إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
ينطبق على: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
تلميح
Data Factory في Microsoft Fabric هو الجيل القادم من Azure Data Factory، مع بنية أبسط، وذكاء اصطناعي مدمج، وميزات جديدة. إذا كنت جديدا في تكامل البيانات، ابدأ مع Fabric Data Factory. يمكن لأعباء عمل ADF الحالية الترقية إلى Fabric للوصول إلى قدرات جديدة في علوم البيانات، والتحليلات اللحظية، والتقارير.
توضح هذه المقالة كيفية استخدام نشاط النسخ في خطوط أنابيب Azure Data Factory وAzure Synapse لنسخ البيانات من وإلى قاعدة بيانات SQL Server واستخدام Data Flow لتحويل البيانات في قاعدة بيانات SQL Server. لمعرفة المزيد، اقرأ المقال التمهيدي ل Azure Data Factory أو Azure Synapse Analytics.
إشعار
هذا الموصل متوفر أيضا في Data Factory في Microsoft Fabric. للحصول على تكوين وميزات Fabric المحددة، راجع وثائق موصل Fabric SQL Server.
القدرات المدعومة
يدعم موصل SQL Server هذا للقدرات التالية:
| القدرات المدعومة | IR |
|---|---|
| Copy activity (المصدر/الحوض) | (1) (2) |
| تعيين تدفق البيانات (المصدر/ المتلقي) | (1) |
| نشاط البحث | (1) (2) |
| نشاط GetMetadata | (1) (2) |
| نشاط البرنامج النصي | (1) (2) |
| نشاط الإجراء المخزن | (1) (2) |
(1) Azure وقت تشغيل التكامل (2) وقت تشغيل التكامل المستضاف ذاتيا
للحصول على قائمة مخازن البيانات المدعومة كمصادر أو أحواض بواسطة نشاط النسخ، راجع جدول مخازن البيانات المدعومة.
على وجه التحديد، يدعم هذا الموصل من SQL Server:
- SQL Server الإصدار 2005 وما فوق.
- نسخ البيانات باستخدام SQL أو Windows authentication.
- كمصدر، استرداد البيانات باستخدام استعلام SQL أو إجراء مخزن. يمكنك أيضا اختيار النسخ المتوازي من المصدر SQL Server، راجع قسم Parallel copy من قاعدة بيانات SQL لمزيد من التفاصيل.
- كمتلقي، إنشاء جدول الوجهة تلقائياً إذا لم يكن موجوداً استناداً إلى المخطط المصدر؛ إلحاق البيانات بجدول أو استدعاء إجراء مُخزن باستخدام منطق مُخصص أثناء النسخ.
SQL Server Express LocalDB غير مدعوم.
هام
يجب أن يدعم مصدر البيانات نوع بيانات NVARCHAR لأنه يؤثر على ترميز البيانات عند تطبيق ترميز غير عالمي على البيانات.
المتطلبات الأساسية
إذا كان مخزن بياناتك يقع داخل شبكة محلية، أو شبكة افتراضية Azure، أو سحابة أمازون الافتراضية الخاصة، فعليك تكوين وقت تشغيل تكامل ذاتي المستضافة للاتصال به.
إذا كان مخزن بياناتك خدمة بيانات سحابية مدارة، يمكنك استخدام Azure Integration Runtime. إذا كان الوصول مقصورا على عناوين IP المعتمدة في قواعد جدار الحماية، يمكنك إضافة Azure Integration Runtime IPs إلى قائمة التصاريح.
يمكنك أيضا استخدام ميزة تشغيل وقت تشغيل تكامل الشبكة الافتراضية المدارة في Azure Data Factory للوصول إلى الشبكة المحلية دون الحاجة لتثبيت وتكوين وقت تشغيل تكامل ذاتي المستضافة.
لمزيد من المعلومات حول آليات وخيارات أمان الشبكة التي يدعمها Data Factory، راجع إستراتيجيات الوصول إلى البيانات.
الشروع في العمل
لتنفيذ نشاط النسخ باستخدام خط أنابيب ، يمكنك استخدام إحدى الأدوات أو مجموعات SDK التالية:
- أداة نسخ البيانات
- مدخل Azure
- مجموعة .NET SDK
- Python SDK
- Azure PowerShell
- واجهة برمجة التطبيقات REST
- Azure Resource Manager قالب
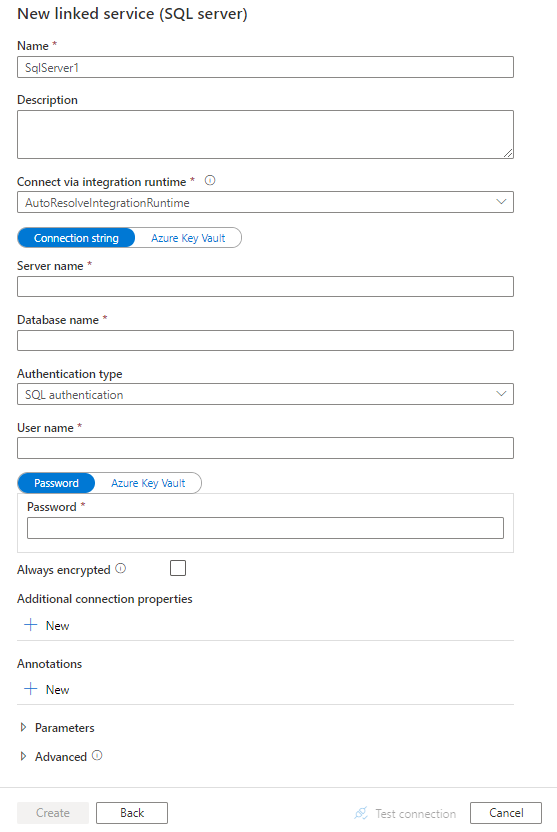
إنشاء خدمة مرتبطة ب SQL Server باستخدام واجهة المستخدم
استخدم الخطوات التالية لإنشاء خدمة مرتبطة ب SQL Server في واجهة بوابة Azure.
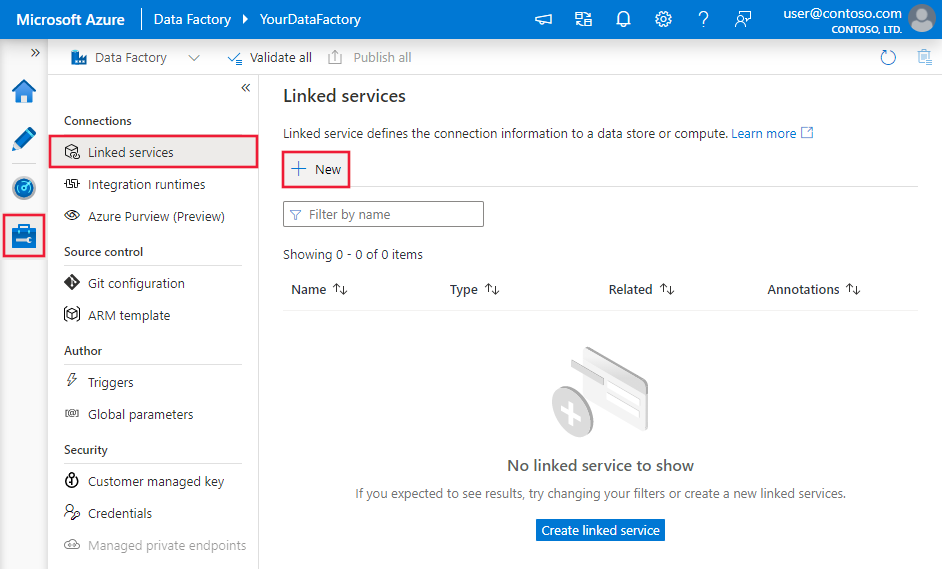
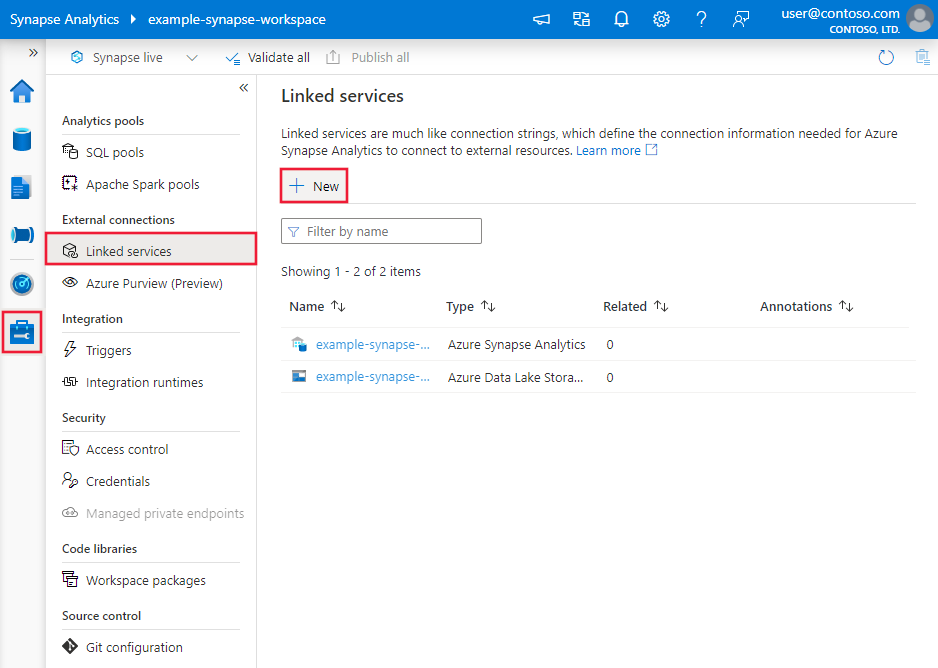
تصفح إلى تبويب الإدارة في Azure Data Factory أو مساحة Synapse الخاصة بك واختر Linked Services، ثم اضغط على New:
ابحث عن SQL واختر موصل SQL Server.

قم بتكوين تفاصيل الخدمة، واختبر الاتصال، وأنشئ الخدمة المرتبطة الجديدة.
تفاصيل تكوين الموصل
تقدم الأقسام التالية تفاصيل عن الخصائص المستخدمة لتعريف كيانات خط أنابيب Data Factory وSynapse الخاصة بموصل قاعدة بيانات SQL Server.
خصائص الخدمة المرتبطة
تدعم نسخة SQL Server Recommended TLS 1.3. راجع هذا section لترقية الخدمة المرتبطة SQL Server إذا كنت تستخدم نسخة Legacy. للحصول على تفاصيل الخاصية، راجع الأقسام المقابلة.
تلميح
إذا صادفت خطأ في رمز الخطأ "UserErrorFailedToConnectToSqlServer" ورسالة مثل "حد الجلسة لقاعدة البيانات هو XXX وتم الوصول إليه"، أضف Pooling=false إلى سلسلة الاتصال وحاول مرة أخرى.
إصدار الموصى به
يتم دعم هذه الخصائص العامة لخدمة مرتبطة بخادم SQL عند تطبيق الإصدار الموصى به :
| الخاصية | الوصف | مطلوب |
|---|---|---|
| النوع | يجب تعيين خاصية النوع إلى SqlServer. | نعم |
| الخادم | اسم أو عنوان الشبكة لمثيل خادم SQL الذي تريد الاتصال به. | نعم |
| قاعدة بيانات | اسم قاعدة البيانات. | نعم |
| نوع المصادقة | النوع المستخدم للمصادقة. القيم المسموح بها هي SQL (افتراضي)، Windows و UserAssignedManagedIdentity (فقط ل SQL Server على Azure VMs). انتقل إلى قسم المصادقة ذات الصلة حول خصائص ومتطلبات أساسية محددة. | نعم |
| alwaysEncryptedSettings | حدد معلومات alwaysencryptedsettings المطلوبة لتمكين Always Encrypted لحماية البيانات الحساسة المُخزنة في خادم SQL باستخدام الهوية المدارة أو كيان الخدمة. لمزيد من المعلومات، راجع مثال JSON الذي يتبع الجدول واستخدم القسم Always Encrypted. إذا لم يتم تحديده، فسيتم تعطيل الإعداد الافتراضي المشفر دائماً. | لا |
| تشفير | الإشارة إلى ما إذا كان تشفير TLS مطلوبا لجميع البيانات المرسلة بين العميل والخادم. الخيارات: إلزامية (ل true، default)/اختيارية (ل false)/strict. | لا |
| trustServerCertificate | الإشارة إلى ما إذا كان سيتم تشفير القناة أثناء تجاوز سلسلة الشهادات للتحقق من صحة الثقة. | لا |
| اسم المضيفInCertificate | اسم المضيف الذي يجب استخدامه عند التحقق من صحة شهادة الخادم للاتصال. عند عدم التحديد، يتم استخدام اسم الخادم للتحقق من صحة الشهادة. | لا |
| connectVia | يُستخدم وقت تشغيل التكامل هذا للاتصال بمخزن البيانات. تعرف على المزيد من قسم المتطلبات الأساسية. إذا لم يتم تحديده، يتم استخدام وقت تشغيل تكامل Azure الافتراضي. | لا |
للحصول على خصائص اتصال إضافية، راجع الجدول أدناه:
| الخاصية | الوصف | مطلوب |
|---|---|---|
| applicationIntent | نوع حمل عمل التطبيق عند الاتصال بخادم. القيم المسموح بها هي ReadOnly وReadWrite. |
لا |
| connectTimeout | طول الوقت (بالثوان) لانتظار اتصال بالخادم قبل إنهاء المحاولة وإنشاء خطأ. | لا |
| connectRetryCount | عدد عمليات إعادة الاتصال التي تمت محاولتها بعد تحديد فشل الاتصال الخامل. يجب أن تكون القيمة عددا صحيحا بين 0 و255. | لا |
| ConnectRetryInterval | مقدار الوقت (بالثوان) بين كل محاولة إعادة اتصال بعد تحديد فشل الاتصال الخامل. يجب أن تكون القيمة عددا صحيحا بين 1 و60. | لا |
| وقت موازنة التحميل | الحد الأدنى من الوقت (بالثوان) للاتصال للعيش في تجمع الاتصال قبل إتلاف الاتصال. | لا |
| commandTimeout | وقت الانتظار الافتراضي (بالثوان) قبل إنهاء محاولة تنفيذ أمر وإنشاء خطأ. | لا |
| الأمان المتكامل | القيم المسموح بها هي true أو false. عند تحديد false، حدد ما إذا كان اسم المستخدم وكلمة المرور محددين في الاتصال. عند تحديد true، يشير إلى ما إذا كانت بيانات اعتماد الحساب الحالية Windows تستخدم للمصادقة. |
لا |
| تجاوز الفشلPartner | اسم أو عنوان الخادم الشريك للاتصال به إذا كان الخادم الأساسي معلقا. | لا |
| maxPoolSize | الحد الأقصى لعدد الاتصالات المسموح بها في تجمع الاتصال للاتصال المحدد. | لا |
| minPoolSize | الحد الأدنى لعدد الاتصالات المسموح بها في تجمع الاتصال للاتصال المحدد. | لا |
| مجموعات متعددةActiveResultSets | القيم المسموح بها هي true أو false. عند تحديد true، يمكن للتطبيق الاحتفاظ بمجموعات نتائج نشطة متعددة (MARS). عند تحديد false، يجب على التطبيق معالجة أو إلغاء جميع مجموعات النتائج من دفعة واحدة قبل أن يتمكن من تنفيذ أي دفعات أخرى على هذا الاتصال. |
لا |
| multiSubnetFailover | القيم المسموح بها هي true أو false. إذا كان التطبيق الخاص بك يتصل بمجموعة توفر AlwaysOn (AG) على شبكات فرعية مختلفة، فقم بتعيين هذه الخاصية لتوفير true اكتشاف أسرع للخادم النشط حاليا والاتصال به. |
لا |
| packetSize | حجم وحدات البايت لحزم الشبكة المستخدمة للاتصال بمثيل الخادم. | لا |
| تجميع | القيم المسموح بها هي true أو false. عند تحديد true، سيتم تجميع الاتصال. عند تحديد false، سيتم فتح الاتصال بشكل صريح في كل مرة يتم فيها طلب الاتصال. |
لا |
مصادقة SQL
لاستخدام مصادقة SQL، بالإضافة إلى الخصائص العامة الموضحة في القسم السابق، حدد الخصائص التالية:
| الخاصية | الوصف | مطلوب |
|---|---|---|
| userName | اسم المستخدم الذي سيتم استخدامه عند الاتصال بالخادم. | نعم |
| كلمة المرور | كلمة المرور لاسم المستخدم. وضع علامة على هذا الحقل باعتباره SecureString لتخزينه بشكل آمن. أو يمكنك الإشارة إلى سر مخزن في Azure Key Vault. | لا |
مثال: استخدام مصادقة SQL
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
مثال: استخدم مصادقة SQL مع كلمة مرور في Azure Key Vault
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
مثال: استخدام Always Encrypted
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"alwaysEncryptedSettings": {
"alwaysEncryptedAkvAuthType": "ServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Windows authentication
لاستخدام Windows authentication، بالإضافة إلى الخصائص العامة الموضحة في القسم السابق، حدد الخصائص التالية:
| الخاصية | الوصف | مطلوب |
|---|---|---|
| userName | حدد اسم مستخدم. مثال على ذلك هو domainname\username. | نعم |
| كلمة المرور | حدد كلمة مرور لحساب المستخدم الذي حددته لاسم المستخدم. وضع علامة على هذا الحقل باعتباره SecureString لتخزينه بشكل آمن. أو يمكنك الإشارة إلى سر مخزن في Azure Key Vault. | نعم |
إشعار
لا يدعم Windows authentication في تدفق البيانات.
مثال: استخدم Windows authentication
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "Windows",
"userName": "<domain\\username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
مثال: استخدم Windows authentication مع كلمة مرور في Azure Key Vault
{
"name": "SqlServerLinkedService",
"properties": {
"annotations": [],
"type": "SqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "Windows",
"userName": "<domain\\username>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
مصادقة الهوية المدارة المعينة من قبل المستخدم
إشعار
المصادقة المدارة للهوية التي يعينها المستخدم تنطبق فقط على SQL Server على Azure الأجهزة الافتراضية.
يمكن ربط مصنع البيانات أو مساحة عمل Synapse ب idities managed المعينة من قبل المستخدم التي تمثل الخدمة عند المصادقة مع موارد أخرى في Azure. يمكنك استخدام هذه الهوية المدارة ل SQL Server على Azure VMs المصادقة. يمكن للمصنع المعين أو مساحة العمل Synapse الوصول إلى البيانات ونسخها من قاعدة البيانات الخاصة بك أو إليها باستخدام هذه الهوية.
لاستخدام مصادقة هوية مدارة من قبل عميل معيّن، بالإضافة إلى الخصائص العامة الموصوفة في القسم السابق، حدد الخصائص التالية:
| الخاصية | الوصف | مطلوب |
|---|---|---|
| بيانات الاعتماد | حدد الهوية المدارة المعينة من قبل المستخدم ككائن بيانات الاعتماد. | نعم |
عليك أيضًا اتباع الخطوات التالية:
امنح أذونات للهوية المدارة المعينة من قبل المستخدم.
تفعيل Microsoft Entra المصادقة إلى SQL Server على Azure الأجهزة الافتراضية.
قم بإنشاء مستخدمي قاعدة البيانات المضمنة للهوية المُدارة المعينة من قبل المستخدم. اتصل بقاعدة البيانات التي تريد نسخ البيانات منها أو إليها باستخدام أدوات مثل SQL Server Management Studio، مع هوية Microsoft Entra التي تحتوي على الأقل صلاحيات تعديل أي مستخدم. قم بتشغيل T-SQL التالي:
CREATE USER [your_resource_name] FROM EXTERNAL PROVIDER;قم بإنشاء هوية مدارة واحدة أو عدة هويات مدارة يعينها المستخدم وامنح الهوية المدارة المعينة من قِبَل المستخدم الأذونات المطلوبة كما تفعل عادةً لمستخدمي SQL وغيرهم. قم بتشغيل التعليمات البرمجية التالية. لمزيد من الخيارات، يرجى مراجعة هذا المستند.
ALTER ROLE [role name] ADD MEMBER [your_resource_name];تعيين هوية مدارة معينة من قبل المستخدم، واحدة أو متعددة، إلى مصنع البيانات وإنشاء بيانات اعتماد لكل هوية مدارة معينة من قبل المستخدم.
قم بتكوين خدمة مرتبطة ب SQL Server.
مثال
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "UserAssignedManagedIdentity",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
الإصدار القديم
يتم دعم هذه الخصائص العامة لخدمة مرتبطة بخادم SQL عند تطبيق الإصدار القديم :
| الخاصية | الوصف | مطلوب |
|---|---|---|
| النوع | يجب تعيين خاصية النوع إلى SqlServer. | نعم |
| alwaysEncryptedSettings | حدد معلومات alwaysencryptedsettings المطلوبة لتمكين Always Encrypted لحماية البيانات الحساسة المُخزنة في خادم SQL باستخدام الهوية المدارة أو كيان الخدمة. لمزيد من المعلومات، راجع قسم استخدام Always Encrypted. إذا لم يتم تحديده، فسيتم تعطيل الإعداد الافتراضي المشفر دائماً. | لا |
| connectVia | يُستخدم وقت تشغيل التكامل هذا للاتصال بمخزن البيانات. تعرف على المزيد من قسم المتطلبات الأساسية. إذا لم يتم تحديده، يتم استخدام وقت تشغيل تكامل Azure الافتراضي. | لا |
يدعم موصل خادم SQL هذا أنواع المصادقة التالية. راجع الأقسام المقابلة للاطلاع على التفاصيل.
مصادقة SQL للإصدار القديم
لاستخدام مصادقة SQL، بالإضافة إلى الخصائص العامة الموضحة في القسم السابق، حدد الخصائص التالية:
| الخاصية | الوصف | مطلوب |
|---|---|---|
| سلسلة الاتصال | حدد معلومات connectionString المطلوبة للاتصال بقاعدة بيانات SQL Server. حدد اسم تسجيل الدخول كاسم مستخدم، وتأكد من تعيين قاعدة البيانات التي تريد الاتصال بها إلى تسجيل الدخول هذا. | نعم |
| كلمة المرور | إذا أردت وضع كلمة مرور في Azure Key Vault، قم بإزالة تكوين password من سلسلة الاتصال. لمزيد من المعلومات، راجع بيانات اعتماد المتجر في Azure Key Vault. |
لا |
Windows authentication للنسخة القديمة
لاستخدام Windows authentication، بالإضافة إلى الخصائص العامة الموضحة في القسم السابق، حدد الخصائص التالية:
| الخاصية | الوصف | مطلوب |
|---|---|---|
| سلسلة الاتصال | حدد معلومات connectionString المطلوبة للاتصال بقاعدة بيانات SQL Server. | نعم |
| userName | حدد اسم مستخدم. مثال على ذلك هو domainname\username. | نعم |
| كلمة المرور | حدد كلمة مرور لحساب المستخدم الذي حددته لاسم المستخدم. وضع علامة على هذا الحقل باعتباره SecureString لتخزينه بشكل آمن. أو يمكنك الإشارة إلى سر مخزن في Azure Key Vault. | نعم |
خصائص مجموعة البيانات
للحصول على قائمة كاملة بالأقسام والخصائص المتوفرة لتعريف مجموعات البيانات، راجع مقالة مجموعات البيانات. يوفر هذا القسم قائمة بالخصائص المدعومة من قبل مجموعة بيانات SQL Server.
لنسخ البيانات من وإلى قاعدة بيانات SQL Server، تدعم الخصائص التالية:
| الخاصية | الوصف | مطلوب |
|---|---|---|
| النوع | يجب تعيين خاصية نوع مجموعة البيانات إلى SqlServerTable. | نعم |
| Schema | اسم المخطط. | لا للمصدر، نعم للمتلقي |
| طاولتنا | اسم الجدول/طريقة العرض. | لا للمصدر، نعم للمتلقي |
| اسم الجدول | اسم الجدول/طريقة العرض مع المخطط. هذه الخاصية مدعومة للتوافق مع الإصدارات السابقة. بالنسبة لحمل العمل الجديد، استخدم schema وtable. |
لا للمصدر، نعم للمتلقي |
مثال
{
"name": "SQLServerDataset",
"properties":
{
"type": "SqlServerTable",
"linkedServiceName": {
"referenceName": "<SQL Server linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
خصائص Copy activity
للحصول على قائمة كاملة بالأقسام والخصائص المتاحة للاستخدام لتعريف الأنشطة، راجع مقالة خطوط التدفقات. يوفر هذا القسم قائمة بالخصائص المدعومة من قبل مصدر SQL Server ومصرفه.
SQL Server كمصدر
تلميح
لتحميل البيانات من SQL Server بكفاءة باستخدام تقسيم البيانات، تعلم المزيد من Parallel copy من قاعدة بيانات SQL.
لنسخ البيانات من SQL Server، اضبط نوع المصدر في نشاط النسخ إلى SqlSource. الخصائص التالية مدعومة في قسم مصدر نشاط النسخ:
| الخاصية | الوصف | مطلوب |
|---|---|---|
| النوع | يجب تعيين خاصية نوع مصدر نشاط النسخ إلى SqlSource. | نعم |
| sqlReaderQuery | استخدم استعلام SQL المخصص لقراءة البيانات. مثال على ذلك select * from MyTable . |
لا |
| sqlReaderStoredProcedureName | هذه الخاصية هي اسم الإجراء المخزن الذي يقرأ البيانات من الجدول المصدر. يجب أن تكون بوابة لغة الاستعلامات المركبة الأخيرة عبارة عن مصطلح SELECT في الإجراء المُخزن. | لا |
| storedProcedureParameters | هذه المعلمات من أجل الإجراء المخزن. القيم المسموح بها هي أزواج الاسم أو القيمة. يجب أن تتطابق أسماء وأغلفة المعلمات مع الأسماء والغلاف الخاص بمعلمات الإجراء المخزن. |
لا |
| isolationLevel | يحدد سلوك تأمين المعاملة لمصدر SQL. القيم المسموح بها هي: ReadCommitted، وReadUncommitted، وRepeatableRead، وSerializable، وSnapshot. إذا لم يتم تحديده، فسيتم استخدام مستوى العزل الافتراضي لقاعدة البيانات. يرجى مراجعة هذا المستند للحصول على المزيد من التفاصيل. | لا |
| خيارات التقسيم | يحدد خيارات تقسيم البيانات المستخدمة لتحميل البيانات من SQL Server. القيم المسموح بها هي: None (افتراضي)، وPhysicalPartitionsOfTable، وDynamicRange. عند تفعيل خيار تقسيم (أي ليس None)، يتم التحكم في درجة التوازي لتحميل البيانات المتزامنة من SQL Server بواسطة إعداد parallelCopies في نشاط النسخ. |
لا |
| partitionSettings | حدد مجموعة الإعدادات الخاصة بتقسيم البيانات. تطبيق عندما لا يكون خيار التقسيم None. |
لا |
تحت partitionSettings: |
||
| partitionColumnName | حدد اسم عمود المصدر بعدد صحيح أو نوع التاريخ/التاريخ والوقت (int أو smallint أو bigint أو date أو smalldatetime أو datetime أو datetime2 أو datetimeoffset) التي سيتم استخدامها عن طريق تقسيم النطاق للنسخ المتوازي. إذا لم يتم تحديده، فسيتم اكتشاف الفهرس أو المفتاح الأساسي للجدول تلقائياً واستخدامهما كعمود للتقسيم.تُطبق عندما يكون خيار التقسيم هو DynamicRange. إذا كنت تستخدم استعلاماً لاسترداد البيانات المصدر، اربط ?DfDynamicRangePartitionCondition في عبارة WHERE. على سبيل المثال، راجع القسم النسخ المتوازي من قاعدة بيانات SQL. |
لا |
| التقسيم | القيمة القصوى لعمود القسم لتقسيم نطاق القسم. تُستخدم هذه القيمة لتحديد مرحلة القسم، وليس لتصفية الصفوف في الجدول. سيتم تقسيم ونسخ جميع الصفوف في الجدول أو نتيجة الاستعلام. إذا لم يتم تحديده، يكشف نشاط النسخ القيمة تلقائياً. تُطبق عندما يكون خيار التقسيم هو DynamicRange. على سبيل المثال، راجع القسم النسخ المتوازي من قاعدة بيانات SQL. |
لا |
| partitionLowerBound | الحد الأدنى لقيمة عمود القسم لتقسيم نطاق القسم. تُستخدم هذه القيمة لتحديد مرحلة القسم، وليس لتصفية الصفوف في الجدول. سيتم تقسيم ونسخ جميع الصفوف في الجدول أو نتيجة الاستعلام. إذا لم يتم تحديده، يكشف نشاط النسخ القيمة تلقائياً. تُطبق عندما يكون خيار التقسيم هو DynamicRange. على سبيل المثال، راجع القسم النسخ المتوازي من قاعدة بيانات SQL. |
لا |
لاحظ النقاط التالية:
- إذا تم تحديد sqlReaderQuery ل SqlSource، فإن نشاط النسخ يشغل هذا الاستعلام ضد المصدر SQL Server للحصول على البيانات. يمكنك أيضاً تحديد إجراء مخزن عن طريق تحديد sqlReaderStoredProcedureName وstoredProcedureParameters إذا كان الإجراء المُخزن يأخذ المعلمات.
- عند استخدام الإجراء المُخزن في المصدر لاسترداد البيانات، لاحظ إذا تم تصميم الإجراء المُخزن الخاص بك لإرجاع مخطط مختلف عند تمرير قيمة معلمة مختلفة، فقد تواجه عطلاً أو ترى نتيجة غير متوقعة عند استيراد مخطط من واجهة المستخدم أو عند نسخ البيانات إلى قاعدة بيانات SQL باستخدام إنشاء الجدول التلقائي.
مثال: استخدام استعلام SQL
"activities":[
{
"name": "CopyFromSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<SQL Server input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
مثال: استخدام إجراء مُخزن
"activities":[
{
"name": "CopyFromSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<SQL Server input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
تعريف الإجراء المُخزن
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
SQL Server كحوض
تلميح
تعرف أكثر على سلوكيات الكتابة المدعومة، والتكوينات، وأفضل الممارسات من أفضل الممارسات لتحميل البيانات في SQL Server.
لنسخ البيانات إلى SQL Server، اضبط نوع المصرف في نشاط النسخ على SqlSink. الخصائص التالية مدعومة في قسم مصدر نشاط النسخ:
| الخاصية | الوصف | مطلوب |
|---|---|---|
| النوع | يجب تعيين خاصية نوع متلقي نشاط النسخ إلى SqlSink. | نعم |
| preCopyScript | تحدد هذه الخاصية استعلام SQL ليتم تشغيل نشاط النسخ قبل كتابة البيانات في SQL Server. يتم استدعاؤه مرة واحدة فقط لكل نسخة تشغيل. يمكنك استخدام هذه الخاصية لتنظيف البيانات المحملة مسبقاً. | لا |
| tableOption | تحديد ما إذا كان سيتم إنشاء جدول المتلقي تلقائياً إذا لم يكن موجوداً استناداً إلى المخطط المصدر. لا يتم دعم الإنشاء التلقائي للجدول عندما يحدد التجمع الإجراء المخزن. القيم المسموح بها هي: none (افتراضي)، وautoCreate. |
لا |
| sqlWriterStoredProcedureName | اسم الإجراء المُخزن الذي يحدد كيفية تطبيق البيانات المصدر في الجدول الهدف. سيتم استدعاء هذا الإجراء المُخزن كل دفعة. بالنسبة للعمليات التي يتم تشغيلها مرة واحدة فقط وليس لها علاقة ببيانات المصدر، على سبيل المثال، الحذف أو الاقتطاع، استخدم الخاصية preCopyScript.يرجى مراجعة مثال من استدعاء إجراء مُخزن من متلقي SQL. |
لا |
| storedProcedureTableTypeParameterName | اسم المعلمة لنوع الجدول المحدد في الإجراء المخزن. | لا |
| sqlWriterTableType | اسم نوع الجدول الذي سيتم استخدامه في الإجراء المخزن. يجعل نشاط النسخ البيانات التي يتم نقلها متاحة في جدول مؤقت بنوع الجدول الماثل. يمكن بعد ذلك أن يدمج رمز الإجراء المخزن البيانات التي يتم نسخها مع البيانات الموجودة. | لا |
| storedProcedureParameters | معلمات الإجراء المخزن. القيم المسموح بها هي أزواج الاسم والقيمة. يجب أن تتطابق الأسماء وغلاف المعلمات مع الأسماء والغلاف الخاص بمعلمات الإجراء المخزن. |
لا |
| writeBatchSize | عدد الصفوف المراد إدراجها في جدول SQL لكل دفعة. القيم المسموح بها هي أعداد صحيحة لعدد الصفوف. بشكل افتراضي، تحدد الخدمة ديناميكياً حجم الدُفعة المناسب بناءً على حجم الصف. |
لا |
| writeBatchTimeout | وقت الانتظار حتى تكتمل عملية الإجراء الإدراج والإصدار والتخزين قبل انتهاء المهلة. القيم المسموح بها هي للمدى الزمني. مثال على ذلك هو "00:30:00" لمدة 30 دقيقة. إذا لم يتم تحديد أي قيمة، يتم تعيين المهلة الافتراضية إلى "00:30:00". |
لا |
| maxConcurrentConnections | الحد الأعلى للاتصالات المتزامنة التي تم إنشاؤها إلى مخزن البيانات أثناء تشغيل النشاط. حدد قيمة فقط عندما تريد تحديد الاتصالات المتزامنة. | لا |
| WriteBehavior | حدد سلوك الكتابة لنشاط النسخ لتحميل البيانات إلى قاعدة بيانات SQL Server. القيمة المسموح بها هي Insert و Upsert. تستخدم الخدمة insert لتحميل البيانات بشكلٍ افتراضي. |
لا |
| upsertSettings | حدد مجموعة إعدادات سلوك الكتابة. استخدمها عندما يكون خيار WriteBehavior هو Upsert. |
لا |
تحت upsertSettings: |
||
| useTempDB | حدد ما إذا كنت تريد استخدام الجدول المؤقت العمومي أو الجدول الفعلي كجدول مؤقت ل upsert. تستخدم الخدمة الجدول المؤقت العمومي كجدول مؤقت بشكلٍ افتراضي. القيمة هي true. |
لا |
| interimSchemaName | حدد المخطط المؤقت لإنشاء جدول مؤقت إذا تم استخدام جدول فعلي. ملاحظة: يحتاج المستخدم إلى الحصول على إذن لإنشاء أي جدول وحذفه. بشكل افتراضي، سيشارك الجدول المؤقت نفس المخطط كجدول متلقي. استخدمه عندما يكون خيار useTempDB هو False. |
لا |
| المفاتيح | حدد أسماء الأعمدة لتعريف الصف الفريد. يمكن استخدام مفتاح واحد أو سلسلة من المفاتيح. إذا لم يتم تحديده، فسيتم استخدام عمود المفتاح الأساسي. | لا |
مثال 1: إلحاق البيانات
"activities":[
{
"name": "CopyToSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<SQL Server output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SqlSink",
"tableOption": "autoCreate",
"writeBatchSize": 100000
}
}
}
]
مثال 2: استدعاء إجراء مخزن أثناء النسخ
تعرف على مزيد من التفاصيل من استدعاء إجراء مخزن من متلقي SQL.
"activities":[
{
"name": "CopyToSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<SQL Server output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SqlSink",
"sqlWriterStoredProcedureName": "CopyTestStoredProcedureWithParameters",
"storedProcedureTableTypeParameterName": "MyTable",
"sqlWriterTableType": "MyTableType",
"storedProcedureParameters": {
"identifier": { "value": "1", "type": "Int" },
"stringData": { "value": "str1" }
}
}
}
}
]
مثال 3: بيانات Upsert
"activities":[
{
"name": "CopyToSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<SQL Server output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SqlSink",
"tableOption": "autoCreate",
"writeBehavior": "upsert",
"upsertSettings": {
"useTempDB": true,
"keys": [
"<column name>"
]
},
}
}
}
]
نسخة موازية من قاعدة بيانات SQL
يوفر موصل SQL Server في نشاط النسخ تقسيم البيانات المدمج لنسخ البيانات بالتوازي. يمكنك العثور على خيارات تقسيم البيانات في علامة التبويب Source لنشاط النسخ.
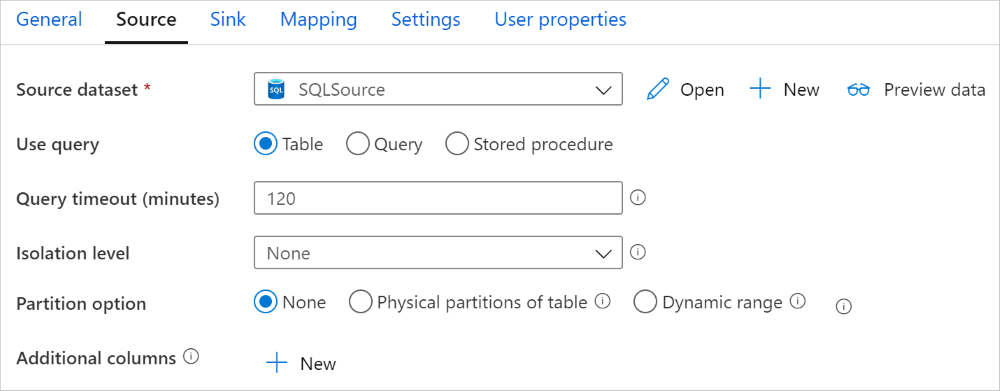
عند تفعيل النسخ المقسمة، يقوم نشاط النسخ بتشغيل استعلامات متوازية على مصدر SQL Server لتحميل البيانات حسب الأقسام. يتم التحكم في الدرجة المتوازية بواسطة parallelCopies الإعداد على نشاط النسخ. على سبيل المثال، إذا قمت بتعيين parallelCopies إلى أربعة، فإن الخدمة تولد وتشغل أربع استعلامات في نفس الوقت بناء على خيار التقسيم والإعدادات التي حددتها، وكل استعلام يسترجع جزءا من البيانات من SQL Server الخاص بك.
ينصح بتفعيل النسخ المتوازية مع تقسيم البيانات خاصة عند تحميل كمية كبيرة من البيانات من SQL Server الخاص بك. فيما يلي تكوينات مقترحة لسيناريوهات مختلفة. عند نسخ البيانات إلى مخزن بيانات مستند إلى ملف، يوصى بالكتابة إلى مجلد كملفات متعددة (حدد اسم المجلد فقط)، وفي هذه الحالة يكون الأداء أفضل من الكتابة إلى ملف واحد.
| السيناريو | الإعدادات المقترحة |
|---|---|
| تحميل كامل من جدول كبير بأقسام فعلية. |
خيار التقسيم: أقسام فعلية للجدول. أثناء التنفيذ، تكتشف الخدمة تلقائياً الأقسام المادية ونسخ البيانات حسب الأقسام. للتحقق مما إذا كان الجدول يحتوي على قسم فعلي أم لا، يمكنك الرجوع إلى هذا الاستعلام. |
| تحميل كامل من جدول كبير، بدون أقسام فعلية، مع وجود عدد صحيح أو عمود التاريخ والوقت لتقسيم البيانات. |
خيارات التقسيم: تقسيم النطاق الديناميكي. عمود التقسيم (اختياري): حدد العمود المستخدم لتقسيم البيانات. إذا لم يتم تحديده، فسيتم استخدام عمود المفتاح الأساسي. الحد الأعلى للتقسيموالحد الأدنى للتقسيم (اختياري): حدد إذا كنت تريد تحديد المقدار الموسع للتقسيم. هذا ليس لتصفية الصفوف في الجدول، سيتم تقسيم ونسخ جميع الصفوف في الجدول. إذا لم يتم تحديده، فإن نسخ النشاط التلقائي يكتشف القيم ويمكن أن يستغرق وقتاً طويلاً اعتماداً على قيم MIN وMAX. من المستحسن تقديم الحد الأعلى والحد الأدنى. على سبيل المثال، إذا كان معرّف عمود التقسيم يحتوي على قيم تتراوح من 1 إلى 100، وقمت بتعيين الحد الأدنى كـ 20 والحد الأعلى كـ 80، مع النسخ المتوازي كـ 4، تسترد الخدمة البيانات من خلال 4 أقسام - المعرّفات في النطاق <= 20 و[21 و50] و[51 و80] و>=81 على التوالي. |
| تحميل كمية كبيرة من البيانات باستخدام استعلام مخصص، دون أقسام فعلية، مع وجود عدد صحيح أو عمود التاريخ/التاريخ والوقت لتقسيم البيانات. |
خيارات التقسيم: تقسيم النطاق الديناميكي. استعلام: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.عمود التقسيم: حدد العمود المستخدم لتقسيم البيانات. الحد الأعلى للتقسيموالحد الأدنى للتقسيم (اختياري): حدد إذا كنت تريد تحديد المقدار الموسع للتقسيم. هذا ليس لتصفية الصفوف في الجدول، سيتم تقسيم كافة الصفوف في نتيجة الاستعلام ونسخها. إذا لم يتم تحديده، يكشف نشاط النسخ القيمة تلقائياً. على سبيل المثال، إذا كان معرّف عمود التقسيم يحتوي على قيم تتراوح من 1 إلى 100، وقمت بتعيين الحد الأدنى كـ 20 والحد الأعلى كـ 80، مع النسخ المتوازي كـ 4، تسترد الخدمة البيانات من خلال 4 أقسام - المعرّفات في النطاق <= 20 و[21 و50] و[51 و80] و>=81 على التوالي. فيما يلي المزيد من نماذج الاستعلامات لسيناريوهات مختلفة: 1. الاستعلام عن الجدول بأكمله: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition2. الاستعلام من جدول مع تحديد عمود وعوامل تصفية إضافية ل where-clause: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>3. الاستعلام باستخدام الاستعلامات الفرعية: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>4. الاستعلام مع القسم في الاستعلام الفرعي: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
أفضل الممارسات لتحميل البيانات مع خيار التقسيم:
- اختر عمود مميز كعمود تقسيم (مثل المفتاح الأساسي أو المفتاح الفريد) لتجنب انحراف البيانات.
- إذا كان الجدول يحتوي على قسم مضمن، فاستخدم خيار القسم "الأقسام المادية للجدول" للحصول على أداء أفضل.
- إذا استخدمت Azure Integration Runtime لنسخ البيانات، يمكنك تعيين وحدات "وحدات تكامل البيانات (DIU)" (>4) أكبر لاستخدام موارد حوسبة أكبر. تحقق من السيناريوهات القابلة للتطبيق هناك.
- تتحكم "درجة توازي النسخ" في أرقام التقسيم، ويؤدي تعيين هذا الرقم إلى عدد كبير جداً في بعض الأحيان إلى الإضرار بالأداء، ويوصي بتعيين هذا الرقم إلى (DIU أو عدد عقد وقت تشغيل التكامل المستضاف ذاتياً) * (2 إلى 4).
مثال: تحميل كامل من جدول كبير مع أقسام فعلية
"source": {
"type": "SqlSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
مثال: الاستعلام مع تقسيم النطاق الديناميكي
"source": {
"type": "SqlSource",
"query": "SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
نموذج استعلام للتحقق من التقسيم الفعلي
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
إذا كان الجدول يحتوي على تقسيم فعلي، فسترى "HasPartition" كـ "yes" كما يلي.

أفضل الممارسات لتحميل البيانات إلى SQL Server
عند نسخ البيانات إلى SQL Server، قد تحتاج إلى سلوك كتابة مختلف:
- إلحاق: تحتوي بيانات المصدر الخاصة بي على سجلات جديدة فقط.
- Upsert: تحتوي بيانات المصدر الخاصة بي على كل من الإدراجات والتحديثات.
- الاستبدال: أريد إعادة تحميل جدول الأبعاد بأكمله في كل مرة.
- الكتابة باستخدام منطق مخصص: أحتاج معالجة إضافية قبل الإدراج النهائي في الجدول الوجهة.
راجع الأقسام الخاصة بكيفية التكوين وأفضل الممارسات.
قم بإلحاق البيانات
إضافة البيانات هي السلوك الافتراضي لموصل SQL Server هذا. تقوم الخدمة بإدراج مجمع للكتابة إلى الجدول بكفاءة. يمكنك تكوين المصدر والإيداع وفقاً لذلك في نشاط النسخ.
إدخال وتحديث البيانات
يدعم Copy activity الآن تحميل البيانات بشكل أصلي في جدول مؤقت لقاعدة البيانات ثم تحديث البيانات في جدول الحوض إذا كان هناك مفتاح وإدخال بيانات جديدة. لمعرفة المزيد عن إعدادات upsert في أنشطة النسخ، راجع SQL Server ك sink.
استبدال الجدول بأكمله
يمكنك تكوين الخاصية preCopyScript في متلقي نشاط نسخ. في هذه الحالة، لكل نشاط نسخ يتم تشغيله، تقوم الخدمة بتشغيل البرنامج النصي أولاً. ثم يقوم بتشغيل النسخة لإدراج البيانات. على سبيل المثال، للكتابة فوق الجدول بأكمله بأحدث البيانات، حدد برنامجاً نصياً لحذف جميع السجلات أولاً قبل تحميل البيانات الجديدة من المصدر بشكل مجمع.
اكتب البيانات بمنطق مخصص
تشبه خطوات كتابة البيانات باستخدام منطق مخصص تلك الموضحة في قسم Upsert data. عندما تحتاج إلى تطبيق معالجة إضافية قبل الإدراج النهائي لبيانات المصدر في الجدول الوجهة، يمكنك التحميل إلى جدول مرحلي ثم استدعاء نشاط الإجراء المُخزن أو استدعاء إجراء مخزن في متلقي نشاط النسخ لتطبيق البيانات.
استدعاء إجراء مخزن من متلقي SQL
عند نسخ البيانات إلى قاعدة بيانات SQL Server، يمكنك أيضا تكوين واستدعاء إجراء مخزن يحدده المستخدم مع معلمات إضافية على كل دفعة من جدول المصدر. تستفيد ميزة الإجراء المخزن من المعلمات ذات القيم الجدولية. لاحظ أن الخدمة تقوم تلقائياً بتضمين الإجراء المخزن في المعاملة الخاصة بها، بحيث تصبح أي معاملة تم إنشاؤها داخل الإجراء المخزن معاملة متداخلة، وقد يكون لها آثار على معالجة الاستثناءات.
يمكنك استخدام إجراء مُخزن عندما لا تخدم آليات النسخ المضمنة الغرض. مثال على ذلك عندما تريد تطبيق معالجة إضافية قبل الإدراج النهائي لبيانات المصدر في الجدول الوجهة. توجد بعض أمثلة المعالجة الإضافية عندما تريد دمج الأعمدة والبحث عن قيم إضافية وإدراجها في أكثر من جدول.
يوضح المثال التالي كيفية استخدام إجراء مخزن لإجراء رفع مستوى إلى جدول في قاعدة بيانات SQL Server. افترض أن بيانات الإدخال وجدول Marketing المتلقي تحتوي كل منها على ثلاثة أعمدة: ProfileID، وState، وCategory. قم بإدراج الصفوف أو تحديثها "upsert" استناداً إلى عمود ProfileID، وطبقه فقط لفئة معينة تسمى "ProductA".
في قاعدة البيانات الخاصة بك، قم بتعريف نوع الجدول بنفس اسم sqlWriterTableType. مخطط نوع الجدول هو نفس المخطط الذي تم إرجاعه بواسطة بيانات الإدخال الخاصة بك.
CREATE TYPE [dbo].[MarketingType] AS TABLE( [ProfileID] [varchar](256) NOT NULL, [State] [varchar](256) NOT NULL, [Category] [varchar](256) NOT NULL )في قاعدة البيانات الخاصة بك، قم بتعريف الإجراء المُخزن بنفس الاسم مثل sqlWriterStoredProcedureName. يتعامل مع بيانات الإدخال من المصدر المحدد ويدمج في جدول الإخراج. اسم معلمة نوع الجدول في الإجراء المُخزن هو نفسه tableName المُحدد في مجموعة البيانات.
CREATE PROCEDURE spOverwriteMarketing @Marketing [dbo].[MarketingType] READONLY, @category varchar(256) AS BEGIN MERGE [dbo].[Marketing] AS target USING @Marketing AS source ON (target.ProfileID = source.ProfileID and target.Category = @category) WHEN MATCHED THEN UPDATE SET State = source.State WHEN NOT MATCHED THEN INSERT (ProfileID, State, Category) VALUES (source.ProfileID, source.State, source.Category); ENDحدد قسم متلقي SQL في نشاط النسخ كما يلي:
"sink": { "type": "SqlSink", "sqlWriterStoredProcedureName": "spOverwriteMarketing", "storedProcedureTableTypeParameterName": "Marketing", "sqlWriterTableType": "MarketingType", "storedProcedureParameters": { "category": { "value": "ProductA" } } }
تعيين خصائص تدفق البيانات
عند تحويل البيانات في رسم خريطة تدفق البيانات، يمكنك القراءة والكتابة إلى جداول من قاعدة بيانات SQL Server. لمزيد من المعلومات، راجع تحويل المصدر و تحويل المتلقي في تعيين تدفقات البيانات.
إشعار
للوصول إلى SQL Server الموقع، تحتاج إلى استخدام Azure Data Factory أو Synapse workspace Managed Virtual Network باستخدام نقطة نهاية خاصة. راجع هذا البرنامج التعليمي للحصول على خطوات مفصلة.
تحويل المصدر
يوضح الجدول أدناه الخصائص المدعومة من قبل مصدر SQL Server. يمكنك تحرير هذه الخصائص في علامة التبويب "Source options".
| Name | الوصف | مطلوب | القيم المسموح بها | خاصية البرنامج النصي لتدفق البيانات |
|---|---|---|---|---|
| جدول | إذا حددت الجدول كمدخلات، فإن تدفق البيانات يجلب جميع البيانات من الجدول المحدد في مجموعة البيانات. | لا | - | - |
| الاستعلام | إذا حددت الاستعلام كإدخال، فحدد استعلام SQL لجلب البيانات من المصدر، والذي يتجاوز أي جدول تحدده في مجموعة البيانات. يعد استخدام الاستعلامات طريقة رائعة لتقليل عدد الصفوف للاختبار أو عمليات البحث. لا يتوفر دعم لعبارة Order By، ولكن يمكنك تعيين عبارة SELECT FROM كاملة. يمكنك أيضاً استخدام وظائف الجدول المعرفة بواسطة المستخدم. تحديد * من udfGetData() هو UDF في SQL الذي يقوم بإرجاع جدول يمكنك استخدامه في تدفق البيانات. مثال الاستعلام: Select * from MyTable where customerId > 1000 and customerId < 2000 |
لا | السلسلة | استعلام |
| حجم الدفعة | حدد حجم دفعة لتقسيم البيانات الكبيرة إلى قراءات. | لا | رقم صحيح | batchSize |
| مستوى العزل | اختر أحد مستويات العزل التالية: - قراءة ثابتة - قراءة غير ثابتة (افتراضي) - القراءة المتكررة - قابل للتسلسل - لا شيء (تجاهل مستوى العزل) |
لا | READ_COMMITTED READ_UNCOMMITTED REPEATABLE_READ SERIALIZABLE لا |
isolationLevel |
| تمكين الاستخراج التزايدي | استخدم هذا الخيار لإخبار ADF بمعالجة الصفوف التي تغيرت منذ آخر مرة تم فيها تنفيذ البنية الأساسية لبرنامج ربط العمليات التجارية فقط. | لا | - | - |
| عمود تاريخ تزايدي | عند استخدام ميزة الاستخراج التزايدي، يجب عليك اختيار عمود التاريخ/الوقت الذي ترغب في استخدامه كعلامة مائية في الجدول المصدر. | لا | - | - |
| تمكين التقاط بيانات التغيير الأصلي (معاينة) | استخدم هذا الخيار لإخبار ADF بمعالجة بيانات دلتا التي تم التقاطها بواسطة تقنية التقاط بيانات تغيير SQL فقط منذ آخر مرة تم فيها تنفيذ البنية الأساسية لبرنامج ربط العمليات التجارية. باستخدام هذا الخيار، سيتم تحميل بيانات دلتا بما في ذلك إدراج الصف والتحديث والحذف تلقائيا دون الحاجة إلى أي عمود تاريخ تزايدي. تحتاج إلى تفعيل تغيير التقاط البيانات على SQL Server قبل استخدام هذا الخيار في ADF. لمزيد من المعلومات حول هذا الخيار في ADF، راجع التقاط بيانات التغيير الأصلي. | لا | - | - |
| بدء القراءة من البداية | سيؤدي تعيين هذا الخيار مع الاستخراج التزايدي إلى توجيه ADF لقراءة جميع الصفوف عند التنفيذ الأول للبنية الأساسية لبرنامج ربط العمليات التجارية مع تشغيل الاستخراج التزايدي. | لا | - | - |
تلميح
تعبير الجدول الشائع (CTE) في SQL غير مدعوم في وضع استعلام تدفق بيانات التعيين، لأن الشرط الأساسي لاستخدام هذا الوضع هو أنه يمكن استخدام الاستعلامات في عبارة SQL query FROM ولكن لا يمكن لـ CTEs إجراء ذلك. لاستخدام CTEs، تحتاج إلى إنشاء إجراء مخزّن باستخدام الاستعلام التالي:
CREATE PROC CTESP @query nvarchar(max)
AS
BEGIN
EXECUTE sp_executesql @query;
END
ثم استخدم وضع الإجراء المخزّن في تحويل المصدر لتدفق بيانات التعيين وتعيين @query مثال يشبه with CTE as (select 'test' as a) select * from CTE. ثم يمكنك استخدام CTEs كما هو متوقع.
مثال على نص المصدر في SQL Server
عندما تستخدم SQL Server كنوع المصدر، يكون سكريبت تدفق البيانات المرتبط به:
source(allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
query: 'select * from MYTABLE',
format: 'query') ~> SQLSource
تحويل المتلقي
الجدول أدناه يسرد الخصائص المدعومة من قبل SQL Server sink. يمكنك تحرير هذه الخصائص في علامة التبويب "Sink options".
| Name | الوصف | مطلوب | القيم المسموح بها | خاصية البرنامج النصي لتدفق البيانات |
|---|---|---|---|---|
| أسلوب التحديث | حدد العمليات المسموح بها في وجهة قاعدة البيانات. الوضع الافتراضي هو السماح فقط بالإدراج. لتحديث صفوف أو إجراء upsert "إدراج الصفوف أو تحديثها" أو حذفها، يلزم إجراء تحويل في الصف المعدل لوضع علامة على الصفوف التي تخضع لتلك الإجراءات. |
نعم |
true أو false |
قابل للحذف قابلة للادراج قابل للتحديث قابل للإدراج أو التحديث |
| الأعمدة الرئيسية | للتحديثات وعمليات الإدراج أو التحديث "upsert" والحذف، يجب تعيين عمود (أعمدة) المفاتيح لتحديد الصف المطلوب تعديله. سيتم استخدام اسم العمود الذي تختاره كمفتاح كجزء من التحديث، أو upsert، أو الحذف اللاحق. لذلك، يجب اختيار عمود موجود في تعيين "المتلقي". |
لا | صفيف | المفاتيح |
| تخطي كتابة أعمدة المفتاح | إذا كنت ترغب في عدم كتابة القيمة إلى عمود المفتاح، فحدد "Skip writing key columns". | لا |
true أو false |
skipKeyWrites |
| إجراء الجدول | يحدد ما إذا كان سيتم إعادة إنشاء أو إزالة كل الصفوف من الجدول الوجهة قبل الكتابة. - None: لن يتم اتخاذ أي إجراء على الجدول. - Recreate: سيتم إسقاط الجدول وإعادة إنشائه. مطلوب في حال إنشاء جدول جديد بشكل ديناميكي. - Truncate: سيتم إزالة جميع الصفوف من الجدول الهدف. |
لا |
true أو false |
إعادة إنشاء اقتطاع |
| حجم الدفعة | حدد عدد الصفوف التي تتم كتابتها في كل دُفعة. تعمل أحجام الدُفعات الأكبر على تحسين الضغط والذاكرة، ولكنها تخاطر بنفاد استثناءات الذاكرة عند تخزين البيانات مؤقتاً. | لا | رقم صحيح | batchSize |
| نصوص SQL السابقة واللاحقة | حدد نصوص SQL متعددة الأسطر التي سيتم تنفيذها قبل (المعالجة المسبقة) وبعد (المعالجة اللاحقة) كتابة البيانات في قاعدة بيانات المتلقي. | لا | السلسلة | preSQLs postSQLs |
تلميح
- يوصى بتقسيم البرامج النصية دفعة واحدة مع أوامر مُتعددة إلى دفعات متعددة.
- يمكن فقط تشغيل عبارات لغة تعريف البيانات (DDL) ولغة معالجة البيانات (DML) التي ترجع عدد تحديثات بسيط كجزء مـن دفعة. تعرَّف على المزيد من خلال تنفيذ عمليات الدُفعات
مثال على سكريبت SQL Server sink
عندما تستخدم SQL Server كنوع مغذي، يكون سكريبت تدفق البيانات المرتبط به:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:true,
updateable:true,
upsertable:true,
keys:['keyColumn'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> SQLSink
رسم خرائط أنواع البيانات ل SQL Server
عند نسخ البيانات من وإلى SQL Server، تستخدم التعيينات التالية من أنواع بيانات SQL Server إلى أنواع بيانات Azure Data Factory المؤقتة. مسارات الاتصال التي تنفذ Data Factory، تستخدم نفس التعيينات. لمعرفة كيفية تعيين نشاط النسخ لمخطط المصدر ونوع البيانات إلى المتلقي، راجع تعيينات نوع البيانات والمخطط.
| نوع بيانات SQL Server | نوع البيانات المؤقتة لمصنع البيانات |
|---|---|
| عدد صحيح كبير | Int64 |
| binary | بايت [] |
| بت | Boolean |
| حرف | سلسلة، Char[] |
| date | DateTime |
| التاريخ/الوقت | DateTime |
| التاريخ والوقت2 | DateTime |
| Datetimeoffset | DateTimeOffset |
| عدد عشري | عدد عشري |
| سمة FILESTREAM (varbinary(max)) | بايت [] |
| Float | مزدوج |
| صورة | بايت [] |
| العدد الصحيح | Int32 |
| money | عدد عشري |
| nchar | سلسلة، Char[] |
| ntext | سلسلة، Char[] |
| عددي | عدد عشري |
| nvarchar | سلسلة، Char[] |
| real | فردي |
| rowversion | بايت [] |
| smalldatetime | DateTime |
| Smallint | Int16 |
| smallmoney | عدد عشري |
| sql_variant | الكائن |
| النص | سلسلة، Char[] |
| time | TimeSpan |
| الطابع الزمني | بايت [] |
| Tinyint | Int16 |
| uniqueidentifier | Guid |
| varbinary | بايت [] |
| حروف متنوعة | سلسلة، Char[] |
| xml | السلسلة |
إشعار
بالنسبة لأنواع البيانات التي تتوافق مع النوع العشري المتوسط، يدعم Copy activity حاليا دقة تصل إلى 28. إذا كانت لديك بيانات تتطلب دقة أكبر من 28، ففكر في التحويل إلى سلسلة في استعلام SQL.
عند نسخ البيانات من SQL Server باستخدام Azure Data Factory، يتم تعيين نوع بيانات البت إلى نوع البيانات المؤقت البولياني. إذا كان لديك بيانات تحتاج إلى الاحتفاظ بها كنوع بيانات البت، فاستخدم الاستعلامات مع T-SQL CAST أو CONVERT.
بحث عن خصائص النشاط
لمعرفة تفاصيل حول الخصائص، تحقق من نشاط البحث.
خصائص نشاط GetMetadata
لمعرفة تفاصيل حول الخصائص، يرجى التحقق من نشاط GetMetadata
باستخدام التشفير دائمًا
عند نسخ البيانات من/إلى SQL Server باستخدام Always Encrypted، اتبع الخطوات التالية:
تخزين مفتاح العمود الرئيسي column (CMK) في Azure Key Vault. تعرف على المزيد حول كيفية تكوين Always Encrypted باستخدام Azure Key Vault
تأكد من سهولة الوصول إلى مخزن المفتاح حيث تم تخزين المفتاح الرئيسي للعمود (CMK). راجع هذه المقالة لمعرفة الأذونات المطلوبة.
قم بإنشاء خدمة مرتبطة للاتصال بقاعدة بيانات SQL الخاصة بك وتمكين وظيفة "التشفير دائماً" باستخدام إما الهوية المدارة أو أساس الخدمة.
إشعار
SQL Server Always Encrypted يدعم السيناريوهات التالية:
- تستخدم مخازن بيانات المصدر أو مصدر البيانات الهوية المُدارة أو أساس الخدمة كنوع مصادقة مزود رئيسي.
- تستخدم كل من مخازن بيانات المصدر والمخزن هوية مُدارة كنوع مصادقة مزود رئيسي.
- تستخدم كل من مخازن بيانات المصدر والمخزن نفس مبدأ الخدمة مثل نوع مصادقة مزود المفتاح.
إشعار
حاليا، يدعم SQL Server Always Encrypted فقط لتحويل المصدر في تدفقات بيانات الخرائط.
التقاط بيانات التغيير الأصلي
يمكن ل Azure Data Factory دعم قدرات التقاط بيانات التغيير الأصلية ل SQL Server و Azure SQL DB و Azure SQL MI. يمكن الكشف عن البيانات التي تم تغييرها بما في ذلك إدراج الصف وتحديثه وحذفه في مخازن SQL تلقائيا واستخراجها بواسطة تدفق بيانات تعيين ADF. مع عدم وجود خبرة في التعليمات البرمجية في تعيين تدفق البيانات، يمكن للمستخدمين بسهولة تحقيق سيناريو النسخ المتماثل للبيانات من مخازن SQL عن طريق إلحاق قاعدة بيانات كمخزن وجهة. ما هو أكثر من ذلك، يمكن للمستخدمين أيضا إنشاء أي منطق تحويل البيانات بين لتحقيق سيناريو ETL تزايدي من مخازن SQL.
تأكد من الاحتفاظ باسم المسار والنشاط دون تغيير، بحيث يمكن تسجيل نقطة التحقق بواسطة ADF للحصول على بيانات تم تغييرها من آخر تشغيل تلقائيًا. إذا قمت بتغيير اسم المسار أو اسم النشاط، فسيتم إعادة تعيين نقطة التحقق، ما يؤدي بك إلى البدء من البداية أو الحصول على تغييرات من الآن في التشغيل التالي. إذا كنت تريد تغيير اسم المسار أو اسم النشاط ولكنك لا تزال تحتفظ بنقطة التحقق للحصول على بيانات تم تغييرها من آخر تشغيل تلقائيا، فيرجى استخدام مفتاح نقطة التحقق الخاص بك في نشاط تدفق البيانات لتحقيق ذلك.
عند تصحيح أخطاء المسار، تعمل هذه الميزة بنفس الطريقة. كن على علم بأنه ستتم إعادة تعيين نقطة التحقق عند تحديث المستعرض الخاص بك أثناء تشغيل التصحيح. بعد أن تكون راضيًا عن نتيجة المسار من تشغيل التصحيح، يمكنك المضي قدمًا للنشر وتشغيل المسار. في اللحظة التي تقوم فيها بتشغيل المسار المنشور لأول مرة، تتم إعادة تشغيله تلقائيًا من البداية أو يحصل على تغييرات من الآن فصاعدًا.
في قسم المراقبة، دائمًا لديك فرصة لإعادة تشغيل المسار. عند القيام بذلك، يتم دائمًا التقاط البيانات التي تم تغييرها من نقطة التحقق السابقة لتشغيل المسار المحدد.
المثال 1:
عند ربط تحويل مصدر مشار إليه مباشرة إلى مجموعة البيانات الممكنة ل SQL CDC مع تحويل متلقي مشار إليه إلى قاعدة بيانات في تدفق بيانات التعيين، سيتم تطبيق التغييرات التي حدثت على مصدر SQL تلقائيا على قاعدة البيانات الهدف، بحيث ستحصل بسهولة على سيناريو النسخ المتماثل للبيانات بين قواعد البيانات. يمكنك استخدام أسلوب التحديث في تحويل المتلقي لتحديد ما إذا كنت تريد السماح بالإدراج أو السماح بالتحديث أو السماح بالحذف في قاعدة البيانات الهدف. البرنامج النصي المثال في تعيين تدفق البيانات كما هو موضح أدناه.
source(output(
id as integer,
name as string
),
allowSchemaDrift: true,
validateSchema: false,
enableNativeCdc: true,
netChanges: true,
skipInitialLoad: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source1 sink(allowSchemaDrift: true,
validateSchema: false,
deletable:true,
insertable:true,
updateable:true,
upsertable:true,
keys:['id'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true,
errorHandlingOption: 'stopOnFirstError') ~> sink1
المثال 2:
إذا كنت ترغب في تمكين سيناريو ETL بدلا من النسخ المتماثل للبيانات بين قاعدة البيانات عبر SQL CDC، يمكنك استخدام التعبيرات في تعيين تدفق البيانات بما في ذلك isInsert(1) و isUpdate(1) و isDelete(1) للتمييز بين الصفوف مع أنواع عمليات مختلفة. فيما يلي أحد أمثلة البرامج النصية لتعيين تدفق البيانات على اشتقاق عمود واحد بالقيمة: 1 للإشارة إلى الصفوف المدرجة، و2 للإشارة إلى الصفوف المحدثة و3 للإشارة إلى الصفوف المحذوفة لتحويلات انتقال البيانات من الخادم لمعالجة بيانات دلتا.
source(output(
id as integer,
name as string
),
allowSchemaDrift: true,
validateSchema: false,
enableNativeCdc: true,
netChanges: true,
skipInitialLoad: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source1 derive(operationType = iif(isInsert(1), 1, iif(isUpdate(1), 2, 3))) ~> derivedColumn1
derivedColumn1 sink(allowSchemaDrift: true,
validateSchema: false,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink1
القيد المعروف:
- سيتم تحميل التغييرات الصافية فقط من SQL CDC بواسطة ADF عبر cdc.fn_cdc_get_net_changes_.
استكشاف المشكلات في الاتصالات وإصلاحها
قم بتكوين نسخة SQL Server الخاصة بك لقبول الاتصالات البعيدة. ابدأ SQL Server Management Studio، انقر بزر الفأرة الأيمن server، واختر Properties. حدد Connectionsمن القائمة، وحدد مربع الاختيار Allow remote connections to this server.
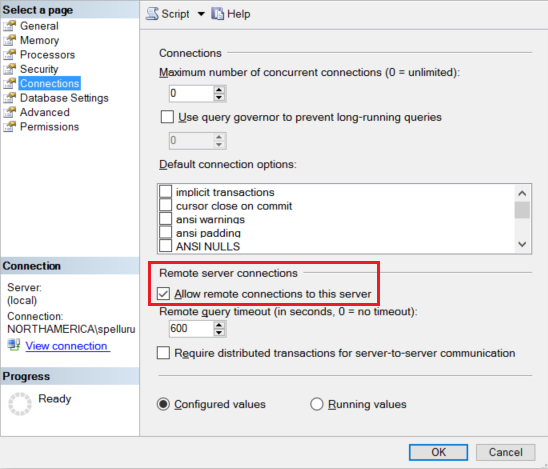
راجع تكوين خيار تكوين الخادم الوصول البعيد للحصول على خطوات مفصلة.
ابدأ إدارة تكوين SQL Server. قم بتوسيع SQL Server Network Configuration للنسخة التي تريدها، واختر Protocols for MSSQLSERVER. تظهر البروتوكولات في الجزء الأيمن. تمكين TCP/IP بالنقر بزر الماوس الأيمن فوق TCP/IP ثم النقر فوق Enable.
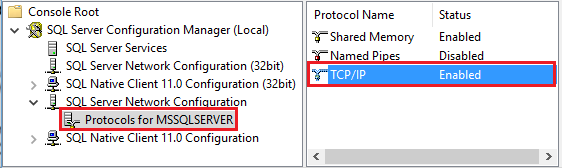
لمزيد من المعلومات والطرق البديلة لتمكين بروتوكول TCP/IP، راجع تمكين أو تعطيل بروتوكول شبكة الخادم .
في نفس الإطار، انقر نقرًا مزدوجًا فوق TCP/IP لإطلاق نافذة TCP/IP Properties.
التبديل إلى علامة التبويب IP Addresses مرر لأسفل لرؤية قسم IPAll. اكتب منفذ TCP . الإعداد الافتراضي هو 1433.
أنشئ rule لجدار الحماية Windows على الجهاز للسماح بمرور حركة المرور الواردة عبر هذا المنفذ.
تحقق من الاتصال: للاتصال ب SQL Server باستخدام اسم مؤهل بالكامل، استخدم SQL Server Management Studio من جهاز مختلف. مثال على ذلك
"<machine>.<domain>.corp.<company>.com,1433".
ترقية نسخة SQL Server
لترقية النسخة SQL Server، في صفحة تحرير الخدمة المرتبطة، اختر Recommended تحت Version وقم بتكوين الخدمة المرتبطة بالرجوع إلى Linked Service خصائص للإصدار الموصى به.
الاختلافات بين الإصدار الموصى به والإصدار القديم
يوضح الجدول أدناه الفروقات بين SQL Server باستخدام النسخة الموصى بها والنسخة القديمة.
| إصدار الموصى به | الإصدار القديم |
|---|---|
دعم TLS 1.3 عبر encrypt ك strict. |
TLS 1.3 غير مدعوم. |
المحتوى ذو الصلة
للحصول على قائمة بمخازن البيانات المدعومة كمصادر ومتلقين من خلال نشاط النسخ، انظر مخازن البيانات المدعومة .