Extrahování textu a informací z obrázků v rozšiřování AI
Díky rozšiřování AI nabízí Azure AI Search několik možností pro vytváření a extrahování prohledávatelného textu z obrázků, mezi které patří:
- OCR pro optické rozpoznávání znaků textu a číslic
- Analýza obrázků, která popisuje obrázky prostřednictvím vizuálních funkcí
- Vlastní dovednosti pro vyvolání jakéhokoli externího zpracování obrázků, které chcete poskytnout
Pomocí OCR můžete extrahovat text z fotek nebo obrázků obsahujících alfanumerický text, například slovo "STOP" ve znaku stop. Pomocí analýzy obrázků můžete vygenerovat textovou reprezentaci obrázku, například "pamdelion" pro fotku pamdelionu nebo barvu "žlutou". Můžete také extrahovat metadata o obrázku, například jeho velikost.
Tento článek popisuje základy práce s obrázky a popisuje také několik běžných scénářů, jako je práce s vloženými obrázky, vlastní dovednosti a překryvné vizualizace na původních obrázcích.
Pokud chcete pracovat s obsahem obrázku v sadě dovedností, budete potřebovat:
- Zdrojové soubory, které obsahují obrázky
- Indexer vyhledávání nakonfigurovaný pro akce obrázků
- Sada dovedností s integrovanými nebo vlastními dovednostmi, které vyvolávají analýzu OCR nebo obrázků
- Index vyhledávání s poli pro příjem analyzovaného textového výstupu a mapování výstupních polí v indexeru, který vytváří přidružení.
Volitelně můžete definovat projekce pro příjem výstupu analyzovaného obrázkem do úložiště znalostí pro scénáře dolování dat.
Nastavení zdrojových souborů
Zpracování obrázků je řízeno indexerem, což znamená, že nezpracované vstupy musí být v podporovaném zdroji dat.
- Analýza obrázků podporuje JPEG, PNG, GIF a BMP.
- OCR podporuje JPEG, PNG, BMP a TIF.
Obrázky jsou buď samostatné binární soubory, nebo vložené do dokumentů (PDF, RTF a soubory aplikací Microsoftu). Z daného dokumentu lze extrahovat maximálně 1 000 obrázků. Pokud je v dokumentu více než 1 000 obrázků, vyextrahuje se prvních 1 000 a vygeneruje se upozornění.
Azure Blob Storage je nejčastěji používané úložiště pro zpracování obrázků ve službě Azure AI Search. Existují tři hlavní úlohy související s načtením obrázků z kontejneru objektů blob:
Povolte přístup k obsahu v kontejneru. Pokud používáte úplný přístup připojovací řetězec, který obsahuje klíč, klíč vám udělí oprávnění k obsahu. Případně se můžete ověřit pomocí ID Microsoft Entra nebo se připojit jako důvěryhodná služba.
Vytvořte zdroj dat typu azureblob, který se připojí k kontejneru objektů blob, do kterého se ukládají vaše soubory.
Zkontrolujte limity úrovně služby a ujistěte se, že zdrojová data jsou pod maximální velikostí a omezeními množství pro indexery a rozšiřování.
Konfigurace indexerů pro zpracování obrázků
Po nastavení zdrojových souborů povolte normalizaci image nastavením parametru v konfiguraci indexeru imageAction . Normalizace obrázků pomáhá usnadnit jednotné zpracování obrázků pro zpracování podřízené položky. Normalizace obrázků zahrnuje následující operace:
- Velikost velkých obrázků se mění na maximální výšku a šířku, aby byly jednotná.
- U obrázků, které mají metadata při orientaci, se otočení obrázku upraví pro vertikální načítání.
Úpravy metadat se zaznamenávají ve složitém typu vytvořeném pro každou image. Z požadavku na normalizaci obrázku se nemůžete odhlásit. Dovednosti, které iterují obrázky, jako je OCR a analýza obrázků, očekávají normalizované obrázky.
Vytvořte nebo aktualizujte indexer pro nastavení vlastností konfigurace:
{ "parameters": { "configuration": { "dataToExtract": "contentAndMetadata", "parsingMode": "default", "imageAction": "generateNormalizedImages" } } }Nastaveno
dataToExtractnacontentAndMetadata(povinné).Ověřte, že
parsingModeje nastavená na výchozí (povinné).Tento parametr určuje členitost vyhledávacích dokumentů vytvořených v indexu. Výchozí režim nastaví korespondenci 1:1 tak, aby jeden objekt blob byl výsledkem jednoho hledaného dokumentu. Pokud jsou dokumenty velké nebo pokud dovednosti vyžadují menší bloky textu, můžete přidat dovednost Rozdělení textu, která rozdělí dokument do stránkování pro účely zpracování. V případě scénářů hledání se ale vyžaduje jeden objekt blob na dokument, pokud rozšiřování zahrnuje zpracování obrázků.
Nastavte
imageActionna povolení uzlu normalized_images ve stromu rozšiřování (povinné):generateNormalizedImagesgenerovat pole normalizovaných obrázků jako součást prolomení dokumentu.generateNormalizedImagePerPage(platí jenom pro PDF) pro vygenerování pole normalizovaných obrázků, kde se každá stránka v PDF vykresluje na jeden výstupní obrázek. U souborů, které nejsou soubory PDF, chování tohoto parametru je podobné, jako kdybyste nastavili generateNormalizedImages. Mějte však na paměti, že nastavení generateNormalizedImagePerPage může provádět operace indexování méně výkonným návrhem (zejména pro velké dokumenty), protože by bylo nutné vygenerovat několik obrázků.
Volitelně můžete upravit šířku nebo výšku vygenerovaných normalizovaných obrázků:
normalizedImageMaxWidth(v pixelech). Výchozí hodnota je 2000. Maximální hodnota je 1 0000.normalizedImageMaxHeight(v pixelech). Výchozí hodnota je 2000. Maximální hodnota je 1 0000.
Výchozí hodnota 2000 pixelů pro normalizované obrázky maximální šířky a výšky je založená na maximální velikosti podporované dovedností OCR a dovedností analýzy obrázků. Dovednost OCR podporuje maximální šířku a výšku 4200 pro neanglické jazyky a 1 0000 pro angličtinu. Pokud zvýšíte maximální limity, zpracování může selhat na větších obrázcích v závislosti na definici sady dovedností a jazyce dokumentů.
Volitelně můžete nastavit kritéria typu souboru, pokud úloha cílí na konkrétní typ souboru. Konfigurace indexeru objektů blob zahrnuje nastavení zahrnutí souborů a vyloučení. Můžete vyfiltrovat soubory, které nechcete.
{ "parameters" : { "configuration" : { "indexedFileNameExtensions" : ".pdf, .docx", "excludedFileNameExtensions" : ".png, .jpeg" } } }
Informace o normalizovaných obrázcích
Pokud imageAction je nastavená jiná hodnota než žádná, obsahuje nové pole normalized_images pole pole obrázků. Každý obrázek je komplexní typ, který má následující členy:
| Člen image | Popis |
|---|---|
| data | Base64 kódovaný řetězec normalizovaného obrázku ve formátu JPEG. |
| width | Šířka normalizovaného obrázku v pixelech |
| height | Výška normalizovaného obrázku v pixelech |
| OriginalWidth | Původní šířka obrázku před normalizací. |
| originalHeight | Původní výška obrázku před normalizací. |
| rotationFromOriginal | Otočení proti směru hodinových ručiček ve stupních, ke kterým došlo k vytvoření normalizovaného obrázku. Hodnota mezi 0 a 360 stupni. Tento krok přečte metadata z obrázku vygenerovaného fotoaparátem nebo skenerem. Obvykle násobek 90 stupňů. |
| contentOffset | Posun znaku v poli obsahu, ze kterého byl obrázek extrahován. Toto pole platí jenom pro soubory s vloženými obrázky. ContentOffset pro obrázky extrahované z dokumentů PDF je vždy na konci textu na stránce, ze které byl extrahován z dokumentu. To znamená, že obrázky se zobrazí po všech textech na této stránce bez ohledu na původní umístění obrázku na stránce. |
| pageNumber | Pokud se obrázek extrahoval nebo vykresloval z PDF, obsahuje toto pole číslo stránky v PDF, ze které bylo extrahováno nebo vykresleno od 1. Pokud obrázek není z PDF, je toto pole 0. |
Ukázková hodnota normalized_images:
[
{
"data": "BASE64 ENCODED STRING OF A JPEG IMAGE",
"width": 500,
"height": 300,
"originalWidth": 5000,
"originalHeight": 3000,
"rotationFromOriginal": 90,
"contentOffset": 500,
"pageNumber": 2
}
]
Definování sad dovedností pro zpracování obrázků
Tato část doplňuje referenční články dovedností tím, že poskytuje kontext pro práci se vstupy dovedností, výstupy a vzory, které souvisejí se zpracováním obrázků.
Vytvořte nebo aktualizujte sadu dovedností, abyste mohli přidat dovednosti.
Přidejte šablony pro OCR a Analýzu obrázků z portálu nebo zkopírujte definice z referenční dokumentace dovedností. Vložte je do pole dovedností definice sady dovedností.
V případě potřeby zahrňte klíč více služeb do vlastnosti služby Azure AI sady dovedností. Azure AI Search volá fakturovatelný prostředek služeb Azure AI pro analýzu OCR a obrázků pro transakce, které překračují bezplatný limit (20 na indexer za den). Služby Azure AI musí být ve stejné oblasti jako vaše vyhledávací služba.
Pokud jsou původní obrázky vložené do souborů PDF nebo aplikací, jako je PPTX nebo DOCX, budete muset přidat dovednost sloučení textu, pokud chcete mít výstup obrázku a výstup textu společně. Práce s vloženými obrázky je podrobněji popsána v tomto článku.
Jakmile se vytvoří základní architektura sady dovedností a nakonfiguruje se služby Azure AI, můžete se zaměřit na jednotlivé dovednosti obrázků, definovat vstupy a zdrojový kontext a mapovat výstupy na pole v indexu nebo úložišti znalostí.
Poznámka:
Viz kurz REST: Použití REST a umělé inteligence k vygenerování prohledávatelného obsahu z objektů blob Azure pro ukázkovou sadu dovedností, která kombinuje zpracování obrázků s podřízeným zpracováním přirozeného jazyka. Ukazuje, jak do rozpoznávání entit a extrakce klíčových frází nasytit výstup obrázků dovedností.
Informace o vstupech pro zpracování obrázků
Jak je uvedeno, obrázky se extrahují během prolomení dokumentu a pak se normalizují jako předběžný krok. Normalizované obrázky jsou vstupy do libovolné dovednosti zpracování obrázků a vždy jsou reprezentovány v rozšířeném stromu dokumentů jedním ze dvou způsobů:
/document/normalized_images/*je určen pro dokumenty, které jsou zpracovány jako celek./document/normalized_images/*/pagesje určen pro dokumenty, které se zpracovávají v blocích (stránkách).
Bez ohledu na to, jestli používáte analýzu OCR a obrázků ve stejné, mají vstupy prakticky stejnou konstrukci:
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [ ]
},
{
"@odata.type": "#Microsoft.Skills.Vision.ImageAnalysisSkill",
"context": "/document/normalized_images/*",
"visualFeatures": [ "tags", "description" ],
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [ ]
}
Mapování výstupů na vyhledávací pole
V sadě dovedností je výstup dovedností analýzy obrázků a OCR vždy text. Výstupní text je reprezentován jako uzly v interním rozšířeném stromu dokumentů a každý uzel musí být namapován na pole v indexu vyhledávání nebo na projekce ve znalostním úložišti, aby byl obsah dostupný ve vaší aplikaci.
V sadě dovedností si projděte
outputsčást každé dovednosti a zjistěte, které uzly existují v rozšířeném dokumentu:{ "@odata.type": "#Microsoft.Skills.Vision.OcrSkill", "context": "/document/normalized_images/*", "detectOrientation": true, "inputs": [ ], "outputs": [ { "name": "text", "targetName": "text" }, { "name": "layoutText", "targetName": "layoutText" } ] }Vytvořte nebo aktualizujte index vyhledávání a přidejte pole pro příjem výstupů dovedností.
V následujícím příkladu kolekce polí je "content" obsah objektu blob. "Metadata_storage_name" obsahuje název souboru (ujistěte se, že je "dostupný"). "Metadata_storage_path" je jedinečná cesta objektu blob a je výchozí klíč dokumentu. "Merged_content" je výstup z funkce Sloučení textu (užitečné při vložení obrázků).
Text a layoutText jsou výstupy dovedností OCR a musí se jednat o kolekci řetězců, aby bylo možné zachytit veškerý výstup vygenerovaný OCR pro celý dokument.
"fields": [ { "name": "content", "type": "Edm.String", "filterable": false, "retrievable": true, "searchable": true, "sortable": false }, { "name": "metadata_storage_name", "type": "Edm.String", "filterable": true, "retrievable": true, "searchable": true, "sortable": false }, { "name": "metadata_storage_path", "type": "Edm.String", "filterable": false, "key": true, "retrievable": true, "searchable": false, "sortable": false }, { "name": "merged_content", "type": "Edm.String", "filterable": false, "retrievable": true, "searchable": true, "sortable": false }, { "name": "text", "type": "Collection(Edm.String)", "filterable": false, "retrievable": true, "searchable": true }, { "name": "layoutText", "type": "Collection(Edm.String)", "filterable": false, "retrievable": true, "searchable": true } ],Aktualizujte indexer tak, aby mapovat výstup sady dovedností (uzly ve stromu rozšiřování) na indexovací pole.
Rozšířené dokumenty jsou interní. Pokud chcete externalizovat uzly v rozšířeném stromu dokumentů, nastavte mapování výstupního pole, které určuje, které pole indexu přijímá obsah uzlu. K obohaceným datům přistupuje vaše aplikace prostřednictvím pole indexu. Následující příklad ukazuje uzel "text" (výstup OCR) v rozšířeném dokumentu, který je mapován na "textové" pole v indexu vyhledávání.
"outputFieldMappings": [ { "sourceFieldName": "/document/normalized_images/*/text", "targetFieldName": "text" }, { "sourceFieldName": "/document/normalized_images/*/layoutText", "targetFieldName": "layoutText" } ]Spuštěním indexeru vyvoláte načtení zdrojového dokumentu, zpracování obrázků a indexování.
Ověření výsledků
Spuštěním dotazu na index zkontrolujte výsledky zpracování obrázků. Průzkumníka služby Search použijte jako klienta vyhledávání nebo jakýkoli nástroj, který odesílá požadavky HTTP. Následující dotaz vybere pole, která obsahují výstup zpracování obrázků.
POST /indexes/[index name]/docs/search?api-version=[api-version]
{
"search": "*",
"select": "metadata_storage_name, text, layoutText, imageCaption, imageTags"
}
OCR rozpozná text v souborech obrázků. To znamená, že pole OCR ("text" a "layoutText") jsou prázdná, pokud jsou zdrojové dokumenty čistým textem nebo čistými obrázky. Podobně jsou pole analýzy obrázků (imageCaption a ImageTags) prázdná, pokud jsou vstupy zdrojového dokumentu výhradně textem. Spuštění indexeru vygeneruje upozornění, pokud jsou vstupy imaging prázdné. Taková upozornění se očekávají, když se uzly v rozšířeném dokumentu nenačtou. Připomeňme si, že indexování objektů blob umožňuje zahrnout nebo vyloučit typy souborů, pokud chcete pracovat s typy obsahu izolovaně. Pomocí tohoto nastavení můžete snížit šum během spuštění indexeru.
Alternativní dotaz pro kontrolu výsledků může obsahovat pole "obsah" a "merged_content". Všimněte si, že tato pole obsahují obsah pro jakýkoli soubor objektu blob, i když nedošlo k žádnému zpracování obrázků.
Informace o výstupech dovedností
Výstupy dovedností zahrnují "text" (OCR), "layoutText" (OCR), "merged_content", "captions" (analýza obrázků), "tags" (analýza obrázků):
Text ukládá výstup vygenerovaný OCR. Tento uzel by měl být mapován na pole typu
Collection(Edm.String). Pro každý vyhledávací dokument existuje jedno "textové" pole skládající se z řetězců oddělených čárkami pro dokumenty, které obsahují více obrázků. Následující obrázek znázorňuje výstup OCR pro tři dokumenty. První je dokument obsahující soubor bez obrázků. Druhý je dokument (soubor obrázku), který obsahuje jedno slovo "Microsoft". Třetí je dokument obsahující více obrázků, některé bez textu ("",)."value": [ { "@search.score": 1, "metadata_storage_name": "facts-about-microsoft.html", "text": [] }, { "@search.score": 1, "metadata_storage_name": "guthrie.jpg", "text": [ "Microsoft" ] }, { "@search.score": 1, "metadata_storage_name": "Azure AI services and Content Intelligence.pptx", "text": [ "", "Microsoft", "", "", "", "Azure AI Search and Augmentation Combining Microsoft Azure AI services and Azure Search" ] } ]"layoutText" ukládá informace generované OCR o umístění textu na stránce popsané z hlediska ohraničujících polí a souřadnic normalizovaného obrázku. Tento uzel by měl být mapován na pole typu
Collection(Edm.String). Pro každý hledaný dokument existuje jedno pole layoutText, které se skládá z řetězců oddělených čárkami."merged_content" ukládá výstup dovednosti sloučení textu a mělo by to být jedno velké pole typu
Edm.String, které obsahuje nezpracovaný text ze zdrojového dokumentu s vloženým textem místo obrázku. Pokud jsou soubory pouze textové, pak analýza OCR a obrázků nemá nic společného a "merged_content" je stejná jako "obsah" (vlastnost objektu blob, která obsahuje obsah objektu blob)."imageCaption" zachycuje popis obrázku jako značky jednotlivců a delší textový popis.
ImageTags ukládá značky o obrázku jako kolekci klíčových slov, jednu kolekci pro všechny obrázky ve zdrojovém dokumentu.
Následující snímek obrazovky je obrázek PDF, který obsahuje text a vložené obrázky. Dokument prolomení zjistila tři vložené obrázky: hejna sagulalů, mapa, orel. Jiný text v příkladu (včetně názvů, nadpisů a základního textu) byl extrahován jako text a vyloučen ze zpracování obrázků.
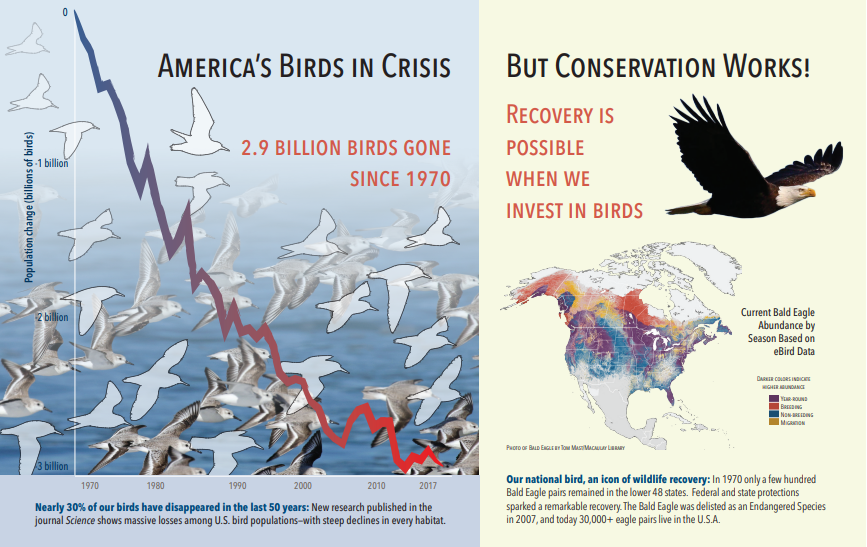
Výstup analýzy obrázků je znázorněn v následujícím formátu JSON (výsledek hledání). Definice dovednosti umožňuje určit, které vizuální funkce jsou zajímavé. V tomto příkladu byly vytvořeny značky a popisy, ale existují další výstupy, ze které si můžete vybrat.
Výstupem "imageCaption" je pole popisů, jeden na obrázek označený "značkami", který se skládá z jednoho slova a delších frází, které popisují obrázek. Všimněte si, že značky skládající se z "hejna sagulalů plavají ve vodě", nebo "zblízka ptáka".
Výstup imageTags je pole jednoduchých značek, které jsou uvedeny v pořadí vytvoření. Všimněte si, že značky se opakují. Neexistuje žádná agregace ani seskupení.
"imageCaption": [
"{\"tags\":[\"bird\",\"outdoor\",\"water\",\"flock\",\"many\",\"lot\",\"bunch\",\"group\",\"several\",\"gathered\",\"pond\",\"lake\",\"different\",\"family\",\"flying\",\"standing\",\"little\",\"air\",\"beach\",\"swimming\",\"large\",\"dog\",\"landing\",\"jumping\",\"playing\"],\"captions\":[{\"text\":\"a flock of seagulls are swimming in the water\",\"confidence\":0.70419257326275686}]}",
"{\"tags\":[\"map\"],\"captions\":[{\"text\":\"map\",\"confidence\":0.99942880868911743}]}",
"{\"tags\":[\"animal\",\"bird\",\"raptor\",\"eagle\",\"sitting\",\"table\"],\"captions\":[{\"text\":\"a close up of a bird\",\"confidence\":0.89643581933539462}]}",
. . .
"imageTags": [
"bird",
"outdoor",
"water",
"flock",
"animal",
"bunch",
"group",
"several",
"drink",
"gathered",
"pond",
"different",
"family",
"same",
"map",
"text",
"animal",
"bird",
"bird of prey",
"eagle"
. . .
Scénář: Vložené obrázky do souborů PDF
Když se image, které chcete zpracovat, vloží do jiných souborů, jako je PDF nebo DOCX, kanál rozšiřování extrahuje jenom obrázky a pak je předá do OCR nebo analýzy obrázků ke zpracování. Extrakce obrázků probíhá během fáze prolomení dokumentu a jakmile jsou obrázky oddělené, zůstanou oddělené, pokud nezpracovaný výstup explicitně sloučíte zpět do zdrojového textu.
Sloučení textu se používá k vložení výstupu zpracování obrázků zpět do dokumentu. I když sloučení textu není pevným požadavkem, často se volá, aby se do dokumentu znovu zavedl výstup obrázku (text OCR, OCR layoutText, značky obrázků, titulky obrázků). V závislosti na dovednosti nahradí výstup obrázku vložený binární obrázek ekvivalentem místního textu. Výstup analýzy obrázků je možné sloučit v umístění obrázku. Výstup OCR se vždy zobrazí na konci každé stránky.
Následující pracovní postup popisuje proces extrakce, analýzy, slučování a rozšíření kanálu tak, aby nasdílel výstup zpracovávaný obrázky do dalších textových dovedností, jako je rozpoznávání entit nebo překlad textu.
Po připojení ke zdroji dat indexer načte a prolomí zdrojové dokumenty, extrahuje obrázky a text a zařadí jednotlivé typy obsahu ke zpracování do fronty. Vytvoří se obohacený dokument, který se skládá pouze z kořenového uzlu (
"document").Obrázky ve frontě se normalizují a předávají do obohacených dokumentů jako
"document/normalized_images"uzlu.Rozšíření obrázků se spouští jako
"/document/normalized_images"vstup.Výstupy obrázků se předávají do rozšířeného stromu dokumentů, přičemž každý výstup je samostatný uzel. Výstupy se liší podle dovednosti (text a layoutText pro OCR, značky a titulky pro analýzu obrázků).
Volitelné, ale doporučené, pokud chcete, aby vyhledávací dokumenty obsahovaly text i text počátek obrázku dohromady, spustí se sloučení textu a zkombinuje textovou reprezentaci těchto obrázků s nezpracovaným textem extrahovaným ze souboru. Textové bloky se sloučí do jednoho velkého řetězce, kde se text vloží jako první do řetězce a potom do textového výstupu OCR nebo značky obrázků a titulků.
Výstup sloučení textu je nyní konečným textem, který se má analyzovat pro všechny podřízené dovednosti, které provádějí zpracování textu. Pokud například vaše sada dovedností zahrnuje OCR i Rozpoznávání entit, měl by být
"document/merged_text"vstup do rozpoznávání entit (targetName výstupu dovednosti sloučení textu).Po provedení všech dovedností je obohacený dokument dokončen. V posledním kroku indexery odkazují na mapování výstupních polí za účelem odesílání rozšířeného obsahu do jednotlivých polí v indexu vyhledávání.
Následující příklad sady dovedností vytvoří "merged_text" pole obsahující původní text dokumentu s vloženým textem OCRed místo vložených obrázků. Zahrnuje také dovednost Rozpoznávání entit, která se používá "merged_text" jako vstup.
Syntaxe textu požadavku
{
"description": "Extract text from images and merge with content text to produce merged_text",
"skills":
[
{
"description": "Extract text (plain and structured) from image.",
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"defaultLanguageCode": "en",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.MergeSkill",
"description": "Create merged_text, which includes all the textual representation of each image inserted at the right location in the content field.",
"context": "/document",
"insertPreTag": " ",
"insertPostTag": " ",
"inputs": [
{
"name":"text", "source": "/document/content"
},
{
"name": "itemsToInsert", "source": "/document/normalized_images/*/text"
},
{
"name":"offsets", "source": "/document/normalized_images/*/contentOffset"
}
],
"outputs": [
{
"name": "mergedText", "targetName" : "merged_text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"context": "/document",
"categories": [ "Person"],
"defaultLanguageCode": "en",
"minimumPrecision": 0.5,
"inputs": [
{
"name": "text", "source": "/document/merged_text"
}
],
"outputs": [
{
"name": "persons", "targetName": "people"
}
]
}
]
}
Teď, když máte merged_text pole, můžete ho mapovat jako prohledávatelné pole v definici indexeru. Veškerý obsah souborů, včetně textu obrázků, bude prohledávatelný.
Scénář: Vizualizace ohraničujících polí
Dalším běžným scénářem je vizualizace informací o rozložení výsledků hledání. Můžete třeba zvýraznit místo, kde se část textu na obrázku našla jako součást výsledků hledání.
Vzhledem k tomu, že se krok OCR provádí na normalizovaných obrázcích, souřadnice rozložení jsou v normalizovaném prostoru obrázku, ale pokud potřebujete zobrazit původní obrázek, převeďte souřadnicové body v rozložení na původní souřadnicový systém obrázku.
Vzor znázorňuje následující algoritmus:
/// <summary>
/// Converts a point in the normalized coordinate space to the original coordinate space.
/// This method assumes the rotation angles are multiples of 90 degrees.
/// </summary>
public static Point GetOriginalCoordinates(Point normalized,
int originalWidth,
int originalHeight,
int width,
int height,
double rotationFromOriginal)
{
Point original = new Point();
double angle = rotationFromOriginal % 360;
if (angle == 0 )
{
original.X = normalized.X;
original.Y = normalized.Y;
} else if (angle == 90)
{
original.X = normalized.Y;
original.Y = (width - normalized.X);
} else if (angle == 180)
{
original.X = (width - normalized.X);
original.Y = (height - normalized.Y);
} else if (angle == 270)
{
original.X = height - normalized.Y;
original.Y = normalized.X;
}
double scalingFactor = (angle % 180 == 0) ? originalHeight / height : originalHeight / width;
original.X = (int) (original.X * scalingFactor);
original.Y = (int)(original.Y * scalingFactor);
return original;
}
Scénář: Vlastní dovednosti obrázků
Obrázky lze také předat a vrátit z vlastních dovedností. Sada dovedností base64 kóduje obrázek, který se předává do vlastní dovednosti. Pokud chcete použít obrázek ve vlastní dovednosti, nastavte "/document/normalized_images/*/data" ho jako vstup pro vlastní dovednost. V kódu vlastní dovednosti kód base64 dekóduje řetězec před převodem na obrázek. Pokud chcete vrátit obrázek do sady dovedností, zakódujte obrázek před vrácením do sady dovedností kódováním base64.
Obrázek se vrátí jako objekt s následujícími vlastnostmi.
{
"$type": "file",
"data": "base64String"
}
Úložiště ukázek Pythonu pro Azure Search obsahuje kompletní ukázku implementovanou v Pythonu vlastní dovednosti, která rozšiřuje obrázky.
Předávání obrázků vlastním dovednostem
Ve scénářích, ve kterých potřebujete vlastní dovednost pro práci na obrázcích, můžete předat obrázky vlastní dovednosti a vrátit text nebo obrázky. Následující sada dovedností pochází z ukázky.
Následující sada dovedností vezme normalizovaný obrázek (získaný během prolomení dokumentu) a výstupy obrázku.
Sada ukázkových dovedností
{
"description": "Extract text from images and merge with content text to produce merged_text",
"skills":
[
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "ImageSkill",
"description": "Segment Images",
"context": "/document/normalized_images/*",
"uri": "https://your.custom.skill.url",
"httpMethod": "POST",
"timeout": "PT30S",
"batchSize": 100,
"degreeOfParallelism": 1,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "slices",
"targetName": "slices"
}
],
"httpHeaders": {}
}
]
}
Příklad vlastní dovednosti
Vlastní dovednost je pro sadu dovedností vnější. V tomto případě je to kód Pythonu, který nejprve prochází dávkou záznamů požadavků ve vlastním formátu dovedností a pak převede řetězec kódovaný base64 na obrázek.
# deserialize the request, for each item in the batch
for value in values:
data = value['data']
base64String = data["image"]["data"]
base64Bytes = base64String.encode('utf-8')
inputBytes = base64.b64decode(base64Bytes)
# Use numpy to convert the string to an image
jpg_as_np = np.frombuffer(inputBytes, dtype=np.uint8)
# you now have an image to work with
Podobně jako vrácení obrázku vrátí řetězec kódovaný v base64 v rámci objektu JSON s $type vlastností file.
def base64EncodeImage(image):
is_success, im_buf_arr = cv2.imencode(".jpg", image)
byte_im = im_buf_arr.tobytes()
base64Bytes = base64.b64encode(byte_im)
base64String = base64Bytes.decode('utf-8')
return base64String
base64String = base64EncodeImage(jpg_as_np)
result = {
"$type": "file",
"data": base64String
}
Viz také
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro