Události
Staňte se certifikovaným Datoví technici fabric
14. 1. 23 - 31. 3. 23
Zkontrolujte, jestli máte nárok na nabídku slev na zkoušku, a zaregistrujte se na bezplatné živé relace a připravte se na zkoušku DP-700.
Další informaceTento prohlížeč se už nepodporuje.
Upgradujte na Microsoft Edge, abyste mohli využívat nejnovější funkce, aktualizace zabezpečení a technickou podporu.
.NET pro Apache Spark poskytuje bezplatnou opensourcovou a multiplatformní podporu .NET pro Spark.
Poskytuje vazby .NET pro Spark, které umožňují přístup k rozhraním Spark API prostřednictvím jazyka C# a F#. Pomocí .NET pro Apache Spark můžete také psát a spouštět uživatelem definované funkce pro Spark napsané v .NET. Rozhraní .NET API pro Spark umožňují přístup ke všem aspektům datových rámců Sparku, které vám pomůžou analyzovat data, včetně Spark SQL, Delta Lake a strukturovaného streamování.
Data můžete analyzovat pomocí .NET pro Apache Spark prostřednictvím definic dávkových úloh Sparku nebo pomocí interaktivních poznámkových bloků Azure Synapse Analytics. V tomto článku se naučíte používat .NET pro Apache Spark s Azure Synapse pomocí obou technik.
Důležité
.NET pro Apache Spark je opensourcový projekt v rámci .NET Foundation, který v současné době vyžaduje knihovnu .NET 3.1, která dosáhla stavu mimo podporu. Chceme uživatele Azure Synapse Spark informovat o odebrání knihovny .NET for Apache Spark v modulu Runtime Azure Synapse pro Apache Spark verze 3.3. Další podrobnosti o této záležitosti můžou uživatelé získat v zásadách podpory .NET.
V důsledku toho už uživatelé nebudou moci využívat rozhraní Apache Spark API prostřednictvím C# a F# nebo spouštět kód jazyka C# v poznámkových blocích v rámci Synapse nebo prostřednictvím definic úloh Apache Spark v Synapse. Je důležité si uvědomit, že tato změna má vliv pouze na azure Synapse Runtime pro Apache Spark 3.3 a vyšší.
Budeme i nadále podporovat .NET pro Apache Spark ve všech předchozích verzích modulu Azure Synapse Runtime podle jejich fází životního cyklu. Nemáme ale plány na podporu .NET pro Apache Spark ve službě Azure Synapse Runtime pro Apache Spark 3.3 a budoucí verze. Doporučujeme uživatelům se stávajícími úlohami napsanými v jazyce C# nebo F# migrovat do Pythonu nebo Scaly. Uživatelům doporučujeme, aby si tyto informace a plánovali odpovídajícím způsobem.
V tomto kurzu se dozvíte, jak pomocí Azure Synapse Analytics vytvořit definice úloh Apache Sparku pro fondy Synapse Spark. Pokud jste aplikaci nezabalili, abyste ji odeslali do Azure Synapse, proveďte následující kroky.
Nakonfigurujte závislosti vaší dotnet aplikace pro zajištění kompatibility se službou Synapse Spark.
Požadovaná verze .NET Spark bude zaznamenána v rozhraní Synapse Studio v konfiguraci fondu Apache Spark v sadě nástrojů Správa.

Vytvořte projekt jako konzolovou aplikaci .NET, která vypíše spustitelný soubor Ubuntu x86.
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<OutputType>Exe</OutputType>
<TargetFramework>netcoreapp3.1</TargetFramework>
</PropertyGroup>
<ItemGroup>
<PackageReference Include="Microsoft.Spark" Version="2.1.0" />
</ItemGroup>
</Project>
Spuštěním následujících příkazů publikujte aplikaci. Nezapomeňte mySparkApp nahradit cestou k vaší aplikaci.
cd mySparkApp
dotnet publish -c Release -f netcoreapp3.1 -r ubuntu.18.04-x64
Zazipujte obsah složky publikování, publish.zip například vytvořenou v důsledku kroku 1. Všechna sestavení by měla být v kořenovém adresáři souboru ZIP a neměla by existovat žádná vrstva zprostředkující složky. To znamená, že při rozbalení publish.zipse všechna sestavení extrahují do aktuálního pracovního adresáře.
Ve Windows:
Pomocí Windows PowerShellu nebo PowerShellu 7 vytvořte z obsahu adresáře publikování soubor .zip.
Compress-Archive publish/* publish.zip -Update
V Linuxu:
Otevřete prostředí Bash a cd do adresáře bin se všemi publikovanými binárními soubory a spusťte následující příkaz.
zip -r publish.zip
Poznámkové bloky jsou skvělou volbou pro vytváření prototypů kanálů a scénářů Apache Sparku pro .NET. Můžete začít rychle a efektivně pracovat s daty, porozumět jim, filtrovat je, zobrazovat a vizualizovat.
Datoví inženýři, datoví vědci, obchodní analytici a technici strojového učení můžou spolupracovat na sdíleném interaktivním dokumentu. Uvidíte okamžité výsledky průzkumu dat a můžete je vizualizovat ve stejném poznámkovém bloku.
Při vytváření nového poznámkového bloku zvolíte jádro jazyka, které chcete vyjádřit obchodní logiku. Podpora jádra je k dispozici pro několik jazyků, včetně jazyka C#.
Pokud chcete použít .NET pro Apache Spark v poznámkovém bloku Azure Synapse Analytics, vyberte jako jádro .NET Spark (C#) a připojte poznámkový blok k existujícímu bezserverovému fondu Apache Spark.
Poznámkový blok .NET Spark je založený na interaktivních prostředích .NET a poskytuje interaktivní prostředí jazyka C# s možností používat .NET pro Spark mimo rámeček s již předdefinovanou proměnnou spark relace Sparku.
Balíčky NuGet podle vašeho výběru můžete do poznámkového bloku nainstalovat pomocí #r nuget příkazu magic před názvem balíčku NuGet. Následující diagram znázorňuje příklad:
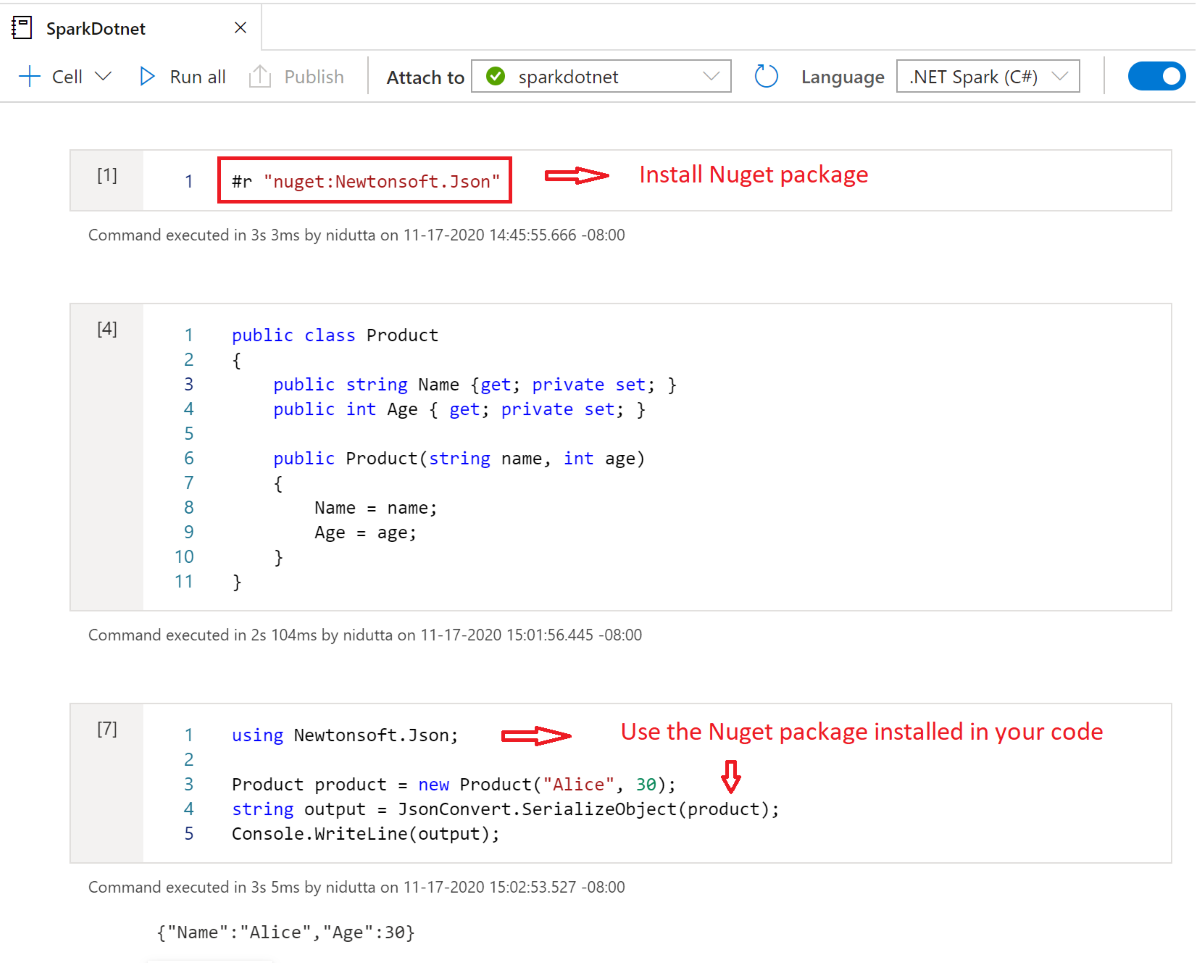
Další informace o tom, jak pracovat s balíčky NuGet v poznámkových blocích, najdete v interaktivní dokumentaci k .NET.
Při použití .NET pro Apache Spark v poznámkovém bloku Azure Synapse Analytics jsou k dispozici následující funkce:
spark jako předdefinovaná proměnná, která vám umožní přístup k relaci Apache Sparku.XPlot.Plotly knihovny.Definice úloh Synapse Sparku ve fondech Spark pomocí Sparku 2.4 vyžadují Microsoft.Spark verzi 1.0.0. Vymažte své bin adresáře a obj publikujte projekt pomocí verze 1.0.0.
Dotnet Spark 1.0.0 používá jinou architekturu ladění než 1.1.1 nebo novější. Pro místní ladění budete muset použít verzi 1.0.0 a 1.1.1 nebo novější.
Události
Staňte se certifikovaným Datoví technici fabric
14. 1. 23 - 31. 3. 23
Zkontrolujte, jestli máte nárok na nabídku slev na zkoušku, a zaregistrujte se na bezplatné živé relace a připravte se na zkoušku DP-700.
Další informaceŠkolení
Modul
Použití poznámkových bloků Sparku v kanálu Azure Synapse - Training
Tento modul popisuje, jak je možné integrovat poznámkové bloky Apache Spark do kanálu Azure Synapse Analytics.
Certifikace
Microsoft Certified: Azure Data Scientist Associate - Certifications
Manage data ingestion and preparation, model training and deployment, and machine learning solution monitoring with Python, Azure Machine Learning and MLflow.