Kurz REST: Použití sad dovedností ke generování prohledávatelného obsahu ve službě Azure AI Search
V tomto kurzu se dozvíte, jak volat rozhraní REST API, která vytvářejí kanál rozšiřování AI pro extrakci a transformace obsahu během indexování.
Sady dovedností přidávají zpracování umělé inteligence do nezpracovaného obsahu, což zpřístupňuje tento obsah jednotnějším a prohledávatelnějším. Jakmile víte, jak sady dovedností fungují, můžete podporovat širokou škálu transformací: od analýzy obrázků až po zpracování přirozeného jazyka až po přizpůsobené zpracování, které poskytujete externě.
Tento kurz vám pomůže naučit se:
- Definujte objekty v kanálu rozšiřování.
- Vytvořte sadu dovedností. Vyvolání OCR, rozpoznávání jazyka, rozpoznávání entit a extrakce klíčových frází
- Spusťte kanál. Vytvoření a načtení indexu vyhledávání
- Zkontrolujte výsledky pomocí fulltextového vyhledávání.
Pokud nemáte předplatné Azure, otevřete si před zahájením bezplatný účet .
Přehled
Tento kurz používá klienta REST a rozhraní REST API služby Azure AI Search k vytvoření zdroje dat, indexu, indexeru a sady dovedností.
Indexer řídí každý krok v kanálu, počínaje extrakcí obsahu ukázkových dat (nestrukturovaného textu a obrázků) v kontejneru objektů blob ve službě Azure Storage.
Jakmile se obsah extrahuje, sada dovedností provede předdefinované dovednosti od Microsoftu a vyhledá a extrahuje informace. Mezi tyto dovednosti patří optické rozpoznávání znaků (OCR) na obrázcích, rozpoznávání jazyka u textu, extrakce klíčových frází a rozpoznávání entit (organizace). Nové informace vytvořené sadou dovedností se posílají do polí v indexu. Po naplnění indexu můžete použít pole v dotazech, omezujících vlastností a filtrech.
Požadavky
Visual Studio Code s klientem REST
Poznámka:
Pro účely tohoto kurzu můžete použít bezplatnou vyhledávací službu. Úroveň Free vás omezuje na tři indexy, tři indexery a tři zdroje dat. V tomto kurzu se vytváří od každého jeden. Než začnete, ujistěte se, že máte ve službě místo pro přijetí nových prostředků.
Stažení souborů
Stáhněte si soubor ZIP ukázkového úložiště dat a extrahujte obsah. Zjistěte jak.
Nahrání ukázkových dat do Azure Storage
Ve službě Azure Storage vytvořte nový kontejner a pojmenujte ho jako ukázku vyhledávání.
Získejte připojovací řetězec úložiště, abyste mohli formulovat připojení ve službě Azure AI Search.
Na levé straně vyberte Přístupové klávesy.
Zkopírujte připojovací řetězec pro klíč jeden nebo dva. Připojovací řetězec se podobá následujícímu příkladu:
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
Služby Azure AI
Integrované rozšiřování AI je podporováno službami Azure AI, včetně služeb language a Azure AI Vision pro zpracování přirozeného jazyka a obrázků. U malých úloh, jako je tento kurz, můžete použít bezplatné přidělení dvaceti transakcí na indexer. U větších úloh připojte prostředek azure AI Services pro více oblastí ke sadě dovedností s cenami průběžných plateb.
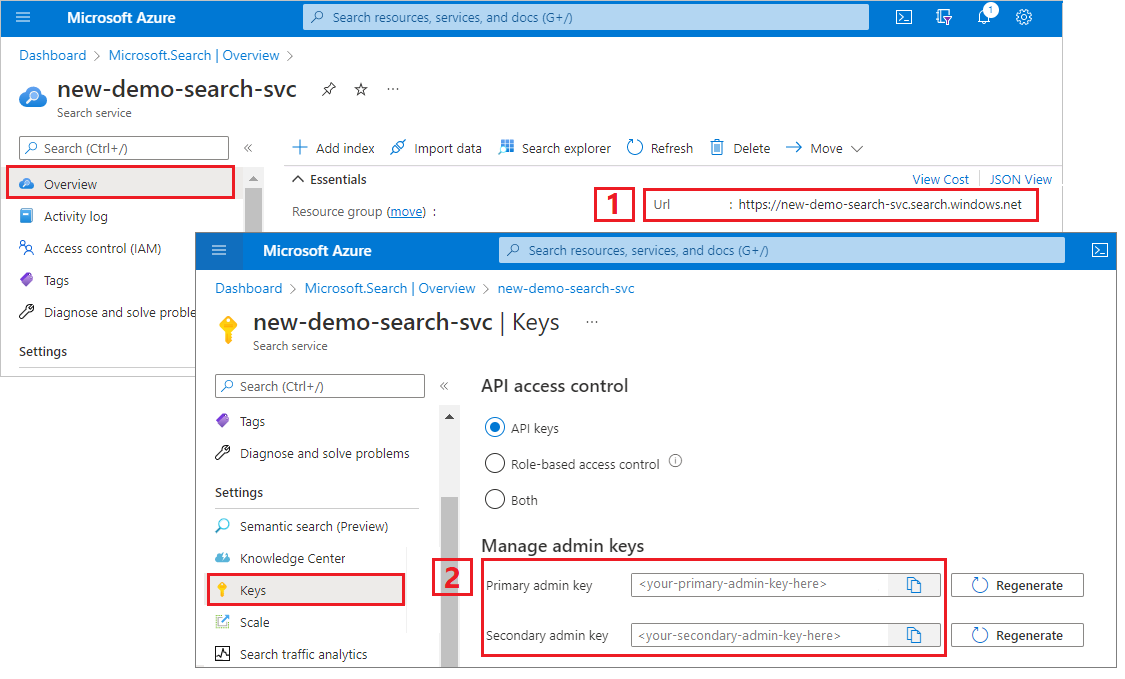
Zkopírování adresy URL vyhledávací služby a klíče rozhraní API
Pro účely tohoto kurzu vyžadují připojení ke službě Azure AI Search koncový bod a klíč rozhraní API. Tyto hodnoty můžete získat z webu Azure Portal.
Přihlaste se k webu Azure Portal, přejděte na stránku Přehled vyhledávací služby a zkopírujte adresu URL. Příkladem koncového bodu může být
https://mydemo.search.windows.net.V části Klíče nastavení>zkopírujte klíč správce. Klíče správce slouží k přidávání, úpravám a odstraňování objektů. Existují dva zaměnitelné klíče správce. Zkopírujte jeden z nich.
Nastavení souboru REST
Spusťte Visual Studio Code a otevřete soubor skillset-tutorial.rest . Viz Rychlý start: Vyhledávání textu pomocí REST , pokud potřebujete pomoc s klientem REST.
Zadejte hodnoty proměnných: koncový bod vyhledávací služby, klíč rozhraní API správce vyhledávací služby, název indexu, připojovací řetězec k vašemu účtu služby Azure Storage a název kontejneru objektů blob.
Vytvoření kanálu
Rozšiřování AI je řízené indexerem. Tato část návodu vytvoří čtyři objekty: zdroj dat, definice indexu, sada dovedností, indexer.
Krok 1: Vytvoření zdroje dat
Voláním příkazu Vytvořit zdroj dat nastavte připojovací řetězec do kontejneru objektů blob obsahujícího ukázkové datové soubory.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnectionString}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
Krok 2: Vytvoření sady dovedností
Voláním sady dovedností můžete určit, které kroky rozšiřování se použijí pro váš obsah. Dovednosti se provádějí paralelně, pokud není závislost.
### Create a skillset
POST {{baseUrl}}/skillsets?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-ss",
"description": "Apply OCR, detect language, extract entities, and extract key-phrases.",
"cognitiveServices": null,
"skills":
[
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"defaultLanguageCode": "en",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.MergeSkill",
"description": "Create merged_text, which includes all the textual representation of each image inserted at the right location in the content field. This is useful for PDF and other file formats that supported embedded images.",
"context": "/document",
"insertPreTag": " ",
"insertPostTag": " ",
"inputs": [
{
"name":"text",
"source": "/document/content"
},
{
"name": "itemsToInsert",
"source": "/document/normalized_images/*/text"
},
{
"name":"offsets",
"source": "/document/normalized_images/*/contentOffset"
}
],
"outputs": [
{
"name": "mergedText",
"targetName" : "merged_text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"textSplitMode": "pages",
"maximumPageLength": 4000,
"defaultLanguageCode": "en",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.LanguageDetectionSkill",
"description": "If you have multilingual content, adding a language code is useful for filtering",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "languageName",
"targetName": "language"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.KeyPhraseExtractionSkill",
"context": "/document/pages/*",
"inputs": [
{
"name": "text",
"source": "/document/pages/*"
}
],
"outputs": [
{
"name": "keyPhrases",
"targetName": "keyPhrases"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Organization"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "organizations",
"targetName": "organizations"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Location"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "locations",
"targetName": "locations"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Person"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "persons",
"targetName": "persons"
}
]
}
]
}
Klíčové body:
Text požadavku určuje následující předdefinované dovednosti:
Dovednost Popis Optické rozpoznávání znaků Rozpozná text a čísla v souborech obrázků. Sloučení textu Vytvoří "sloučený obsah", který rekombinuje dříve oddělený obsah, užitečný pro dokumenty s vloženými obrázky (PDF, DOCX atd.). Obrázky a text jsou odděleny během fáze prolomení dokumentu. Sloučit dovednosti je rekombinuje vložením rozpoznaného textu, titulků obrázků nebo značek vytvořených během rozšiřování do stejného umístění, kde byl obrázek extrahován z dokumentu. Když pracujete se sloučeným obsahem v sadě dovedností, tento uzel zahrnuje veškerý text v dokumentu, včetně textových dokumentů, které nikdy neprošly analýzou OCR nebo obrázků. Rozpoznávání jazyka Rozpozná jazyk a výstup buď název jazyka, nebo kód. Ve vícejazyčných datových sadách může být pole jazyka užitečné pro filtry. Rozpoznávání entit Extrahuje jména lidí, organizací a umístění ze sloučeného obsahu. Rozdělení textu Před voláním dovednosti extrakce klíčových frází rozdělí velký sloučený obsah na menší bloky dat. Extrakce klíčových frází přijímá vstup složený z 50 000 znaků nebo méně. Některé ze zdrojových souborů je nutné rozdělit, aby se do tohoto limitu vešly. Extrakce klíčových frází Vytáhne hlavní klíčové fráze. Pro obsah dokumentu se využijí jednotlivé dovednosti. Během zpracování azure AI Search prolomí každý dokument tak, aby četl obsah z různých formátů souborů. Nalezený text, který pochází ze zdrojového souboru, se umístí do vygenerovaného pole
content, jednoho pro každý dokument. Vstup se tak stane"/document/content".Pro extrakci klíčových frází používáme dovednost rozdělovače textu k rozdělení větších souborů na stránky, kontext dovednosti extrakce klíčových frází je
"document/pages/*"(pro každou stránku v dokumentu) místo"/document/content".
Poznámka:
Výstupy se dají namapovat na index, použít jako vstup do podřízené dovednosti, nebo využít oběma způsoby tak, jak se to dělá s kódem jazyka. V indexu je kód jazyka užitečný při filtrování. Další informace o základních principech sady dovedností najdete v článku o definování sady dovedností.
Krok 3: Vytvoření indexu
Voláním vytvořit index zadejte schéma použité k vytvoření invertovaných indexů a dalších konstruktorů ve službě Azure AI Search.
Největší součástí indexu je kolekce polí, kde datový typ a atributy určují obsah a chování ve službě Azure AI Search. Ujistěte se, že máte pole pro nově vygenerovaný výstup.
### Create an index
POST {{baseUrl}}/indexes?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-idx",
"defaultScoringProfile": "",
"fields": [
{
"name": "content",
"type": "Edm.String",
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
},
{
"name": "text",
"type": "Collection(Edm.String)",
"facetable": false,
"filterable": true,
"searchable": true,
"sortable": false
},
{
"name": "language",
"type": "Edm.String",
"searchable": false,
"sortable": true,
"filterable": true,
"facetable": false
},
{
"name": "keyPhrases",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "organizations",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "persons",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "locations",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "metadata_storage_path",
"type": "Edm.String",
"key": true,
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
},
{
"name": "metadata_storage_name",
"type": "Edm.String",
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
}
]
}
Krok 4: Vytvoření a spuštění indexeru
Voláním create Indexer se řídí kanál. Dosud vytvořené tři komponenty (zdroj dat, sada dovedností, index) jsou vstupy indexeru. Vytvoření indexeru ve službě Azure AI Search je událost, která umístí celý kanál do pohybu.
Buďte připravení na to, že může trvat i několik minut, než se tento krok dokončí. I když je sada dat malá, analytické dovednosti jsou výpočetně náročné.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-idxr",
"description": "",
"dataSourceName" : "cog-search-demo-ds",
"targetIndexName" : "cog-search-demo-idx",
"skillsetName" : "cog-search-demo-ss",
"fieldMappings" : [
{
"sourceFieldName" : "metadata_storage_path",
"targetFieldName" : "metadata_storage_path",
"mappingFunction" : { "name" : "base64Encode" }
},
{
"sourceFieldName": "metadata_storage_name",
"targetFieldName": "metadata_storage_name"
}
],
"outputFieldMappings" :
[
{
"sourceFieldName": "/document/merged_text",
"targetFieldName": "content"
},
{
"sourceFieldName" : "/document/normalized_images/*/text",
"targetFieldName" : "text"
},
{
"sourceFieldName" : "/document/organizations",
"targetFieldName" : "organizations"
},
{
"sourceFieldName": "/document/language",
"targetFieldName": "language"
},
{
"sourceFieldName" : "/document/persons",
"targetFieldName" : "persons"
},
{
"sourceFieldName" : "/document/locations",
"targetFieldName" : "locations"
},
{
"sourceFieldName" : "/document/pages/*/keyPhrases/*",
"targetFieldName" : "keyPhrases"
}
],
"parameters":
{
"batchSize": 1,
"maxFailedItems":-1,
"maxFailedItemsPerBatch":-1,
"configuration":
{
"dataToExtract": "contentAndMetadata",
"imageAction": "generateNormalizedImages"
}
}
}
Klíčové body:
Tělo požadavku obsahuje odkazy na předchozí objekty, vlastnosti konfigurace vyžadované ke zpracování obrázku a dva typy mapování polí.
"fieldMappings"se zpracovávají před sadou dovedností a odesílají obsah ze zdroje dat do cílových polí v indexu. Mapování polí slouží k odesílání existujícího nemodifikovaného obsahu do indexu. Pokud jsou názvy polí a typy na obou koncích stejné, nevyžaduje se žádné mapování."outputFieldMappings"jsou určena pro pole vytvořená dovednostmi po spuštění sady dovedností. Odkazy nasourceFieldNameinoutputFieldMappingsneexistují, dokud je nezlomení dokumentu nebo rozšiřování vytvoří. Jedná setargetFieldNameo pole v indexu definovaném ve schématu indexu.Parametr
"maxFailedItems"je nastaven na hodnotu -1, což dává modulu indexování pokyn, aby při importu dat ignoroval chyby. To je přijatelné, protože v ukázkovém zdroji dat je tak málo dokumentů. Pro větší zdroje dat by tato hodnota byla větší než 0.Příkaz
"dataToExtract":"contentAndMetadata"říká indexeru, aby automaticky extrahovali hodnoty z vlastnosti obsahu objektu blob a metadata každého objektu.Parametr
imageActionříká indexeru, aby extrahovali text z obrázků nalezených ve zdroji dat. Konfigurace"imageAction":"generateNormalizedImages"v kombinaci s dovednostmi OCR Skill and Text Merge Skill říká indexeru, aby extrahoval text z obrázků (například slovo "stop" z znaménka zastavení provozu) a vložil ho jako součást pole obsahu. Toto chování platí pro vložené obrázky (představte si obrázek uvnitř PDF) i samostatné soubory obrázků, například soubor JPG.
Poznámka:
Vytvoření indexeru vyvolá kanál. Pokud dojde k nějakému problému při komunikaci s daty, při mapování vstupů a výstupů nebo s pořadím operací, zobrazí se v této fázi. Pokud chcete kanál spustit znovu s pozměněným kódem nebo skriptem, bude možná nutné nejdříve zahodit objekty. Další informace najdete v článku o resetování a opětovném spuštění.
Monitorování indexování
Indexování a rozšiřování se zahájí, jakmile odešlete žádost o vytvoření indexeru. V závislosti na složitosti sady dovedností a operací může indexování chvíli trvat.
Pokud chcete zjistit, jestli je indexer stále spuštěný, zavolejte Načíst stav indexeru a zkontrolujte stav indexeru.
### Get Indexer Status (wait several minutes for the indexer to complete)
GET {{baseUrl}}/indexers/cog-search-demo-idxr/status?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
Klíčové body:
Upozornění jsou v některých scénářích běžná a ne vždy značí problém. Pokud například kontejner objektů blob obsahuje soubory obrázků a kanál nezpracuje obrázky, zobrazí se upozornění, že se nezpracovaly obrázky.
V této ukázce je soubor PNG, který neobsahuje žádný text. Všech pět dovedností založených na textu (rozpoznávání jazyka, rozpoznávání entit umístění, organizací, lidí a extrakce klíčových frází) se v tomto souboru nepodaří provést. Výsledné oznámení se zobrazí v historii provádění.
Kontrola výsledků
Teď, když jste vytvořili index, který obsahuje obsah vygenerovaný pomocí umělé inteligence, zavolejte vyhledávací dokumenty a spusťte některé dotazy, aby se zobrazily výsledky.
### Query the index\
POST {{baseUrl}}/indexes/cog-search-demo-idx/docs/search?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"select": "metadata_storage_name,language,organizations",
"count": true
}
Filtry vám můžou pomoct zúžit výsledky na položky, které vás zajímají:
### Filter by organization
POST {{baseUrl}}/indexes/cog-search-demo-idx/docs/search?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"filter": "organizations/any(organizations: organizations eq 'Microsoft')",
"select": "metadata_storage_name,organizations",
"count": true
}
Tyto dotazy ilustrují několik způsobů, jak můžete pracovat se syntaxí dotazů a filtry na nových polích vytvořených službou Azure AI Search. Další příklady dotazů najdete v tématu Příklady v rozhraní REST API pro vyhledávání dokumentů, příklady jednoduchých syntaxí dotazů a úplné příklady dotazů Lucene.
Resetování a opětovné spuštění
V počátečních fázích vývoje je běžná iterace návrhu. Obnovení a opětovné spuštění pomáhá s iterací.
Shrnutí
Tento kurz ukazuje základní kroky pro použití rozhraní REST API k vytvoření kanálu rozšiřování AI: zdroj dat, sada dovedností, index a indexer.
Předdefinované dovednosti byly zavedeny spolu s definicí sady dovedností, která ukazuje mechanismus řetězení dovedností prostřednictvím vstupů a výstupů. Také jste se dozvěděli, že outputFieldMappings v definici indexeru se vyžaduje směrování obohacených hodnot z kanálu do prohledávatelného indexu v Search Azure AI.
Nakonec jste se dozvěděli, jak testovat výsledky a resetovat systém pro další iterace. Zjistili jste, že zasílání dotazů na index vrací výstup vytvořený kanálem rozšířeného indexování.
Vyčištění prostředků
Když pracujete ve vlastním předplatném, je na konci projektu vhodné odebrat prostředky, které už nepotřebujete. Prostředky, které necháte spuštěné, vás stojí peníze. Prostředky můžete odstraňovat jednotlivě nebo můžete odstranit skupinu prostředků, a odstranit tak celou sadu prostředků najednou.
Prostředky můžete najít a spravovat na portálu pomocí odkazu Všechny prostředky nebo skupiny prostředků v levém navigačním podokně.
Další kroky
Teď, když znáte všechny objekty v kanálu rozšiřování AI, se podrobněji podíváme na definice sady dovedností a individuální dovednosti.