Průvodce importem dat na webu Azure Portal
Azure AI Search má dva průvodce importem, který automatizuje indexování a vytváření objektů, abyste mohli začít dotazovat okamžitě. Pokud s Azure AI Search začínáte, jsou tito průvodci jednou z nejvýkonnějších funkcí, které máte k dispozici. S minimálním úsilím můžete vytvořit kanál indexování nebo rozšiřování, který provádí většinu funkcí služby Azure AI Search.
Průvodce importem dat podporuje nevectorové pracovní postupy. Z nezpracovaných dokumentů můžete extrahovat text a čísla. Můžete také nakonfigurovat použité AI a integrované dovednosti, které odvozují strukturu a generují text prohledávatelný obsah ze souborů obrázků a nestrukturovaných dat.
Průvodce importem a vektorizací dat přidává bloky dat a vektorizaci. Musíte zadat existující nasazení modelu vkládání, ale průvodce vytvoří připojení, formuluje požadavek a zpracuje odpověď. Generuje vektorový obsah z textového nebo obrázkového obsahu.
Pokud používáte průvodce pro testování konceptu, tento článek vysvětluje interní fungování průvodců, abyste je mohli efektivněji používat.
Tento článek není krok za krokem. Nápovědu k použití průvodce s ukázkovými daty najdete tady:
- Rychlý start: Vytvoření indexu vyhledávání
- Rychlý start: Vytvoření sady dovedností pro překlad textu a entitu
- Rychlý start: Vytvoření vektorového indexu
- Rychlý start: vyhledávání obrázků (vektory)
Průvodci podporují většinu zdrojů dat podporovaných indexery.
| Data | Průvodce importem dat | Průvodce importem a vektorizací dat |
|---|---|---|
| ADLS Gen2 | ✅ | ✅ |
| Azure Blob Storage | ✅ | ✅ |
| Azure File Storage | ❌ | ❌ |
| Azure Table Storage | ✅ | ✅ |
| Databáze Azure SQL a spravovaná instance | ✅ | ✅ |
| Cosmos DB pro NoSQL | ✅ | ✅ |
| Cosmos DB pro MongoDB | ✅ | ✅ |
| Cosmos DB pro Apache Gremlin | ✅ | ✅ |
| MySQL | ❌ | ❌ |
| OneLake | ✅ | ✅ |
| SharePoint Online | ❌ | ❌ |
| SQL Server na virtuálních počítačích | ✅ | ✅ |
Microsoft hostuje ukázková data, abyste mohli vynechat krok konfigurace zdroje dat v pracovním postupu průvodce.
| Vzorová data | Průvodce importem dat | Průvodce importem a vektorizací dat |
|---|---|---|
| hotely | ✅ | ❌ |
| nemovitost | ✅ | ❌ |
Tato část obsahuje seznam dovedností, které se můžou objevit v sadě dovedností vygenerované průvodcem. Průvodci generují mapování sad dovedností a výstupních polí na základě vybraných možností. Po vytvoření sady dovedností můžete upravit její definici JSON a přidat tak další dovednosti.
Tady je několik bodů, které byste měli mít na paměti o dovednostech v následujícím seznamu:
- Možnosti analýzy OCR a obrázků jsou k dispozici pro objekty blob ve službě Azure Storage a soubory ve OneLake za předpokladu výchozího režimu analýzy. Obrázky jsou buď typ obsahu obrázku (například PNG nebo JPG), nebo vložený obrázek v souboru aplikace (například PDF).
- Shaper se přidá, pokud nakonfigurujete úložiště znalostí.
- Rozdělení textu a sloučení textu se přidají pro vytváření bloků dat, pokud zvolíte model vložení. Pokud je úroveň podrobností zdrojového pole nastavená na stránky nebo věty, přidají se pro další dovednosti, které se nevkládají.
| Kvalifikace | Průvodce importem dat | Průvodce importem a vektorizací dat |
|---|---|---|
| Multimodální umělá inteligence (AI Vision) | ❌ | ✅ |
| Vkládání Azure OpenAI | ❌ | ✅ |
| Azure Machine Learning (katalog modelů Azure AI Foundry) | ❌ | ✅ |
| Rozložení dokumentu | ❌ | ✅ |
| Rozpoznávání entit | ✅ | ❌ |
| Analýza obrázku (platí pro objekty blob, výchozí analýza, indexování celého souboru | ✅ | ❌ |
| Extrakce klíčových slov | ✅ | ❌ |
| Detekce jazyka | ✅ | ❌ |
| Překlad textu | ✅ | ❌ |
| OCR (platí pro objekty blob, výchozí analýza, indexování celého souboru) | ✅ | ✅ |
| Detekce PII | ✅ | ❌ |
| Analýza mínění | ✅ | ❌ |
| Shaper (platí pro úložiště znalostí) | ✅ | ❌ |
| Rozdělení textu | ✅ | ✅ |
| Sloučení textu | ✅ | ✅ |
Úložiště znalostí můžete vygenerovat pro sekundární úložiště rozšířeného obsahu (generovaného dovednostmi). Můžete chtít úložiště znalostí pro pracovní postupy načítání informací, které nevyžadují vyhledávací web.
| Knowledge Store | Průvodce importem dat | Průvodce importem a vektorizací dat |
|---|---|---|
| úložiště | ✅ | ❌ |
Průvodci importem vytvoří objekty popsané v následující tabulce. Po vytvoření objektů můžete zkontrolovat jejich definice JSON na webu Azure Portal nebo je volat z kódu.
Chcete-li zobrazit tyto objekty po spuštění průvodce:
Přihlaste se k webu Azure Portal a vyhledejte vyhledávací službu.
Výběrem možnosti Správa vyhledávání v nabídce vyhledáte stránky pro indexy, indexery, zdroje dat a sady dovedností.
| Objekt | Popis |
|---|---|
| Indexer | Objekt konfigurace určující zdroj dat, cílový index, volitelnou sadu dovedností, volitelný plán a volitelné nastavení konfigurace pro předání chyb a kódování base-64. |
| Zdroj dat | Zachová informace o připojení k podporovanému zdroji dat v Azure. Objekt zdroje dat se používá výhradně s indexery. |
| Index | Fyzická datová struktura používaná pro fulltextové vyhledávání a další dotazy. |
| Sada dovedností | Nepovinné. Kompletní sada instrukcí pro manipulaci, transformaci a tvarování obsahu, včetně analýzy a extrahování informací ze souborů obrázků. Sady dovedností se také používají pro integrovanou vektorizaci. Pokud objem práce spadá pod limit 20 transakcí na indexer za den, musí sada dovedností obsahovat odkaz na prostředek azure AI s více službami, který poskytuje rozšiřování. Pro integrovanou vektorizaci můžete použít Azure AI Vision nebo vložený model v katalogu modelů Azure AI Foundry. |
| Úložiště znalostí | Nepovinné. K dispozici pouze v Průvodci importem dat . Ukládá rozšířené výstupy sady dovedností z tabulek a objektů blob ve službě Azure Storage pro nezávislé analýzy nebo podřízené zpracování ve scénářích, které neprohledat. |
Před napsáním jakéhokoli kódu můžete použít průvodce k vytváření prototypů a testování konceptu. Průvodci se připojují k externím zdrojům dat, vzorkují data, aby vytvořily počáteční index, a pak data naimportují a volitelně vektorizují jako dokumenty JSON do indexu ve službě Azure AI Search.
Pokud vyhodnocujete sady dovedností, průvodce zpracuje mapování výstupních polí a přidá pomocné funkce pro vytváření použitelných objektů. Rozdělení textu se přidá, pokud zadáte režim analýzy. Sloučení textu se přidá, pokud jste zvolili analýzu obrázků, aby průvodce mohl znovu sloučit textové popisy s obsahem obrázku. Dovednosti shaperu se přidají k podpoře platných projekcí, pokud jste zvolili možnost úložiště znalostí. Všechny výše uvedené úkoly mají křivku učení. Pokud s rozšiřováním začínáte, můžete mít tyto kroky zvládnuty, abyste mohli měřit hodnotu dovednosti, aniž byste museli investovat mnoho času a úsilí.
Vzorkování je proces, kterým je odvozeno schéma indexu a má určitá omezení. Po vytvoření zdroje dat průvodce vybere náhodný vzorek dokumentů a rozhodne, které sloupce jsou součástí zdroje dat. Ne všechny soubory se čtou, protože to může trvat hodiny u velmi velkých zdrojů dat. Při výběru dokumentů, zdrojových metadat, jako je název pole nebo typ, se používá k vytvoření kolekce polí ve schématu indexu. V závislosti na složitosti zdrojových dat možná budete muset upravit počáteční schéma pro přesnost nebo prodloužit jeho úplnost. Změny můžete provést přímo na stránce definice indexu.
Obecně platí, že výhody použití průvodce jsou jasné: pokud jsou splněné požadavky, můžete během několika minut vytvořit dotazovatelný index. Některé složitosti indexování, jako je serializace dat jako dokumentů JSON, jsou zpracovávány průvodci.
Průvodci importem nejsou bez omezení. Omezení se shrnují takto:
Průvodci nepodporují iteraci ani opakované použití. Každý průchod průvodce vytvoří novou konfiguraci indexu, sady dovedností a indexeru. V průvodci je možné uchovávat a opakovaně používat pouze zdroje dat. Pokud chcete upravit nebo upřesnit jiné objekty, odstraňte objekty a začněte znovu, nebo pomocí rozhraní REST API nebo sady .NET SDK upravte struktury.
Zdrojový obsah se musí nacházet v podporovaném zdroji dat.
Vzorkování je nad podmnožinou zdrojových dat. U velkých zdrojů dat může průvodce vynechat pole. V případě nedostatečného vzorkování možná budete muset schéma rozšířit nebo opravit odvozené datové typy.
Rozšiřování AI, jak je zveřejněné na webu Azure Portal, je omezené na podmnožinu předdefinovaných dovedností.
Úložiště znalostí, které může vytvořit průvodce importem dat, je omezené na několik výchozích projekcí a používá výchozí zásady vytváření názvů. Pokud chcete přizpůsobit názvy nebo projekce, budete muset vytvořit úložiště znalostí prostřednictvím rozhraní REST API nebo sad SDK.
Průvodci importem provádějí odchozí připojení pomocí kontroleru webu Azure Portal a veřejných koncových bodů. Průvodce nemůžete použít, pokud se k prostředkům Azure přistupuje přes privátní připojení nebo přes sdílené privátní propojení.
Průvodce můžete použít přes omezená veřejná připojení, ale ne všechny funkce jsou k dispozici.
Import předdefinovaných ukázkových dat ve vyhledávací službě vyžaduje veřejný koncový bod a žádná pravidla brány firewall.
Ukázková data hostuje Microsoft na konkrétních prostředcích Azure. Kontroler webu Azure Portal se k těmto prostředkům připojuje přes veřejný koncový bod. Pokud umístíte vyhledávací službu za bránu firewall, zobrazí se tato chyba při pokusu o načtení předdefinovaných ukázkových dat:
Import configuration failed, error creating Data Sourcea následně"An error has occured.".Na podporovaných zdrojích dat Azure chráněných branami firewall můžete načíst data, pokud máte správná pravidla brány firewall.
Prostředek Azure musí přijímat síťové požadavky z IP adresy zařízení použitého v připojení. Službu Azure AI Search byste také měli uvést jako důvěryhodnou službu v konfiguraci sítě prostředku. Například ve službě Azure Storage můžete zobrazit seznam
Microsoft.Search/searchServicesjako důvěryhodnou službu.Připojení k účtu Azure AI s více službami, který zadáte, nebo připojení k vkládání modelů nasazených na portálu Azure AI Foundry nebo Azure OpenAI, musí být povolený veřejný internetový přístup, pokud vaše vyhledávací služba nesplňuje požadavky na datum vytvoření, vrstvu a oblast pro privátní připojení. Další informace o těchto požadavcích najdete v tématu Vytváření odchozích připojení prostřednictvím sdíleného privátního propojení.
Připojení k více službám Azure AI jsou určená pro účely fakturace. K fakturaci dochází v případě, že volání rozhraní API překročí počet bezplatných transakcí (20 na spuštění indexeru) pro předdefinované dovednosti volané průvodcem importem dat nebo integrovanou vektorizací v průvodci importem a vektorizací dat .
Pokud se Azure AI Search nemůže připojit:
V průvodci importem a vektorizací dat je chyba
"Access denied due to Virtual Network/Firewall rules."V průvodci importem dat neexistuje žádná chyba, ale sada dovedností se nevytvořila.
Pokud nastavení brány firewall brání úspěšnému fungování pracovních postupů průvodce, zvažte místo toho skriptované nebo programové přístupy.
Průvodce je uspořádaný do čtyř hlavních kroků:
Připojte se k podporovanému zdroji dat Azure.
Vytvořte schéma indexu odvozené vzorkováním zdrojových dat.
Volitelně přidává dovednosti k extrakci nebo generování obsahu a struktury. Vstupy pro vytvoření úložiště znalostí se shromažďují v tomto kroku.
Spuštěním průvodce vytvořte objekty, volitelně vektorizovat data, načíst data do indexu, nastavit plán a další možnosti konfigurace.
Pracovní postup je kanál, takže je jedním ze způsobů. Průvodce nemůžete použít k úpravě objektů, které byly vytvořeny, ale pro povolené aktualizace můžete použít jiné nástroje portálu, jako je návrhář indexu nebo indexer nebo editory JSON.
Tady je postup, jak spustíte průvodce.
Na webu Azure Portal otevřete stránku vyhledávací služby z řídicího panelu nebo vyhledejte službu v seznamu služeb.
Na stránce Přehled služby v horní části vyberte Importovat data nebo Importovat a vektorizovat data.
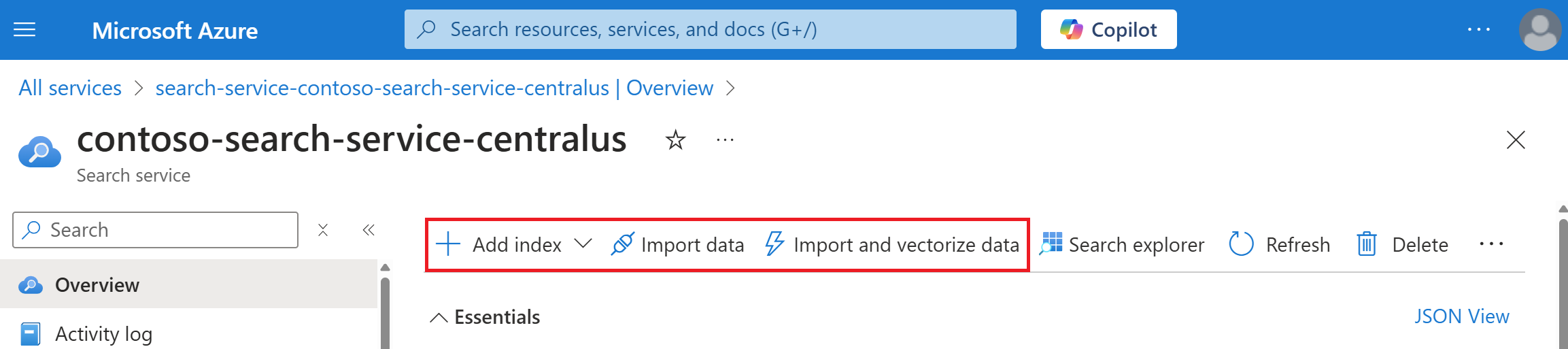
Průvodci se v okně prohlížeče otevřou plně rozbalené, abyste měli víc místa na práci.
Pokud jste vybrali možnost Importovat data, můžete vybrat možnost Ukázky pro indexování datové sady hostované Microsoftem z podporovaného zdroje dat.
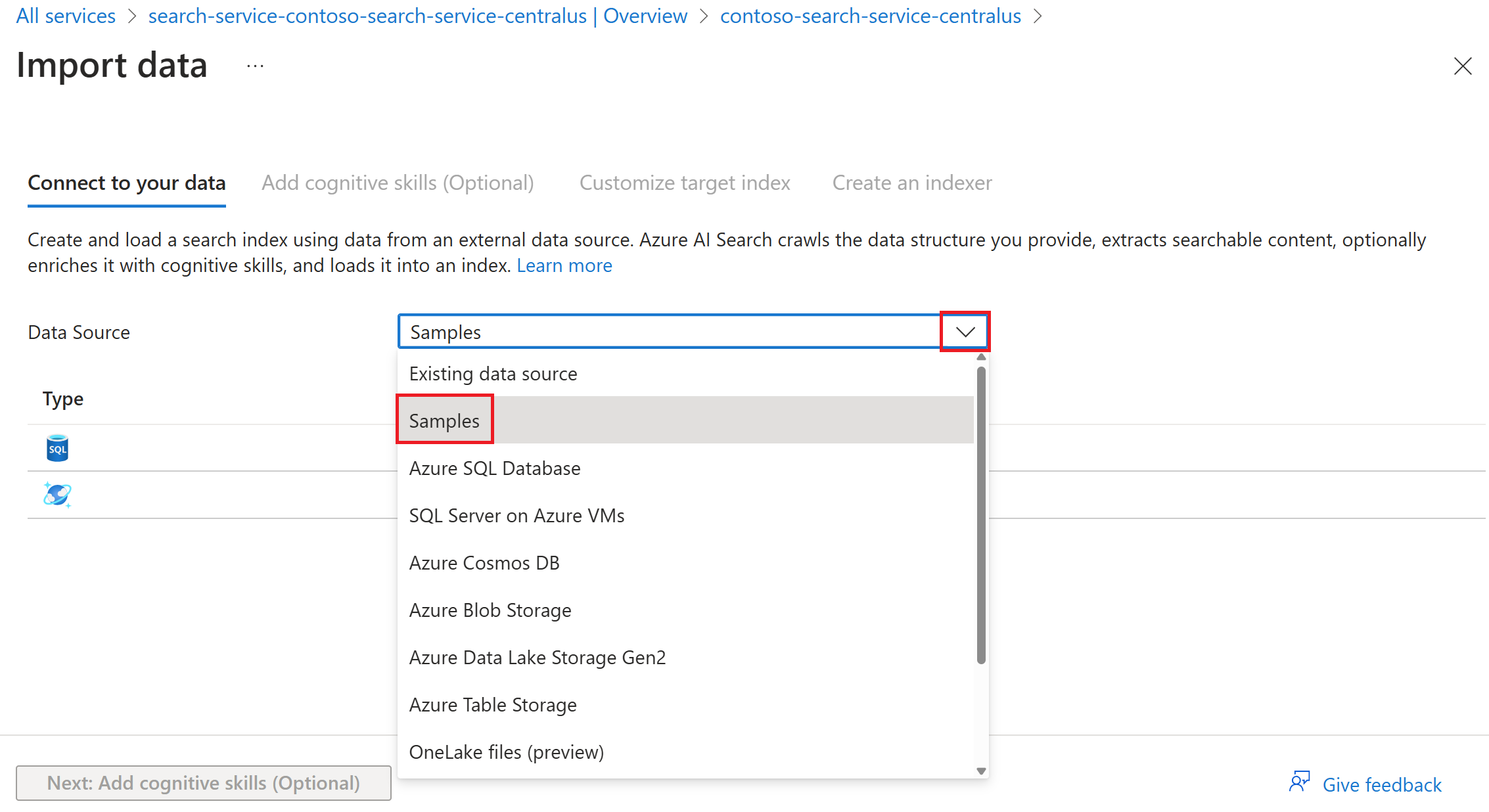
Pomocí zbývajících kroků v průvodci vytvořte index a indexer.
Můžete také spustit import dat z jiných služeb Azure, včetně Azure Cosmos DB, Azure SQL Database, SQL Managed Instance a Azure Blob Storage. V levém navigačním podokně na stránce přehledu služby vyhledejte přidání služby Azure AI Search.
Průvodci se připojují k externímu podporovanému zdroji dat pomocí interní logiky poskytované indexery služby Azure AI Search, které jsou vybavené k vzorkování zdroje, čtení metadat, prolomení dokumentů pro čtení obsahu a struktury a serializaci obsahu jako JSON pro následný import do služby Azure AI Search.
Můžete vložit připojení k podporovanému zdroji dat v jiném předplatném nebo oblasti, ale výběr existujícího připojení je vymezený na aktivní předplatné.
Ne všechny zdroje dat ve verzi Preview jsou zaručené, že budou v průvodci dostupné. Vzhledem k tomu, že každý zdroj dat má potenciál zavést další změny podřízené, zdroj dat ve verzi Preview se přidá do seznamu zdrojů dat pouze v případě, že plně podporuje všechna prostředí v průvodci, jako je definice sady dovedností a odvození schématu indexu.
Importovat můžete pouze z jedné tabulky, zobrazení databáze nebo ekvivalentní datové struktury, ale struktura může zahrnovat hierarchické nebo vnořené podstruktury. Další informace naleznete v tématu Modelování složitých typů.
Konfigurace sady dovedností se vyskytuje po definici zdroje dat, protože typ zdroje dat informuje o dostupnosti určitých předdefinovaných dovedností. Konkrétně pokud indexujete soubory z úložiště objektů blob, můžete zvolit režim analýzy těchto souborů a určit, jestli je analýza mínění dostupná.
Průvodce přidá dovednosti, které zvolíte. Přidává také další dovednosti, které jsou nezbytné k dosažení úspěšného výsledku. Pokud například zadáte úložiště znalostí, průvodce přidá dovednost Shaper pro podporu projekcí (nebo fyzických datových struktur).
Sady dovedností jsou volitelné a v dolní části stránky je tlačítko, které vás přeskočí, pokud nechcete, aby se rozšiřování umělé inteligence střídá.
Průvodci vzorek zdroje dat k detekci polí a typu pole. V závislosti na zdroji dat může také nabízet pole pro indexování metadat.
Vzhledem k tomu, že vzorkování je nepřesné cvičení, projděte si index s následujícími aspekty:
Je seznam polí přesný? Pokud zdroj dat obsahuje pole, která se nevyzvedla v vzorkování, můžete ručně přidat všechna nová pole, která vzorkování zmeškala, a odebrat všechna, která nepřidají hodnotu do vyhledávacího prostředí nebo která se nebudou používat ve výrazu filtru nebo v bodovacím profilu.
Je datový typ vhodný pro příchozí data? Azure AI Search podporuje datové typy datového modelu entity (EDM). V případě dat Azure SQL je k dispozici mapový graf , který obsahuje ekvivalentní hodnoty. Další informace najdete v tématu Mapování a transformace polí.
Máte jedno pole, které může sloužit jako klíč? Toto pole musí být Edm.string a musí jednoznačně identifikovat dokument. U relačních dat je možné je namapovat na primární klíč. U objektů blob to může být .
metadata-storage-pathPokud hodnoty polí obsahují mezery nebo pomlčky, je nutné nastavit možnost Klíč kódování Base-64 v kroku Vytvořit indexer v části Upřesnit možnosti, aby se potlačí kontrola ověření těchto znaků.Nastavte atributy, abyste zjistili, jak se toto pole používá v indexu.
S tímto krokem si dejte čas, protože atributy určují fyzický výraz polí v indexu. Pokud chcete později změnit atributy i programově, budete téměř vždy muset index vypustit a znovu sestavit. Základní atributy, jako je Prohledávatelné a Retrievable, mají zanedbatelný vliv na úložiště. Povolenífiltrůch
Umožňuje prohledávat fulltextové vyhledávání. Každé pole použité v dotazech volného formuláře nebo ve výrazech dotazu musí mít tento atribut. Invertované indexy se vytvoří pro každé pole, které označíte jako prohledávatelné.
Načtení vrátí pole ve výsledcích hledání. Každé pole, které poskytuje obsah výsledkům hledání, musí mít tento atribut. Nastavení tohoto pole nemá vliv na velikost indexu.
Filtrovatelné umožňuje odkaz na pole ve výrazech filtru. Každé pole použité ve výrazu $filter musí mít tento atribut. Výrazy filtru jsou přesné shody. Vzhledem k tomu, že textové řetězce zůstávají nedotčené, je potřeba více úložiště pro doslovný obsah.
Fasetová tabulka umožňuje pole pro fasetové navigace. Jako facetable lze označit pouze pole označená jako filtrovatelná.
Řazení umožňuje použití pole v řazení. Každé pole použité ve výrazu $Orderby musí mít tento atribut.
Potřebujete lexikální analýzu? U polí Edm.string, která jsou prohledávatelná, můžete nastavit Analyzátor , pokud chcete indexování a dotazování rozšířeného jazyka.
Výchozí hodnota je Standard Lucene , ale pokud chcete použít analyzátor Microsoftu pro pokročilé lexikální zpracování, jako je například řešení nepravidelných podstatných jmen a sloves. Na webu Azure Portal je možné zadat pouze analyzátory jazyka. Pokud používáte vlastní analyzátor nebo analyzátor bez jazyka, jako je klíčové slovo, vzor atd., musíte ho vytvořit programově. Další informace o analyzátorech najdete v tématu Přidání analyzátorů jazyka.
Potřebujete funkci pro psaní textu ve formě automatického dokončování nebo navrhovaných výsledků? Zaškrtněte políčko Navrhnout, pokud chcete u vybraných polí povolit návrhy dotazů pro psaní a automatické dokončování. Návrhy přidají do počtu tokenizovaných termínů v indexu, a proto spotřebovávají více úložiště.
Poslední stránka průvodce shromažďuje uživatelské vstupy pro konfiguraci indexeru. Můžete zadat plán a nastavit další možnosti, které se budou lišit podle typu zdroje dat.
Průvodce také interně nastaví následující definice, které nejsou v indexeru viditelné, dokud se nevytvořil:
- mapování polí mezi zdrojem dat a indexem
- Mapování výstupních polí mezi výstupem dovednosti a indexem
Nejlepším způsobem, jak porozumět výhodám a omezením průvodce, je projít si ho. Tady je několik rychlých startů založených na průvodci.