Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tento článek popisuje, jak generace rozšířená vyhledáváním umožňuje LLMs přistupovat k vašim zdrojům dat jako ke znalostem bez nutnosti trénování.
LLM mají rozsáhlé znalostní báze díky školení. Ve většině scénářů můžete vybrat LLM, který je určený pro vaše požadavky, ale tyto LLM stále vyžadují další trénování, aby porozuměly vašim konkrétním datům. Generování s rozšířeným načítáním umožňuje zpřístupnit data pro LLMs, aniž by bylo nutné je nejprve trénovat.
Jak RAG funguje
Chcete-li provádět generování obohacené načítáním, vytvoříte vestavby pro svá data spolu s běžnými dotazy. Můžete to provést za běhu nebo můžete vytvářet a ukládat vložené položky pomocí řešení vektorové databáze.
Když uživatel položí otázku, LLM použije vaše vkládání k porovnání otázky uživatele s vašimi daty a nalezení nejrelevavantnějšího kontextu. Tento kontext a dotaz uživatele jsou poté zadané LLM jako výzva a LLM poskytuje odpověď na základě těchto informací.
Základní proces RAG
Chcete-li provést RAG, je nutné zpracovat každý zdroj dat, který chcete použít pro načítání. Základní proces je následující:
- Rozdělte velká data do spravovatelných částí.
- Převeďte bloky dat do prohledávatelného formátu.
- Ukládejte převedená data do umístění, které umožňuje efektivní přístup. Kromě toho je důležité ukládat relevantní metadata pro citace nebo odkazy, když LLM poskytuje odpovědi.
- Po zobrazení výzev můžete převést data na LLM.
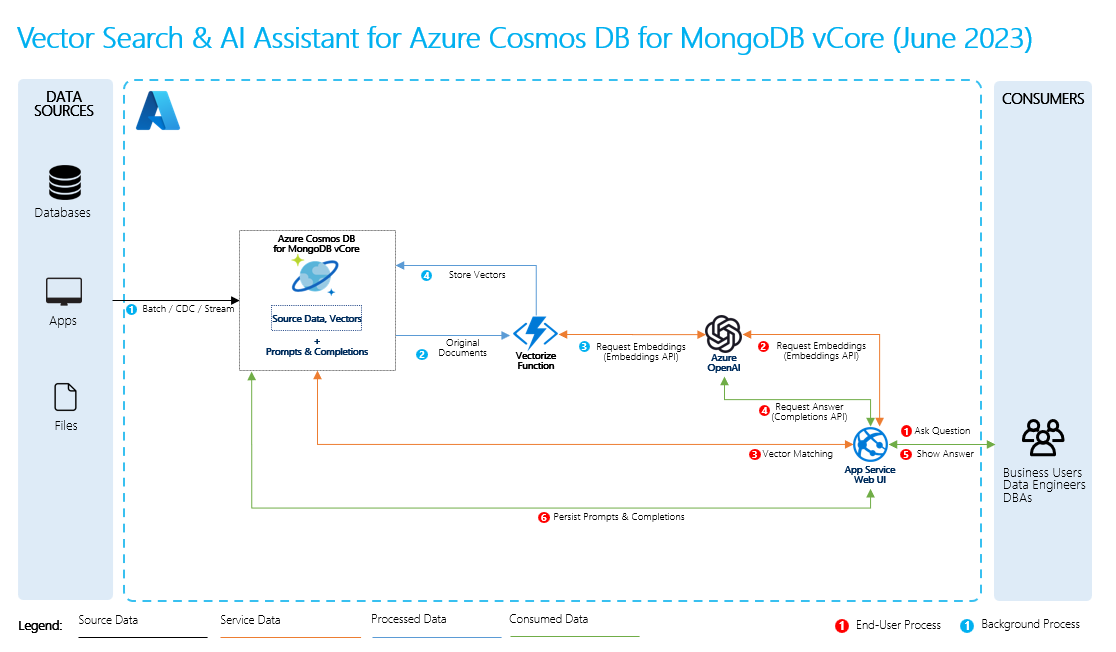
- Zdrojová data: Tady jsou vaše data. Může se jednat o soubor nebo složku na vašem počítači, soubor v cloudovém úložišti, datový prostředek služby Azure Machine Learning, úložiště Git nebo databázi SQL.
- Rozdělování dat na bloky: Data ve vašem zdroji musí být převedena na prostý text. Například dokumenty Word nebo soubory PDF musí být otevřeny a převedeny na text. Text se pak rozdělí na menší části.
- Převod textu na vektory: Jedná se o vkládání. Vektory jsou číselné reprezentace konceptů převedených na číselné sekvence, což usnadňuje počítačům pochopení vztahů mezi těmito koncepty.
- Propojení mezi zdrojovými daty a embeddingy: Tyto informace se ukládají jako metadata na vytvořených blocích, které se pak používají, aby LLMs generovaly citace při vytváření odpovědí.
Viz také
Spolupracujte s námi na GitHubu
Zdroj tohoto obsahu najdete na GitHubu, kde můžete také vytvářet a kontrolovat problémy a žádosti o přijetí změn. Další informace najdete v našem průvodci pro přispěvatele.