدام هذه الهوية المدارة لقاعدة بيانات Azure لمصادقة PostgreSQL. يمكن للمصنع المعين أو مساحة العمل Synapse الوصول إلى البيانات ونسخها من قاعدة البيانات الخاصة بك أو إليها باستخدام هذه الهوية.
لاستخدام مصادقة هوية مدارة من قبل عميل معيّن، بالإضافة إلى الخصائص العامة الموصوفة في القسم السابق، حدد الخصائص التالية:
| الخاصية | الوصف | مطلوب |
|---|---|---|
| بيانات الاعتماد | حدد الهوية المدارة المعينة من قبل المستخدم ككائن بيانات الاعتماد. | نعم |
تحتاج أيضا إلى اتباع الخطوات التالية:
تأكد من الإنشاء على مورد الهوية المدارة المعين من قبل المستخدم على مدخل Microsoft Azure. لمعرفة المزيد، انتقل إلى إدارة الهويات المدارة المعينة من قبل المستخدم
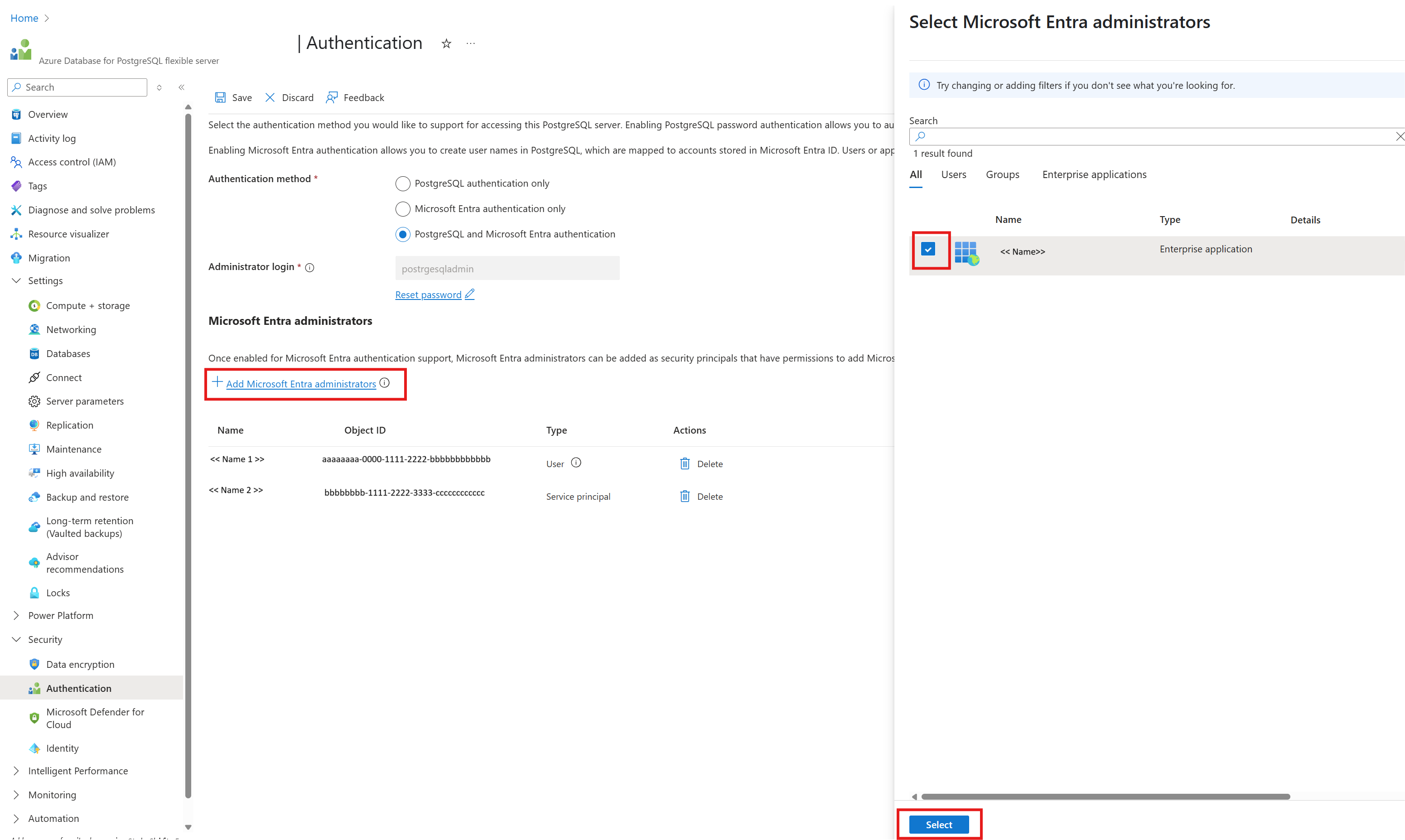
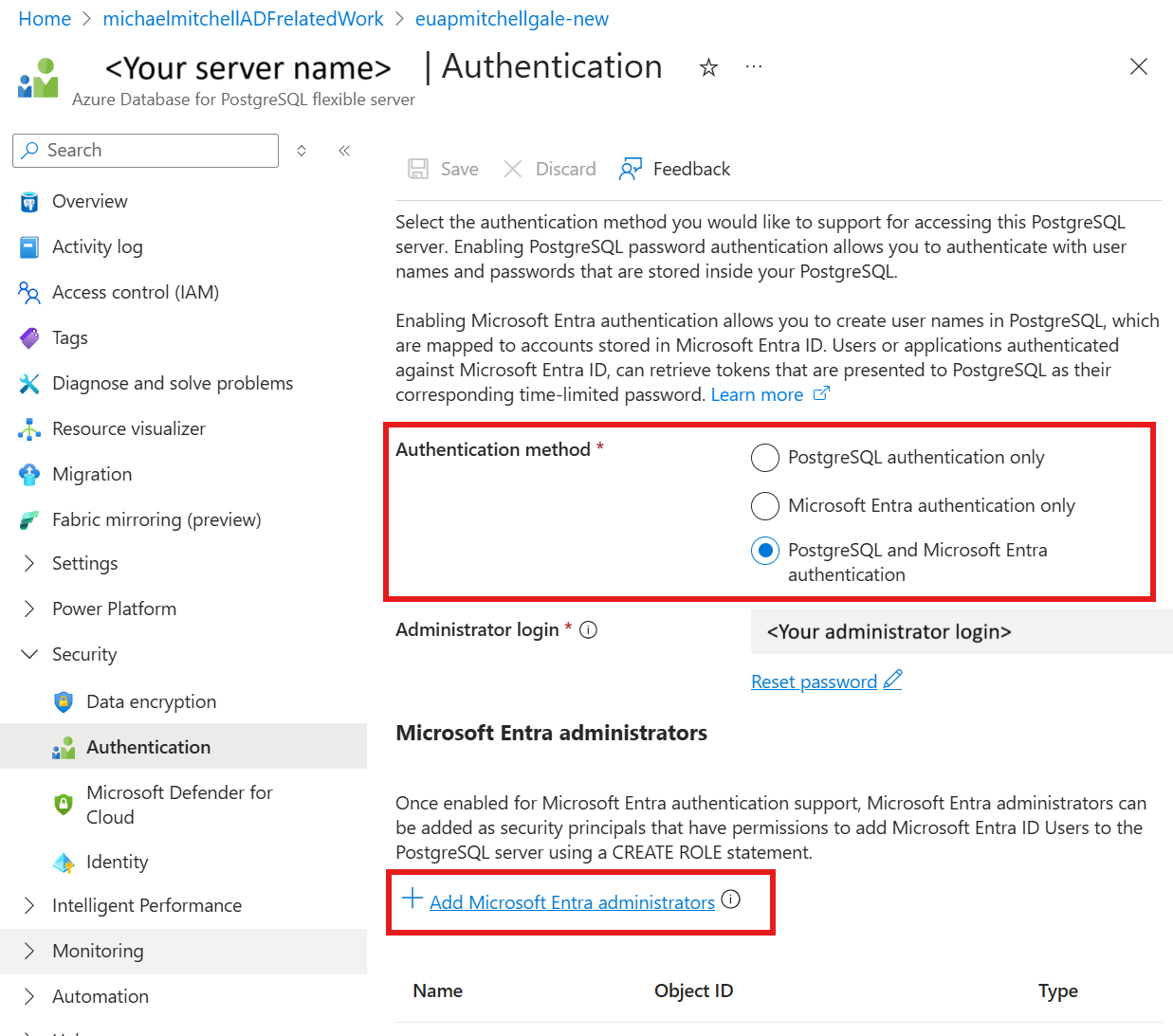
تعيين الهوية المدارة المعينة من قبل المستخدم إلى قاعدة بيانات Azure لمورد PostgreSQL
في قاعدة بيانات Azure لمورد خادم PostgreSQL، ضمن الأمان
حدد المصادقة
تحقق مما إذا كانت طريقة المصادقة هي مصادقة Microsoft Entra فقط أو مصادقة PostgreSQL وMicrosoft Entra
حدد + Add Microsoft Entra administrators link وحدد الهوية المدارة المعينة من قبل المستخدم
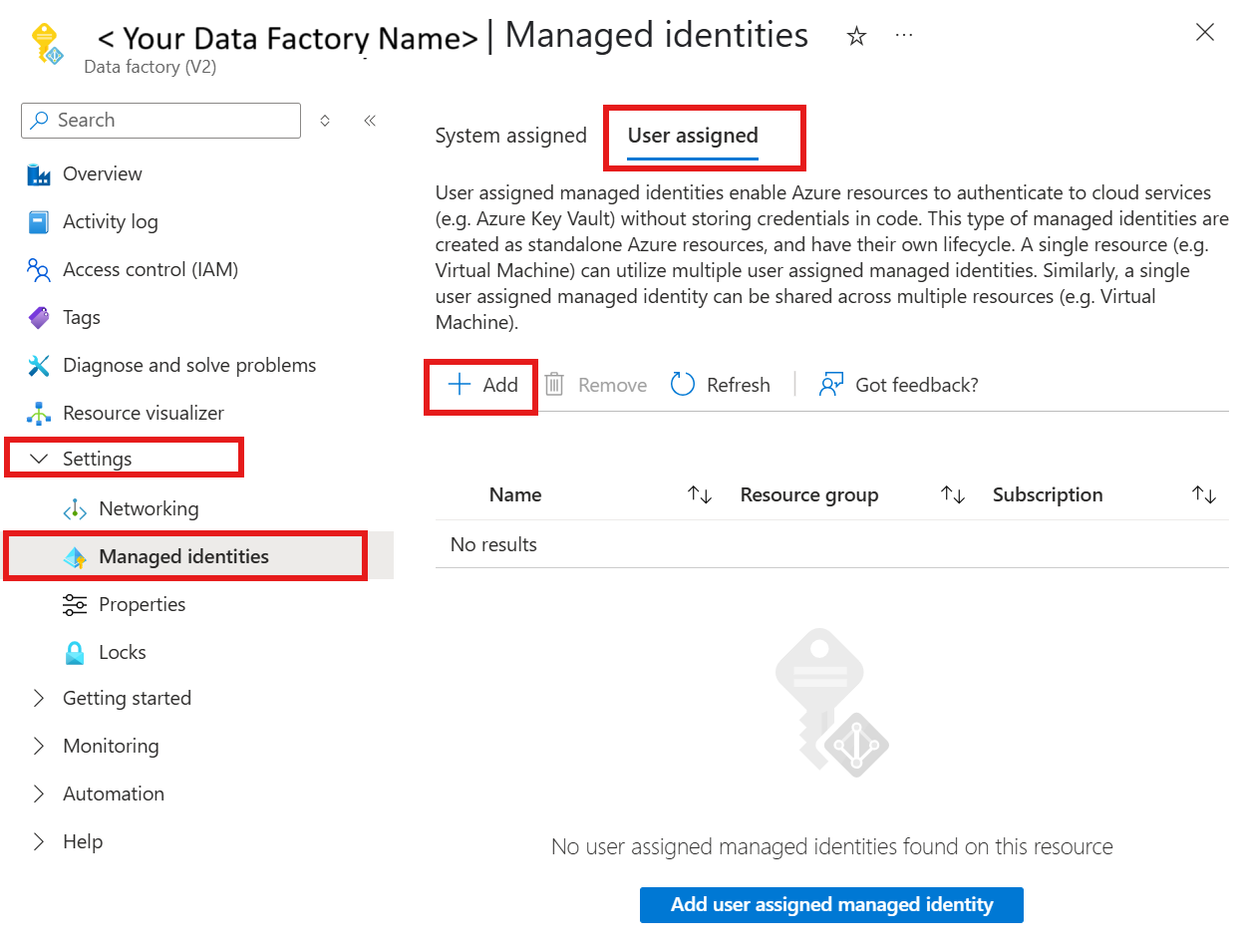
تعيين الهوية المدارة المعينة من قبل المستخدم إلى مورد Azure Data Factory
حدد الإعدادات ثم الهويات المدارة
ضمن علامة التبويب تعيين المستخدم . حدد الارتباط + Add وحدد الهوية التي يديرها المستخدم
تكوين قاعدة بيانات Azure لخدمة PostgreSQL المرتبطة.


على سبيل المثال:
{
"name": "AzurePostgreSqlLinkedService",
"type": "Microsoft.DataFactory/factories/linkedservices",
"properties": {
"annotations": [],
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": 5432,
"database": "<database name>",
"sslMode": 2,
"authenticationType": "UserAssignedManagedIdentity",
"credential": {
"referenceName": "<your credential>",
"type": "CredentialReference"
}
}
}
}
المصادقة الأساسية للخدمة
| الخاصية | الوصف | مطلوب |
|---|---|---|
| اسم المستخدم | الاسم المعروض لمدير الخدمة | نعم |
| مستاجر | المستأجر الذي توجد به قاعدة بيانات Azure لخادم PostgreSQL | نعم |
| servicePrincipalId | معرف التطبيق الخاص بكيان الخدمة | نعم |
| servicePrincipalCredentialType | حدد ما إذا كانت الشهادة الأساسية للخدمة أو مفتاح الخدمة الأساسي هو أسلوب المصادقة المطلوب - ServicePrincipalCert: تعيين إلى الشهادة الأساسية للخدمة للشهادة الأساسية للخدمة. - ServicePrincipalKey: تعيين إلى مفتاح الخدمة الأساسي لمصادقة مفتاح الخدمة الأساسي. |
نعم |
| servicePrincipalKey | قيمة سر العميل. يستخدم عند تحديد مفتاح الخدمة الأساسي | نعم |
| azureCloudType | حدد نوع سحابة Azure لخادم Azure Database for PostgreSQL | نعم |
| servicePrincipalEmbeddedCert | ملف الشهادة الأساسية للخدمة | نعم |
| servicePrincipalEmbeddedCertPassword | كلمة مرور الشهادة الأساسية للخدمة إذا لزم الأمر | لا |
مثال:
مفتاح الخدمة الأساسي
{
"name": "AzurePostgreSqlLinkedService",
"type": "Microsoft.DataFactory/factories/linkedservices",
"properties": {
"annotations": [],
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": 5432,
"database": "<database name>",
"sslMode": 2,
"username": "<service principal name>",
"authenticationType": "<authentication type>",
"tenant": "<tenant>",
"servicePrincipalId": "<service principal ID>",
"azureCloudType": "<azure cloud type>",
"servicePrincipalCredentialType": "<service principal type>",
"servicePrincipalKey": "<service principal key>"
}
}
}
مثال:
الشهادة الأساسية للخدمة
{
"name": "AzurePostgreSqlLinkedService",
"type": "Microsoft.DataFactory/factories/linkedservices",
"properties": {
"annotations": [],
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": 5432,
"database": "<database name>",
"sslMode": 2,
"username": "<service principal name>",
"authenticationType": "<authentication type>",
"tenant": "<tenant>",
"servicePrincipalId": "<service principal ID>",
"azureCloudType": "<azure cloud type>",
"servicePrincipalCredentialType": "<service principal type>",
"servicePrincipalEmbeddedCert": "<service principal certificate>",
"servicePrincipalEmbeddedCertPassword": "<service principal embedded certificate password>"
}
}
}
الإصدار 1.0
يتم دعم الخصائص التالية لخدمة Azure Database for PostgreSQL المرتبطة عند تطبيق الإصدار 1.0:
| الخاصية | الوصف | مطلوب |
|---|---|---|
| النوع | يجب تعيين خاصية النوع على: AzurePostgreSql . | نعم |
| إصدار | الإصدار الذي تحدده. القيمة هي 1.0. |
نعم |
| سلسلة الاتصال | سلسلة اتصال Npgsql للاتصال بقاعدة بيانات Azure ل PostgreSQL. يمكنك أيضًا وضع كلمة مرور في Azure Key Vault وسحب تكوين password خارج سلسلة الاتصال. راجع العينات التالية وبيانات اعتماد المخزن في Azure Key Vault لمزيد من التفاصيل. |
نعم |
| connectVia | تمثل هذه الخاصية وقت تشغيل التكامل للاتصال بمخزن البيانات. يمكنك استخدام Azure Integration Runtime أو وقت تشغيل التكامل المستضاف ذاتياً (إذا كان مخزن البيانات موجوداً في شبكة خاصة). إذا لم يتم تحديده، فإنه يستخدم Azure Integration Runtime الافتراضي. | لا |
سلسلة الاتصال النموذجية هي host=<server>.postgres.database.azure.com;database=<database>;port=<port>;uid=<username>;password=<password>. فيما يلي المزيد من الخصائص التي يمكنك تعيينها لكل حالة:
| الخاصية | الوصف | الخيارات | مطلوب |
|---|---|---|---|
| طريقة التشفير (EM) | الطريقة التي يستخدمها برنامج التشغيل لتشفير البيانات المرسلة بين برنامج التشغيل وخادم قاعدة البيانات. على سبيل المثال، EncryptionMethod=<0/1/6>; |
0 (بلا تشفير ) (افتراضي) / 1 (SSL) / 6 (RequestSSL) | لا |
| التحقق من صحةServerCertificate (VSC) | يحدد ما إذا كان برنامج التشغيل يتحقق من صحة الشهادة التي تم إرسالها بواسطة خادم قاعدة البيانات عند تمكين تشفير SSL (طريقة التشفير = 1). على سبيل المثال، ValidateServerCertificate=<0/1>; |
0 (معطل) (افتراضي) / 1 (ممكّن) | لا |
مثال:
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"version": "1.0",
"typeProperties": {
"connectionString": "host=<server>.postgres.database.azure.com;database=<database>;port=<port>;uid=<username>;password=<password>"
}
}
}
مثال:
تخزين كلمة المرور في Azure Key Vault
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"version": "1.0",
"typeProperties": {
"connectionString": "host=<server>.postgres.database.azure.com;database=<database>;port=<port>;uid=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
}
}
}
خصائص مجموعة البيانات
للاطلاع على قائمة كاملة للأقسام والخصائص المتوفرة لتحديد مجموعات البيانات، راجع مجموعات البيانات. يوفر هذا القسم قائمة بالخصائص التي تدعمها قاعدة بيانات Azure لـ PostgreSQL في مجموعات البيانات.
لنسخ البيانات من قاعدة بيانات Azure لـ PostgreSQL، عيّن خاصية النوع لمجموعة البيانات إلى AzurePostgreSqlTable . تدعم الخصائص التالية:
| الخاصية | الوصف | مطلوب |
|---|---|---|
| النوع | يجب تعيين خاصية نوع مجموعة البيانات إلى AzurePostgreSqlTable. | نعم |
| Schema | اسم المخطط. | لا (إذا تم تحديد "الاستعلام" في مصدر النشاط) |
| طاولتنا | اسم الجدول/طريقة العرض. | لا (إذا تم تحديد "الاستعلام" في مصدر النشاط) |
| اسم الجدول | ضع اسمًا للجدول. هذه الخاصية مدعومة للتوافق مع الإصدارات السابقة. بالنسبة لحمل العمل الجديد، استخدم schema وtable. |
لا (إذا تم تحديد "الاستعلام" في مصدر النشاط) |
مثال:
{
"name": "AzurePostgreSqlDataset",
"properties": {
"type": "AzurePostgreSqlTable",
"linkedServiceName": {
"referenceName": "<AzurePostgreSql linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
انسخ خصائص النشاط
للحصول على قائمة كاملة بالأقسام والخصائص المتوفرة لتعريف الأنشطة، راجع خطوط الأنابيب والأنشطة . يوفر هذا القسم قائمة بالخصائص التي تدعمها قاعدة بيانات Azure لمصدر PostgreSQL.
قاعدة بيانات Azure لـ PostgreSql كمصدر
لنسخ البيانات من قاعدة بيانات Azure لـ PostgreSQL، عيّن نوع المصدر في نشاط النسخ إلى AzurePostgreSqlSource . تُدعم الخصائص التالية في قسم مصدر نشاط النسخ:
| الخاصية | الوصف | مطلوب |
|---|---|---|
| النوع | يجب تعيين خاصية النوع لمصدر نشاط النسخ على AzurePostgreSqlSource | نعم |
| استعلام | استخدم استعلام SQL المخصص لقراءة البيانات. على سبيل المثال: SELECT * FROM mytable أو SELECT * FROM "MyTable". ملاحظة في PostgreSQL، يتم التعامل مع اسم الكيان على أنه غير حساس لحالة الأحرف إذا لم يتم اقتباسه. |
لا (إذا تم تحديد خاصية اسم الجدول في مجموعة البيانات) |
| وقت الاستعلام | وقت الانتظار قبل إنهاء محاولة تنفيذ أمر وإنشاء خطأ، الافتراضي هو 120 دقيقة. إذا تم تعيين المعلمة لهذه الخاصية، فإن القيم المسموح بها هي الفترة الزمنية، مثل "02:00:00" (120 دقيقة). لمزيد من المعلومات، راجع CommandTimeout. | لا |
| خيارات التقسيم | يحدد خيارات تقسيم البيانات المستخدمة لتحميل البيانات من قاعدة بيانات Azure SQL. القيم المسموح بها هي: None (افتراضي)، وPhysicalPartitionsOfTable، وDynamicRange. عند تمكين خيار القسم (أي ليس None)، يتم التحكم في درجة التوازي لتحميل البيانات بشكل متزامن من قاعدة بيانات Azure SQL من خلال الإعداد parallelCopies في نشاط النسخ. |
لا |
| إعدادات الأقسام | حدد مجموعة الإعدادات الخاصة بتقسيم البيانات. تطبيق عندما لا يكون خيار التقسيم None. |
لا |
تحت partitionSettings: |
||
| أسماء أقسام | قائمة الأقسام المادية التي يجب نسخها. تُطبق عندما يكون خيار التقسيم هو PhysicalPartitionsOfTable. إذا كنت تستخدم استعلاماً لاسترداد البيانات المصدر، اربط ?AdfTabularPartitionName في عبارة WHERE. للحصول على مثال، راجع قسم نسخة متوازية من قاعدة بيانات Azure لـ PostgreSQL . |
لا |
| partitionColumnName | حدد اسم عمود المصدر بعدد صحيح أو نوع التاريخ/التاريخ والوقت (int أو smallint أو bigint أو date أو timestamp without time zone أو timestamp with time zone أو time without time zone) التي سيتم استخدامها عن طريق تقسيم النطاق للنسخ المتوازي. إذا لم يتم تحديده، فسيتم اكتشاف المفتاح الأساسي للجدول تلقائياً واستخدامه كعمود قسم.تُطبق عندما يكون خيار التقسيم هو DynamicRange. إذا كنت تستخدم استعلاماً لاسترداد البيانات المصدر، اربط ?AdfRangePartitionColumnName في عبارة WHERE. للحصول على مثال، راجع قسم نسخة متوازية من قاعدة بيانات Azure لـ PostgreSQL . |
لا |
| التقسيم | الحد الأقصى لقيمة عمود القسم لنسخ البيانات. تُطبق عندما يكون خيار التقسيم هو DynamicRange. إذا كنت تستخدم استعلاماً لاسترداد البيانات المصدر، اربط ?AdfRangePartitionUpbound في عبارة WHERE. للحصول على مثال، راجع قسم نسخة متوازية من قاعدة بيانات Azure لـ PostgreSQL . |
لا |
| partitionLowerBound | الحد الأدنى لقيمة عمود القسم لنسخ البيانات. تُطبق عندما يكون خيار التقسيم هو DynamicRange. إذا كنت تستخدم استعلاماً لاسترداد البيانات المصدر، اربط ?AdfRangePartitionLowbound في عبارة WHERE. للحصول على مثال، راجع قسم نسخة متوازية من قاعدة بيانات Azure لـ PostgreSQL . |
لا |
مثال:
"activities":[
{
"name": "CopyFromAzurePostgreSql",
"type": "Copy",
"inputs": [
{
"referenceName": "<AzurePostgreSql input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzurePostgreSqlSource",
"query": "<custom query e.g. SELECT * FROM mytable>",
"queryTimeout": "00:10:00"
},
"sink": {
"type": "<sink type>"
}
}
}
]
قاعدة بيانات Azure لـ PostgreSQL كمصدر
لنسخ البيانات إلى قاعدة بيانات Azure لـ PostgreSQL، يتم دعم الخصائص التالية في قسم حوض نشاط النسخ:
| الخاصية | الوصف | مطلوب |
|---|---|---|
| النوع | يجب تعيين خاصية نوع متلقي نشاط النسخ إلى AzurePostgreSqlSink. | نعم |
| ما قبل النسخ النصية | حدد استعلام SQL لنشاط النسخ لتنفيذه قبل كتابة البيانات في قاعدة بيانات Azure لـ PostgreSQL في كل تشغيل. يمكنك استخدام هذه الخاصية لتنظيف البيانات المحملة مسبقاً. | لا |
| طريقة الكتابة | الطريقة المستخدمة لكتابة البيانات في قاعدة بيانات Azure لـ PostgreSQL. القيم المسموح بها هي: CopyCommand (افتراضي، أيهما أكثر أداءً)، BulkInsert . |
لا |
| writeBatchSize | عدد الصفوف التي تم تحميلها في قاعدة بيانات Azure لـ PostgreSQL لكل دفعة. القيمة المسموح بها هي عدد صحيح يمثل عدد الصفوف. |
لا (الافتراضي هو 1,000,000) |
| writeBatchTimeout | وقت الانتظار حتى تكتمل عملية إدراج الدُفعة قبل انتهاء مهلتها. القيم المسموح بها هي سلاسل Timespan. مثال على ذلك هو 00:30:00 (30 دقيقة). |
لا (الافتراضي هو 00:30:00) |
مثال:
"activities":[
{
"name": "CopyToAzureDatabaseForPostgreSQL",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure PostgreSQL output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzurePostgreSqlSink",
"preCopyScript": "<custom SQL script>",
"writeMethod": "CopyCommand",
"writeBatchSize": 1000000
}
}
}
]
نسخة متوازية من قاعدة بيانات Azure لـ PostgreSQL
توفر قاعدة بيانات Azure لموصل PostgreSQL في نشاط النسخ تقسيماً مضمناً للبيانات لنسخ البيانات بشكل متوازٍ. يمكنك العثور على خيارات تقسيم البيانات في علامة التبويب Source لنشاط النسخ.
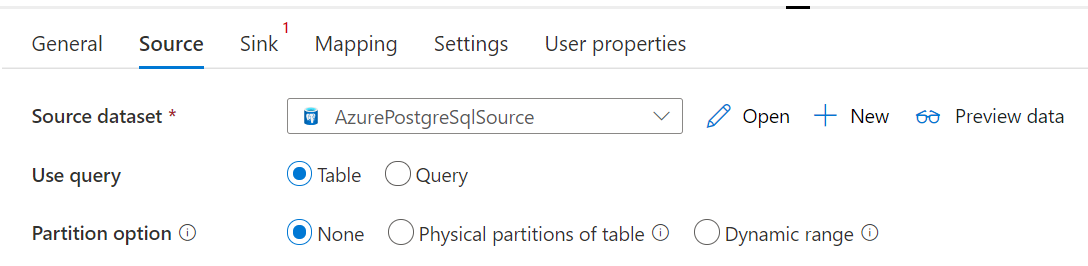
عند تمكين النسخة المقسمة، يقوم نشاط النسخ بتشغيل استعلامات متوازية مقابل قاعدة بيانات Azure لمصدر PostgreSQL لتحميل البيانات حسب الأقسام. يتم التحكم في الدرجة المتوازية بواسطة parallelCopies الإعداد على نشاط النسخ. على سبيل المثال، إذا قمت بتعيين parallelCopies على أربعة، تقوم الخدمة في نفس الوقت بإنشاء وتشغيل أربعة استعلامات بناءً على خيار القسم المحدد والإعدادات، ويسترد كل استعلام جزءاً من البيانات من قاعدة بيانات Azure الخاصة بك لـ PostgreSQL.
يقترح عليك تمكين النسخ المتوازي مع تقسيم البيانات خاصة عند تحميل كمية كبيرة من البيانات من قاعدة بيانات Azure ل PostgreSQL. فيما يلي تكوينات مقترحة لسيناريوهات مختلفة. عند نسخ البيانات إلى مخزن البيانات المستندة إلى الملفات، فإن التوصية هي الكتابة إلى مجلد كملفات متعددة (تحديد اسم المجلد فقط)، وفي هذه الحالة يكون الأداء أفضل من الكتابة إلى ملف واحد.
| السيناريو | الإعدادات المقترحة |
|---|---|
| تحميل كامل من جدول كبير بأقسام فعلية. |
خيار التقسيم: أقسام فعلية للجدول. أثناء التنفيذ، تكتشف الخدمة تلقائياً الأقسام المادية ونسخ البيانات حسب الأقسام. |
| تحميل كامل من جدول كبير، دون أقسام فعلية، مع وجود عمود لعدد صحيح لتقسيم البيانات. |
خيارات التقسيم: تقسيم النطاق الديناميكي. عمود التقسيم: حدد العمود المستخدم لتقسيم البيانات. إذا لم يتم تحديده، فسيتم استخدام عمود المفتاح الأساسي. |
| قم بتحميل كمية كبيرة من البيانات باستخدام استعلام مخصص بأقسام فعلية. |
خيار التقسيم: أقسام فعلية للجدول. استعلام: SELECT * FROM ?AdfTabularPartitionName WHERE <your_additional_where_clause>.اسم القسم: حدد اسم قسم واحد أو أكثر لنسخ البيانات منه. إذا لم يتم تحديد الخدمة تلقائياً بالكشف عن الأقسام الفعلية المذكورة بالجدول المحدد في مجموعة بيانات Oracle. أثناء التنفيذ، تستبدل الخدمة ?AdfTabularPartitionName باسم القسم الفعلي، وترسل إلى قاعدة بيانات Azure لـ PostgreSQL. |
| يمكنك تحميل كمية كبيرة من البيانات باستخدام استعلام مخصص، بدون أقسام فعلية، أثناء استخدام عمود مخصص لعدد صحيح لتقسيم البيانات. |
خيارات التقسيم: تقسيم النطاق الديناميكي. استعلام: SELECT * FROM ?AdfTabularPartitionName WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>.عمود التقسيم: حدد العمود المستخدم لتقسيم البيانات. يمكنك التقسيم مقابل العمود بعدد صحيح أو نوع بيانات التاريخ / التاريخ والوقت. الحد الأعلى للتقسيموالحد الأدنى للتقسيم: تحديد إذا ما كنت تريد التصفية مقابل عمود التقسيم لاسترداد البيانات فقط بين النطاقين الأدنى والأعلى. أثناء التنفيذ، تستبدل الخدمة ?AdfRangePartitionColumnName و?AdfRangePartitionUpbound و?AdfRangePartitionLowbound باسم العمود الفعلي ونطاقات القيمة لكل قسم، وترسل إلى قاعدة بيانات Azure لـ PostgreSQL. على سبيل المثال، إذا تم تعيين "ID" لعمود القسم الخاص بك مع الحد السفلي ك 1 وأعلى حد ك 80، مع تعيين النسخة المتوازية على 4، تسترد الخدمة البيانات بأربعة أقسام. هوياتهم تتراوح بين [1،20]، [21، 40]، [41، 60]، [61، 80] على التوالي. |
أفضل الممارسات لتحميل البيانات مع خيار التقسيم:
- اختر عمود مميز كعمود تقسيم (مثل المفتاح الأساسي أو المفتاح الفريد) لتجنب انحراف البيانات.
- إذا كان الجدول يحتوي على قسم مضمن، فاستخدم خيار القسم "الأقسام المادية للجدول" للحصول على أداء أفضل.
- إذا كنت تستخدم Azure Microsoft Integration Runtime لنسخ البيانات لكن يمكنك تعيين "وحدات تكامل بيانات (DIU)" (> 4) أكبر للاستفادة من المزيد من موارد الحوسبة. تحقق من السيناريوهات القابلة للتطبيق هناك.
- تتحكم "درجة توازي النسخ" في أرقام الأقسام، تعيين هذا الرقم كبير جدا في وقت ما يضر بالأداء. يوصى بتعيين هذا الرقم ك (DIU أو عدد عقد وقت تشغيل التكامل المستضاف ذاتيا) * (2 إلى 4).
مثال: تحميل كامل من جدول كبير مع أقسام فعلية
"source": {
"type": "AzurePostgreSqlSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
مثال: الاستعلام مع تقسيم النطاق الديناميكي
"source": {
"type": "AzurePostgreSqlSource",
"query": "SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
تعيين خصائص تدفق البيانات
عند تحويل البيانات في تعيين تدفق البيانات، يمكنك القراءة والكتابة في الجداول من قاعدة بيانات Azure لـ PostgreSQL. لمزيد من المعلومات، راجع تحويل المصدر و تحويل المتلقي في تعيين تدفقات البيانات. يمكنك اختيار استخدام قاعدة بيانات Azure لمجموعة بيانات PostgreSQL أو مجموعة بيانات مضمنة كنوع مصدر وحوض.
تحويل المصدر
يسرد الجدول أدناه الخصائص التي تدعمها قاعدة بيانات Azure لمصدر PostgreSQL. يمكنك تحرير هذه الخصائص في علامة التبويب "Source options".
| الاسم | الوصف | مطلوب | القيم المسموح بها | خاصية البرنامج النصي لتدفق البيانات |
|---|---|---|---|---|
| جدول | إذا حددت الجدول كمدخلات، فإن تدفق البيانات يجلب جميع البيانات من الجدول المحدد في مجموعة البيانات. | لا | - |
(لمجموعة البيانات المضمنة فقط) اسم الجدول |
| الاستعلام | إذا حددت الاستعلام كإدخال، فحدد استعلام SQL لجلب البيانات من المصدر، والذي يتجاوز أي جدول تحدده في مجموعة البيانات. يعد استخدام الاستعلامات طريقة رائعة لتقليل عدد الصفوف للاختبار أو عمليات البحث. عبارة Order By غير مدعومة، ولكن يمكنك تعيين عبارة SELECT FROM كاملة. يمكنك أيضاً استخدام وظائف الجدول المعرفة بواسطة المستخدم. تحديد * من udfGetData() هو UDF في SQL الذي يقوم بإرجاع جدول يمكنك استخدامه في تدفق البيانات. مثال على استعلام: select * from mytable where customerId > 1000 and customerId < 2000 أو select * from "MyTable". ملاحظة في PostgreSQL، يتم التعامل مع اسم الكيان على أنه غير حساس لحالة الأحرف إذا لم يتم اقتباسه. |
لا | السلسلة | استعلام |
| اسم المخطط | إذا حددت الإجراء المخزن كإدخال، فحدد اسم مخطط للإجراء المخزن، أو حدد "تحديث" لمطالبة الخدمة باكتشاف أسماء المخططات. | لا | السلسلة | اسم المخطط |
| الإجراء المخزّن | إذا حددت الإجراء المخزن كإدخال، فحدد اسم الإجراء المخزن لقراءة البيانات من الجدول المصدر، أو حدد تحديث لمطالبة الخدمة باكتشاف أسماء الإجراءات. | نعم (إذا حددت الإجراء المخزّن كإدخال) | السلسلة | اسم الإجراء |
| معلمات الإجـراء | إذا حددت الإجراء المخزن كإدخال، فحدد أي معلمات إدخال للإجراء المخزن في الترتيب الذي تم تعيينه فـي الإجراء، أو حدد استيراد لاستيراد كافة معلمات الإجراء باستخدام النموذج @paraName. |
لا | صفيف | إدخال |
| حجم الدفعة | حدد حجم الدُفعة لتقسيم البيانات الكبيرة إلى دُفعات. | لا | رقم صحيح | حجم الدفعات |
| مستوى العزل | اختر أحد مستويات العزل التالية: - قراءة ثابتة - قراءة غير ثابتة (افتراضي) - القراءة المتكررة - قابل للتسلسل - لا شيء (تجاهل مستوى العزل) |
لا | READ_COMMITTED READ_UNCOMMITTED REPEATABLE_READ التسلسل لا |
مستوى العزل |
قاعدة بيانات Azure لمثال البرنامج النصي المصدر PostgreSQL
عند استخدام قاعدة بيانات Azure لـ PostgreSQL كنوع مصدر، يكون البرنامج النصي لتدفق البيانات المرتبط هو:
source(allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
query: 'select * from mytable',
format: 'query') ~> AzurePostgreSQLSource
تحويل المتلقي
يسرد الجدول أدناه الخصائص التي تدعمها قاعدة بيانات Azure لمتلقي PostgreSQL. يمكنك تحرير هذه الخصائص في علامة التبويب "Sink options".
| الاسم | الوصف | مطلوب | القيم المسموح بها | خاصية البرنامج النصي لتدفق البيانات |
|---|---|---|---|---|
| أسلوب التحديث | حدد العمليات المسموح بها في وجهة قاعدة البيانات. الوضع الافتراضي هو السماح فقط بالإدراج. لتحديث صفوف أو إجراء upsert "إدراج الصفوف أو تحديثها" أو حذفها، يلزم إجراء تحويل في الصف المعدل لوضع علامة على الصفوف التي تخضع لتلك الإجراءات. |
نعم |
true أو false |
قابل للحذف قابلة للادراج قابل للتحديث قابل للإدراج أو التحديث |
| الأعمدة الرئيسية | بالنسبة للتحديثات والتحديثات والحذف، يجب تعيين أعمدة المفاتيح لتحديد الصف الذي يجب تغييره. يتم استخدام اسم العمود الذي تختاره كمفتاح كجزء من التحديث اللاحق، upsert، حذف. لذلك، يجب اختيار عمود موجود في تعيين "المتلقي". |
لا | صفيف | المفاتيح |
| تخطي كتابة أعمدة المفتاح | إذا كنت ترغب في عدم كتابة القيمة إلى عمود المفتاح، فحدد "Skip writing key columns". | لا |
true أو false |
skipKeyWrites |
| إجراء الجدول | تحديد ما إذا كنت تريد إعادة إنشاء كافة الصفوف أو إزالتها من الجدول الوجهة قبل الكتابة. - بلا: لم يتم تنفيذ أي إجراء على الجدول. - إعادة إنشاء: يتم إسقاط الجدول وإعادة إنشائه. مطلوب في حال إنشاء جدول جديد بشكل ديناميكي. - اقتطاع: تتم إزالة جميع الصفوف من الجدول الهدف. |
لا |
true أو false |
إعادة إنشاء اقتطاع |
| حجم الدفعة | حدد عدد الصفوف التي تتم كتابتها في كل دُفعة. تعمل أحجام الدُفعات الأكبر على تحسين الضغط والذاكرة، ولكنها تخاطر بنفاد استثناءات الذاكرة عند تخزين البيانات مؤقتاً. | لا | رقم صحيح | حجم الدفعات |
| تحديد مخطط قاعدة بيانات المستخدم | بشكل افتراضي، يتم إنشاء جدول مؤقت ضمن مخطط المتلقي كتقسيم مرحلي. يمكنك بدلا من ذلك إلغاء تحديد الخيار استخدام مخطط المتلقي وبدلا من ذلك، حدد اسم مخطط يقوم Data Factory بموجبه بإنشاء جدول مرحلي لتحميل البيانات المصدر وتنظيفها تلقائيا عند الانتهاء. تأكد من حصولك على إذن إنشاء الجدول في قاعدة البيانات وقم بتغيير الإذن في المخطط. | لا | السلسلة | stagingSchemaName |
| نصوص SQL السابقة واللاحقة | حدد البرامج النصية SQL متعددة الأسطر التي سيتم تنفيذها قبل (المعالجة المسبقة) وبعد كتابة البيانات (بعد المعالجة) إلى قاعدة بيانات Sink. | لا | السلسلة | preSQLs عناوين postSQLs |
تلميح
- تقسيم البرامج النصية دفعة واحدة مع أوامر متعددة إلى دفعات متعددة.
- يمكن فقط تشغيل عبارات لغة تعريف البيانات (DDL) ولغة معالجة البيانات (DML) التي ترجع عدد تحديثات بسيط كجزء مـن دفعة. تعرَّف على المزيد من خلال تنفيذ عمليات الدُفعات
تمكين الاستخراج التزايدي: استخدم هذا الخيار لإخبار ADF بمعالجة الصفوف التي تغيرت منذ آخر مرة تم فيها تنفيذ المسار.
عمود تزايدي: عند استخدام ميزة الاستخراج التزايدي، يجب اختيار التاريخ/الوقت أو العمود الرقمي الذي ترغب في استخدامه كعلامة مائية في الجدول المصدر.
بدء القراءة من البداية: يؤدي تعيين هذا الخيار باستخدام الاستخراج التزايدي إلى توجيه ADF لقراءة جميع الصفوف عند التنفيذ الأول للبنية الأساسية لبرنامج ربط العمليات التجارية مع تشغيل الاستخراج التزايدي.
مثال على قاعدة بيانات Azure لبرنامج نصي متلقي PostgreSQL
عند استخدام قاعدة بيانات Azure لـ PostgreSQL كنوع متلقي، يكون البرنامج النصي لتدفق البيانات المرتبط هو:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:true,
updateable:true,
upsertable:true,
keys:['keyColumn'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzurePostgreSqlSink
بحث عن خصائص النشاط
لمزيد من المعلومات حول الخصائص، راجع نشاط البحث.
ترقية قاعدة بيانات Azure لموصل PostgreSQL
في صفحة تحرير الخدمة المرتبطة ، حدد 2.0 ضمن الإصدار وقم بتكوين الخدمة المرتبطة بالإشارة إلى خصائص الخدمة المرتبطة الإصدار 2.0.
المحتوى ذو الصلة
للحصول على قائمة بمخازن البيانات المدعومة كمصادر ومتلقين من خلال نشاط النسخ، انظر مخازن البيانات المدعومة .