Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Vektory jsou vysoce dimenzionální vkládání, které představují text, obrázky a další obsah matematicky. Azure AI Search ukládá vektory na úrovni pole, což umožňuje, aby vektorový a nevectorový obsah společně existovat ve stejném indexu vyhledávání.
Index vyhledávání se stane vektorovým indexem při definování vektorových polí a konfigurace vektoru. Pokud chcete naplnit vektorová pole, můžete do nich vložit předem vypočítané vkládání nebo použít integrovanou vektorizaci, integrovanou funkci azure AI Search, která generuje vkládání během indexování.
V době dotazu umožňují vektorová pole v indexu vyhledávání podobností, kde systém načte dokumenty, jejichž vektory jsou nejvíce podobné vektorovém dotazu. Pomocí vektorového vyhledávání můžete vyhledat shodu podobnosti samostatně nebo hybridním vyhledáváním pro kombinaci podobnosti a párování klíčových slov.
Tento článek se zabývá klíčovými koncepty vytváření a správy vektorového indexu, včetně následujících:
- Vzory načítání vektorů
- Obsah (vektorová pole a konfigurace)
- Fyzická datová struktura
- Základní operace
Návod
Chcete začít hned? Viz Vytvoření vektorového indexu.
Vzory načítání vektorů
Azure AI Search podporuje dva vzory pro načítání vektorů:
Klasické vyhledávání. Tento vzor používá vyhledávací panel, vstup dotazu a vykreslené výsledky. Během provádění dotazu vyhledávací modul nebo kód aplikace vektorizuje uživatelský vstup. Vyhledávací web pak provede vektorové vyhledávání nad vektorovými poli v indexu a zformuluje odpověď, kterou v klientské aplikaci vykreslíte.
Ve službě Azure AI Search se výsledky vrátí jako zploštěná sada řádků a můžete zvolit pole, která se mají zahrnout do odpovědi. Přestože vyhledávač pracuje s vektory, měl by váš index obsahovat nevektorový obsah čitelný pro lidské oko, aby se naplnily výsledky hledání. Klasické vyhledávání podporuje vektorové dotazy i hybridní dotazy.
Generování vyhledávání Jazykové modely používají data z Azure AI Search k reagování na dotazy uživatelů. Vrstva orchestrace obvykle koordinuje výzvy a udržuje kontext a dodává výsledky hledání do chatovacích modelů, jako je GPT. Tento model je založený na architektuře rag (retrieval-augmented generation), kde index vyhledávání poskytuje základní data.
Schéma vektorového indexu
Schéma vektorového indexu vyžaduje následující:
- Název
- Klíčové pole (řetězec)
- Jedno nebo více vektorových polí
- Konfigurace vektoru
Pole nevectoru nejsou povinná, ale doporučujeme je přidat do hybridních dotazů nebo vrátit doslovný obsah, který neprochází jazykovým modelem. Další informace naleznete v tématu Vytvoření vektorového indexu.
Schéma indexu by mělo odrážet váš vzor načítání vektorů. Tato část se většinou zabývá složením polí pro klasické vyhledávání, ale poskytuje také pokyny schématu pro generování vyhledávání.
Základní konfigurace vektorových polí
Vektorová pole mají jedinečné datové typy a vlastnosti. Vektorové pole vypadá v kolekci polí takto:
{
"name": "content_vector",
"type": "Collection(Edm.Single)",
"searchable": true,
"retrievable": true,
"dimensions": 1536,
"vectorSearchProfile": "my-vector-profile"
}
Pro vektorová pole jsou podporovány pouze určité datové typy . Nejběžnějším typem je Collection(Edm.Single), ale použití úzkých typů může ušetřit na úložišti.
Vektorová pole musí být prohledávatelná a načístelná, ale nemůžou být filtrovatelná, fasetová nebo řaditelná. Nemohou mít analyzátory, normalizátory ani přiřazení synonymních map.
Vlastnost dimensions musí být nastavena na počet vkládání vygenerovaných modelem vkládání. Například text-embedding-ada-002 generuje 1 536 vkládání pro každý blok textu.
Vektorová pole se indexují pomocí algoritmů zadaných v profilu vektorového vyhledávání, který je definován jinde v indexu a v tomto příkladu se nezobrazuje. Další informace naleznete v tématu Přidání konfigurace vektorového vyhledávání.
Kolekce polí pro úlohy se základními vektory
Vektorové indexy vyžadují více než jen vektorová pole. Například všechny indexy musí mít klíčové pole, které je id v následujícím příkladu:
"name": "example-basic-vector-idx",
"fields": [
{ "name": "id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "key": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": null },
{ "name": "content", "type": "Edm.String", "searchable": true, "retrievable": true, "analyzer": null },
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": true, "facetable": true }
]
Další pole, například content pole, poskytují čitelný ekvivalent pole pro člověka content_vector . Pokud používáte jazykové modely výhradně pro formulaci odpovědí, můžete vynechat pole obsahu jiného typu nežvector, ale řešení, která odsílala výsledky hledání přímo do klientských aplikací, by měla obsahovat obsah nevectoru.
Pole metadat jsou užitečná pro filtry, zejména pokud obsahují informace o zdroji zdrojového dokumentu. I když nemůžete filtrovat přímo u vektorového pole, můžete nastavit prefilter, postfilter nebo přísné režimy postfilteru (Preview) a filtrovat před nebo po spuštění vektorového dotazu.
Schéma vygenerované průvodcem importem
Doporučujeme průvodce importem dat (nový) pro vyhodnocení a testování konceptu. Průvodce vygeneruje ukázkové schéma v této části.
Průvodce rozdělí obsah do menších vyhledávacích dokumentů, což přináší výhody aplikací RAG, které používají jazykové modely k formulování odpovědí. Chunkování vám pomůže zůstat v mezích vstupních omezení jazykových modelů a limitů tokenů sémantických rankerů. Zlepšuje také přesnost vyhledávání podobnosti tím, že porovnává dotazy na bloky dat natažené z více nadřazených dokumentů. Další informace naleznete v článku Jak rozdělit velké dokumenty pro řešení vektorového vyhledávání.
Pro každý vyhledávací dokument v následujícím příkladu existuje jedno ID bloku dat, nadřazené ID, blok dat, název a vektorové pole. Průvodce:
Naplní
chunk_idpoleparent_idmetadaty objektů blob s kódováním Base64 (cesta).Extrahuje pole
chunkz obsahu objektu blob a poletitlez názvu objektu blob.Vytvoří pole
vectorzavoláním embedovaného modelu Azure OpenAI, který zadáte pro převedení polechunkdo vektorů. Během tohoto procesu se plně vygeneruje pouze vektorové pole.
"name": "example-index-from-import-wizard",
"fields": [
{ "name": "chunk_id", "type": "Edm.String", "key": true, "searchable": true, "filterable": true, "retrievable": true, "sortable": true, "facetable": true, "analyzer": "keyword"},
{ "name": "parent_id", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": true},
{ "name": "chunk", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true, "sortable": false},
{ "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": false},
{ "name": "vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "vector-1707768500058-profile"}
]
Schéma pro generování vyhledávání
Pokud navrhujete vektorové úložiště pro rag a aplikace ve stylu chatu, můžete vytvořit dva indexy:
- Jeden pro statický obsah, který jste indexovali a vektorizovali.
- Jedna pro konverzace, které lze použít v tocích podnětů.
Pro ilustrativní účely tato část používá chat s akcelerátorem řešení na datech k vytvoření indexů chat-index a conversations.
Následující pole z chat-index podporují generativní vyhledávací zážitky:
"name": "example-index-from-accelerator",
"fields": [
{ "name": "id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "my-vector-profile"},
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "facetable": true },
{ "name": "source", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true },
{ "name": "chunk", "type": "Edm.Int32", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "offset", "type": "Edm.Int32", "searchable": false, "filterable": true, "retrievable": true }
]
Následující pole z conversations podporují orchestrace a historii chatu:
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": false },
{ "name": "conversation_id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "default-profile" },
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "type", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "user_id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "sources", "type": "Collection(Edm.String)", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "created_at", "type": "Edm.DateTimeOffset", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "updated_at", "type": "Edm.DateTimeOffset", "searchable": false, "filterable": true, "retrievable": true }
]
Následující snímek obrazovky ukazuje výsledky conversations hledání v Průzkumníku služby Search:
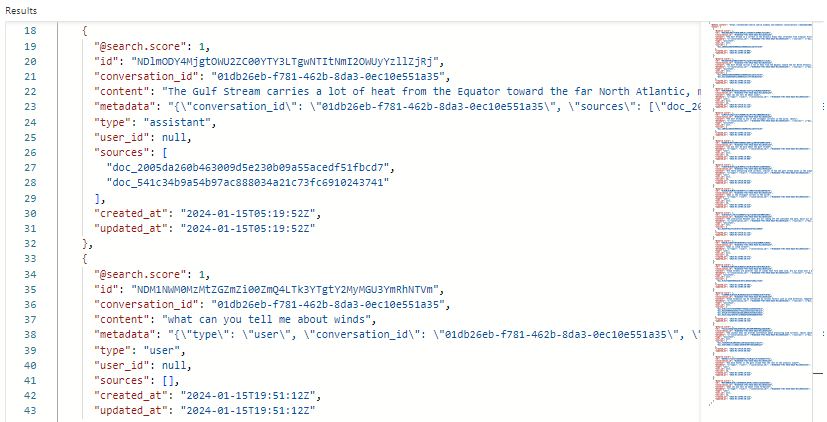
V našem příkladu je skóre hledání 1,00, protože hledání není kvalifikované. Několik polí podporuje orchestrace a průběh výzev.
-
conversation_ididentifikuje každou chatovací relaci. -
typeurčuje, zda je obsah od uživatele nebo asistenta. -
created_ataupdated_atodstraní chaty z historie.
Fyzická struktura a velikost
Ve službě Azure AI Search je fyzická struktura indexu z velké části interní implementací. Můžete získat přístup ke schématu, načtení a dotazování jeho obsahu, monitorovat jeho velikost a spravovat její kapacitu. Microsoft ale spravuje infrastrukturu a fyzické datové struktury uložené ve vyhledávací službě.
Velikost a podstata indexu jsou určeny:
Množství a složení dokumentů.
Atributy pro jednotlivá pole Například pro filtrovatelná pole je vyžadováno více úložiště.
Konfigurace indexu, včetně vektorové konfigurace, která určuje způsob vytváření interních navigačních struktur. Pro hledání podobností můžete zvolit HNSW nebo vyčerpávající metodu KNN.
Azure AI Search omezuje úložiště vektorů, což pomáhá udržovat vyvážený a stabilní systém pro všechny úlohy. Abychom vám pomohli zůstat pod limity, využití vektorů se sleduje a hlásí samostatně na webu Azure Portal a programově prostřednictvím statistik služby a indexu.
Následující snímek obrazovky ukazuje službu S1 nakonfigurovanou s jedním oddílem a jednou replikou. Tato služba má 24 malých indexů, z nichž každý má průměr jednoho vektorového pole sestávající z 1 536 vkládání. Druhá dlaždice zobrazuje kvótu a využití vektorových indexů. Protože vektorový index je interní datová struktura vytvořená pro každé vektorové pole, úložiště pro vektorové indexy je vždy zlomkem celkového úložiště používaného indexem. Pole nevektorů a další datové struktury spotřebovávají zbytek.
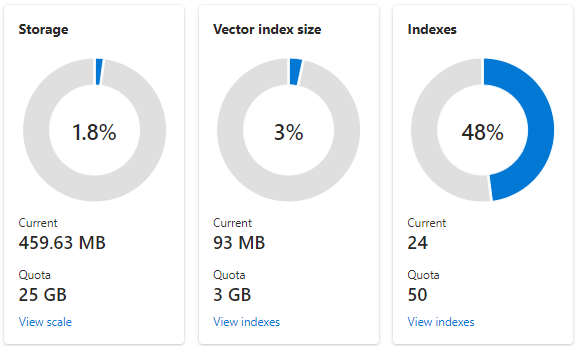
Omezení a odhady vektorového indexu jsou popsány v jiném článku, ale dva body, které je potřeba zdůraznit, jsou, že maximální úložiště závisí na datu vytvoření a cenové úrovni vyhledávací služby. Novější služby stejné vrstvy mají výrazně větší kapacitu pro indexy vektorů. Z těchto důvodů byste měli:
Zkontrolujte datum vytvoření vyhledávací služby. Pokud byla vytvořena před 3. dubnem 2024, možná budete moct upgradovat službu pro větší kapacitu.
Pokud očekáváte kolísání požadavků na vektorové úložiště, zvolte škálovatelnou úroveň . U starších vyhledávacích služeb je úroveň Basic omezena na jeden oddíl. Zvažte standard 1 (S1) a vyšší, aby byla větší flexibilita a rychlejší výkon. Můžete také přepínat mezi úrovněmi Basic a Standard (S1, S2 a S3).
Základní operace a interakce
Tato část představuje operace runtime vektorů, včetně připojení k a zabezpečení jednoho indexu.
Poznámka:
Pro přesun nebo kopírování indexu neexistuje žádná podpora portálu ani rozhraní API. Obvykle nasměrujete nasazení aplikace na jinou vyhledávací službu (pomocí stejného názvu indexu) nebo upravíte název, aby se vytvořila kopie ve vaší aktuální vyhledávací službě a pak ji sestavíte.
Izolace indexu
Ve službě Azure AI Search pracujete současně s jedním indexem. Všechny operace související s indexem cílí na jeden index. Neexistuje žádný koncept souvisejících indexů ani spojení nezávislých indexů pro indexování nebo dotazování.
Nepřetržitě dostupný
Index je okamžitě k dispozici pro dotazy hned po indexování prvního dokumentu, ale není plně funkční, dokud nebudou indexovány všechny dokumenty. Interně se index distribuuje mezi oddíly a spouští se na replikách. Fyzický index se spravuje interně. Logický index spravujete.
Index je nepřetržitě dostupný a nedá se pozastavit ani přecházet do offline režimu. Vzhledem k tomu, že je navržená pro průběžné operace, aktualizace obsahu a přidání samotného indexu probíhají v reálném čase. Pokud se požadavek shoduje s aktualizací dokumentu, můžou dotazy dočasně vrátit neúplné výsledky.
Kontinuita dotazů existuje pro operace dokumentů, jako je aktualizace nebo odstranění, a pro úpravy, které nemají vliv na existující strukturu nebo integritu indexu, například přidání nových polí. Strukturální aktualizace, jako je změna existujících polí, se obvykle spravují pomocí pracovního postupu vyřazení a opětovného sestavení ve vývojovém prostředí nebo vytvořením nové verze indexu v produkční službě.
Aby se zabránilo opětovnému sestavení indexu, někteří zákazníci, kteří provádějí malé změny, "verzují" pole vytvořením nového, které spoluexistuje s předchozí verzí. V průběhu času to vede k opomenutému obsahu prostřednictvím zastaralých polí a zastaralých definic uživatelských analyzátorů, zejména v produkčním indexu, jehož replikace je nákladná. Tyto problémy můžete vyřešit během plánovaných aktualizací indexu jako součást správy životního cyklu indexu.
Připojení koncového bodu
Všechny vektorové indexování a požadavky dotazu cílí na index. Koncové body jsou obvykle jedním z následujících způsobů:
| Koncový bod | Připojení a řízení přístupu |
|---|---|
<your-service>.search.windows.net/indexes |
Cílí na kolekci indexů. Používá se při vytváření, výpisu nebo odstraňování indexu. Pro tyto operace jsou vyžadována práva správce a jsou k dispozici prostřednictvím klíčů rozhraní API pro správu nebo role Přispěvatel vyhledávání. |
<your-service>.search.windows.net/indexes/<your-index>/docs |
Cílí na kolekci dokumentů jednoho indexu. Používá se při dotazování indexu nebo aktualizace dat. U dotazů jsou oprávnění ke čtení dostatečná a dostupná prostřednictvím klíčů rozhraní API dotazů nebo role čtenáře dat. Pro aktualizaci dat jsou vyžadována práva správce. |
Jak se připojit ke službě Azure AI Search
Ujistěte se, že máte oprávnění nebo přístupový klíč rozhraní API. Pokud se nedotazujete na existující index, potřebujete oprávnění správce nebo přiřazení role Přispěvatel ke správě a zobrazení obsahu ve vyhledávací službě.
Začněte s portálem Azure. Osoba, která vytvořila vyhledávací službu, může zobrazit a spravovat, včetně udělení přístupu ostatním na stránce Řízení přístupu (IAM).
Přejděte k dalším klientům pro programový přístup. Pro první kroky doporučujeme rychlý start: Vyhledávání vektorů pomocí REST a úložiště azure-search-vector-samples .
Správa úložišť vektorů
Azure poskytuje monitorovací platformu, která zahrnuje protokolování diagnostiky a upozorňování. Doporučujeme vám:
Zabezpečený přístup k vektorům dat
Azure AI Search implementuje šifrování dat, privátní připojení pro scénáře bez internetu a přiřazení rolí pro zabezpečený přístup prostřednictvím ID Microsoft Entra. Další informace o funkcích zabezpečení podniku najdete v tématu Zabezpečení ve službě Azure AI Search.