إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
تلميح
Microsoft Fabric Data Warehouse هو مستودع علائقي على نطاق مؤسسي قائم على أساس بحيرة البيانات، مع بنية جاهزة للمستقبل، وذكاء اصطناعي مدمج، وميزات جديدة. إذا كنت جديدا في مستودع البيانات، ابدأ ب Fabric Data Warehouse. يمكن لأحمال عمل تجمع SQL المخصصة الحالية الترقية إلى Fabric للوصول إلى قدرات جديدة في علوم البيانات، والتحليلات اللحظية، والتقارير.
تحتوي هذه المقالة على معلومات حول كيفية استكشاف المشكلات الأكثر شيوعاً بتجمع SQL بلا خادم وإصلاحها في Azure Synapse Analytics.
لمعرفة المزيد حول Azure Synapse Analytics، تحقق من الموضوعات في نظرة عامة.
Synapse Studio
Synapse Studio هو أداة سهلة الاستخدام يمكنك استخدامها للوصول إلى بياناتك باستخدام مستعرض دون الحاجة إلى تثبيت أدوات الوصول إلى قاعدة البيانات. لم يتم تصميم Synapse Studio لقراءة مجموعة كبيرة من البيانات أو الإدارة الكاملة لعناصر SQL.
يتخذ تجمع SQL بلا خادم اللون الرمادي في Synapse Studio
إذا لم يتمكن Synapse Studio من إنشاء اتصال بتجمع SQL بلا خادم، ستلاحظ أن تجمع SQL بلا خادم باللون الرمادي أو يعرض حالة غير متصل.
تحدث هذه المشكلة عادة لأحد سببين:
- تمنع شبكتك الاتصال بالواجهة الخلفية لـ Azure Synapse Analytics. الحالة الأكثر تكرارا هي أن منفذ TCP 1443 محظور. لتشغيل تجمع SQL بلا خادم، عليك إلغاء حظر هذا المنفذ. قد تمنع مشاكل أخرى تجمع SQL بلا خادم من العمل أيضاً. راجع دليل الكشف عن الأخطاء وإصلاحها لمزيد من المعلومات.
- لا يتوفر لديك الإذن لتسجيل الدخول إلى تجمع SQL بلا خادم. للحصول على إمكانية الوصول، يجب أن يضيفك أحد مسؤولي مساحة عمل Azure Synapse إلى دور مسؤول مساحة العمل أو دور مسؤول SQL. لمزيد من المعلومات، راجع التحكم في الوصول إلى Azure Synapse.
تم إغلاق اتصال WebSocket بشكل غير متوقع
قد يفشل الاستعلام الخاص بك مع رسالة Websocket connection was closed unexpectedly. الخطأ تعني هذه الرسالة أنه تمت مقاطعة اتصال المستعرض ب Synapse Studio، على سبيل المثال، بسبب مشكلة في الشبكة.
- لحل هذه المشكلة، أعد تشغيل الاستعلام.
- جرب إضافة MSSQL ل تعليمة Visual Studio برمجية أو SQL Server Management Studio لنفس الاستعلامات بدلا من Synapse Studio لمزيد من التحقيق.
- إذا ظهرت هذه الرسالة غالبًا في بيئتك، فاحصل على المساعدة من مسؤول الشبكة. يمكنك أيضاً التحقق من إعدادات جدار الحماية، والتحقق من دليل استكشاف الأخطاء وإصلاحها.
- إذا استمرت المشكلة، فقم بإنشاء تذكرة دعم من خلال مدخل Azure.
لا تظهر قواعد البيانات بلا خادم في Synapse Studio
إذا كنت لا ترى قواعد البيانات التي تم إنشاؤها في تجمع SQL بلا خادم، فتحقق لمعرفة ما إذا كان تجمع SQL بلا خادم قد بدأ. إذا تم إلغاء تنشيط تجمع SQL بلا خادم، فلن تظهر قواعد البيانات. قم بتنفيذ أي استعلام، على سبيل المثال، SELECT 1على تجمع SQL بلا خادم لتنشيطه وجعل قواعد البيانات تظهر.
يظهر تجمع SQL Synapse بلا خادم على أنه غير متوفر
غالباً ما يكون تكوين الشبكة غير الصحيح هو سبب هذا السلوك. تأكد من تكوين المنافذ بشكل صحيح. إذا كنت تستخدم جدار حماية أو نقاط نهاية خاصة، فتحقق من هذه الإعدادات أيضاً.
وأخيرا، تأكد من منح الأدوار المناسبة ولم يتم إبطالها.
تعذر إنشاء قاعدة بيانات جديدة حيث سيستخدم الطلب المفتاح القديم/منتهية الصلاحية
يحدث هذا الخطأ بسبب تغيير المفتاح المدار لعميل مساحة العمل المستخدم للتشفير. يمكنك اختيار إعادة تشفير جميع البيانات في مساحة العمل باستخدام أحدث إصدار من المفتاح النشط. لإعادة التشفير، قم بتغيير المفتاح في مدخل Microsoft Azure إلى مفتاح مؤقت ثم قم بالتبديل مرة أخرى إلى المفتاح الذي ترغب في استخدامه للتشفير. تعرف هنا على كيفية إدارة مفاتيح مساحة العمل.
تجمع SQL بلا خادم Synapse غير متوفر بعد نقل اشتراك إلى مستأجر Microsoft Entra مختلف
إذا قمت بنقل اشتراك إلى مستأجر Microsoft Entra آخر، فقد تواجه بعض المشكلات مع تجمع SQL بلا خادم. أنشئ تذكرة دعم وسيتصل بك دعم Azure لحل المشكلة.
الوصول إلى التخزين
إذا تلقيت أخطاء أثناء محاولة الوصول إلى الملفات في تخزين Azure، فتأكد من أن لديك الإذن للوصول إلى البيانات. يجب أن تكون قادراً على الوصول إلى الملفات المتوفرة للجمهور. إذا حاولت الوصول إلى البيانات بدون بيانات اعتماد، فتأكد من أن هوية Microsoft Entra الخاصة بك يمكنها الوصول مباشرة إلى الملفات.
إذا كان لديك مفتاح توقيع وصول مشترك يجب عليك استخدامه للوصول إلى الملفات، فتأكد من إنشاء بيانات اعتماد على مستوى الخادم أو على نطاق قاعدة بيانات تحتوي على بيانات الاعتماد هذه. بيانات الاعتماد مطلوبة إذا كنت بحاجة إلى الوصول إلى البيانات باستخدام الهوية المدارة لمساحة العمل واسم الخدمة الأساسي (SPN) المخصص.
تتعذر قراءة الملفات أو سردها أو الوصول إليها في Azure Data Lake Storage
إذا كنت تستخدم تسجيل دخول Microsoft Entra دون بيانات اعتماد صريحة، فتأكد من أن هوية Microsoft Entra الخاصة بك يمكنها الوصول إلى الملفات في التخزين. للوصول إلى الملفات، يجب أن يكون لدى هوية Microsoft Entra إذن قارئ بيانات Blob، أو أذونات لقوائم التحكم في الوصول إلى القائمة والقراءة (ACL) في ADLS. لمزيد من المعلومات، راجع فشل الاستعلام لأنه لا يمكن فتح الملف.
إذا قمت بالوصول إلى التخزين باستخدام بيانات الاعتماد، فتأكد من أن هويتكالمدارة أو SPN لها دور قارئ البيانات أو المساهم أو أذونات ACL محددة. إذا استخدمت رمز توقيع وصول مشترك، فتأكد من أنه لديه إذن rl، ومن أن صلاحيته لم تنته بعد.
إذا كنت تستخدم تسجيل دخول SQL والدالة OPENROWSETبدون مصدر بيانات، فتأكد من أن لديك بيانات اعتماد على مستوى الخادم تطابق URI التخزين ولديك إذن للوصول إلى التخزين.
فشل الاستعلام نظراً لتعذر فتح الملف
إذا فشل الاستعلام مع الخطأ File cannot be opened because it does not exist or it is used by another process وكنت متأكدا من وجود كلا الملفين ولم يتم استخدامهما بواسطة عملية أخرى، فلن يتمكن تجمع SQL بلا خادم من الوصول إلى الملف. تحدث هذه المشكلة عادة لأن هوية Microsoft Entra لا تتمتع بحقوق الوصول إلى الملف أو لأن جدار الحماية يمنع الوصول إلى الملف.
بشكل افتراضي، يحاول تجمع SQL بلا خادم الوصول إلى الملف باستخدام هوية Microsoft Entra. لحل هذه المشكلة، يجب أن تمتلك الحقوق المناسبة للوصول إلى الملف. تتمثل أسهل طريقة في منح نفسك دور مساهم لبيانات Storage Blob في حساب التخزين الذي تحاول الاستعلام عنه.
لمزيد من المعلومات، راجع:
- التحكم في الوصول إلى معرف Microsoft Entra للتخزين
- التحكم في الوصول إلى حساب التخزين لتجمع SQL بلا خادم في Azure Synapse Analytics
بديل دور Storage Blob Data Contributor
بدلاً من منح نفسك دور مساهم بيانات Storage Blob، يمكنك أيضًا منح المزيد من الأذونات الدقيقة لمجموعة فرعية من الملفات.
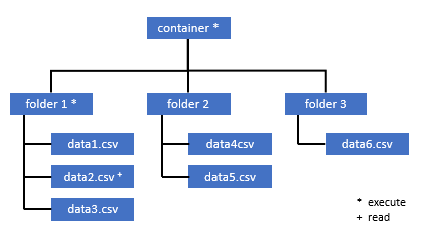
يجب أيضًا أن يحصل جميع المستخدمين الذين يحتاجون إلى الوصول إلى بعض البيانات في هذه الحاوية على إذن التنفيذ على كافة المجلدات الرئيسية حتى الجذر (الحاوية).
تعرف على المزيد عن كيفية تعيين قوائم التحكم في الوصول (ACL) في Azure Data Lake Storage Gen2.
إشعار
يجب تعيين إذن التنفيذ على مستوى الحاوية داخل Azure Data Lake Storage Gen2. يمكن تعيين الأذونات الموجودة على المجلد داخل Azure Synapse.
إذا كنت ترغب في الاستعلام عن data2.csv في هذا المثال، تكون الأذونات التالية مطلوبة:
- إذن التنفيذ على الحاوية
- إذن التنفيذ على folder1
- إذن القراءة على data2.csv
سجل الدخول إلى Azure Synapse من خلال مستخدم مسؤول لديه أذونات كاملة على البيانات التي تريد الوصول إليها.
في جزء البيانات، انقر بزر الماوس الأيمن فوق الملف وحدد إدارة الوصول.
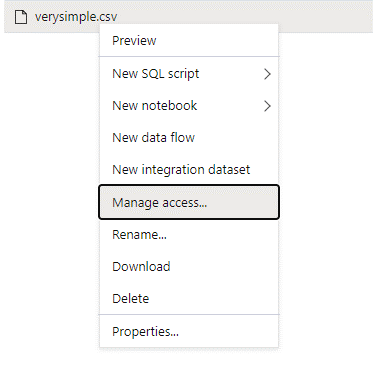
حدد إذن القراءة على الأقل. أدخل اسم المستخدم الأساسي للمستخدم أو معرف العنصر، على سبيل المثال،
user@contoso.com. حدد إضافة.امنح إذن القراءة "read" لهذا المستخدم.

إشعار
بالنسبة للمستخدمين الضيوف، يجب تنفيذ هذه الخطوة مباشرةً باستخدام Azure Data Lake لأنه لا يمكن إجراؤها مباشرةً من خلال Azure Synapse.
لا يمكن سرد محتوى الدليل على المسار
يشير هذا الخطأ إلى أن المستخدم الذي يقوم بالاستعلام عن Azure Data Lake لا يمكنه سرد الملفات في موقع التخزين. هناك عدة سيناريوهات قد يحدث فيها هذا الخطأ:
- لا يملك مستخدم Microsoft Entra الذي يستخدم مصادقة مرور Microsoft Entra إذنا لسرد الملفات في Data Lake Storage.
- معرف Microsoft Entra أو مستخدم SQL الذي يقرأ البيانات باستخدام مفتاح توقيع وصول مشترك أو هوية مدارة لمساحة العمل وهذا المفتاح أو الهوية ليس لديه إذن لإدراج الملفات في التخزين.
- المستخدم الذي يصل إلى بيانات Dataverse الذي لا يمتلك إذناً للاستعلام عن البيانات في Dataverse. قد يحدث هذا السيناريو إذا كنت تستخدم مستخدمي SQL.
- قد لا يكون لدى المستخدم الذي يصل إلى Delta Lake الإذن لقراءة سجل عمليات Delta Lake.
أسهل طريقة لحل هذه المشكلة هي منح نفسك دور Storage Blob Data Contributor في حساب التخزين الذي تحاول الاستعلام فيه.
لمزيد من المعلومات، راجع:
- التحكم في الوصول إلى معرف Microsoft Entra للتخزين
- التحكم في الوصول إلى حساب التخزين لتجمع SQL بلا خادم في Azure Synapse Analytics
لا يمكن إدراج محتوى جدول Dataverse
إذا كنت تستخدم Azure Synapse Link for Dataverse لقراءة جداول DataVerse المرتبطة، فستحتاج إلى استخدام حساب Microsoft Entra للوصول إلى البيانات المرتبطة باستخدام تجمع SQL بلا خادم. لمزيد من المعلومات، راجع ارتباط Azure Synapse لـ Dataverse مع Azure Data Lake.
إذا حاولت استخدام تسجيل دخول SQL لقراءة جدول خارجي يشير إلى جدول DataVerse، فستحصل على الخطأ التالي: External table '???' is not accessible because content of directory cannot be listed.
تستخدم جداول Dataverse الخارجية دائما مصادقة مرور Microsoft Entra. لا يمكنك تكوينها لاستخدام مفتاح توقيع وصول مشترك أو هوية مدارة لمساحة العمل.
لا يمكن إدراج محتوى سجل عمليات Delta Lake
يتم إرجاع الخطأ التالي عندما لا يمكن لتجمع SQL بلا خادم قراءة مجلد سجل عمليات Delta Lake:
Content of directory on path 'https://.....core.windows.net/.../_delta_log/*.json' cannot be listed.
تأكد من أن المجلد _delta_log موجود. ربما تقوم بالاستعلام عن ملفات Parquet العادية التي لم يتم تحويلها إلى تنسيق Delta Lake.
_delta_log إذا كان المجلد موجودا، فتأكد من أن لديك إذن القراءة والقائمة على مجلدات Delta Lake الأساسية. حاول قراءة ملفات json مباشرة باستخدام FORMAT='csv'. ضع URI الخاص بك في المعلمة BULK:
select top 10 *
from openrowset(BULK 'https://.....core.windows.net/.../_delta_log/*.json',FORMAT='csv', FIELDQUOTE = '0x0b', FIELDTERMINATOR ='0x0b',ROWTERMINATOR = '0x0b')
with (line varchar(max)) as logs
إذا فشل هذا الاستعلام، فلا يملك القائم بالاستدعاء الإذن لقراءة ملفات التخزين الأساسية.
تنفيذ الاستعلام
قد تحصل على أخطاء أثناء تنفيذ الاستعلام في الحالات التالية:
- لا يمكن للقائم بالاستدعاء الوصول إلى بعض العناصر.
- لا يمكن للاستعلام الوصول إلى البيانات الخارجية.
- يحتوي الاستعلام على بعض الوظائف غير المدعومة في تجمعات SQL بلا خادم.
فشل الاستعلام لأنه لا يمكن تنفيذه بسبب قيود الموارد الحالية
قد يفشل الاستعلام الخاص بك مع رسالة This query cannot be executed due to current resource constraints. الخطأ تعني هذه الرسالة أنه لا يمكن تنفيذ تجمع SQL بلا خادم في هذه اللحظة. فيما يلي بعض خيارات استكشاف الأخطاء وإصلاحها:
- تأكد من استخدام أنواع بيانات ذات أحجام معقولة.
- إذا كان استعلامك يستهدف ملفات Parquet ففكر في تحديد أنواع صريحة لأعمدة السلسلة لأنها ستكون VARCHAR(8000) بشكل افتراضي. تحقق من أنواع البيانات المستنتَجة.
- إذا كان استعلامك يستهدف ملفات CSV، ففكر في إنشاء الإحصائيات.
- لتحسين استعلامك، راجع أفضل ممارسات الأداء لتجمع SQL بلا خادم لتحسين الاستعلام.
انتهت مهلة الاستعلام
يتم إرجاع الخطأ Query timeout expired إذا نفذ الاستعلام أكثر من 30 دقيقة على تجمع SQL بلا خادم. لا يمكن تغيير هذا الحد لتجمع SQL بلا خادم.
- حاول تحسين استعلامك من خلال تطبيق أفضل الممارسات.
- حاول تجسيد أجزاء من الاستعلامات باستخدام إنشاء جدول خارجي كمحدد (CETAS).
- تحقق مما إذا كان هناك حمل عمل متزامن يعمل على تجمع SQL بلا خادم لأن الاستعلامات الأخرى قد تأخذ الموارد. في هذه الحالة، قد تقوم بتقسيم حمل العمل على مساحات عمل متعددة.
اسم عنصر غير صالح
يشير الخطأ Invalid object name 'table name' إلى أنك تستخدم كائنا، مثل جدول أو طريقة عرض، غير موجود في قاعدة بيانات تجمع SQL بلا خادم. جرب هذه الخيارات:
قم بسرد الجداول أو طرق العرض والتحقق مما إذا كان العنصر موجودًا. استخدم SQL Server Management Studio أو تعليمة Visual Studio برمجية، لأن Synapse Studio قد تظهر بعض الجداول غير المتوفرة في مجموعة SQL بدون خادم.
إذا رأيت العنصر، فتحقق من أنك تستخدم بعض ترتيب قاعدة البيانات الثنائية/الحساسة لحالة الأحرف. ربما لا يتطابق اسم العنصر مع الاسم الذي استخدمته في الاستعلام. مع ترتيب قاعدة البيانات الثنائية،
Employeeوemployeeهما عنصران مختلفان.إذا كنت لا ترى العنصر، فربما تحاول الاستعلام عن جدول من مستودع أو قاعدة بيانات Spark. قد لا يكون الجدول متوفراً في تجمع SQL بلا خادم بسبب:
- يحتوي الجدول على بعض أنواع الأعمدة التي لا يمكن تمثيلها في تجمع SQL بلا خادم.
- يحتوي الجدول على تنسيق غير مدعوم في تجمع SQL بلا خادم. ومن الأمثلة على ذلك Avro أو ORC.
سيتم اقتطاع سلسلة أو بيانات ثنائية
يحدث هذا الخطأ إذا كان طول السلسلة أو نوع العمود الثنائي (على سبيل المثال VARCHAR، VARBINARYأو NVARCHAR) أقصر من الحجم الفعلي للبيانات التي تقرأها. يمكنك إصلاح هذا الخطأ عن طريق زيادة طول نوع العمود:
- إذا تم تعريف عمود السلسلة على أنه
VARCHAR(32)النوع وكان النص 60 حرفا، فاستخدمVARCHAR(60)النوع (أو أطول) في مخطط العمود. - إذا كنت تستخدم استنتاج المخطط (بدون
WITHالمخطط)، يتم تعريف جميع أعمدة السلسلة تلقائيا كنوعVARCHAR(8000). إذا كنت تتلقى هذا الخطأ، فحدد المخطط بشكل صريح فيWITHعبارة بنوع العمود الأكبرVARCHAR(MAX)لحل هذا الخطأ. - إذا كان الجدول الخاص بك في قاعدة بيانات Lake، فحاول زيادة حجم عمود السلسلة في تجمع Spark.
-
SET ANSI_WARNINGS OFFحاول تمكين تجمع SQL بلا خادم من اقتطاع قيم VARCHAR تلقائيا، إذا لم يؤثر ذلك على وظائفك.
علامة اقتباس غير مغلقة بعد سلسلة الأحرف
في حالات نادرة، حيث يمكنك استخدام عامل تشغيل LIKE على عمود سلسلة أو مقارنة مع القيم الحرفية للسلسلة، قد تحصل على الخطأ التالي:
Unclosed quotation mark after the character string
قد يحدث هذا الخطأ إذا كنت تستخدم ترتيب Latin1_General_100_BIN2_UTF8 على العمود. حاول تعيين ترتيب Latin1_General_100_CI_AS_SC_UTF8 على العمود بدلاً من الترتيب Latin1_General_100_BIN2_UTF8 لحل المشكلة. إذا كان الخطأ لا يزال يتم إرجاعه، فرفع طلب دعم من خلال مدخل Azure.
تعذر تخصيص مساحة tempdb أثناء نقل البيانات من توزيع إلى آخر
يتم إرجاع الخطأ Could not allocate tempdb space while transferring data from one distribution to another عندما لا يتمكن مشغل تنفيذ الاستعلام من معالجة البيانات ونقلها بين العقد التي تنفذ الاستعلام. إنها حالة خاصة من فشل الاستعلام العام لأنه لا يمكن تنفيذه بسبب خطأ قيود الموارد الحالية. يتم إرجاع هذا الخطأ عندما تكون الموارد المخصصة لقاعدة بيانات tempdb غير كافية لتشغيل الاستعلام.
قم بتطبيق أفضل الممارسات قبل تقديم تذكرة دعم.
فشل الاستعلام مع وجود خطأ في معالجة ملف خارجي (تم الوصول إلى الحد الأقصى لعدد الأخطاء)
إذا فشل الاستعلام مع رسالة error handling external file: Max errors count reachedالخطأ ، فهذا يعني أن هناك عدم تطابق لنوع عمود محدد والبيانات التي يجب تحميلها.
للحصول على مزيد من المعلومات حول الخطأ والصفوف والأعمدة التي يجب إلقاء نظرة عليها، غيِّر إصدار الموزع من 2.0 إلى 1.0.
مثال
إذا كنت تريد الاستعلام عن الملف names.csv باستخدام هذا الاستعلام 1، فإن تجمع SQL بلا خادم Azure Synapse يرجع مع الخطأ التالي: Error handling external file: 'Max error count reached'. File/External table name: [filepath]. على سبيل المثال:
يحتوي ملف names.csv على:
Id,first name,
1, Adam
2,Bob
3,Charles
4,David
5,Eva
الاستعلام 1:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
)
AS [result]
السبب
بمجرد تغيير إصدار الموزع من الإصدار 2.0 إلى الإصدار 1.0، تساعد رسائل الخطأ في التعرف على المشكلة. رسالة الخطأ الجديدة الآن Bulk load data conversion error (truncation) for row 1, column 2 (Text) in data file [filepath].
يخبرنا الاقتطاع أن نوع العمود صغير للغاية بحيث لا يتناسب مع البيانات. يحتوي أطول اسم أول في هذا names.csv الملف على سبعة أحرف. يجب أن يكون نوع البيانات الموافق المطلوب استخدامه VARCHAR(7) على الأقل. يحدث الخطأ بسبب هذا السطر من التعليمات البرمجية:
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
يؤدي تغيير الاستعلام وفقاً لذلك إلى حل الخطأ. بعد تصحيح الأخطاء، غيِّر إصدار الموزع إلى 2.0 مرة أخرى لتحقيق أقصى أداء.
لمزيد من المعلومات حول وقت استخدام إصدار الموزع، راجع استخدام OPENROWSET باستخدام تجمع SQL بلا خادم في Synapse Analytics.
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (7) COLLATE Latin1_General_BIN2
)
AS [result]
لا يمكن إجراء التحميل المجمع حيث تعذر فتح الملف
يتم إرجاع الخطأ Cannot bulk load because the file could not be opened إذا تم تعديل ملف أثناء تنفيذ الاستعلام. عادة، قد تحصل على خطأ مثل Cannot bulk load because the file {file path} could not be opened. Operating system error code 12. (The access code is invalid.)
لا يمكن لتجمعات مستعرض لغة الاستعلامات المركبة بلا خادم قراءة الملفات قيد التعديل أثناء إجراء الاستعلام. لا يمكن أن يقوم الاستعلام بقفل الملفات. إذا كنت تعرف أن عملية التعديل ملحقة، يمكنك محاولة تعيين الخيار التالي: {"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}.
لمزيد من المعلومات، راجع كيفية الاستعلام عن الملفات الملحقة فقط أو إنشاء جداول على ملفات ملحقة فقط.
فشل الاستعلام بخطأ في التحويل
قد يفشل الاستعلام مع ظهور رسالة Bulk load data conversion error (type mismatches or invalid character for the specified code page) for row n, column m [columnname] in the data file [filepath]. الخطأ تعني هذه الرسالة أن أنواع البيانات الخاصة بك لم تتطابق مع البيانات الفعلية للصف n والعمود m.
على سبيل المثال، إذا كنت تتوقع أعدادًا صحيحة فقط في بياناتك، ولكن في الصف n هناك سلسلة، فإن رسالة الخطأ هذه هي الرسالة التي ستحصل عليها.
لحل هذه المشكلة، افحص الملف وأنواع البيانات التي اخترتها. تحقق أيضاً من صحة إعدادات محدِّد الصفوف وفاصل الحقول. يوضح المثال التالي كيفية إجراء الفحص باستخدام VARCHAR كنوع عمود.
لمزيد من المعلومات حول فواصل الحقول ومحددات الصفوف وأحرف اقتباس الإلغاء، راجع الاستعلام عن ملفات CSV.
مثال
إذا كنت تريد الاستعلام عن الملف names.csv:
Id, first name,
1,Adam
2,Bob
3,Charles
4,David
five,Eva
باستخدام الاستعلام التالي:
الاستعلام 1:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
يقوم تجمع SQL بلا خادم في Azure Synapse بإرجاع الخطأ Bulk load data conversion error (type mismatch or invalid character for the specified code page) for row 6, column 1 (ID) in data file [filepath].
من الضروري استعراض البيانات واتخاذ قرار مستنير لمعالجة هذه المشكلة. لإلقاء نظرة على البيانات التي تسبب هذه المشكلة، يجب تغيير نوع البيانات أولاً. بدلاً من الاستعلام عن العمود "المعرف" بنوع البيانات "SMALLINT"، يُستخدم VARCHAR(100) الآن لتحليل هذه المشكلة.
باستخدام هذا الاستعلام 2 المغيَّر تغييراً طفيفاً، يمكن أن تتم معالجة البيانات الآن وتعرض قائمة الأسماء.
الاستعلام 2:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
قد تلاحظ أن البيانات تحتوي على قيم غير متوقعة للمعرف في الصف الخامس. في مثل هذه الظروف، من المهم التوافق مع مالك العمل للبيانات للاتفاق على كيفية تجنب البيانات التالفة مثل هذا المثال. إذا لم تكن الوقاية ممكنة على مستوى التطبيق، فقد يكون VARCHAR ذو الحجم المعقول هو الخيار الوحيد هنا.
تلميح
حاول جعل VARCHAR() أقصر قدر المستطاع. تجنب VARCHAR(MAX) إذا كان ذلك ممكناً لأن هذا يمكن أن يُضعف الأداء.
لا تبدو نتيجة الاستعلام كما هو متوقع
قد لا يفشل استعلامك، ولكن قد ترى أن مجموعة النتائج ليست كما هو متوقع. قد تكون الأعمدة الناتجة فارغة أو قد يتم إرجاع بيانات غير متوقعة. في هذا السيناريو، من المحتمل أن يكون محدد صف أو فاصل حقل قد تم اختياره بشكل غير صحيح.
لحل هذه المشكلة، عليك إلقاء نظرة أخرى على البيانات وتغيير تلك الإعدادات. يتسم تصحيح أخطاء هذا الاستعلام بالسهولة، كما هو موضح في المثال التالي.
مثال
إذا كنت تريد الاستعلام عن الملف names.csv بالاستعلام في الاستعلام 1، فإن تجمع SQL بلا خادم لـ Azure Synapse يرجع بنتيجة تبدو غريبة:
في names.csv:
Id,first name,
1, Adam
2, Bob
3, Charles
4, David
5, Eva
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
| ID | Firstname |
| ------------- |------------- |
| 1,Adam | NULL |
| 2,Bob | NULL |
| 3,Charles | NULL |
| 4,David | NULL |
| 5,Eva | NULL |
يبدو أنه لا توجد قيمة في العمود Firstname. بدلاً من ذلك، انتهى الأمر بجميع القيم في العمود ID. تُفصل تلك القيم بفاصلة. حدثت المشكلة بسبب هذا السطر من التعليمات البرمجية نظراً لأنه من الضروري اختيار الفاصلة بدلاً من رمز الفاصلة المنقوطة كفاصل للحقول:
FIELDTERMINATOR =';',
يؤدي تغيير هذا الحرف الفردي إلى حل المشكلة:
FIELDTERMINATOR =',',
تبدو مجموعة النتائج التي تم إنشاؤها بواسطة الاستعلام 2 الآن كما هو متوقع:
الاستعلام 2:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
ارجاع:
| ID | Firstname |
| ------------- |------------- |
| 1 | Adam |
| 2 | Bob |
| 3 | Charles |
| 4 | David |
| 5 | Eva |
عمود النوع غير متوافق مع نوع البيانات الخارجية
إذا فشل الاستعلام مع رسالة Column [column-name] of type [type-name] is not compatible with external data type […], الخطأ، فمن المحتمل أن يكون نوع بيانات PARQUET قد تم تعيينه إلى نوع بيانات SQL غير صحيح.
على سبيل المثال، إذا كان ملف Parquet يحتوي على عمود سعر بأرقام عائمة (مثل 12.89) وحاولت تعيينه إلى INT، فهذه هي رسالة الخطأ التي ستتلقاها.
لحل هذه المشكلة، افحص الملف وأنواع البيانات التي اخترتها. يساعد جدول التعيين هذا في اختيار نوع بيانات SQL الصحيح. كأفضل ممارسة، حدد التعيين فقط للأعمدة التي قد يتم حلها في نوع بيانات VARCHAR. يؤدي تجنب VARCHAR عندما يكون ذلك ممكناً، إلى أداء أفضل في الاستعلامات.
مثال
إذا كنت ترغب في الاستعلام عن الملف taxi-data.parquet باستخدام الاستعلام 1 هذا، فإن تجمع SQL بلا خادم Azure Synapse يرجع الخطأ التالي:
يحتوي الملف taxi-data.parquet على:
|PassengerCount |SumTripDistance|AvgTripDistance |
|---------------|---------------|----------------|
| 1 | 2635668.66000064 | 6.72731710678951 |
| 2 | 172174.330000005 | 2.97915543404919 |
| 3 | 296384.390000011 | 2.8991352022851 |
| 4 | 12544348.58999806| 6.30581582240281 |
| 5 | 13091570.2799993 | 111.065989028627 |
الاستعلام 1:
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance INT,
AVGTripDistance FLOAT
)
AS [result]
Column 'SumTripDistance' of type 'INT' is not compatible with external data type 'Parquet physical type: DOUBLE', please try with 'FLOAT'. File/External table name: '<filepath>taxi-data.parquet'.
تخبرك رسالة الخطأ هذه أن أنواع البيانات غير متوافقة، وتأتي مع اقتراح استخدام FLOAT بدلاً من INT. يحدث الخطأ بسبب هذا السطر من التعليمات البرمجية:
SumTripDistance INT,
باستخدام هذا الاستعلام 2 المغيَّر تغييراً طفيفاً، يمكن أن تتم معالجة البيانات الآن وتعرض الأعمدة الثلاثة كلها:
الاستعلام 2:
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance FLOAT,
AVGTripDistance FLOAT
)
AS [result]
يشير الاستعلام إلى عنصر غير مدعوم في وضع المعالجة الموزعة
يشير الخطأ The query references an object that is not supported in distributed processing mode إلى أنك استخدمت كائنا أو دالة لا يمكن استخدامها أثناء الاستعلام عن البيانات في تخزين Azure أو تخزين Azure Cosmos DB التحليلي.
لا يمكن استخدام بعض العناصر، مثل طرق عرض النظام، والدوال أثناء الاستعلام عن البيانات المخزنة في Azure Data Lake أو التخزين التحليلي لـ Azure Cosmos DB. تجنب استخدام الاستعلامات التي تنضم إلى البيانات الخارجية باستخدام طرق عرض النظام، أو تحميل البيانات الخارجية في جدول مؤقت، أو استخدام بعض وظائف الأمان أو بيانات التعريف لتصفية البيانات الخارجية.
فشل استدعاء WaitIOCompletion
تشير رسالة WaitIOCompletion call failed الخطأ إلى فشل الاستعلام أثناء انتظار إكمال عملية الإدخال/الإخراج التي تقرأ البيانات من التخزين البعيد، Azure Data Lake.
تحتوي رسالة الخطأ على النمط التالي: Error handling external file: 'WaitIOCompletion call failed. HRESULT = ???'. File/External table name...
تأكد من وضع التخزين الخاص بك في نفس المنطقة مثل تجمع SQL بلا خادم. تحقق من مقاييس التخزين وتحقق من عدم وجود أحمال عمل أخرى على طبقة التخزين، مثل تحميل ملفات جديدة، يمكن أن تعترض طلبات الإدخال والإخراج.
يحتوي الحقل HRESULT على رمز النتيجة. رموز الخطأ التالية هي الأكثر شيوعاً مع حلولها المحتملة.
يعني رمز الخطأ هذا أن الملف المصدر غير موجود في موقع التخزين.
هناك أسباب وراء إمكانية حدوث رمز الخطأ هذا:
- تم حذف الملف بواسطة تطبيق آخر.
- في هذا السيناريو الشائع، يبدأ تنفيذ الاستعلام، ويعدد الملفات، ويتم العثور على الملفات. لاحقاً، أثناء تنفيذ الاستعلام، يتم حذف ملف. على سبيل المثال، يمكن حذفه بواسطة Databricks أو Spark أو Azure Data Factory. فشل الاستعلام بسبب عدم العثور على الملف.
- يمكن أن تحدث هذه المشكلة أيضاً بتنسيق Delta. قد ينجح الاستعلام في إعادة المحاولة لأن هناك إصداراً جديداً من الجدول، ولا يتم الاستعلام عن الملف المحذوف مرة أخرى.
- تم تخزين خطة تنفيذ غير صالحة مؤقتاً.
- كتخفيف مؤقت، قم بتشغيل الأمر
DBCC FREEPROCCACHE. إذا استمرت المشكلة، قم بإنشاء تذكرة دعم.
- كتخفيف مؤقت، قم بتشغيل الأمر
بناء جملة غير صحيح بالقرب من 'NOT'
يشير الخطأ Incorrect syntax near 'NOT' إلى وجود بعض الجداول الخارجية مع أعمدة تحتوي على قيد NOT NULL في تعريف العمود.
- قم بتحديث الجدول لإزالة NOT NULL من تعريف العمود.
- يمكن أن يحدث هذا الخطأ أحياناً بشكل عابر مع الجداول التي تم إنشاؤها من عبارة CETAS. إذا لم يتم حل المشكلة، يمكنك محاولة إسقاط الجدول الخارجي وإعادة إنشائه.
يُرجِع تقسيم العمود قيم NULL
إذا أرجع الاستعلام قيم NULL بدلاً من تقسيم الأعمدة أو تعذر العثور على أعمدة القسم، فهناك بعض الخطوات المحتملة لاستكشاف الأخطاء وإصلاحها:
- إذا كنت تستخدم الجداول للاستعلام عن مجموعة بيانات مقسمة، فإن الجداول لا تدعم التقسيم. استبدل الجدول بطرق العرض المقسمة.
- إذا كنت تستخدم طرق العرض المقسمة مع OPENROWSET التي تقوم بالاستعلامات عن الملفات المقسمة باستخدام الدالة FILEPATH()، فتأكد من تحديد نمط حرف البدل في الموقع بشكل صحيح واستخدام الفهرس المناسب للإشارة إلى حرف البدل.
- إذا كنت تقوم بالاستعلام عن الملفات مباشرة في المجلد المقسم، فإن أعمدة التقسيم ليست أجزاء من أعمدة الملفات. يتم وضع قيم التقسيم في مسارات المجلد وليس الملفات. لهذا السبب، لا تحتوي الملفات على قيم التقسيم.
فشل إدخال قيمة إلى الدُفعة لنوع العمود DATETIME2
يشير الخطأ Inserting value to batch for column type DATETIME2 failed إلى أن التجمع بلا خادم لا يمكنه قراءة قيم التاريخ من الملفات الأساسية. لا يمكن تمثيل قيمة التاريخ المخزنة في ملف Parquet أو Delta Lake كعمود DATETIME2.
افحص القيمة الدنيا في الملف باستخدام Spark، وتحقق من أن بعض التواريخ أقل من 0001-01-03. إذا قمت بتخزين الملفات باستخدام إصدار Spark الأعلى الذي لا يزال يستخدم تنسيق تخزين التاريخ والوقت القديم، تتم كتابة قيم التاريخ والوقت من قبل باستخدام التقويم اليولياني الذي لا يتماشى مع التقويم الميلادي المتعدد المستخدم في تجمعات SQL بلا خادم.
قد يكون هناك اختلاف لمدة يومين بين التقويم اليولياني المستخدم لكتابة القيم في Parquet (في بعض إصدارات Spark) والتقويم الغريغوري المطول المستخدم في تجمع SQL بلا خادم. قد يتسبب هذا الاختلاف في التحويل إلى قيمة تاريخ سالبة، وهي قيمة غير صالحة.
حاول استخدام Spark لتحديث هذه القيم لأنه يتم التعامل معها كقيم تاريخ غير صالحة في SQL. يوضح النموذج التالي كيفية تحديث القيم خارج نطاقات التاريخ SQL إلى NULL في Delta Lake:
from delta.tables import *
from pyspark.sql.functions import *
deltaTable = DeltaTable.forPath(spark,
"abfss://my-container@myaccount.dfs.core.windows.net/delta-lake-data-set")
deltaTable.update(col("MyDateTimeColumn") < '0001-02-02', { "MyDateTimeColumn": null } )
يزيل هذا التغيير القيم التي لا يمكن تمثيلها. قد يتم تحميل قيم التاريخ الأخرى بشكل صحيح، ولكن يتم تمثيلها بشكل غير صحيح لأنه لا يزال هناك فرق بين التقويمات اليوليانية والتقويم الميلادي. قد ترى تغييرات غير متوقعة في التاريخ حتى بالنسبة للتواريخ السابقة قبل 1900-01-01 إذا كنت تستخدم Spark 3.0 أو الإصدارات الأقدم.
ضع في اعتبارك الترحيل إلى Spark 3.1 أو أعلى والتبديل إلى التقويم الميلادي proleptic. تستخدم أحدث إصدارات Spark بشكل افتراضي تقويم ميلادي proleptic يتوافق مع التقويم في تجمع SQL بلا خادم. أعد تحميل بياناتك القديمة باستخدام الإصدار الأعلى من Spark، واستخدم الإعداد التالي لتصحيح التواريخ:
spark.conf.set("spark.sql.legacy.parquet.int96RebaseModeInWrite", "CORRECTED")
فشل الاستعلام بسبب تغيير طبولوجيا أو فشل في حاوية الحساب
قد يشير هذا الخطأ إلى حدوث مشكلة ما في عملية داخلية في تجمع SQL بلا خادم. قم بتقديم تذكرة دعم بجميع التفاصيل الضرورية التي يمكن أن تساعد فريق دعم Azure في التحقيق في المشكلة.
وصف أي شيء قد يكون غير عادي مقارنة بحمل العمل العادي. على سبيل المثال، ربما كان هناك عدد كبير من الطلبات المتزامنة أو حمل عمل خاص أو استعلام بدأ في التنفيذ قبل حدوث هذا الخطأ.
انتهاء مهلة توسيع حرف البدل
كما هو موضح في قسم مجلدات الاستعلام وملفات متعددة، يدعم تجمع SQL بلا خادم قراءة ملفات/مجلدات متعددة باستخدام أحرف البدل. هناك حد أقصى يبلغ 10 أحرف بدل لكل استعلام. يجب أن تدرك أن هذه الوظيفة تأتي بتكلفة. يستغرق التجمع بلا خادم وقتا لسرد جميع الملفات التي يمكن أن تتطابق مع حرف البدل. وهذا يقدم زمن انتقال ويمكن أن يزيد زمن الانتقال هذا إذا كان عدد الملفات التي تحاول الاستعلام فيها مرتفعا. في هذه الحالة، يمكنك تشغيل الخطأ التالي:
"Wildcard expansion timed out after X seconds."
هناك العديد من خطوات التخفيف التي يمكنك القيام بها لتجنب هذا:
- تطبيق أفضل الممارسات الموضحة في أفضل الممارسات تجمع SQL بلا خادم.
- حاول تقليل عدد الملفات التي تحاول الاستعلام فيها، عن طريق ضغط الملفات في ملفات أكبر. حاول الاحتفاظ بأحجام الملفات أعلى من 100 ميغابايت.
- تأكد من استخدام عوامل التصفية عبر أعمدة التقسيم كلما أمكن ذلك.
- إذا كنت تستخدم تنسيق ملف دلتا، فاستخدم ميزة تحسين الكتابة في Spark. يمكن أن يؤدي ذلك إلى تحسين أداء الاستعلامات عن طريق تقليل كمية البيانات التي تحتاج إلى قراءة ومعالجة. يتم وصف كيفية استخدام تحسين الكتابة في استخدام تحسين الكتابة على Apache Spark.
- لتجنب بعض أحرف البدل ذات المستوى الأعلى عن طريق ترميز عوامل التصفية الضمنية بشكل فعال عبر تقسيم الأعمدة، استخدم SQL الديناميكي.
عمود مفقود عند استخدام الاستدلال التلقائي على المخطط
يمكنك بسهولة الاستعلام عن الملفات دون معرفة المخطط أو تحديده، عن طريق حذف عبارة WITH. في هذه الحالة سيتم استنتاج أسماء الأعمدة وأنواع البيانات من الملفات. ضع في اعتبارك أنه إذا كنت تقرأ عدد الملفات في وقت واحد، استنتاج المخطط من خدمة الملفات الأولى التي تحصل عليها من التخزين. قد يعني هذا أنه تم حذف بعض الأعمدة المتوقعة، كل ذلك لأن الملف المستخدم من قبل الخدمة لتعريف المخطط لم يحتوي على هذه الأعمدة. لتحديد المخطط بشكل صريح، استخدم عبارة OPENROWSET WITH. إذا قمت بتحديد المخطط (باستخدام جدول خارجي أو عبارة OPENROWSET WITH) استخدام وضع مسار التراخي الافتراضي. وهذا يعني أنه سيتم إرجاع الأعمدة غير الموجودة في بعض الملفات ك NULLs (للصفوف من تلك الملفات). لفهم كيفية استخدام وضع المسار، تحقق من الوثائق والعينة التالية.
التكوين
تمكنك تجمعات SQL بلا خادم من استخدام T-SQL لتكوين عناصر في قاعدة البيانات. هناك بعض القيود:
- لا يمكنك إنشاء عناصر في
masterوlakehouseأو قاعدة بيانات Spark. - يجب أن يكون لديك مفتاح رئيسي لإنشاء بيانات الاعتماد.
- يجب أن يكون لديك الإذن للإشارة إلى البيانات المستخدمة في العنصر.
يتعذر إنشاء قاعدة بيانات
إذا تلقيت الخطأ CREATE DATABASE failed. User database limit has been already reached.، فقد أنشأت أكبر عدد من قواعد البيانات المدعومة في مساحة عمل واحدة. لمزيد من المعلومات، راجع القيود.
- إذا كنت بحاجة إلى فصل العناصر، فاستخدم المخططات داخل قواعد البيانات.
- إذا كنت بحاجة إلى الرجوع إلى تخزين Azure Data Lake، فقم بإنشاء قواعد بيانات المستودعات أو قواعد بيانات Spark التي ستتم مزامنتها في تجمع SQL بلا خادم.
فشل إنشاء جدول أو تغييره لأن الحد الأدنى لحجم الصف يتجاوز الحد الأقصى المسموح به لحجم صف الجدول وهو 8060 بايت
يمكن أن يحتوي أي جدول على ما يصل إلى 8 كيلوبايت من الحجم لكل صف (لا يتضمن بيانات VARCHAR(MAX) /VARBINARY(MAX) خارج الصف). إذا قمت بإنشاء جدول يتجاوز فيه الحجم الإجمالي للخلايا في الصف 8060 بايت، فستحصل على الخطأ التالي:
Msg 1701, Level 16, State 1, Line 3
Creating or altering table '<table name>' failed because the minimum row size would be <???>,
including <???> bytes of internal overhead.
This exceeds the maximum allowable table row size of 8060 bytes.
قد يحدث هذا الخطأ أيضا في قاعدة بيانات Lake إذا قمت بإنشاء جدول Spark بأحجام الأعمدة التي تتجاوز 8060 بايت، ولا يمكن لتجمع SQL بلا خادم إنشاء جدول يشير إلى بيانات جدول Spark.
كتخفيف، تجنب استخدام أنواع الأحجام الثابتة مثل CHAR(N) واستبدلها لأنواع متغيرة الحجم VARCHAR(N) ، أو إنقاص الحجم في CHAR(N). راجع قيود مجموعة صفوف 8 كيلوبايت في SQL Server.
قم بإنشاء مفتاح رئيسي في قاعدة البيانات أو افتح المفتاح الرئيسي في الجلسة قبل إجراء هذه العملية
إذا فشل الاستعلام مع رسالة Please create a master key in the database or open the master key in the session before performing this operation.الخطأ ، فهذا يعني أن قاعدة بيانات المستخدم الخاصة بك ليس لديها حق الوصول إلى مفتاح رئيسي في الوقت الحالي.
على الأرجح أنك أنشأت قاعدة بيانات مستخدم جديدة ولم تنشئ مفتاحاً رئيسياً بعد.
لحل هذه المشكلة، أنشئ مفتاحاً رئيسياً باستخدام الاستعلام التالي:
CREATE MASTER KEY [ ENCRYPTION BY PASSWORD ='strongpasswordhere' ];
إشعار
استبدل 'strongpasswordhere' ببيانات سرية مختلفة هنا.
عبارة CREATE غير مدعومة في قاعدة البيانات الرئيسية
إذا فشل الاستعلام مع رسالة Failed to execute query. Error: CREATE EXTERNAL TABLE/DATA SOURCE/DATABASE SCOPED CREDENTIAL/FILE FORMAT is not supported in master database.الخطأ ، فهذا يعني أن master قاعدة البيانات في تجمع SQL بلا خادم لا تدعم إنشاء:
- الجداول الخارجية.
- مصادر البيانات الخارجية.
- بيانات اعتماد محددة النطاق لقاعدة البيانات.
- تنسيقات الملفات الخارجية.
إليكم الحل:
إنشاء قاعدة بيانات مستخدمين:
CREATE DATABASE <DATABASE_NAME>نفذ عبارة CREATE في سياق <DATABASE_NAME>، والتي فشلت في وقت سابق
masterلقاعدة البيانات الرئيسية.فيما يلي مثال على إنشاء تنسيق ملف خارجي:
USE <DATABASE_NAME> CREATE EXTERNAL FILE FORMAT [SynapseParquetFormat] WITH ( FORMAT_TYPE = PARQUET)
لا يمكن إنشاء تسجيل دخول أو مستخدم Microsoft Entra
إذا تلقيت خطأ أثناء محاولة إنشاء تسجيل دخول أو مستخدم جديد ل Microsoft Entra في قاعدة بيانات، فتحقق من تسجيل الدخول الذي استخدمته للاتصال بقاعدة البيانات. يجب أن يكون لتسجيل الدخول الذي يحاول إنشاء مستخدم Microsoft Entra جديد إذنا للوصول إلى مجال Microsoft Entra والتحقق مما إذا كان المستخدم موجودا. انتبه إلى أنه:
- ليس لدى تسجيلات دخول SQL هذا الإذن، لذلك ستحصل دائما على هذا الخطأ إذا كنت تستخدم مصادقة SQL.
- إذا كنت تستخدم تسجيل دخول Microsoft Entra لإنشاء تسجيلات دخول جديدة، فتحقق لمعرفة ما إذا كان لديك إذن للوصول إلى مجال Microsoft Entra.
Azure Cosmos DB
تمكنك تجمعات SQL بلا خادم من الاستعلام عن التخزين التحليلي لـ Azure Cosmos DB باستخدام الدالة OPENROWSET. تأكد من أن حاوية Azure Cosmos DB تحتوي على تخزين تحليلي. تأكد من تحديد الحساب وقاعدة البيانات واسم الحاوية بشكل صحيح. تأكد أيضاً من أن مفتاح حساب Azure Cosmos DB صالح. لمزيد من المعلومات، راجع المتطلبات الأساسية.
لا يمكن الاستعلام عن Azure Cosmos DB باستخدام الدالة OPENROWSET
إذا لم تتمكن من الاتصال بحساب Azure Cosmos DB، فانظر إلى المتطلبات الأساسية. يتم سرد الأخطاء المحتملة وإجراءات استكشاف الأخطاء وإصلاحها في الجدول التالي.
| خطأ | السبب الجذري |
|---|---|
| أخطاء بناء الجملة: - بناء جملة غير صحيح بالقرب من OPENROWSET.- ... لا يعد خيار موفر خدمة BULK OPENROWSET معروفًا.- بناء جملة غير صحيح بالقرب من .... |
الأسباب الجذرية المحتملة: - عدم استخدام Azure Cosmos DB كمعلمة أولى. - استخدام قيمة حرفية للسلسلة بدلاً من معرف في المعلمة الثالثة. - عدم تحديد المعلمة الثالثة (اسم الحاوية). |
| حدث خطأ في سلسلة اتصال Azure Cosmos DB. | - الحساب أو قاعدة البيانات أو المفتاح غير محدد. - خيار في سلسلة اتصال غير معروف. - يتم وضع فاصلة منقوطة ( ;) في نهاية سلسلة اتصال. |
| فشل تحليل مسار Azure Cosmos DB مع ظهور الخطأ "اسم حساب غير صحيح" أو "اسم قاعدة بيانات غير صحيح." | لا يمكن العثور على اسم الحساب أو اسم قاعدة البيانات أو الحاوية المحددة، أو لم يتم تمكين التخزين التحليلي للمجموعة المحددة. |
| فشل حل مسار Azure Cosmos DB بسبب الخطأ "قيمة بيانات سرية غير صحيحة" أو "البيانات السرية فارغة أو خالية." | مفتاح الحساب غير صالح أو مفقود. |
يتم إرجاع تحذير ترتيب UTF-8 أثناء قراءة أنواع سلاسل Azure Cosmos DB
يُرجِع تجمع SQL بلا خادم تحذير وقت تحويل برمجي إذا لم يكن ترتيب أعمدة OPENROWSET يحتوي على ترميز UTF-8. يمكنك بسهولة تغيير الترتيب الافتراضي لجميع OPENROWSET الوظائف التي تعمل في قاعدة البيانات الحالية باستخدام عبارة T-SQL:
ALTER DATABASE CURRENT COLLATE Latin1_General_100_CI_AS_SC_UTF8;
ترتيب Latin1_General_100_BIN2_UTF8 يقدم أفضل أداء عند تصفية البيانات باستخدام دالات تقييم السلسلة.
الصفوف المفقودة في مخزن Azure Cosmos DB التحليلي
قد لا يتم إرجاع بعض العناصر من Azure Cosmos DB بواسطة الدالة OPENROWSET. انتبه إلى أنه:
- هناك تأخير في المزامنة بين مخزن العمليات والمخزن التحليلي. قد يظهر المستند الذي أدخلته في مخزن عمليات Azure Cosmos DB في المخزن التحليلي بعد دقيقتين إلى ثلاث دقائق.
- قد يخالف المستند بعض قيود المخطط.
يقوم الاستعلام بإرجاع قيم NULL في بعض عناصر Azure Cosmos DB
يقوم Azure Synapse SQL بإرجاع NULL بدلاً من القيم التي تراها في مخزن العمليات في الحالات التالية:
- هناك تأخير في المزامنة بين مخزن العمليات والمخزن التحليلي. قد تظهر القيمة التي أدخلتها في مخزن عمليات Azure Cosmos DB في المخزن التحليلي بعد دقيقتين إلى 3 دقائق.
- قد يكون هناك اسم عمود أو تعبير مسار خاطئ في عبارة WITH. يجب أن يطابق اسم العمود (أو تعبير المسار بعد نوع العمود) في عبارة WITH أسماء الخصائص في مجموعة Azure Cosmos DB. تكون المقارنة حساسة لحالة الأحرف. على سبيل المثال،
productCodeوProductCodeخاصيتان مختلفتان. تأكد من أن أسماء الأعمدة تطابق أسماء خصائص Azure Cosmos DB بالضبط. - قد لا يتم نقل الخاصية إلى المخزن التحليلي لأنه يخالف بعض قيود المخطط، مثل أكثر من 1000 خاصية أو أكثر من 127 مستوى تداخل.
- إذا كنت تستخدم تمثيل مخطط محدد جيداً، فقد تكون القيمة في مخزن العمليات بنوع خاطئ. يعمل المخطط المحدد جيداً على تأمين أنواع كل خاصية عن طريق أخذ عينات من المستندات. يتم التعامل مع أي قيمة مضافة في مخزن المعامَلات لا تتطابق مع النوع كقيمة خاطئة ولا يتم ترحيلها إلى المخزن التحليلي.
- إذا كنت تستخدم تمثيل مخطط كامل الدقة، فتأكد من إضافة لاحقة نوع بعد اسم الخاصية مثل
$.price.int64. إذا لم تشاهد قيمة للمسار المشار إليه، فربما تم تخزينها ضمن مسار نوع مختلف، على سبيل المثال$.price.float64. لمزيد من المعلومات، راجع الاستعلام عن مجموعات Azure Cosmos DB في مخطط كامل الدقة.
العمود غير متوافق مع نوع البيانات الخارجي
يتم إرجاع الخطأ Column 'column name' of the type 'type name' is not compatible with the external data type 'type name'. إذا كان نوع العمود المحدد في عبارة WITH لا يتطابق مع النوع في حاوية Azure Cosmos DB. حاول تغيير نوع العمود كما هو موضح في القسم عمليات تعيين نوع Azure Cosmos DB إلى SQL، أو استخدم نوع VARCHAR.
الحل: فشل مسار Azure Cosmos DB بسبب الخطأ
إذا حصلت على التحقق من الخطأ Resolving Azure Cosmos DB path has failed with error 'This request is not authorized to perform this operation'. لمعرفة ما إذا كنت تستخدم نقاط النهاية الخاصة في Azure Cosmos DB. للسماح لتجمع SQL بلا خادم بالوصول إلى مخزن تحليلي بنقاط نهاية خاصة، يجب تكوين نقاط نهاية خاصة لمخزن Azure Cosmos DB التحليلي.
مشكلات أداء Azure Cosmos DB
إذا كنت تواجه بعض المشكلات غير المتوقعة في الأداء، فتأكد من تطبيق أفضل الممارسات مثل:
- تأكد من وضع تطبيق العميل والتجمع بلا خادم ومخزن Cosmos DB التحليلي في المنطقة نفسها.
- تأكد من استخدام عبارة WITH مع أنواع البيانات المثلى.
- تأكد من استخدام ترتيب Latin1_General_100_BIN2_UTF8 عند تصفية البيانات باستخدام دالات تقييم السلسلة.
- إذا كان لديك استعلامات متكررة قد تكون مخزنة مؤقتاً، حاول استخدام CETAS لتخزين نتائج الاستعلام في Azure Data Lake Storage.
بحيرة دلتا
هناك بعض القيود التي قد تراها في دعم Delta Lake في تجمعات SQL بلا خادم:
- تأكد من الإشارة إلى مجلد Delta Lake الجذر في دالة OPENROWSET أو موقع الجدول الخارجي.
- يجب أن يكون للمجلد الجذر مجلد فرعي يسمى
_delta_log. يفشل الاستعلام إذا لم يكن هناك مجلد_delta_log. إذا لم يمكنك رؤية ذلك المجلد، فمعنى هذا أنك تشير إلى ملفات Parquet العادية التي يجب تحويلها إلى Delta Lake باستخدام تجمعات Apache Spark. - لا تحدد حروف البدل لوصف مخطط الأقسام. سيحدد استعلام Delta Lake أقسام Delta Lake تلقائياً.
- يجب أن يكون للمجلد الجذر مجلد فرعي يسمى
- تتوفر جداول Delta Lake التي تم إنشاؤها في تجمعات Apache Spark تلقائيا في تجمع SQL بلا خادم، ولكن لا يتم تحديث المخطط (قيود المعاينة العامة). إذا أضفت أعمدة في جدول Delta باستخدام تجمع Spark، فلن تظهر التغييرات في قاعدة بيانات تجمع SQL بلا خادم.
- لا تدعم الجداول الخارجية التقسيم. استخدم طرق العرض المقسمة في مجلد Delta Lake للاستفادة من حذف الأقسام. راجع المشكلات والحلول المعروفة لاحقاً في المقالة.
- لا تدعم تجمعات SQL بلا خادم استعلامات السفر عبر الزمن. استخدم تجمعات Apache Spark في Synapse Analytics لقراءة البيانات السابقة.
- لا تدعم تجمعات SQL بلا خادم تحديث ملفات Delta Lake. يمكنك استخدام تجمع SQL بلا خادم للاستعلام عن أحدث إصدار من Delta Lake. استخدم تجمعات Apache Spark في Synapse Analytics لتحديث Delta Lake.
- لا يمكنك تخزين نتائج الاستعلام للتخزين بتنسيق Delta Lake باستخدام الأمر CETAS. يدعم أمر CETAS فقط Parquet وCSV كتنسيقات الإخراج.
- تجمعات SQL بلا خادم في Synapse Analytics متوافقة مع الإصدار 1 من قارئ دلتا.
- لا تدعم تجمعات SQL بلا خادم في Synapse Analytics مجموعات البيانات باستخدام عامل تصفية BLOOM. يتجاهل تجمع SQL بلا خادم عوامل تصفية BLOOM.
- لا يتوفر دعم Delta Lake في تجمعات SQL المخصصة. تأكد من استخدام تجمعات SQL بلا خادم للاستعلام عن ملفات Delta Lake.
- لمزيد من المعلومات حول المشكلات المعروفة مع تجمعات SQL بلا خادم، راجع المشكلات المعروفة في Azure Synapse Analytics.
دعم بلا خادم لإصدار Delta 1.0
تجمعات SQL بلا خادم تقرأ إصدار Delta Lake 1.0 فقط. تجمعات SQL بلا خادم هي قارئ دلتا مع المستوى 1، ولا تدعم الميزات التالية:
- يتم تجاهل تعيينات الأعمدة - سترجع تجمعات SQL بلا خادم أسماء الأعمدة الأصلية.
- يتم تجاهل متجهات الحذف وسيتم إرجاع الإصدار القديم من الصفوف المحذوفة/المحدثة (ربما نتائج خاطئة).
- ميزات Delta Lake التالية غير مدعومة: نقاط التحقق V2، الطابع الزمني دون منطقة زمنية، فحص بروتوكول فراغ
يتم تجاهل حذف المتجهات
إذا تم تكوين جدول Delta lake لاستخدام الإصدار 7 من كاتب Delta، تخزين الصفوف المحذوفة والإصدارات القديمة من الصفوف المحدثة في Delete Vectors (DV). نظرا لأن تجمعات SQL بلا خادم لها مستوى قارئ دلتا 1، فإنها ستتجاهل متجهات الحذف وربما تنتج نتائج خاطئة عند قراءة إصدار Delta Lake غير المدعوم.
إعادة تسمية العمود في جدول Delta غير معتمدة
لا يدعم تجمع SQL بلا خادم الاستعلام عن جداول Delta Lake باستخدام الأعمدة التي تمت إعادة تسميتها. لا يمكن لتجمع SQL بلا خادم قراءة البيانات من العمود الذي تمت إعادة تسميته.
قيمة عمود في جدول Delta هي NULL
إذا كنت تستخدم مجموعة بيانات Delta التي تتطلب إصدار قارئ دلتا 2 أو أعلى، وتستخدم الميزات غير المعتمدة في الإصدار 1 (على سبيل المثال - إعادة تسمية الأعمدة أو إسقاط الأعمدة أو تعيين العمود)، فقد لا تظهر القيم الموجودة في الأعمدة المشار إليها.
لم يتم تنسيق نص JSON بشكل صحيح
يشير هذا الخطأ إلى أن تجمع SQL بلا خادم لا يمكنه قراءة سجل عمليات Delta Lake. سترى رسالة الخطأ التالية:
Msg 13609, Level 16, State 4, Line 1
JSON text is not properly formatted. Unexpected character '' is found at position 263934.
Msg 16513, Level 16, State 0, Line 1
Error reading external metadata.
تأكد من أن مجموعة بيانات Delta Lake غير تالفة. تحقق من أنه يمكنك قراءة محتوى مجلد Delta Lake باستخدام تجمع Apache Spark في Azure Synapse. بهذه الطريقة، ستضمن أن ملف _delta_log غير تالف.
الحل البديل
حاول إنشاء نقطة تحقق في مجموعة بيانات Delta Lake باستخدام تجمع Apache Spark، وأعد تشغيل الاستعلام. ستعمل نقطة التحقق على تجميع ملفات سجل JSON للعمليات، وقد تساعد في حل المشكلة.
إذا كانت مجموعة البيانات صالحة، فأنشئ تذكرة دعم، وقدم المزيد من المعلومات:
- لا تُدخِل أية تغييرات مثل إضافة أو إزالة الأعمدة أو تحسين الجدول لأن هذه العملية قد تؤدي إلى تغيير حالة ملفات سجل عمليات Delta Lake.
- انسخ محتوى مجلد
_delta_logإلى مجلد فارغ جديد. لا تنسخ.parquet dataالملفات. - حاول قراءة المحتوى الذي نسخته في المجلد الجديد، ثم تحقق من أنك تتلقى الخطأ نفسه.
- أرسل محتوى ملف
_delta_logالمنسوخ إلى دعم Azure.
الآن، يمكنك الاستمرار في استخدام مجلد Delta Lake مع تجمع Spark. سيكون عليك توفير البيانات المنسوخة لدعم Microsoft إذا كان يُسمح لك بمشاركة هذه المعلومات. سيحقق فريق Azure في محتوى ملف delta_log، ويوفر مزيد من المعلومات حول الأخطاء والحلول البديلة المحتملة.
فشل حل سجلات Delta
يشير الخطأ التالي إلى أن تجمع SQL بلا خادم لا يمكنه حل سجلات Delta: Resolving Delta logs on path '%ls' failed with error: Cannot parse json object from log folder. السبب الأكثر شيوعا هو أن last_checkpoint_file في _delta_log المجلد أكبر من 200 بايت بسبب checkpointSchema الحقل المضاف في Spark 3.3.
هناك خياران متاحان للتحايل على هذا الخطأ:
- تعديل التكوين المناسب في دفتر ملاحظات Spark وإنشاء نقطة تحقق جديدة، بحيث
last_checkpoint_fileيتم إعادة إنشائها. في حالة استخدام Azure Databricks، يكون تعديل التكوين هو التالي:spark.conf.set("spark.databricks.delta.checkpointSchema.writeThresholdLength", 0); - الرجوع إلى الإصدار الأدنى إلى Spark 3.2.1.
يعمل فريق الهندسة لدينا حاليا على تقديم دعم كامل لـ Spark 3.3.
لا يظهر جدول Delta الذي تم إنشاؤه في Spark في تجمع بلا خادم
إشعار
لا يزال النسخ المتماثل لجداول دلتا التي تم إنشاؤها في Spark في المعاينة العامة.
إذا قمت بإنشاء جدول Delta في Spark، ولم يظهر في تجمع SQL بلا خادم، فتحقق مما يلي:
- انتظر بعض الوقت (عادة 30 ثانية) لأن جداول Spark متزامنة مع التأخير.
- إذا لم يظهر الجدول في تجمع SQL بلا خادم بعد مرور بعض الوقت، فتحقق من مخطط جدول Spark Delta. لا تتوفر جداول Spark ذات الأنواع المعقدة أو الأنواع غير المعتمدة في بلا خادم. حاول إنشاء جدول Spark Parquet بنفس المخطط في قاعدة بيانات بحيرة وتحقق من ظهور هذا الجدول في تجمع SQL بلا خادم.
- تحقق من مجلد الوصول إلى Delta Lake لمساحة العمل المدارة للهوية المشار إليها بواسطة الجدول. يستخدم تجمع SQL بلا خادم هوية مدارة لمساحة العمل للحصول على معلومات عمود الجدول من التخزين لإنشاء الجدول.
قاعدة بيانات البحيرة
تتوفر جداول قاعدة بيانات Lake التي تم إنشاؤها باستخدام مصمم Spark أو Synapse تلقائيًا في تجمع SQL بلا خادم للاستعلام. يمكنك استخدام تجمع SQL بلا خادم للاستعلام عن جداول Parquet وCSV وData Lake التي تم إنشاؤها باستخدام تجمع Spark، وإضافة مخططات وطرق عرض وإجراءات ووظائف قيمة الجدول ومستخدمي Microsoft Entra في دورهم إلى db_datareader قاعدة بيانات Lake. يتم سرد المشكلات المحتملة في هذا القسم.
لا يتوفر جدول تم إنشاؤه في Spark في تجمع بلا خادم
قد لا تتوفر الجداول التي تم إنشاؤها على الفور في تجمع SQL بلا خادم.
- ستكون الجداول متوفرة في تجمعات بلا خادم مع بعض التأخير. قد تحتاج إلى الانتظار من 5 إلى 10 دقائق بعد إنشاء جدول في Spark لرؤيتها في تجمع SQL بلا خادم.
- تتوفر الجداول التي تشير إلى تنسيقات Parquet وCSV وDta فقط في تجمع SQL بلا خادم. أنواع الجداول الأخرى غير متوفرة.
- لن يتوفر جدول يحتوي على بعض أنواع الأعمدة غير المدعومة في تجمع SQL بلا خادم.
- الوصول إلى جداول Delta Lake في قواعد بيانات Lake في المعاينة العامة. تحقق من المشكلات الأخرى المدرجة في هذا القسم أو في قسم Delta Lake.
يعرض جدول خارجي تم إنشاؤه في Spark نتائج غير متوقعة في تجمع بلا خادم
يمكن أن يحدث أن هناك عدم تطابق بين جدول Spark الخارجي المصدر والجدول الخارجي المنسوخ نسخا متماثلا على التجمع بلا خادم. يمكن أن يحدث هذا إذا كانت الملفات المستخدمة في إنشاء جداول Spark الخارجية بدون ملحقات. للحصول على النتائج المناسبة، تأكد من أن جميع الملفات بها ملحقات مثل .parquet.
العملية غير مسموح بها لقاعدة بيانات منسوخة نسخاً متماثلاً
يتم إرجاع هذا الخطأ إذا كنت تحاول تعديل قاعدة بيانات Lake أو إنشاء جداول خارجية أو مصادر بيانات خارجية أو بيانات اعتماد محددة النطاق لقاعدة البيانات أو كائنات أخرى في قاعدة بيانات Lake. يمكن إنشاء هذه الكائنات فقط على قواعد بيانات SQL.
يتم نسخ قواعد بيانات Lake من تجمع Apache Spark وإدارتها بواسطة Apache Spark. لذلك، لا يمكنك إنشاء كائنات مثل في قواعد بيانات SQL باستخدام لغة T-SQL.
يسمح فقط بالعملية التالية في قواعد بيانات Lake:
- إنشاء طرق العرض والإجراءات ودوال قيمة الجدول المضمنة (iTVF) أو إسقاطها أو تغييرها في المخططات بخلاف
dbo. - إنشاء وإفلات مستخدمي قاعدة البيانات من معرف Microsoft Entra.
- إضافة مستخدمي قاعدة البيانات أو إزالتهم من المخطط
db_datareader.
لا يسمح بعمليات أخرى في قواعد بيانات Lake.
إشعار
إذا كنت تقوم بإنشاء عنصر عرض أو إجراء أو دالة في المخطط dbo (أو حذف المخطط واستخدام المخطط الافتراضي الذي عادة ما يكون dbo)، فستتلقى رسالة الخطأ.
لا تتوفر جداول Delta في قواعد بيانات Lake في تجمع SQL بلا خادم
تأكد من أن الهوية المدارة لمساحة العمل الخاصة بك لديها حق الوصول للقراءة على تخزين ADLS الذي يحتوي على مجلد Delta. يقرأ تجمع SQL بلا خادم مخطط جدول Delta Lake من سجلات Delta التي تم وضعها في ADLS ويستخدم هوية مدارة لمساحة العمل للوصول إلى سجلات معاملات Delta.
حاول إعداد مصدر بيانات في بعض قاعدة بيانات SQL التي تشير إلى تخزين Azure Data Lake باستخدام بيانات اعتماد الهوية المدارة، وحاول إنشاء جدول خارجي أعلى مصدر البيانات باستخدام الهوية المدارة للتأكد من أن الجدول الذي يحتوي على الهوية المدارة يمكنه الوصول إلى التخزين الخاص بك.
لا تحتوي جداول Delta في قواعد بيانات Lake على مخطط متطابق في Spark وتجمعات بلا خادم
تمكنك تجمعات SQL بلا خادم من الوصول إلى جداول Parquet وCSV وData التي تم إنشاؤها في قاعدة بيانات Lake باستخدام مصمم Spark أو Synapse. لا يزال الوصول إلى جداول Delta في المعاينة العامة، وسيتزامن حاليا بلا خادم مع جدول Delta مع Spark في وقت الإنشاء ولكنه لن يحدث المخطط إذا تمت إضافة الأعمدة لاحقا باستخدام العبارة ALTER TABLE في Spark.
هذا قيد معاينة عام. قم بإسقاط جدول Delta وإعادة إنشائه في Spark (إذا كان ذلك ممكنا) بدلا من تغيير الجداول لحل هذه المشكلة.
مهلة الاستعلام أو تدهور الأداء على جدول
عند تعديل الجدول الأصلي في Spark أو Dataverse، تتم إعادة إنشاء الجداول المقابلة في التجمع بلا خادم تلقائيا. وتؤدي هذه العملية إلى فقدان الإحصاءات الموجودة على الطاولة. بدون هذه الإحصائيات ، قد تواجه الاستعلامات على الطاولة تأخيرات أو حتى مهلات.
إذا واجهت هذه المشكلة، ففكر في إعداد وظيفة لإعادة إنشاء إحصائيات على الجداول بعد التغييرات في Spark/Dataverse أو وفقا لجدول زمني منتظم.
الأداء
يُحدد تجمع SQL بلا خادم الموارد إلى الاستعلامات استناداً إلى حجم مجموعة البيانات ودرجة تعقيد الاستعلامات. لا يمكنك تغيير أو الحد من الموارد التي يتم توفيرها للاستعلامات. هناك بعض الحالات التي قد تواجه فيها انخفاضًا غير متوقع في أداء الاستعلام، وقد تضطر إلى تحديد الأسباب الجذرية.
مدة الاستعلام طويلة جداً
إذا كانت لديك استعلامات ذات مدة استعلام أطول من 30 دقيقة، فإن الاستعلام الذي يرجع النتائج ببطء إلى العميل يكون بطيئاً. يحتوي تجمع SQL بلا خادم على حد 30 دقيقة للتنفيذ. يتم قضاء أي وقت إضافي في دفق النتائج. جرب الحلول البديلة التالية:
- إذا كنت تستخدم Synapse Studio، حاول إعادة إنتاج المشاكل باستخدام تطبيق آخر مثل SQL Server Management Studio أو تعليمة Visual Studio برمجية.
- إذا كان استعلامك بطيئا عند التنفيذ باستخدام SQL Server Management Studio أو تعليمة Visual Studio برمجية أو Power BI أو أي تطبيق آخر، تحقق من مشاكل الشبكة وأفضل الممارسات.
- ضع الاستعلام في الأمر CETAS وقم بقياس مدة الاستعلام. يخزن الأمر CETAS النتائج إلى Azure Data Lake Storage، ولا يعتمد على اتصال العميل. إذا انتهى الأمر CETAS بشكل أسرع من الاستعلام الأصلي، فتحقق من النطاق الترددي للشبكة بين العميل وتجمع SQL بلا خادم.
يكون الاستعلام بطيئاً عند تنفيذه باستخدام Synapse Studio
إذا كنت تستخدم Synapse Studio، جرب استخدام عميل سطح مكتب مثل SQL Server Management Studio أو تعليمة Visual Studio برمجية. Synapse Studio هو عميل ويب يتصل بمجموعة SQL بدون خادم باستخدام بروتوكول HTTP، والذي يكون عادة أبطأ من الاتصالات الأصلية المستخدمة في SQL Server Management Studio أو تعليمة Visual Studio برمجية.
يكون الاستعلام بطيئاً عند تنفيذه باستخدام تطبيق
تحقق من المشكلات التالية إذا كنت تواجه تنفيذ الاستعلام ببطء:
- تأكد من أن يتم تجميع تطبيقات العميل مع نقطة النهاية في تجمع لغة الاستعلامات المركبة بلا خادم. يمكن أن يؤدي تنفيذ استعلام عبر المنطقة إلى زمن انتقال إضافي وبطء تدفق مجموعة النتائج.
- تأكد من عدم وجود مشكلات في الشبكات يمكن أن تتسبب في بطء دفق مجموعة النتائج
- تأكد من أن التطبيق العميل يمتلك الموارد الكافية (على سبيل المثال، تفادي استخدام معالج CPU بنسبة 100٪).
- تأكد من وضع حساب التخزين أو التخزين التحليلي Azure Cosmos DB في نفس المنطقة مثل نقطة نهاية SQL بلا خادم.
راجع أفضل الممارسات لتجميع الموارد.
تباينات عالية في مدة الاستعلام
إذا كنت تنفذ نفس الاستعلام ولاحظت الاختلافات في فترات الاستعلام، فقد تتسبب عدة أسباب في حدوث هذا السلوك:
- تحقق مما إذا كان هذا هو التنفيذ الأول للاستعلام. يقوم التنفيذ الأول للاستعلام بتجميع الإحصائيات المطلوبة لإنشاء خطة. تُجمع الإحصائيات عن طريق مسح الملفات الأساسية مما يزيد مدة الاستعلام. في Synapse Studio، سترى استعلامات "إنشاء الإحصائيات العامة" في قائمة طلبات SQL التي يتم تنفيذها قبل استعلامك.
- قد تنتهي صلاحية الإحصائيات بعد مرور بعض الوقت. بشكل دوري، قد تلاحظ تأثيرًا على الأداء لأنه يجب أن يقوم التجمع بلا خادم بفحص الإحصائيات وإعادة بنائها. قد تلاحظ استعلامات "إنشاء إحصائيات عامة" أخرى في قائمة طلبات SQL التي تم تنفيذها قبل استعلامك.
- تحقق مما إذا كان هناك بعض أحمال العمل التي يتم تشغيلها على نفس نقطة النهاية عند تنفيذ الاستعلام لمدة أطول. ستُخصص نقطة نهاية SQL بلا خادم الموارد إلى كافة الاستعلامات التي يتم تنفيذها بالتوازي، كما قد يتم تأخير الاستعلام.
الاتصالات
يمكنك تجمع SQL بلا خادم من الاتصال باستخدام بروتوكول TDS وباستخدام لغة T-SQL للاستعلام عن البيانات. يمكن لمعظم الأدوات التي يمكنها الاتصال بقاعدة بيانات SQL Server أو Azure SQL أيضاً الاتصال بتجمع SQL بلا خادم.
تجمع SQL على وشك التنشيط
بعد فترة أطول من عدم النشاط، سيتم إلغاء تنشيط تجمع SQL بلا خادم. يحدث التنشيط تلقائياً في النشاط التالي الأول، مثل محاولة الاتصال الأولى. قد تستغرق عملية التنشيط وقتًا أطول قليلاً من الفاصل الزمني لمحاولة اتصال واحدة، لذلك يتم عرض رسالة الخطأ. يجب أن تكون إعادة محاولة الاتصال كافية.
كأفضل ممارسة، للعملاء الذين يدعمونها، استخدم الكلمات الأساسية لسلسلة اتصال ConnectionRetryCount وConnectRetryInterval للتحكم في سلوك إعادة الاتصال. معظم برامج تشغيل عميل SQL لديها مهلة الاتصال الافتراضية التي تم تعيينها على 15 ثانية. تأكد من تكوين مهلة الاتصال للسماح بجميع محاولات إعادة المحاولة. على سبيل المثال، يجب أن تفي القيم المختارة بالشرط التالي: مهلة > الاتصال ConnectRetryCount * ConnectionRetryInterval.
إذا استمرت رسالة الخطأ في الظهور، فقم بإرسال بطاقة دعم عبر مدخل Azure.
يتعذر الاتصال من Synapse Studio
انتقل إلى Synapse Studio
يتعذر الاتصال بتجمع Azure Synapse من أداة
قد لا تحتوي بعض الأدوات على خيار صريح يمكنك استخدامه للاتصال بتجمع SQL بلا خادم في Azure Synapse. استخدم خياراً ستستخدمه للاتصال بقاعدة بيانات SQL Server أو SQL. لا يلزم وصف مربع حوار الاتصال على أنه "Synapse" لأن تجمع SQL بلا خادم يستخدم نفس البروتوكول، مثل SQL Server أو قاعدة بيانات SQL.
حتى إذا كانت الأداة تتيح لك إدخال اسم خادم منطقي فقط وتحديد المجال database.windows.net مسبقًا، فضع اسم مساحة عمل Azure Synapse متبوعًا باللاحقة -ondemand والمجال database.windows.net.
الأمان
تأكد من أن المستخدم لديه أذونات للوصول إلى قواعد البيانات، والأذونات لتنفيذ الأوامر، والأذونات للوصول إلى Azure Data Lake أو تخزين Azure Cosmos DB.
لا يمكن الوصول إلى حساب Azure Cosmos DB
يجب استخدام مفتاح Azure Cosmos DB للقراءة فقط للوصول إلى التخزين التحليلي، لذا تأكد من عدم انتهاء صلاحيته أو عدم إعادة إنشائه.
إذا تلقيت الخطأ "فشل حل مسار Azure Cosmos DB مع الخطأ"، فتأكد من تكوين جدار حماية.
لا يمكن الوصول إلى قاعدة بيانات المستودعات أو Spark
إذا لم يتمكن المستخدم من الوصول إلى قاعدة بيانات المستودعات أو Spark، فقد لا يكون لدى المستخدم الإذن بالوصول إلى قاعدة البيانات وقراءتها. يجب أن يكون لدى المستخدم الذي لديه إذن CONTROL SERVER حق الوصول الكامل إلى جميع قواعد البيانات. كإذن مقيد، قد تحاول استخدام CONNECT ANY DATABASE وSELECT ALL USER SECURABLES.
لا يمكن لمستخدم SQL الوصول إلى جداول Dataverse
تصل جداول Dataverse إلى التخزين باستخدام هوية Microsoft Entra الخاصة بالمتصل. قد يحاول مستخدم SQL لديه أذونات عالية تحديد البيانات من جدول، ولكن لن يتمكن الجدول من الوصول إلى بيانات Dataverse. هذا السيناريو غير مدعوم.
فشل تسجيل الدخول الأساسي لخدمة Microsoft Entra عند إنشاء SPI لتعيين دور
إذا كنت ترغب في إنشاء تعيين دور لمعرف كيان الخدمة (SPI) أو تطبيق Microsoft Entra باستخدام SPI آخر، أو قمت بالفعل بإنشاء واحد وفشل في تسجيل الدخول، فمن المحتمل أن تتلقى الخطأ التالي: Login error: Login failed for user '<token-identified principal>'.
بالنسبة لأساسيات الخدمة، يجب إنشاء تسجيل الدخول باستخدام معرف تطبيق كمعرف أمان (SID) وليس بمعرف كائن. هناك قيود معروفة لكيانات الخدمة، والتي تمنع Azure Synapse من جلب معرف التطبيق من Microsoft Graph عندما يقوم بإنشاء تعيين دور لمعرف كيان خدمة أو تطبيق آخر.
الحل 1
انتقل إلى مدخل Azure>Synapse Studio>إدارة>التحكم بالوصول، وقم يدويًا بإضافة مسؤول Synapse أو مسؤول Synapse SQL لكيان الخدمة المطلوب.
الحل 2
يجب عليك إنشاء تسجيل دخول مناسب يدويا باستخدام التعليمات البرمجية SQL:
use master
go
CREATE LOGIN [<service_principal_name>] FROM EXTERNAL PROVIDER;
go
ALTER SERVER ROLE sysadmin ADD MEMBER [<service_principal_name>];
go
الحل 3
يمكنك أيضاً إعداد مسؤول Azure Synapse لكيان الخدمة باستخدام PowerShell. يجب أن يكون لديك وحدة Az.Synapse مثبتة.
الحل هو استخدام الأمر cmdlet New-AzSynapseRoleAssignmentمع -ObjectId "parameter". في حقل المعلمة هذا، قم بتوفير معرف التطبيق بدلاً من معرف العنصر باستخدام بيانات اعتماد كيان خدمة Azure لمسؤول مساحة العمل.
البرنامج النصي لـ PowerShell:
$spAppId = "<app_id_which_is_already_an_admin_on_the_workspace>"
$SPPassword = "<application_secret>"
$tenantId = "<tenant_id>"
$secpasswd = ConvertTo-SecureString -String $SPPassword -AsPlainText -Force
$cred = New-Object -TypeName System.Management.Automation.PSCredential -ArgumentList $spAppId, $secpasswd
Connect-AzAccount -ServicePrincipal -Credential $cred -Tenant $tenantId
New-AzSynapseRoleAssignment -WorkspaceName "<workspaceName>" -RoleDefinitionName "Synapse Administrator" -ObjectId "<app_id_to_add_as_admin>" [-Debug]
إشعار
في هذه الحالة، لن تعرض واجهة مستخدم استوديو بيانات synapse تعيين الدور الذي تمت إضافته بواسطة الأسلوب أعلاه، لذلك يوصى بإضافة تعيين الدور إلى كل من معرف الكائن ومعرف التطبيق في نفس الوقت بحيث يمكن عرضه على واجهة المستخدم أيضا.
New-AzSynapseRoleAssignment -WorkspaceName "<workspaceName>" -RoleDefinitionName "مسؤول Synapse" -ObjectId "<object_id_to_add_as_admin>" [-Debug]
التحقق
اتصل بنقطة نهاية SQL بلا خادم وتحقق من إنشاء تسجيل الدخول الخارجي باستخدام SID (app_id_to_add_as_admin في النموذج السابق):
SELECT name, convert(uniqueidentifier, sid) AS sid, create_date
FROM sys.server_principals
WHERE type in ('E', 'X');
أو حاول تسجيل الدخول على نقطة نهاية SQL بلا خادم باستخدام تطبيق المسؤول المحدد.
القيود
قد تؤثر بعض قيود النظام العامة على حمل العمل الخاص بك:
| الخاصية | القيد |
|---|---|
| الحد الأقصى لعدد مساحات عمل Azure Synapse لكل اشتراك | راجع الحدود. |
| الحد الأقصى لعدد قواعد البيانات لكل تجمع بلا خادم | 100 (لا يشمل قواعد البيانات المتزامنة من تجمع Apache Spark). |
| الحد الأقصى لعدد قواعد البيانات المتزامنة من تجمع Apache Spark | غير محدودة |
| الحد الأقصى لعدد عناصر قواعد البيانات لكل قاعدة بيانات | لا يمكن أن يتجاوز مجموع عدد كل العناصر في قاعدة البيانات 2,147,483,647. راجع القيود في محرك قاعدة بيانات SQL Server. |
| الحد الأقصى لطول المعرف بالأحرف | 128. راجع القيود في محرك قاعدة بيانات SQL Server. |
| الحد الأقصى لمدة الاستعلام | 30 دقيقة. |
| الحد الأقصى لحجم مجموعة النتائج | ما يصل إلى 400 جيجابايت مشتركة بين الاستعلامات المتزامنة. |
| الحد الأقصى للتزامن | غير محدود ويعتمد على تعقيد الاستعلام ومقدار البيانات التي يتم فحصها. يمكن لتجمع SQL واحد بلا خادم معالجة 1000 جلسة نشطة تنفذ استعلامات خفيفة الوزن بشكل متزامن. ستنخفض الأرقام إذا كانت الاستعلامات أكثر تعقيدا أو تفحص كمية أكبر من البيانات، لذلك في هذه الحالة ضع في اعتبارك تقليل التزامن وتنفيذ الاستعلامات على مدى فترة زمنية أطول إن أمكن. |
| الحد الأقصى لحجم اسم الجدول الخارجي | 100 حرف. |
يتعذر إنشاء قاعدة بيانات في تجمع SQL بلا خادم
تحتوي تجمعات SQL بلا خادم على قيود، ولا يمكنك إنشاء أكثر من 100 قاعدة بيانات لكل مساحة عمل. إذا كنت بحاجة إلى فصل العناصر وعزلها، فاستخدم المخططات.
إذا تلقيت الخطأ CREATE DATABASE failed. User database limit has been already reached ، فقد أنشأت الحد الأقصى لعدد قواعد البيانات المعتمدة في مساحة عمل واحدة.
لا تحتاج إلى استخدام قواعد بيانات منفصلة لعزل البيانات لمستأجرين مختلفين. يتم تخزين جميع البيانات خارجياً على مستودع بيانات وAzure Cosmos DB. يمكن عزل بيانات التعريف، مثل الجدول وطرق العرض وتعريفات الدالة بنجاح باستخدام المخططات. يتم أيضاً استخدام العزل المستند إلى المخطط في Spark، حيث قواعد البيانات والمخططات هي نفس المفاهيم.