Kopírování a transformace dat ve službě Azure Synapse Analytics pomocí kanálů Azure Data Factory nebo Synapse
PLATÍ PRO: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Tento článek popisuje, jak pomocí aktivity kopírování v kanálech Azure Data Factory nebo Synapse kopírovat data z a do Azure Synapse Analytics a jak pomocí Tok dat transformovat data v Azure Data Lake Storage Gen2. Další informace o službě Azure Data Factory najdete v úvodním článku.
Podporované funkce
Tento konektor Azure Synapse Analytics je podporovaný pro následující funkce:
| Podporované funkce | IR | Spravovaný privátní koncový bod |
|---|---|---|
| aktivita Copy (zdroj/jímka) | (1) (2) | ✓ |
| Mapování toku dat (zdroj/jímka) | (1) | ✓ |
| Aktivita Lookup | (1) (2) | ✓ |
| Aktivita GetMetadata | (1) (2) | ✓ |
| Aktivita skriptu | (1) (2) | ✓ |
| Aktivita uložená procedura | (1) (2) | ✓ |
(1) Prostředí Azure Integration Runtime (2) Místní prostředí Integration Runtime
Pro aktivita Copy podporuje tento konektor Azure Synapse Analytics tyto funkce:
- Kopírování dat pomocí ověřování SQL a ověřování tokenu aplikace Microsoft Entra s instančním objektem nebo spravovanými identitami pro prostředky Azure
- Jako zdroj načtěte data pomocí dotazu SQL nebo uložené procedury. Můžete se také rozhodnout pro paralelní kopírování ze zdroje Azure Synapse Analytics. Podrobnosti najdete v části Paralelní kopírování z Azure Synapse Analytics .
- Jako jímku načtěte data pomocí příkazu COPY nebo PolyBase nebo hromadného vložení. Pro lepší výkon kopírování doporučujeme příkaz COPY nebo PolyBase. Konektor také podporuje automatické vytváření cílové tabulky pomocí funkce DISTRIBUTION = ROUND_ROBIN, pokud neexistuje na základě zdrojového schématu.
Důležité
Pokud kopírujete data pomocí prostředí Azure Integration Runtime, nakonfigurujte pravidlo brány firewall na úrovni serveru, aby služby Azure mohly přistupovat k logickému SQL serveru. Pokud kopírujete data pomocí místního prostředí Integration Runtime, nakonfigurujte bránu firewall tak, aby povolila odpovídající rozsah IP adres. Tento rozsah zahrnuje IP adresu počítače, která se používá pro připojení k Azure Synapse Analytics.
Začínáme
Tip
Pokud chcete dosáhnout nejlepšího výkonu, použijte příkaz PolyBase nebo COPY k načtení dat do Azure Synapse Analytics. Použití PolyBase k načtení dat do Azure Synapse Analytics a použití příkazu COPY k načtení dat do oddílů Azure Synapse Analytics obsahuje podrobnosti. Návod k případu použití najdete v tématu Načtení 1 TB do Azure Synapse Analytics do služby Azure Synapse Analytics do 15 minut pomocí služby Azure Data Factory.
K provedení aktivita Copy s kanálem můžete použít jeden z následujících nástrojů nebo sad SDK:
- Nástroj pro kopírování dat
- Azure Portal
- Sada .NET SDK
- Sada Python SDK
- Azure PowerShell
- Rozhraní REST API
- Šablona Azure Resource Manageru
Vytvoření propojené služby Azure Synapse Analytics pomocí uživatelského rozhraní
Pomocí následujících kroků vytvořte propojenou službu Azure Synapse Analytics v uživatelském rozhraní webu Azure Portal.
Přejděte na kartu Správa v pracovním prostoru Azure Data Factory nebo Synapse a vyberte Propojené služby a pak klikněte na Nový:
Vyhledejte Synapse a vyberte konektor Azure Synapse Analytics.
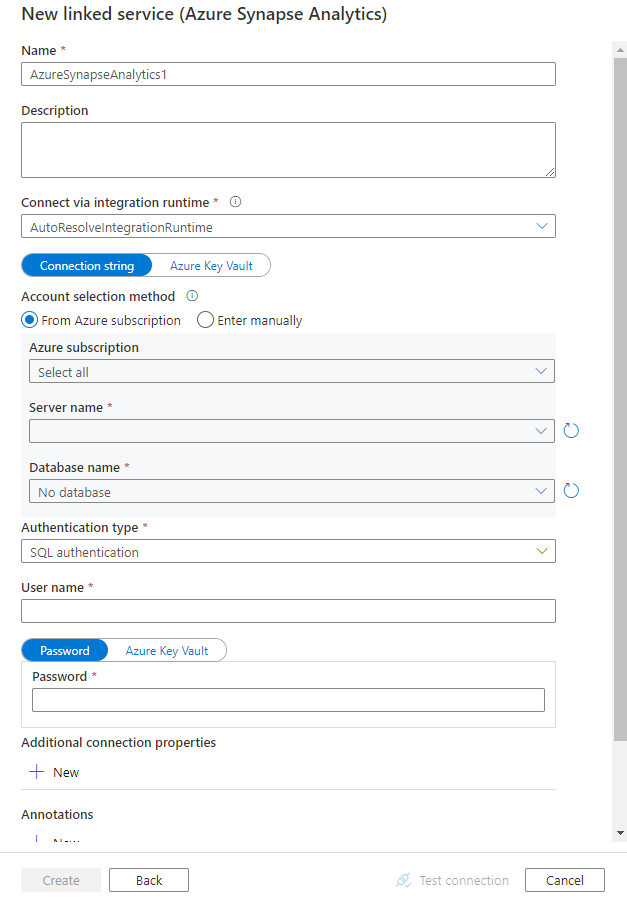
Nakonfigurujte podrobnosti o službě, otestujte připojení a vytvořte novou propojenou službu.
podrobnosti o konfiguraci Připojení oru
Následující části obsahují podrobnosti o vlastnostech, které definují entity kanálu Data Factory a Synapse specifické pro konektor Azure Synapse Analytics.
Vlastnosti propojené služby
Pro propojenou službu Azure Synapse Analytics se podporují tyto obecné vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu musí být nastavená na AzureSqlDW. | Ano |
| připojovací řetězec | Zadejte informace potřebné pro připojení k instanci Azure Synapse Analytics pro vlastnost connectionString . Označte toto pole jako řetězec SecureString, abyste ho bezpečně uložili. Do služby Azure Key Vault můžete také vložit heslo nebo instanční klíč a pokud ověřování SQL přetáhne password konfiguraci z připojovací řetězec. Další podrobnosti najdete v příkladu JSON pod tabulkou a přihlašovacími údaji k úložišti přihlašovacích údajů ve službě Azure Key Vault . |
Ano |
| azureCloudType | Pro ověřování instančního objektu zadejte typ cloudového prostředí Azure, ke kterému je zaregistrovaná vaše aplikace Microsoft Entra. Povolené hodnoty jsou AzurePublic, AzureChina, AzureUsGovernmenta AzureGermany. Ve výchozím nastavení se používá cloudové prostředí datové továrny nebo kanálu Synapse. |
No |
| connectVia | Prostředí Integration Runtime , které se má použít pro připojení k úložišti dat. Můžete použít prostředí Azure Integration Runtime nebo místní prostředí Integration Runtime (pokud se vaše úložiště dat nachází v privátní síti). Pokud není zadaný, použije výchozí prostředí Azure Integration Runtime. | No |
Informace o různých typech ověřování najdete v následujících částech o konkrétních vlastnostech, požadavcích a ukázkách JSON:
- Ověřování SQL
- Ověřování instančních objektů
- Ověřování spravované identity přiřazené systémem
- Ověřování spravované identity přiřazené uživatelem
Tip
Při vytváření propojené služby pro bezserverový fond SQL ve službě Azure Synapse z webu Azure Portal:
- V případě metody výběru účtu zvolte Zadat ručně.
- Vložte plně kvalifikovaný název domény bezserverového koncového bodu. Najdete ho na stránce Přehled webu Azure Portal pro váš pracovní prostor Synapse ve vlastnostech v části Bezserverový koncový bod SQL. Například
myserver-ondemand.sql-azuresynapse.net. - Jako název databáze zadejte název databáze v bezserverovém fondu SQL.
Tip
Pokud dojde k chybě s kódem chyby UserErrorFailedTo Připojení ToSqlServer a zpráva typu "Limit relace pro databázi je XXX a byl dosažen", přidejte Pooling=false do svého připojovací řetězec a zkuste to znovu.
Ověřování SQL
Chcete-li použít typ ověřování ověřování SQL, zadejte obecné vlastnosti popsané v předchozí části.
Příklad propojené služby, který používá ověřování SQL
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"connectionString": "Server=tcp:<servername>.database.windows.net,1433;Database=<databasename>;User ID=<username>@<servername>;Password=<password>;Trusted_Connection=False;Encrypt=True;Connection Timeout=30"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Heslo ve službě Azure Key Vault:
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"connectionString": "Server=tcp:<servername>.database.windows.net,1433;Database=<databasename>;User ID=<username>@<servername>;Trusted_Connection=False;Encrypt=True;Connection Timeout=30",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Ověřování instančního objektu
Pokud chcete použít ověřování instančního objektu, kromě obecných vlastností popsaných v předchozí části zadejte následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| servicePrincipalId | Zadejte ID klienta aplikace. | Ano |
| servicePrincipalKey | Zadejte klíč aplikace. Označte toto pole jako securestring, abyste ho mohli bezpečně uložit, nebo odkazovat na tajný klíč uložený ve službě Azure Key Vault. | Ano |
| tenant | Zadejte informace o tenantovi (název domény nebo ID tenanta), pod kterým se vaše aplikace nachází. Můžete ho načíst tak, že na něj narazíte myší v pravém horním rohu webu Azure Portal. | Ano |
Musíte také postupovat podle následujících kroků:
Na webu Azure Portal vytvořte aplikaci Microsoft Entra. Poznamenejte si název aplikace a následující hodnoty, které definují propojenou službu:
- ID aplikace
- Klíč aplikace
- ID tenanta
Pokud jste to ještě neudělali, zřiďte správce Microsoft Entra pro váš server na webu Azure Portal. Správcem Microsoft Entra může být uživatel Microsoft Entra nebo skupina Microsoft Entra. Pokud skupině udělíte roli správce spravované identity, přeskočte kroky 3 a 4. Správce bude mít úplný přístup k databázi.
Vytvořte uživatele databáze s omezením pro instanční objekt. Připojení do datového skladu nebo do kterého chcete kopírovat data pomocí nástrojů, jako je SSMS, s identitou Microsoft Entra, která má alespoň oprávnění ALTER ANY USER. Spusťte následující příkaz T-SQL:
CREATE USER [your_application_name] FROM EXTERNAL PROVIDER;Udělte instančnímu objektu potřebná oprávnění jako obvykle pro uživatele SQL nebo jiné uživatele. Spusťte následující kód nebo se tady podívejte na další možnosti. Pokud chcete k načtení dat použít PolyBase, přečtěte si požadované oprávnění k databázi.
EXEC sp_addrolemember db_owner, [your application name];Nakonfigurujte propojenou službu Azure Synapse Analytics v pracovním prostoru Azure Data Factory nebo Synapse.
Příklad propojené služby, který používá ověřování instančního objektu
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"connectionString": "Server=tcp:<servername>.database.windows.net,1433;Database=<databasename>;Connection Timeout=30",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Spravované identity přiřazené systémem pro ověřování prostředků Azure
Pracovní prostor datové továrny nebo Synapse je možné přidružit ke spravované identitě přiřazené systémem pro prostředky Azure, které daný prostředek představují. Tuto spravovanou identitu můžete použít pro ověřování Azure Synapse Analytics. Určený prostředek může přistupovat k datům z datového skladu nebo do vašeho datového skladu a kopírovat je pomocí této identity.
Pokud chcete použít ověřování spravované identity přiřazené systémem, zadejte obecné vlastnosti popsané v předchozí části a postupujte podle těchto kroků.
Pokud jste to ještě neudělali, zřiďte správce Microsoft Entra pro váš server na webu Azure Portal. Správcem Microsoft Entra může být uživatel Microsoft Entra nebo skupina Microsoft Entra. Pokud skupině udělíte spravovanou identitu přiřazenou systémem roli správce, přeskočte kroky 3 a 4. Správce bude mít úplný přístup k databázi.
Vytvořte uživatele databáze s omezením pro spravovanou identitu přiřazenou systémem. Připojení do datového skladu nebo do kterého chcete kopírovat data pomocí nástrojů, jako je SSMS, s identitou Microsoft Entra, která má alespoň oprávnění ALTER ANY USER. Spusťte následující příkaz T-SQL.
CREATE USER [your_resource_name] FROM EXTERNAL PROVIDER;Udělte spravované identitě přiřazené systémem potřebná oprávnění jako obvykle pro uživatele SQL a další uživatele. Spusťte následující kód nebo se tady podívejte na další možnosti. Pokud chcete k načtení dat použít PolyBase, přečtěte si požadované oprávnění k databázi.
EXEC sp_addrolemember db_owner, [your_resource_name];Nakonfigurujte propojenou službu Azure Synapse Analytics.
Příklad:
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"connectionString": "Server=tcp:<servername>.database.windows.net,1433;Database=<databasename>;Connection Timeout=30"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Ověřování spravované identity přiřazené uživatelem
Pracovní prostor datové továrny nebo Synapse je možné přidružit ke spravovaným identitám přiřazeným uživatelem, které představují prostředek. Tuto spravovanou identitu můžete použít pro ověřování Azure Synapse Analytics. Určený prostředek může přistupovat k datům z datového skladu nebo do vašeho datového skladu a kopírovat je pomocí této identity.
Pokud chcete použít ověřování spravované identity přiřazené uživatelem, kromě obecných vlastností popsaných v předchozí části zadejte následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| přihlašovací údaje | Jako objekt přihlašovacích údajů zadejte spravovanou identitu přiřazenou uživatelem. | Ano |
Musíte také postupovat podle následujících kroků:
Pokud jste to ještě neudělali, zřiďte správce Microsoft Entra pro váš server na webu Azure Portal. Správcem Microsoft Entra může být uživatel Microsoft Entra nebo skupina Microsoft Entra. Pokud skupině udělíte spravovanou identitu přiřazenou uživatelem roli správce, přeskočte kroky 3. Správce bude mít úplný přístup k databázi.
Vytvořte uživatele databáze s omezením pro spravovanou identitu přiřazenou uživatelem. Připojení do datového skladu nebo do kterého chcete kopírovat data pomocí nástrojů, jako je SSMS, s identitou Microsoft Entra, která má alespoň oprávnění ALTER ANY USER. Spusťte následující příkaz T-SQL.
CREATE USER [your_resource_name] FROM EXTERNAL PROVIDER;Vytvořte jednu nebo více spravovaných identit přiřazených uživatelem a udělte spravované identitě přiřazené uživatelem potřebná oprávnění jako obvykle pro uživatele SQL a další. Spusťte následující kód nebo se tady podívejte na další možnosti. Pokud chcete k načtení dat použít PolyBase, přečtěte si požadované oprávnění k databázi.
EXEC sp_addrolemember db_owner, [your_resource_name];Přiřaďte k datové továrně jednu nebo více spravovaných identit přiřazených uživatelem a vytvořte přihlašovací údaje pro každou spravovanou identitu přiřazenou uživatelem.
Nakonfigurujte propojenou službu Azure Synapse Analytics.
Příklad:
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"connectionString": "Server=tcp:<servername>.database.windows.net,1433;Database=<databasename>;Connection Timeout=30",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Vlastnosti datové sady
Úplný seznam oddílů a vlastností dostupných pro definování datových sad najdete v článku Datové sady .
Pro datovou sadu Azure Synapse Analytics se podporují následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu datové sady musí být nastavená na AzureSqlDWTable. | Ano |
| schema | Název schématu | Ne pro zdroj, Ano pro jímku |
| table | Název tabulky nebo zobrazení | Ne pro zdroj, Ano pro jímku |
| tableName | Název tabulky nebo zobrazení se schématem Tato vlastnost je podporována pro zpětnou kompatibilitu. Pro nové úlohy použijte schema a table. |
Ne pro zdroj, Ano pro jímku |
Příklad vlastností datové sady
{
"name": "AzureSQLDWDataset",
"properties":
{
"type": "AzureSqlDWTable",
"linkedServiceName": {
"referenceName": "<Azure Synapse Analytics linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
Vlastnosti aktivity kopírování
Úplný seznam oddílů a vlastností dostupných pro definování aktivit najdete v článku Pipelines . Tato část obsahuje seznam vlastností podporovaných zdrojem a jímkou služby Azure Synapse Analytics.
Azure Synapse Analytics jako zdroj
Tip
Pokud chcete efektivně načítat data z Azure Synapse Analytics pomocí dělení dat, přečtěte si další informace o paralelním kopírování z Azure Synapse Analytics.
Pokud chcete kopírovat data z Azure Synapse Analytics, nastavte vlastnost typu ve zdroji aktivity kopírování na SqlDWSource. Ve zdroji aktivity kopírování jsou podporovány následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu zdroje aktivity kopírování musí být nastavena na SqlDWSource. | Ano |
| sqlReaderQuery | Ke čtení dat použijte vlastní dotaz SQL. Příklad: select * from MyTable. |
No |
| sqlReaderStoredProcedureName | Název uložené procedury, která čte data ze zdrojové tabulky. Poslední příkaz SQL musí být příkaz SELECT v uložené proceduře. | No |
| storedProcedureParameters | Parametry uložené procedury. Povolené hodnoty jsou dvojice názvů nebo hodnot. Názvy a velikost písmen parametrů musí odpovídat názvům a velikostem písmen parametrů uložené procedury. |
No |
| Isolationlevel | Určuje chování uzamčení transakce pro zdroj SQL. Povolené hodnoty jsou: ReadCommitted, ReadUncommitted, RepeatableRead, Serializable, Snapshot. Pokud není zadáno, použije se výchozí úroveň izolace databáze. Další informace naleznete v tématu system.data.isolationlevel. | No |
| partitionOptions | Určuje možnosti dělení dat používané k načtení dat z Azure Synapse Analytics. Povolené hodnoty jsou: None (výchozí), PhysicalPartitionsOfTable a DynamicRange. Pokud je povolená možnost oddílu (tj. ne None), stupeň paralelismu pro souběžné načítání dat z Azure Synapse Analytics se řídí parallelCopies nastavením aktivity kopírování. |
No |
| oddíl Nastavení | Zadejte skupinu nastavení pro dělení dat. Použít, pokud možnost oddílu není None. |
No |
V části partitionSettings: |
||
| partitionColumnName | Zadejte název zdrojového sloupce v celočíselném čísle nebo typu date/datetime (int, smallint, bigint, smalldatetimedate, , datetime, datetime2nebo datetimeoffset), který bude použit dělením rozsahu pro paralelní kopírování. Pokud není zadaný, index nebo primární klíč tabulky se automaticky zjistí a použije se jako sloupec oddílu.Použít, pokud je DynamicRangemožnost oddílu . Pokud k načtení zdrojových dat použijete dotaz, připojte se ?AdfDynamicRangePartitionCondition do klauzule WHERE. Příklad najdete v části Paralelní kopírování z databáze SQL. |
No |
| partitionUpperBound | Maximální hodnota sloupce oddílu pro rozdělení rozsahu oddílů. Tato hodnota se používá k rozhodování o kroku oddílu, nikoli k filtrování řádků v tabulce. Všechny řádky v tabulce nebo výsledku dotazu se rozdělí a zkopírují. Pokud není zadáno, aktivita kopírování automaticky rozpozná hodnotu. Použít, pokud je DynamicRangemožnost oddílu . Příklad najdete v části Paralelní kopírování z databáze SQL. |
No |
| partitionLowerBound | Minimální hodnota sloupce oddílu pro rozdělení rozsahu oddílů. Tato hodnota se používá k rozhodování o kroku oddílu, nikoli k filtrování řádků v tabulce. Všechny řádky v tabulce nebo výsledku dotazu se rozdělí a zkopírují. Pokud není zadáno, aktivita kopírování automaticky rozpozná hodnotu. Použít, pokud je DynamicRangemožnost oddílu . Příklad najdete v části Paralelní kopírování z databáze SQL. |
No |
Všimněte si následujícího bodu:
- Při použití uložené procedury ve zdroji k načtení dat si všimněte, že uložená procedura je navržena jako vrácení jiného schématu, pokud je předána jiná hodnota parametru, může dojít k selhání nebo může dojít k neočekávanému výsledku při importu schématu z uživatelského rozhraní nebo při kopírování dat do databáze SQL s automatickým vytvořením tabulky.
Příklad: Použití dotazu SQL
"activities":[
{
"name": "CopyFromAzureSQLDW",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure Synapse Analytics input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlDWSource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Příklad: použití uložené procedury
"activities":[
{
"name": "CopyFromAzureSQLDW",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure Synapse Analytics input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlDWSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Ukázková uložená procedura:
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
Azure Synapse Analytics jako jímka
Kanály Azure Data Factory a Synapse podporují tři způsoby načtení dat do Azure Synapse Analytics.
- Použití příkazu COPY
- Použití PolyBase
- Použití hromadného vložení
Nejrychlejším a nejš škálovatelným způsobem načítání dat je příkaz COPY nebo PolyBase.
Pokud chcete kopírovat data do Azure Synapse Analytics, nastavte typ jímky v aktivitě kopírování na SqlDWSink. V části Jímka aktivity kopírování se podporují následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu jímky aktivity kopírování musí být nastavena na SqlDWSink. | Ano |
| allowPolyBase | Určuje, jestli se má použít PolyBase k načtení dat do Azure Synapse Analytics. allowCopyCommand a allowPolyBase nemůže být pravdivý. Informace o omezeních a podrobnostech najdete v části Použití PolyBase k načtení dat do části Azure Synapse Analytics . Povolené hodnoty jsou True a False (výchozí). |
Ne. Použít při použití PolyBase. |
| polyBase Nastavení | Skupina vlastností, které lze zadat, když allowPolybase je vlastnost nastavena na hodnotu true. |
Ne. Použít při použití PolyBase. |
| allowCopyCommand | Určuje, jestli se má použít příkaz COPY k načtení dat do Azure Synapse Analytics. allowCopyCommand a allowPolyBase nemůže být pravdivý. Informace o omezeních a podrobnostech najdete v části Použití příkazu COPY k načtení dat do části Azure Synapse Analytics . Povolené hodnoty jsou True a False (výchozí). |
Ne. Použít při použití funkce COPY. |
| copyCommand Nastavení | Skupina vlastností, které lze zadat, když allowCopyCommand je vlastnost nastavena na HODNOTU TRUE. |
Ne. Použít při použití funkce COPY. |
| writeBatchSize | Počet řádků, které se mají vložit do tabulky SQL na dávku Povolená hodnota je celé číslo (počet řádků). Ve výchozím nastavení služba dynamicky určuje odpovídající velikost dávky na základě velikosti řádku. |
Ne. Použít při použití hromadného vložení |
| writeBatchTimeout | Doba čekání na dokončení operace vložení, upsertu a uložené procedury před vypršením časového limitu. Povolené hodnoty jsou pro časový rozsah. Příkladem je 00:30:00 po dobu 30 minut. Pokud není zadána žádná hodnota, časový limit je výchozí hodnota 00:30:00. |
Ne. Použít při použití hromadného vložení |
| preCopyScript | Zadejte dotaz SQL pro aktivitu kopírování, který se má spustit před zápisem dat do Azure Synapse Analytics v každém spuštění. Tato vlastnost slouží k vyčištění předem načtených dat. | No |
| tableOption | Určuje, zda se má automaticky vytvořit tabulka jímky, pokud neexistuje, na základě zdrojového schématu. Povolené hodnoty jsou: none (výchozí), autoCreate. |
No |
| disableMetricsCollection | Služba shromažďuje metriky, jako jsou jednotky DWU Azure Synapse Analytics pro optimalizaci výkonu kopírování a doporučení, která představují další hlavní přístup k databázi. Pokud máte obavy o toto chování, určete true , jestli chcete toto chování vypnout. |
Ne (výchozí hodnota je false) |
| maxConcurrent Připojení ions | Horní limit souběžných připojení vytvořených k úložišti dat během spuštění aktivity. Zadejte hodnotu pouze v případech, kdy chcete omezit souběžná připojení. | Ne |
| WriteBehavior | Zadejte chování zápisu aktivity kopírování pro načtení dat do služby Azure SQL Database. Povolená hodnota je Insert a Upsert. Ve výchozím nastavení služba používá k načtení dat vložení. |
No |
| upsert Nastavení | Zadejte skupinu nastavení pro chování zápisu. Použít, pokud je Upsertmožnost WriteBehavior . |
No |
V části upsertSettings: |
||
| keys | Zadejte názvy sloupců pro jedinečnou identifikaci řádků. Můžete použít jeden klíč nebo řadu klíčů. Pokud není zadaný, použije se primární klíč. | No |
| interimSchemaName | Zadejte dočasné schéma pro vytvoření dočasné tabulky. Poznámka: Uživatel musí mít oprávnění k vytváření a odstraňování tabulek. Ve výchozím nastavení bude dočasná tabulka sdílet stejné schéma jako tabulka jímky. | No |
Příklad 1: Jímka služby Azure Synapse Analytics
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true,
"polyBaseSettings":
{
"rejectType": "percentage",
"rejectValue": 10.0,
"rejectSampleValue": 100,
"useTypeDefault": true
}
}
Příklad 2: Upsert data
"sink": {
"type": "SqlDWSink",
"writeBehavior": "Upsert",
"upsertSettings": {
"keys": [
"<column name>"
],
"interimSchemaName": "<interim schema name>"
},
}
Paralelní kopírování z Azure Synapse Analytics
Konektor Azure Synapse Analytics v aktivitě kopírování poskytuje integrované dělení dat pro paralelní kopírování dat. Možnosti dělení dat najdete na kartě Zdroj aktivity kopírování.
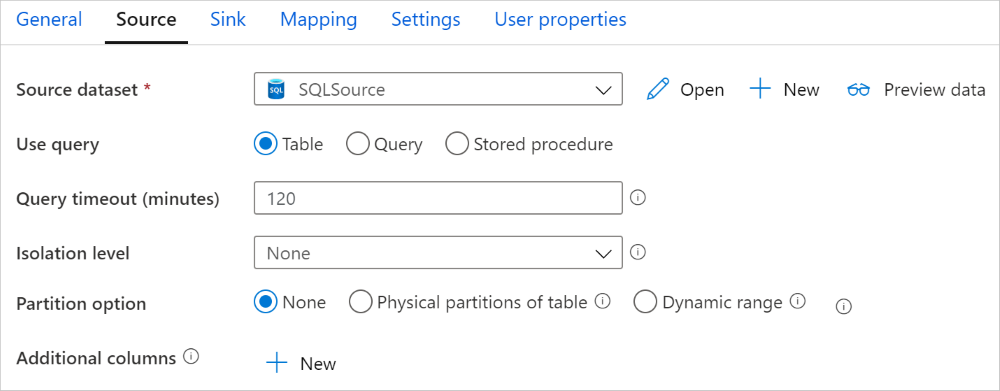
Když povolíte dělené kopírování, aktivita kopírování spouští paralelní dotazy na zdroj Azure Synapse Analytics, aby načetla data podle oddílů. Paralelní stupeň se řídí parallelCopies nastavením aktivity kopírování. Pokud například nastavíte parallelCopies hodnotu čtyři, služba souběžně vygeneruje a spouští čtyři dotazy na základě zadané možnosti a nastavení oddílu a každý dotaz načte část dat z vaší služby Azure Synapse Analytics.
Doporučujeme povolit paralelní kopírování s dělením dat, zejména pokud načítáte velké množství dat z Azure Synapse Analytics. Následující konfigurace jsou navržené pro různé scénáře. Při kopírování dat do souborového úložiště dat se doporučuje zapisovat do složky jako více souborů (zadat pouze název složky), v takovém případě je výkon lepší než zápis do jednoho souboru.
| Scénář | Navrhovaná nastavení |
|---|---|
| Úplné načtení z velké tabulky s fyzickými oddíly | Možnost oddílu: Fyzické oddíly tabulky. Během provádění služba automaticky rozpozná fyzické oddíly a kopíruje data podle oddílů. Pokud chcete zkontrolovat, jestli tabulka obsahuje fyzický oddíl nebo ne, můžete odkazovat na tento dotaz. |
| Úplné načtení z velké tabulky bez fyzických oddílů, zatímco s celočíselnou nebo datetime sloupcem pro dělení dat. | Možnosti oddílu: Oddíl dynamického rozsahu Sloupec oddílu (volitelné): Zadejte sloupec použitý k dělení dat. Pokud není zadaný, použije se sloupec indexu nebo primárního klíče. Horní mez oddílu a dolní mez oddílu (volitelné): Určete, jestli chcete určit krok oddílu. To není pro filtrování řádků v tabulce, všechny řádky v tabulce budou rozděleny a zkopírovány. Pokud není zadáno, aktivita kopírování automaticky rozpozná hodnoty. Pokud má například sloupec oddílu ID hodnoty od 1 do 100 a dolní mez nastavíte jako 20 a horní mez jako 80, přičemž paralelní kopírování je 4, služba načte data o 4 oddílech – ID v rozsahu <=20, [21, 50], [51, 80] a >=81. |
| Načtěte velké množství dat pomocí vlastního dotazu bez fyzických oddílů, zatímco s celočíselnou nebo datem a datem a časem pro dělení dat. | Možnosti oddílu: Oddíl dynamického rozsahu Dotaz: SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>.Sloupec oddílu: Zadejte sloupec použitý k rozdělení dat. Horní mez oddílu a dolní mez oddílu (volitelné): Určete, jestli chcete určit krok oddílu. To není pro filtrování řádků v tabulce, všechny řádky ve výsledku dotazu budou rozděleny a zkopírovány. Pokud není zadáno, aktivita kopírování automaticky rozpozná hodnotu. Během provádění služba nahradí ?AdfRangePartitionColumnName skutečný název sloupce a rozsahy hodnot pro každý oddíl a odešle do Azure Synapse Analytics. Pokud má například sloupec oddílu ID hodnoty od 1 do 100 a dolní mez nastavíte jako 20 a horní mez 80, přičemž paralelní kopírování je 4, služba načte data podle 4 oddílů v rozsahu <=20, [21, 50], [51, 80] a >=81. Tady jsou další ukázkové dotazy pro různé scénáře: 1. Dotaz na celou tabulku: SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition2. Dotaz z tabulky s výběrem sloupce a dalšími filtry klauzule where: SELECT <column_list> FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>3. Dotaz s poddotazy: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>4. Dotaz s oddílem v poddotazu: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition) AS T |
Osvědčené postupy pro načtení dat s možností oddílu:
- Zvolte výrazný sloupec jako sloupec oddílu (například primární klíč nebo jedinečný klíč), abyste se vyhnuli nerovnoměrné distribuci dat.
- Pokud tabulka obsahuje předdefinovaný oddíl, použijte možnost oddílu Fyzické oddíly tabulky, abyste dosáhli lepšího výkonu.
- Pokud ke kopírování dat používáte Prostředí Azure Integration Runtime, můžete nastavit větší počet jednotek Integrace Dat (DIU) (>4) a využít tak více výpočetních prostředků. Zkontrolujte tam příslušné scénáře.
- "Stupeň paralelismu kopírování" řídí čísla oddílů, nastavení příliš velkého čísla někdy snižuje výkon, doporučujeme nastavit toto číslo jako (DIU nebo počet uzlů místního prostředí IR) * (2 až 4).
- Všimněte si, že Azure Synapse Analytics může v tuto chvíli spouštět maximálně 32 dotazů. Nastavení stupně paralelismu kopírování může způsobit problém s omezováním Synapse.
Příklad: Úplné načtení z velké tabulky s fyzickými oddíly
"source": {
"type": "SqlDWSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Příklad: Dotaz s oddílem dynamického rozsahu
"source": {
"type": "SqlDWSource",
"query": "SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Ukázkový dotaz pro kontrolu fyzického oddílu
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, c.name AS ColumnName, CASE WHEN c.name IS NULL THEN 'no' ELSE 'yes' END AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.types AS y ON c.system_type_id = y.system_type_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Pokud tabulka obsahuje fyzický oddíl, zobrazí se hodnota HasPartition jako ano.
Použití příkazu COPY k načtení dat do Azure Synapse Analytics
Použití příkazu COPY je jednoduchý a flexibilní způsob načítání dat do Azure Synapse Analytics s vysokou propustností. Další podrobnosti získáte tak, že pomocí příkazu COPY zkontrolujete hromadná načtení dat.
- Pokud jsou zdrojová data ve službě Azure Blob nebo Azure Data Lake Storage Gen2 a formát je kompatibilní s příkazem COPY, můžete pomocí aktivity kopírování přímo vyvolat příkaz COPY, aby služba Azure Synapse Analytics načetla data ze zdroje. Podrobnosti najdete v tématu Přímé kopírování pomocí příkazu COPY.
- Pokud vaše zdrojové úložiště dat a formát není původně podporováno příkazem COPY, použijte místo toho funkci fázované kopie pomocí funkce příkazu COPY. Funkce fázovaného kopírování také poskytuje lepší propustnost. Automaticky převede data do formátu kompatibilního s příkazem COPY, uloží data do úložiště objektů blob v Azure a pak zavolá příkaz COPY, který načte data do Azure Synapse Analytics.
Tip
Při použití příkazu COPY se službou Azure Integration Runtime je efektivní jednotky Integrace Dat (DIU) vždy 2. Ladění DIU nemá vliv na výkon, protože načítání dat z úložiště využívá modul Azure Synapse.
Přímé kopírování pomocí příkazu COPY
Příkaz COPY služby Azure Synapse Analytics přímo podporuje Azure Blob, Azure Data Lake Storage Gen1 a Azure Data Lake Storage Gen2. Pokud zdrojová data splňují kritéria popsaná v této části, zkopírujte příkaz COPY přímo ze zdrojového úložiště dat do Azure Synapse Analytics. V opačném případě použijte fázovanou kopii pomocí příkazu COPY. služba zkontroluje nastavení a nezdaří spuštění aktivity kopírování, pokud kritéria nejsou splněna.
Zdrojová propojená služba a formát mají následující typy a metody ověřování:
Podporovaný typ zdrojového úložiště dat Podporovaný formát Podporovaný typ ověřování zdroje Azure Blob Text s oddělovači Ověřování pomocí klíče účtu, ověřování pomocí sdíleného přístupového podpisu, ověřování instančního objektu, ověřování spravované identity přiřazené systémem Parketové Ověřování pomocí klíče účtu, ověřování pomocí sdíleného přístupového podpisu ORC Ověřování pomocí klíče účtu, ověřování pomocí sdíleného přístupového podpisu Azure Data Lake Storage Gen2 Text s oddělovači
Parketové
ORCOvěřování pomocí klíče účtu, ověřování instančního objektu, ověřování spravované identity přiřazené systémem Důležité
- Pokud pro propojenou službu úložiště používáte ověřování spravované identity, seznamte se s potřebnými konfiguracemi pro Azure Blob a Azure Data Lake Storage Gen2 .
- Pokud je služba Azure Storage nakonfigurovaná s koncovým bodem služby virtuální sítě, musíte pro účet úložiště použít ověřování spravované identity s povolenou možností Povolit důvěryhodnou službu Microsoftu, projděte si dopad používání koncových bodů služeb virtuální sítě s úložištěm Azure.
Nastavení formátu jsou následující:
- Pro Parquet:
compressionnesmí být komprese, Snappy neboGZip. - Pro ORC:
compressionnemůže být žádná komprese,zlibnebo Snappy. - Text s oddělovači:
rowDelimiterje explicitně nastaven jako jeden znak nebo \r\n, výchozí hodnota není podporována.nullValueje ponechán jako výchozí nebo je nastaven na prázdný řetězec ("").encodingNameje ve výchozím nastavení nebo nastaven na utf-8 nebo utf-16.escapeCharmusí být stejný jakoquoteChara není prázdný.skipLineCountje ponechán jako výchozí nebo je nastaven na hodnotu 0.compressionnemůže být žádná komprese neboGZip.
- Pro Parquet:
Pokud je zdrojem složka,
recursivemusí být aktivita kopírování nastavena na true awildcardFilenamemusí být*nebo*.*.wildcardFolderPath,wildcardFilename(jiné než*nebo*.*),modifiedDateTimeStart,modifiedDateTimeEnd,prefixenablePartitionDiscoveryaadditionalColumnsnejsou zadány.
V aktivitě kopírování se podporují allowCopyCommand následující nastavení příkazu COPY:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| defaultValues | Určuje výchozí hodnoty pro každý cílový sloupec ve službě Azure Synapse Analytics. Výchozí hodnoty ve vlastnosti přepíší omezení DEFAULT nastavené v datovém skladu a sloupec identity nemůže mít výchozí hodnotu. | No |
| additionalOptions | Další možnosti, které se předají do příkazu COPY služby Azure Synapse Analytics přímo v klauzuli With v příkazu COPY. Podle potřeby uvozujte hodnotu tak, aby odpovídala požadavkům příkazu COPY. | No |
"activities":[
{
"name": "CopyFromAzureBlobToSQLDataWarehouseViaCOPY",
"type": "Copy",
"inputs": [
{
"referenceName": "ParquetDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "ParquetSource",
"storeSettings":{
"type": "AzureBlobStorageReadSettings",
"recursive": true
}
},
"sink": {
"type": "SqlDWSink",
"allowCopyCommand": true,
"copyCommandSettings": {
"defaultValues": [
{
"columnName": "col_string",
"defaultValue": "DefaultStringValue"
}
],
"additionalOptions": {
"MAXERRORS": "10000",
"DATEFORMAT": "'ymd'"
}
}
},
"enableSkipIncompatibleRow": true
}
}
]
Fázované kopírování pomocí příkazu COPY
Pokud zdrojová data nejsou nativně kompatibilní s příkazem COPY, povolte kopírování dat prostřednictvím dočasného přípravného objektu blob Azure nebo Azure Data Lake Storage Gen2 (nejde o Azure Premium Storage). V takovém případě služba automaticky převede data tak, aby splňovala požadavky na formát dat příkazu COPY. Potom vyvolá příkaz COPY, který načte data do Azure Synapse Analytics. Nakonec vyčistí dočasná data z úložiště. Podrobnosti o kopírování dat prostřednictvím přípravného procesu najdete v části Fázovaná kopie .
Pokud chcete tuto funkci použít, vytvořte propojenou službu Azure Blob Storage nebo propojenou službu Azure Data Lake Storage Gen2 s klíčem účtu nebo ověřováním identit spravovanou systémem, která odkazuje na účet úložiště Azure jako dočasné úložiště.
Důležité
- Pokud pro svoji přípravnou propojenou službu používáte ověřování spravovaných identit, seznamte se s potřebnými konfiguracemi pro Azure Blob a Azure Data Lake Storage Gen2 . Ve svém pracovním účtu Azure Blob Storage nebo Azure Data Lake Storage Gen2 musíte také udělit oprávnění ke spravované identitě pracovního prostoru Azure Synapse Analytics. Informace o udělení tohoto oprávnění najdete v tématu Udělení oprávnění spravované identitě pracovního prostoru.
- Pokud je vaše přípravná služba Azure Storage nakonfigurovaná s koncovým bodem služby virtuální sítě, musíte pro účet úložiště použít ověřování spravované identity s povolenou možností Povolit důvěryhodnou službu Microsoftu, projděte si dopad používání koncových bodů služeb virtuální sítě s úložištěm Azure.
Důležité
Pokud je vaše přípravná služba Azure Storage nakonfigurovaná se spravovaným privátním koncovým bodem a má povolenou bránu firewall úložiště, musíte použít ověřování spravované identity a udělit službě Synapse SQL Server oprávnění čtenáře dat objektů blob služby Storage, aby se zajistilo, že bude mít přístup k fázovaným souborům během načítání příkazu COPY.
"activities":[
{
"name": "CopyFromSQLServerToSQLDataWarehouseViaCOPYstatement",
"type": "Copy",
"inputs": [
{
"referenceName": "SQLServerDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
},
"sink": {
"type": "SqlDWSink",
"allowCopyCommand": true
},
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
}
}
}
}
]
Načtení dat do Azure Synapse Analytics pomocí PolyBase
Použití PolyBase představuje efektivní způsob načtení velkého množství dat do Azure Synapse Analytics s vysokou propustností. Místo výchozího mechanismu BULKINSERT uvidíte velké zvýšení propustnosti pomocí PolyBase.
- Pokud jsou zdrojová data v Azure Blob, Azure Data Lake Storage Gen1 nebo Azure Data Lake Storage Gen2 a formát je kompatibilní s PolyBase, můžete pomocí aktivity kopírování přímo vyvolat PolyBase, aby služba Azure Synapse Analytics načetla data ze zdroje. Podrobnosti najdete v tématu Přímé kopírování pomocí PolyBase.
- Pokud polyBase původně nepodporuje vaše zdrojové úložiště a formát dat, použijte místo toho fázovanou kopii pomocí funkce PolyBase . Funkce fázovaného kopírování také poskytuje lepší propustnost. Automaticky převede data do formátu kompatibilního s PolyBase, uloží je do úložiště objektů blob v Azure a pak zavolá PolyBase, aby načetla data do Azure Synapse Analytics.
Tip
Přečtěte si další informace o osvědčených postupech pro používání PolyBase. Při použití PolyBase se službou Azure Integration Runtime je efektivní Integrace Dat jednotky (DIU) pro přímé nebo fázované úložiště do Synapse vždy 2. Ladění DIU nemá vliv na výkon, protože načítání dat z úložiště využívá modul Synapse.
V aktivitě kopírování se podporují polyBaseSettings následující nastavení PolyBase:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| rejectValue | Určuje počet nebo procento řádků, které lze odmítnout před selháním dotazu. Další informace o možnostech zamítnutí PolyBase najdete v části Argumenty create EXTERNAL TABLE (Transact-SQL). Povolené hodnoty jsou 0 (výchozí), 1, 2 atd. |
No |
| rejectType | Určuje, zda je možnost rejectValue hodnota literálu nebo procento. Povolené hodnoty jsou Hodnota (výchozí) a Procento. |
No |
| rejectSampleValue | Určuje počet řádků, které se mají načíst, než PolyBase přepočítá procento odmítnutých řádků. Povolené hodnoty jsou 1, 2 atd. |
Ano, pokud je typ rejectType procento. |
| useTypeDefault | Určuje, jak zpracovat chybějící hodnoty v textových souborech s oddělovači, když PolyBase načte data z textového souboru. Další informace o této vlastnosti najdete v části Argumenty ve formátu CREATE EXTERNAL FILE FORMAT (Transact-SQL). Povolené hodnoty jsou True a False (výchozí). |
No |
Přímé kopírování pomocí PolyBase
Azure Synapse Analytics PolyBase přímo podporuje Azure Blob, Azure Data Lake Storage Gen1 a Azure Data Lake Storage Gen2. Pokud zdrojová data splňují kritéria popsaná v této části, zkopírujte PolyBase přímo ze zdrojového úložiště dat do Azure Synapse Analytics. V opačném případě použijte fázovanou kopii pomocí PolyBase.
Tip
Pokud chcete data efektivně kopírovat do Azure Synapse Analytics, přečtěte si další informace o službě Azure Data Factory, díky čemuž je ještě jednodušší a pohodlnější odhalit poznatky z dat při použití Služby Data Lake Store s Azure Synapse Analytics.
Pokud požadavky nejsou splněné, služba zkontroluje nastavení a automaticky se vrátí do mechanismu BULKINSERT pro přesun dat.
Zdrojová propojená služba má následující typy a metody ověřování:
Podporovaný typ zdrojového úložiště dat Podporovaný typ ověřování zdroje Azure Blob Ověřování pomocí klíče účtu, ověřování spravované identity přiřazené systémem Azure Data Lake Storage Gen1 Ověřování instančního objektu Azure Data Lake Storage Gen2 Ověřování pomocí klíče účtu, ověřování spravované identity přiřazené systémem Důležité
- Pokud pro propojenou službu úložiště používáte ověřování spravované identity, seznamte se s potřebnými konfiguracemi pro Azure Blob a Azure Data Lake Storage Gen2 .
- Pokud je služba Azure Storage nakonfigurovaná s koncovým bodem služby virtuální sítě, musíte pro účet úložiště použít ověřování spravované identity s povolenou možností Povolit důvěryhodnou službu Microsoftu, projděte si dopad používání koncových bodů služeb virtuální sítě s úložištěm Azure.
Formát zdrojových dat je parquet, ORC nebo text s oddělovači s následujícími konfiguracemi:
- Cesta ke složce neobsahuje filtr zástupných znaků.
- Název souboru je prázdný nebo odkazuje na jeden soubor. Pokud v aktivitě kopírování zadáte název souboru se zástupným znakem, může to být
*pouze nebo*.*. rowDelimiterje výchozí, \n, \r\n nebo \r.nullValueje ponechána jako výchozí nebo nastavena na prázdný řetězec (""), atreatEmptyAsNullje ponechána jako výchozí nebo nastavena na hodnotu true.encodingNameje ve výchozím nastavení nebo nastaven na utf-8.quoteChar,escapeCharaskipLineCountnejsou zadány. PolyBase podporuje přeskočení řádku záhlaví, který lze nakonfigurovat jakofirstRowAsHeader.compressionnesmí být komprese,GZipani Deflate.
Pokud je zdrojem složka,
recursivemusí být v aktivitě kopírování nastavena hodnota true.wildcardFolderPath,wildcardFilename,modifiedDateTimeStart,modifiedDateTimeEnd,prefix,enablePartitionDiscovery, aadditionalColumnsnejsou zadány.
Poznámka:
Pokud je zdrojem složka, všimněte si, že PolyBase načte soubory ze složky a všech jejích podsložek a nenačítá data ze souborů, pro které název souboru začíná podtržením (_) nebo tečkou (.), jak je uvedeno zde – argument LOCATION.
"activities":[
{
"name": "CopyFromAzureBlobToSQLDataWarehouseViaPolyBase",
"type": "Copy",
"inputs": [
{
"referenceName": "ParquetDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "ParquetSource",
"storeSettings":{
"type": "AzureBlobStorageReadSettings",
"recursive": true
}
},
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true
}
}
}
]
Fázované kopírování pomocí PolyBase
Pokud zdrojová data nejsou nativně kompatibilní s PolyBase, povolte kopírování dat prostřednictvím dočasného přípravného objektu blob Azure nebo Azure Data Lake Storage Gen2 (nejde o Azure Premium Storage). V tomto případě služba automaticky převede data tak, aby splňovala požadavky na formát dat PolyBase. Potom vyvolá PolyBase, aby načetla data do Azure Synapse Analytics. Nakonec vyčistí dočasná data z úložiště. Podrobnosti o kopírování dat prostřednictvím přípravného procesu najdete v části Fázovaná kopie .
Pokud chcete tuto funkci použít, vytvořte propojenou službu Azure Blob Storage nebo propojenou službu Azure Data Lake Storage Gen2 s klíčem účtu nebo ověřováním spravované identity, které odkazuje na účet úložiště Azure jako dočasné úložiště.
Důležité
- Pokud pro svoji přípravnou propojenou službu používáte ověřování spravovaných identit, seznamte se s potřebnými konfiguracemi pro Azure Blob a Azure Data Lake Storage Gen2 . Ve svém pracovním účtu Azure Blob Storage nebo Azure Data Lake Storage Gen2 musíte také udělit oprávnění ke spravované identitě pracovního prostoru Azure Synapse Analytics. Informace o udělení tohoto oprávnění najdete v tématu Udělení oprávnění spravované identitě pracovního prostoru.
- Pokud je vaše přípravná služba Azure Storage nakonfigurovaná s koncovým bodem služby virtuální sítě, musíte pro účet úložiště použít ověřování spravované identity s povolenou možností Povolit důvěryhodnou službu Microsoftu, projděte si dopad používání koncových bodů služeb virtuální sítě s úložištěm Azure.
Důležité
Pokud je vaše přípravná služba Azure Storage nakonfigurovaná se spravovaným privátním koncovým bodem a má povolenou bránu firewall úložiště, musíte použít ověřování spravované identity a udělit službě Synapse SQL Server oprávnění čtenáře dat objektů blob služby Storage, aby se zajistilo, že bude mít přístup k fázovaným souborům během načítání PolyBase.
"activities":[
{
"name": "CopyFromSQLServerToSQLDataWarehouseViaPolyBase",
"type": "Copy",
"inputs": [
{
"referenceName": "SQLServerDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
},
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
}
}
}
}
]
Osvědčené postupy pro používání PolyBase
Následující části obsahují kromě těchto postupů také osvědčené postupy uvedené v osvědčených postupech pro Azure Synapse Analytics.
Požadované oprávnění k databázi
Pokud chcete použít PolyBase, musí mít uživatel, který načítá data do Azure Synapse Analytics , oprávnění CONTROL pro cílovou databázi. Jedním ze způsobů, jak toho dosáhnout, je přidat uživatele jako člena db_owner role. Zjistěte, jak to udělat v přehledu Azure Synapse Analytics.
Omezení velikosti řádků a datového typu
Načtení PolyBase je omezené na řádky menší než 1 MB. Nedá se použít k načtení do VARCHR(MAX), NVARCHAR(MAX) nebo VARBINARY(MAX). Další informace najdete v tématu Omezení kapacity služby Azure Synapse Analytics.
Pokud zdrojová data mají řádky větší než 1 MB, můžete zdrojové tabulky svisle rozdělit na několik malých. Ujistěte se, že největší velikost každého řádku nepřekračuje limit. Menší tabulky je pak možné načíst pomocí PolyBase a sloučit je v Azure Synapse Analytics.
Pro data s těmito širokými sloupci můžete data načíst pomocí jiného typu než PolyBase vypnutím nastavení povolit PolyBase.
Třída prostředků Azure Synapse Analytics
Pokud chcete dosáhnout co nejlepší propustnosti, přiřaďte uživateli větší třídu prostředků, která načítá data do Azure Synapse Analytics prostřednictvím PolyBase.
Řešení potíží s PolyBase
Načítání do desetinného sloupce
Pokud jsou zdrojová data v textovém formátu nebo jiných úložištích kompatibilních s PolyBase (pomocí fázované kopie a PolyBase) a obsahuje prázdnou hodnotu, která se má načíst do sloupce Desetinné číslo Služby Synapse Analytics, může se zobrazit následující chyba:
ErrorCode=FailedDbOperation, ......HadoopSqlException: Error converting data type VARCHAR to DECIMAL.....Detailed Message=Empty string can't be converted to DECIMAL.....
Řešením je zrušit výběr možnosti Použít výchozí typ (jako false) v jímce aktivity kopírování –> nastavení PolyBase. "USE_TYPE_DEFAULT" je nativní konfigurace PolyBase, která určuje, jak zpracovat chybějící hodnoty v textových souborech s oddělovači, když PolyBase načte data z textového souboru.
Kontrola vlastnosti tableName ve službě Azure Synapse Analytics
Následující tabulka uvádí příklady, jak zadat vlastnost tableName v datové sadě JSON. Zobrazuje několik kombinací názvů schémat a tabulek.
| Schéma databáze | Název tabulky | tableName JSON – vlastnost |
|---|---|---|
| dbo | MyTable | Tabulka nebo dbo. MyTable nebo [dbo]. [Moje tabulka] |
| dbo1 | MyTable | dbo1. MyTable nebo [dbo1]. [Moje tabulka] |
| dbo | My.Table | [My.Table] nebo [dbo]. [My.Table] |
| dbo1 | My.Table | [dbo1]. [My.Table] |
Pokud se zobrazí následující chyba, může být problém hodnota, kterou jste zadali pro vlastnost tableName . Správný způsob zadání hodnot pro vlastnost tableName JSON najdete v předchozí tabulce.
Type=System.Data.SqlClient.SqlException,Message=Invalid object name 'stg.Account_test'.,Source=.Net SqlClient Data Provider
Sloupce s výchozími hodnotami
Funkce PolyBase v současné době přijímá pouze stejný počet sloupců jako v cílové tabulce. Příkladem je tabulka se čtyřmi sloupci, kde je jedna z nich definována s výchozí hodnotou. Vstupní data musí mít stále čtyři sloupce. Vstupní datová sada se třemi sloupci přináší chybu podobnou následující zprávě:
All columns of the table must be specified in the INSERT BULK statement.
Hodnota NULL je speciální forma výchozí hodnoty. Pokud má sloupec hodnotu null, můžou být vstupní data v objektu blob pro tento sloupec prázdná. Ve vstupní datové sadě ale nemůže chybět. PolyBase vloží hodnotu NULL pro chybějící hodnoty ve službě Azure Synapse Analytics.
Přístup k externímu souboru se nezdařil.
Pokud se zobrazí následující chyba, ujistěte se, že používáte ověřování spravované identity a udělili oprávnění čtenáře dat objektů blob služby Storage spravované identitě pracovního prostoru Azure Synapse.
Job failed due to reason: at Sink '[SinkName]': shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: External file access failed due to internal error: 'Error occurred while accessing HDFS: Java exception raised on call to HdfsBridge_IsDirExist. Java exception message:\r\nHdfsBridge::isDirExist
Další informace najdete v tématu Udělení oprávnění spravované identitě po vytvoření pracovního prostoru.
Mapování vlastností toku dat
Při transformaci dat při mapování toku dat můžete číst a zapisovat do tabulek z Azure Synapse Analytics. Další informace najdete v tématu transformace zdroje a transformace jímky v mapování toků dat.
Transformace zdroje
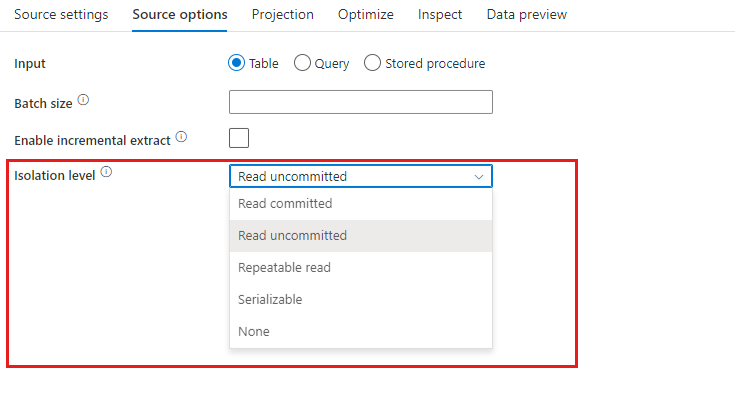
Nastavení specifické pro Azure Synapse Analytics jsou k dispozici v Karta Možnosti zdroje transformace zdroje
Vstup Vyberte, jestli zdroj nasměrujete na tabulku (ekvivalent ) Select * from <table-name>nebo zadáte vlastní dotaz SQL.
Povolit přípravu důrazně doporučujeme použít tuto možnost v produkčních úlohách se zdroji Azure Synapse Analytics. Když spustíte aktivitu toku dat se zdroji Azure Synapse Analytics z kanálu, zobrazí se výzva k zadání pracovního účtu úložiště umístění a použije se k načítání fázovaných dat. Jedná se o nejrychlejší mechanismus načítání dat z Azure Synapse Analytics.
- Pokud pro propojenou službu úložiště používáte ověřování spravované identity, seznamte se s potřebnými konfiguracemi pro Azure Blob a Azure Data Lake Storage Gen2 .
- Pokud je služba Azure Storage nakonfigurovaná s koncovým bodem služby virtuální sítě, musíte pro účet úložiště použít ověřování spravované identity s povolenou možností Povolit důvěryhodnou službu Microsoftu, projděte si dopad používání koncových bodů služeb virtuální sítě s úložištěm Azure.
- Pokud jako zdroj použijete bezserverový fond SQL Azure Synapse, povolení přípravy se nepodporuje.
Dotaz: Pokud ve vstupním poli vyberete Dotaz, zadejte dotaz SQL pro zdroj. Toto nastavení přepíše všechny tabulky, které jste zvolili v datové sadě. Klauzule Order By se tady nepodporují, ale můžete nastavit úplný příkaz SELECT FROM. Můžete také použít uživatelem definované funkce tabulek. select * from udfGetData() je UDF v SQL, který vrací tabulku. Tento dotaz vytvoří zdrojovou tabulku, kterou můžete použít ve svém toku dat. Použitídotazůch
Příklad SQL: Select * from MyTable where customerId > 1000 and customerId < 2000
Velikost dávky: Zadejte velikost dávky pro rozdělení velkých dat do čtení. V tocích dat se toto nastavení použije k nastavení sloupcového ukládání do mezipaměti Sparku. Toto je pole možnosti, které použije výchozí hodnoty Sparku, pokud zůstane prázdné.
Úroveň izolace: Výchozí hodnota pro zdroje SQL v mapování toku dat je nepotvrzená. Úroveň izolace můžete změnit tady na jednu z těchto hodnot:
- Přečteno potvrzeno
- Nepotvrzené čtení
- Opakovatelné čtení
- Serializovatelný
- Žádné (ignorovat úroveň izolace)
Transformace jímky
Nastavení specifické pro Azure Synapse Analytics jsou k dispozici na kartě Nastavení transformace jímky.
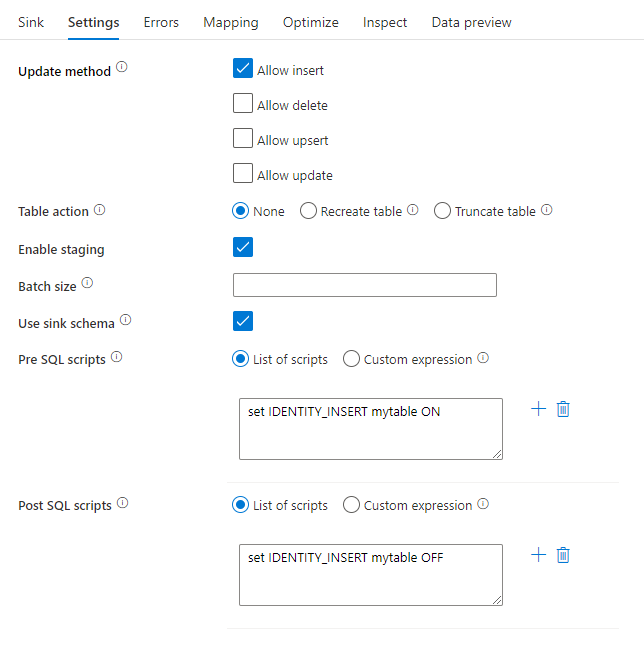
Metoda aktualizace: Určuje, jaké operace jsou povoleny v cíli databáze. Výchozí hodnota je povolit pouze vkládání. Pokud chcete aktualizovat, upsertovat nebo odstranit řádky, je pro tyto akce potřeba transformace alter-row. Pro aktualizace, upserty a odstranění je nutné nastavit klíčový sloupec nebo sloupce, aby bylo možné určit, který řádek se má změnit.
Akce tabulky: Určuje, zda se mají před zápisem znovu vytvořit nebo odebrat všechny řádky z cílové tabulky.
- Žádné: V tabulce se neprovede žádná akce.
- Znovu vytvořte: Tabulka se přehodí a znovu vytvoří. Vyžaduje se při dynamickém vytváření nové tabulky.
- Zkrácení: Odeberou se všechny řádky z cílové tabulky.
Povolit přípravu: To umožňuje načítání do fondů SQL služby Azure Synapse Analytics pomocí příkazu kopírování a doporučuje se pro většinu jímek Synapse. Přípravné úložiště je nakonfigurované v aktivitě Execute Tok dat.
- Pokud pro propojenou službu úložiště používáte ověřování spravované identity, seznamte se s potřebnými konfiguracemi pro Azure Blob a Azure Data Lake Storage Gen2 .
- Pokud je služba Azure Storage nakonfigurovaná s koncovým bodem služby virtuální sítě, musíte pro účet úložiště použít ověřování spravované identity s povolenou možností Povolit důvěryhodnou službu Microsoftu, projděte si dopad používání koncových bodů služeb virtuální sítě s úložištěm Azure.
Velikost dávky: Určuje, kolik řádků se zapisuje v každém kontejneru. Větší velikosti dávek zlepšují kompresi a optimalizaci paměti, ale při ukládání dat do mezipaměti riskují výjimky z paměti.
Použít schéma jímky: Ve výchozím nastavení se ve schématu jímky vytvoří dočasná tabulka jako pracovní. Alternativně můžete zrušit zaškrtnutí možnosti Použít schéma jímky a místo toho ve schématu Vybrat uživatelskou databázi zadat název schématu, pod kterým Služba Data Factory vytvoří pracovní tabulku pro načtení nadřazených dat a automaticky je po dokončení vyčistí. Ujistěte se, že máte v databázi oprávnění k vytvoření tabulky, a upravte oprávnění ke schématu.

Skripty předběžného a post SQL: Zadejte víceřádkové skripty SQL, které se spustí před (předběžné zpracování) a po (po zpracování) zapisují do databáze jímky.
Tip
- Doporučujeme rozdělit jednotlivé dávkové skripty několika příkazy do několika dávek.
- Jako součást dávky je možné spustit pouze příkazy DDL (Data Definition Language) a DML (Data Manipulation Language), které vracejí jednoduchý počet aktualizací. Další informace o provádění dávkových operací
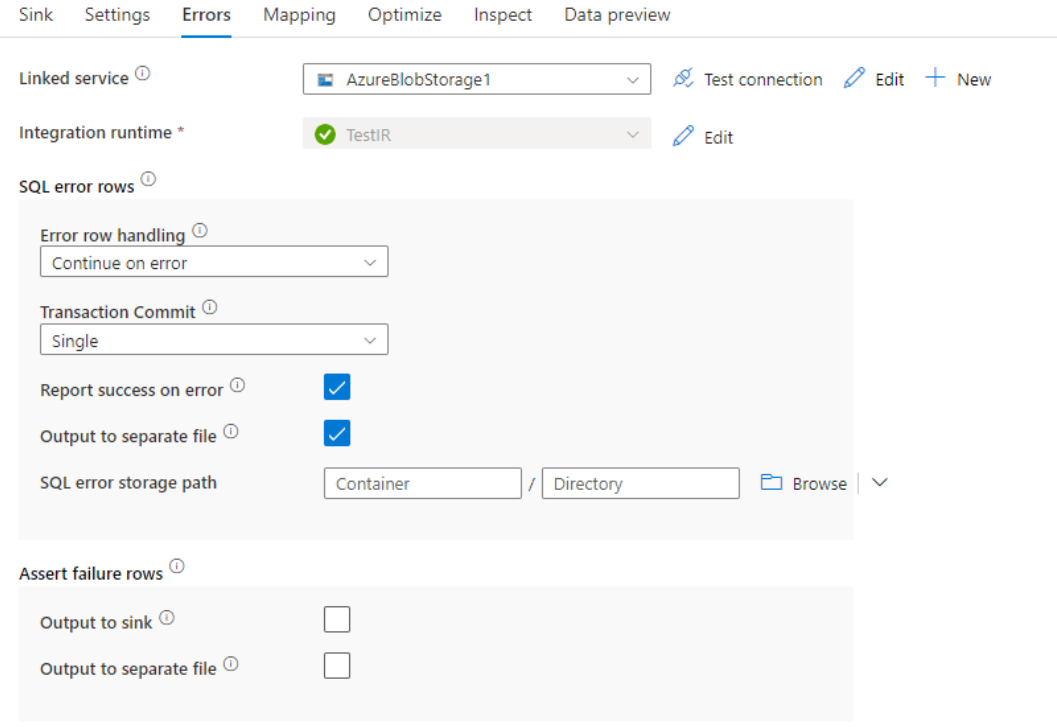
Zpracování chybového řádku
Při zápisu do služby Azure Synapse Analytics může dojít k selhání určitých řádků dat kvůli omezením nastaveným cílem. Mezi běžné chyby patří:
- Řetězcová nebo binární data by byla v tabulce zkrácena.
- Hodnotu NULL nelze vložit do sloupce.
- Převod se nezdařil při převodu hodnoty na datový typ
Spuštění toku dat ve výchozím nastavení selže při první chybě, která se zobrazí. Můžete se rozhodnout pokračovat v chybě , která umožňuje dokončení toku dat, i když mají jednotlivé řádky chyby. Služba poskytuje různé možnosti, jak tyto řádky chyb zpracovat.
Potvrzení transakce: Zvolte, zda se vaše data zapisuje do jedné transakce nebo v dávkách. Jedna transakce zajistí lepší výkon a ostatní nebudou vidět žádná zapsaná data, dokud se transakce nedokončí. Dávkové transakce mají horší výkon, ale můžou fungovat pro velké datové sady.
Odmítnutá data výstupu: Pokud je tato možnost povolená, můžete vypíšete řádky chyb do souboru CSV ve službě Azure Blob Storage nebo účtu Azure Data Lake Storage Gen2 podle vašeho výběru. Tím se zapíšou řádky chyb se třemi dalšími sloupci: operace SQL, jako je INSERT nebo UPDATE, kód chyby toku dat a chybová zpráva na řádku.
Nahlášení úspěchu při chybě: Pokud je tok dat povolený, označí se jako úspěšný i v případě, že jsou nalezeny řádky chyb.
Vlastnosti aktivity vyhledávání
Podrobnosti o vlastnostech najdete v aktivitě Vyhledávání.
Vlastnosti aktivity GetMetadata
Podrobnosti o vlastnostech najdete v aktivitě GetMetadata.
Mapování datových typů pro Azure Synapse Analytics
Když kopírujete data z Azure Synapse Analytics nebo do Služby Synapse Analytics, použijí se následující mapování z datových typů Azure Synapse Analytics do dočasných datových typů azure Data Factory. Tato mapování se také používají při kopírování dat z nebo do Azure Synapse Analytics pomocí kanálů Synapse, protože kanály také implementují Službu Azure Data Factory v rámci Azure Synapse. Podívejte se na mapování schématu a datového typu a zjistěte, jak aktivita kopírování mapuje zdrojové schéma a datový typ na jímku.
Tip
Informace o datových typech tabulky najdete v článku o podporovaných datových typech Azure Synapse Analytics ve službě Azure Synapse Analytics a alternativní řešení pro nepodporované datové typy.
| Datový typ Azure Synapse Analytics | Dočasný datový typ služby Data Factory |
|---|---|
| bigint | Int64 |
| binární | Bajt[] |
| bitové | Logická hodnota |
| char | Řetězec, znak[] |
| datum | DateTime |
| Datum a čas | DateTime |
| datetime2 | DateTime |
| Datetimeoffset | DateTimeOffset |
| Desetinné číslo | Desetinné číslo |
| ATRIBUT FILESTREAM (varbinary(max)) | Bajt[] |
| Float | Hodnota s dvojitou přesností |
| image | Bajt[] |
| int | Int32 |
| Peníze | Desetinné číslo |
| Nchar | Řetězec, znak[] |
| numerické | Desetinné číslo |
| Nvarchar | Řetězec, znak[] |
| real | Jeden |
| Rowversion | Bajt[] |
| Smalldatetime | DateTime |
| smallint | Int16 |
| Smallmoney | Desetinné číslo |
| čas | TimeSpan |
| tinyint | Byte |
| Uniqueidentifier | Guid |
| Varbinary | Bajt[] |
| varchar | Řetězec, znak[] |
Související obsah
Seznam úložišť dat podporovaných jako zdroje a jímky aktivitou kopírování najdete v podporovaných úložištích a formátech dat.