Osvědčené postupy pro konfiguraci HADR (SQL Server na virtuálních počítačích Azure)
Platí pro: ![]() SQL Server na virtuálním počítači Azure
SQL Server na virtuálním počítači Azure
Cluster s podporou převzetí služeb při selhání Windows Serveru se používá pro zajištění vysoké dostupnosti a zotavení po havárii (HADR) s SQL Serverem na virtuálních počítačích Azure.
Tento článek obsahuje osvědčené postupy konfigurace clusteru pro instance clusteru s podporou převzetí služeb při selhání i skupiny dostupnosti při jejich použití s SQL Serverem na virtuálních počítačích Azure.
Další informace najdete v dalších článcích v této sérii: kontrolní seznam, velikost virtuálního počítače, úložiště, zabezpečení, konfigurace HADR, shromažďování standardních hodnot.
Kontrolní seznam
V následujícím kontrolním seznamu najdete stručný přehled osvědčených postupů HADR, které zbývající část článku podrobněji popisuje.
Funkce vysoké dostupnosti a zotavení po havárii (HADR), jako je skupina dostupnosti AlwaysOn a instance clusteru s podporou převzetí služeb při selhání, závisí na základní technologii clusteru s podporou převzetí služeb při selhání Windows Serveru. Projděte si osvědčené postupy pro úpravu nastavení HADR, abyste mohli lépe podporovat cloudové prostředí.
Pro váš cluster s Windows zvažte tyto osvědčené postupy:
- Nasaďte virtuální počítače s SQL Serverem do několika podsítí, kdykoli je to možné, abyste se vyhnuli závislosti na Azure Load Balanceru nebo názvu distribuované sítě (DNN) pro směrování provozu do vašeho řešení HADR.
- Změňte cluster na méně agresivní parametry, abyste se vyhnuli neočekávaným výpadkům v přechodných selháních sítě nebo údržbě platformy Azure. Další informace najdete v tématu Nastavení prezenčních signálů a prahových hodnot. Pro Windows Server 2012 a novější použijte následující doporučené hodnoty:
- SameSubnetDelay: 1 sekunda
- SameSubnetThreshold: 40 prezenčních signálů
- CrossSubnetDelay: 1 sekunda
- CrossSubnetThreshold: 40 prezenčních signálů
- Umístěte virtuální počítače do skupiny dostupnosti nebo do různých zón dostupnosti. Další informace najdete v tématu Nastavení dostupnosti virtuálního počítače.
- Použijte jednu síťovou kartu na uzel clusteru.
- Nakonfigurujte hlasování kvora clusteru tak, aby používalo 3 nebo více lichých hlasů. Nepřiřazujte hlasy do oblastí zotavení po havárii.
- Pečlivě monitorujte limity prostředků, abyste se vyhnuli neočekávaným restartováním nebo převzetí služeb při selhání kvůli omezením prostředků.
- Ujistěte se, že operační systém, ovladače a SQL Server mají nejnovější sestavení.
- Optimalizujte výkon SQL Serveru na virtuálních počítačích Azure. Další informace najdete v dalších částech tohoto článku.
- Omezte nebo rozložte úlohu, abyste se vyhnuli omezením prostředků.
- Přesuňte se na virtuální počítač nebo disk, který má vyšší limity, abyste se vyhnuli omezením.
Pro vaši skupinu dostupnosti SQL Serveru nebo instanci clusteru s podporou převzetí služeb při selhání zvažte tyto osvědčené postupy:
- Pokud dochází k častým neočekávaným selháním, postupujte podle osvědčených postupů pro výkon popsaných ve zbývající části tohoto článku.
- Pokud optimalizace výkonu virtuálního počítače s SQL Serverem nevyřeší neočekávané převzetí služeb při selhání, zvažte uvolnění monitorování pro skupinu dostupnosti nebo instanci clusteru s podporou převzetí služeb při selhání. To však nemusí řešit základní zdroj problému a mohl by maskovat příznaky snížením pravděpodobnosti selhání. Možná budete muset prozkoumat a vyřešit původní příčinu. Pro Windows Server 2012 nebo novější použijte následující doporučené hodnoty:
- Časový limit zapůjčení: Tuto rovnici použijte k výpočtu maximální hodnoty časového limitu zapůjčení:
Lease timeout < (2 * SameSubnetThreshold * SameSubnetDelay).
Začněte 40 sekundami. Pokud používáte uvolněnéSameSubnetThresholdhodnoty aSameSubnetDelayhodnoty doporučené dříve, nepřesáhejte pro hodnotu časového limitu zapůjčení 80 sekund. - Maximální počet selhání v zadaném období: Nastavte tuto hodnotu na hodnotu 6.
- Časový limit zapůjčení: Tuto rovnici použijte k výpočtu maximální hodnoty časového limitu zapůjčení:
- Při použití názvu virtuální sítě (VNN) a Azure Load Balanceru pro připojení k řešení HADR zadejte
MultiSubnetFailover = truev připojovací řetězec, i když váš cluster pokrývá pouze jednu podsíť.- Pokud klient nepodporuje
MultiSubnetFailover = True, možná budete muset nastavitRegisterAllProvidersIP = 0aHostRecordTTL = 300uložit přihlašovací údaje klienta do mezipaměti po kratší dobu. To ale může způsobit další dotazy na server DNS.
- Pokud klient nepodporuje
- Pokud se chcete připojit k řešení HADR pomocí názvu distribuované sítě (DNN), zvažte následující:
- Musíte použít klientský ovladač, který podporuje
MultiSubnetFailover = True, a tento parametr musí být v připojovací řetězec. - Při připojování k naslouchacímu procesu DNN pro skupinu dostupnosti použijte jedinečný port DNN v připojovací řetězec.
- Musíte použít klientský ovladač, který podporuje
- Zrcadlení databáze připojovací řetězec pro základní skupinu dostupnosti použijte k obejití potřeby nástroje pro vyrovnávání zatížení nebo sítě DNN.
- Před nasazením řešení s vysokou dostupností ověřte velikost sektoru virtuálních pevných disků, abyste se vyhnuli nesprávnému zarovnání vstupně-výstupních operací. Další informace najdete v KB3009974 .
- Pokud je databázový stroj SQL Serveru, naslouchací proces skupiny dostupnosti AlwaysOn nebo sonda stavu instance clusteru s podporou převzetí služeb při selhání nakonfigurovaná tak, aby používala port mezi 49 152 a 65 536 ( výchozí dynamický rozsah portů pro tcp/IP), přidejte pro každý port vyloučení. Tím zabráníte dynamickému přiřazování stejného portu jiným systémům. Následující příklad vytvoří vyloučení pro port 59999:
netsh int ipv4 add excludedportrange tcp startport=59999 numberofports=1 store=persistent
Pokud chcete porovnat kontrolní seznam HADR s dalšími osvědčenými postupy, podívejte se na úplný kontrolní seznam osvědčených postupů pro výkon.
Nastavení dostupnosti virtuálního počítače
Pokud chcete snížit dopad výpadků, zvažte následující nastavení nejlepší dostupnosti virtuálního počítače:
- Používejte skupiny umístění bezkontaktní komunikace společně s akcelerovanými síťovými službami pro nejnižší latenci.
- Umístěte uzly clusteru virtuálních počítačů do samostatných zón dostupnosti, aby se chránily před selháním na úrovni datacentra nebo v jedné skupině dostupnosti pro zajištění redundance s nižší latencí v rámci stejného datacentra.
- Pro virtuální počítače ve skupině dostupnosti používejte disky s operačním systémem a datovými disky spravovanými premium.
- Nakonfigurujte každou aplikační vrstvu do samostatných skupin dostupnosti.
Kvorum
I když cluster se dvěma uzly funguje bez prostředku kvora, zákazníci musí výhradně použít prostředek kvora, aby měli podporu produkčního prostředí. Ověření clusteru nepředává žádný cluster bez prostředku kvora.
Z technického hlediska může cluster se třemi uzly přežít ztrátu jednoho uzlu (až dva uzly) bez prostředku kvora, ale po výpadku clusteru na dva uzly, pokud dojde ke ztrátě nebo selhání komunikace jiného uzlu, znamená to, že clusterované prostředky přejdou do režimu offline, aby se zabránilo rozdělenému scénáři mozku. Konfigurace prostředku kvora umožňuje clusteru pokračovat online pouze s jedním uzlem online.
Disk s kopií clusteru je nejodolnější možností kvora, ale pokud chcete použít určující disk na SQL Serveru na virtuálním počítači Azure, musíte použít sdílený disk Azure, který má určitá omezení pro řešení s vysokou dostupností. Pokud například konfigurujete instanci clusteru s podporou převzetí služeb při selhání se sdílenými disky Azure, použijte disk s kopií clusteru, jinak použijte cloudovou kopii clusteru, kdykoli je to možné.
Následující tabulka uvádí možnosti kvora dostupné pro SQL Server na virtuálních počítačích Azure:
| Určující cloud | Disk s kopií clusteru | Určující sdílená složka | |
|---|---|---|---|
| Podporovaný operační systém | Windows Server 2016+ | Vše | Vše |
- Cloudová kopie clusteru je ideální pro nasazení ve více lokalitách, více zónách a několika oblastech. Pokud nepoužíváte řešení clusteru se sdíleným úložištěm, použijte určující cloud, kdykoli je to možné.
- Disk s kopií clusteru je nejodolnější možností kvora a preferuje se pro všechny clustery, které používají sdílené disky Azure (nebo jakékoli řešení sdíleného disku, jako je sdílené rozhraní SCSI, iSCSI nebo síť SAN s vlákny). Clusterovaný sdílený svazek nejde použít jako určující disk.
- Určující sdílená složka je vhodná pro případy, kdy disk s kopií clusteru a cloudová kopie nejsou k dispozici.
Pokud chcete začít, přečtěte si téma Konfigurace kvora clusteru.
Hlasování kvora
Je možné změnit hlas kvora uzlu, který se účastní clusteru s podporou převzetí služeb při selhání Windows Serveru.
Při úpravě nastavení hlasu uzlu postupujte podle těchto pokynů:
| Pravidla hlasování kvora |
|---|
| Začněte s každým uzlem, který nemá ve výchozím nastavení žádné hlasy. Každý uzel by měl mít pouze hlas s explicitním odůvodněním. |
| Povolte hlasy pro uzly clusteru, které hostují primární repliku skupiny dostupnosti, nebo upřednostňované vlastníky instance clusteru s podporou převzetí služeb při selhání. |
| Povolte hlasy pro vlastníky automatického převzetí služeb při selhání. Každý uzel, který může být hostitelem primární repliky nebo FCI v důsledku automatického převzetí služeb při selhání, by měl mít hlas. |
| Pokud má skupina dostupnosti více než jednu sekundární repliku, povolte hlasy jenom pro repliky, které mají automatické převzetí služeb při selhání. |
| Zakažte hlasy pro uzly, které jsou v sekundárních lokalitách zotavení po havárii. Uzly v sekundárních lokalitách by neměly přispívat k rozhodnutí o offline režimu clusteru, pokud není nic špatného s primární lokalitou. |
| Máte lichý počet hlasů, minimálně tři hlasy kvora. V případě potřeby přidejte určující kopii kvora pro další hlas v clusteru se dvěma uzly. |
| Znovu posoudí přiřazení hlasů po převzetí služeb při selhání. Nechcete převzít služby při selhání do konfigurace clusteru, která nepodporuje kvorum v pořádku. |
Připojení
Pokud chcete odpovídat místnímu prostředí pro připojení k naslouchacímu procesu skupiny dostupnosti nebo instanci clusteru s podporou převzetí služeb při selhání, nasaďte virtuální počítače s SQL Serverem do několika podsítí ve stejné virtuální síti. Několik podsítí neguje potřebu další závislosti na Azure Load Balanceru nebo názvu distribuované sítě pro směrování provozu do naslouchacího procesu.
Pokud chcete zjednodušit řešení HADR, nasaďte virtuální počítače s SQL Serverem do několika podsítí, kdykoli je to možné. Další informace najdete v tématu Skupina dostupnosti s více podsítěmi a FCI s více podsítěmi.
Pokud jsou virtuální počítače s SQL Serverem v jedné podsíti, je možné nakonfigurovat název virtuální sítě (VNN) a Azure Load Balancer nebo název distribuované sítě (DNN) pro instance clusteru s podporou převzetí služeb při selhání i naslouchací procesy skupiny dostupnosti.
Název distribuované sítě je doporučenou možností připojení, pokud je k dispozici:
- Ucelené řešení je robustnější, protože už nemusíte udržovat prostředek nástroje pro vyrovnávání zatížení.
- Eliminování sond nástroje pro vyrovnávání zatížení minimalizuje dobu trvání převzetí služeb při selhání.
- Síť DNN zjednodušuje zřizování a správu instance clusteru s podporou převzetí služeb při selhání nebo naslouchacího procesu skupiny dostupnosti s SQL Serverem na virtuálních počítačích Azure.
Berte v úvahu následující omezení:
- Klientský ovladač musí parametr podporovat
MultiSubnetFailover=True. - Funkce DNN je dostupná od SQL Serveru 2016 SP3, SQL Serveru 2017 CU25 a SQL Serveru 2019 CU8 ve Windows Serveru 2016 a novějším.
Další informace najdete v přehledu clusteru s podporou převzetí služeb při selhání Windows Serveru.
Informace o konfiguraci připojení najdete v následujících článcích:
- Skupina dostupnosti: Konfigurace sítě DNN, konfigurace sítě VNN
- Instance clusteru s podporou převzetí služeb při selhání: Konfigurace sítě DNN, konfigurace sítě VNN
Většina funkcí SQL Serveru funguje transparentně s FCI a skupinami dostupnosti při používání sítě DNN, ale existují určité funkce, které mohou vyžadovat zvláštní pozornost. Další informace najdete v tématu Interoperabilita FCI a DNN a interoperabilita skupin dostupnosti a sítě DNN.
Tip
Nastavte parametr MultiSubnetFailover = true v připojovací řetězec i pro řešení HADR, která pokrývají jednu podsíť, aby podporovala budoucí pokrývání podsítí, aniž by bylo nutné aktualizovat připojovací řetězec.
Prezenčních signálů a prahových hodnot
Změňte nastavení prezenčních signálu a prahových hodnot clusteru na uvolněné nastavení. Výchozí nastavení prezenčních signálů a prahových hodnot clusteru jsou navržená pro vysoce vyladěné místní sítě a nepovažujte za možnost zvýšené latence v cloudovém prostředí. Síť prezenčních signálů se udržuje pomocí UDP 3343, což je řešení tradičně méně spolehlivé než TCP a náchylnější k neúplným konverzacím.
Proto při spouštění uzlů clusteru pro SQL Server na virtuálních počítačích Azure s vysokou dostupností změňte nastavení clusteru na uvolněnější stav monitorování, abyste se vyhnuli přechodným selháním kvůli zvýšené možnosti latence sítě nebo selhání, údržby Azure nebo dosažení kritických bodů prostředků.
Nastavení zpoždění a prahové hodnoty mají kumulativní účinek na celkovou detekci stavu. Například nastavení CrossSubnetDelay pro odeslání prezenčního signálu každých 2 sekundy a nastavení CrossSubnetThreshold na 10 zmeškaných prezenčních signálů před zahájením obnovení znamená, že cluster může mít celkovou toleranci sítě 20 sekund před provedením akce obnovení. Obecně platí, že se upřednostňují časté prezenčních signály, ale mají vyšší prahové hodnoty.
Pokud chcete zajistit obnovení během legitimních výpadků a současně zajistit větší odolnost vůči přechodným problémům, uvolněte nastavení zpoždění a prahové hodnoty na doporučené hodnoty popsané v následující tabulce:
| Nastavení | Windows Server 2012 nebo novější | Windows Server 2008 R2 |
|---|---|---|
| SameSubnetDelay | 1 sekunda | 2 sekundy |
| SameSubnetThreshold | 40 prezenčních signálů | 10 prezenčních signálů (max. |
| CrossSubnetDelay | 1 sekunda | 2 sekundy |
| CrossSubnetThreshold | 40 prezenčních signálů | 20 prezenčních signálů (max. |
Pomocí PowerShellu můžete změnit parametry clusteru:
(get-cluster).SameSubnetThreshold = 40
(get-cluster).CrossSubnetThreshold = 40
Pomocí PowerShellu ověřte změny:
get-cluster | fl *subnet*
Zvažte použití těchto zdrojů:
- Tato změna je okamžitá, restartování clusteru nebo jakýchkoli prostředků se nevyžaduje.
- Stejné hodnoty podsítě by neměly být větší než hodnoty napříč podsítěmi.
- SameSubnetThreshold <= CrossSubnetThreshold
- SameSubnetDelay <= CrossSubnetDelay
Zvolte uvolněné hodnoty na základě toho, kolik času výpadku je tolerovatelné a jak dlouho by se mělo provést nápravná akce v závislosti na vaší aplikaci, obchodních potřebách a vašem prostředí. Pokud nemůžete překročit výchozí hodnoty Windows Serveru 2019, zkuste je alespoň spárovat, pokud je to možné:
Následující tabulka obsahuje podrobnosti o výchozích hodnotách:
| Nastavení | Windows Server 2019 | Windows Server 2016 | Windows Server 2008 – 2012 R2 |
|---|---|---|---|
| SameSubnetDelay | 1 sekunda | 1 sekunda | 1 sekunda |
| SameSubnetThreshold | 20 prezenčních signálů | 10 prezenčních signálů | 5 prezenčních signálů |
| CrossSubnetDelay | 1 sekunda | 1 sekunda | 1 sekunda |
| CrossSubnetThreshold | 20 prezenčních signálů | 10 prezenčních signálů | 5 prezenčních signálů |
Další informace najdete v tématu Ladění prahových hodnot sítě clusteru s podporou převzetí služeb při selhání.
Uvolněné monitorování
Pokud ladění nastavení prezenčních signálů a prahových hodnot clusteru podle doporučení není dostatečná tolerance a stále dochází k převzetí služeb při selhání kvůli přechodným problémům místo skutečných výpadků, můžete nakonfigurovat monitorování skupiny dostupnosti nebo FCI tak, aby byly uvolněnější. V některých scénářích může být užitečné dočasně uvolnit monitorování po určitou dobu vzhledem k úrovni aktivity. Můžete například chtít uvolnit monitorování, když provádíte úlohy náročné na vstupně-výstupní operace, jako jsou zálohy databází, údržba indexů, DBCC CHECKDB atd. Po dokončení aktivity nastavte monitorování na méně uvolněné hodnoty.
Upozorňující
Změna těchto nastavení může zamaskovat základní problém a měla by se použít jako dočasné řešení pro snížení, nikoli odstranění pravděpodobnosti selhání. Základní problémy by měly být stále prošetřeny a vyřešeny.
Začněte zvýšením následujících parametrů z výchozích hodnot pro uvolněné monitorování a podle potřeby upravte:
| Parametr | Default value | Uvolněná hodnota | Popis |
|---|---|---|---|
| Časový limit kontroly stavu | 30000 | 60000 | Určuje stav primární repliky nebo uzlu. Knihovna DLL sp_server_diagnostics prostředků clusteru vrátí výsledky v intervalu, který se rovná 1/3 prahové hodnotě časového limitu kontroly stavu. Pokud sp_server_diagnostics je pomalé nebo nevrací informace, knihovna DLL prostředků čeká na úplný interval prahové hodnoty časového limitu kontroly stavu, než zjistí, že prostředek nereaguje, a pokud je nakonfigurované, spustí automatické převzetí služeb při selhání. |
| Úroveň podmínky selhání | 3 | 2 | Podmínky, které aktivují automatické převzetí služeb při selhání Existuje pět úrovní stavu selhání, které se liší od nejnižší omezující úrovně (úroveň 1) po nejvíce omezující (úroveň pět). |
Pomocí jazyka Transact-SQL (T-SQL) můžete upravit kontrolu stavu a podmínky selhání pro skupiny AG i FCI.
Pro skupiny dostupnosti:
ALTER AVAILABILITY GROUP AG1 SET (HEALTH_CHECK_TIMEOUT =60000);
ALTER AVAILABILITY GROUP AG1 SET (FAILURE_CONDITION_LEVEL = 2);
Pro instance clusteru s podporou převzetí služeb při selhání:
ALTER SERVER CONFIGURATION SET FAILOVER CLUSTER PROPERTY HealthCheckTimeout = 60000;
ALTER SERVER CONFIGURATION SET FAILOVER CLUSTER PROPERTY FailureConditionLevel = 2;
Specifické pro skupiny dostupnosti, začněte následujícími doporučenými parametry a podle potřeby upravte:
| Parametr | Default value | Uvolněná hodnota | Popis |
|---|---|---|---|
| Časový limit zapůjčení | 20 000 | 40000 | Zabraňuje rozdělení mozku. |
| Časový limit relace | 10000 | 20 000 | Kontroluje problémy s komunikací mezi replikami. Doba časového limitu relace je vlastnost repliky, která určuje, jak dlouho (v sekundách) replika dostupnosti čeká na odpověď ping z připojené repliky, než bude spojení považováno za neúspěšné. Ve výchozím nastavení replika čeká 10 sekund na odpověď ping. Tato vlastnost repliky se vztahuje pouze na připojení mezi danou sekundární replikou a primární replikou skupiny dostupnosti. |
| Maximální počet selhání v zadaném období | 2 | 6 | Používá se k zabránění neomezenému přesunu clusterovaného prostředku v rámci selhání více uzlů. Příliš nízká hodnota může vést ke skupině dostupnosti ve stavu selhání. Zvyšte hodnotu, abyste zabránili krátkým přerušením problémů s výkonem, protože příliš nízká hodnota může vést k tomu, že skupina dostupnosti je ve stavu selhání. |
Před provedením jakýchkoli změn zvažte následující:
- Neosílejte žádné hodnoty časového limitu pod jejich výchozími hodnotami.
- Pomocí této rovnice můžete vypočítat maximální hodnotu časového limitu zapůjčení:
Lease timeout < (2 * SameSubnetThreshold * SameSubnetDelay).
Začněte 40 sekundami. Pokud používáte uvolněnéSameSubnetThresholdhodnoty aSameSubnetDelayhodnoty doporučené dříve, nepřesáhejte pro hodnotu časového limitu zapůjčení 80 sekund. - U replik synchronního potvrzení může změna časového limitu relace na vysokou hodnotu zvýšit HADR_sync_commit čekání.
Časový limit zapůjčení
Pomocí Správce clusteru s podporou převzetí služeb při selhání můžete upravit nastavení časového limitu zapůjčení pro vaši skupinu dostupnosti. Podrobné kroky najdete v dokumentaci ke kontrole stavu zapůjčení skupiny dostupnosti SQL Serveru.
Časový limit relace
Pomocí jazyka Transact-SQL (T-SQL) upravte časový limit relace pro skupinu dostupnosti:
ALTER AVAILABILITY GROUP AG1
MODIFY REPLICA ON 'INSTANCE01' WITH (SESSION_TIMEOUT = 20);
Maximální počet selhání v zadaném období
Ke změně maximálního počtu selhání v zadané hodnotě období použijte Správce clusteru s podporou převzetí služeb při selhání:
- V navigačním podokně vyberte Role .
- V části Role klikněte pravým tlačítkem myši na clusterovaný prostředek a zvolte Vlastnosti.
- Vyberte kartu Převzetí služeb při selhání a podle potřeby zvyšte maximální počet selhání v zadané hodnotě období.
Omezení prostředků
Omezení virtuálních počítačů nebo disků mohou vést ke kritickým bodům prostředků, které ovlivňují stav clusteru, a brání kontrole stavu. Pokud máte problémy s limity prostředků, zvažte následující možnosti:
- Pomocí V/V Analysis (Preview) na webu Azure Portal identifikujte problémy s výkonem disku, které můžou způsobit převzetí služeb při selhání.
- Ujistěte se, že operační systém, ovladače a SQL Server mají nejnovější sestavení.
- Optimalizace SQL Serveru na virtuálním počítači Azure, jak je popsáno v pokynech k výkonu SQL Serveru na virtuálních počítačích Azure
- Používání
- Snižte nebo rozložte úlohy za účelem snížení využití bez překročení limitů prostředků.
- Pokud existuje nějaká příležitost, vylaďte úlohu SQL Serveru, například
- Přidejte nebo optimalizujte indexy.
- V případě potřeby aktualizujte statistiky a pokud je to možné, použijte úplnou kontrolou.
- Funkce, jako je správce prostředků (počínaje SQL Serverem 2014, jenom edice Enterprise), použijte k omezení využití prostředků během konkrétních úloh, jako jsou zálohy nebo údržba indexů.
- Přejděte na virtuální počítač nebo disk s vyššími limity, které splňují nebo překračují požadavky vaší úlohy.
Sítě
Nasaďte virtuální počítače s SQL Serverem do několika podsítí, kdykoli je to možné, abyste se vyhnuli závislosti na Azure Load Balanceru nebo názvu distribuované sítě (DNN) pro směrování provozu do vašeho řešení HADR.
Použít jednu síťovou kartu na server (uzel clusteru). Sítě Azure mají fyzickou redundanci, což v clusteru hostů virtuálního počítače Azure nepotřebuje další síťové karty. Sestava ověření clusteru vás upozorní, že uzly jsou dostupné pouze v jedné síti. Toto upozornění můžete ignorovat u clusterů s podporou převzetí služeb při selhání hosta virtuálního počítače Azure.
Omezení šířky pásma pro konkrétní virtuální počítač se sdílí mezi síťovými kartami a přidáním další síťové karty nezlepšíte výkon skupiny dostupnosti pro SQL Server na virtuálních počítačích Azure. Proto není potřeba přidat druhou síťovou kartu.
Služba DHCP kompatibilní s dokumentem RFC v Azure může způsobit selhání vytváření určitých konfigurací clusteru s podporou převzetí služeb při selhání. K této chybě dochází, protože název sítě clusteru má přiřazenou duplicitní IP adresu, například stejnou IP adresu jako jeden z uzlů clusteru. Jedná se o problém při použití skupin dostupnosti, které závisí na funkci clusteru s podporou převzetí služeb při selhání systému Windows.
Představte si scénář vytvoření clusteru se dvěma uzly a přeneste ho do režimu online:
- Cluster je online a uzel NODE1 požádá o dynamicky přiřazenou IP adresu pro název sítě clusteru.
- Služba DHCP neposkytuje žádnou IP adresu jinou než vlastní IP adresu NODE1, protože služba DHCP rozpozná, že požadavek pochází ze samotného uzlu 1.
- Systém Windows zjistí, že je duplicitní adresa přiřazená k uzlu 1 i k názvu sítě clusteru s podporou převzetí služeb při selhání a výchozí skupina clusteru se nezdaří do režimu online.
- Výchozí skupina clusteru se přesune na UZEL2. NODE2 považuje IP adresu NODE1 za IP adresu clusteru a přenese výchozí skupinu clusteru do režimu online.
- Když se node2 pokusí navázat připojení k uzlu 1, pakety směrované na NODE1 nikdy neopustí NODE2, protože přeloží IP adresu NODE1 na sebe. NODE2 nemůže navázat připojení k uzlu NODE1 a pak ztratí kvorum a vypne cluster.
- NODE1 může posílat pakety do NODE2, ale NODE2 nemůže odpovědět. UZEL1 ztratí kvorum a vypne cluster.
Tomuto scénáři se můžete vyhnout přiřazením nepoužívané statické IP adresy k názvu sítě clusteru, aby se název sítě clusteru přenesl do režimu online a přidal IP adresu do Azure Load Balanceru.
Pokud databázový stroj SQL Serveru, naslouchací proces skupiny dostupnosti AlwaysOn, sonda stavu instance clusteru s podporou převzetí služeb při selhání, koncový bod zrcadlení databáze, prostředek základní IP adresy clusteru nebo jakýkoli jiný prostředek SQL je nakonfigurovaný tak, aby používal port mezi 49 152 a 65 536 ( výchozí dynamický rozsah portů pro TCP/IP), přidejte vyloučení pro každý port. Tím zabráníte dynamickému přiřazení stejného portu jiným systémovým procesům. Následující příklad vytvoří vyloučení pro port 59999:
netsh int ipv4 add excludedportrange tcp startport=59999 numberofports=1 store=persistent
Pokud se port nepoužívá, je důležité nakonfigurovat vyloučení portů, jinak příkaz selže se zprávou typu Proces nemůže získat přístup k souboru, protože ho používá jiný proces.
Chcete-li ověřit, že vyloučení byla správně nakonfigurována, použijte následující příkaz: netsh int ipv4 show excludedportrange tcp.
Nastavení tohoto vyloučení pro port sondy ip adresy role skupiny dostupnosti by mělo bránit událostem, jako je ID události: 1069 se stavem 10048. Tuto událost lze zobrazit v událostech clusteru s podporou převzetí služeb při selhání systému Windows s následující zprávou:
Cluster resource '<IP name in AG role>' of type 'IP Address' in cluster role '<AG Name>' failed.
An Event ID: 1069 with status 10048 can be identified from cluster logs with events like:
Resource IP Address 10.0.1.0 called SetResourceStatusEx: checkpoint 5. Old state OnlinePending, new state OnlinePending, AppSpErrorCode 0, Flags 0, nores=false
IP Address <IP Address 10.0.1.0>: IpaOnlineThread: **Listening on probe port 59999** failed with status **10048**
Status [**10048**](/windows/win32/winsock/windows-sockets-error-codes-2) refers to: **This error occurs** if an application attempts to bind a socket to an **IP address/port that has already been used** for an existing socket.
Příčinou může být interní proces, který přebírá stejný port definovaný jako port sondy. Nezapomeňte, že port sondy se používá ke kontrole stavu instance back-endového fondu z Azure Load Balanceru.
Pokud sonda stavu nezískne odpověď z instance back-endu, nebudou do této back-endové instance odeslána žádná nová připojení, dokud se sonda stavu znovu nezdaří.
Známé problémy
Projděte si řešení některých běžně známých problémů a chyb.
Kolize prostředků (zejména vstupně-výstupní operace) způsobuje převzetí služeb při selhání
Vyčerpání V/V nebo kapacity procesoru virtuálního počítače může způsobit převzetí služeb při selhání vaší skupiny dostupnosti. Identifikace kolizí, ke které dochází přímo před převzetím služeb při selhání, je nejspolehlivější způsob, jak zjistit, co způsobuje automatické převzetí služeb při selhání.
Použití vstupně-výstupní analýzy
Pomocí V/V Analysis (Preview) na webu Azure Portal identifikujte problémy s výkonem disku, které můžou způsobit převzetí služeb při selhání.
Monitorování s využitím metrik vstupně-výstupních operací úložiště virtuálních počítačů
Monitorujte virtuální počítače Azure a podívejte se na metriky využití vstupně-výstupních operací úložiště, abyste porozuměli latenci na úrovni virtuálního počítače nebo disku.
Pokud chcete zkontrolovat celkovou událost vyčerpání vstupně-výstupních operací virtuálního počítače Azure, postupujte takto:
Přejděte na virtuální počítač na webu Azure Portal , ne na virtuálních počítačích SQL.
Výběrem možnosti Metriky v části Monitorování otevřete stránku Metriky .
Vyberte Místní čas a určete časový rozsah, který vás zajímá, a časové pásmo, buď místní pro virtuální počítač, nebo UTC/GMT.
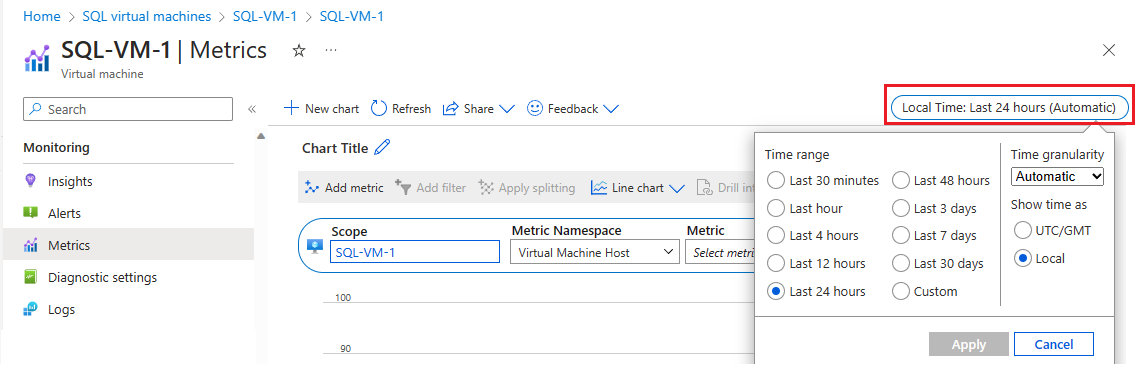
Výběrem možnosti Přidat metriku přidejte následující dvě metriky, abyste viděli graf:
- Procento spotřebované šířky pásma v mezipaměti virtuálního počítače
- Procento šířky pásma mimo mezipaměť využité virtuálním počítačem
Hostitelé virtuálních počítačů Azure způsobí převzetí služeb při selhání
Je možné, že hostEvent virtuálního počítače Azure způsobí převzetí služeb při selhání vaší skupiny dostupnosti. Pokud se domníváte, že hostEvent virtuálního počítače Azure způsobil převzetí služeb při selhání, můžete zkontrolovat protokol aktivit služby Azure Monitor a přehled služby Azure VM Resource Health.
Protokol aktivit služby Azure Monitor je protokol platformy v Azure, který poskytuje přehled o událostech na úrovni předplatného. Protokol aktivit obsahuje informace, jako je například změna prostředku nebo spuštění virtuálního počítače. Protokol aktivit můžete zobrazit na webu Azure Portal nebo načíst položky pomocí PowerShellu a Azure CLI.
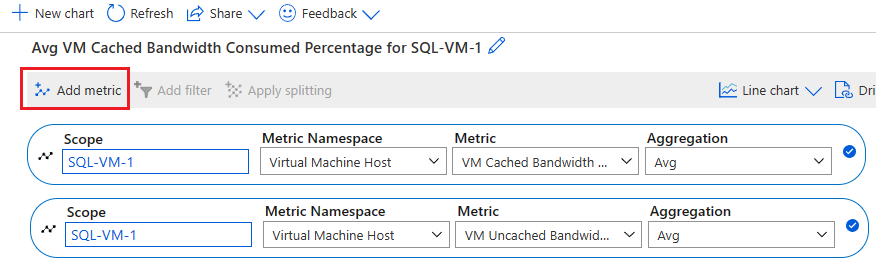
Pokud chcete zkontrolovat protokol aktivit služby Azure Monitor, postupujte takto:
Přechod na virtuální počítač na webu Azure Portal
Výběr protokolu aktivit v podokně Virtuální počítač
Vyberte Časový rozsah a pak zvolte časový rámec, kdy vaše skupina dostupnosti převzala služby při selhání. Vyberte Použít.
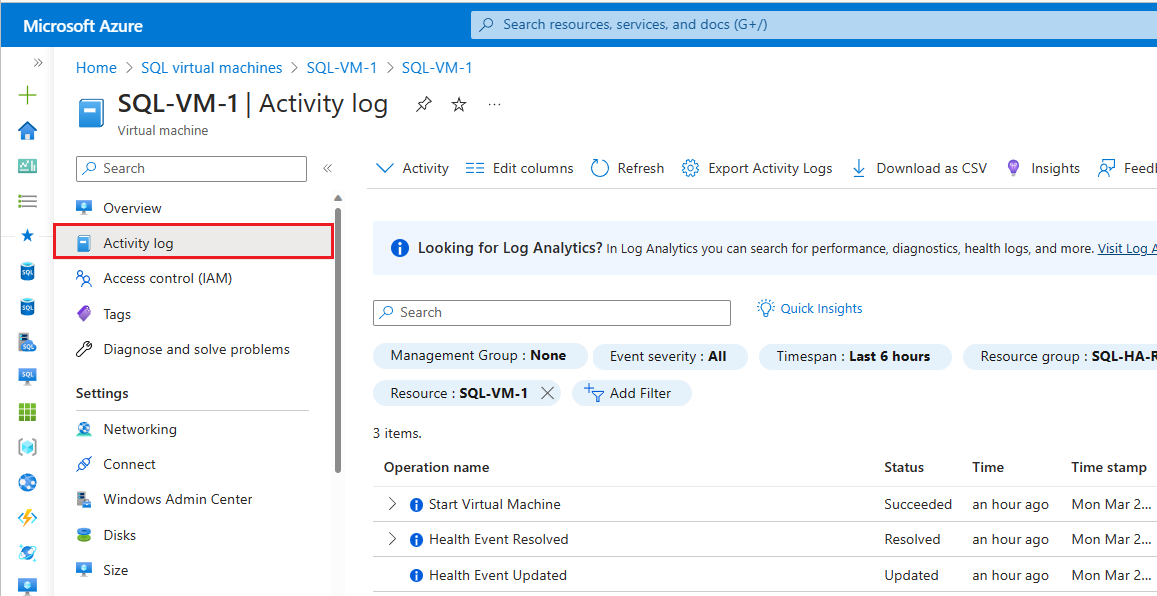
Pokud má Azure další informace o původní příčině nedostupnosti iniciované platformou, můžou se tyto informace publikovat na stránce přehledu služby Azure Resource Health až 72 hodin po počáteční nedostupnosti. Tyto informace jsou v současné době k dispozici jen pro virtuální počítače.
- Přechod na virtuální počítač na webu Azure Portal
- V podokně Stav vyberte Resource Health.
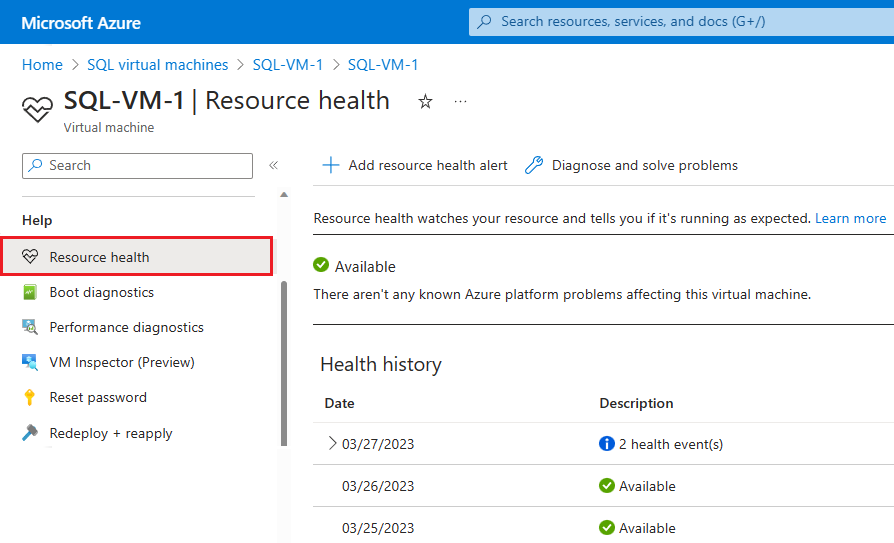
Můžete také nakonfigurovat výstrahy na základě událostí stavu z této stránky.
Uzel clusteru odebraný z členství
Pokud jsou nastavení prezenčních signálů a prahových hodnot clusteru Windows pro vaše prostředí příliš agresivní, může se v protokolu událostí systému často zobrazovat následující zpráva.
Error 1135
Cluster node 'Node1' was removed from the active failover cluster membership.
The Cluster service on this node may have stopped. This could also be due to the node having
lost communication with other active nodes in the failover cluster. Run the Validate a
Configuration Wizard to check your network configuration. If the condition persists, check
for hardware or software errors related to the network adapters on this node. Also check for
failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Další informace najdete v tématu Řešení potíží s clusterem s ID události 1135.
Platnost zapůjčení vypršela / Zapůjčení už není platné.
Pokud je monitorování pro vaše prostředí příliš agresivní, může se zobrazit časté restartování skupiny dostupnosti nebo restartování FCI, selhání nebo převzetí služeb při selhání. U skupin dostupnosti se navíc můžou v protokolu chyb SQL Serveru zobrazit následující zprávy:
Error 19407: The lease between availability group 'PRODAG' and the Windows Server Failover Cluster has expired.
A connectivity issue occurred between the instance of SQL Server and the Windows Server Failover Cluster.
To determine whether the availability group is failing over correctly, check the corresponding availability group
resource in the Windows Server Failover Cluster
Error 19419: The renewal of the lease between availability group '%.*ls' and the Windows Server Failover Cluster
failed because the existing lease is no longer valid.
Vypršení časového limitu připojení
Pokud je časový limit relace pro vaše prostředí skupiny dostupnosti příliš agresivní, můžou se často zobrazovat následující zprávy:
Error 35201: A connection timeout has occurred while attempting to establish a connection to availability
replica 'replicaname' with ID [availability_group_id]. Either a networking or firewall issue exists,
or the endpoint address provided for the replica is not the database mirroring endpoint of the host server instance.
Error 35206
A connection timeout has occurred on a previously established connection to availability
replica 'replicaname' with ID [availability_group_id]. Either a networking or a firewall issue
exists, or the availability replica has transitioned to the resolving role.
Skupina nepřebíjela služby při selhání
Pokud je maximální počet selhání v zadané hodnotě období příliš nízký a dochází k přerušovaným selháním kvůli přechodným problémům, může vaše skupina dostupnosti končit stavem selhání. Zvyšte tuto hodnotu, abyste tolerovali více přechodných selhání.
Not failing over group <Resource name>, failoverCount 3, failoverThresholdSetting <Number>, computedFailoverThreshold 2.
Událost 1196 – Prostředek názvu sítě selhal registrací přidruženého názvu DNS
- Zkontrolujte nastavení síťových karet jednotlivých uzlů clusteru a ujistěte se, že neobsahují žádné externí záznamy DNS.
- Ujistěte se, že na vašich interních serverech DNS existuje záznam A pro váš cluster. Pokud ne, vytvořte na serveru DNS ručně nový záznam A pro objekt řízení přístupu ke clusteru a zaškrtněte políčko Povolit všem ověřeným uživatelům aktualizovat záznamy DNS se stejným názvem vlastníka.
- Převeďte prostředek
s prostředkem IP adresy do režimu offline a opravte ho.
Událost 157 – Disk byl překvapen odebráním.
K tomu může dojít v případě, že je pro prostředí skupiny dostupnosti nastavená vlastnost prostorů úložiště AutomaticClusteringEnabled na hodnotu True. Změňte ji na hodnotu False. Událost resetování nebo neočekávaného odebrání disku může aktivovat také spuštění sestavy ověření s možností úložiště. Událost neočekávaného odebrání disku může aktivovat také omezování systému úložiště.
Událost 1206 – Prostředek názvu sítě clusteru nejde převést do režimu online.
Objekt počítače přidružený k prostředku nelze v doméně aktualizovat. Ujistěte se, že máte příslušná oprávnění k doméně.
Chyby clusteringu Windows
Při nastavování clusteru s podporou převzetí služeb při selhání systému Windows nebo jeho připojení může dojít k problémům, pokud nemáte otevřené porty služby clusteru pro komunikaci.
Pokud používáte Windows Server 2019 a nevidíte IP adresu clusteru s Windows, nakonfigurovali jste název distribuované sítě, který se podporuje jenom na SQL Serveru 2019. Pokud máte starší verzi SQL Serveru, můžete cluster odebrat a vytvořit ho znovu s použitím názvu sítě.
Další chyby událostí clusteringu s podporou převzetí služeb při selhání systému Windows a jejich řešení najdete tady.
Další kroky
Další informace najdete v následujících tématech:
- Nastavení HADR pro SQL Server na virtuálních počítačích Azure
- Cluster s podporou převzetí služeb při selhání Windows Serveru s SQL Serverem na virtuálních počítačích Azure
- Skupiny dostupnosti AlwaysOn s SQL Serverem na virtuálních počítačích Azure
- Cluster s podporou převzetí služeb při selhání Windows Serveru s SQL Serverem na virtuálních počítačích Azure
- Instance clusteru s podporou převzetí služeb při selhání s SQL Serverem na virtuálních počítačích Azure
- Přehled instance clusteru s podporou převzetí služeb při selhání